Chapter 27
The Future of Large Language Models
"The future of AI is not just about making models bigger, but making them smarter, more efficient, and more aligned with human values." — Fei-Fei Li
Chapter 27 of LMVR explores the future of large language models (LLMs) through the lens of emerging trends, advanced architectures, innovative training techniques, and optimized deployment strategies, all within the context of Rust. The chapter emphasizes how Rust's performance, safety, and scalability make it an ideal language for pushing the boundaries of LLMs, from implementing cutting-edge models like sparse transformers to optimizing real-time inference and ensuring ethical AI development. It also looks forward to the integration of LLMs with emerging technologies, such as quantum computing and neuromorphic hardware, positioning Rust as a key enabler of the next generation of AI research and innovation.
27.1. Emerging Trends in Large Language Models
The field of large language models (LLMs) has seen remarkable advancements in recent years, with their applications extending across numerous industries, including healthcare, finance, education, and customer support. LLMs have transformed how companies and developers approach tasks like language translation, content creation, code generation, and even customer interaction. These models leverage vast amounts of data and complex architectures to generate human-like responses and insights, enabling them to perform a wide array of tasks previously considered out of reach for machines. This section provides an overview of the emerging trends shaping the future of LLMs, emphasizing how advancements in model architecture, training methodologies, and deployment strategies are redefining what LLMs can achieve. Furthermore, we explore the unique role that Rust can play in these developments, particularly as a tool for improving performance, memory safety, and scalability, all critical factors for next-generation language model applications.
Figure 1: Future advancements in LLMs using Rust technology.
As LLMs increase in complexity and scale, so does the demand for more efficient and optimized training and inference methods. One of the primary trends emerging in response to this challenge is the focus on model efficiency. New architectures such as sparse attention models, knowledge-augmented transformers, and hybrid neural-symbolic architectures are pushing the boundaries of traditional LLM design, making it possible to train larger models without the prohibitive resource costs typically associated with scale. For instance, the shift towards sparsity in transformer models reduces the number of computations required by focusing on a select subset of attention connections, leading to faster inference times and lower power consumption. Rust’s concurrency and memory safety features make it well-suited for implementing these efficient architectures, particularly through libraries like tch-rs and candle. By leveraging Rust’s low-level control and powerful concurrency model, developers can achieve high throughput and minimize latency, which are essential for deploying complex LLMs efficiently.
In parallel with the drive for efficiency, the LLM field is also moving towards more specialized and domain-specific models. While general-purpose LLMs have proven effective in a wide variety of tasks, industry-specific applications often require models fine-tuned for specialized vocabulary, context, and operational constraints. For instance, in healthcare, an LLM trained on medical literature and patient interaction data can provide diagnostic support and patient guidance with greater relevance than a general-purpose model. Rust’s strong ecosystem of libraries like llm_chain and langchain_rust enables developers to construct custom pipelines for training and fine-tuning domain-specific models. The memory efficiency of Rust allows for rapid prototyping and experimentation with smaller, specialized models on limited hardware resources, making it feasible for companies to develop tailored LLMs without large-scale infrastructure investments.
The growth of LLMs also brings significant ethical considerations, particularly around issues of bias, privacy, and the potential misuse of AI-generated content. As models become more autonomous and widely deployed, it is essential to address these ethical concerns. Techniques for bias mitigation, such as adversarial training and data balancing, and privacy-preserving methods like differential privacy, are becoming standard practices in LLM development. Rust’s ownership model and strong typing system provide the reliability required to implement privacy-preserving algorithms safely, and cryptographic libraries in Rust support differential privacy implementations that ensure individual data points cannot be reverse-engineered from model outputs. Furthermore, Rust’s deterministic memory management reduces the risk of accidental data leakage, an essential feature in privacy-sensitive applications like finance and healthcare.
Setting up a Rust-based environment for LLM experimentation involves using Rust's mature libraries and frameworks that streamline the development and optimization of advanced LLM techniques. Libraries such as tch-rs, which provides bindings for PyTorch in Rust, and candle, which is designed for efficient deep learning on minimal hardware, allow developers to create and test LLM architectures natively in Rust. The llm_chain crate supports building multi-step pipelines for tasks that require more than single-pass generation, such as conversational agents or interactive applications. For example, a typical pipeline might include an initial model prompt generation followed by response filtering and context maintenance, a setup that llm_chain makes highly modular and efficient.
This pseudo code demonstrates the development and deployment of large language models (LLMs) in Rust, focusing on model efficiency, domain specialization, and ethical considerations. It outlines steps to implement efficient architectures, such as sparse attention models, and to fine-tune domain-specific LLMs for specialized applications like healthcare. Furthermore, it incorporates privacy-preserving techniques and ethical safeguards using Rust's memory safety, concurrency, and cryptographic capabilities. Rust’s libraries, including tch-rs, candle, and llm_chain, are leveraged to streamline the development of modular, secure, and efficient LLM systems suitable for production use.
// Define Advanced LLM System with Efficiency, Domain Specialization, and Privacy-Safety Features
LLMSystem:
model_architecture: architecture of the LLM (e.g., sparse attention)
domain_data: dataset specific to the target industry or application
privacy_settings: differential privacy parameters (epsilon, delta)
ethical_constraints: configurations for bias mitigation and data protection
// Initialize the LLM system with model architecture, domain data, privacy, and ethical constraints
new(model_architecture, domain_data, privacy_settings, ethical_constraints):
set self.model_architecture to model_architecture
set self.domain_data to domain_data
set self.privacy_settings to privacy_settings
set self.ethical_constraints to ethical_constraints
// Method for efficient model training with sparse attention
train_with_sparse_attention():
sparse_attention_model = initialize_sparse_attention_model(model_architecture)
for each batch in domain_data:
gradients = compute_gradients(sparse_attention_model, batch)
sparse_gradients = apply_sparse_mask(gradients)
update_model_parameters(sparse_attention_model, sparse_gradients)
return sparse_attention_model
// Method for domain-specific fine-tuning using custom pipeline
fine_tune_for_domain():
specialized_model = initialize_model_for_domain(model_architecture, domain_data)
for each epoch in training loop:
domain_batch = sample_domain_data(domain_data)
loss = calculate_loss(specialized_model, domain_batch)
update_model_with_fine_tuning(specialized_model, loss)
return specialized_model
// Method for privacy-preserving differential privacy implementation
apply_differential_privacy(model):
noise_scale = calculate_noise_scale(privacy_settings)
for each parameter in model:
parameter += generate_noise(noise_scale)
return model
// Method to integrate ethical safeguards for bias mitigation
integrate_bias_mitigation():
for each client_data in domain_data:
bias_metrics = calculate_bias_metrics(client_data)
if bias_metrics exceed threshold:
adjust_data_balance(client_data)
return calculate_global_bias_score()
// Main LLM processing pipeline using modular steps
async llm_processing_pipeline():
// Step 1: Train with efficiency using sparse attention
sparse_model = train_with_sparse_attention()
// Step 2: Fine-tune the model for specific domain needs
domain_model = fine_tune_for_domain()
// Step 3: Apply differential privacy for secure data handling
private_model = apply_differential_privacy(domain_model)
// Step 4: Integrate ethical safeguards for model fairness
bias_score = integrate_bias_mitigation()
log_bias_score(bias_score)
// Return the optimized and privacy-preserving model
return private_model
// Supporting Functions for LLM System
// Function to initialize a sparse attention model
initialize_sparse_attention_model(architecture):
model = create_model(architecture with sparse attention layers)
return model
// Function to compute gradients with sparse connections
apply_sparse_mask(gradients):
return apply mask to gradients to zero out less important connections
// Function to initialize a model fine-tuned for a specific domain
initialize_model_for_domain(architecture, data):
model = create_model(architecture)
load domain-specific weights and settings into model
return model
// Function to calculate loss for domain-specific training
calculate_loss(model, data):
return compute loss for model predictions on data
// Function to add differential privacy noise to model parameters
generate_noise(scale):
return Gaussian or Laplace noise scaled by scale
// Function to calculate bias metrics for data
calculate_bias_metrics(data):
return analyze data for representational biases
// Function to adjust data balance to mitigate bias
adjust_data_balance(data):
modify data proportions to reduce identified bias
// Function to log bias score for model auditing
log_bias_score(score):
log score with timestamp for auditing and compliance
// Main Execution for Advanced LLM System
main:
model_architecture = set LLM architecture (e.g., sparse attention)
domain_data = load data specific to the target industry (e.g., healthcare)
privacy_settings = configure differential privacy parameters (epsilon, delta)
ethical_constraints = set bias and fairness thresholds
// Initialize LLM system with specified configurations
llm_system = new LLMSystem(model_architecture, domain_data, privacy_settings, ethical_constraints)
// Run the asynchronous LLM processing pipeline
optimized_model = await llm_system.llm_processing_pipeline()
print "LLM Pipeline Completed with Privacy and Bias Mitigations"
This pseudo code provides a modular LLM development and deployment pipeline that integrates efficiency, domain specialization, privacy preservation, and ethical considerations:
Efficient Training with Sparse Attention: The
train_with_sparse_attentionmethod initializes and trains a sparse attention model, reducing the computational load by masking unimportant attention connections. This setup allows for faster inference and training.Domain-Specific Fine-Tuning: The
fine_tune_for_domainmethod further customizes the model using domain-specific data (e.g., healthcare), improving relevance and accuracy for specialized tasks. This method samples domain data and fine-tunes the model based on calculated losses, allowing targeted model adaptation.Privacy Preservation with Differential Privacy: The
apply_differential_privacymethod applies noise to model parameters, ensuring individual data privacy according to privacy settings (e.g.,epsilon,delta). This step prevents sensitive data from being reverse-engineered from model outputs.Bias Mitigation for Ethical Safeguards: The
integrate_bias_mitigationmethod calculates bias metrics and adjusts data balance as necessary to prevent skewed results. It provides a bias score that is logged for compliance and ethical transparency.LLM Processing Pipeline: The
llm_processing_pipelinemethod orchestrates the complete workflow asynchronously, running each step (efficient training, fine-tuning, privacy application, and bias mitigation) sequentially to produce an optimized, secure, and ethically sound model.
