Chapter 25
Bias, Fairness, and Ethics in LLMs
"Fairness is not an optional add-on in AI systems; it’s a fundamental requirement that must be integrated into the fabric of these technologies from the start." — Timnit Gebru
Chapter 25 of LMVR provides an in-depth exploration of the critical issues of bias, fairness, and ethics in large language models (LLMs) through the implementation of Rust. The chapter addresses the detection and mitigation of bias, emphasizing the importance of fairness in AI systems, and explores the ethical considerations that must guide LLM development and deployment. It also covers the regulatory and legal frameworks governing AI, discussing how Rust-based tools can help ensure compliance with these standards. Finally, the chapter looks forward to emerging trends and future directions, highlighting the ongoing need for innovation and interdisciplinary collaboration to create AI systems that are both powerful and ethically sound.
25.1. Introduction to Bias, Fairness, and Ethics in LLMs
As large language models (LLMs) become increasingly embedded in real-world applications, ensuring that these systems operate fairly and ethically has become a top priority. Bias, fairness, and ethics are core challenges within artificial intelligence, particularly because LLMs can inadvertently reflect, and even amplify, the biases present in their training data. Bias in LLMs can lead to unjust, inaccurate, or otherwise harmful outcomes, especially when deployed in high-stakes sectors such as healthcare, finance, and law. Addressing bias and achieving fairness is thus essential not only for creating accurate models but also for building systems that align with broader societal values of inclusivity, transparency, and accountability. Ethics in AI goes beyond technical correctness; it encompasses the need to create models that respect user rights, avoid reinforcing harmful stereotypes, and contribute to a society where technology is beneficial and equitable for all.
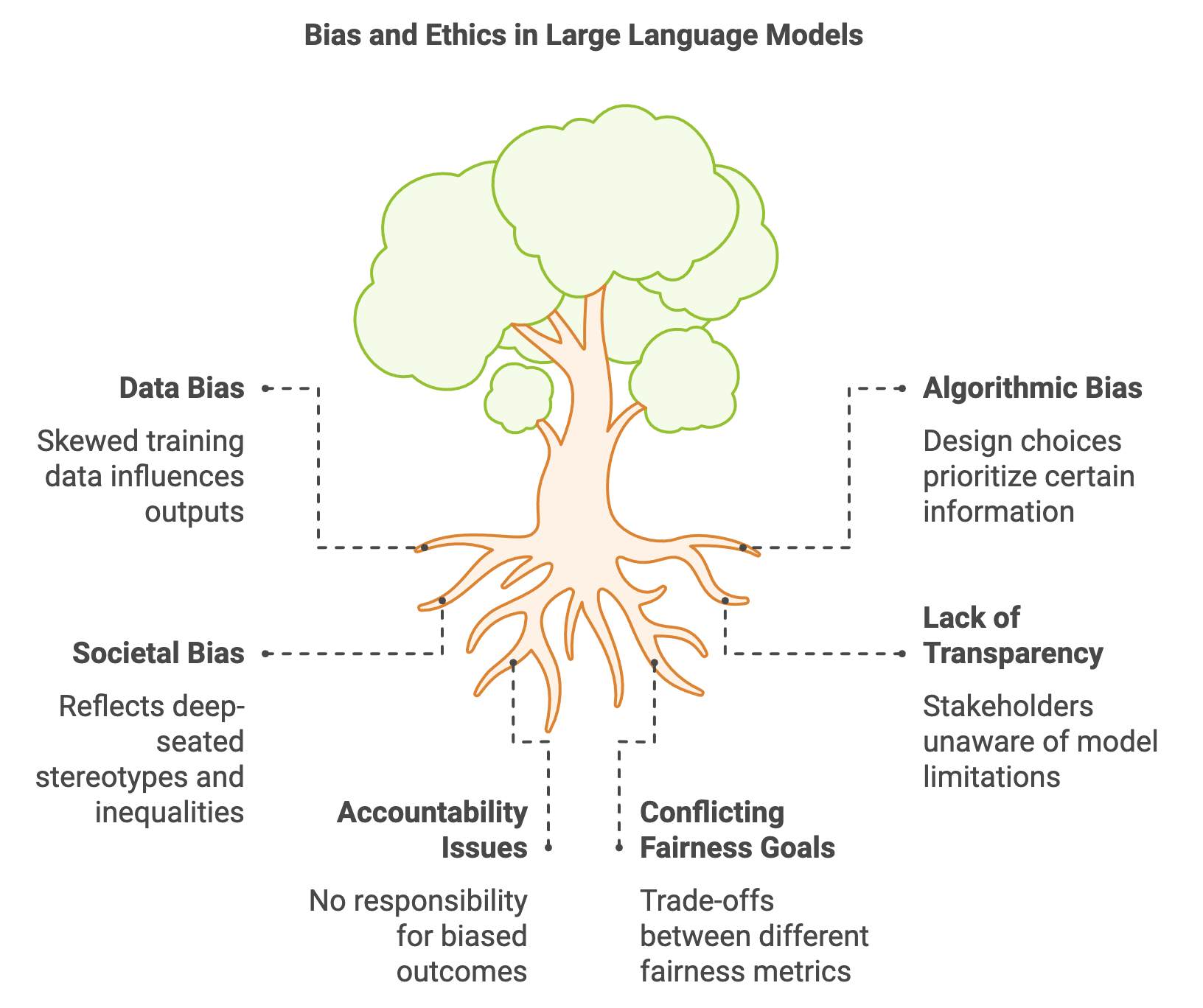
Figure 1: Key elements of bias and ethics in LLMs.
Understanding bias in LLMs requires examining its origins and manifestations. Bias in LLMs can be categorized into three main types: data bias, algorithmic bias, and societal bias. Data bias originates from the datasets used to train models. For instance, if an LLM is trained predominantly on text from certain demographic groups or regions, it may develop responses that are skewed toward the perspectives, language patterns, or cultural norms of those groups. Algorithmic bias, in contrast, can emerge from the design choices and parameters of the model itself, such as tokenization strategies or weighting mechanisms, which can inadvertently prioritize certain types of information. Lastly, societal bias reflects the fact that AI models do not operate in isolation; they are products of human societies and can thus reflect deep-seated stereotypes or inequalities. For example, LLMs used in hiring processes could perpetuate biases present in historical hiring data, leading to discriminatory outcomes. Rust provides a unique platform for addressing these issues, as it allows for efficient and safe experimentation with tools that detect and measure bias, offering developers a controlled environment in which they can evaluate ethical considerations rigorously.
The ethical implications of biased LLM outputs are far-reaching, especially in critical applications. In healthcare, biased models could lead to disparities in treatment recommendations for patients from different demographics, affecting both the quality of care and patient outcomes. In finance, biased algorithms in lending decisions may discriminate against certain groups, potentially violating anti-discrimination laws and exposing financial institutions to regulatory scrutiny. In legal contexts, biased language models might produce outputs that unfairly sway judgment in ways that are misaligned with justice principles. Such examples underscore the need for clear ethical principles, such as transparency, accountability, and inclusivity, to guide the development and deployment of LLMs. Transparency entails ensuring that both the model’s operation and its limitations are understandable to stakeholders. Accountability requires that those deploying AI systems are responsible for the outcomes these systems produce, while inclusivity emphasizes designing models that consider the needs and perspectives of all affected groups.
The concept of fairness in AI is complex, with multiple definitions and perspectives often leading to trade-offs. One common approach to fairness is demographic parity, which requires that a model’s predictions or classifications are equally distributed across different groups. However, in practice, achieving demographic parity may conflict with other fairness goals, such as individual fairness, which focuses on treating similar individuals similarly. Formalizing fairness mathematically often involves balancing these differing fairness metrics, which may involve constraints and optimization functions within model training. Rust can facilitate fairness experimentation by providing tools to set up constrained optimization environments and calculate fairness metrics across demographic groups, allowing developers to test various fairness definitions and evaluate their trade-offs in LLM outputs.
A Rust-based environment offers robust support for developing tools that address bias, fairness, and ethics in LLMs. With Rust’s strong emphasis on performance and safety, developers can implement bias detection algorithms that process large datasets efficiently, ensuring that bias detection can scale with model size. For instance, bias measurement in Rust could involve calculating metrics like the "Fairness Discrepancy Index," which quantifies disparities in model outputs across demographic categories, or developing "Embedding Distance Metrics," which analyze the semantic proximity between words or phrases related to different social groups. In Rust, these calculations can be optimized for large-scale datasets using parallel processing capabilities, thereby enabling rapid and reliable bias assessments. Rust’s type safety and memory management features also reduce the risk of errors, ensuring that the bias detection tools operate as expected even in high-stakes environments.
This pseudo code outlines a framework for detecting bias in LLMs by calculating metrics that quantify fairness and embedding distances across demographic groups. The BiasDetectionFramework class uses a model, dataset, and list of demographic groups to run analyses. The calculate_fairness_discrepancy method generates model outputs for each demographic group, then calculates the Fairness Discrepancy Index by comparing outputs to identify any disparities. The calculate_embedding_distances method computes semantic distances between embeddings for each pair of demographic groups, capturing their relative proximity. By leveraging parallel processing, these tasks run concurrently for efficiency. Helper methods are included for generating model outputs, calculating discrepancies, embeddings, and distances. The main function initializes this framework, runs the calculations, and outputs the results, providing valuable insights into bias and fairness across model predictions.
// Define Bias Detection Framework for LLMs
BiasDetectionFramework:
model: reference to LLM model
dataset: collection of text inputs for bias evaluation
demographics: list of demographic groups for comparison
// Constructor to initialize framework with model, dataset, and demographics
new(model, dataset, demographics):
set self.model to model
set self.dataset to dataset
set self.demographics to demographics
// Method to calculate the Fairness Discrepancy Index across demographic groups
calculate_fairness_discrepancy():
group_outputs = empty dictionary
// Generate model outputs for each demographic group in parallel
for each demographic in demographics (concurrently):
outputs = filter dataset by demographic
model_outputs = generate_model_outputs(model, outputs)
group_outputs[demographic] = model_outputs
// Calculate discrepancies in model outputs between demographic groups
fairness_discrepancy_index = calculate_discrepancy(group_outputs)
return fairness_discrepancy_index
// Method to calculate Embedding Distance Metrics between social groups
calculate_embedding_distances():
distances = empty dictionary
// Calculate semantic distances between pairs of demographic groups in parallel
for each pair of demographics (concurrently):
embedding1 = calculate_embedding(model, demographics[0])
embedding2 = calculate_embedding(model, demographics[1])
distance = calculate_distance(embedding1, embedding2)
distances[(demographics[0], demographics[1])] = distance
return distances
// Helper method to generate model outputs for a filtered dataset
generate_model_outputs(model, dataset):
outputs = empty list
for each item in dataset:
output = model.predict(item)
append output to outputs
return outputs
// Helper method to calculate discrepancy in outputs
calculate_discrepancy(group_outputs):
calculate statistical measures across group_outputs
return computed discrepancy index
// Helper method to calculate semantic embedding for a demographic group
calculate_embedding(model, demographic):
aggregate embeddings for demographic data using model
return aggregated embedding
// Helper method to calculate distance between embeddings
calculate_distance(embedding1, embedding2):
use metric (e.g., cosine similarity) to calculate distance
return computed distance
// Main function to execute bias detection framework
main:
model = initialize LLM model
dataset = load dataset for evaluation
demographics = list of demographic groups (e.g., gender, ethnicity)
// Initialize and run Bias Detection Framework
framework = new BiasDetectionFramework(model, dataset, demographics)
// Calculate Fairness Discrepancy Index
fairness_discrepancy_index = framework.calculate_fairness_discrepancy()
print "Fairness Discrepancy Index:", fairness_discrepancy_index
// Calculate Embedding Distance Metrics
embedding_distances = framework.calculate_embedding_distances()
print "Embedding Distance Metrics:", embedding_distances
In addition to bias detection, Rust can be used to implement tools that measure fairness and other ethical metrics. For example, Rust can support the development of frameworks that apply counterfactual fairness tests. These tests examine whether an LLM’s outputs would differ if sensitive attributes, such as gender or race, were hypothetically changed. Such tests involve generating counterfactual inputs and evaluating the model’s responses, with a fair model ideally showing little to no change in outputs. Rust’s efficient handling of data processing pipelines allows for the implementation of such counterfactual frameworks in ways that remain scalable and responsive. Furthermore, by integrating these techniques into a Rust-based workflow, developers can create an automated pipeline for fairness assessment, making it easier to test LLMs regularly and identify fairness-related concerns before deploying them in production environments.
