Chapter 26
Federated Learning and Privacy-Preserving LLMs
"Privacy is not about hiding something; it’s about protecting our identities and ensuring that we remain in control of our personal data, even in the age of AI." — Andrew Trask
Chapter 26 of LMVR provides a robust exploration of federated learning and privacy-preserving techniques within the context of large language models (LLMs) using Rust. The chapter begins by introducing the foundational concepts of federated learning, emphasizing its importance in decentralized model training and the preservation of data privacy. It delves into privacy-preserving methods such as differential privacy and secure multiparty computation, discussing their critical roles in ensuring that sensitive data remains secure during LLM training. The chapter also highlights the unique advantages of implementing these techniques using Rust, focusing on its performance, security, and concurrency features. Finally, it addresses the current challenges and future directions in federated learning and privacy-preserving methods, encouraging ongoing research and innovation to overcome existing limitations.
26.1. Federated Learning and Privacy-Preserving Techniques
Federated learning (FL) represents a paradigm shift in the way large language models (LLMs) are trained by enabling decentralized training across multiple devices or data sources. Instead of collecting data in a centralized location, FL allows each device, such as a smartphone or a local server, to compute updates to the model locally on its own data. These updates, rather than the data itself, are then aggregated to form a global model. This approach minimizes data transfer, preserves user privacy, and aligns well with data privacy regulations. Federated learning is particularly valuable for LLMs that need to learn from distributed data sources—such as personal devices—without compromising data privacy. Combined with privacy-preserving techniques, FL enables the development of robust LLMs that respect user confidentiality, adhere to regulatory requirements, and address ethical concerns around data usage.
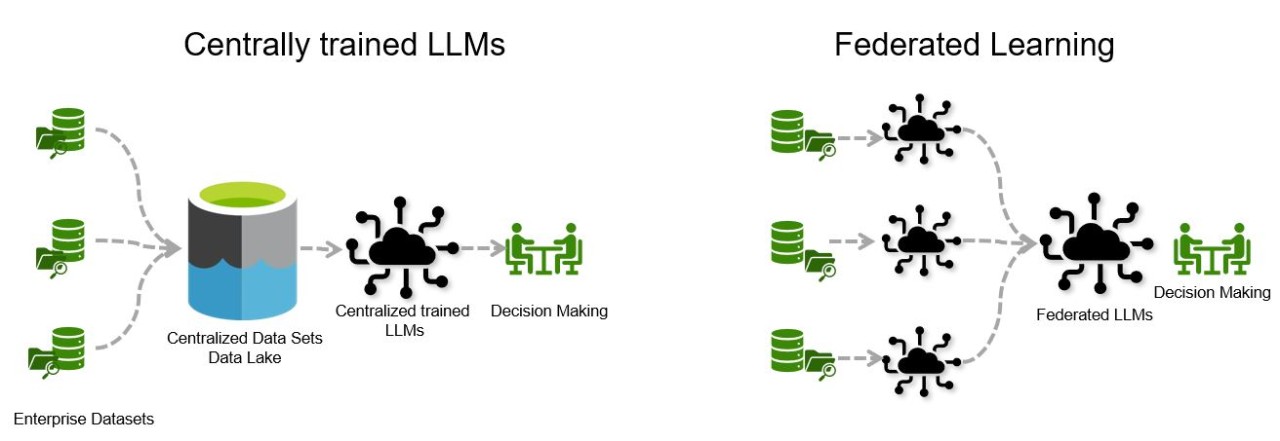
Figure 1: Centrally trained vs Federated Learning LLMs development.
Privacy-preserving techniques such as differential privacy and secure multiparty computation complement federated learning by ensuring that even the updates transmitted during training reveal minimal information about the underlying data. Differential privacy achieves this by adding calibrated noise to the updates, ensuring that individual contributions remain anonymous in the aggregated model. Mathematically, differential privacy operates on the principle that an algorithm’s output should not significantly differ whether or not a particular individual’s data is included. For example, if we denote a function $f$ acting on a dataset $D$, differential privacy ensures that for neighboring datasets $D$ and $D'$ (differing by one individual’s data), the probability distribution $P(f(D))$ is approximately the same as $P(f(D'))$. In Rust, this can be achieved using noise-generating crates such as rand to add randomized perturbations, helping ensure user anonymity during training.
Secure multiparty computation (SMPC) takes privacy preservation a step further by allowing multiple parties to jointly compute a function over their inputs without revealing those inputs to one another. SMPC is particularly beneficial when the updates being transmitted are themselves sensitive or when additional privacy constraints need to be met, such as in collaborative training across different organizations. Using Rust’s powerful cryptographic crates, such as rust-crypto or ring, developers can implement SMPC protocols for secure model aggregation. In SMPC, the function $f(x_1, x_2, \dots, x_n)$ can be computed by breaking it down into partial functions $f_i(x_i)$ for each party iii, which then only need to share the encrypted results. Rust’s low-level memory management and strong type system make it an ideal language for implementing these cryptographic computations with efficiency and security.
SMPC enables collaborative analysis of sensitive data, such as patient genomes and proprietary pharmaceutical datasets, while ensuring that only the original data providers can access their own data. This capability allows stakeholders in biomedicine—like academic institutions, clinical labs, and commercial entities—to securely share sensitive data for various biomedical applications, including genetic association studies, drug-target prediction, and metagenomic profiling. MPC achieves secure collaboration by partitioning sensitive data into encrypted shares, which are then distributed across multiple computing parties (often the data providers themselves), using a cryptographic approach called secret sharing. Conducting computations on distributed, encrypted data requires complex protocols that can introduce significant performance overhead. Sequre addresses this by automatically translating programs from a high-level, Python-like language into optimized, high-performance MPC programs, which accelerates both development and execution. We envision that end-users, such as collaborating researchers, will use Sequre to quickly develop and validate a secure study pipeline, then deploy the optimized programs produced by Sequre to computing parties for execution. This process allows end-users to gain insights from combined datasets that would be unattainable through individual analyses alone.
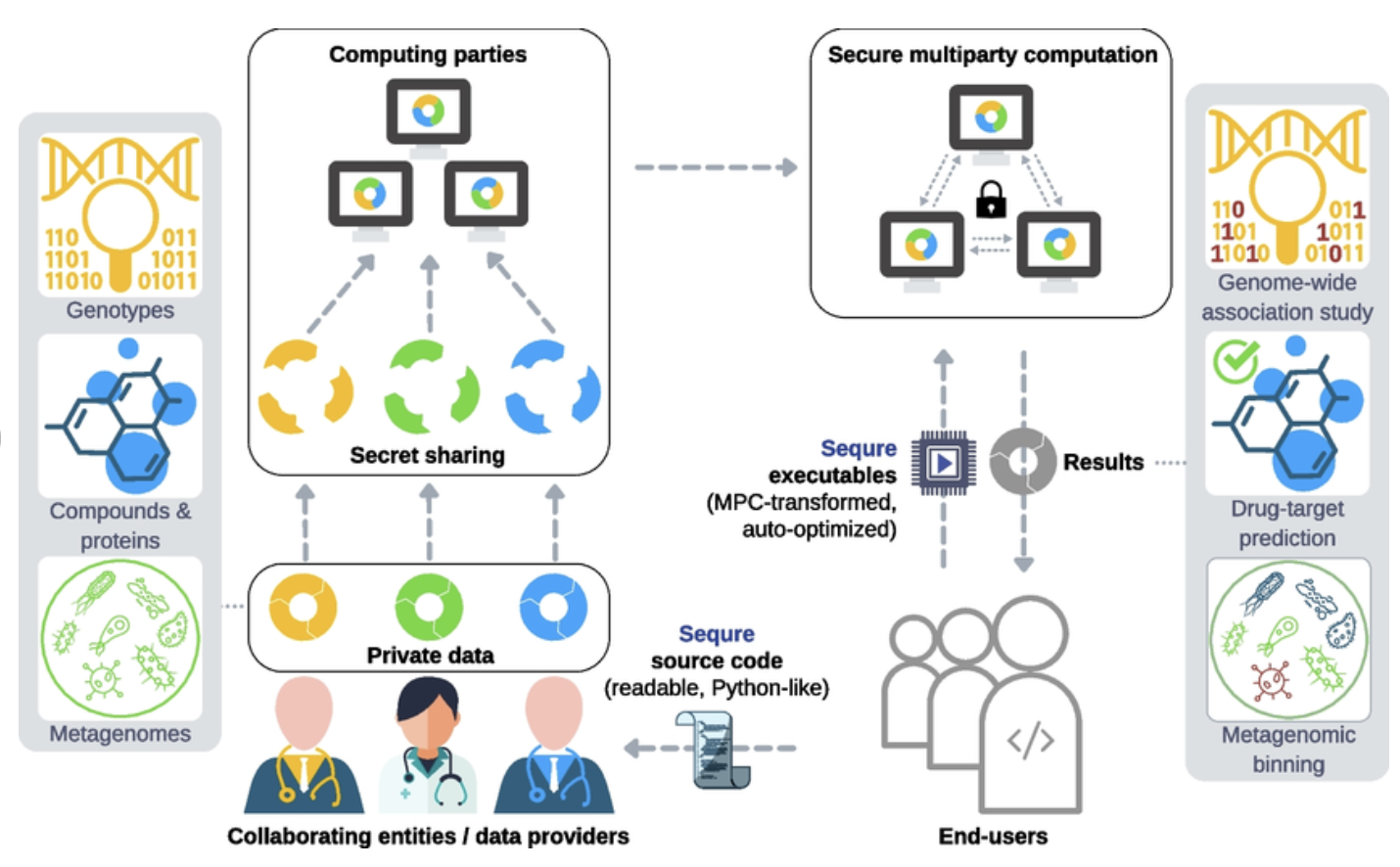
Figure 2: Example of SMPC use cases in Healthcare industry.
Decentralized training in FL differs significantly from centralized training. In centralized training, all data is collected and stored in a central location, where the model training occurs. This centralized approach can lead to significant privacy risks, as data collected from various sources can be vulnerable to breaches. In contrast, FL avoids such vulnerabilities by keeping data local. Only aggregated model updates are transmitted to a central server or aggregation point, drastically reducing the exposure of sensitive data. Rust’s concurrency model is well-suited to managing the complexities of data flow in FL. By allowing parallel processing of model updates, Rust can efficiently handle the data aggregation required in federated learning, providing both speed and safety in managing data.