In the main function, an LLM system is initialized with specified architecture, domain data, privacy settings, and ethical constraints, and the processing pipeline is executed. This setup is well-suited to Rust's strengths in memory safety, efficient computation, and strong type system, making it reliable and performant for real-world applications in sensitive fields.
Finally, the future of LLMs will likely continue to be shaped by an integration of ethical considerations with technical advancements. The latest trends indicate a shift toward explainability-by-design, where transparency is built into model architectures, making it easier to interpret how specific outputs are generated. For example, models may incorporate features that track and visualize the attention mechanism during inference, providing insights into how particular input tokens influence the model’s response. As these explainability features become more prevalent, Rust’s extensive visualization libraries and secure memory management will be valuable for creating transparent, interpretable models suitable for deployment in sensitive applications. Explainable LLMs offer the potential for more accountable AI systems, which can meet regulatory standards and gain user trust, especially in sectors like healthcare and finance, where decision support systems must be both accurate and transparent.
The Rust ecosystem’s rapid growth, combined with its performance, safety, and scalability, positions it as an essential tool in the development of next-generation LLMs. As industry adoption of Rust increases, the language’s role in AI, and particularly in the evolution of LLMs, is expected to expand significantly, paving the way for a future where efficient, secure, and ethically sound language models are within reach for a wide array of applications. This section provides a foundational understanding of the emerging trends in LLMs, setting the stage for more detailed explorations into each aspect of Rust-based LLM development in subsequent sections.
27.2. Advancements in Model Architecture and Design
As large language models (LLMs) evolve, new model architectures are emerging to push the boundaries of what these models can achieve. Traditional transformer architectures have been the backbone of LLMs, but newer designs like sparse transformers, mixture of experts (MoE), and neural architecture search (NAS) are introducing innovative ways to optimize performance, efficiency, and scalability. Sparse transformers, for instance, modify the traditional dense attention mechanisms by selectively focusing on specific parts of the input sequence, significantly reducing computation without compromising model accuracy. Mixture of experts models, on the other hand, use modular networks in which only a subset of “experts” is activated for any given input, resulting in a massive reduction in computational load. Meanwhile, NAS automates the process of architecture design by applying machine learning to explore various model configurations, generating architectures optimized for specific tasks or resource limitations. These advancements, coupled with the performance capabilities of Rust, offer an exciting new frontier for LLM development, where models are not only powerful but also highly efficient in their computational demands.
Figure 2: LLM architecture implementation.
Implementing advanced architectures like sparse transformers, mixture of experts (MoE), and neural architecture search (NAS) for large language models (LLMs) in Rust addresses multiple challenges inherent in modern LLM design. These architectures push efficiency and scalability to new levels, tackling computational demands without compromising model performance. Sparse transformers, for instance, are especially suited for processing long sequences by focusing attention on only the most relevant tokens, reducing memory usage and computation time. Rust’s low-level memory control capabilities are particularly advantageous here, as they enable efficient handling of sparse data structures and optimized execution, especially when combined with high-performance libraries like tch-rs. This approach allows developers to selectively compute attention scores, minimizing unnecessary calculations and improving latency for deployments where efficiency is critical.
Mixture of experts (MoE) models bring a modular, scalable approach to LLMs by selectively activating only the experts necessary for a given input. This selective activation dramatically reduces computational overhead while maintaining model accuracy. Rust’s asynchronous processing capabilities, supported by libraries like tokio, make it possible to dynamically route inputs to the most relevant experts in a non-blocking, concurrent manner. This ensures that MoE models can efficiently handle large-scale input data without creating bottlenecks. In Rust, each expert can operate concurrently, and the concurrency model helps manage resources effectively, optimizing computation even with multiple active experts. This modularity enables the efficient handling of massive models, making Rust an ideal environment for MoE implementations.
Neural Architecture Search (NAS) is an adaptive technique in LLM development, automating the creation of optimal architectures for specific tasks. NAS algorithms are computationally demanding, often requiring extensive trial-and-error across configurations to identify the best model setup. Rust’s parallel processing and concurrency strengths make it well-suited for implementing NAS algorithms efficiently, allowing developers to explore and evaluate numerous configurations in parallel. Rust’s deterministic memory management also ensures that these experiments are reliable, reducing the likelihood of unexpected behaviors that could affect performance during large-scale architecture searches. The controlled and predictable memory environment of Rust allows NAS to run efficiently even across large search spaces, making it a practical choice for optimizing LLM architectures.
In Rust, these advanced LLM architectures—sparse transformers, MoE, and NAS—are more feasible to experiment with and deploy at scale. Sparse transformers enable the creation of models that maintain accuracy while operating under reduced computational loads, a balance achieved through Rust’s fine-grained memory control and concurrency. MoE models benefit from Rust’s support for concurrent processing, allowing the system to dynamically activate only the necessary experts and process each in parallel. NAS implementations capitalize on Rust’s ability to handle extensive configuration testing with minimal latency and memory safety. By incorporating these innovations into LLM systems, Rust provides the tools necessary for developing, experimenting, and benchmarking next-generation LLM architectures, offering a strong foundation for models that need to be both powerful and computationally efficient.
As LLM development advances, Rust emerges as a robust foundation for building and deploying these innovative models. The combination of Rust’s performance, safety, and memory management capabilities allows developers to explore and refine architectures that meet the efficiency and scalability requirements of real-world applications. With Rust, LLMs that implement sparse transformers, MoE, and NAS are not only feasible but optimized for modern computational demands, paving the way for language models that are both capable and resource-efficient. In doing so, Rust positions itself as an essential tool for driving forward the future of LLMs, supporting applications across industries that demand cutting-edge AI solutions.
The following pseudo codes demonstrate the implementation of advanced LLM architectures in Rust, including sparse transformers for efficient attention calculations, mixture of experts (MoE) models for modular computation, and neural architecture search (NAS) for optimizing model configurations. These architectures collectively aim to improve model efficiency, scalability, and adaptability to computational constraints.
Sparse transformers reduce computation by calculating attention only for a subset of relevant tokens, improving efficiency for long sequences.
// Define Sparse Transformer Class
SparseTransformer:
input_sequence: input data for processing
top_k: number of tokens to select for sparse attention
// Initialize with input data and sparsity level
new(input_sequence, top_k):
set self.input_sequence to input_sequence
set self.top_k to top_k
// Method to compute sparse attention
compute_sparse_attention():
for each token in input_sequence:
scores = calculate_attention_scores(token, input_sequence)
top_scores = select_top_k(scores, self.top_k)
attention_weights = apply_softmax(top_scores)
weighted_sum = calculate_weighted_sum(attention_weights, input_sequence)
return weighted_sum
// Supporting Functions
calculate_attention_scores(token, sequence):
return dot_product(token, sequence) / sqrt(sequence.length)
select_top_k(scores, k):
return select top k highest scores from scores
apply_softmax(scores):
return normalized probabilities of scores
calculate_weighted_sum(weights, sequence):
return sum(weights * corresponding values in sequence)
// Execute Sparse Transformer
main:
sequence = load_data()
sparse_transformer = SparseTransformer(sequence, top_k=5)
sparse_output = sparse_transformer.compute_sparse_attention()
print("Sparse Attention Output:", sparse_output)
The MoE model activates a subset of expert modules based on input, reducing computational demands while maintaining model flexibility and accuracy.