Real-world case studies underscore the importance of addressing bias and fairness in LLMs. One prominent example is the case of a major social media platform that deployed a content moderation model which exhibited a strong bias against minority languages, leading to a disproportionate number of false positives for content in those languages. By retrospectively analyzing this model through interpretability and fairness assessment techniques, the development team was able to identify the training data imbalance as a root cause and subsequently improved the dataset's diversity. Using a Rust-based approach, this type of post-mortem analysis could be made efficient and repeatable. A Rust tool could process large volumes of multilingual data to identify biased patterns systematically, enabling proactive steps to enhance fairness. Another example is in the financial industry, where an AI-driven loan recommendation system was found to under-recommend loans to certain minority applicants. The organization responded by implementing fairness metrics and re-weighting training data, adjusting the model’s outputs to meet fairness standards. Rust can play a role in developing similar re-weighting tools that automatically adjust training datasets and model parameters to improve fairness outcomes.
The latest trends in AI ethics research highlight the movement toward more granular, context-sensitive fairness evaluations, and Rust is well-suited to facilitate these advancements. For instance, researchers are now developing fairness metrics that account for intersectional attributes, such as race and gender combined, to capture nuanced biases that single-attribute fairness metrics may miss. Rust can support the development of these advanced metrics by managing the complex, multi-dimensional data structures required for intersectional analysis. Additionally, Rust’s thriving ecosystem of libraries and tools enables integration with statistical analysis frameworks, allowing developers to build sophisticated, data-driven approaches to measuring and improving fairness.
In summary, addressing bias, fairness, and ethics in LLMs is both a technical and a societal necessity, as these models become increasingly central to applications that impact individuals and communities. Rust provides a powerful environment for building tools that can detect, measure, and mitigate bias in LLMs, leveraging its performance and reliability to handle complex fairness calculations at scale. By using Rust to develop tools that assess and enhance fairness, developers can create AI systems that adhere to ethical standards, comply with regulations, and gain the trust of diverse stakeholders. In future chapters, we will delve deeper into specific techniques for measuring bias, applying fairness metrics, and implementing ethical frameworks in Rust, laying the foundation for creating LLMs that are not only performant but also aligned with societal values of equity and responsibility.
25.2. Detecting Bias in Large Language Models
Detecting bias in large language models (LLMs) is a critical step in developing ethical and fair AI systems, as these models play an increasingly influential role in fields ranging from finance to healthcare. Bias detection is challenging and involves both qualitative and quantitative techniques to uncover hidden biases in model outputs. Bias in LLMs can stem from various sources, including biased training datasets, model architectures that inadvertently favor certain inputs, or historical and systemic inequalities embedded in language data. This section will explore techniques for detecting bias in LLMs, covering both the mathematical metrics that quantify bias and the practical implementations of these techniques in Rust. Rust, with its performance optimization and memory safety features, is an excellent choice for building efficient and reliable bias detection tools that operate at scale.
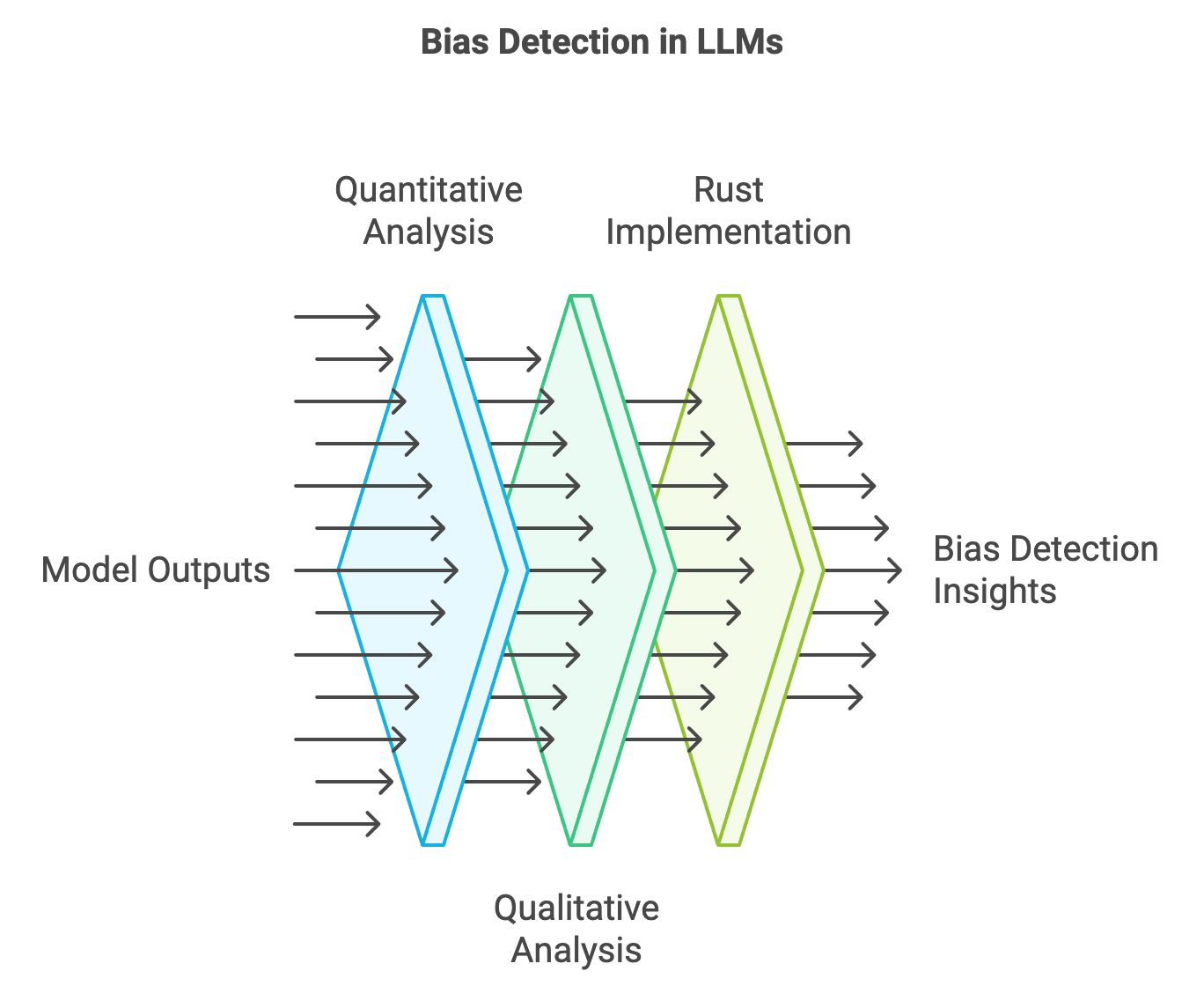
Figure 2: Common process for bias detection using Rust.
Detecting bias in natural language processing (NLP) is inherently complex because language often carries subtle, context-dependent biases that are not easily quantified. Traditional metrics for bias detection—such as demographic parity, equalized odds, and disparate impact—can provide insights into how an LLM’s predictions vary across demographic groups. Demographic parity, for instance, assesses whether a model’s positive predictions are evenly distributed across different demographic groups, while equalized odds measure whether the model’s accuracy remains consistent across these groups. Mathematically, demographic parity can be expressed as a probability condition: $P(\hat{Y} = 1 | D = d) = P(\hat{Y} = 1)$ for all demographic groups $d$, where $\hat{Y}$ represents the predicted outcome and $D$ is the demographic attribute. Rust’s data handling capabilities enable the computation of these metrics with high precision and efficiency, supporting large-scale analysis of demographic parity across different model outputs.
The quantitative techniques for bias detection in Rust can be implemented by processing model outputs and analyzing their correlations with demographic data. For example, a Rust-based tool might analyze a sentiment analysis model’s outputs across different gendered terms to check for gender bias. Suppose the model consistently produces more positive sentiments for phrases associated with male-coded language and more negative sentiments for phrases associated with female-coded language. In this case, the tool would detect a gender disparity, signaling a need for further investigation. By implementing such metrics within a Rust framework, developers can create automated bias detection pipelines that operate across large datasets, identifying subtle but impactful biases in a systematic way. Rust’s speed and type safety make it ideal for handling these computations efficiently, ensuring that bias metrics are calculated accurately and consistently, even for large datasets.
In addition to quantitative methods, qualitative approaches play an essential role in detecting bias in LLMs, especially in identifying context-dependent biases. Qualitative techniques often involve generating sample outputs from the model and analyzing these outputs for language patterns or associations that may reflect biases. For instance, an LLM used in customer service could be evaluated by generating responses to different demographic-specific queries, observing whether certain demographics receive disproportionately positive or negative tones. By analyzing the word embeddings or attention weights associated with these responses, developers can gain insights into how the model’s structure may be amplifying certain biases. Rust supports such qualitative analysis by allowing developers to experiment with token-level manipulation and embedding visualization tools. Using libraries like plotters for visualization, Rust-based tools can graphically display embedding relationships, helping developers interpret language associations and detect potential bias in the model’s internal representations.
Implementing bias detection techniques in Rust also involves setting up custom tests tailored to specific use cases. For instance, if a model is used in sentiment analysis, bias detection tests might focus on evaluating how sentiment scores vary for language patterns associated with different racial or ethnic groups. In Rust, developers can create custom testing frameworks that measure sentiment scores across thousands of examples, automatically flagging any significant discrepancies. Another common use case is language translation, where biases can appear if certain demographic identifiers are translated with stereotypical or skewed terms. A Rust-based test for this application might generate translations for phrases containing demographic identifiers and compare the target translations to a list of non-biased alternatives, flagging any inconsistencies for further review.
A practical approach to building a bias detection tool in Rust could involve defining a function that calculates bias metrics across different demographic groups. For instance, a function that calculates demographic parity might take two arguments—a model’s predictions and the demographic attributes associated with each input. Using Rust’s HashMap to store predictions and attributes, the function could efficiently compute bias metrics by grouping predictions by demographic category and comparing the outcomes. Additionally, implementing parallel processing with Rust’s rayon library could speed up the bias detection process, allowing the function to analyze predictions across large datasets in a fraction of the time it would take using a less optimized language.
The Rust code below demonstrates a bias detection framework designed to analyze and visualize sentiment disparities across demographic groups in large language model (LLM) predictions. It includes quantitative analysis through demographic parity, which calculates average sentiment scores for different demographics, and qualitative analysis by flagging specific language patterns that might indicate bias. The framework leverages Rust’s HashMap for efficient data grouping and the plotters crate for visualizing the sentiment distribution across demographics. Example predictions and demographic attributes are provided to illustrate how the code performs both types of analysis and outputs a visualization image for further inspection.
[dependencies]
plotters = "0.3.7"
rayon = "1.10.0"
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
use serde::{Deserialize, Serialize};
use plotters::prelude::*;
use std::collections::HashMap;
// Define a struct for model predictions associated with demographic attributes
#[derive(Debug, Deserialize, Serialize)]
struct Prediction {
text: String,
sentiment_score: f64,
demographic: String,
}
// Function to calculate demographic parity by comparing average sentiment scores
fn calculate_demographic_parity(predictions: &Vec<Prediction>) -> HashMap<String, f64> {
let mut demographic_scores: HashMap<String, Vec<f64>> = HashMap::new();
// Group sentiment scores by demographic
for pred in predictions {
demographic_scores.entry(pred.demographic.clone())
.or_insert_with(Vec::new)
.push(pred.sentiment_score);
}
// Calculate average sentiment for each demographic
demographic_scores.into_iter()
.map(|(demographic, scores)| {
let avg_score = scores.iter().sum::<f64>() / scores.len() as f64;
(demographic, avg_score)
})
.collect()
}
// Function to visualize embedding distances or sentiment distributions
fn visualize_sentiment_distribution(demographic_averages: &HashMap<String, f64>, filename: &str) -> Result<(), Box<dyn std::error::Error>> {
let root = BitMapBackend::new(filename, (640, 480)).into_drawing_area();
root.fill(&WHITE)?;
let max_value = demographic_averages.values().cloned().fold(0./0., f64::max);
let min_value = demographic_averages.values().cloned().fold(0./0., f64::min);
let mut chart = ChartBuilder::on(&root)
.caption("Sentiment Distribution Across Demographics", ("sans-serif", 20))
.x_label_area_size(30)
.y_label_area_size(40)
.build_cartesian_2d(
0..demographic_averages.len(),
min_value..max_value,
)?;
chart.configure_mesh().draw()?;
for (idx, (demographic, avg_score)) in demographic_averages.iter().enumerate() {
chart.draw_series(
std::iter::once(Circle::new((idx, *avg_score), 5, RED.filled())),
)?