The need for privacy-preserving techniques in FL arises not only from ethical considerations but also from regulatory mandates, such as GDPR and HIPAA, which require stringent data privacy protections. In healthcare, for instance, federated learning can enable hospitals to collaboratively train an LLM on patient data without sharing the data itself, adhering to HIPAA’s privacy requirements. Privacy-preserving techniques like differential privacy are not just beneficial but necessary for meeting these regulations. In finance, FL can allow banks to train a collaborative model on fraud detection without compromising individual transaction data. Rust’s cryptographic and privacy-focused libraries, such as ring, sodiumoxide, and curve25519-dalek, provide the necessary tools for developing secure and privacy-compliant federated learning frameworks that protect data throughout the training process.
Despite its advantages, FL is not without challenges. One key challenge is the limited computation power on edge devices, which can restrict the complexity of the models that can be trained locally. Another challenge is ensuring that the data distribution across devices is representative of the broader data population, as data on personal devices can be highly individualized. Additionally, communication constraints can affect the synchronization of updates across devices, potentially leading to inconsistencies in the global model. To address these challenges, developers can implement efficient communication protocols in Rust using libraries such as tokio for asynchronous networking, which can help manage bandwidth and data transfer costs in FL.
Setting up a Rust environment for FL and privacy-preserving algorithms begins by creating a multi-threaded system where each device or data source can be represented as an individual thread. Using the tokio crate for asynchronous programming, Rust developers can simulate multiple clients that compute model updates locally and send encrypted updates to a central aggregator. A simple FL example could involve each client training a logistic regression model on their local data and then using the ring crate to encrypt the model weights before sending them to a central server for aggregation. Aggregation in this context involves averaging the model weights received from each client, which can be implemented using standard Rust functions for numerical computation.
A practical example of implementing differential privacy in Rust for FL involves adding Gaussian or Laplacian noise to model updates. Using the rand crate, developers can generate random values to perturb the model weights, ensuring individual data contributions remain untraceable in the aggregated result. For example, if $\theta_i$ represents the model weights from client $i$, differential privacy can be applied by updating $\theta_i' = \theta_i + \mathcal{N}(0, \sigma^2)$, where $\mathcal{N}$ denotes Gaussian noise with a variance $\sigma^2$ calibrated to achieve the desired privacy guarantee. The aggregated model weights $\theta$ can then be computed as $\theta = \frac{1}{N} \sum_{i=1}^N \theta_i'$, achieving a differentially private result.
To explore federated learning on a larger scale, Rust developers can extend these examples to complex neural network architectures by leveraging the tch-rs crate, which provides bindings to the PyTorch library. This setup allows the simulation of federated training for LLMs, where individual clients train smaller parts of a neural network on local data before sending encrypted updates to a central model. This setup demonstrates the scalability of Rust in privacy-preserving FL for more advanced LLM applications, highlighting Rust’s ability to handle heavy computational tasks securely and efficiently.
In conclusion, federated learning and privacy-preserving techniques are essential for the future of LLMs, enabling these models to learn from decentralized data without compromising privacy. Rust’s concurrency model, low-level memory control, and cryptographic libraries make it an excellent language for implementing these techniques. By enabling decentralized and privacy-compliant learning, federated learning in Rust provides a pathway to secure and responsible LLM development, setting a foundation for ethical AI practices in industries that demand high standards of privacy and security. This section has introduced the core concepts, explored ethical and legal motivations, and provided practical guidance on using Rust for federated learning and privacy preservation, establishing the groundwork for secure, decentralized LLMs.
26.2. Fundamentals of Federated Learning
Federated learning (FL) is a decentralized machine learning approach designed to train models on data distributed across multiple clients or devices without centralizing the data. This architectural shift is motivated by privacy concerns, as it reduces the need to transfer sensitive data by processing it locally. There are two primary architectures in federated learning: the client-server model and the peer-to-peer model. In the client-server model, individual clients train local models on their data and send updates to a central server that aggregates these updates to form a global model. The peer-to-peer model, on the other hand, allows clients to share updates directly with one another in a decentralized network, creating a dynamic and resilient training environment. Rust’s strong support for concurrency and secure communication protocols makes it an ideal language for implementing these FL architectures efficiently and securely.
One of the most widely used algorithms in FL is federated averaging, introduced by McMahan et al. in 2017. Federated averaging combines client model updates by averaging their parameters, resulting in a global model that incorporates insights from all clients. The process begins with each client iii training a local model $\theta_i$ on its dataset. After each local training session, the clients send their model parameters $\theta_i$ to a central server, which computes the average $\theta = \frac{1}{N} \sum_{i=1}^N \theta_i$. This averaging mechanism helps ensure that the global model reflects the combined knowledge of all clients, without direct access to their data. In Rust, this process can be implemented by leveraging data structures like HashMap for client management and using concurrent processing with the tokio crate for asynchronous model aggregation.
An important concept in FL is client heterogeneity, which refers to differences in client resources, data distributions, and network conditions. Unlike traditional centralized training, where all data is assumed to follow a similar distribution, federated learning often involves data that is non-IID (non-independent and identically distributed). This non-IID nature can create challenges in training since clients may have vastly different data representations. For example, in an LLM application across user devices, one user’s data may be biased toward medical terms while another’s focuses on legal jargon. Such heterogeneous data can slow model convergence and affect overall accuracy. Addressing this challenge requires careful algorithmic adjustments, such as weighting updates based on data variance or adjusting the global model’s learning rate. Rust’s low-level control and efficient computation make it suitable for simulating and experimenting with different data distribution scenarios in FL, providing insights into handling non-IID data effectively.
Balancing data privacy with model accuracy presents another trade-off in FL. Privacy preservation mechanisms, such as differential privacy, can reduce the model’s ability to generalize by adding noise to the updates. This trade-off between accuracy and privacy is critical in industries like healthcare and finance, where data sensitivity is paramount. Rust’s cryptographic libraries, like ring and rust-crypto, support the implementation of these privacy-preserving techniques in a federated learning setup, allowing developers to test and fine-tune the balance between model accuracy and data protection.
In a federated learning environment, communication efficiency is key to scalability. The iterative exchange of model updates between clients and the server can consume significant bandwidth and computational resources, especially as the model grows in complexity. Techniques such as model compression, update quantization, and sparsification are commonly used to reduce the amount of data transmitted in each round. In Rust, implementing these optimizations can be facilitated through custom compression algorithms and data quantization techniques, supported by libraries like ndarray for array manipulation and tokio for managing asynchronous communication. These optimizations help improve efficiency, enabling federated learning systems to operate smoothly in bandwidth-constrained or resource-limited environments.
A significant challenge in federated learning is handling unreliable communication and client dropout. In real-world applications, clients may disconnect or fail to send updates on time due to network instability or hardware limitations. Techniques such as straggler mitigation, which limits the waiting time for slow clients, and selective aggregation, which only updates the global model with contributions from active clients, help ensure training continuity. Using Rust, developers can implement these techniques with asynchronous programming patterns from the tokio crate, enabling efficient management of client updates. The tokio runtime allows Rust to handle numerous clients concurrently, scheduling aggregation tasks even when some clients experience delays, thus making the system more resilient to network instability.
Implementing a basic federated learning system in Rust involves constructing modules for client communication, model training, and aggregation. A simplified FL setup could start with clients training local linear regression models on simulated data and sending their model parameters to a central server. Using Rust’s ndarray crate for numerical operations, we can simulate the averaging of client models by computing the mean of model parameters received. This basic implementation could then be extended to include security features, such as encrypting the parameters before transmission with the ring crate, and privacy measures, like adding Gaussian noise to the aggregated model using the rand_distr crate.
To examine the effects of non-IID data in FL, Rust developers can create customized data distributions for each client, simulating real-world variations in data availability and characteristics. Testing FL systems with diverse data distributions allows developers to observe how well the model generalizes when client data diverges, highlighting the impact of data heterogeneity on training stability and model performance. This approach, supported by Rust’s numerical libraries, is invaluable for optimizing federated learning protocols to improve convergence and accuracy across varying data distributions.
This pseudo code outlines the development of a federated learning (FL) system in Rust, covering the main components of FL: client-server communication, federated averaging, handling non-IID data, privacy preservation, and communication efficiency. The code simulates a basic FL setup where clients train local models on distributed data, send model updates to a central server, and the server aggregates these updates into a global model. Advanced features, such as privacy preservation, efficient communication, and resilience to client dropout, are included to demonstrate how Rust’s concurrency, cryptographic libraries, and numerical operations can enable robust and scalable FL systems.