// Define Mixture of Experts Model
MixtureOfExperts:
experts: list of expert modules
router: mechanism for assigning inputs to relevant experts
// Initialize with experts and routing mechanism
new(experts, router):
set self.experts to experts
set self.router to router
// Method to process input with active experts
process_input(input_data):
selected_experts = router.assign_experts(input_data)
expert_outputs = []
for each expert in selected_experts:
expert_output = expert.compute(input_data)
expert_outputs.append(expert_output)
return aggregate_outputs(expert_outputs)
// Supporting Functions
assign_experts(input_data):
return select subset of experts based on input features
aggregate_outputs(outputs):
return combine outputs from active experts (e.g., average or weighted sum)
// Execute Mixture of Experts
main:
experts = initialize_experts()
router = initialize_router()
moe_model = MixtureOfExperts(experts, router)
input_data = load_data()
output = moe_model.process_input(input_data)
print("Mixture of Experts Output:", output)
NAS iteratively searches for the best model architecture by testing multiple configurations, balancing factors like layer depth, sparsity, and performance.
// Define Neural Architecture Search System
NeuralArchitectureSearch:
search_space: list of potential model configurations
evaluation_metric: performance metric for evaluating architectures
// Initialize with search space and metric
new(search_space, evaluation_metric):
set self.search_space to search_space
set self.evaluation_metric to evaluation_metric
// Method to search for optimal architecture
search_optimal_architecture():
best_score = -infinity
best_architecture = None
for each architecture in search_space:
model = build_model(architecture)
performance = evaluate_model(model, evaluation_metric)
if performance > best_score:
best_score = performance
best_architecture = architecture
return best_architecture, best_score
// Supporting Functions
build_model(architecture):
return construct model with specified architecture
evaluate_model(model, metric):
return performance of model on given metric
// Execute Neural Architecture Search
main:
search_space = define_model_search_space()
nas = NeuralArchitectureSearch(search_space, evaluation_metric="accuracy")
optimal_architecture, score = nas.search_optimal_architecture()
print("Optimal Architecture:", optimal_architecture)
print("Performance Score:", score)
Implementing these advanced architectures in Rust addresses significant challenges associated with modern LLMs:
Sparse Transformer for Efficient Attention: Sparse transformers focus computational resources on the most relevant parts of input sequences, achieving efficiency without sacrificing performance. Rust’s memory management ensures sparse attention computations are conducted efficiently, particularly with libraries like
tch-rsthat optimize tensor operations. The sparse transformer selectively calculates attention scores, which minimizes computation for long sequences, making it well-suited for latency-sensitive applications.Mixture of Experts for Modular Computation: MoE models select and activate only the necessary experts for each input, drastically reducing computational load. Rust’s
tokiolibrary allows asynchronous, concurrent execution, enabling multiple experts to run independently and optimizing resource usage. This setup is beneficial for handling large-scale data inputs with minimal delays, as Rust’s concurrency model supports efficient management of modular computation, enabling the model to scale easily.Neural Architecture Search for Optimal Model Design: NAS explores numerous architectural configurations to identify the most efficient model. This process is computationally intensive, but Rust’s performance optimizations and parallel processing capabilities enable it to execute NAS efficiently across large search spaces. Rust’s deterministic memory management enhances reliability, reducing unexpected behavior during NAS and ensuring that the architecture search process is both effective and resource-conscious.
By implementing architectures like sparse transformers, MoE models, and NAS, developers can push LLM efficiency and scalability to new levels. Rust’s strengths in performance, memory safety, and concurrency make it an ideal language for handling the computational demands and resource constraints of modern LLM architectures. With Rust, these advanced models are feasible to develop, experiment with, and deploy, providing a reliable foundation for language models that meet the efficiency and scalability needs of real-world applications. Rust’s high performance and safety features position it as a key tool for advancing LLM design, supporting the development of robust, efficient, and scalable models that drive innovation across industries.
Through advanced architectures like sparse transformers, MoE models, and NAS, the future of LLMs is set to be both more powerful and efficient. Rust’s strengths in performance, safety, and scalability provide a stable foundation for realizing these advancements, enabling developers to experiment with novel architectural designs and build models that are not only computationally efficient but also reliable and scalable. These advancements position Rust as an instrumental language for pushing the boundaries of what is possible in large language model development, supporting the next generation of LLMs that will define the future of AI across industries.
27.3. Innovations in Training Techniques and Optimization
In recent years, significant advancements in training techniques and optimization strategies have emerged to address the growing computational demands of large language models (LLMs). These innovations are critical as models continue to increase in size, with billions or even trillions of parameters, requiring vast computational resources and careful management of memory and processing power. Techniques like low-rank factorization, model quantization, and gradient checkpointing are at the forefront of these improvements, each offering methods to streamline training without sacrificing model performance. Low-rank factorization reduces the complexity of model layers by approximating large matrices with smaller, low-rank components, which in turn lessens the memory and processing requirements during training. Quantization, on the other hand, decreases the precision of model parameters, reducing memory usage and speeding up computations by utilizing lower-bit representations. Gradient checkpointing enables efficient memory usage by storing only a subset of intermediate states during the forward pass, recalculating them as needed during backpropagation. These techniques not only address computational costs but also support the future scalability of LLMs, making it feasible to train increasingly sophisticated models. Rust’s inherent performance, memory safety, and control over low-level memory operations make it an ideal language for implementing these advanced training optimizations.
Figure 3: Common optimization techniques for LLMs.
Optimizing training efficiency in LLMs often involves balancing computational savings with model performance. Low-rank factorization, for example, approximates dense layers with smaller matrices, reducing memory and computational load. Mathematically, a matrix $W \in \mathbb{R}^{m \times n}$ can be approximated as $W \approx UV$, where $U \in \mathbb{R}^{m \times k}$ and $V \in \mathbb{R}^{k \times n}$ with $k \ll \min(m, n)$. This factorization reduces the number of parameters and speeds up matrix multiplication, enabling faster model updates. Implementing low-rank factorization in Rust is efficient due to its direct memory control and concurrency model, which reduces the bottlenecks often encountered in high-dimensional computations.
The following pseudo code provides a comprehensive framework for optimizing the training process of large language models (LLMs), which are computationally intensive due to their vast number of parameters. The code employs several advanced techniques such as low-rank factorization, quantization, gradient checkpointing, distributed training, and hardware acceleration to manage memory usage, enhance processing efficiency, and reduce computational overhead. These methods are critical for enabling scalable training of LLMs on limited resources, making the framework ideal for applications that demand high-performance language models in a sustainable and accessible manner.