.label(demographic)
.legend(|(x, y)| Circle::new((x, y), 5, RED.filled()));
}
chart.configure_series_labels().position(SeriesLabelPosition::UpperLeft).draw()?;
Ok(())
}
// Custom test for qualitative bias detection in sentiment responses
fn evaluate_qualitative_bias(predictions: &Vec<Prediction>, keywords: &Vec<&str>) -> HashMap<String, bool> {
let mut bias_flags: HashMap<String, bool> = HashMap::new();
for keyword in keywords {
let contains_bias = predictions.iter()
.any(|pred| pred.text.contains(keyword) && pred.sentiment_score < 0.5); // Example threshold
bias_flags.insert(keyword.to_string(), contains_bias);
}
bias_flags
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Load predictions (example data)
let predictions = vec![
Prediction { text: "Positive response".to_string(), sentiment_score: 0.8, demographic: "GroupA".to_string() },
Prediction { text: "Neutral response".to_string(), sentiment_score: 0.5, demographic: "GroupB".to_string() },
Prediction { text: "Negative response".to_string(), sentiment_score: 0.3, demographic: "GroupA".to_string() },
Prediction { text: "Slightly negative response".to_string(), sentiment_score: 0.4, demographic: "GroupB".to_string() },
];
// Calculate demographic parity
let demographic_averages = calculate_demographic_parity(&predictions);
println!("Demographic Parity Results: {:?}", demographic_averages);
// Visualize the sentiment distribution
visualize_sentiment_distribution(&demographic_averages, "sentiment_distribution.png")?;
// Define keywords to check for qualitative biases
let keywords = vec!["Positive", "Negative"];
let qualitative_bias_results = evaluate_qualitative_bias(&predictions, &keywords);
println!("Qualitative Bias Detection Results: {:?}", qualitative_bias_results);
Ok(())
}
The code is structured into three main components: (1) a quantitative function calculate_demographic_parity that groups sentiment scores by demographics and calculates average sentiment for each group to assess fairness; (2) a visualization function visualize_sentiment_distribution that uses plotters to create a scatter plot showing sentiment distribution across demographics; and (3) a qualitative function evaluate_qualitative_bias that checks for predefined keywords in model responses to identify potential negative associations with specific terms. By combining these approaches, the framework provides a comprehensive view of potential biases in LLM predictions, highlighting both numerical discrepancies and language patterns that might indicate bias. This enables developers to perform robust and interpretable bias analysis in Rust, with visualization support to facilitate a more intuitive understanding of sentiment distribution.
One industry case study that highlights the importance of bias detection is the use of LLMs in recruitment software. A major recruitment platform developed an AI model to screen candidates based on their resumes. However, a post-deployment analysis revealed that the model disproportionately favored certain demographic groups, reflecting biases present in historical hiring data. Using demographic parity and disparate impact metrics, the company identified these biases and modified the training process to include a more diverse dataset. In Rust, developers in similar scenarios could build bias detection tools to identify biases in the early stages of deployment, minimizing the risk of biased outcomes. For example, a Rust-based recruitment model could integrate demographic parity checks directly into the inference pipeline, alerting developers whenever disparities arise, thus enabling proactive bias mitigation.
Recent trends in AI ethics research suggest a shift toward continuous bias monitoring, where bias detection is treated as an ongoing process rather than a one-time analysis. This approach involves re-evaluating bias metrics as new data is introduced to the model, ensuring that bias detection evolves alongside the model’s training. Rust is well-suited for implementing continuous monitoring systems, thanks to its memory efficiency and real-time processing capabilities. By integrating periodic bias assessments within a Rust-based LLM pipeline, developers can automate bias tracking across model updates, preventing biased outputs from accumulating over time. This approach not only ensures that models remain fair and unbiased but also strengthens trust with stakeholders, as the model’s ethical standards are consistently maintained.
In conclusion, detecting bias in LLMs is a multifaceted process that combines quantitative metrics, qualitative analysis, and context-specific testing. Rust’s performance and memory safety make it an ideal language for building bias detection tools that can operate efficiently on large datasets and provide accurate, reliable assessments of fairness and bias in LLM outputs. By leveraging Rust for bias detection, developers can create robust frameworks that quantify and analyze bias across demographic groups, enabling AI systems to operate more ethically and responsibly. This section has introduced the fundamental and conceptual ideas underlying bias detection, as well as practical methods for implementing these techniques in Rust, laying the groundwork for the development of fairer, more transparent LLMs in various real-world applications.
25.3. Mitigating Bias and Enhancing Fairness in LLMs
As large language models (LLMs) become central to applications across diverse fields, mitigating bias and enhancing fairness have become essential goals in AI development. Bias mitigation strategies aim to address the inherent biases present in data and model architectures, ensuring that LLMs perform equitably across diverse demographic groups. Fairness, in this context, involves creating systems that offer consistent outcomes for users regardless of gender, race, socioeconomic background, or other sensitive attributes. There are three primary approaches to bias mitigation in LLMs: data preprocessing, algorithmic adjustments, and post-processing methods. Data preprocessing involves curating and rebalancing training data to reduce bias in inputs. Algorithmic adjustments modify the learning process itself, embedding fairness constraints within model training, while post-processing methods adjust outputs to mitigate potential biases. This section examines each of these techniques in detail, exploring their applications, limitations, and practical implementations in Rust. By leveraging Rust’s computational performance and safety, developers can create robust bias mitigation tools that ensure fairness without sacrificing model efficiency.
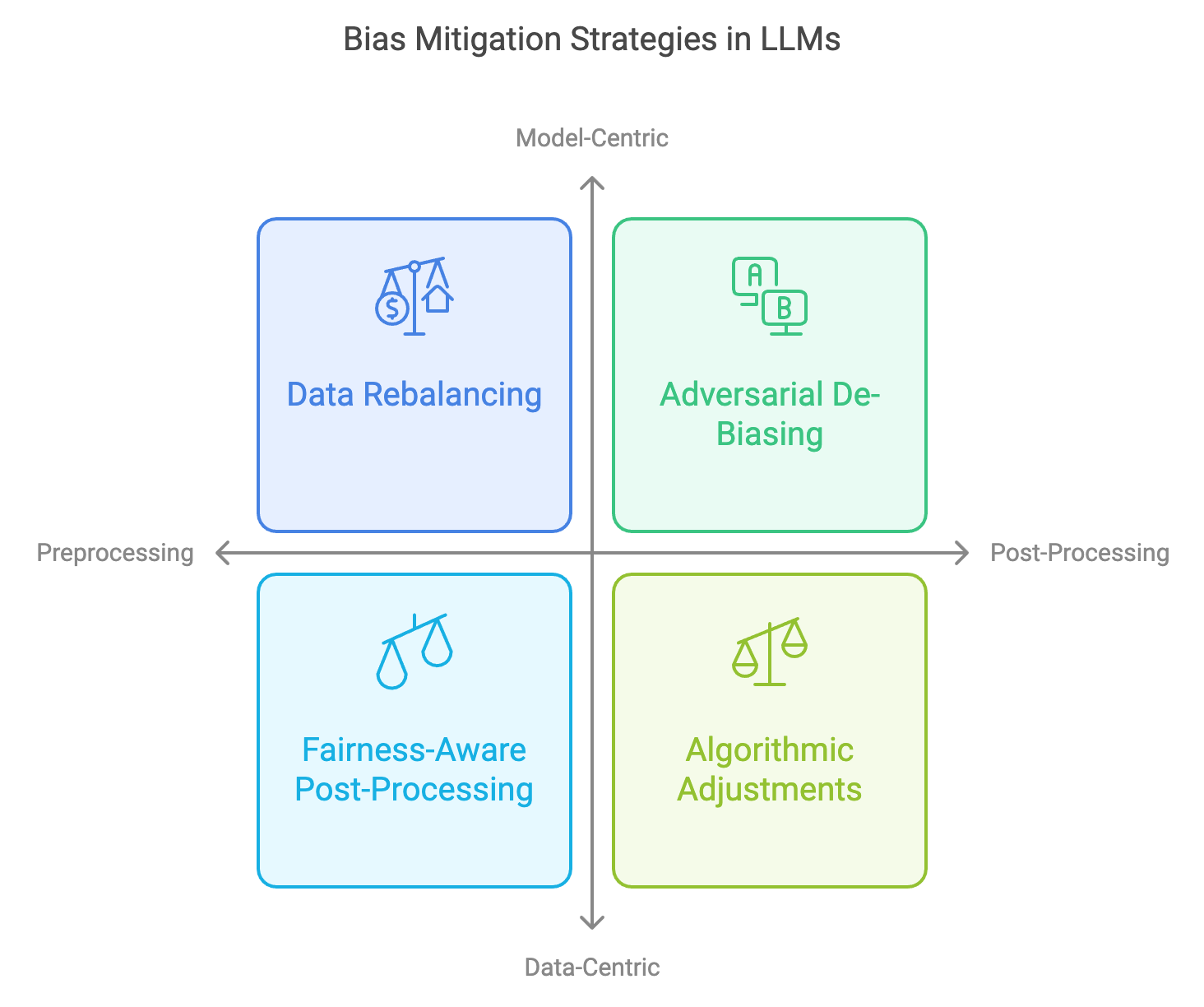
Figure 3: Bias mitigation strategy for LLMs.
Data preprocessing techniques form the foundation of many bias mitigation efforts. Biases in LLMs often stem from training datasets that over-represent or under-represent specific demographic groups. For instance, if a language model is primarily trained on English text from the Global North, it may struggle to handle or fairly represent dialects, expressions, or perspectives from other regions. In Rust, data rebalancing methods can be implemented by analyzing dataset distributions and re-weighting examples from underrepresented groups to ensure more balanced learning. Consider a dataset where instances containing female pronouns are underrepresented compared to male pronouns. In Rust, developers could write a function that adjusts sampling weights, upsampling the minority group to achieve demographic parity. Mathematically, this can be achieved by increasing the probability $P(x)$ of selecting examples from underrepresented classes, where $x$ denotes the input data for each class. With Rust’s parallel processing capabilities, these re-weighting operations can be conducted efficiently, even on large datasets, ensuring that preprocessing does not become a bottleneck in model training.
Beyond preprocessing, algorithmic adjustments introduce fairness constraints directly into the LLM training process. These adjustments are particularly powerful because they embed fairness considerations within the model itself, producing outputs that respect defined fairness constraints. A common approach is to incorporate demographic parity or equalized odds as constraints during training, modifying the optimization function to balance accuracy and fairness. For example, demographic parity requires that the probability of a favorable outcome (e.g., a positive sentiment prediction) remains consistent across demographic groups. In Rust, such constraints can be incorporated into custom training loops, adjusting model parameters to minimize both prediction error and fairness discrepancies. By using Rust’s fine-grained control over memory and computation, developers can create optimized, custom loss functions that enforce these constraints without significantly impacting model performance.
Another technique within algorithmic adjustments is adversarial de-biasing, where an additional adversarial component is introduced during training to minimize bias. In this approach, the primary LLM is trained to maximize predictive accuracy, while a secondary adversarial model is trained to detect and eliminate any demographic biases in the outputs. The primary model thus learns to produce outputs that the adversarial model cannot easily classify by demographic group, minimizing bias. In Rust, adversarial de-biasing can be implemented by running two training processes in parallel, using Rust’s concurrency features to handle both the main model and the adversarial component efficiently. The adversarial model’s objective function is to increase the difference between groups, while the primary model’s objective is to decrease it, thus leading to fairer outcomes.