// Define Federated Learning System
FederatedLearningSystem:
clients: list of client devices or entities participating in FL
global_model: centralized model shared across clients
server: central server to aggregate client updates
disparity_threshold: acceptable level of data disparity across clients
// Initialize FL system with clients and global model
new(clients, global_model, server):
set self.clients to clients
set self.global_model to global_model
set self.server to server
// Method to simulate local training on clients
client_train():
for each client in clients:
client_data = get_data_for_client(client)
client_model = train_local_model(client_data)
send_model_to_server(client, client_model)
// Method to aggregate client updates using federated averaging
aggregate_updates():
model_parameters = collect_model_parameters(server)
// Compute federated average of client models
global_model.parameters = federated_average(model_parameters)
update_global_model(global_model)
// Method to handle non-IID data by adjusting weights or learning rates
adjust_for_non_iid_data():
for each client in clients:
client_data_distribution = analyze_data_distribution(client)
if client_data_distribution is non-IID:
apply_weight_adjustment(client)
adjust_learning_rate(global_model)
// Method to apply privacy preservation using differential privacy
apply_privacy_preservation():
for each client in clients:
local_update = get_client_update(client)
secure_update = apply_differential_privacy(local_update)
send_secure_update_to_server(client, secure_update)
// Method to optimize communication by compressing and quantizing updates
optimize_communication():
for each client in clients:
local_update = get_client_update(client)
compressed_update = compress_update(local_update)
quantized_update = quantize_update(compressed_update)
send_optimized_update_to_server(client, quantized_update)
// Method to handle client dropout and communication issues
manage_client_dropouts():
active_clients = []
for each client in clients:
if client is active:
add client to active_clients
// Aggregate updates only from active clients
aggregate_updates_from_clients(active_clients)
if client_dropouts_exceed_threshold:
apply_straggler_mitigation()
// Supporting Functions for Federated Learning System
// Function to train local model on client's data
train_local_model(data):
local_model = initialize local model
for each epoch in training loop:
update local_model using data
return local_model
// Function to send client model parameters to the server
send_model_to_server(client, model):
send encrypted model parameters from client to server
// Function to collect model parameters from all clients
collect_model_parameters(server):
model_parameters = receive model parameters from all clients
return model_parameters
// Function to calculate federated average of client models
federated_average(model_parameters):
return sum(model_parameters) / count(model_parameters)
// Function to apply differential privacy to client updates
apply_differential_privacy(update):
return update with Gaussian noise added to maintain privacy
// Function to compress client updates before transmission
compress_update(update):
return apply custom compression algorithm to update
// Function to quantize client updates for reduced data size
quantize_update(update):
return quantize data values in update for transmission efficiency
// Function to analyze client data distribution
analyze_data_distribution(client):
return compute statistics on client data to assess distribution
// Function to apply adjustments for non-IID data
apply_weight_adjustment(client):
adjust client model weights to compensate for data skew
// Function to update global model with aggregated parameters
update_global_model(global_model):
replace current global model parameters with new aggregated parameters
// Main Execution for Federated Learning System
main:
clients = initialize clients with data
global_model = initialize global model
server = initialize central server for aggregation
disparity_threshold = set allowable disparity level
// Initialize FL system with clients, global model, and server
fl_system = new FederatedLearningSystem(clients, global_model, server)
// Simulate local training on each client
fl_system.client_train()
// Aggregate model updates from clients to form global model
fl_system.aggregate_updates()
// Adjust for non-IID data if detected among clients
fl_system.adjust_for_non_iid_data()
// Apply privacy preservation techniques to secure client updates
fl_system.apply_privacy_preservation()
// Optimize communication with compressed and quantized updates
fl_system.optimize_communication()
// Handle client dropouts and network instability
fl_system.manage_client_dropouts()
print "Federated Learning Process Completed"
This pseudo code organizes the federated learning system into distinct modules for client-server communication, model training, aggregation, and optimization. Key methods include:
Client Training: The
client_trainmethod simulates local model training on each client’s data. Each client sends its locally trained model parameters to the central server after training.Federated Averaging: The
aggregate_updatesmethod aggregates client model updates through federated averaging, where model parameters are averaged to create a global model that reflects all clients' insights.Handling Non-IID Data: The
adjust_for_non_iid_datamethod detects non-IID data across clients and adjusts the learning process (e.g., by weighting updates or adjusting learning rates) to address data distribution challenges.Privacy Preservation: The
apply_privacy_preservationmethod applies differential privacy by adding noise to client updates, protecting sensitive information while balancing model accuracy.Communication Optimization: The
optimize_communicationmethod compresses and quantizes updates, reducing bandwidth consumption and ensuring efficient communication between clients and the server.Managing Client Dropouts: The
manage_client_dropoutsmethod identifies active clients and aggregates updates only from those connected. It applies straggler mitigation techniques to handle client dropout without disrupting the training process.
In the main function, the system initializes clients, a global model, and a server, then sequentially runs client training, aggregation, and optimizations. This structure, made possible by Rust’s efficient data handling, concurrency, and cryptographic support, enables secure, scalable, and privacy-preserving federated learning for real-world applications.
In summary, federated learning offers a framework for privacy-preserving, decentralized model training, accommodating client diversity and network variability while ensuring data confidentiality. Rust’s concurrency model, cryptographic capabilities, and computational efficiency provide the necessary tools for developing advanced FL systems. By understanding the trade-offs between privacy and accuracy, simulating non-IID data distributions, and addressing communication challenges, developers can create federated learning systems in Rust that meet the stringent requirements of real-world applications, setting the stage for secure and scalable LLMs in a decentralized environment. This section introduces the core principles of FL and demonstrates how Rust can support cutting-edge research and development in this innovative approach to model training.
26.3. Privacy-Preserving Techniques in LLMs
Privacy-preserving techniques are fundamental in modern large language models (LLMs) to protect sensitive data while enabling powerful machine learning capabilities. One of the cornerstone approaches in this area is differential privacy (DP), which mathematically ensures that individual data points in a dataset cannot be easily distinguished by adding carefully calibrated noise to the model’s computations. Differential privacy is critical for maintaining user confidentiality, particularly in sensitive applications like healthcare or finance. Formally, DP is defined by ensuring that the output of an algorithm is statistically similar whether or not any single individual's data is included. In the context of an LLM, differential privacy is implemented by adding noise to model updates or gradients, limiting the risk of identifying specific data points in training. For Rust-based implementations, crates like rand can be used to generate and add Gaussian or Laplacian noise to the training process, maintaining privacy while preserving as much model utility as possible.
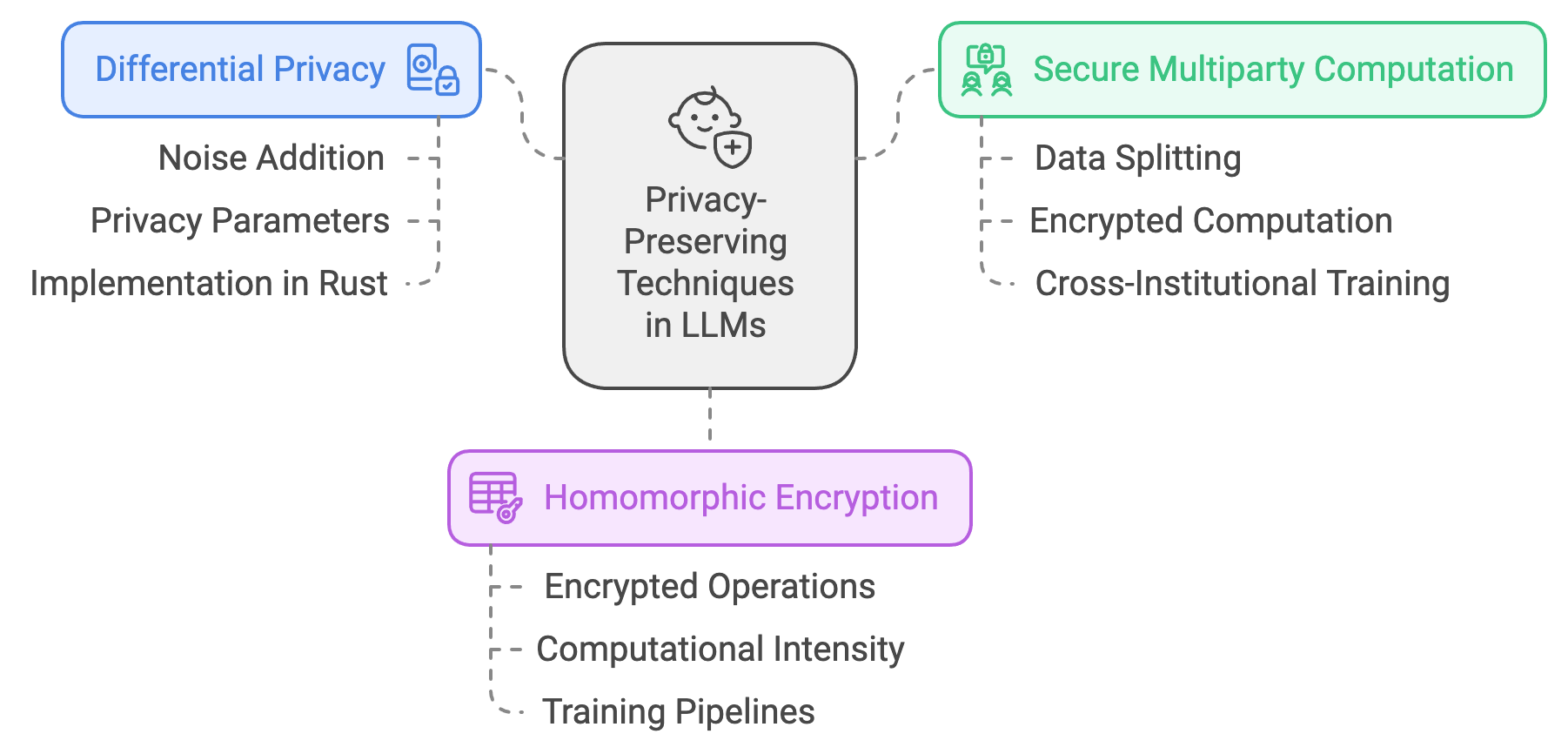
Figure 3: Privacy preserving techniques in LLMs.
Secure multiparty computation (SMPC) is another vital technique that enables collaborative learning without requiring data sharing between parties. SMPC works by splitting data into encrypted parts and distributing them to various parties who compute functions on their data without accessing others' inputs. Mathematically, if parties $A$ and $B$ hold inputs $x$ and $y$, respectively, SMPC protocols enable them to compute a function $f(x, y)$ without disclosing $x$ or $y$ to one another. For LLMs, SMPC is particularly beneficial in cross-institutional training scenarios, where institutions like hospitals or banks need to collaborate on model training without exposing sensitive data. Rust’s cryptographic libraries, such as ring and rsa, facilitate the secure key exchanges and encryption needed for SMPC implementations. By utilizing SMPC, multiple parties can securely train an LLM that benefits from diverse datasets, without compromising individual privacy or regulatory compliance.
Homomorphic encryption (HE) provides another layer of security by allowing computations to be performed on encrypted data. This is especially useful in privacy-preserving machine learning, as it enables servers to compute on data without ever decrypting it. Homomorphic encryption ensures that sensitive data remains encrypted throughout the entire process, reducing the risk of data leaks even in the event of unauthorized access. Rust libraries like concrete offer support for homomorphic encryption and can be applied to create encrypted LLM training pipelines, making it possible to perform operations directly on encrypted weights and biases. However, a key challenge with homomorphic encryption is its computational intensity, which can significantly slow down training. Developers must balance the need for robust encryption with computational feasibility, particularly for real-time or large-scale applications.
Differential privacy, SMPC, and homomorphic encryption each offer unique trade-offs between privacy guarantees and model utility. Differential privacy’s noise addition can reduce model accuracy if the noise level is too high, impacting the LLM’s ability to generalize from training data. SMPC, while secure, increases communication overhead as data needs to be shared across multiple parties in encrypted form, which can lead to latency and increased bandwidth use. Homomorphic encryption provides robust privacy but is computationally demanding, posing challenges in applications requiring rapid model updates. Thus, the choice of technique depends heavily on the specific use case and the privacy needs of the application. For instance, in a federated learning setup, differential privacy may suffice for protecting individual updates, while SMPC or homomorphic encryption could be more appropriate in multi-organization collaborations where data sensitivity is high.
