Chapter 24
Interpretability and Explainability in LLMs
"We must remember that the true potential of AI lies not just in its ability to perform tasks, but in our ability to understand and trust its decisions." — Cynthia Rudin
Chapter 24 of LMVR offers a comprehensive exploration of interpretability and explainability in large language models (LLMs) through the lens of Rust implementation. The chapter delves into the critical distinctions between interpretability and explainability, and the importance of these concepts in building trustworthy and ethical AI systems. It covers a range of techniques, from feature attribution and attention visualization to model-agnostic and model-specific methods, providing practical tools for making LLMs more transparent and understandable. The chapter also addresses the ethical and regulatory implications of deploying opaque models and explores future trends in explainability, emphasizing the need for models that are not only powerful but also interpretable and accountable.
24.1. Introduction to Interpretability and Explainability in LLMs
The rapid advancements in large language models (LLMs) have brought about powerful tools capable of generating and processing human-like language with remarkable precision. However, as these models grow in complexity, their inner workings become increasingly opaque. Interpretability and explainability, two critical areas in AI, seek to address this opacity. Interpretability refers to making a model’s internal processes understandable, while explainability focuses on elucidating the reasoning behind a model’s specific decisions or outputs. Together, they form the basis for ensuring transparency and trustworthiness in LLMs, enabling stakeholders to understand how and why a model arrives at its conclusions. This is especially important in high-stakes environments such as healthcare, finance, and legal systems, where misinterpretations or undetected biases in model outputs could lead to serious consequences.
Figure 1: Challenges in interpretability and explainability in LLMs.
Interpretability techniques can be classified broadly into global and local approaches. Global interpretability aims to make the overall behavior and structure of a model comprehensible, typically by examining patterns in the learned parameters or the network architecture. This involves identifying dominant features, recurring patterns, and other general characteristics across multiple inputs. On the other hand, local interpretability is concerned with specific outputs and the factors influencing individual predictions or responses. Local interpretability techniques, such as saliency maps and attention visualization, allow practitioners to pinpoint what influenced a particular model output. By combining global and local interpretability, we gain a more complete understanding of an LLM’s capabilities and limitations. Developing effective tools to achieve this understanding within the Rust programming language—known for its performance and memory safety—has the potential to make model analysis more efficient and reproducible.
Achieving interpretability and explainability in LLMs is challenging due to the inherently complex and multi-layered architecture of these models. Many interpretability techniques, such as feature attribution and layer-wise relevance propagation, are adapted from simpler machine learning models like decision trees and convolutional neural networks. Applying these methods to LLMs, which process thousands of tokens and span numerous layers, introduces unique challenges. Techniques developed for simpler models often lack scalability when applied to LLMs, as they need to handle the intricate interactions between tokens and the vast number of parameters within the model. One mathematical approach to interpretability in LLMs involves examining the gradients and attention weights. By analyzing the gradients of the model’s loss function with respect to its input tokens, practitioners can assess which parts of the input have the most significant influence on a prediction. This approach, known as gradient-based saliency mapping, can be implemented in Rust by directly accessing and manipulating tensors. Rust’s safety and performance make it particularly suited for implementing such memory-intensive operations efficiently.
In addition to interpretability, explainability has gained attention in recent years, focusing on providing stakeholders with understandable reasons for a model’s decisions. For example, in finance, a model’s decision to flag a transaction as suspicious must be explainable to compliance officers. This requirement is not only a matter of user trust but is also often mandated by regulatory bodies. Ethical considerations are crucial here: LLMs that operate as "black boxes" can introduce bias, leading to unfair treatment or discrimination, especially in applications involving sensitive data. Models deployed in critical applications are increasingly expected to be transparent and compliant with ethical standards, particularly when their decisions can have profound impacts on human lives. In Rust, achieving such explainability requires tools that can simulate or approximate the decision-making processes of LLMs. This can be done by developing interpretable surrogate models that approximate the behavior of an LLM for certain inputs, effectively creating a simpler, explainable model that mirrors the complex model's behavior in specific cases.
To experiment with these ideas in Rust, setting up a reliable environment for interpretability research is essential. Rust’s strengths in low-level systems programming, combined with its growing ecosystem of machine learning libraries, make it a suitable choice for building efficient interpretability tools. Implementing basic interpretability tools in Rust requires familiarity with tensor operations, gradient calculations, and visualization libraries for representing model behavior graphically. For instance, a Rust-based saliency map generator could calculate token gradients with respect to output layers and display which tokens contribute most to the model's response. Rust’s safety guarantees can help prevent memory errors in these intensive computations, particularly important when manipulating large matrices and tensors across layers in LLMs.
A practical Rust implementation of interpretability might involve developing a tool to visualize attention layers in transformers, a common model structure in LLMs. The tool could output a graphical representation of attention heads, illustrating which tokens attend to which other tokens and to what degree. By isolating specific attention heads and layers, Rust can be used to perform precise calculations on the attention weights, showing where the model focuses during different stages of processing. Furthermore, attention patterns can reveal biases, especially when the model consistently assigns higher attention to particular token patterns based on training data. This kind of interpretability tool is invaluable for identifying potential sources of bias and correcting them, fostering trust in the model's outputs.
To visualize attention layers in transformer networks using Rust, the following code leverages the tch-rs library to interact with a pre-trained transformer model and plotters for graphical representation of attention weights. This tool is designed to output a visualization of the attention heads, illustrating which tokens attend to others and to what degree. By isolating specific attention heads and layers, this implementation allows us to precisely analyze attention patterns, helping in the interpretation of model behavior. Such visualizations are crucial for understanding potential biases in token relationships and model decision pathways, ultimately supporting transparency in LLMs.
[dependencies]
plotters = "0.3.7"
tch = "0.12.0"
use plotters::prelude::*;
use tch::{Tensor, Device, Kind};
use std::error::Error;
// Define a simplified transformer model structure
struct TransformerModel {
attention_weights: Vec<Tensor>,
}
impl TransformerModel {
fn new() -> Self {
// Placeholder for attention weights, typically derived from a transformer model
let attention_weights = Vec::new();
Self {
attention_weights,
}
}
fn forward(&mut self, input: &Tensor) -> Tensor {
// Simulate forward pass and populate attention weights
self.attention_weights = vec![Tensor::randn(&[8, 12, 64, 64], (Kind::Float, Device::Cpu))];
input.shallow_clone() // Return the input as a placeholder output
}
fn get_attention_weights(&self) -> &Vec<Tensor> {
&self.attention_weights
}
}
// Visualize attention weights using plotters
fn visualize_attention(attention: &Tensor, output_path: &str) -> Result<(), Box<dyn Error>> {
let root = BitMapBackend::new(output_path, (800, 600)).into_drawing_area();
root.fill(&WHITE)?;
let mut chart = ChartBuilder::on(&root)
.caption("Attention Weights", ("sans-serif", 50).into_font())
.margin(10)
.x_label_area_size(30)
.y_label_area_size(30)
.build_cartesian_2d(0..63, 0..63)?;
chart.configure_mesh().draw()?;
for head in 0..attention.size()[1] {
let attn_head = attention.get(0).get(head);
let heatmap_data = (0..64).flat_map(|i| {
let attn_head = &attn_head; // Borrow `attn_head` by reference within the inner closure
(0..64).map(move |j| ((i as i32, j as i32), attn_head.double_value(&[i, j])))
});
chart.draw_series(
heatmap_data.map(|((x, y), val)| {
Rectangle::new(
[(x, y), (x + 1, y + 1)],
Palette99::pick((val * 99.0) as usize).filled(),
)
}),
)?;
}
root.present()?;
Ok(())
}
fn main() -> Result<(), Box<dyn Error>> {
// Initialize the model and create a sample input
let mut model = TransformerModel::new();
let input = Tensor::randn(&[1, 64], (Kind::Float, Device::Cpu));
let _output = model.forward(&input);
// Get attention weights and visualize
let attention_weights = model.get_attention_weights();
for (i, attn) in attention_weights.iter().enumerate() {
let output_path = format!("attention_layer_{}.png", i);
visualize_attention(attn, &output_path)?;
println!("Saved attention visualization to {}", output_path);
}
Ok(())
}
This Rust code defines a simplified transformer model with an attention mechanism, utilizing tch-rs to perform tensor operations and plotters to create a visualization of the attention weights. The TransformerModel struct contains placeholder methods to initialize a transformer model and simulate attention weights across multiple layers and heads. In the visualize_attention function, we use the plotters library to create a 2D heatmap that represents attention scores between tokens. The code iterates over attention heads and plots each value, with higher attention values shown in more intense colors. Each heatmap is saved as an image, providing a graphical representation of which tokens each attention head is focusing on, thus helping in visualizing the model’s interpretability. This visual tool can be invaluable for model debugging, bias analysis, and understanding complex decision-making in transformer models.