Post-processing methods offer another layer of bias mitigation, particularly useful when adjusting pre-trained LLMs. Post-processing techniques modify the outputs rather than the model or data, making them a flexible option for production environments where re-training is not feasible. One such technique is fairness-aware post-processing, where model outputs are adjusted to meet fairness criteria like equal opportunity or disparate impact. For instance, suppose an LLM used for loan recommendations produces a higher rate of positive outcomes for certain demographics. A post-processing function could apply a statistical adjustment to equalize these rates across groups. Rust enables the creation of these post-processing adjustments through its high-performance data manipulation capabilities. Developers can implement functions that systematically monitor output distributions and apply fairness adjustments as necessary, ensuring that results align with the desired fairness metrics. Rust’s safety and concurrency model allow this process to operate at scale, adjusting outputs in real time for high-throughput applications like recommendation engines.
Mitigating bias in LLMs often involves trade-offs, as prioritizing fairness can sometimes impact other performance metrics like accuracy or robustness. In practical terms, Rust-based bias mitigation tools can be configured to monitor these trade-offs, allowing developers to experiment with various fairness parameters and document their effects on overall model performance. For example, a Rust framework could implement a multi-objective optimization approach that balances accuracy and fairness as dual objectives, allowing developers to configure fairness thresholds and analyze how they impact prediction error. This flexibility enables organizations to customize fairness configurations based on specific application requirements, whether the goal is to minimize demographic disparities or ensure absolute demographic parity. Rust’s speed and type safety make it ideal for testing these configurations rapidly, allowing developers to iterate over multiple fairness definitions to find an optimal balance.
This pseudo code illustrates a bias mitigation framework that incorporates algorithmic adjustments to apply fairness constraints directly in the training process of large language models (LLMs). The approach includes defining fairness-aware constraints (e.g., demographic parity), implementing adversarial de-biasing with a secondary model, and post-processing model outputs to meet fairness criteria. By leveraging Rust’s high-performance and concurrency features, this framework allows for efficient training adjustments and fairness monitoring across large datasets, ensuring real-time output adjustments and enabling trade-off analysis between fairness and accuracy.
// Main Bias Mitigation Framework for Fairness in LLMs
BiasMitigationFramework:
primary_model: LLM model
adversarial_model: model trained to detect demographic biases
data: training dataset
demographics: list of demographic groups associated with data
fairness_threshold: threshold for acceptable fairness disparity
// Initialize framework with models, data, and fairness criteria
new(primary_model, adversarial_model, data, demographics, fairness_threshold):
set self.primary_model to primary_model
set self.adversarial_model to adversarial_model
set self.data to data
set self.demographics to demographics
set self.fairness_threshold to fairness_threshold
// Method for training primary model with fairness constraints
train_with_fairness_constraints():
for each epoch in training loop:
predictions = primary_model.predict(data)
// Calculate demographic parity as a fairness constraint
fairness_discrepancy = calculate_demographic_parity(predictions, demographics)
// Update primary model parameters to minimize both error and fairness discrepancy
primary_model.update_parameters(predictions, data.labels, fairness_discrepancy)
if fairness_discrepancy < fairness_threshold:
break
// Method for adversarial de-biasing
adversarial_debiasing():
for each epoch in training loop (concurrently for both models):
// Train primary model on prediction task
primary_model.train(data, labels)
// Train adversarial model to detect demographic biases in primary model’s output
demographic_predictions = adversarial_model.predict(data)
adversarial_loss = calculate_demographic_disparity(demographic_predictions, demographics)
adversarial_model.update_parameters(demographic_predictions, demographics, -adversarial_loss)
// Adjust primary model to minimize adversarial influence
primary_model.adjust_for_adversarial(adversarial_loss)
// Post-processing function to adjust model outputs for fairness
fairness_post_processing(predictions):
group_averages = calculate_group_means(predictions, demographics)
// Adjust predictions to meet demographic parity
for each prediction in predictions:
demographic_group = get_demographic(prediction)
adjust prediction to match group_averages[demographic_group]
return adjusted predictions
// Method to calculate trade-offs between accuracy and fairness
analyze_tradeoffs():
accuracy_results = []
fairness_results = []
for each fairness_threshold level:
train primary_model with threshold
accuracy = primary_model.evaluate_accuracy(data)
fairness_discrepancy = calculate_demographic_parity(primary_model.predict(data), demographics)
// Record accuracy and fairness results
append accuracy to accuracy_results
append fairness_discrepancy to fairness_results
return accuracy_results, fairness_results
// Function to calculate demographic parity in predictions
calculate_demographic_parity(predictions, demographics):
group_totals = empty dictionary
group_counts = empty dictionary
for each prediction and its demographic in predictions and demographics:
add prediction to group_totals[demographic]
increment group_counts[demographic]
average_by_group = calculate_average(group_totals, group_counts)
return calculate_disparity(average_by_group)
// Main execution to set up and run the bias mitigation framework
main:
primary_model = initialize primary LLM model
adversarial_model = initialize adversarial model
data, demographics = load training data with demographics
fairness_threshold = set acceptable fairness level
framework = new BiasMitigationFramework(primary_model, adversarial_model, data, demographics, fairness_threshold)
// Train primary model with fairness constraints
framework.train_with_fairness_constraints()
// Apply adversarial de-biasing technique
framework.adversarial_debiasing()
// Run post-processing on predictions for fairness
predictions = primary_model.predict(data)
adjusted_predictions = framework.fairness_post_processing(predictions)
// Analyze trade-offs between fairness and accuracy
accuracy, fairness_discrepancies = framework.analyze_tradeoffs()
print "Accuracy vs. Fairness Results:", accuracy, fairness_discrepancies
This pseudo code defines a multi-step bias mitigation framework in the context of LLM training. The BiasMitigationFramework class initializes with a primary model, an adversarial model, and fairness criteria, and includes methods for applying fairness constraints during training. The train_with_fairness_constraints method modifies the optimization process by calculating and minimizing demographic parity discrepancies, ensuring that favorable outcomes are more evenly distributed across demographics. The adversarial_debiasing method runs a parallel process where the adversarial model learns to detect biases while the primary model minimizes them. For post-processing, the fairness_post_processing method adjusts predictions to enforce fairness metrics. Lastly, the analyze_tradeoffs method evaluates the balance between accuracy and fairness across different thresholds, helping developers explore optimal configurations for their applications. This framework enables a comprehensive approach to bias mitigation in LLMs, leveraging Rust’s capabilities for efficient and safe concurrency and data manipulation.
An industry case study that illustrates the value of bias mitigation techniques is the use of LLMs in automated recruitment. A technology company using LLMs for resume screening faced scrutiny when its model showed a preference for certain demographic groups, partly due to biased historical data. By incorporating demographic parity constraints and adversarial de-biasing during model training, the company was able to reduce these biases significantly. Rust-based implementations of similar fairness constraints could enable companies to build and deploy recruitment models that consistently meet demographic parity, ensuring compliance with anti-discrimination laws. Furthermore, Rust’s stability allows for rigorous testing of these models, verifying that fairness constraints hold under different data conditions and update cycles.
A recent trend in AI fairness research emphasizes the need for continuous bias mitigation, treating it as an ongoing process rather than a one-time adjustment. This perspective is particularly relevant in contexts where LLMs are continuously updated or fine-tuned with new data, as bias can re-emerge over time. Rust-based tools can facilitate this approach by automating fairness checks at regular intervals, monitoring model outputs for demographic disparities, and re-applying mitigation techniques when necessary. For instance, a Rust-based fairness monitoring tool could calculate bias metrics after each update, triggering re-training or post-processing adjustments whenever a fairness threshold is breached. This approach aligns with Rust’s strengths in efficient, real-time processing, ensuring that bias mitigation operates seamlessly as part of the model lifecycle.
In conclusion, mitigating bias and enhancing fairness in LLMs is a complex but achievable goal, requiring a combination of data preprocessing, algorithmic adjustments, and post-processing techniques. Rust’s performance, safety, and concurrency capabilities make it an ideal environment for implementing these techniques at scale, supporting organizations in developing ethical and equitable AI systems. By incorporating these bias mitigation methods into their workflows, developers can ensure that LLMs are not only accurate but also fair and aligned with societal values. This section has provided a foundation for understanding and implementing bias mitigation in Rust, covering both theoretical concepts and practical applications, thereby enabling the creation of LLMs that perform equitably across diverse user groups.
25.4. Ethical Considerations in LLM Development and Deployment
The development and deployment of large language models (LLMs) require careful adherence to ethical principles to ensure that these powerful systems align with societal values and norms. Ethical principles such as privacy, non-discrimination, and accountability are crucial in shaping LLMs that respect user rights and mitigate harm. Respect for privacy, for example, involves implementing techniques to prevent the model from inadvertently disclosing sensitive or personal information. Non-discrimination requires that LLMs operate fairly across demographic groups, avoiding any form of bias that may reinforce existing societal inequalities. Accountability ensures that the creators and deployers of LLMs take responsibility for the systems’ outputs, especially in high-stakes environments such as healthcare, finance, and education. Beyond these principles, ethical guidelines and frameworks have emerged to guide LLM development, providing a foundation for evaluating the model’s behavior and ensuring alignment with accepted ethical standards.
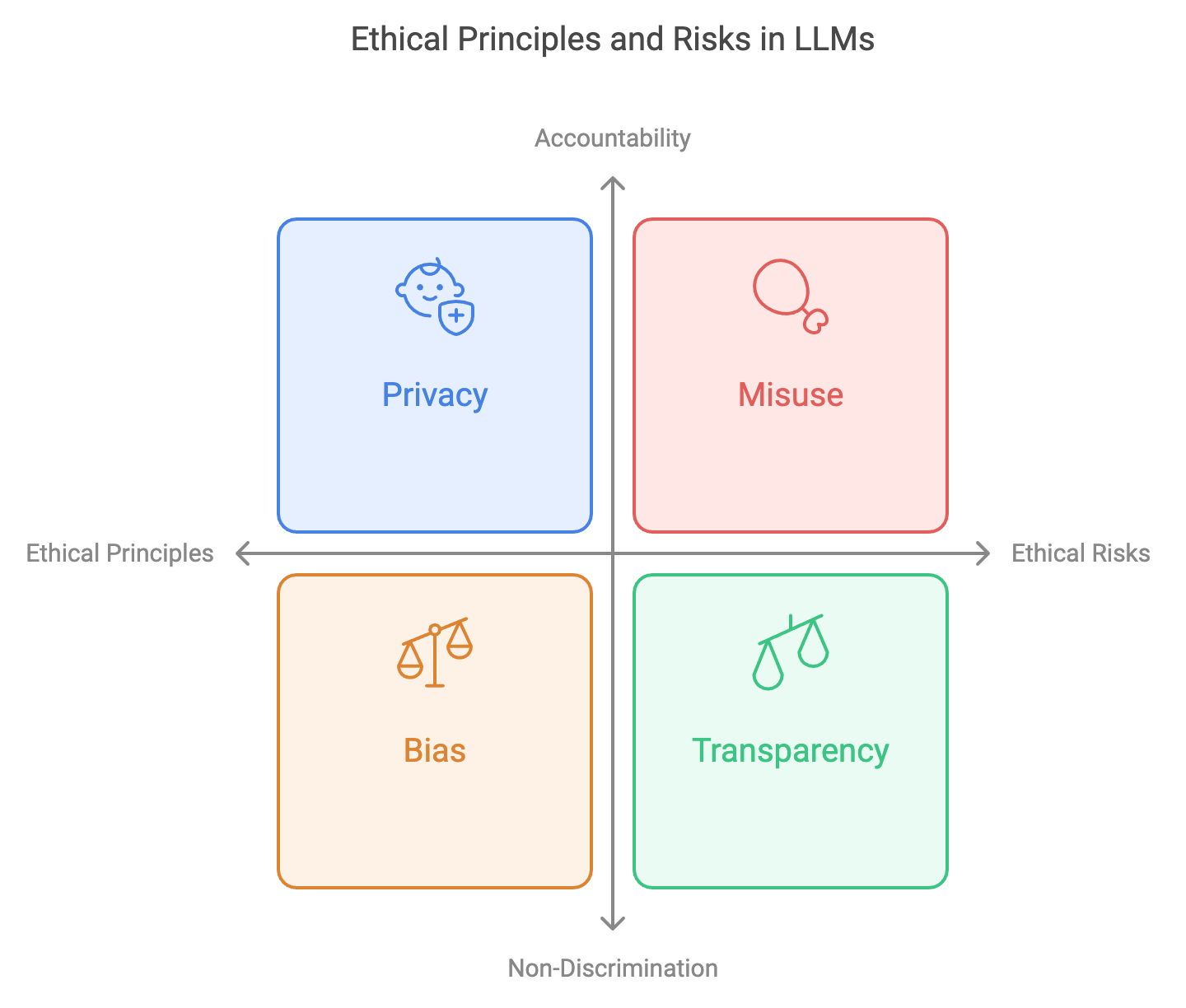
Figure 4: Ethical strategy for LLMs.