Implementing differential privacy in Rust begins by defining privacy parameters, specifically the noise scale, often denoted as $\epsilon$ and $\delta$. $\epsilon$ controls the level of privacy, with smaller values indicating greater privacy at the expense of utility. For a Rust-based differential privacy implementation, noise can be added to the gradient calculations during training. For instance, by using the rand_distr crate, a Gaussian noise generator can be initialized and applied to gradient updates, ensuring individual contributions are obfuscated.
This pseudo code demonstrates how to implement privacy-preserving techniques—differential privacy (DP), secure multiparty computation (SMPC), and homomorphic encryption (HE)—in a large language model (LLM) training setup using Rust. Each technique aims to protect sensitive data while enabling effective model training. Differential privacy obfuscates individual data contributions by adding noise to model updates. SMPC allows multiple institutions to collaboratively train a model without sharing raw data by distributing encrypted data among participants. Homomorphic encryption permits computations directly on encrypted data, ensuring that sensitive information remains secure. These privacy-preserving techniques offer unique trade-offs, balancing privacy, computational efficiency, and model utility.
// Define Privacy-Preserving LLM Training System
PrivacyPreservingLLMTraining:
model: LLM model to be trained
data: dataset with sensitive data
privacy_parameters: differential privacy parameters (epsilon, delta)
smpc_parties: list of parties involved in SMPC for collaborative training
encryption_keys: keys used for homomorphic encryption
// Initialize training system with model, data, and privacy parameters
new(model, data, privacy_parameters, smpc_parties, encryption_keys):
set self.model to model
set self.data to data
set self.privacy_parameters to privacy_parameters
set self.smpc_parties to smpc_parties
set self.encryption_keys to encryption_keys
// Method for applying Differential Privacy by adding noise to gradients
apply_differential_privacy():
noise_scale = calculate_noise_scale(privacy_parameters)
for each training iteration:
gradients = compute_gradients(model, data)
noisy_gradients = add_noise_to_gradients(gradients, noise_scale)
update_model_parameters(model, noisy_gradients)
// Method for Secure Multiparty Computation (SMPC) in collaborative training
perform_smpc_training():
split_data_for_smpc(data, smpc_parties)
for each smpc_party in smpc_parties:
encrypted_data = encrypt_data(smpc_party.data, smpc_party.encryption_key)
encrypted_gradients = compute_encrypted_gradients(encrypted_data, model)
// Send encrypted gradients to central aggregator or other parties
send_encrypted_gradients(smpc_party, encrypted_gradients)
// Aggregate encrypted gradients without decryption
global_encrypted_gradients = aggregate_encrypted_gradients(smpc_parties)
global_gradients = decrypt_gradients(global_encrypted_gradients, encryption_keys)
update_model_parameters(model, global_gradients)
// Method for Homomorphic Encryption to compute directly on encrypted data
apply_homomorphic_encryption():
encrypted_model = encrypt_model_parameters(model, encryption_keys)
for each training iteration:
encrypted_gradients = compute_gradients(encrypted_model, data, encrypted=True)
encrypted_model = update_encrypted_model(encrypted_model, encrypted_gradients)
decrypted_model = decrypt_model(encrypted_model, encryption_keys)
return decrypted_model
// Method to balance trade-offs between privacy, utility, and computation
evaluate_tradeoffs():
privacy_impact = assess_privacy_impact(privacy_parameters)
utility_impact = assess_model_utility(model)
computational_cost = estimate_computation_cost()
return {
"privacy": privacy_impact,
"utility": utility_impact,
"computation": computational_cost
}
// Supporting Functions for Privacy-Preserving LLM Training
// Function to calculate noise scale based on privacy parameters
calculate_noise_scale(privacy_parameters):
return calculate noise scale from epsilon and delta
// Function to compute gradients of the model
compute_gradients(model, data, encrypted=False):
if encrypted:
return calculate gradients on encrypted data
else:
return calculate gradients on plain data
// Function to add noise to gradients for differential privacy
add_noise_to_gradients(gradients, noise_scale):
noisy_gradients = []
for each gradient in gradients:
noise = generate_gaussian_noise(noise_scale)
noisy_gradient = gradient + noise
noisy_gradients.append(noisy_gradient)
return noisy_gradients
// Function to split data for SMPC across multiple parties
split_data_for_smpc(data, smpc_parties):
divide data into shares for each party in smpc_parties
// Function to encrypt data for SMPC
encrypt_data(data, encryption_key):
return encrypt data using encryption_key
// Function to compute encrypted gradients
compute_encrypted_gradients(encrypted_data, model):
return calculate gradients on encrypted data without decryption
// Function to send encrypted gradients to other parties
send_encrypted_gradients(party, encrypted_gradients):
transmit encrypted gradients to designated parties
// Function to aggregate encrypted gradients without decrypting
aggregate_encrypted_gradients(smpc_parties):
return aggregate encrypted gradients received from smpc_parties
// Function to decrypt gradients after aggregation
decrypt_gradients(encrypted_gradients, encryption_keys):
return decrypt aggregated gradients using encryption_keys
// Function to encrypt model parameters for homomorphic encryption
encrypt_model_parameters(model, encryption_keys):
return encrypt each parameter of the model with encryption_keys
// Function to update model with encrypted gradients
update_encrypted_model(encrypted_model, encrypted_gradients):
for each parameter in encrypted_model:
update parameter with corresponding encrypted gradient
return encrypted_model
// Function to decrypt model parameters after training
decrypt_model(encrypted_model, encryption_keys):
return decrypt each parameter of encrypted_model with encryption_keys
// Function to assess the privacy impact of differential privacy parameters
assess_privacy_impact(privacy_parameters):
return analyze privacy trade-offs based on epsilon and delta
// Function to assess model utility by evaluating accuracy or performance
assess_model_utility(model):
return evaluate model accuracy or performance metrics
// Function to estimate computational cost for different techniques
estima
This pseudo code represents a privacy-preserving LLM training framework with methods for differential privacy, SMPC, and homomorphic encryption, each designed to protect sensitive data in different ways:
Differential Privacy: The
apply_differential_privacymethod adds Gaussian noise to model gradients based on privacy parameters (ϵ\\epsilonϵ, δ\\deltaδ) to obfuscate individual contributions and maintain data privacy. This prevents identifying specific data points while still allowing effective model training.Secure Multiparty Computation (SMPC): The
perform_smpc_trainingmethod allows multiple parties to collaboratively train a model without sharing raw data. Data is split and encrypted, and each party computes encrypted gradients independently. Aggregated gradients are then decrypted and applied to the global model, maintaining privacy in multi-party environments.Homomorphic Encryption: The
apply_homomorphic_encryptionmethod performs model updates directly on encrypted data, so sensitive information remains encrypted throughout the computation process. This provides strong data security, though it comes at a higher computational cost.Trade-off Evaluation: The
evaluate_tradeoffsmethod assesses the trade-offs between privacy, model utility, and computational cost for each technique, enabling informed choices depending on application requirements.
In the main function, the framework is initialized with a model, data, privacy parameters, SMPC parties, and encryption keys. The framework sequentially applies differential privacy, SMPC, and homomorphic encryption, concluding with an evaluation of trade-offs. This pseudo code outlines a comprehensive approach to building secure and privacy-preserving LLM systems, leveraging Rust’s capabilities for data security and efficient computation.
For SMPC in Rust, an example would involve splitting a model’s weight matrix across multiple devices. Each device encrypts its local data using a shared secret and contributes only its encrypted update. The updates are then aggregated to form a global model without any device revealing its data to others. Implementing this process efficiently in Rust requires using libraries like ring for cryptographic functions and tokio for managing asynchronous communication.
This pseudo code illustrates the implementation of secure multiparty computation (SMPC) for a large language model’s (LLM) weight matrix in Rust. Each device splits and encrypts its local model updates and securely contributes its encrypted data to the global model without exposing any private information. Using cryptographic functions from libraries like ring for encryption and tokio for asynchronous communication, this approach enables devices to collaborate securely while maintaining data privacy.
// Define Secure Multiparty Computation (SMPC) System for LLM Weights
SMPCSystem:
devices: list of devices participating in SMPC
shared_secret_keys: keys for encrypting and decrypting updates
global_weight_matrix: shared global model weights across all devices
// Initialize SMPC system with devices and shared secret keys
new(devices, shared_secret_keys):
set self.devices to devices
set self.shared_secret_keys to shared_secret_keys
initialize self.global_weight_matrix as empty
// Method for each device to split and encrypt its local weight matrix
encrypt_local_weights(device):
local_weight_matrix = get_weight_matrix(device.model)
// Split weights using shared secret keys
encrypted_shares = []
for each weight in local_weight_matrix:
encrypted_share = encrypt_weight_with_secret(weight, shared_secret_keys[device])
encrypted_shares.append(encrypted_share)
return encrypted_shares
// Method for devices to send encrypted updates asynchronously to central server
send_encrypted_updates(device):
encrypted_shares = encrypt_local_weights(device)
// Use asynchronous communication to send encrypted updates
async send_to_server(device, encrypted_shares)
// Method for the server to aggregate encrypted updates without decryption
aggregate_encrypted_updates():
aggregated_weights = initialize_weight_matrix()
for each device in devices:
device_updates = receive_encrypted_updates(device)
// Aggregate weights element-wise across all encrypted shares
for each (i, j) in aggregated_weights:
aggregated_weights[i][j] += device_updates[i][j]
return aggregated_weights
// Method to decrypt the aggregated weights to form the global model
decrypt_global_weights(aggregated_weights):
decrypted_weights = initialize_weight_matrix()
for each (i, j) in aggregated_weights:
decrypted_weights[i][j] = decrypt_weight_with_secret(aggregated_weights[i][j], shared_secret_keys)
set self.global_weight_matrix to decrypted_weights
return decrypted_weights
// Main SMPC process to run asynchronously for secure collaboration
smpc_process():
for each device in devices:
async send_encrypted_updates(device)
// Aggregate encrypted updates from all devices
aggregated_weights = aggregate_encrypted_updates()
// Decrypt to obtain the updated global weight matrix
decrypted_global_weights = decrypt_global_weights(aggregated_weights)
return decrypted_global_weights
// Supporting Functions for SMPC System
// Function to retrieve weight matrix from a device's model
get_weight_matrix(model):
return model.weight_matrix
// Function to encrypt a weight using a shared secret
encrypt_weight_with_secret(weight, secret_key):
return apply encryption function with weight and secret_key
// Function to decrypt a weight using a shared secret
decrypt_weight_with_secret(encrypted_weight, secret_keys):
return apply decryption function with encrypted_weight and corresponding secret_keys
// Function to initialize an empty weight matrix
initialize_weight_matrix():
return create matrix with dimensions of the model weight matrix initialized to zero
// Function to send encrypted updates asynchronously to the server
async send_to_server(device, encrypted_shares):
establish connection with server asynchronously
transmit encrypted_shares to the server
close connection
// Function to receive encrypted updates from devices
receive_encrypted_updates(device):
establish connection with server asynchronously
retrieve encrypted updates sent by device
close connection
return encrypted updates
// Main Execution for SMPC in LLM Training
main:
devices = initialize list of participating devices
shared_secret_keys = generate shared secret keys for each device
smpc_system = new SMPCSystem(devices, shared_secret_keys)
// Run SMPC process to securely aggregate and update global weight matrix
global_model_weights = smpc_system.smpc_process()
print "Updated Global Model Weights:", global_model_weights
This pseudo code defines an SMPCSystem class for securely aggregating a large language model’s weight matrix using SMPC. Here are the primary components:
Local Weight Encryption: The
encrypt_local_weightsmethod splits and encrypts each device’s weight matrix using shared secret keys, ensuring that sensitive information remains protected. Each encrypted share is created independently and stored for secure transmission.Asynchronous Communication: The
send_encrypted_updatesmethod transmits encrypted weight shares from each device to the central server using asynchronous communication (async), reducing latency and improving system scalability.Aggregation Without Decryption: The
aggregate_encrypted_updatesmethod aggregates the encrypted weight matrices received from all devices. By summing encrypted values element-wise, the server produces an aggregated encrypted model without decrypting any individual updates.Global Model Decryption: The
decrypt_global_weightsmethod decrypts the aggregated weight matrix using shared secrets, creating a final global model that incorporates contributions from all devices without compromising individual privacy.Asynchronous SMPC Process: The
smpc_processmethod coordinates the asynchronous transmission, aggregation, and decryption to produce a secure global model update.