// Pseudo Code for Training and Optimizing Large Language Models (LLMs) in Rust
// Initialize model and define essential functions for training optimizations
START:
FUNCTION InitializeModel(parameters):
Create a model with specified layers and parameters
Initialize layers with random weights
RETURN model
// Low-Rank Factorization to reduce model complexity
FUNCTION LowRankFactorization(matrix, rank):
// matrix: Original model matrix
// rank: Lower rank for approximation
Initialize U and V matrices of shapes m x rank and rank x n
WHILE convergence criteria not met:
Update U and V to minimize error between matrix and U * V
RETURN U, V
// Low-Rank Approximation example usage
Initialize modelMatrix
U, V = LowRankFactorization(modelMatrix, rank)
approximation = U * V // Use the approximation in place of original matrix
// Quantization for memory and computation efficiency
FUNCTION QuantizeWeights(model, bitPrecision):
// Convert model weights to specified lower bit precision (e.g., 8-bit)
FOR each layer in model:
Convert layer weights to bitPrecision
RETURN quantizedModel
// Quantization-aware Training (QAT) which adjusts weights during training
FUNCTION QuantizationAwareTraining(model, bitPrecision):
FOR each training iteration:
Perform forward pass on quantized model
Compute loss and backpropagate gradients
Adjust weights with bit precision taken into account
RETURN optimizedQuantizedModel
// Gradient Checkpointing to reduce memory use during backpropagation
FUNCTION GradientCheckpointing(model, layersToCheckpoint):
// Save memory by storing selective layers' activations only
FOR each layer in model:
IF layer in layersToCheckpoint:
Store activation
ELSE:
Recompute activation during backward pass as needed
RETURN memoryOptimizedModel
// Distributed Training for parallel computation
FUNCTION DistributedTraining(model, data, numNodes):
Split data into chunks, distribute across nodes
FOR each node:
Initialize model replica
Perform forward and backward passes
Send gradient updates to central node
Aggregate gradients across nodes
Update global model with aggregated gradients
RETURN distributedModel
// Hardware Acceleration with GPUs/TPUs
FUNCTION UseHardwareAcceleration(model, device):
IF device == "GPU" or "TPU":
Allocate model to device memory
Use accelerated computation kernels (e.g., CUDA for GPU)
ELSE:
Perform on CPU
RETURN acceleratedModel
// Main training loop integrating all techniques
FUNCTION TrainModel(data, parameters):
model = InitializeModel(parameters)
// Apply Low-Rank Factorization to reduce computation complexity
FOR each matrix in model layers:
U, V = LowRankFactorization(matrix, rank)
Replace original matrix with U * V
// Quantize model for memory efficiency
quantizedModel = QuantizeWeights(model, bitPrecision=8)
// Optimize memory with Gradient Checkpointing
checkpointedModel = GradientCheckpointing(quantizedModel, layersToCheckpoint)
// Parallelize using Distributed Training
distributedModel = DistributedTraining(checkpointedModel, data, numNodes)
// Use Hardware Acceleration for speedup
finalModel = UseHardwareAcceleration(distributedModel, device="GPU")
RETURN finalModel
// Final Training and Evaluation
Initialize data and model parameters
trainedModel = TrainModel(data, parameters)
EVALUATE trainedModel on test data
PRINT "Training complete and model optimized for large-scale usage"
END
The code begins with model initialization and applies low-rank factorization to reduce matrix sizes, which lowers memory and processing needs. Quantization follows, converting model weights to lower-precision representations, effectively reducing memory and computation time. Gradient checkpointing is used to save selective layer states, conserving memory during backpropagation by recomputing intermediate activations only when necessary. The code then distributes training tasks across multiple nodes or GPUs, achieving parallelism and expediting the training process. Finally, it utilizes hardware acceleration with GPUs or TPUs to optimize computation speed further. Together, these techniques streamline the training of large-scale models by minimizing memory usage, increasing computational speed, and maintaining model performance, making it possible to train large models efficiently.
Quantization further aids in memory and computation efficiency by representing model weights and activations in lower precision. In many cases, 32-bit floating-point numbers can be represented as 8-bit integers, dramatically reducing memory usage and computation time with minimal impact on accuracy. Quantization-aware training, which adjusts the weights during training to account for lower precision, can be effectively implemented in Rust by controlling data types and bitwise operations directly. The tch crate (PyTorch bindings for Rust) supports model quantization, allowing users to switch between higher and lower precision types dynamically.
For training large models, distributed systems offer another critical solution, distributing workload across multiple GPUs or computing nodes. Distributed training in Rust can be implemented using tokio for asynchronous processing and crates like mpi for inter-process communication, enabling parallel computation and synchronization across nodes. Rust’s type safety and efficient concurrency model are ideal for managing distributed systems, where errors in memory management or process synchronization can lead to significant resource wastage or model inaccuracies.
Gradient checkpointing is another optimization technique that conserves memory during backpropagation by selectively saving certain layers’ states and recomputing them as needed. For large-scale LLMs, storing every layer’s state is infeasible due to memory constraints, especially when working with hardware-limited environments. Gradient checkpointing offers an alternative by recalculating activations in the backward pass. This is particularly feasible in Rust due to its efficient memory handling and control over computation flow, enabling recomputation with minimal memory overhead.
Hardware acceleration, using devices like GPUs and TPUs, plays a vital role in executing these advanced training techniques at scale. Rust’s ecosystem provides integration with CUDA for GPU-based computation, allowing developers to harness the parallel processing power of GPUs for intensive training tasks. The cust crate provides Rust bindings for CUDA, making it possible to perform low-level CUDA programming within Rust, offering precise control over device memory and kernel execution. Combining gradient checkpointing, quantization, and distributed training with hardware acceleration in Rust can significantly reduce training times for large models, making it possible to train LLMs more effectively on limited resources.
Energy efficiency and sustainability have become increasingly important in the field of LLMs, given the high computational demands of these models. As LLMs grow larger, so does their environmental footprint, with training sometimes consuming thousands of megawatt-hours. Efficient training methods such as low-rank factorization, gradient checkpointing, and hardware-optimized operations can mitigate this impact by reducing the number of computations required. Rust’s low-level control and efficient resource management contribute to more sustainable AI development, allowing researchers to implement energy-efficient algorithms that minimize resource consumption without compromising performance.
Rust provides an excellent environment for experimenting with these innovations in training and optimization techniques. For example, distributed systems in Rust can be used to implement federated learning, which decentralizes model training to reduce centralized resource requirements and improve privacy. The ability to manage concurrent tasks and inter-process communication in Rust makes it an ideal choice for these types of distributed, resource-optimized applications. With advancements in Rust libraries and tools, the language is well-suited to support future developments in LLM training, positioning it as a valuable resource for researchers and engineers dedicated to building efficient, powerful, and sustainable LLMs.
By exploring these training and optimization techniques, developers can harness the power of Rust to meet the challenges posed by the next generation of LLMs. Innovations such as low-rank factorization, quantization, gradient checkpointing, and distributed systems are not only enhancing the efficiency of model training but are also shaping the future landscape of AI by making LLMs more accessible, sustainable, and adaptable to diverse applications. With Rust at the core of these advancements, the future of LLMs holds immense potential for innovation and impact across industries.
27.4. Deployment Strategies and Real-Time Inference
Deploying large language models (LLMs) presents unique challenges in balancing latency, scalability, and operational cost. With billions of parameters, these models demand considerable computational resources, which can become a limiting factor in real-time applications where responsiveness is crucial. As LLMs continue to advance, the deployment environment—whether cloud, edge, or on-device—plays a pivotal role in determining the feasibility and performance of these models. In cloud-based deployments, scalability is the primary advantage, allowing resources to be scaled elastically to meet demand. However, edge deployments offer the advantage of reduced latency by bringing computation closer to the user, while on-device deployments are particularly valuable in applications that demand offline capabilities. Rust’s high-performance capabilities, coupled with its fine-grained control over memory and hardware resources, make it an ideal language for building optimized deployment pipelines that address these diverse requirements.
Figure 4: LLM Deployment Optimizations.
One of the key challenges in deploying LLMs is achieving low latency in inference while managing computational costs. Real-time inference demands that models produce predictions in milliseconds, making optimizations like model distillation, pruning, and caching essential. Model distillation involves training a smaller, less complex model (the student) to mimic the behavior of a larger, more complex model (the teacher), effectively reducing latency while preserving performance. In Rust, model distillation can be implemented by training a simplified architecture and then deploying this distilled model using libraries like tch-rs or candle. Pruning, on the other hand, reduces the model’s parameter count by removing unimportant weights, which directly decreases the model size and improves inference speed. Rust’s memory safety and resource control ensure efficient implementation of pruning techniques, allowing developers to manage the trade-off between speed and accuracy effectively.
The following pseudo code demonstrates an efficient approach for deploying large language models (LLMs) with minimal latency and optimized computational costs. By integrating caching, distillation, and pruning techniques, it enables faster inference and lower memory usage, which is essential for real-time applications. The caching mechanism stores previous model responses to avoid redundant computation, while model distillation and pruning reduce model size and complexity. This pseudo code also outlines edge deployment strategies for low-latency environments, continuous monitoring for model performance, and the use of hardware accelerators for high-throughput scenarios.