Figure 2: Simple visualization of attention layer.
Industry use cases emphasize the importance of interpretability and explainability, particularly where LLMs support critical decision-making. In healthcare, for instance, LLMs might assist in diagnosing conditions based on clinical notes. Without explainability, these tools are difficult for practitioners to trust, especially if they lack medical training data transparency. A case study in healthcare could involve developing a Rust-based tool that applies attention visualization and saliency mapping techniques to detect key terms or phrases that the model prioritizes in its responses. Rust’s ability to handle large data operations efficiently allows such a tool to operate on extensive clinical datasets, providing real-time insights into the model’s decision-making processes.
In summary, interpretability and explainability are foundational for making LLMs trustworthy and ethical, especially as their applications expand into sensitive fields. Rust offers unique advantages for implementing these techniques, enabling high-performance, memory-safe tools that can handle the computational demands of model analysis. By leveraging Rust's robust system capabilities, we can create tools that reveal insights into both the local and global behavior of LLMs, aiding in their debugging, improvement, and ethical deployment. The latest trends in the field emphasize the need for hybrid interpretability techniques that combine visualizations, gradient analysis, and surrogate modeling, creating a multi-faceted approach that Rust is well-suited to support. Through these advancements, Rust is poised to play an essential role in the future of interpretability and explainability in AI.
24.2. Techniques for Improving Interpretability in LLMs
As the complexity of large language models (LLMs) grows, the need for robust interpretability techniques has become a pressing concern. These techniques enable researchers, developers, and stakeholders to understand how LLMs make decisions and generate responses. Among the most widely used methods for enhancing interpretability are feature attribution, attention visualization, and surrogate modeling. Feature attribution aims to identify the specific inputs or features that contribute most to a model's output. Attention visualization, especially in transformer-based models, provides a way to see where the model focuses when processing different parts of the input. Surrogate models, meanwhile, serve as simplified representations of complex models, retaining the essential behavior of the original model but in a more interpretable form. Rust's ecosystem, known for its efficiency and memory safety, provides a promising platform for implementing these interpretability techniques. Rust libraries and crates offer robust support for computationally demanding tasks, making it feasible to perform detailed interpretability analysis at scale.
Feature attribution methods are foundational for understanding which parts of an input most influence a model’s decision. Mathematically, feature attribution often involves calculating the gradient of the model’s output with respect to its inputs. This gradient can highlight the inputs that most affect the model’s response, indicating which words or phrases the model "pays attention to" when generating an output. In Rust, this can be implemented by manipulating tensors to compute these gradients, which requires efficient and safe handling of memory-intensive computations. For instance, a Rust-based tool for feature attribution might involve accessing the gradients at each layer of a transformer model, identifying the most influential tokens. By incorporating gradient-based methods, we can identify parts of an input that disproportionately influence certain model responses. This level of analysis, when efficiently executed in Rust, is highly valuable for debugging and improving LLMs, especially in sensitive applications such as medical diagnosis or financial forecasting, where understanding the model’s decision-making process is critical.
Attention visualization is another technique that has gained popularity for interpreting transformer-based models, the architecture underpinning most modern LLMs. Transformers use attention mechanisms to process inputs by focusing on specific tokens that are contextually relevant. For example, in translating a sentence, a transformer may assign higher attention to words directly related to the target language's syntax and grammar. Visualizing these attention patterns provides insights into which parts of an input the model considers important at each layer of processing. In Rust, implementing attention visualization can be achieved by extracting and visualizing the attention weights associated with each token. For each layer and attention head in the transformer, attention scores are calculated and visualized in matrices, highlighting the relationships between tokens. This approach allows users to see which tokens are "communicating" with each other in the model’s internal representations. Rust's computational efficiency enables handling these large attention matrices without significant overhead, making it an ideal choice for real-time or large-scale interpretability analyses.
Surrogate modeling is a powerful technique that approximates a complex LLM with a simpler model, providing a "stand-in" that maintains much of the original model's behavior but is inherently easier to interpret. Surrogate models, often designed as smaller decision trees or linear models, offer a way to approximate the decision boundaries and reasoning patterns of an LLM without fully replicating its complexity. This approach is beneficial in cases where a high level of interpretability is required but the exact mechanics of the LLM are too intricate to analyze directly. The surrogate model can be trained on the inputs and outputs of the LLM, capturing the core patterns in the data while remaining transparent enough for users to understand. In Rust, constructing surrogate models requires careful handling of data and ensuring that the surrogate model accurately captures the behaviors of the LLM. For example, a decision tree built in Rust could serve as a surrogate for a large transformer model, enabling interpretable if-then-else rule generation that sheds light on the logic of the larger model.
While these interpretability techniques are valuable, they come with inherent trade-offs between complexity and understanding. High-complexity models, by nature, capture more intricate patterns in data, but they are harder to interpret directly. By simplifying or approximating these models through techniques like attention visualization or surrogate modeling, we gain insights but may sacrifice some precision or nuance in understanding the model's full capabilities. This trade-off is particularly evident when using surrogate models: while they provide a transparent approximation, they may overlook some of the subtle relationships captured by the original model. In critical applications, balancing this trade-off is essential, as too much simplification could misrepresent the model’s behavior, while too little interpretability could make the model unusable for decision-making.
Rust is particularly well-suited for developing tools that manage this balance, as it combines computational efficiency with a rigorous focus on memory safety. Implementing these techniques in Rust allows for fine-grained control over performance and reliability, particularly important when working with large-scale LLMs. For instance, by using Rust to develop an attention visualization tool, developers can ensure that the tool operates efficiently across multiple layers of a transformer model, even with complex, token-rich inputs. Rust’s concurrency capabilities also make it possible to parallelize operations across layers and attention heads, further enhancing the performance of interpretability tools.
The code below leverages parallelism to improve the efficiency of visualizing attention weights from a simplified transformer model. Using crossbeam's threading capabilities, it processes and generates visualizations for each attention head concurrently. Instead of handling each attention head sequentially, the code distributes the workload across threads, allowing multiple visualization tasks to run in parallel. This approach is particularly beneficial when handling large-scale models with numerous attention heads, as it reduces overall computation time and makes the visualization process faster and more efficient.