One of the key ethical risks in LLMs is misuse, where the model is deployed in a manner that causes harm or spreads misinformation. Misuse is particularly dangerous because LLMs can generate highly realistic outputs that may appear authoritative, leading to unintended consequences if users are misled. Additionally, LLMs can inadvertently reinforce societal inequalities by replicating biases present in the training data. For instance, if the data contains subtle stereotypes, the model may echo or even amplify these biases in its responses. To address these risks, Rust-based tools can be used to evaluate model outputs, detecting patterns that may indicate harmful biases or the potential for misuse. Another critical ethical risk is the erosion of user privacy; LLMs trained on large datasets may inadvertently reveal personal information embedded within the data. Privacy-preserving techniques, such as differential privacy and data anonymization, can be implemented in Rust to mitigate this risk by ensuring that the model’s outputs do not expose sensitive information.
Ethical governance in AI emphasizes transparency, explainability, and stakeholder engagement. Transparency involves making both the model’s design and its limitations accessible to end-users, which helps build trust and fosters accountability. Explainability, closely related to transparency, requires that users and stakeholders understand why the model generates specific outputs. For example, in financial or medical contexts, it is essential to explain the model’s reasoning to avoid decisions that appear arbitrary or unsupported. Rust-based tools for explainability can analyze model outputs in real time, offering insights into which features or tokens contributed most significantly to a given response. Stakeholder engagement, meanwhile, is essential to ensuring that the voices of those affected by the model are heard, particularly in cases where vulnerable populations might be impacted by AI-driven decisions. Stakeholders, including policymakers, user advocates, and domain experts, can provide valuable feedback during the development phase, helping identify potential ethical issues early and facilitating smoother deployment.
Ethical dilemmas often emerge during the development and deployment of LLMs, requiring developers to make trade-offs between competing ethical goals. For instance, improving a model’s accuracy for specific user groups might require exposing certain biases or sacrificing privacy by using sensitive data. Rust can support ethical decision-making by providing tools to evaluate these trade-offs quantitatively. For example, a Rust-based system might track how various data preprocessing methods affect both model accuracy and bias, allowing developers to select methods that align with the organization’s ethical priorities. Another ethical dilemma arises when balancing model performance with transparency. Highly complex models may be more accurate but also more opaque, complicating efforts to make their outputs understandable to non-expert users. Rust’s capacity for creating interpretable, modular frameworks enables developers to experiment with model simplification and transparency-enhancing features, helping them find an acceptable balance between accuracy and interpretability.
Ethical audits are crucial to maintaining the integrity of LLM systems, acting as checkpoints that evaluate adherence to ethical standards throughout the model’s lifecycle. Rust can be used to develop an ethical audit framework that assesses LLMs against predefined ethical criteria, such as fairness, transparency, and robustness. This framework could involve a series of tests, from bias measurements and transparency assessments to privacy evaluations. For instance, a Rust-based audit tool might simulate different demographic inputs to evaluate whether the model responds equitably across groups. It could also include robustness tests, where the model is exposed to adversarial inputs or noisy data to determine if it maintains its ethical standards under challenging conditions. Through these audits, developers can gather insights into the model’s ethical performance, document any issues that arise, and make iterative improvements based on findings.
Practical Rust-based tools can enforce ethical guidelines in LLMs by embedding privacy-preserving and transparency-enabling features within the model architecture. Differential privacy, for instance, can be implemented in Rust by adding controlled noise to data points before model training, ensuring that individual user data cannot be extracted from the model. Rust’s concurrency and memory safety make it well-suited for handling the large computations required for differential privacy, allowing developers to balance user privacy with model accuracy. Similarly, transparency tools in Rust can involve tracking and reporting the contribution of each input token to the model’s final output, enabling a clearer understanding of the model’s decision-making process. By embedding these ethical features within the Rust-based model pipeline, developers can ensure that ethical standards are upheld even after deployment, providing a reliable foundation for user trust.
This pseudo code describes a Rust-based framework to address ethical dilemmas in large language model (LLM) development, balancing goals like accuracy, privacy, fairness, and transparency. The framework includes tools for evaluating trade-offs between competing ethical goals, conducting ethical audits throughout the model lifecycle, and embedding privacy-preserving and transparency-enhancing features into the model architecture. By incorporating these elements, developers can assess and enforce ethical standards in a structured and measurable way, helping ensure that LLM systems align with the organization’s values.
// Define Ethical Evaluation Framework for LLMs
EthicalFramework:
model: LLM model
data: dataset for training and evaluation
ethical_criteria: list of ethical priorities (e.g., privacy, fairness, transparency)
// Initialize framework with model, data, and ethical priorities
new(model, data, ethical_criteria):
set self.model to model
set self.data to data
set self.ethical_criteria to ethical_criteria
// Method to evaluate ethical trade-offs between accuracy, bias, and privacy
evaluate_tradeoffs():
tradeoff_results = empty dictionary
// Test different preprocessing methods
for each preprocessing_method in data.preprocessing_methods:
processed_data = apply_preprocessing(data, preprocessing_method)
accuracy, bias = model.train_and_evaluate(processed_data)
// Document trade-off impact on accuracy and bias
tradeoff_results[preprocessing_method] = { "accuracy": accuracy, "bias": bias }
return tradeoff_results
// Method to perform ethical audit on model outputs
ethical_audit():
audit_results = empty dictionary
// Test for fairness by simulating different demographic inputs
fairness_results = test_fairness_across_demographics(model, data.demographics)
audit_results["fairness"] = fairness_results
// Test for robustness under noisy and adversarial inputs
robustness_results = test_robustness(model, data.noisy_data, data.adversarial_data)
audit_results["robustness"] = robustness_results
// Evaluate transparency based on model interpretability
transparency_score = evaluate_transparency(model)
audit_results["transparency"] = transparency_score
return audit_results
// Method to enforce ethical guidelines through privacy-preserving and transparency-enhancing features
enforce_guidelines():
// Apply differential privacy to data
private_data = apply_differential_privacy(data)
model.train(private_data)
// Add transparency tool to model for tracking input contributions
model.add_transparency_tracking()
return "Ethical guidelines enforced"
// Supporting Functions for Ethical Evaluation Framework
// Function to apply preprocessing method to dataset
apply_preprocessing(data, preprocessing_method):
return data processed according to preprocessing_method
// Function to test fairness by demographic simulation
test_fairness_across_demographics(model, demographics):
fairness_results = empty dictionary
for each demographic in demographics:
inputs = generate_inputs_for_demographic(demographic)
responses = model.predict(inputs)
fairness_score = calculate_fairness_score(responses)
fairness_results[demographic] = fairness_score
return fairness_results
// Function to test robustness using noisy and adversarial inputs
test_robustness(model, noisy_data, adversarial_data):
robustness_results = empty dictionary
// Evaluate model with noisy data
noisy_responses = model.predict(noisy_data)
robustness_results["noisy"] = calculate_robustness_score(noisy_responses)
// Evaluate model with adversarial data
adversarial_responses = model.predict(adversarial_data)
robustness_results["adversarial"] = calculate_robustness_score(adversarial_responses)
return robustness_results
// Function to evaluate model transparency
evaluate_transparency(model):
interpretability_metrics = calculate_interpretability(model)
return interpretability_metrics as transparency score
// Function to apply differential privacy to data
apply_differential_privacy(data):
return data with controlled noise added to maintain privacy
// Main Execution for Ethical Framework in LLM Development
main:
model = initialize LLM model
data = load dataset with demographics, noisy, and adversarial samples
ethical_criteria = ["privacy", "fairness", "transparency"]
// Initialize ethical framework with model, data, and criteria
framework = new EthicalFramework(model, data, ethical_criteria)
// Evaluate trade-offs for ethical decision-making
tradeoff_results = framework.evaluate_tradeoffs()
print "Trade-off Results:", tradeoff_results
// Conduct an ethical audit on the model
audit_results = framework.ethical_audit()
print "Ethical Audit Results:", audit_results
// Enforce ethical guidelines in model training and deployment
framework.enforce_guidelines()
print "Ethical guidelines enforced successfully"
This pseudo code outlines an ethical evaluation and enforcement framework for LLMs, focusing on balancing accuracy, privacy, fairness, and transparency. The EthicalFramework class includes three primary methods: evaluate_tradeoffs, ethical_audit, and enforce_guidelines.
Trade-off Evaluation: The
evaluate_tradeoffsmethod assesses the impact of various data preprocessing techniques on model accuracy and bias, helping developers choose preprocessing methods that align with ethical priorities.Ethical Audit: The
ethical_auditmethod performs comprehensive tests on the model to evaluate fairness, robustness, and transparency. It simulates responses for different demographic groups to assess fairness, evaluates model performance on noisy and adversarial inputs for robustness, and calculates interpretability metrics to assess transparency.Guideline Enforcement: The
enforce_guidelinesmethod applies differential privacy to the data to protect user privacy during model training and enables a transparency tracking tool to monitor each input’s contribution to model predictions, enhancing interpretability.
In the main function, the ethical framework is initialized with the model, dataset, and ethical criteria, and then used to evaluate trade-offs, perform an ethical audit, and enforce ethical guidelines. This framework allows developers to address ethical dilemmas systematically, ensuring that LLMs are developed and deployed with attention to critical ethical standards.
Several industry cases highlight the critical role of ethics in LLM deployment. One example comes from the deployment of an LLM in customer service, where the model occasionally generated responses perceived as biased against certain user demographics. This led to a reputational risk and required the company to halt deployment temporarily while addressing these ethical concerns. Through an ethical audit and adjustments to the model’s training data, the company managed to re-train the model to ensure more equitable responses. If Rust had been employed in this setting, its safety and concurrency features would have supported rapid testing and auditing, minimizing downtime and maintaining user trust. Another example involves a healthcare application, where an LLM used for medical guidance inadvertently recommended harmful treatments due to limitations in its training data. This situation underscored the need for robust ethical auditing and stakeholder engagement to ensure model outputs are clinically safe and ethically sound. Rust’s ability to handle data-intensive tasks and audit requirements could help developers implement more rigorous safety checks, ensuring that models are appropriate for sensitive domains like healthcare.
In recent AI research, the concept of proactive ethics has gained traction, emphasizing the need to embed ethical standards into every stage of the model lifecycle rather than treating ethics as an afterthought. This approach involves integrating ethical standards into model design, training, testing, and deployment, creating systems where ethical compliance is automatic and continuous. Rust’s modularity and performance capabilities enable developers to embed ethics checks directly within the model pipeline, offering real-time ethical evaluations that persist throughout the model’s operation. For instance, a Rust-based model could include continuous bias monitoring as part of its response generation function, allowing developers to catch and address ethical issues as they arise rather than waiting for post-deployment audits. This proactive approach aligns with Rust’s ethos of reliability and safety, ensuring that the LLM remains ethically compliant even in dynamic, real-world settings.
In conclusion, ethical considerations in LLM development are critical to ensuring that these powerful tools serve society responsibly and equitably. Rust’s speed, memory safety, and concurrency capabilities make it a powerful language for implementing ethical tools that monitor, evaluate, and enhance LLMs’ ethical standards. From privacy-preserving techniques and transparency mechanisms to ethical audit frameworks and proactive ethics checks, Rust supports a comprehensive approach to ethical AI development. By integrating these tools into the LLM pipeline, developers can create systems that not only deliver high performance but also adhere to the principles of privacy, fairness, and accountability. This section has outlined the foundational, conceptual, and practical aspects of ethical considerations in LLM development, establishing a framework for responsible AI practices that align with both industry standards and societal values.