In the main function, devices and shared keys are initialized, and the SMPC process is executed. Each device’s data remains private, as the server never accesses raw weights—only encrypted shares—ensuring privacy and regulatory compliance in sensitive applications. Rust’s asynchronous capabilities (tokio crate) and cryptographic libraries (e.g., ring) make this process efficient and secure, enabling real-world applications in collaborative machine learning.
Experiments using privacy-preserving techniques often reveal their impact on model performance, which must be carefully measured and optimized. In LLMs, adding privacy mechanisms like DP can reduce the model's ability to generalize effectively, as it may overfit to noise rather than meaningful patterns. By conducting controlled experiments in Rust, developers can analyze the trade-offs and measure model performance across different privacy settings. For instance, running benchmarks with various levels of differential privacy allows developers to tune the privacy parameters to achieve a suitable balance between data protection and model accuracy.
In real-world applications, privacy-preserving techniques are essential for compliance with data protection regulations, such as GDPR in the European Union. Regulations like GDPR mandate strict controls over data access and processing, especially in high-stakes domains like healthcare, finance, and legal services. In these sectors, privacy-preserving LLMs can enable organizations to leverage sensitive data without breaching regulatory requirements. For example, in a medical research context, federated learning enhanced by DP ensures that a hospital can contribute patient data insights to a shared model without exposing individual records, thereby maintaining patient confidentiality. Rust, with its performance-focused approach and strong memory safety, provides a reliable platform for building compliance-focused solutions that protect sensitive data and enhance trustworthiness.
In conclusion, privacy-preserving techniques are pivotal in the development of LLMs that respect user privacy and adhere to regulatory standards. Differential privacy, SMPC, and homomorphic encryption each provide unique approaches to secure model training, allowing LLMs to operate on sensitive data while minimizing privacy risks. Rust’s ecosystem, with its robust cryptographic libraries and efficient concurrency model, offers the tools necessary for implementing these techniques at scale. By leveraging these privacy-preserving methods, Rust developers can create LLMs that are not only effective but also aligned with ethical and legal standards, paving the way for trustworthy AI in data-sensitive applications. This section has provided a foundation for understanding and implementing privacy-preserving techniques in Rust, equipping developers to build secure, compliant LLMs that meet the demands of modern AI-driven industries.
26.4. Federated Learning and Privacy in the Rust Ecosystem
The Rust ecosystem provides a compelling foundation for implementing federated learning (FL) and privacy-preserving techniques, combining robust performance with the safety and concurrency features necessary for secure distributed computing. Rust’s core strengths, such as memory safety without a garbage collector and a strong type system, make it ideal for building secure federated systems that can handle the rigorous demands of both computation and communication inherent in FL architectures. Unlike many traditional languages used in machine learning and data processing, Rust ensures memory safety at compile-time, which is essential for secure FL applications, particularly when sensitive data and client information are involved. This section explores the Rust ecosystem’s unique advantages for FL and privacy, covering relevant libraries and sample implementations that leverage Rust's key features.
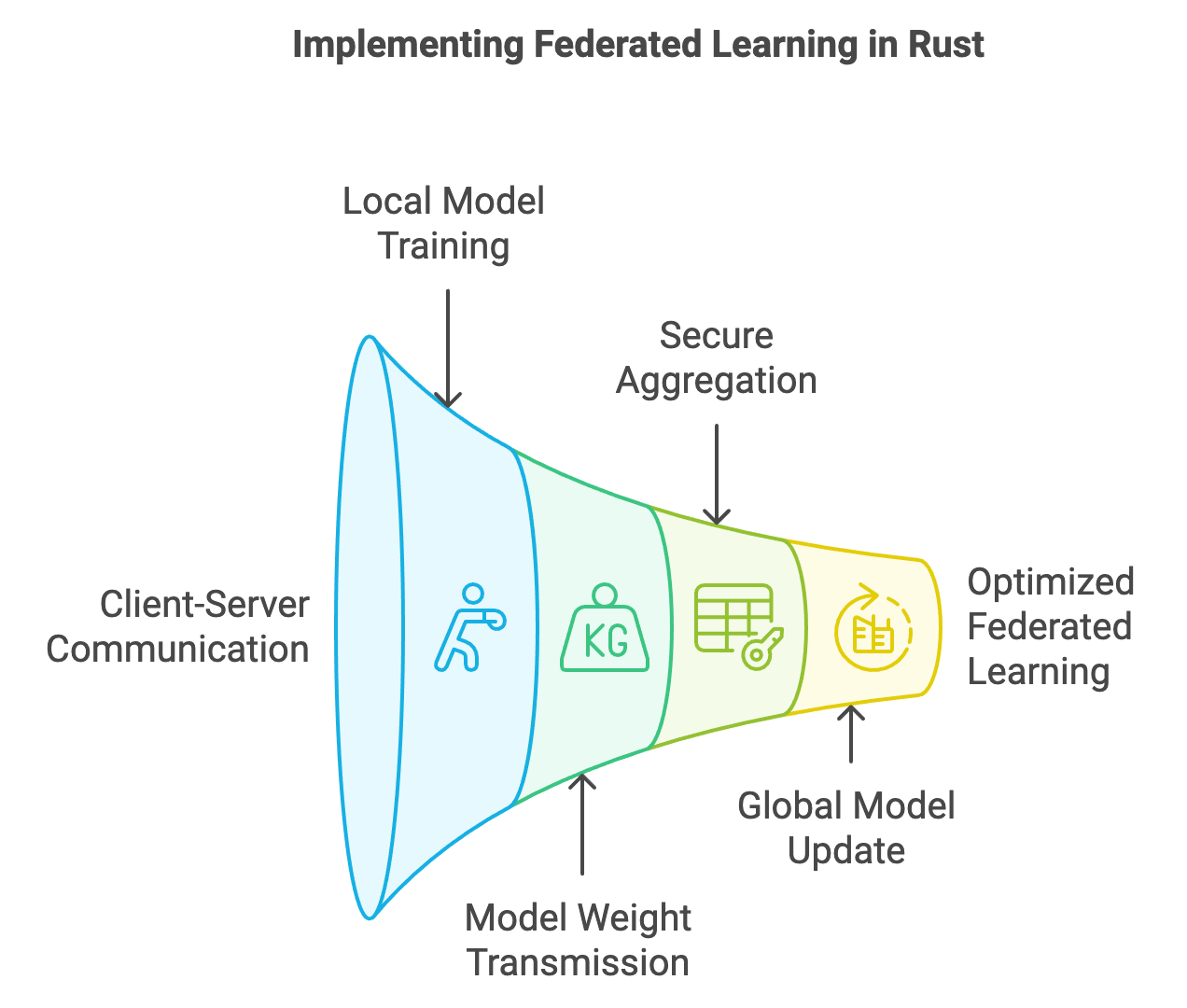
Figure 4: Implementation cycle of federated learning in Rust.
Rust’s asynchronous programming model is particularly suited to managing the complex network communications that federated learning requires. Federated learning systems rely heavily on continuous data exchange between clients (e.g., mobile devices, institutions) and central servers to update global models. Rust’s tokio and async-std libraries offer asynchronous, event-driven models that manage concurrent client-server communications effectively, optimizing network traffic and reducing latency. For instance, asynchronous programming in Rust enables the non-blocking handling of model updates from multiple clients, allowing the system to manage thousands of concurrent updates without performance degradation. This capability is vital in federated learning, where communication bottlenecks can slow model convergence and affect accuracy. The actix framework further enhances this capability by enabling high-performance web services in Rust, allowing FL servers to handle client requests with minimal delay.
One of the primary concerns in federated learning and privacy-preserving computations is maintaining data confidentiality. Rust provides a powerful set of cryptographic libraries, such as ring and rust-crypto, which support various encryption methods essential for secure data transmission and computation. For example, federated learning protocols often involve secure aggregation methods to combine model updates from clients in a way that protects individual data points. By leveraging libraries like ring, Rust developers can implement homomorphic encryption and secure multiparty computation (SMPC) protocols, enabling secure model aggregation without exposing client data. Furthermore, Rust’s low-level control over memory operations minimizes the risk of data leaks or unauthorized memory access, a critical feature for ensuring compliance with data protection regulations such as GDPR.