[dependencies]
crossbeam = "0.8.4"
plotters = "0.3.7"
tch = "0.12.0"
use plotters::prelude::*;
use tch::{Tensor, Device, Kind};
use std::error::Error;
use std::sync::{Arc, Mutex};
use crossbeam::thread;
// Define a simplified transformer model structure
struct TransformerModel {
attention_weights: Vec<Tensor>,
}
impl TransformerModel {
fn new() -> Self {
let attention_weights = Vec::new();
Self {
attention_weights,
}
}
fn forward(&mut self, input: &Tensor) -> Tensor {
self.attention_weights = vec![Tensor::randn(&[8, 12, 64, 64], (Kind::Float, Device::Cpu))];
input.shallow_clone()
}
fn get_attention_weights(&self) -> &Vec<Tensor> {
&self.attention_weights
}
}
// Visualize attention weights using plotters
fn visualize_attention(attention: &Tensor, output_path: &str) -> Result<(), Box<dyn Error>> {
let root = BitMapBackend::new(output_path, (800, 600)).into_drawing_area();
root.fill(&WHITE)?;
let mut chart = ChartBuilder::on(&root)
.caption("Attention Weights", ("sans-serif", 50).into_font())
.margin(10)
.x_label_area_size(30)
.y_label_area_size(30)
.build_cartesian_2d(0..63, 0..63)?;
chart.configure_mesh().draw()?;
for head in 0..attention.size()[1] {
let attn_head = attention.get(0).get(head.into());
let heatmap_data: Vec<((i32, i32), f64)> = (0..64)
.flat_map(|i| {
let attn_head = &attn_head;
(0..64).map(move |j| ((i as i32, j as i32), attn_head.double_value(&[i as i64, j as i64])))
})
.collect();
chart.draw_series(
heatmap_data.into_iter().map(|((x, y), val)| {
Rectangle::new(
[(x, y), (x + 1, y + 1)],
Palette99::pick((val * 99.0) as usize).filled(),
)
}),
)?;
}
root.present()?;
Ok(())
}
fn main() -> Result<(), Box<dyn Error>> {
let mut model = TransformerModel::new();
let input = Tensor::randn(&[1, 64], (Kind::Float, Device::Cpu));
let _output = model.forward(&input);
// Pass the reference to attention_weights directly to Arc without cloning
let attention_weights = Arc::new(model.get_attention_weights());
let results = Arc::new(Mutex::new(vec![]));
thread::scope(|s| {
for (i, attn) in attention_weights.iter().enumerate() {
let attn = attn.shallow_clone();
let output_path = format!("attention_layer_{}.png", i);
let results = Arc::clone(&results);
s.spawn(move |_| {
if let Err(e) = visualize_attention(&attn, &output_path) {
eprintln!("Error visualizing attention for layer {}: {}", i, e);
} else {
println!("Saved attention visualization to {}", output_path);
results.lock().unwrap().push(output_path);
}
});
}
})
.unwrap();
Ok(())
}
The code defines a TransformerModel struct to simulate a transformer with attention weights generated during the forward pass. In main, after initializing the model and running a forward pass on a sample input, the attention weights are accessed and wrapped in an Arc (Atomic Reference Counter), making them safely shareable across threads. The crossbeam crate is then used to spawn a thread for each attention head, allowing each thread to generate and save a heatmap visualization concurrently. The visualize_attention function creates a plot for each attention head, iterating over each coordinate pair to calculate attention values. The use of Arc ensures safe access to shared data among threads, while Mutex is used to collect output file paths without race conditions. This design leverages Rust’s concurrency model for thread-safe parallelism, optimizing visualization tasks for efficiency and speed.
In practice, these techniques are applied across various industries to ensure that LLMs are both effective and responsible in their outputs. In the financial sector, feature attribution is used to analyze LLM-generated forecasts, helping experts understand which economic indicators or historical events the model has prioritized in its predictions. This kind of interpretability is crucial for compliance, as regulatory bodies require transparency in algorithmic decision-making, especially in high-stakes scenarios. Attention visualization is valuable in customer support applications, where understanding the flow of attention across tokens can help optimize the model’s responses and ensure it addresses customer queries accurately. Surrogate models find application in healthcare, where they serve as interpretable approximations for more complex models used in diagnostic tools, providing insights into the factors that influence a model’s recommendations for treatment options.
In summary, improving interpretability in LLMs is essential for responsible AI deployment, and Rust provides a unique platform for implementing efficient, reliable interpretability techniques. As industries increasingly rely on LLMs for decision-making, having access to transparent models that offer clear insights into their internal workings is critical. Rust-based tools for feature attribution, attention visualization, and surrogate modeling enable practitioners to explore LLMs’ complex behaviors in a controlled, interpretable manner, supporting ethical, effective, and trustworthy applications. The latest trends in interpretability research underscore the importance of hybrid approaches that combine multiple interpretability methods to provide a comprehensive view of model behavior, a direction that Rust’s robust ecosystem is well-positioned to support. Through these advancements, Rust emerges as a powerful language for advancing interpretability in AI, bridging the gap between model complexity and human understanding.
24.3. Explainability Techniques for LLM Outputs
As large language models (LLMs) become more integral to various applications, understanding how they arrive at specific outputs is crucial for trust, transparency, and accountability. Explainability focuses on making individual model predictions or responses understandable, which is essential in cases where LLMs yield unexpected, incorrect, or sensitive outputs. Techniques like SHAP (SHapley Additive exPlanations), LIME (Local Interpretable Model-agnostic Explanations), and counterfactual explanations offer ways to demystify these outputs. SHAP and LIME quantify the contributions of input features to a model’s output, while counterfactual explanations explore how slight changes in input could lead to different predictions. Applying these explainability techniques to LLMs presents both challenges and opportunities. The inherent complexity of LLMs complicates the generation of accurate, meaningful explanations, but success in this area enables deeper insights into model behavior and supports informed decision-making in high-stakes fields like healthcare, finance, and law.
Figure 3: Common methods for explainability of LLMs (SHAP, LIME and Counterfactual).
SHAP, derived from cooperative game theory, is one of the most widely used techniques for feature attribution. SHAP values are based on Shapley values, which allocate the "contribution" of each input feature towards the final output by treating each feature as a "player" in a cooperative game. For an LLM, SHAP values help identify which input tokens or phrases had the most influence on generating a particular output. Mathematically, SHAP values are computed by averaging the marginal contributions of each feature across all possible feature subsets. For Rust implementations, SHAP calculations involve manipulating large sets of input combinations and aggregating their marginal effects on model outputs, which requires efficient memory handling and concurrency for scalability. In Rust, parallel computation using multithreading is feasible and often necessary due to the combinatorial nature of Shapley values. By using Rust’s threading capabilities, developers can implement SHAP for LLM outputs to reveal the underlying decision patterns and offer interpretable explanations that align with cooperative game theory principles.
LIME provides another approach for understanding specific model predictions by approximating complex models locally. LIME works by generating a series of slightly altered inputs (perturbations) around a specific input, then training a simpler model, such as a linear regression or decision tree, to approximate the LLM’s behavior in that localized input space. For example, in Rust, LIME can be implemented by perturbing text inputs and analyzing changes in model outputs. The perturbed examples are then used to train a simplified model that mimics the LLM’s decision process for the target input. Rust’s capabilities in handling large data operations and implementing high-performance, localized models allow developers to efficiently manage and execute LIME-based explanations. Implementing LIME for LLMs in Rust requires creating a pipeline to process text, generate perturbations, and evaluate model outputs, after which an interpretable surrogate model is trained to approximate the LLM’s responses. This surrogate model, even if simplistic, provides valuable insights into the main factors driving the LLM’s decisions, shedding light on otherwise opaque model outputs.
Counterfactual explanations offer a unique perspective by exploring how small, hypothetical changes in the input could lead to different model predictions. In essence, counterfactuals answer the question, “What would the model output if the input were slightly different?” Counterfactual analysis is particularly valuable for debugging and enhancing LLMs, as it reveals the sensitivity of a model’s output to variations in input. Mathematically, counterfactual explanations involve finding minimal changes to an input vector that would lead to a desired change in output, often posed as an optimization problem. In Rust, a counterfactual framework for LLMs could be implemented by iteratively modifying input tokens and assessing the resulting outputs. For instance, a Rust-based tool could incrementally replace specific tokens in a text input, measuring each modification’s effect on the model’s response. This can help reveal thresholds or key terms that, when altered, significantly influence the model’s behavior. Such insights are useful for quality control, as developers can identify whether a model is overly sensitive to particular terms or phrases, which may indicate a need for retraining or fine-tuning.
Explainability techniques must balance accuracy with interpretability, as highly accurate explanations may sometimes be too complex to understand, while overly simplified explanations may lose critical details. SHAP, LIME, and counterfactual explanations each handle this trade-off differently. SHAP provides mathematically grounded, precise attributions but may require extensive computation for LLMs, given the combinatorial explosion of feature subsets. LIME offers approximate explanations that are interpretable and computationally feasible, although it relies on the quality of the perturbations and the surrogate model’s ability to reflect the LLM’s behavior. Counterfactuals, while directly actionable and intuitive, may lack comprehensive coverage, as they highlight individual "what-if" scenarios rather than an overarching understanding of the model. In Rust, combining these methods can be efficient, especially when leveraging concurrency and memory optimization for computationally intensive tasks. Developers might create hybrid frameworks in Rust that apply SHAP, LIME, and counterfactuals sequentially or selectively, depending on the needs of a particular application.