24.5. Regulatory and Legal Aspects of Bias and Fairness in LLMs
As large language models (LLMs) become integral to decision-making across industries, the regulatory and legal frameworks surrounding AI ethics, bias, and fairness have evolved to safeguard public interests. Ensuring compliance with these frameworks is paramount for developers working with LLMs, as non-compliance can lead to legal consequences, damage to user trust, and significant reputational risks. Regulations such as the General Data Protection Regulation (GDPR) in the European Union, the AI Act proposed by the European Commission, and sector-specific guidelines in areas like finance and healthcare, have set out stringent requirements for transparency, accountability, and data privacy. These frameworks mandate that organizations deploy AI models responsibly, maintaining high standards of fairness and bias mitigation. Rust, with its performance and memory safety, provides an ideal environment for developing compliance-focused tools, offering developers the ability to implement real-time monitoring, data protection mechanisms, and compliance checks within the LLM pipeline.
Figure 5: Compliance complexities of LLM deployment.
From a legal perspective, the risks of biased or unfair outputs from LLMs are most pronounced in regulated sectors such as finance, healthcare, and employment, where even minor errors can have severe implications. For instance, an LLM deployed in the financial sector that exhibits bias in credit scoring or loan approvals could violate anti-discrimination laws, exposing the organization to legal liability. Similarly, in healthcare, LLMs must comply with privacy regulations that prevent the exposure of sensitive patient information. GDPR, one of the most comprehensive data protection regulations, influences LLM deployment significantly by requiring organizations to be transparent about data usage, to obtain user consent for processing, and to ensure that personal data is adequately protected. The regulation's provisions on data minimization and purpose limitation demand that LLMs are carefully designed to avoid unnecessary data retention, a requirement that Rust’s efficient memory management can facilitate by enabling strict control over data processing pipelines.
In addition to data privacy, the AI Act proposes specific standards for high-risk AI systems, including LLMs that may impact individuals’ rights and freedoms. This act emphasizes fairness, transparency, and accuracy as essential metrics for AI systems, setting out requirements that high-risk applications undergo rigorous testing for bias and maintain clear documentation on their decision-making processes. For Rust developers, this translates into a need for robust compliance frameworks that can audit LLM outputs for fairness and log decision-making data for transparency. Rust’s structured type system and concurrency model allow developers to build automated systems that check LLM outputs for regulatory compliance, integrating bias checks and audit logs directly into the production workflow. Moreover, Rust's performance optimizations ensure these compliance tools operate efficiently, meeting the high-throughput demands of real-time applications.
Implementing compliance measures in Rust involves creating automated tools that track and assess key fairness, transparency, and data protection metrics. For instance, developers can build a compliance checklist that performs routine audits to verify adherence to regulatory standards. Such a checklist might include verifying demographic parity in model outputs, ensuring that data retention policies align with GDPR, and generating transparency reports that document the model's decision rationale for each output. In Rust, this can be achieved by defining a ComplianceChecker struct with associated functions for each regulatory requirement. Each function would analyze model behavior, validate data handling, or inspect model outputs, then log results for auditing. By using Rust’s concurrency capabilities, developers can deploy this compliance checker in parallel with regular model operations, making regulatory assessments seamless and scalable even for large-scale deployments.
To illustrate the impact of regulations on LLM deployment, consider a case study where a technology firm faced scrutiny over an LLM-driven recruitment tool that exhibited demographic bias, with a measurable disparity in positive recommendations across gender groups. Regulatory bodies required the firm to re-evaluate and audit the model, which led to significant adjustments in its data preprocessing and training methods to reduce bias. If this tool had been developed in Rust, its bias detection and mitigation could have been continuously monitored using a compliance checker that flags disparities automatically, allowing the firm to proactively address potential issues before they escalated. Rust’s speed and error-checking capabilities also facilitate the creation of fairness constraints that can be baked into the model pipeline, ensuring compliance from the outset rather than relying on retrospective audits.
This pseudo code illustrates a compliance-focused framework for developing and deploying a large language model (LLM)-driven recruitment tool that must adhere to regulatory requirements. The framework includes an automated compliance checker to detect demographic bias in real time, along with integrated fairness constraints within the training pipeline. This proactive approach, facilitated by Rust’s performance and safety features, helps the technology firm continuously monitor and adjust the model to maintain regulatory compliance.
// Define Compliance Checker Framework for LLM Deployment
ComplianceChecker:
model: LLM recruitment tool model
data: dataset for training and evaluation
demographics: list of demographic attributes in data
disparity_threshold: acceptable level of disparity for compliance
// Initialize Compliance Checker with model, data, demographics, and threshold
new(model, data, demographics, disparity_threshold):
set self.model to model
set self.data to data
set self.demographics to demographics
set self.disparity_threshold to disparity_threshold
// Method to monitor real-time bias and flag disparities
monitor_bias():
bias_results = empty dictionary
for each demographic_group in demographics:
demographic_data = filter_data_by_group(data, demographic_group)
recommendations = model.predict(demographic_data)
positive_rate = calculate_positive_rate(recommendations)
// Check if the positive rate disparity is within acceptable limits
if abs(positive_rate - overall_positive_rate(data)) > disparity_threshold:
flag_compliance_issue(demographic_group, positive_rate)
bias_results[demographic_group] = positive_rate
return bias_results
// Method to enforce fairness constraints during training
enforce_fairness_constraints():
for each epoch in training loop:
predictions = model.train(data)
// Calculate demographic disparities and enforce constraints
disparity_scores = calculate_demographic_disparities(predictions, demographics)
if any_disparity_exceeds_threshold(disparity_scores, disparity_threshold):
model.adjust_parameters_for_fairness(disparity_scores)
if model.is_converged():
break
return "Training with fairness constraints completed"
// Method to audit and re-evaluate model for regulatory compliance
audit_model():
audit_results = empty dictionary
// Evaluate fairness across demographics
fairness_results = monitor_bias()
audit_results["fairness"] = fairness_results
// Run additional compliance checks for robustness and transparency
robustness_score = evaluate_robustness(model, data.noisy_data, data.adversarial_data)
audit_results["robustness"] = robustness_score
transparency_score = evaluate_transparency(model)
audit_results["transparency"] = transparency_score
return audit_results
// Supporting Functions for Compliance Checker Framework
// Function to filter dataset by demographic group
filter_data_by_group(data, demographic_group):
return subset of data where demographic attribute matches demographic_group
// Function to calculate positive rate for recommendations
calculate_positive_rate(recommendations):
return count of positive recommendations / total recommendations
// Function to calculate overall positive rate for entire dataset
overall_positive_rate(data):
return calculate positive rate for all recommendations in data
// Function to flag a compliance issue for a specific demographic group
flag_compliance_issue(demographic_group, positive_rate):
print "Compliance issue flagged: ", demographic_group, positive_rate
// Function to calculate demographic disparities in model predictions
calculate_demographic_disparities(predictions, demographics):
disparity_scores = empty dictionary
for each demographic_group in demographics:
group_predictions = filter_predictions_by_group(predictions, demographic_group)
positive_rate = calculate_positive_rate(group_predictions)
disparity_scores[demographic_group] = positive_rate
return disparity_scores
// Function to evaluate model robustness with noisy and adversarial data
evaluate_robustness(model, noisy_data, adversarial_data):
robustness_score_noisy = calculate_robustness_score(model.predict(noisy_data))
robustness_score_adversarial = calculate_robustness_score(model.predict(adversarial_data))
return (robustness_score_noisy + robustness_score_adversarial) / 2
// Function to evaluate model transparency
evaluate_transparency(model):
interpretability_metrics = calculate_interpretability(model)
return interpretability_metrics as transparency score
// Main Execution for Compliance Monitoring in Recruitment LLM
main:
model = initialize recruitment LLM model
data = load recruitment dataset with demographic attributes and robustness tests
demographics = ["gender", "age_group", "ethnicity"]
disparity_threshold = set regulatory compliance threshold
// Initialize Compliance Checker
compliance_checker = new ComplianceChecker(model, data, demographics, disparity_threshold)
// Monitor model for bias in real-time and flag issues
bias_results = compliance_checker.monitor_bias()
print "Real-time Bias Monitoring Results:", bias_results
// Enforce fairness constraints in model training
training_status = compliance_checker.enforce_fairness_constraints()
print training_status
// Perform a full audit to assess compliance with regulatory requirements
audit_results = compliance_checker.audit_model()
print "Audit Results:", audit_results
This pseudo code outlines a compliance checker framework for an LLM-driven recruitment tool, helping a technology firm address regulatory requirements around demographic bias and fairness. The ComplianceChecker class includes three primary methods:
Real-Time Bias Monitoring: The
monitor_biasmethod calculates the positive recommendation rate across demographic groups and flags any compliance issues if the disparity exceeds the defined threshold. This enables continuous monitoring of bias throughout the model's use.Fairness-Constrained Training: The
enforce_fairness_constraintsmethod integrates fairness constraints into the training loop. By tracking disparities in real-time and adjusting model parameters when necessary, this method ensures the model aligns with fairness objectives during training, potentially reducing the need for retrospective adjustments.Regulatory Audit: The
audit_modelmethod performs a comprehensive review of the model’s fairness, robustness, and transparency. This includes testing for demographic fairness, evaluating robustness using noisy and adversarial data, and calculating transparency metrics to ensure the model meets regulatory standards.
The main function initializes the ComplianceChecker, monitors real-time bias, enforces fairness constraints, and audits the model to verify compliance. This approach, facilitated by Rust’s performance and error-checking capabilities, enables the firm to address regulatory requirements proactively, ensuring the LLM-driven recruitment tool maintains fairness and accountability.
In another example from the healthcare sector, an LLM used for diagnostic assistance came under investigation for privacy violations, as it inadvertently generated outputs containing sensitive patient information. Compliance with GDPR’s data protection and minimization principles would have required anonymization methods and strict data control policies to prevent such issues. Rust’s emphasis on memory safety and secure handling of data allows developers to implement these requirements effectively. For instance, a Rust-based LLM framework could enforce data deletion policies, automatically erasing personally identifiable information (PII) from inputs and outputs. By combining Rust's memory management with privacy-preserving algorithms, developers can ensure that LLMs retain only the information necessary for functionality, safeguarding against inadvertent exposure of sensitive data.
Despite these advancements, aligning LLM development with regulatory standards presents several challenges, including the need for cross-disciplinary collaboration between legal experts, ethicists, and developers. Legal standards for fairness, transparency, and accountability often lack precise technical definitions, making it difficult to translate them directly into code. In such cases, Rust’s modular and testable design can support iterative development and testing, helping developers refine compliance tools based on evolving regulatory guidance. For example, Rust’s robust testing capabilities can simulate various demographic inputs, allowing developers to analyze fairness impacts and adjust compliance metrics iteratively. This approach facilitates close collaboration with legal advisors, who can provide input on regulatory interpretations, while developers refine and validate compliance measures.
A growing trend in regulatory compliance for AI involves “explainability-by-design,” where models are designed to inherently align with transparency requirements. In Rust, developers can adopt this approach by implementing interpretable model structures and embedding transparency logs that document the decision path for each LLM output. Explainability-by-design frameworks can involve structuring model code to enable easy inspection of intermediate decision stages, thus allowing developers to meet transparency requirements without compromising model performance. Rust’s capability for low-level data access can also facilitate detailed logging, making it easier to reconstruct the steps leading to any given prediction and providing the necessary transparency for regulatory audits.
In conclusion, regulatory and legal aspects of bias and fairness in LLMs are essential considerations that must be integrated throughout the model development lifecycle. By leveraging Rust’s robust performance, memory safety, and concurrency capabilities, developers can create compliance tools that ensure LLMs meet the demands of regulations such as GDPR, the AI Act, and sector-specific standards. These tools allow developers to systematically monitor bias, safeguard user privacy, and maintain transparency, ensuring that LLMs align with ethical and legal expectations. As regulatory frameworks continue to evolve, Rust’s flexibility and reliability will be invaluable in adapting compliance tools to new standards, supporting the responsible and lawful deployment of LLMs in various domains. This section has established a foundation for understanding and implementing regulatory compliance within LLM development, setting the stage for creating ethically sound and legally compliant AI systems.