Rust’s ownership model and strong type system help prevent common security vulnerabilities like data races and unauthorized memory access, which are particularly problematic in distributed systems with concurrent data processing. In FL implementations, data is distributed across multiple clients, with each client maintaining ownership of its data. Rust’s ownership model enforces strict rules about data access and modification, ensuring that only one part of the program has access to sensitive data at any time. This model is particularly beneficial when working with client-specific data in federated learning, as it reduces the risk of inadvertent data exposure during the training process. Additionally, Rust’s type system ensures that only validated data structures and model updates are communicated between clients and the server, mitigating the risk of corrupted updates affecting the global model.
Implementing a basic federated learning environment in Rust involves setting up client-server communication channels, defining local model training on clients, and implementing secure aggregation on the server. For instance, using the serde library, Rust developers can serialize and deserialize model parameters, allowing for efficient data transmission between clients and servers. In the federated averaging algorithm, each client trains a local model and then sends the model weights back to the server. The server aggregates these weights to update the global model, after which it broadcasts the updated model to clients. Rust’s tokio library can manage this workflow asynchronously, handling each client’s update independently, thus optimizing communication latency.
This pseudo code demonstrates a federated learning (FL) setup in Rust, leveraging Rust’s asynchronous programming capabilities with the tokio library for efficient client-server communication, the serde library for serializing model parameters, and ring for cryptographic data protection. The FL system asynchronously manages updates from multiple clients, securely aggregates these updates on the server, and then broadcasts the updated global model to each client. Rust’s strong type system, ownership model, and cryptographic support make it ideal for secure and scalable FL implementations.
// Define Federated Learning System with Asynchronous Client-Server Communication
FederatedLearningSystem:
clients: list of clients participating in federated learning
global_model: centralized model shared across clients
secure_aggregator: cryptographic aggregator for secure model updates
// Initialize FL system with clients, global model, and secure aggregator
new(clients, global_model, secure_aggregator):
set self.clients to clients
set self.global_model to global_model
set self.secure_aggregator to secure_aggregator
// Asynchronous method for clients to train local models and send updates
async client_training_and_update():
for each client in clients:
local_model = train_local_model(client.data)
serialized_model = serialize_model(local_model)
// Encrypt model update before sending to server
encrypted_update = secure_aggregator.encrypt(serialized_model)
await send_update_to_server(client, encrypted_update)
// Asynchronous method for server to receive and aggregate updates
async server_aggregate_updates():
aggregated_weights = initialize_weight_matrix()
for each client in clients:
// Receive and decrypt client updates asynchronously
encrypted_update = await receive_update_from_client(client)
decrypted_update = secure_aggregator.decrypt(encrypted_update)
client_weights = deserialize_model(decrypted_update)
// Aggregate each client's weights into global model
aggregated_weights = add_to_aggregated_weights(aggregated_weights, client_weights)
set self.global_model to federated_average(aggregated_weights)
// Method to broadcast updated global model to all clients
async broadcast_global_model():
serialized_global_model = serialize_model(self.global_model)
for each client in clients:
await send_global_model_to_client(client, serialized_global_model)
// Main Federated Learning Process using asynchronous functions
async federated_learning_process():
// Step 1: Clients train and send updates asynchronously
await client_training_and_update()
// Step 2: Server aggregates updates asynchronously
await server_aggregate_updates()
// Step 3: Server broadcasts global model back to clients
await broadcast_global_model()
// Supporting Functions for Federated Learning System
// Function for each client to train a local model
train_local_model(data):
model = initialize_model()
for each epoch in training loop:
update model using data
return model
// Function to serialize model parameters for transmission
serialize_model(model):
return serde.serialize(model.parameters)
// Function to deserialize model parameters after receiving
deserialize_model(serialized_data):
return serde.deserialize(serialized_data)
// Function to send encrypted model update from client to server asynchronously
async send_update_to_server(client, encrypted_update):
establish connection with server asynchronously
send encrypted_update to server
close connection
// Function to receive encrypted model update from client asynchronously
async receive_update_from_client(client):
establish connection with client asynchronously
receive encrypted model update from client
close connection
return encrypted_update
// Function to add client weights to aggregated weights
add_to_aggregated_weights(aggregated_weights, client_weights):
return element-wise sum of aggregated_weights and client_weights
// Function to compute federated average of aggregated weights
federated_average(aggregated_weights):
return divide aggregated_weights by number of clients
// Function to send global model to client asynchronously
async send_global_model_to_client(client, serialized_global_model):
establish connection with client asynchronously
send serialized_global_model to client
close connection
// Main Execution for Federated Learning with Asynchronous Communication
main:
clients = initialize clients with local data
global_model = initialize global model
secure_aggregator = initialize cryptographic aggregator with encryption keys
fl_system = new FederatedLearningSystem(clients, global_model, secure_aggregator)
// Run asynchronous federated learning process
await fl_system.federated_learning_process()
print "Federated Learning Process Completed with Global Model Updates"
This pseudo code defines a FederatedLearningSystem class with asynchronous methods for handling client-server communication and secure aggregation of model updates:
Client Training and Update: The
client_training_and_updatemethod asynchronously initiates training on each client’s local data and serializes the trained model. The serialized model is encrypted usingsecure_aggregatorand sent to the server for aggregation.Server Aggregation: The
server_aggregate_updatesmethod asynchronously receives encrypted updates from clients, decrypts each update, deserializes the model parameters, and aggregates the weights into a global model. The federated average is then computed and assigned toglobal_model.Broadcasting the Global Model: The
broadcast_global_modelmethod asynchronously sends the updated global model back to each client. The model is serialized for transmission and then sent asynchronously to each client.Asynchronous Federated Learning Process: The
federated_learning_processmethod orchestrates the entire workflow by running each of the key steps (client training, server aggregation, and broadcasting) asynchronously. This approach minimizes network delays and optimizes resource usage.
In the main function, clients and the secure aggregator are initialized, and the asynchronous FL process is executed. Rust’s asynchronous capabilities (tokio library) and cryptographic support (e.g., ring library) ensure efficient communication and secure data transmission in federated learning, supporting privacy and scalability. This setup reduces latency and maximizes performance by handling client updates independently, even at large scales.
Privacy-preserving techniques, such as differential privacy (DP), are essential for ensuring that individual client data cannot be inferred from model updates. Rust’s random number generation libraries, such as rand and rand_distr, can be used to implement differential privacy by adding Gaussian or Laplacian noise to client updates. This approach ensures that even if a malicious actor were to intercept client updates, the noise obscures the specific data points, maintaining data privacy.
As federated learning and privacy-preserving machine learning advance, Rust is increasingly recognized for its robustness and performance in this field. With an expanding ecosystem of libraries that support cryptography, asynchronous communication, and data serialization, Rust equips developers with the tools necessary to build secure, scalable FL systems. Its memory safety, coupled with efficient concurrency handling, makes it possible to handle large-scale deployments while maintaining rigorous security and privacy standards. In industries like finance, healthcare, and IoT, where data sensitivity and regulatory compliance are critical, Rust-based FL solutions provide a powerful alternative for managing distributed data processing and preserving privacy.
The Rust ecosystem continues to evolve, with new libraries and tools emerging to support FL and privacy-preserving techniques. These innovations, combined with Rust’s inherent performance and safety features, make it well-suited for the future of federated learning and privacy in AI. As demand for privacy-respecting AI solutions grows, Rust’s capabilities in secure, efficient, and scalable distributed computing will play a vital role in developing next-generation federated learning applications. This section has explored the foundational aspects of the Rust ecosystem as it applies to federated learning and privacy-preserving techniques, setting the stage for more advanced implementations and industry-specific adaptations in subsequent chapters.
26.5. Challenges and Future Directions
Federated learning (FL) and privacy-preserving techniques face significant challenges, particularly as these methods are scaled up for deployment in real-world systems. One major hurdle is the difficulty of efficiently aggregating and managing data from a large number of distributed clients, each with unique data distributions, hardware capacities, and network conditions. This heterogeneity complicates model convergence and can significantly slow down training times. A considerable area of ongoing research aims to optimize FL algorithms for these diverse settings, introducing techniques that adjust dynamically to the unique characteristics of each client. At the same time, there is a push to enhance privacy guarantees, such as through advanced methods in differential privacy (DP) and secure multiparty computation (SMPC). Rust’s ecosystem provides a promising framework for addressing these challenges due to its efficient concurrency model and robust cryptographic libraries, which are essential for privacy-preserving FL systems that prioritize security without compromising scalability.
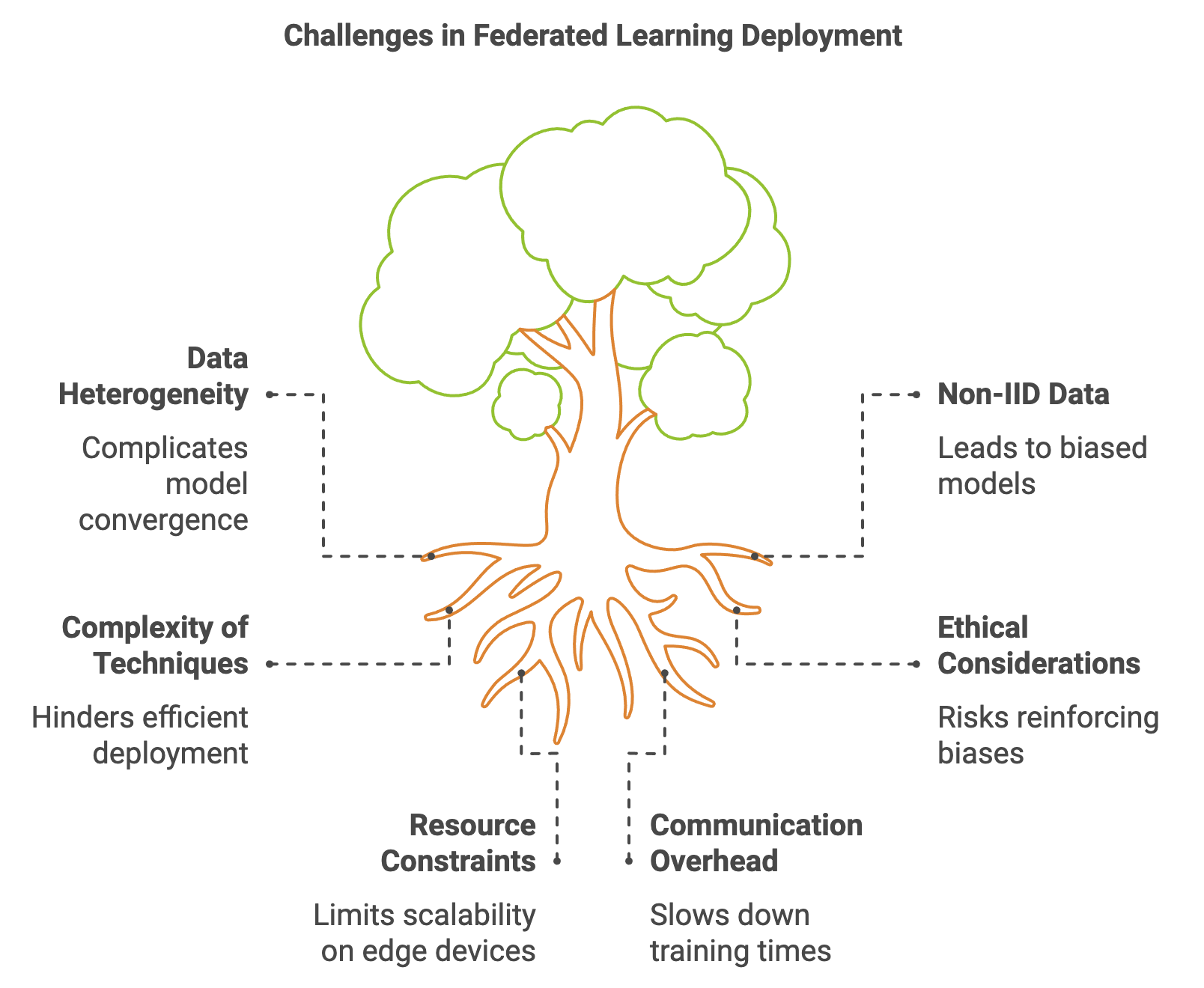
Figure 5: Key challenges in Federated Learning deployment.