The practical implementation of these techniques in Rust enables the development of tools that improve user trust and promote transparency. A SHAP-based Rust tool could be integrated into a pipeline for model testing, automatically generating feature attributions for sample outputs and flagging cases where attributions appear inconsistent or unexpected. A LIME-based tool could be used by developers to assess model outputs on a case-by-case basis, providing local explanations whenever unexpected responses arise. Counterfactual tools in Rust could serve as debugging aids, allowing engineers to experiment with input modifications and observe their effects on model behavior in real time. Together, these tools form a comprehensive explainability framework that enables both technical users and stakeholders to gain actionable insights into model performance, enhancing trust and accountability.
This pseudo code describes the process of building two types of analyzers—SHAP and LIME—used to interpret model predictions by analyzing the impact of each word in a given input. The SHAP analyzer iterates through each word in the input, replaces it with a mask, and runs the masked input through the model to estimate each word's individual impact on the prediction. The LIME analyzer works similarly, but instead of masking, it replaces each word with an alternative placeholder. In the code, both analyzers use a shared model_inference function to interact with the model, receiving numerical values to quantify each word's contribution. In the main function, an OpenAI model client is created, and both analyzers use it to generate explanations for a sample question, "Why is the sky blue?", outputting results that indicate how each word influences the model’s responses.
// Define SHAP-based analyzer structure with a model
SHAPAnalyzer:
model: reference to OpenAI model
// Constructor to initialize SHAPAnalyzer with a model
new(model):
set self.model to model
// Method to explain the model’s response based on SHAP
explain(input):
split input into words (tokens)
shap_values = empty list
for each word in tokens:
create perturbed_input by replacing current word with "[MASK]"
explanation = model_inference(perturbed_input)
append explanation to shap_values
return shap_values
// Method to infer explanation score for perturbed input
model_inference(input):
create prompt "Generate response: 'input'"
create step using prompt
create chain with step
output = run chain with model
return parsed output as float score
// Define LIME-based analyzer structure with a model
LIMEAnalyzer:
model: reference to OpenAI model
// Constructor to initialize LIMEAnalyzer with a model
new(model):
set self.model to model
// Method to explain the model’s response based on LIME
explain(input):
split input into words (tokens)
lime_values = empty list
for each word in tokens:
create perturbed_input by replacing current word with "..."
score = model_inference(perturbed_input)
append (perturbed_input, score) to lime_values
return lime_values
// Method to infer explanation score for perturbed input
model_inference(input):
create prompt "Generate response: 'input'"
create step using prompt
create chain with step
output = run chain with model
return parsed output as float score
// Main function to execute the SHAP and LIME analyzers
main:
initialize OpenAI model client
model = create OpenAIExecutor with client
// Initialize analyzers with the model
shap_analyzer = new SHAPAnalyzer(model)
lime_analyzer = new LIMEAnalyzer(model)
input = "Why is the sky blue?"
// Get explanations using SHAP and LIME analyzers
shap_result = shap_analyzer.explain(input)
print "SHAP explanation:", shap_result
lime_result = lime_analyzer.explain(input)
print "LIME explanation:", lime_result
The pseudo code describes two analyzer structures, SHAPAnalyzer and LIMEAnalyzer, each with methods for providing explanations based on interpreting model responses for modified inputs. Both analyzers use the model_inference function to replace parts of the input, generate prompts, and execute steps to retrieve an explanation score from a model. The SHAPAnalyzer masks each word in turn with "[MASK]" to analyze its effect on the model’s output, while the LIMEAnalyzer substitutes each word with "..." to approximate the importance of individual words. The main function sets up the OpenAI model client and then runs both SHAP and LIME explanations for a sample input, printing the results to show how each word in the input affects the model's response. This setup allows us to interpret how the model weights each word's contribution.
In the industry, explainability techniques have been instrumental in sectors that demand accountability and transparency. In finance, for instance, regulatory frameworks often require that AI-driven predictions, such as credit scoring or fraud detection, are explainable. By implementing SHAP values in Rust, financial institutions could deploy high-performance models that also satisfy regulatory explainability requirements, offering clear attributions for each decision. In healthcare, where LLMs might assist in generating clinical summaries or diagnostic suggestions, LIME-based tools can help healthcare providers understand the reasons behind specific outputs. Counterfactual explanations are equally valuable, especially in scenarios like patient diagnosis, where changing patient data slightly and observing the model's response provides insights into the factors most relevant to the diagnosis. Such tools, implemented efficiently in Rust, enable real-time interpretability even in resource-constrained environments, like embedded medical devices or financial services.
The latest trends in explainability research highlight a growing preference for hybrid methods that blend SHAP, LIME, and counterfactual explanations. This multi-faceted approach, which Rust is well-suited to handle due to its performance optimization capabilities, allows practitioners to view model behavior from different angles. SHAP can provide detailed attributions, while LIME offers localized insights, and counterfactuals reveal potential for change in model predictions. With Rust’s concurrency model, combining these techniques becomes efficient and scalable, enabling high-throughput explainability for production-grade models. This trend aligns with the increasing demand for interpretability in AI, especially as LLMs find applications in high-stakes, regulated fields where explainability is not just preferred but required.
In conclusion, Rust offers a powerful and efficient platform for implementing explainability techniques for LLM outputs. By developing SHAP, LIME, and counterfactual tools in Rust, developers can create a comprehensive suite of explainability tools that reveal insights into LLM behavior, improve transparency, and foster user trust. These techniques, while challenging to implement, are essential in building robust, ethical AI systems that align with industry standards and regulatory demands. Rust’s memory safety and performance make it uniquely capable of supporting large-scale explainability tasks, positioning it as an ideal language for driving innovation in the field of explainable AI.
24.4. Model-Agnostic vs. Model-Specific Interpretability
In the realm of interpretability for large language models (LLMs), techniques are often classified into two categories: model-agnostic and model-specific. Model-agnostic interpretability techniques are designed to be applied across different types of models, regardless of their underlying architecture. These techniques provide insights into the input-output relationship without leveraging model-specific characteristics, which makes them flexible and adaptable to various settings. Model-specific interpretability techniques, on the other hand, are tailored to particular model architectures, such as transformers. These methods make use of unique structural features of the model, allowing for a deeper understanding of the model’s behavior. Understanding when to apply model-agnostic versus model-specific techniques is crucial for achieving interpretability that is both effective and meaningful for the given application. Rust, with its strong performance capabilities, provides an ideal platform for implementing and comparing these interpretability approaches.