// Define a data structure for caching model inferences to reduce redundant computations
Class InferenceCache:
Initialize cache as a thread-safe storage (e.g., Mutex-protected HashMap)
Method get_or_compute(input, compute_function):
Lock the cache for thread safety
If input exists in cache:
Return cached response
Else:
Compute response using compute_function
Store computed response in cache
Return computed response
// Main function for handling inference requests
Function main():
Initialize inference cache
Define model computation logic:
Generate tensor for input data using a random tensor generator
Call get_or_compute on cache to either retrieve or compute the inference
Output cached inference result
// Implement model distillation to train a smaller model
Function model_distillation(teacher_model, student_model):
Loop over training data:
Obtain teacher model predictions
Train student model to replicate teacher predictions
Return trained student model for faster inference
// Implement model pruning to optimize the model by removing unnecessary weights
Function prune_model(model, threshold):
For each weight in model:
If weight is below threshold:
Set weight to zero
Return pruned model
// Implement edge deployment for real-time, low-latency inference
Function deploy_to_edge(model, edge_device):
Convert model to a format compatible with edge devices (e.g., WebAssembly)
Load model onto the edge device
Run inference on edge device to minimize latency
// Continuous monitoring to track model performance and detect drift
Function monitor_model_performance(model, metric_threshold):
Loop periodically:
Gather real-time metrics for model performance
If performance metrics fall below threshold:
Trigger an alert or initiate retraining
// Use hardware accelerators (GPUs, TPUs) to speed up model computation
Function use_hardware_acceleration(model, data_batch):
If GPU available:
Load model onto GPU
Run inference on GPU for batch of data
Else if TPU available:
Load model onto TPU for matrix-intensive computations
Return results
// Deploy model to the cloud with Kubernetes or Docker for scaling
Function cloud_deployment(model):
Package model as a container (Docker)
Deploy container to cloud infrastructure using Kubernetes
Scale horizontally as demand increases
End Function
The pseudo code first defines an InferenceCache class to manage caching, storing input-output pairs of previous queries to reduce repeated computation. It includes a get_or_compute method that checks the cache for a given input; if the input is not cached, it computes the response, stores it, and returns the result. The model_distillation function then outlines how a student model can learn to mimic a larger teacher model’s outputs, effectively reducing model complexity while maintaining performance. The prune_model function iterates through the model’s weights, removing those below a specific threshold to reduce model size and increase inference speed.
For deployment, deploy_to_edge converts the model to a portable format (e.g., WebAssembly) and deploys it to an edge device, reducing latency by bringing computation closer to the data source. The monitor_model_performance function regularly checks the model’s prediction quality and triggers retraining or alerts if performance declines. The use_hardware_acceleration function harnesses GPUs or TPUs for accelerated batch processing, which is especially beneficial in high-demand scenarios. Finally, cloud_deployment packages the model for cloud infrastructure, using Docker and Kubernetes to manage and scale deployments according to user demand. Together, these techniques ensure efficient, scalable, and low-latency deployment of LLMs across diverse environments.
Edge deployment is another promising avenue, especially for applications where low latency and data privacy are paramount. Deploying LLMs at the edge brings the model computation closer to the data source, reducing round-trip latency and potentially enhancing data security. Edge devices, however, have limited computational and memory resources, so efficient Rust code is crucial in such deployments. Using crates like wasi for WebAssembly-based deployment enables Rust code to be executed efficiently on various edge devices, ensuring compatibility and performance. WebAssembly’s portability also allows the LLM to be deployed across different types of devices with minimal modification, providing flexibility in edge deployment.
Another critical aspect of deployment is monitoring and updating deployed models to maintain performance and adapt to evolving data patterns. Continuous monitoring of model predictions enables detection of potential drifts, errors, or degradations in performance over time. Rust’s concurrency features are valuable for implementing a robust monitoring system that can handle a large volume of real-time data without performance bottlenecks. For instance, Rust’s asynchronous programming capabilities using tokio can be leveraged to periodically gather inference metrics, log data, and generate alerts if model performance falls below a certain threshold. Automated retraining or fine-tuning based on monitored data can be scheduled to update the deployed models, keeping them aligned with changing data patterns or user requirements.
In cloud-based deployments, Rust’s efficient resource management also helps in cost optimization. By reducing the memory footprint and optimizing CPU/GPU utilization through techniques like asynchronous processing, Rust enables efficient model deployment even in large-scale cloud infrastructures. For example, Rust can be integrated with Kubernetes or Docker to handle containerized deployments of LLMs, facilitating horizontal scaling across multiple instances. This approach ensures that deployed models can meet high demand without incurring excessive operational costs. Furthermore, Rust’s memory safety and control over low-level operations make it well-suited for managing containerized resources, which is essential for ensuring consistent performance in production environments.
The role of hardware acceleration, including GPUs and TPUs, is essential for deploying LLMs in real-time. Rust provides bindings to CUDA and OpenCL, enabling the use of hardware accelerators for efficient computation. For instance, using Rust’s CUDA bindings allows developers to leverage the parallelism of GPUs to process multiple inferences concurrently, thereby meeting the demands of real-time applications. This GPU support is particularly valuable in scenarios where LLMs are deployed on large datasets or in high-throughput environments. Additionally, TPU support can be explored for edge environments with more stringent latency requirements, as TPUs are optimized for matrix operations central to transformer-based models.
The deployment of LLMs is evolving to meet the demands of various real-world applications, from cloud services to edge devices. Rust’s efficiency, concurrency, and direct control over memory make it an excellent choice for building deployment pipelines that can handle the computational load of LLMs while maintaining low latency and high scalability. The emergence of optimized deployment strategies, such as caching, pruning, distillation, and hardware acceleration, underscores the potential of Rust to support robust, real-time deployment of LLMs across diverse platforms. As the field advances, these Rust-based solutions are set to play a crucial role in overcoming the deployment challenges associated with large-scale, real-time language models, making LLM technology accessible and efficient for applications across industries.
27.5. Ethical and Regulatory Considerations for Future LLMs
As large language models (LLMs) become more deeply integrated into critical systems and high-stakes applications, ethical and regulatory considerations have taken center stage in their development and deployment. With their potential to influence public opinion, generate real-time information, and assist in decision-making processes, LLMs must be built to uphold principles of fairness, transparency, and privacy. Ethical challenges in LLMs stem from issues like embedded biases, potential for generating misinformation, and reinforcing societal inequalities. Bias mitigation, fairness, and privacy-preserving techniques are crucial for the responsible deployment of future LLMs. Rust, known for its performance, security, and transparent codebase, provides a robust foundation for creating ethically sound and regulatory-compliant AI systems. By leveraging Rust’s secure programming capabilities, developers can build interpretable models, implement bias detection, and incorporate privacy-preserving algorithms to ensure that LLMs align with ethical guidelines and legal standards.
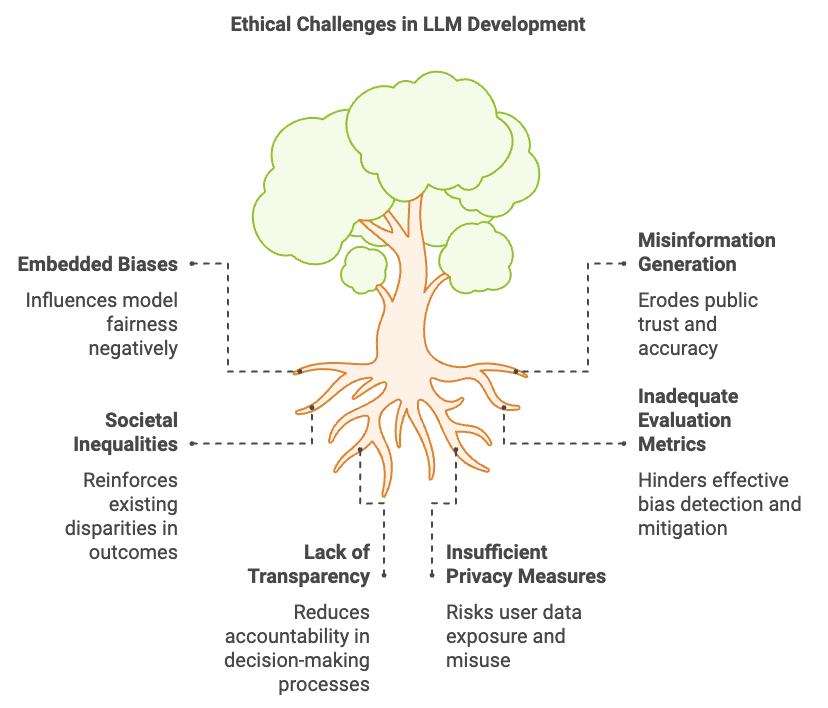
Figure 5: Ethical complexities and challenges in LLMs.
A central ethical challenge in LLMs is bias—an inherent risk due to the reliance on large, pre-existing datasets that may reflect historical and societal prejudices. Detecting and mitigating bias requires a combination of statistical methods, fairness constraints, and robust evaluation metrics. For example, techniques such as demographic parity and equalized odds can be integrated into the model evaluation process. Demographic parity requires that an LLM’s outcomes are statistically similar across different demographic groups, while equalized odds mandate that outcomes are equal across groups given the same conditions. Rust, with its support for statistical libraries such as ndarray for matrix computations, allows developers to implement these fairness constraints and check for biased outputs.