One of the primary limitations of existing FL and privacy-preserving techniques is their complexity in deployment, particularly as models and networks grow larger. Traditional FL methods like federated averaging (FedAvg) struggle with highly non-IID (non-independent and identically distributed) data, which is common in real-world applications where clients generate data with unique distributions. Non-IID data can lead to biased models that do not generalize well across clients. Hybrid approaches, combining FL with advanced AI techniques like reinforcement learning, generative models, and continual learning, offer exciting potential to counter these challenges. By leveraging reinforcement learning, for example, models can be tuned to adapt to dynamic environments and non-stationary data sources, improving their generalization capabilities. Generative models can be used to generate synthetic data for underrepresented clients, enhancing the fairness of the aggregated model. Rust’s high performance makes it suitable for these experimental approaches, where efficient resource management and real-time processing are critical.
The ethical considerations of federated learning and privacy-preserving methods are an increasingly important area of focus. As models are trained on decentralized data, ensuring that they do not inadvertently reinforce or exacerbate biases becomes critical, especially in sensitive fields like finance, healthcare, and criminal justice. Privacy-preserving techniques such as DP, while effective in protecting individual data, can sometimes obscure underlying trends in minority or sensitive data groups, leading to unfair or biased models. Ethical implications must be carefully evaluated in federated learning systems, balancing privacy with the need for transparency and accountability. Rust’s memory safety features, combined with its support for reproducible builds, facilitate robust experimentation with FL models, allowing researchers to carefully document and audit models for fairness and bias.
A practical way to approach these challenges is by developing a research proposal using Rust to address a specific issue within FL or privacy-preserving machine learning. For example, a proposal might focus on optimizing FL algorithms for environments with non-IID data, where Rust’s concurrency features can be used to parallelize data processing and aggregation across clients, reducing the communication overhead. Using Rust’s tokio library for asynchronous communication, researchers can simulate large-scale FL deployments and analyze the performance impact of various optimization techniques in real-time. Additionally, by implementing DP in Rust with the rand_distr crate, researchers can evaluate the trade-offs between privacy and model utility, experimenting with different noise distributions and privacy budgets.
In recent years, advancements in the field have spurred new directions for future research. For instance, privacy-preserving federated learning on edge devices is gaining traction as computational capabilities on these devices improve. Rust’s lightweight runtime and low-level control over memory and processor usage make it an ideal candidate for developing and deploying FL systems on resource-constrained devices like smartphones and IoT devices. Combining FL with edge computing enables faster, more efficient updates, reducing the latency associated with centralized server communication. Rust libraries such as actix and hyper are well-suited for building decentralized networks that manage data and models across edge devices, enabling the deployment of federated learning systems that are highly scalable and privacy-compliant.
In addition to improving performance, there is also a growing interest in making FL systems more resilient to security threats. Model poisoning attacks, where malicious clients send incorrect updates to influence the global model, pose a significant risk to federated learning systems. Rust’s strong type system and secure memory management provide a foundation for building robust FL systems that are resistant to such attacks. By employing Rust’s cryptographic libraries, developers can implement secure aggregation and verification protocols to detect and mitigate tampering in client updates.
This pseudo code outlines a federated learning (FL) system in Rust designed to address the limitations of traditional FL techniques, especially in handling non-IID data and security threats. The system incorporates hybrid methods, such as reinforcement learning and generative models, to improve model generalization on diverse client data. Additionally, it emphasizes ethical considerations and security through differential privacy (DP) and secure aggregation. Rust’s high-performance concurrency features (e.g., tokio), cryptographic libraries (e.g., ring), and memory safety make it well-suited for implementing advanced FL solutions that are efficient, resilient, and privacy-preserving.
// Define Advanced Federated Learning System for Non-IID Data and Security
AdvancedFLSystem:
clients: list of clients with non-IID data distributions
global_model: shared model that aggregates updates from clients
privacy_parameters: differential privacy settings (epsilon, delta)
reinforcement_agent: agent for reinforcement learning adaptation
secure_aggregator: aggregator with secure verification protocols
poison_detection: protocol for detecting malicious updates
// Initialize FL system with clients, model, privacy parameters, and security protocols
new(clients, global_model, privacy_parameters, reinforcement_agent, secure_aggregator, poison_detection):
set self.clients to clients
set self.global_model to global_model
set self.privacy_parameters to privacy_parameters
set self.reinforcement_agent to reinforcement_agent
set self.secure_aggregator to secure_aggregator
set self.poison_detection to poison_detection
// Method for adaptive client training with reinforcement learning
adaptive_client_training():
for each client in clients:
local_data = get_data(client)
// Train local model and adapt to non-stationary data
local_model = train_local_model(local_data)
adapted_model = self.reinforcement_agent.adapt(local_model, local_data)
// Apply differential privacy noise to the model updates
dp_model = apply_differential_privacy(adapted_model, self.privacy_parameters)
send_model_to_server(client, dp_model)
// Asynchronous method for aggregating updates with secure protocols
async secure_aggregation():
encrypted_updates = []
for each client in clients:
encrypted_update = await receive_encrypted_update(client)
// Verify update for tampering or poisoning
if self.poison_detection.verify(encrypted_update):
encrypted_updates.append(encrypted_update)
aggregated_model = self.secure_aggregator.aggregate(encrypted_updates)
set self.global_model to aggregated_model
// Method for generating synthetic data to balance non-IID data distribution
generate_synthetic_data():
for each underrepresented client in clients:
synthetic_data = self.reinforcement_agent.generate_synthetic_data()
augmented_model = train_with_synthetic_data(synthetic_data)
send_model_to_server(underrepresented_client, augmented_model)
// Method to monitor ethical considerations, such as fairness and bias
ethical_monitoring():
bias_metrics = []
for each client_data in clients:
client_bias = analyze_bias_in_data(client_data)
bias_metrics.append(client_bias)
fairness_score = calculate_fairness_score(bias_metrics)
return fairness_score
// Main federated learning process
async federated_learning_process():
// Step 1: Adaptive client training
adaptive_client_training()
// Step 2: Securely aggregate updates asynchronously
await secure_aggregation()
// Step 3: Generate synthetic data for non-IID clients if needed
generate_synthetic_data()
// Step 4: Perform ethical monitoring
fairness_score = ethical_monitoring()
log_fairness(fairness_score)
// Broadcast the global model back to clients
await broadcast_global_model()
// Supporting Functions for Advanced Federated Learning System
// Function for each client to train a local model
train_local_model(data):
model = initialize_model()
for each epoch in training loop:
update model using data
return model
// Function to adapt the model using reinforcement learning for non-IID data
reinforcement_agent.adapt(model, data):
return fine-tune model parameters based on reinforcement signals from data
// Function to apply differential privacy to model updates
apply_differential_privacy(model, privacy_parameters):
noise_scale = calculate_noise_scale(privacy_parameters)
for each parameter in model:
parameter += generate_noise(noise_scale)
return model
// Function to send model to server asynchronously
async send_model_to_server(client, model):
establish connection with server
serialize and send model to server
close connection
// Function to verify client update for poisoning or tampering
poison_detection.verify(update):
if update contains anomalies or suspicious patterns:
return False
return True
// Function to securely aggregate model updates
secure_aggregator.aggregate(updates):
aggregated_model = initialize_global_model()
for each update in updates:
add encrypted update to aggregated_model
return aggregated_model
// Function to analyze bias in client data
analyze_bias_in_data(data):
calculate bias metrics from data distribution
return bias_score
// Function to calculate overall fairness score
calculate_fairness_score(bias_metrics):
return average(bias_metrics)
// Function to log fairness score for auditing
log_fairness(score):
log score with timestamp for auditing purposes
// Main Execution for Advanced Federated Learning System
main:
clients = initialize clients with non-IID data
global_model = initialize global model
privacy_parameters = set differential privacy parameters (epsilon, delta)
reinforcement_agent = initialize reinforcement learning agent
secure_aggregator = initialize secure aggregator with cryptographic protocols
poison_detection = initialize protocol for detecting malicious updates
fl_system = new AdvancedFLSystem(clients, global_model, privacy_parameters, reinforcement_agent, secure_aggregator, poison_detection)
// Run the federated learning process asynchronously
await fl_system.federated_learning_process()
print "Federated Learning with Enhanced Adaptation, Security, and Fairness Completed"
This pseudo code represents an advanced federated learning system with a focus on handling non-IID data, ensuring security, and monitoring ethical considerations:
Adaptive Client Training: The
adaptive_client_trainingmethod uses reinforcement learning to adapt local models for non-IID data on each client. Differential privacy is applied to model updates before they are sent to the server to protect individual client data.Secure Aggregation: The
secure_aggregationmethod asynchronously receives encrypted updates from clients and uses secure aggregation to combine them without compromising privacy. Apoison_detectionprotocol verifies each update to detect any tampering or malicious attempts to corrupt the model.Synthetic Data Generation: The
generate_synthetic_datamethod uses a generative model to create synthetic data for clients with underrepresented data distributions. This approach balances non-IID distributions, ensuring fairness in the global model.Ethical Monitoring: The
ethical_monitoringmethod calculates a fairness score by analyzing bias metrics across client data, helping ensure the model remains unbiased and ethically sound.Federated Learning Process: The
federated_learning_processorchestrates the entire workflow asynchronously, allowing adaptive client training, secure aggregation, synthetic data generation, and ethical monitoring to happen concurrently. After aggregation, the global model is broadcast back to clients.