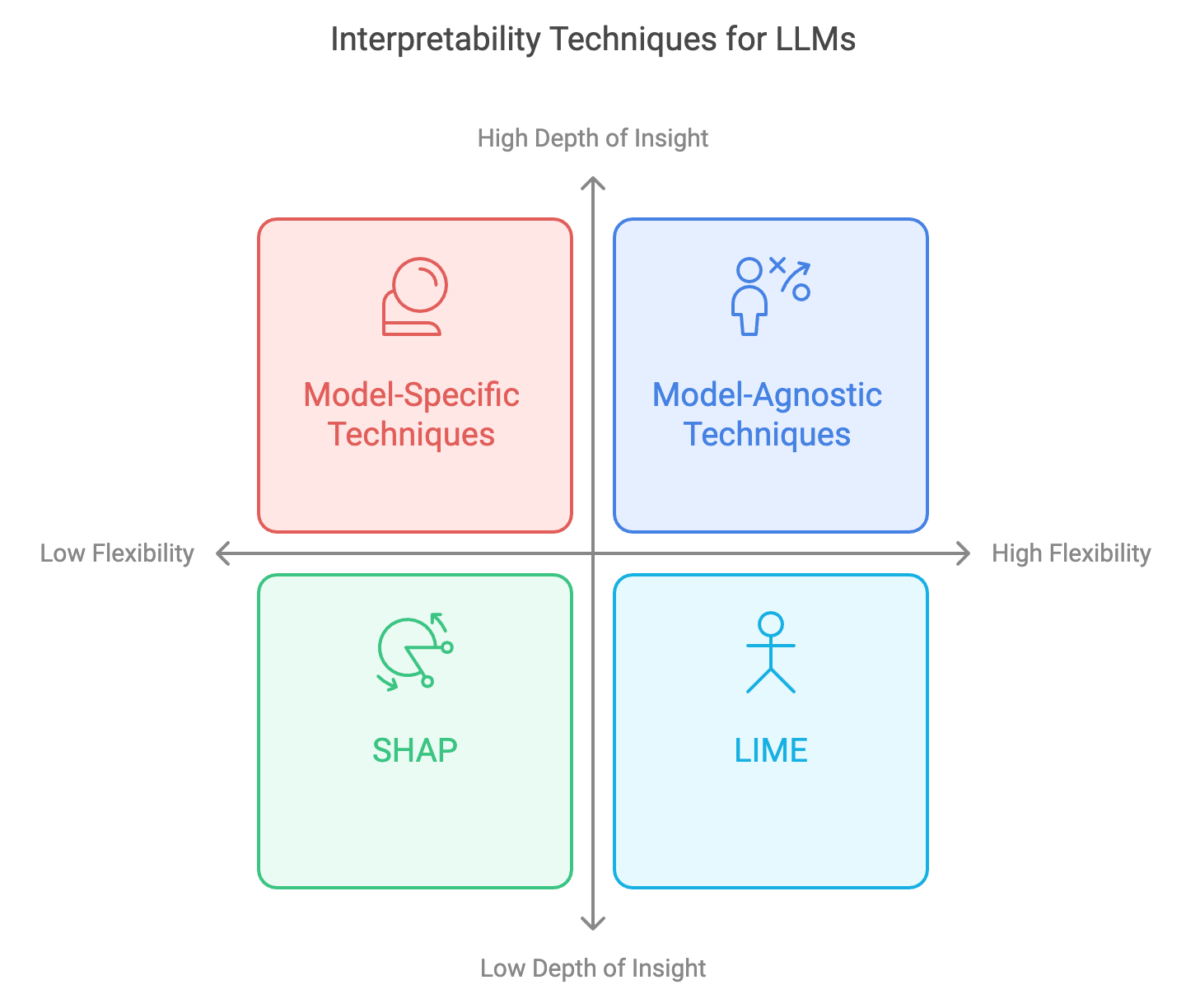
Figure 4: Common strategy for interpretability in LLMs.
Model-agnostic techniques, like SHAP (Shapley Additive ExPlanations) and LIME (Local Interpretable Model-agnostic Explanations), are widely used in interpretability because they can be applied across various types of LLMs. These methods typically work by perturbing the input and observing changes in the output, effectively treating the model as a "black box." For example, SHAP leverages Shapley values to assign importance to each input feature by examining its contributions across different subsets of inputs, following principles from cooperative game theory. Mathematically, SHAP is defined by calculating the marginal contribution of each feature across all possible feature coalitions, which involves complex combinatorial calculations. In Rust, implementing SHAP involves efficiently handling combinations of input subsets and calculating their marginal effects on model outputs. Using Rust’s multithreading and memory safety features can optimize this process, making it feasible to compute SHAP values at scale, even for complex LLMs. By enabling these calculations to be performed concurrently, Rust ensures that model-agnostic interpretability remains efficient, allowing for robust analysis across various types of models in large-scale applications.
LIME, another prominent model-agnostic technique, approximates complex model behaviors by locally fitting a simpler model, such as a linear regression, around a given input point. This technique is particularly valuable in scenarios where localized insights are needed. LIME works by creating perturbations around the input, using the resulting outputs to train a surrogate model that can approximate the LLM's behavior in the immediate vicinity of that input. In Rust, implementing LIME involves generating and processing a large number of perturbed inputs and fitting a surrogate model efficiently. Rust’s strong type system and memory management capabilities help handle these operations with minimal overhead, ensuring that the LIME-based explanations are both accurate and computationally feasible. For developers, Rust’s ecosystem provides a suitable environment to integrate LIME into larger interpretability frameworks, enabling model-agnostic analyses to be applied across different LLMs without compromising on performance.
Model-specific interpretability techniques, in contrast, are designed to exploit the unique characteristics of a specific model architecture. In the case of transformers, the attention mechanism is a defining feature that can be analyzed to understand which tokens the model "pays attention to" at different layers. Attention visualization techniques allow practitioners to inspect the relationships between tokens in the input sequence, revealing patterns in how the model contextualizes information. Mathematically, attention scores are computed as softmax-normalized dot products between token embeddings, forming attention matrices that highlight token dependencies. Implementing attention visualization in Rust involves accessing and processing the attention weights across layers and heads of a transformer. Rust’s high performance and low-level control make it possible to efficiently manipulate large attention matrices, even for models with many layers. By visualizing these attention patterns, practitioners can gain insights into how the transformer model interprets different parts of the input and assigns contextual relevance, which would be difficult to achieve with model-agnostic techniques.
The choice between model-agnostic and model-specific techniques involves considering the trade-offs between flexibility and depth of insight. Model-agnostic techniques are particularly advantageous in regulatory contexts where transparency is required across a range of models, as they provide a consistent approach to interpretability. They can be applied to LLMs, decision trees, and other model types without modification, ensuring that explanations are accessible and consistent. This is especially useful in industries like finance and healthcare, where stakeholders demand interpretability that adheres to regulatory standards. Model-specific techniques, however, offer deeper insights by leveraging model architecture. By understanding unique aspects of the model, such as the layered attention mechanisms in transformers, model-specific techniques allow practitioners to perform a more nuanced analysis, revealing underlying decision patterns and dependencies that model-agnostic methods might miss.
To illustrate these concepts in Rust, a decision framework can be implemented to help guide the choice between model-agnostic and model-specific techniques based on user requirements. For instance, this framework could include a function that evaluates the complexity of the model and its application context, then suggests an appropriate interpretability technique. In Rust, a simple decision framework could be designed using pattern matching and enum-based logic, allowing for flexible selection based on predefined conditions. For example, if the model is a transformer and the task requires insights into token interactions, the framework would recommend a model-specific approach, such as attention visualization. If the application is in a regulated industry requiring cross-model consistency, the framework would suggest model-agnostic techniques like SHAP or LIME.
Testing the robustness and consistency of model-agnostic techniques across different LLMs is essential to validate their applicability in diverse settings. In Rust, this testing can involve creating an automated pipeline that applies SHAP and LIME to various models and assesses the consistency of their explanations. This could be achieved by running each interpretability technique on a range of LLM architectures and comparing the stability and interpretability of the outputs. For example, a Rust-based testing suite could generate SHAP values across different models for the same input, measuring variations in feature importance and identifying inconsistencies. By leveraging Rust’s concurrency and safety features, such a pipeline can run efficiently, handling multiple interpretability processes simultaneously and ensuring accurate, reliable results.
This pseudo code describes a testing pipeline designed to apply SHAP and LIME interpretability techniques to multiple LLM models to test consistency and robustness. The TestingPipeline class accepts a list of models and an input text to test. Its run_tests method iterates over the models, initializing SHAP and LIME analyzers for each model and running explanations on the input text concurrently for efficiency. Results are stored in a dictionary for each model. The assess_consistency method then compares SHAP and LIME outputs across model pairs, identifying any inconsistencies if feature importance values differ significantly. This automated pipeline in the main function provides a systematic way to validate interpretability techniques across various LLM architectures, leveraging concurrency for efficient execution and accurate consistency assessments.