25.6. Future Directions in Bias, Fairness, and Ethics for LLMs
The fields of bias, fairness, and ethics in large language models (LLMs) are undergoing rapid evolution, driven by advancements in AI technology and a growing awareness of ethical challenges. With LLMs now embedded in critical decision-making processes across sectors such as finance, healthcare, and education, there is an increasing need to address the ethical dimensions of these models. Emerging trends in AI emphasize interpretability, transparency, and accountability, setting the stage for LLMs that not only meet functional requirements but also adhere to high ethical standards. New research areas are focused on developing more robust tools for bias detection and mitigation, advancing fairness constraints in model training, and creating frameworks that ensure ethical compliance. Rust, known for its efficiency and safety, is well-suited to contribute to these advancements, offering the technical capacity to handle large-scale, real-time bias assessments, and ethical evaluations. This section delves into the future directions for LLM ethics and bias mitigation, exploring the latest trends, conceptual shifts, and practical opportunities that lie ahead.
Figure 6: Summary of Ethics and Bias in LLMs.
Despite the progress in understanding and mitigating biases in LLMs, existing methods often fall short of capturing the full complexity of fairness in human contexts. Current techniques, like demographic parity and equalized odds, provide a foundation for evaluating bias but are limited in scope and flexibility. These metrics typically quantify fairness by measuring performance across demographic groups, but they may not address nuanced biases that arise from the interplay between multiple social factors. For instance, biases that impact intersectional groups—such as individuals who are both women and members of an ethnic minority—are difficult to detect using standard methods. Future research is likely to explore multidimensional fairness metrics that can capture these complex dynamics. Rust-based tools could play a key role in this research, enabling efficient computations for high-dimensional fairness metrics and leveraging parallel processing to analyze intersecting demographic groups in large datasets. Such innovations would help LLMs more accurately reflect societal values, setting a new benchmark for ethical AI.
One promising area of research lies in explainable AI (XAI), which seeks to make AI systems more interpretable and understandable to humans. In the context of LLMs, XAI can reveal why a model makes particular decisions, thereby identifying potential sources of bias or unfairness. Rust’s capabilities for low-level data access and processing can enhance the development of explainable LLM frameworks by offering high precision in monitoring and analyzing model behaviors. For example, Rust-based explainability tools could track attention mechanisms in transformer architectures, revealing which words or phrases influence specific outputs. This level of transparency allows stakeholders to assess whether the model exhibits biases in its focus on particular terms or entities. Moreover, advancements in XAI could include the development of ethical auditing tools that operate in real time, continuously analyzing model decisions and raising alerts when potential biases are detected. By implementing these tools in Rust, developers can ensure that ethical checks operate at the necessary speed and scale for real-world applications.
AI ethics frameworks are also evolving to guide the responsible development of LLMs. As ethical concerns around AI grow, interdisciplinary collaboration between AI researchers, ethicists, legal experts, and social scientists is becoming essential. Legal and ethical frameworks, such as the EU’s AI Act and the IEEE’s Ethical AI guidelines, provide a structure for addressing bias, fairness, and accountability, but these guidelines are still under development and open to interpretation. Rust-based tools could assist in making these frameworks more actionable by providing concrete mechanisms for implementing ethical standards in AI workflows. For example, a compliance framework in Rust could include modules for fairness assessment, privacy checks, and interpretability validation, mapping each ethical standard to specific software functions. By creating frameworks that embody regulatory guidelines, developers can ensure that LLMs align with both current and future regulations, helping them stay ahead of the ethical compliance curve as policies evolve.
From a practical perspective, Rust developers have the opportunity to experiment with cutting-edge tools that push the boundaries of bias detection and fairness in LLMs. Rust’s performance enables the use of computationally intensive techniques, such as adversarial testing, which generates test cases designed to expose model biases under challenging conditions. For example, an adversarial testing framework in Rust could systematically alter input text to examine how the LLM’s responses vary with demographic markers, helping developers identify biases that may not be apparent through conventional testing. Additionally, Rust’s robust support for functional programming allows developers to construct modular components for fairness evaluation, which can be easily adapted and extended as new fairness metrics are developed. This modularity supports a research-oriented approach, allowing developers to quickly test different fairness hypotheses and refine their models based on empirical findings.
This pseudo code demonstrates the development of an explainable AI (XAI) and ethics compliance framework for large language models (LLMs) using Rust. The framework includes tools for real-time explainability, ethical auditing, and adversarial testing. Explainability features track model attention to reveal decision-making patterns, while ethical auditing ensures compliance with evolving AI regulations. Additionally, adversarial testing exposes hidden biases by systematically altering input texts. This modular and high-performance framework leverages Rust’s low-level data access and processing capabilities to achieve transparency, fairness, and compliance in LLMs, supporting stakeholders in building accountable AI systems.
// Define Explainability and Ethical Compliance Framework for LLMs
ExplainabilityEthicsFramework:
model: LLM model
data: dataset for training and evaluation
ethical_guidelines: list of ethical standards (e.g., fairness, transparency, privacy)
// Initialize framework with model, data, and ethical guidelines
new(model, data, ethical_guidelines):
set self.model to model
set self.data to data
set self.ethical_guidelines to ethical_guidelines
// Method for explainability: Track attention and influence of input tokens
explain_model_decisions(input_text):
tokenized_input = tokenize(input_text)
attention_weights = model.compute_attention(tokenized_input)
// Identify top influential words based on attention weights
influential_tokens = identify_influential_tokens(attention_weights, tokenized_input)
explanation = format_explanation(influential_tokens, input_text)
return explanation
// Method for ethical auditing based on attention and output analysis
ethical_audit():
audit_results = empty dictionary
// Run fairness assessment based on attention bias across demographic terms
fairness_results = analyze_attention_bias(model, data.demographic_terms)
audit_results["fairness"] = fairness_results
// Perform privacy check if sensitive data is involved
if "privacy" in ethical_guidelines:
privacy_compliance = verify_privacy_compliance(data)
audit_results["privacy"] = privacy_compliance
// Evaluate interpretability based on model complexity
interpretability_score = assess_interpretability(model)
audit_results["transparency"] = interpretability_score
return audit_results
// Method for adversarial testing to detect hidden biases
adversarial_testing():
test_results = empty dictionary
for each demographic_marker in data.demographic_markers:
adversarial_inputs = generate_adversarial_variations(input_text, demographic_marker)
responses = model.predict(adversarial_inputs)
// Measure response variations for biases
bias_detected = evaluate_bias_in_responses(responses, demographic_marker)
test_results[demographic_marker] = bias_detected
return test_results
// Method to ensure compliance with ethical guidelines in model pipeline
enforce_compliance():
compliance_results = empty dictionary
for each guideline in ethical_guidelines:
if guideline == "fairness":
apply_fairness_constraints(model)
if guideline == "transparency":
model.enable_transparency_tracking()
if guideline == "privacy":
data = apply_differential_privacy(data)
compliance_results[guideline] = "Enforced"
return compliance_results
// Supporting Functions for Explainability and Ethics Framework
// Function to identify influential tokens from attention weights
identify_influential_tokens(attention_weights, tokenized_input):
influential_tokens = filter tokens with highest attention scores from attention_weights
return influential_tokens
// Function to analyze attention bias across demographic terms
analyze_attention_bias(model, demographic_terms):
attention_scores = model.compute_attention(demographic_terms)
bias_scores = calculate_bias_from_attention(attention_scores, demographic_terms)
return bias_scores
// Function to verify privacy compliance by checking for sensitive data exposure
verify_privacy_compliance(data):
check data against privacy rules
return privacy_compliance_status
// Function to assess interpretability based on model complexity
assess_interpretability(model):
interpretability_score = calculate_interpretability_metric(model)
return interpretability_score
// Function to generate adversarial inputs by altering demographic markers
generate_adversarial_variations(input_text, demographic_marker):
variations = create modified versions of input_text with demographic_marker
return variations
// Function to evaluate bias in model responses to adversarial inputs
evaluate_bias_in_responses(responses, demographic_marker):
analyze response variations for demographic_marker
return "Bias Detected" if significant variation found else "No Bias"
// Function to apply fairness constraints in model training
apply_fairness_constraints(model):
for each epoch in training loop:
predictions = model.train(data)
// Adjust model to reduce disparities
disparity_score = calculate_disparity(predictions, data.demographics)
if disparity_score > acceptable_threshold:
model.adjust_for_fairness(disparity_score)
if model.is_converged():
break
// Main Execution for Explainability and Ethics in LLM Deployment
main:
model = initialize LLM model
data = load dataset with demographic terms and markers
ethical_guidelines = ["fairness", "transparency", "privacy"]
// Initialize the Explainability and Ethics Framework
framework = new ExplainabilityEthicsFramework(model, data, ethical_guidelines)
// Explain model decisions for a sample input
input_text = "Analyze my qualifications for this job."
explanation = framework.explain_model_decisions(input_text)
print "Model Explanation:", explanation
// Perform ethical audit to assess model compliance
audit_results = framework.ethical_audit()
print "Ethical Audit Results:", audit_results
// Conduct adversarial testing to detect hidden biases
test_results = framework.adversarial_testing()
print "Adversarial Testing Results:", test_results
// Enforce ethical guidelines within the model pipeline
compliance_results = framework.enforce_compliance()
print "Compliance Enforcement Results:", compliance_results
This pseudo code defines an ExplainabilityEthicsFramework class to support explainable AI (XAI) and ethics compliance in LLM deployment. The framework consists of four main methods:
Explainability: The
explain_model_decisionsmethod tokenizes an input text, computes attention weights, and identifies influential tokens. This reveals which parts of the input text contribute most to the model’s decision, providing transparency into the model’s reasoning.Ethical Auditing: The
ethical_auditmethod evaluates the model’s fairness by analyzing attention bias across demographic terms, checks privacy compliance, and assesses interpretability based on model complexity. This produces an audit report indicating areas where the model meets or fails ethical standards.Adversarial Testing: The
adversarial_testingmethod systematically alters input texts using demographic markers to expose hidden biases. By comparing responses to these variations, this method identifies any significant changes that suggest demographic bias in model predictions.Compliance Enforcement: The
enforce_compliancemethod applies ethical standards directly within the model pipeline. It adjusts training to minimize disparities (fairness), enables transparency tracking (transparency), and applies differential privacy (privacy) to ensure compliance with ethical guidelines.
In the main function, the framework is instantiated, and each method is called sequentially to explain model decisions, audit compliance, conduct adversarial testing, and enforce ethical guidelines. By leveraging Rust’s data processing capabilities, this framework offers an efficient and reliable approach to XAI and ethics in LLMs, helping developers maintain accountability and trustworthiness in their AI systems.
Another promising direction in AI ethics is the concept of explainability-by-design, which emphasizes designing models with built-in interpretability rather than retrofitting transparency features. Explainability-by-design is particularly relevant for complex models like LLMs, where interpreting decisions post hoc can be challenging. By building transparency into the model architecture, developers can provide stakeholders with a clearer view of the LLM’s decision-making processes. Rust’s system-level capabilities make it well-suited for implementing explainability-by-design, as developers can closely manage data flow, inspect intermediate layers, and track decision paths at the code level. For instance, developers could design transformer layers that output attention weights alongside the final predictions, allowing users to understand which aspects of the input most influenced the model. These innovations are likely to be critical for high-stakes applications, such as legal or medical decision support, where transparency is not only beneficial but necessary for ethical and legal reasons.
In addition to technical advancements, recent studies underscore the need for an AI research agenda that prioritizes fairness, bias mitigation, and ethical accountability. As LLMs grow in scale and complexity, the risks associated with biased or unethical outputs also increase, creating an urgent need for new safeguards. Research institutions and industry leaders are actively investing in AI ethics research, with initiatives that range from developing sophisticated bias metrics to designing interventions that make models more inclusive. Rust, with its speed and control over computational resources, is an ideal language for testing these experimental techniques, as it allows developers to prototype and benchmark new fairness tools efficiently. For instance, a Rust-based research proposal could explore a novel approach to ethical LLM design by combining real-time fairness checks with reinforcement learning, guiding the model toward unbiased outputs by rewarding ethically sound behavior.
Ultimately, the future of LLM ethics and fairness is likely to involve continuous innovation and close interdisciplinary collaboration. While current techniques address many ethical challenges, they represent only the beginning of a much larger journey toward responsible AI. By involving experts from diverse fields, such as cognitive science, ethics, and sociology, the AI community can create a more comprehensive framework for assessing and mitigating bias. Rust’s versatility in data handling, computation, and performance optimization makes it an excellent tool for this cross-disciplinary effort, enabling developers to build tools that analyze model outputs from multiple perspectives and ensure that ethical standards are maintained across diverse applications.