The following pseudo code addresses the ethical challenges of bias and privacy in deploying large language models (LLMs). It introduces bias detection mechanisms, such as demographic parity and equalized odds, along with differential privacy for data protection, ensuring compliance with regulations like GDPR. Bias detection involves identifying the frequency of certain gendered terms in the generated text, and differential privacy is achieved by adding controlled noise to sensitive data outputs. These implementations form the basis of a robust ethical framework that can be further enhanced by interpretability and monitoring systems. Using techniques like federated learning, which decentralizes training across devices, enhances privacy while maintaining model accuracy.
// Bias Detection for Language Models
Function detect_bias(text, keywords):
Initialize keyword_count as empty dictionary
For each keyword in keywords:
Count occurrences of keyword in text
Store the count in keyword_count dictionary
Return keyword_count
// Main function for bias detection
Function main():
Define sample text = "The engineer and doctor worked together, while the nurse provided support."
Define keywords = ["engineer", "doctor", "nurse"]
Call detect_bias with text and keywords
Output the bias analysis results
// Privacy-Preserving Differential Privacy using Noise Addition
Function apply_differential_privacy(data, sensitivity, epsilon):
Calculate sigma = sensitivity / epsilon
Generate Gaussian noise with mean 0 and standard deviation sigma
Return data + noise
// Main function for privacy demonstration
Function main():
Define original_value = 42.0
Define sensitivity = 1.0
Define epsilon = 0.1 (Privacy parameter)
Call apply_differential_privacy with original_value, sensitivity, and epsilon
Output original and private values
// Federated Learning for Decentralized Privacy-Preserving Training
Function federated_learning(nodes, model, data_partition):
For each node in nodes:
Train model locally on data_partition of that node
Store model updates locally on node
Aggregate model updates across nodes without sharing individual data
Update global model with aggregated results
Return global model
// Ethical Auditing System for Compliance
Function ethical_audit(model, data, evaluation_criteria):
Loop periodically:
Gather model predictions on data
Compare predictions against ethical evaluation criteria
If predictions deviate from criteria:
Alert stakeholders about potential bias or drift
End Loop
// Interpretability System for Model Transparency
Function interpretability_system(model, input_data):
Calculate SHAP values or attention weights for input_data
Generate visual representation of model's decision-making process
Output interpretability metrics and visualizations to support transparency
End Function
The pseudo code outlines several ethical and regulatory measures for managing bias and privacy in LLM deployments. The detect_bias function analyzes gender-based bias by counting specific gendered terms in model outputs, helping identify patterns that may require mitigation. The apply_differential_privacy function illustrates how differential privacy can be achieved by adding controlled Gaussian noise to sensitive data outputs, masking individual data points while preserving overall trends.
The federated_learning function demonstrates a privacy-preserving approach to decentralized model training, where each node trains a local model, and only the aggregated updates are shared. This structure ensures data privacy by keeping raw data on each device while contributing to a global model. To monitor ethical compliance, the ethical_audit function periodically evaluates model predictions against predefined ethical criteria, alerting stakeholders if biases or other ethical deviations are detected. Finally, the interpretability_system function provides transparency by calculating SHAP values or attention weights for input data, generating insights into the model’s decision-making process. Together, these components create a comprehensive framework for ethical, transparent, and privacy-preserving LLM deployment.
The ethical challenges in deploying LLMs are compounded by regulatory requirements, which demand transparency, accountability, and control over model operations. Regulations like the GDPR and the forthcoming AI Act outline strict guidelines for transparency, requiring models to be interpretable and their decision-making processes explainable. Rust supports the development of interpretable models by facilitating the integration of explainability libraries and tools, enabling developers to provide insights into the decision-making processes of LLMs. Techniques like attention visualization and SHAP (SHapley Additive exPlanations) values can be implemented to clarify why specific inputs lead to certain outputs. These interpretability features are crucial for building user trust and ensuring compliance with regulatory standards.
To ensure that models continuously meet ethical and legal standards, organizations can implement monitoring and auditing systems. Rust’s reliability and efficiency make it suitable for developing such auditing frameworks, capable of analyzing model behavior in real time and providing actionable insights. For example, an ethical audit system in Rust could periodically evaluate a deployed model’s outputs, detect any deviations from predefined ethical criteria, and alert stakeholders if the model shows signs of drift or produces biased outputs.
As LLMs continue to evolve, ethical and regulatory considerations are likely to become more complex and encompassing. By prioritizing transparency, accountability, fairness, and privacy, developers can deploy LLMs that serve society responsibly and align with the growing body of AI regulations. Rust, with its performance, memory safety, and robust concurrency model, is well-equipped to handle the technical and ethical complexities involved in developing, deploying, and maintaining large language models in a regulatory-compliant manner.
27.6. Future Directions and Research Opportunities in LLMs
The field of large language models (LLMs) continues to expand rapidly, with potential future directions that promise to enhance their capabilities and applications across various domains. Research into unsupervised learning methods is opening doors to more autonomous LLMs that can learn without extensive labeled datasets, which is particularly valuable for niche areas with limited annotated data. Transfer learning, where models trained on one task or dataset are adapted to perform well on another, remains a critical technique for making LLMs more adaptable and efficient. Rust, with its focus on high performance and safety, provides a reliable platform for implementing these techniques, offering tools that allow researchers to optimize model performance without compromising on resource efficiency. Meanwhile, advancements in multimodal models, which combine text with other data types like images or audio, are broadening the scope of LLM applications, especially in fields such as medical diagnostics and autonomous systems. Rust’s strong type system and concurrency features provide a foundation for experimenting with and deploying such computationally intensive models, making it an asset for researchers venturing into next-generation AI.
One promising area of future research is the integration of LLMs with emerging technologies such as quantum computing and neuromorphic hardware. Quantum computing, still in its nascent stages for practical AI applications, has the potential to revolutionize LLMs by enabling massive parallelism and addressing the limitations of classical computation. Rust, with crates like qiskit for quantum programming, can support this integration, allowing researchers to experiment with quantum algorithms for LLMs that could, for example, optimize training efficiency or introduce new forms of generative modeling. Similarly, neuromorphic hardware, designed to mimic the neural architecture of the human brain, offers unique opportunities for building low-power, high-efficiency AI systems. Rust’s efficiency and system-level control make it ideal for programming these specialized chips, enabling the development of LLMs that are not only faster but also more energy-efficient.
Integrating LLMs with other AI paradigms, such as reinforcement learning (RL) and generative adversarial networks (GANs), presents another intriguing research avenue. RL allows models to learn from feedback loops, adapting dynamically to complex environments, which could prove especially useful for conversational agents or interactive AI systems. Implementing RL in Rust could lead to more efficient and real-time adaptive models, as demonstrated by frameworks like tch-rs, which support PyTorch bindings for reinforcement learning. GANs, widely used for generating synthetic data, could also enhance LLMs by creating diverse training examples, addressing bias, or simulating rare scenarios. Rust’s performance advantages and memory safety features make it a robust choice for developing these complex, multi-stage AI workflows. Rust-based implementations could facilitate the combination of LLMs and GANs for tasks where data scarcity or ethical considerations demand synthetic data.
The convergence of LLMs with other scientific fields, such as neuroscience and ethics, suggests future research that is interdisciplinary in nature. Rust’s flexibility allows researchers to implement models that draw on insights from both neural computing and ethical AI frameworks, creating LLMs that are not only more efficient but also aligned with human cognitive principles and societal values. The potential for Rust to support this interdisciplinary research lies in its versatility and open-source ecosystem, where contributions from various fields can lead to innovative, ethically sound AI solutions. Through Rust, researchers can explore brain-inspired architectures and reinforcement mechanisms, incorporating insights from neuroscience to enhance model efficiency, interpretability, and trustworthiness.
Collaboration among academia, industry, and the open-source community will be essential in pushing the boundaries of LLM research. With Rust’s expanding ecosystem and strong community support, researchers and practitioners are well-positioned to develop cutting-edge LLM techniques. Rust-based research proposals might explore quantum computing applications in language modeling or experiment with neuromorphic-inspired AI architectures to improve energy efficiency and adaptability. This collaborative approach, combined with Rust’s performance-oriented design, can support a range of experimental LLM applications, from real-time adaptive learning to privacy-preserving models.