// Define testing pipeline for interpretability techniques across multiple LLMs
TestingPipeline:
models: list of LLM models
input_text: text input for interpretability testing
// Constructor to initialize pipeline with models and input text
new(models, input_text):
set self.models to models
set self.input_text to input_text
// Method to run interpretability tests on all models
run_tests():
results = empty dictionary
// Parallel processing of models for efficiency
for each model in models (concurrently):
shap_analyzer = initialize SHAPAnalyzer with model
lime_analyzer = initialize LIMEAnalyzer with model
shap_result = shap_analyzer.explain(input_text)
lime_result = lime_analyzer.explain(input_text)
// Store SHAP and LIME results for this model
results[model] = { "SHAP": shap_result, "LIME": lime_result }
return results
// Method to assess consistency between models
assess_consistency(results):
inconsistencies = empty list
// For each model's results, compare SHAP and LIME values with others
for each pair of models in results:
compare SHAP and LIME values for differences in feature importance
if differences exceed threshold:
log inconsistency in inconsistencies
return inconsistencies
// Main function to execute testing pipeline
main:
models = list of LLM models (e.g., GPT-3, BERT, LLaMA)
input_text = "Why is the sky blue?"
// Initialize and run testing pipeline
pipeline = new TestingPipeline(models, input_text)
results = pipeline.run_tests()
// Assess consistency of interpretability results across models
inconsistencies = pipeline.assess_consistency(results)
// Output inconsistencies for analysis
print "Inconsistencies found:", inconsistencies
The industry applications for both model-agnostic and model-specific interpretability techniques highlight their importance in building trustworthy AI systems. In sectors such as legal tech, model-agnostic methods are often preferred because they provide consistent explanations regardless of the underlying model architecture, which is essential for compliance and accountability. In fields like natural language processing, where transformers are dominant, model-specific interpretability techniques offer insights into the model’s inner workings, enabling developers to fine-tune and improve their models with a better understanding of token dependencies and attention patterns. By using Rust to develop these interpretability tools, practitioners can achieve high-performance, scalable solutions that support comprehensive interpretability across various industries.
In conclusion, both model-agnostic and model-specific interpretability techniques have valuable roles in understanding and improving LLMs. Model-agnostic techniques offer flexibility and are ideal for regulated environments, while model-specific techniques provide deeper insights by leveraging the unique characteristics of specific models, particularly transformers. Rust’s efficiency, concurrency, and memory safety make it an excellent choice for implementing and comparing these interpretability methods, allowing developers to build powerful, scalable tools that enhance transparency in AI. As trends in explainability research move toward hybrid approaches that incorporate both model-agnostic and model-specific methods, Rust’s capabilities in managing complex computations and large datasets position it as a foundational tool for advancing interpretability and explainability in large language models.
24.5. Evaluating the Effectiveness of Interpretability and Explainability
Evaluating interpretability and explainability is essential to ensure that large language models (LLMs) not only function accurately but are also understood by a range of stakeholders. This evaluation often revolves around specific metrics and benchmarks that measure how well an interpretability or explainability technique helps users understand, trust, and interact with the model. Effectiveness in this context is multi-dimensional; it includes metrics such as clarity, completeness, and relevance, and often involves subjective measures of user trust and satisfaction. These evaluations are particularly relevant in industries where transparency is critical, such as finance and healthcare, where regulatory standards demand not only accurate models but also explanations that can be clearly understood by end-users and regulators. Rust, with its speed and efficiency, provides a practical foundation for building evaluation frameworks that can assess interpretability and explainability metrics rigorously and at scale.
Figure 5: Process to evaluate interpretability metrics of LLMs using Rust.
Evaluating interpretability techniques typically begins with identifying key metrics that are both relevant to the stakeholders and feasible to measure. Common metrics include trust, satisfaction, and understanding. Trust measures the extent to which users feel confident in the model's predictions after receiving explanations, satisfaction assesses the user's overall experience with the interpretability tool, and understanding gauges how well users can explain the model's behavior or decisions after reading the explanations. These metrics, though valuable, are challenging to quantify directly, as they depend heavily on context and user background. For instance, developers and data scientists might focus on technical explanations and transparency in model decisions, while end-users and regulators might prioritize comprehensibility and ease of interpretation. A Rust-based framework for evaluating these metrics can provide a structured way to collect data, execute user studies, and calculate statistical indicators that measure these often subjective aspects of interpretability.
One approach to building an evaluation framework in Rust involves creating a set of metrics that assess explanations on both objective and subjective criteria. Objective criteria might include the consistency of explanations (measured by repeatability of outputs given similar inputs) and completeness (evaluating whether the explanation covers all influential input features). Subjective criteria, on the other hand, rely on user feedback. For instance, a satisfaction metric could be captured by presenting users with a Likert scale survey after they interact with the explanation tool. In Rust, these metrics can be implemented within a structured framework using Rust’s concurrency capabilities to handle multiple user feedback forms and input-output analyses simultaneously, ensuring that the evaluation process is both responsive and scalable. This framework could utilize data structures optimized for concurrent access and operations, such as Rust’s atomic reference-counted pointers and thread-safe containers, allowing developers to conduct large-scale user studies efficiently.
In addition to formal metrics, user studies play an essential role in evaluating interpretability and explainability, as they offer direct insights into how real users perceive and interact with model explanations. Designing effective user studies in Rust entails creating an interface that collects and processes feedback in real-time, allowing evaluators to monitor trends and identify areas for improvement. For example, a Rust-based tool could present a model explanation to users and then prompt them with questions about the clarity, completeness, and usefulness of the explanation. Rust’s speed and stability ensure that even complex input-response workflows are handled smoothly, making it suitable for real-time user studies. The collected feedback can then be analyzed statistically to determine trends in user satisfaction and understanding. This feedback loop is invaluable for refining interpretability techniques, as it helps developers understand the specific needs of their users and adjust their explanations accordingly.
One of the main challenges in measuring interpretability and explainability is balancing the level of detail in explanations with the risk of overwhelming users. Detailed explanations are beneficial for technical audiences, such as developers and analysts, who seek a comprehensive understanding of the model’s behavior. However, for non-technical stakeholders, extensive details can reduce comprehension and lead to user fatigue. This balance is often quantified through comprehension scores, which measure how well users understand a model’s behavior based on a given explanation. In Rust, these scores can be calculated by tracking user responses to questions that test their understanding of model outputs after reading an explanation. A Rust-based evaluation framework can use scoring mechanisms and dynamically adjust the complexity of explanations based on user profiles, ensuring that explanations are optimally tailored to each user’s comprehension level.
To gain a comprehensive understanding of interpretability effectiveness, it is useful to evaluate the consistency and robustness of explanations across different models and scenarios. Model-agnostic techniques like SHAP and LIME, for instance, should provide stable explanations across different LLM architectures if they are truly robust and interpretable. By implementing consistency checks within a Rust-based framework, developers can compare how explanations vary for similar inputs across models. This involves running the interpretability method on different LLM architectures and calculating consistency scores, which indicate how much the explanations align. Rust’s performance capabilities allow for such large-scale evaluations to be run efficiently, making it feasible to benchmark interpretability techniques across various settings and validate their reliability.
This pseudo code sets up a framework to test the consistency and robustness of SHAP and LIME interpretability techniques across multiple LLM models. The InterpretabilityFramework class takes a list of models, an input text, and a threshold for acceptable variance in explanations. Its run_consistency_checks method applies SHAP and LIME to each model concurrently, storing the results for each model in a dictionary. It then compares the SHAP and LIME explanations between pairs of models, calculating a consistency score based on the variance. If the variance falls below the threshold, the explanations are considered "consistent"; otherwise, they’re "inconsistent." The main function initializes the framework with selected models, runs the tests, and outputs the consistency scores, enabling developers to assess the reliability of SHAP and LIME explanations across different models.