In the main function, the federated learning system is initialized and executed asynchronously, using Rust’s concurrency and cryptographic capabilities. This setup provides a robust, privacy-preserving FL framework suitable for real-world applications where data distributions are varied, ethical standards must be maintained, and security threats like model poisoning are a concern.
Looking forward, the field of federated learning and privacy-preserving machine learning is expected to grow rapidly, with Rust emerging as a key player in this evolution. The unique combination of high performance, security, and scalability that Rust offers aligns well with the requirements of federated learning systems, especially as they scale to meet the demands of real-world deployments. By focusing on optimization, privacy, and security, Rust-based solutions will play a critical role in shaping the future of federated learning, enabling the development of AI systems that are both effective and ethically responsible. This section has outlined the current challenges in federated learning and privacy preservation, setting the stage for the next wave of innovations that Rust developers and researchers are likely to pioneer in the coming years.
26.6. Conclusion
Chapter 26 underscores the significance of federated learning and privacy-preserving techniques as essential tools for developing ethical and secure large language models. By leveraging the power of Rust, developers can create systems that not only respect user privacy but also maintain high levels of performance and security, paving the way for more responsible AI development in a decentralized world.
26.6.1. Further Learning with GenAI
Each prompt is crafted to challenge your understanding, push your technical boundaries, and guide you in exploring both the theoretical and practical aspects of federated learning and privacy preservation.
Explain the fundamental differences between federated learning and traditional centralized learning. How does federated learning enhance data privacy, and what are the trade-offs in terms of model performance and communication overhead?
Discuss the key components of a federated learning system, such as client-server models, model aggregation, and communication protocols. How can Rust be used to implement these components efficiently?
Describe the concept of federated averaging in federated learning. How does this algorithm work, and what are the challenges associated with its implementation in large-scale systems? Provide examples of how federated averaging can be implemented in Rust.
Analyze the impact of non-IID (non-identically and independently distributed) data on federated learning. How does data heterogeneity affect model convergence and accuracy, and what strategies can be employed to mitigate these challenges in a Rust-based implementation?
Explore the role of privacy-preserving techniques such as differential privacy in federated learning. How can Rust be used to implement differential privacy during the training of LLMs, and what are the trade-offs between privacy and model utility?
Discuss the concept of secure multiparty computation (SMPC) and its application in privacy-preserving machine learning. How can Rust be utilized to implement SMPC in federated learning scenarios, and what are the potential performance and security implications?
Explain the importance of communication efficiency in federated learning. What techniques can be used to reduce communication overhead, and how can Rust's concurrency features be leveraged to optimize communication in a federated learning system?
Describe the challenges of implementing federated learning in resource-constrained environments, such as mobile devices or edge computing. How can Rust's performance advantages be utilized to develop efficient federated learning solutions in these contexts?
Analyze the trade-offs between model accuracy and privacy in the context of federated learning. How can Rust be used to implement techniques that balance these trade-offs, and what are the implications for real-world deployments of privacy-preserving LLMs?
Discuss the role of asynchronous programming in federated learning. How can Rust's asynchronous features be used to manage the complexities of communication and computation in a federated learning system? Provide examples of how async programming can be applied to federated learning in Rust.
Explore the ethical implications of federated learning and privacy-preserving techniques. How do these methods align with ethical principles such as transparency, fairness, and accountability, and how can Rust be used to implement ethical AI systems?
Explain how homomorphic encryption can be used in privacy-preserving federated learning. How does this technique enable computations on encrypted data, and what are the challenges of implementing homomorphic encryption in Rust?
Discuss the potential of combining federated learning with reinforcement learning to develop more robust AI systems. How can Rust be used to implement such hybrid models, and what are the benefits and challenges of this approach?
Analyze the security vulnerabilities associated with federated learning, such as model inversion attacks and data poisoning. How can Rust be used to develop secure federated learning systems that mitigate these risks?
Describe the process of implementing a federated learning system using Rust. What are the key steps involved, and what Rust crates and libraries are most useful for building such a system?
Explore the concept of client heterogeneity in federated learning. How does varying client capability affect model training, and what strategies can be employed to address these differences in a Rust-based implementation?
Discuss the challenges of scaling federated learning systems to large numbers of clients. How can Rust's performance and concurrency features be utilized to develop scalable federated learning solutions?
Explain the role of model aggregation in federated learning. How can Rust be used to implement and optimize model aggregation algorithms, and what are the challenges associated with aggregating models from heterogeneous clients?
Analyze the future directions of federated learning and privacy-preserving techniques. What emerging trends and technologies could enhance these methods, and how can Rust be leveraged to support these advancements?
Discuss the potential of Rust as a language for developing federated learning and privacy-preserving LLMs. How does Rust's focus on safety, concurrency, and performance make it an ideal choice for these applications, and what are the challenges of using Rust in this domain?
By engaging with these comprehensive and in-depth prompts, you will not only expand your technical expertise in implementing these concepts using Rust but also develop a nuanced understanding of the ethical and practical challenges involved.
26.6.2. Hands On Practices
Self-Exercise 26.1: Implementing Federated Averaging in Rust
Objective: To develop and implement a federated averaging algorithm in Rust, focusing on handling non-IID data and optimizing model aggregation.
Tasks:
Research the federated averaging algorithm and understand how it handles model updates from multiple clients in a federated learning system.
Implement the federated averaging algorithm in Rust, ensuring it can aggregate model updates from clients with non-IID data distributions.
Test the implementation using simulated client data with varying distributions, and measure the impact on model convergence and accuracy.
Optimize the implementation to handle large numbers of clients efficiently, using Rust’s concurrency features to manage communication and aggregation.
Deliverables:
A Rust-based implementation of the federated averaging algorithm, complete with source code and documentation.
A detailed report analyzing the performance of the algorithm on non-IID data, including metrics on model convergence and accuracy.
Optimized code that scales to large client numbers, along with an explanation of the concurrency strategies used.
Self-Exercise 26.2: Implementing Differential Privacy in Federated Learning
Objective: To implement differential privacy techniques in a federated learning system using Rust, balancing privacy guarantees with model utility.
Tasks:
Research the principles of differential privacy and how it can be applied to federated learning to protect client data during model training.
Implement differential privacy in Rust, focusing on adding noise to the model updates to ensure privacy while maintaining as much model utility as possible.
Test the privacy-preserving federated learning system with different levels of noise, analyzing the trade-offs between privacy and model accuracy.
Compare the performance of the differential privacy implementation with a baseline federated learning system without privacy guarantees.
Deliverables:
A Rust-based implementation of differential privacy in federated learning, including source code and detailed documentation.
A comprehensive analysis report on the trade-offs between privacy levels and model accuracy, including recommendations for optimal privacy settings.
Comparative results between the privacy-preserving system and the baseline, highlighting the impact of differential privacy on the model.
Self-Exercise 26.3: Developing a Secure Multiparty Computation (SMPC) System in Rust
Objective: To design and implement a secure multiparty computation (SMPC) system in Rust, enabling privacy-preserving computations across multiple parties without exposing individual data.
Tasks:
Research the concepts and protocols behind SMPC, with a focus on how it can be used in federated learning to ensure data privacy.
Implement an SMPC system in Rust that allows multiple clients to jointly compute a model without revealing their individual data.
Test the SMPC system with a simulated federated learning scenario, ensuring that it maintains both privacy and accuracy in model computation.
Optimize the SMPC implementation for performance, focusing on reducing computational overhead and improving efficiency.
Deliverables:
A Rust-based SMPC system implementation, complete with source code, protocols, and comprehensive documentation.
A test report demonstrating the system’s ability to maintain privacy during federated learning, along with performance metrics.
Optimized code with an analysis of the performance improvements achieved, including potential use cases for the SMPC system.
Self-Exercise 26.4: Optimizing Communication Efficiency in Federated Learning
Objective: To optimize the communication efficiency in a Rust-based federated learning system, focusing on reducing communication overhead and latency.
Tasks:
Research communication protocols and techniques that can be used to minimize communication overhead in federated learning.
Implement these communication optimization techniques in a Rust-based federated learning system, focusing on reducing the amount of data transferred between clients and the central server.
Test the communication efficiency of the system under different network conditions, analyzing the impact of the optimizations on model training time and convergence.
Document the best practices for optimizing communication in federated learning systems, with a focus on using Rust’s concurrency and asynchronous features.
Deliverables:
A Rust-based federated learning system with optimized communication protocols, including source code and detailed implementation notes.
A performance report analyzing the impact of communication optimizations on training time and model convergence under various conditions.
A best practices guide for communication optimization in federated learning, with examples and recommendations for future implementations.
Self-Exercise 26.5: Implementing Homomorphic Encryption in Federated Learning
Objective: To implement homomorphic encryption in a federated learning system using Rust, enabling secure computation on encrypted data.
Tasks:
Research homomorphic encryption and understand how it can be used to perform computations on encrypted data in the context of federated learning.
Implement a Rust-based federated learning system that uses homomorphic encryption to protect client data during model training.
Test the system by training a model on encrypted data, measuring the impact of encryption on model accuracy and computational efficiency.
Compare the performance of the homomorphic encryption system with a baseline federated learning system without encryption, focusing on the trade-offs between security and efficiency.
Deliverables:
A Rust-based implementation of homomorphic encryption in federated learning, including source code and detailed documentation.
A performance analysis report comparing the encrypted federated learning system with a baseline, highlighting the trade-offs in security and efficiency.
Recommendations for optimizing homomorphic encryption in federated learning, with a focus on maintaining a balance between data security and computational performance.
Comments