Rust’s ecosystem provides tools and libraries that are ideally suited for exploring novel directions in LLM research. For instance, the Rust crate ndarray supports linear algebra operations, essential for experimenting with unsupervised learning and transfer learning techniques. Unsupervised learning approaches, such as clustering and anomaly detection, allow LLMs to extract meaningful patterns from unlabeled data, enhancing adaptability to new domains. Transfer learning methods can further extend this adaptability, allowing researchers to take pre-trained LLMs and fine-tune them for specific tasks. Rust’s high-level concurrency support facilitates parallel processing in these complex training workflows, making Rust an asset for researchers focused on maximizing efficiency in unsupervised and transfer learning tasks.
This pseudo code explores the advanced, interdisciplinary research directions and emerging technologies influencing the future of large language models (LLMs). It addresses methods such as unsupervised learning, transfer learning, and multimodal modeling to enhance LLM capabilities across different domains. By integrating quantum computing, neuromorphic hardware, reinforcement learning (RL), and generative adversarial networks (GANs), the code reflects cutting-edge advancements in LLMs that emphasize efficiency, adaptability, and ethical alignment. Through techniques such as clustering and energy-efficient architectures, this pseudo code outlines a comprehensive roadmap for future LLM research, demonstrating the potential for high-performance, sustainable, and privacy-preserving AI models.
// Define Future Directions for Large Language Models (LLMs)
// Unsupervised Learning
Function perform_unsupervised_learning(model, dataset):
Apply clustering to dataset to group similar data points without labels
Extract patterns and anomalies from clusters
Train model on patterns to improve adaptability to new domains
Return model trained on unsupervised patterns
// Transfer Learning
Function apply_transfer_learning(pre_trained_model, target_task):
Initialize new model with layers and parameters from pre_trained_model
Fine-tune model on target_task data to adapt to specific requirements
Adjust parameters to optimize performance for target_task
Return adapted model for target_task
// Multimodal Learning for Text, Image, and Audio
Function integrate_multimodal_data(text_data, image_data, audio_data):
Process text_data with language model
Process image_data with vision model
Process audio_data with audio model
Combine processed outputs to create multimodal representation
Train multimodal model using combined representation for enhanced context understanding
Return trained multimodal model
// Quantum Computing for Advanced Computation
Function quantum_computing_integration(model):
Initialize quantum circuit for parallel computation
Apply quantum algorithms to optimize model training
Experiment with quantum layers in model architecture for efficient computation
Return model enhanced by quantum processing
// Neuromorphic Hardware Integration for Energy Efficiency
Function optimize_with_neuromorphic_hardware(model, neuromorphic_chip):
Load model onto neuromorphic_chip designed to mimic brain-like operations
Execute model computations with lower power consumption
Adjust model for efficient operation on neuromorphic_chip
Return model adapted for neuromorphic hardware deployment
// Reinforcement Learning (RL) Integration for Adaptability
Function integrate_reinforcement_learning(model, environment):
Initialize RL agent using model as the policy network
Train agent with feedback from environment to adapt to changing scenarios
Update model based on RL rewards and feedback
Return RL-adapted model for real-time adaptability
// Generative Adversarial Network (GAN) for Data Generation
Function integrate_gan_for_data_augmentation(generator, discriminator, real_data):
Train generator to create synthetic data samples similar to real_data
Train discriminator to distinguish between real_data and synthetic data
Use synthetic data to augment model training and address data scarcity
Return model trained with augmented data for improved generalization
// Ethics and Privacy Compliance
Function ensure_ethics_and_privacy(model, regulatory_criteria):
Apply fairness checks to ensure unbiased outputs across demographic groups
Add differential privacy techniques to protect individual data points
Regularly monitor model outputs for adherence to regulatory_criteria
Alert stakeholders if model outputs deviate from ethical standards
Return compliance-audited model
// Sustainability and Energy Efficiency
Function optimize_for_energy_efficiency(model, hardware_acceleration):
Deploy model on GPU or TPU for reduced carbon footprint
Apply model distillation and pruning to lower computational requirements
Adjust memory and processing parameters to minimize resource usage
Return model optimized for energy efficiency
// Continuous Monitoring and Adaptive Updates
Function continuous_model_monitoring(model, metrics):
Periodically check model performance metrics (accuracy, bias, energy usage)
If performance metrics deviate from thresholds:
Trigger alerts or retraining process
Schedule adaptive updates to keep model aligned with evolving data patterns
Return monitored and updated model
End Function
The pseudo code outlines advanced research directions and technical implementations for improving LLMs, encompassing techniques for adaptability, efficiency, and ethical compliance. The perform_unsupervised_learning function trains the model using unlabeled data, identifying patterns through clustering to enhance adaptability across domains. apply_transfer_learning leverages pre-trained knowledge to adapt models for specific tasks, while integrate_multimodal_data combines text, image, and audio data for richer context understanding. Quantum computing and neuromorphic hardware integration, represented in quantum_computing_integration and optimize_with_neuromorphic_hardware, explore future hardware advancements for optimized computation and energy efficiency.
The pseudo code also includes reinforcement learning (RL) through integrate_reinforcement_learning and synthetic data generation using GANs in integrate_gan_for_data_augmentation, enhancing LLMs’ adaptability and mitigating data limitations. Ethical considerations are addressed in ensure_ethics_and_privacy, where fairness and differential privacy methods ensure compliance with regulatory standards. Finally, sustainability is achieved with optimize_for_energy_efficiency by employing hardware acceleration and distillation, while continuous_model_monitoring schedules model updates, aligning outputs with evolving data and performance metrics. Together, these functions form a robust framework for the future development of ethical, adaptable, and sustainable LLMs.
In the near future, advancements in LLMs are likely to converge on the goals of sustainability, efficiency, and responsible AI. Rust’s strengths in safety and memory management make it a valuable tool for addressing these goals. For example, Rust’s integration with GPU and TPU acceleration can reduce the carbon footprint of training and deploying large models, supporting the development of greener AI solutions. As researchers strive to create models that are more energy-efficient, scalable, and ethically aligned, Rust’s growing ecosystem offers a foundation for building the next generation of LLMs that can meet the technical and societal demands of the future.
27.7. Conclusion
Chapter 27 highlights the critical role Rust will play in advancing the future of large language models, enabling the development of smarter, more efficient, and ethically sound AI systems. As LLMs continue to evolve, Rust's capabilities will be central to driving innovation and ensuring that these models are both powerful and responsible in their impact on society.
27.7.1. Further Learning with GenAI
By engaging deeply with these comprehensive and technically rigorous prompts, you will not only master the current state of LLMs but also contribute to shaping their future.
Evaluate the current state of large language models (LLMs) by identifying and critically analyzing key trends such as model scaling, transformer variations, and hybrid models. How can Rust be applied to optimize these trends in terms of computational efficiency, scalability, and deployment across diverse environments? Discuss specific Rust crates that could support these advancements.
Explore the architectural evolution from traditional transformers to sparse transformers. What are the specific computational benefits of sparse transformers, and how do they impact memory usage and inference speed? Provide a detailed implementation strategy for sparse transformers in Rust, highlighting the challenges and solutions related to efficient memory management and parallel processing.
Discuss the mixture of experts (MoE) architecture in LLMs, including its underlying mechanisms for model efficiency and scalability. How can Rust be utilized to implement an MoE model, particularly focusing on dynamic routing and load balancing between experts? Provide examples of how to optimize MoE for large-scale, real-time applications using Rust.
Examine the role of neural architecture search (NAS) in optimizing LLM performance. What are the key algorithms used in NAS, and how can Rust be leveraged to automate and accelerate the architecture search process? Discuss the integration of NAS with reinforcement learning techniques in Rust to create adaptive LLM architectures.
Analyze the implementation and impact of low-rank factorization techniques on the training efficiency of LLMs. How do these techniques reduce the computational complexity of training without significantly compromising model accuracy? Provide a comprehensive guide to implementing low-rank factorization in Rust, including potential performance optimizations for large-scale models.
Explore gradient checkpointing as a memory optimization technique during LLM training. How does gradient checkpointing reduce memory usage, and what are the trade-offs in terms of training speed and complexity? Implement a Rust-based gradient checkpointing system and evaluate its impact on memory usage, training time, and overall model performance.
Discuss the process and benefits of model quantization for LLMs, focusing on how it reduces model size and inference latency. How can Rust be used to implement both post-training quantization and quantization-aware training? Provide an in-depth analysis of the accuracy-performance trade-offs involved in quantizing large-scale models, with a focus on practical deployment scenarios.