// Define interpretability testing framework to evaluate explanation consistency
InterpretabilityFramework:
models: list of LLM models
input_text: text input for consistency testing
threshold: acceptable level of variance for consistency
// Constructor to initialize framework with models, input, and threshold
new(models, input_text, threshold):
set self.models to models
set self.input_text to input_text
set self.threshold to threshold
// Method to generate explanations and compute consistency scores
run_consistency_checks():
explanations = empty dictionary
// Run SHAP and LIME for each model concurrently
for each model in models (concurrently):
shap_analyzer = initialize SHAPAnalyzer with model
lime_analyzer = initialize LIMEAnalyzer with model
shap_result = shap_analyzer.explain(input_text)
lime_result = lime_analyzer.explain(input_text)
// Store SHAP and LIME results for each model
explanations[model] = { "SHAP": shap_result, "LIME": lime_result }
// Calculate consistency scores between model explanations
consistency_scores = empty dictionary
for each pair of models in explanations:
shap_consistency = calculate_consistency(explanations[model1]["SHAP"], explanations[model2]["SHAP"])
lime_consistency = calculate_consistency(explanations[model1]["LIME"], explanations[model2]["LIME"])
// Store scores
consistency_scores[(model1, model2)] = { "SHAP": shap_consistency, "LIME": lime_consistency }
return consistency_scores
// Method to calculate consistency between two sets of explanations
calculate_consistency(explanation1, explanation2):
calculate variance between explanation1 and explanation2
if variance <= threshold:
return "consistent"
else:
return "inconsistent"
// Main function to execute interpretability framework
main:
models = list of LLM models (e.g., GPT-3, BERT, LLaMA)
input_text = "Why is the sky blue?"
threshold = 0.1 // Define acceptable variance level
// Initialize framework and run consistency checks
framework = new InterpretabilityFramework(models, input_text, threshold)
consistency_scores = framework.run_consistency_checks()
// Output consistency scores for analysis
print "Consistency scores across models:", consistency_scores
Industry applications illustrate the importance of thorough evaluation in interpretability and explainability. In healthcare, for instance, clinicians rely on model explanations to validate automated recommendations for diagnostics or treatments. In these cases, a robust evaluation framework could include user studies with healthcare professionals to assess their understanding and trust in model explanations. This might involve presenting explanations generated by interpretability tools like attention visualization and gradient-based feature attribution and assessing whether the professionals find these explanations clear and clinically relevant. Rust’s concurrent processing capabilities make it possible to handle such evaluations in real-time, ensuring a responsive and seamless experience for users who may be evaluating explanations in critical, time-sensitive contexts. In finance, where regulatory standards often mandate model transparency, model-agnostic explanations are evaluated on consistency and clarity to ensure they meet compliance requirements. Rust can handle high-frequency assessments across large datasets, making it a viable choice for ensuring compliance across a financial institution’s machine learning models.
The latest trends in interpretability evaluation emphasize hybrid approaches that combine formal metrics with subjective user feedback to provide a multi-dimensional view of explainability effectiveness. By integrating both quantitative data from formal metrics and qualitative insights from user studies, evaluators can capture a more complete picture of how well explanations meet the needs of diverse stakeholders. Rust is particularly suited to hybrid evaluation frameworks, as it allows developers to handle large-scale metric calculations alongside real-time user feedback, combining these data streams in a single, efficient system. This enables ongoing refinement of interpretability tools based on direct user input, resulting in explanations that are both accurate and accessible.
In conclusion, evaluating the effectiveness of interpretability and explainability is a multi-faceted process that involves measuring trust, satisfaction, understanding, and robustness. Rust provides an ideal environment for implementing these evaluations due to its concurrency, efficiency, and reliability, allowing developers to create structured, scalable frameworks for interpretability assessment. By combining formal metrics with user feedback, Rust-based evaluation frameworks can capture both the quantitative and qualitative dimensions of interpretability, enabling developers to refine their models and explanations iteratively. This ensures that LLMs remain transparent, accountable, and aligned with the needs of their users, ultimately advancing the field of trustworthy AI.
24.6. Ethical and Regulatory Considerations
As large language models (LLMs) become increasingly influential in domains such as healthcare, finance, and law, ethical and regulatory considerations surrounding their interpretability and explainability have taken on critical importance. Deploying opaque or "black-box" models without mechanisms for transparency can lead to severe consequences, including diminished trust, unchecked biases, and, in some cases, non-compliance with regulations. The ethical implications of opaque LLMs stem from their potential to make decisions that significantly impact human lives without offering clear justifications or explanations. Moreover, LLMs trained on biased or skewed data are at risk of perpetuating or even amplifying biases within their outputs. Regulatory bodies around the world are increasingly aware of these risks, prompting the development of laws that mandate transparency, fairness, and accountability in AI systems. By focusing on interpretability and explainability, practitioners can work toward building ethical, transparent, and regulatory-compliant LLMs, an effort well-supported by the Rust programming language due to its reliability, speed, and safety features.

Figure 6: Ethical and compliance concerns of LLMs.
The ethical issues tied to LLMs are multifaceted, particularly in settings where decisions directly affect individuals. For example, when an LLM is used in financial lending, it might evaluate an applicant’s profile and make recommendations regarding creditworthiness. If this decision-making process is opaque, applicants may find it difficult to understand why they were denied credit, which not only affects trust but could also conceal discriminatory practices. Ethical guidelines in AI stress the importance of model interpretability as a means of revealing how certain input features influence decisions. Techniques like feature attribution and counterfactual explanations are essential in making these influences transparent. Feature attribution highlights which input features are most significant in the decision, while counterfactuals allow users to explore how slight changes in input data might alter the output. Implementing these techniques in Rust enables efficient and reliable execution, especially in high-stakes applications. Rust’s memory safety and speed ensure that these interpretability calculations are both secure and scalable, meeting the performance demands of real-world deployments.
Regulatory frameworks in many regions are evolving to address AI transparency, with several countries introducing specific requirements for AI models used in sensitive domains. In the European Union, the General Data Protection Regulation (GDPR) includes provisions for “right to explanation,” where users impacted by automated decisions have the right to know the rationale behind these decisions. In the United States, sectors like finance and healthcare are subject to rigorous standards that emphasize transparency and accountability. For instance, the Equal Credit Opportunity Act (ECOA) requires fairness and non-discrimination in credit decisions, which indirectly demands transparent and interpretable models to detect and prevent biases. Implementing compliance tools in Rust allows companies to systematically verify that their LLMs meet regulatory requirements for fairness and transparency. A Rust-based compliance framework could automate checks for bias, track feature attributions, and validate that explanations are consistently available. This approach is not only efficient but also aligns with Rust’s emphasis on correctness and reliability, essential attributes for tools handling regulatory compliance in AI.
To address the ethical and regulatory challenges, interpretability techniques in Rust can play a significant role in mitigating biases and promoting fairness. For instance, by examining the attention weights in transformer-based models, developers can observe patterns that may inadvertently prioritize certain types of content over others, potentially reflecting biases present in training data. In Rust, developers can implement tools to audit attention mechanisms by inspecting these weights across different layers and input cases, helping to detect and address potential biases. Additionally, Rust-based tools can perform fairness assessments by analyzing model outputs for various demographic groups, identifying patterns that could lead to biased or unfair treatment. This assessment can be extended by using surrogate models or counterfactual explanations to provide alternative outputs, revealing whether the LLM treats different groups equitably.
Transparency and accountability in AI development are not just technical concerns but foundational pillars of responsible AI. Accountability requires clear documentation and auditable processes, ensuring that developers can track and verify model behavior over time. Rust’s strength in managing large datasets with low latency enables the creation of logging systems that document model inputs, outputs, and interpretation data in real time. For instance, a Rust-based logging framework could record the intermediate states of interpretability techniques, such as feature attributions, and store this information securely. In regulated environments, this logged data provides a basis for audits, ensuring that organizations can demonstrate accountability for their LLMs. By implementing explainability and interpretability features as auditable processes within Rust, developers can contribute to a trustworthy AI pipeline that can withstand scrutiny from regulatory bodies and stakeholders alike.
Case studies from various industries highlight the value of interpretability for meeting ethical and regulatory standards. In healthcare, for example, LLMs are used to generate diagnostic summaries or recommend treatments. Here, interpretability is critical, as medical professionals need to understand the reasoning behind AI-generated suggestions to ensure patient safety. By implementing interpretable models with feature attribution techniques in Rust, healthcare providers can create AI systems that align with ethical standards and maintain transparency in life-critical decisions. In finance, the implementation of interpretable LLMs enables banks and financial institutions to adhere to transparency requirements when assessing loan applications or detecting fraud. A Rust-based compliance tool could automatically generate SHAP values for specific predictions, ensuring that credit decisions are explainable and fair. In these cases, Rust’s speed and safety allow for high-frequency, reliable interpretability analyses, making it a suitable choice for such regulated applications.