In conclusion, the future directions for bias, fairness, and ethics in LLMs are shaped by advancements in AI technology, growing regulatory expectations, and a deepening understanding of ethical issues. As researchers and practitioners explore new techniques for enhancing LLM transparency and accountability, Rust stands out as a powerful and adaptable language that can support these initiatives. This section has highlighted key areas of focus for future research and practical application, from developing explainable AI tools and compliance frameworks to experimenting with ethical design principles in Rust. By prioritizing these efforts, the AI community can ensure that LLMs are not only functionally advanced but also aligned with the values of fairness, equity, and social responsibility.
25.7. Conclusion
This chapter provide a structured and comprehensive approach to understanding and addressing bias, fairness, and ethics in LLMs using Rust. Each section in this chapter blends theoretical concepts with practical tools and techniques, empowering readers to build and deploy LLMs that are not only powerful but also aligned with ethical and regulatory standards.
25.7.1. Further Learning with GenAI
Each prompt challenges you to think critically and act proactively, ensuring that the AI systems you build are not only powerful but also just, transparent, and aligned with the highest ethical standards.
Explain in detail the different types of biases (e.g., data bias, algorithmic bias, societal bias) that can affect large language models (LLMs). How do these biases manifest in the data, model training, and outputs of LLMs? Discuss specific examples where these biases have led to unintended consequences, and outline potential strategies to identify and mitigate each type of bias.
Discuss the ethical implications of deploying biased LLMs in critical applications such as healthcare, finance, and law. How can biased LLMs exacerbate existing societal inequalities, and what are the potential long-term consequences? Explore the role of developers and organizations in addressing these ethical concerns, and propose a framework for ethical decision-making in AI development.
Describe the process of detecting bias in LLMs using Rust-based tools. What are the key techniques for identifying both overt and subtle biases in model outputs, and how can these techniques be implemented in a Rust environment? Provide a step-by-step guide to creating a bias detection tool in Rust, including considerations for different types of data and model architectures.
Analyze the challenges involved in defining and measuring fairness in LLMs. What are the various fairness metrics (e.g., demographic parity, equalized odds, disparate impact), and how do they differ in their approach to evaluating fairness? Discuss the trade-offs between these metrics and how Rust can be used to implement them in a way that balances fairness with other performance indicators like accuracy and efficiency.
Explore the trade-offs between model accuracy and fairness in LLMs. How can these trade-offs be quantified and managed during model development? Discuss specific examples where prioritizing fairness has led to a reduction in accuracy, and propose strategies for mitigating this impact. Explain how Rust can be used to implement fairness constraints in LLMs and analyze the outcomes of these implementations.
Explain how data preprocessing techniques can be used to mitigate bias in LLMs. What are the methods for detecting and correcting biased data before model training, and how can these methods be effectively implemented using Rust? Provide a comprehensive guide to data preprocessing for bias mitigation, including examples of different types of biases and the tools available in Rust to address them.
Discuss the role of algorithmic adjustments in enhancing fairness in LLMs. How can model training processes be modified to reduce bias and improve fairness, and what are the challenges associated with these adjustments? Explore the use of Rust-based tools to implement fairness-aware algorithms, and analyze the effectiveness of these approaches in real-world applications.
Explore the ethical principles that should guide the development and deployment of LLMs. How can these principles be operationalized in AI projects, particularly those using Rust, to ensure that LLMs are developed and deployed responsibly? Discuss the challenges of implementing ethical guidelines in practice, and propose a comprehensive framework for ethical AI development that integrates Rust tools and best practices.
Describe the potential ethical risks associated with LLMs, such as misuse, unintended harm, and the reinforcement of societal inequalities. How can these risks be proactively identified and mitigated during the development and deployment of LLMs? Discuss how Rust tools can be used to monitor ethical risks throughout the lifecycle of an LLM, and provide examples of how these tools have been successfully implemented in real-world projects.
Discuss the importance of transparency and accountability in AI systems. How can Rust be used to develop tools that enhance the transparency of LLMs, making their decision-making processes more understandable to users and stakeholders? Explore the challenges of achieving transparency in complex models like LLMs, and propose solutions that balance the need for transparency with the practical limitations of model complexity.
Analyze the regulatory landscape governing AI, with a focus on bias, fairness, and ethics in LLMs. What are the key legal requirements and standards that AI systems must meet in different industries, and how can Rust-based tools be used to ensure compliance with these regulations? Discuss specific examples of AI regulations, such as GDPR, and provide a detailed guide to developing compliant AI systems using Rust.
Explore the impact of regulations like GDPR on the design and deployment of LLMs. How do data protection and transparency requirements influence the development of AI systems, and what are the challenges of ensuring compliance? Discuss how Rust can be used to develop AI systems that meet these regulatory requirements while maintaining high performance, and provide examples of best practices for GDPR compliance in AI projects.
Explain the role of ethical audits in evaluating LLMs. How can an ethical audit framework be developed using Rust to assess the adherence of LLMs to ethical standards? Provide a detailed guide to designing and conducting ethical audits, including the key components of the audit process, the metrics used to evaluate ethical performance, and the challenges of implementing audits in practice.
Discuss the challenges of aligning LLM development with legal requirements across different jurisdictions. How can Rust-based tools be designed to navigate the complexities of global AI regulations, and what are the key considerations for ensuring that LLMs meet diverse legal standards? Provide a comprehensive analysis of the challenges and solutions for developing legally compliant LLMs, with examples of how Rust has been used to address these issues.
Describe the process of implementing fairness constraints in LLMs using Rust. How can fairness be operationalized during model training and evaluation, and what are the potential impacts on model performance and usability? Discuss the challenges of integrating fairness constraints into existing AI systems, and provide a step-by-step guide to implementing fairness-aware LLMs using Rust tools and libraries.
Explore the concept of explainability in the context of ethical AI. How can Rust be used to develop explainable AI tools that help users and stakeholders understand the decisions made by LLMs? Discuss the importance of explainability in promoting transparency and trust in AI systems, and provide examples of how explainable AI techniques can be implemented in Rust to improve the interpretability of LLM outputs.
Discuss the future directions of bias, fairness, and ethics in AI. What emerging trends and technologies could improve the ethical design of LLMs, and how can Rust be leveraged to support these advancements? Provide a forward-looking analysis of the challenges and opportunities in this field, and propose a roadmap for integrating ethical considerations into the next generation of AI systems using Rust.
Explain the potential of AI-assisted tools in enhancing the ethical design of LLMs. How can machine learning techniques be used to automatically detect and mitigate biases in LLMs, and what role can Rust play in developing these tools? Discuss the challenges of creating AI-assisted ethical tools, and provide examples of how Rust can be used to implement these tools in real-world projects.
Analyze the importance of interdisciplinary collaboration in advancing fairness and ethics in AI. How can insights from fields such as ethics, law, and social sciences be integrated into the development of responsible AI systems, and what role can Rust play in facilitating this collaboration? Provide a comprehensive guide to developing interdisciplinary AI projects, with examples of how Rust has been used to integrate diverse perspectives into the design and deployment of ethical LLMs.
Discuss the role of continuous monitoring and feedback in maintaining the fairness and ethics of LLMs. How can Rust-based tools be developed to provide ongoing assessments of LLM performance, ensuring that ethical standards are upheld throughout the model's lifecycle? Provide a detailed guide to designing and implementing continuous monitoring systems for LLMs, including the key metrics to monitor, the challenges of maintaining ethical standards over time, and the role of Rust in supporting these efforts.
By engaging with these comprehensive and in-depth exercises, you will develop not only technical expertise in implementing these concepts using Rust but also a deep appreciation for the ethical responsibilities that come with AI development.
25.7.2. Hands On Practices
Self-Exercise 25.1: Detecting and Analyzing Bias in LLMs
Objective: To develop and implement a Rust-based tool that detects and analyzes different types of biases in large language models (LLMs), focusing on both overt and subtle biases.
Tasks:
Research and identify common types of biases (e.g., gender, racial, societal biases) that can affect LLM outputs.
Design and implement a Rust-based tool that detects these biases in LLM outputs using quantitative metrics and qualitative analysis.
Apply the tool to a sample LLM, running tests on a variety of inputs to detect and quantify biases.
Analyze the results, comparing the presence and severity of biases across different inputs, and document your findings.
Deliverables:
A Rust-based bias detection tool, complete with source code and documentation.
A detailed report analyzing the biases detected in the sample LLM, including quantitative results and qualitative observations.
Recommendations for mitigating the identified biases in the LLM, with a focus on improving fairness and reducing harm.
Self-Exercise 25.2: Implementing Fairness Constraints in LLM Training
Objective: To implement fairness constraints during the training of an LLM using Rust, balancing the trade-offs between accuracy and fairness.
Tasks:
Research fairness metrics such as demographic parity, equalized odds, and disparate impact, and select appropriate metrics for your LLM.
Implement fairness constraints in Rust that can be integrated into the LLM training process, ensuring that the model meets these fairness metrics.
Train the LLM with these constraints in place, monitoring how the constraints affect model performance and fairness outcomes.
Evaluate the impact of the fairness constraints on the LLM’s outputs, comparing the results to a baseline model without constraints.
Deliverables:
A Rust-based implementation of fairness constraints for LLM training, including source code and documentation.
A trained LLM model that incorporates fairness constraints, with performance metrics and fairness outcomes documented.
A comparative analysis of the fairness-constrained model versus a baseline model, including insights into the trade-offs between fairness and accuracy.
Self-Exercise 25.3: Developing an Ethical Audit Framework for LLMs
Objective: To design and conduct an ethical audit of an LLM using a Rust-based framework, evaluating the model against established ethical standards.
Tasks:
Research ethical principles and standards relevant to AI development, focusing on issues such as bias, fairness, transparency, and accountability.
Design an ethical audit framework using Rust, incorporating metrics and evaluation criteria that align with these ethical standards.
Apply the ethical audit framework to a sample LLM, systematically evaluating the model’s compliance with ethical guidelines.
Document the audit findings, identifying areas where the LLM meets or falls short of ethical standards, and provide recommendations for improvement.
Deliverables:
A Rust-based ethical audit framework, including source code, documentation, and the criteria used for evaluation.
A comprehensive audit report detailing the ethical performance of the sample LLM, with specific examples of compliance and areas for improvement.
Recommendations for enhancing the ethical design and deployment of the LLM, focusing on actionable steps for addressing identified ethical concerns.
Self-Exercise 25.4: Enhancing Explainability in LLMs through Rust
Objective: To develop tools in Rust that improve the explainability of LLM outputs, making the model’s decision-making process more transparent and understandable.
Tasks:
Research explainability techniques that can be applied to LLMs, such as feature attribution, attention visualization, and counterfactual explanations.
Implement one or more of these techniques in Rust, creating tools that can generate explanations for specific LLM outputs.
Test the explainability tools on a variety of LLM outputs, evaluating how well the tools help users understand the model’s decisions.
Analyze the effectiveness of the explanations generated by the tools, documenting user feedback and areas where the tools can be improved.
Deliverables:
A Rust-based explainability tool or suite of tools, complete with source code, documentation, and examples of generated explanations.
A detailed evaluation report on the effectiveness of the explainability tools, including user feedback and analysis of the clarity and usefulness of the explanations.
Recommendations for refining the explainability tools, with a focus on improving their ability to convey complex model decisions in an understandable manner.
Self-Exercise 25.5: Continuous Monitoring and Feedback for Fairness in LLMs
Objective: To implement a continuous monitoring system in Rust that assesses the fairness of an LLM over time, ensuring that the model maintains ethical standards throughout its lifecycle.
Tasks:
Research continuous monitoring techniques and fairness metrics that can be applied to LLMs, focusing on long-term performance and ethical compliance.
Develop a Rust-based monitoring system that continuously evaluates the fairness of LLM outputs, flagging any deviations from established standards.
Deploy the monitoring system alongside an LLM, tracking its performance over time and collecting data on fairness outcomes.
Analyze the data collected by the monitoring system, identifying trends, potential biases, and areas where the model’s fairness can be improved.
Deliverables:
A Rust-based continuous monitoring system for fairness in LLMs, including source code, documentation, and deployment instructions.
A report analyzing the fairness of the LLM over time, with insights into how the model’s performance evolves and where ethical issues may arise.
Recommendations for ongoing improvements to the LLM, based on the monitoring data, with a focus on maintaining high ethical standards throughout the model’s lifecycle.
Comments