Evaluate the challenges and strategies for distributed training of LLMs across multiple GPUs or compute nodes. How can Rust be employed to implement a distributed training framework that optimizes communication efficiency and fault tolerance? Analyze the impact of different parallelization techniques (e.g., data parallelism, model parallelism) on training speed and model convergence.
Discuss the role of hardware acceleration (e.g., GPUs, TPUs) in the training and inference of LLMs. How does Rust interface with these hardware accelerators to optimize computation, and what are the specific challenges in managing memory, parallelism, and hardware-specific operations? Provide examples of optimizing LLM training on different hardware platforms using Rust.
Explore the complexities of deploying LLMs in real-time, latency-sensitive applications. How can Rust be used to develop a deployment pipeline that minimizes latency while maintaining scalability and cost-efficiency? Discuss the integration of techniques like model pruning, distillation, and caching within a Rust-based deployment environment to achieve real-time performance.
Analyze the concept of model distillation and its impact on reducing inference latency and computational cost. How can Rust be used to implement model distillation, particularly focusing on teacher-student training and the trade-offs between model size, accuracy, and latency? Provide a detailed example of deploying a distilled LLM in a production environment.
Discuss the trade-offs between cloud-based, edge-based, and on-device deployment of LLMs. How can Rust be employed to optimize LLM deployment for each environment, considering factors like latency, bandwidth, power consumption, and model size? Provide case studies or examples of deploying LLMs in these different environments using Rust.
Examine the importance of continuous monitoring and updates in maintaining the performance, reliability, and security of deployed LLMs. How can Rust-based tools be developed to automate this process, including anomaly detection, model retraining, and rollback mechanisms? Discuss the challenges and best practices for implementing continuous monitoring in large-scale, real-world applications.
Explore the ethical challenges associated with the development and deployment of future LLMs, particularly in areas such as bias, fairness, and privacy. How can Rust be utilized to implement bias detection, mitigation, and privacy-preserving techniques during both training and inference? Provide a comprehensive strategy for integrating these ethical considerations into the LLM development pipeline using Rust.
Analyze the regulatory requirements for AI, such as GDPR, the AI Act, and other global regulations. How can Rust be used to ensure that LLMs comply with these regulations while maintaining high performance and efficiency? Provide a step-by-step guide to implementing compliance checks and audit trails in a Rust-based LLM system.
Discuss the potential of unsupervised and transfer learning techniques in advancing the adaptability and generalization of LLMs. How can Rust be used to implement these techniques, particularly in scenarios where labeled data is scarce or domain-specific knowledge is required? Provide examples of using transfer learning in Rust to fine-tune LLMs for specialized tasks.
Evaluate the impact of emerging technologies like quantum computing and neuromorphic hardware on the future of LLMs. How can Rust be used to integrate these technologies with LLMs, considering the unique computational paradigms they offer? Discuss the challenges and opportunities of developing Rust-based tools for quantum and neuromorphic computing in the context of LLMs.
Explore the potential for integrating LLMs with reinforcement learning (RL) and generative adversarial networks (GANs). How can Rust be leveraged to develop hybrid models that combine the strengths of LLMs, RL, and GANs? Provide detailed examples of implementing such models in Rust, focusing on applications like autonomous decision-making and creative content generation.
Analyze the importance of interdisciplinary collaboration in advancing the state of the art in LLMs. How can Rust facilitate collaboration between computer science, neuroscience, ethics, and other fields to develop more robust and responsible AI systems? Discuss the potential for Rust to serve as a unifying platform for interdisciplinary research and development in AI.
Discuss the future directions of large language models, focusing on the role Rust will play in driving innovation and ensuring ethical AI development. How can Rust be positioned as a key enabler of the next generation of LLM research and development, particularly in areas such as explainability, robustness, and user control? Provide a roadmap for future research and practical implementations using Rust.
Embrace these exercises as an opportunity to drive the next wave of AI research and development, ensuring that the technologies you build are both cutting-edge and aligned with the highest ethical standards.
27.7.2. Hands On Practices
Self-Exercise 27.1: Implementing Sparse Transformers in Rust
Objective: To design and implement a sparse transformer model using Rust, focusing on optimizing memory usage and inference speed for large-scale language models.
Tasks:
Research the sparse transformer architecture and its advantages over traditional transformers, particularly in terms of computational efficiency.
Implement a sparse transformer model in Rust, using available libraries and crates to handle matrix operations and attention mechanisms.
Optimize the model for performance, focusing on reducing memory consumption and improving inference speed.
Test the model with various datasets, comparing its performance to that of a traditional transformer model.
Deliverables:
A Rust-based implementation of a sparse transformer model, including source code and documentation.
A performance report comparing the sparse transformer to a traditional transformer in terms of memory usage, inference speed, and accuracy.
An analysis of the challenges encountered during implementation and suggestions for further optimization.
Self-Exercise 27.2: Distributed Training of LLMs Using Rust
Objective: To develop a distributed training framework for large language models (LLMs) using Rust, optimizing communication efficiency and fault tolerance across multiple GPUs or nodes.
Tasks:
Research distributed training techniques, focusing on data parallelism and model parallelism, and how they can be applied to LLMs.
Implement a distributed training system in Rust, utilizing Rust’s concurrency and networking features to manage communication between nodes.
Optimize the system for fault tolerance, ensuring that training can continue smoothly in the event of node failures or communication disruptions.
Test the system on a large-scale LLM, evaluating the impact of distributed training on model convergence, training speed, and resource utilization.
Deliverables:
A Rust-based distributed training framework for LLMs, complete with source code and documentation.
A performance report detailing the impact of distributed training on model performance, including metrics on convergence, speed, and resource utilization.
A fault tolerance analysis, outlining the strategies implemented to handle node failures and communication issues during training.
Self-Exercise 27.3: Implementing Model Distillation for Real-Time Inference
Objective: To implement a model distillation pipeline in Rust, focusing on reducing the size and latency of large language models for real-time inference applications.
Tasks:
Research the concept of model distillation and its application in reducing the complexity of LLMs while preserving performance.
Implement a teacher-student model distillation process in Rust, training a smaller model to replicate the performance of a larger one.
Optimize the distilled model for real-time inference, focusing on reducing latency and computational cost.
Deploy the distilled model in a real-time application, evaluating its performance compared to the original larger model.
Deliverables:
A Rust-based model distillation pipeline, including source code and detailed documentation.
A performance comparison between the original LLM and the distilled model, focusing on inference latency, accuracy, and computational cost.
A deployment guide for real-time inference, highlighting best practices for optimizing model performance in production environments.
Self-Exercise 27.4: Integrating Bias Mitigation Techniques in LLMs
Objective: To develop and implement bias mitigation techniques in large language models (LLMs) using Rust, ensuring fairness and reducing bias in model outputs.
Tasks:
Research bias mitigation strategies in LLMs, such as reweighting, adversarial training, and fairness constraints.
Implement bias detection and mitigation techniques in Rust, integrating them into the LLM training and inference pipeline.
Test the bias mitigation methods on a variety of datasets, evaluating their effectiveness in reducing bias without significantly impacting model performance.
Analyze the trade-offs between fairness and accuracy, and provide recommendations for optimizing bias mitigation in LLMs.
Deliverables:
A Rust-based implementation of bias mitigation techniques for LLMs, including source code and documentation.
A comprehensive report analyzing the effectiveness of the bias mitigation methods, with metrics on fairness and model accuracy.
Recommendations for optimizing bias mitigation in LLMs, based on the results of the experiments.
Self-Exercise 27.5: Exploring Neural Architecture Search (NAS) in Rust
Objective: To explore and implement neural architecture search (NAS) in Rust, automating the process of discovering optimal architectures for large language models.
Tasks:
Research the principles of neural architecture search, focusing on the algorithms and techniques used to explore and optimize model architectures.
Implement a NAS system in Rust, utilizing reinforcement learning or evolutionary algorithms to discover optimal architectures for LLMs.
Test the NAS system on different LLM tasks, evaluating the architectures it generates in terms of performance and efficiency.
Optimize the NAS process for speed and scalability, ensuring that it can efficiently handle large search spaces and complex models.
Deliverables:
A Rust-based neural architecture search system, complete with source code and documentation.
A report detailing the performance of the architectures generated by the NAS system, including comparisons to manually designed models.
An analysis of the challenges encountered during the NAS process, with recommendations for improving the efficiency and scalability of the system.
Comments