The latest trends in AI ethics and regulation point toward the growing necessity of hybrid interpretability frameworks that incorporate multiple explainability techniques. Such frameworks combine feature attributions, counterfactuals, and surrogate models to provide a holistic view of an LLM’s behavior. This approach enables a nuanced understanding of model decisions, which is especially valuable in regulated domains where a single explanation technique may not be sufficient. Rust’s performance and concurrency capabilities allow developers to implement these hybrid frameworks efficiently, managing multiple interpretability methods within a single platform. This combination enables organizations to produce comprehensive explanations that meet the complex ethical and regulatory demands of modern AI applications.
In summary, ethical and regulatory considerations are fundamental to the responsible deployment of LLMs, particularly in domains where the consequences of opaque models can be severe. Rust provides a powerful foundation for building interpretability and explainability tools that meet these ethical and regulatory requirements, allowing developers to implement feature attribution, counterfactual analysis, and logging frameworks that ensure transparency, fairness, and accountability. By leveraging Rust’s efficiency and safety, these tools can operate at scale, enabling developers to create AI systems that are both high-performing and aligned with industry standards. As trends in AI ethics and regulation continue to evolve, Rust’s role in supporting robust interpretability solutions will become increasingly valuable, promoting the responsible and ethical deployment of large language models across various fields.
24.7. Future Directions in Interpretability and Explainability
As large language models (LLMs) continue to increase in scale and complexity, the fields of interpretability and explainability face significant new challenges. Current trends indicate a strong movement toward more advanced and integrated interpretability tools, particularly as regulatory bodies and industries call for higher standards in AI transparency. With complex architectures like transformers, the traditional methods of interpreting models—such as feature attribution and local explanations—are proving insufficient to handle the intricacies of modern LLMs. This chapter will explore the cutting-edge techniques and methodologies that are emerging to meet these challenges, with an emphasis on explainability-by-design approaches. In this paradigm, interpretability is embedded directly into the model architecture and training processes, allowing for native interpretability rather than relying on post-hoc explanations. Rust’s performance capabilities and low-level control provide a unique foundation for developing and testing these innovative interpretability techniques, potentially shaping a new era of transparent and responsible AI.
Figure 7: Proposed model for advancing LLM interpretability using Rust.
One major limitation of current interpretability techniques is their inability to scale with the increasing complexity of LLMs. Modern models, with billions of parameters and intricate dependencies, demand interpretability methods that can handle high-dimensional data effectively. Traditional feature attribution techniques, for instance, are computationally intensive and often fail to capture the deeper relationships within the model. In response to these limitations, researchers are exploring AI-assisted interpretability, where machine learning itself is used to generate and refine explanations. This can involve using simpler, interpretable models to approximate the behavior of complex LLMs or leveraging reinforcement learning to iteratively improve the clarity and relevance of explanations. In Rust, these techniques can be implemented by utilizing high-performance computing tools, allowing for the real-time generation of surrogate models or reinforcement learning processes to refine explanations on the fly. The efficiency of Rust’s memory management enables developers to handle the large volumes of data required for such interpretability approaches without compromising speed or reliability.
Explainability-by-design represents another promising future direction, emphasizing the integration of transparency mechanisms directly within the model’s architecture. For example, researchers are investigating architectures that output explanations alongside predictions, effectively creating models that self-explain as part of their operation. This might involve designing models with attention mechanisms that are constrained to focus on interpretable features or structuring models in a way that enforces modular, interpretable layers. Formal mathematical constraints can guide these structures, ensuring that the model’s intermediate states and final outputs align with human-understandable concepts. For Rust developers, experimenting with explainability-by-design involves creating custom model architectures and training procedures, where transparency constraints are encoded into the model layers themselves. By implementing such architectures in Rust, developers can build models that generate inherently interpretable outputs, reducing the reliance on post-hoc explanations and increasing the robustness of model interpretability.
Another emerging area involves the intersection of interpretability with cognitive science, ethics, and law, highlighting the importance of interdisciplinary collaboration. Cognitive science, for instance, can offer insights into how humans naturally interpret information, providing a framework for designing explanations that are intuitively understandable. By aligning interpretability tools with human cognitive processes, explanations can be made more accessible to non-technical users. In Rust, implementing cognitively informed explanations might involve designing explanation systems that simplify information hierarchically or emphasize contextually relevant features based on principles from cognitive load theory. For regulated industries, legal expertise is also essential to ensure that interpretability tools align with compliance standards and ethical guidelines. By working with legal experts, Rust developers can design interpretability frameworks that adhere to evolving regulatory requirements, automating compliance checks and ensuring transparent record-keeping for auditing purposes. In healthcare, for example, transparency requirements could involve explanations that prioritize clinically relevant features, and a Rust-based interpretability tool could be designed to automatically filter and highlight these elements, simplifying the model’s complexity for medical professionals.
In practical terms, advancing interpretability requires continual experimentation with new techniques. For instance, developers can experiment in Rust with feature sparsity techniques, which constrain the model to use fewer features in its decision-making process, making the output easier to interpret. In a Rust-based environment, this can be achieved by implementing optimization functions that penalize feature redundancy during training. Similarly, developers could test novel visualization techniques for transformer attention patterns, such as using dynamic graphs to represent token interactions across multiple layers. Rust’s performance strengths support the efficient computation of these high-dimensional visualizations, allowing for real-time exploration of token relationships within large language models. These advanced interpretability tools, designed with Rust’s performance capabilities in mind, enable practitioners to gain a detailed view of model behavior without sacrificing computational efficiency.
Moreover, Rust provides an ideal environment for analyzing and evaluating emerging tools that are shaping the future of interpretability. As new libraries and technologies for interpretability emerge, Rust developers have the opportunity to integrate these tools within scalable, performance-driven frameworks. For example, using Rust’s powerful trait system, developers can design modular interpretability libraries that support multiple techniques—such as feature attribution, attention visualization, and surrogate modeling—within a single, extensible system. This modular design approach not only simplifies the development process but also ensures that each interpretability tool can be reused or replaced as needed. As a result, developers are equipped to respond flexibly to advances in interpretability, maintaining high standards of transparency and explainability as AI technology continues to evolve.
In the industry, the demand for interpretable models is particularly strong in sectors where AI-driven decisions have significant ethical and social consequences. The finance industry, for example, relies heavily on transparent AI systems to meet regulatory compliance and foster trust with clients. By integrating explainability-by-design techniques in Rust, financial institutions can deploy LLMs that provide transparent credit scoring, fraud detection, and investment recommendations. Rust-based interpretability tools, equipped with feature attribution and visualization capabilities, can offer clients detailed insights into AI decisions, supporting informed decision-making and mitigating risks associated with opaque models. Similarly, in autonomous systems, interpretable models are essential for safety and ethical accountability. Rust’s performance and safety make it an ideal choice for developing interpretability solutions for autonomous vehicles and drones, where understanding model behavior is crucial for ensuring safe and ethical operation.
The latest trends in explainability research indicate a shift towards more proactive approaches, where interpretability is not just a diagnostic tool but a design principle built into the model’s lifecycle. This shift is evident in the movement toward hybrid interpretability frameworks that combine multiple techniques to provide comprehensive insights into model behavior. By integrating feature attribution, attention mechanisms, and cognitive models into a single interpretability framework, Rust developers can create tools that offer a holistic view of LLM outputs. These hybrid frameworks are particularly relevant for multi-modal systems, where text, image, and audio data intersect, requiring interpretability techniques that account for diverse data modalities. Rust’s concurrency capabilities and data handling efficiency enable developers to manage and process these complex data types seamlessly, ensuring that interpretability is maintained across different input formats and model architectures.
In conclusion, the future of interpretability and explainability in large language models hinges on advancing techniques, tools, and methodologies that keep pace with the increasing complexity of AI systems. Explainability-by-design, AI-assisted interpretability, and interdisciplinary approaches represent key directions that can enable more transparent and ethical deployment of LLMs. Rust, with its performance optimization, memory safety, and concurrency support, is positioned to play a crucial role in developing these next-generation interpretability solutions. By leveraging Rust for both experimental and production-level interpretability tools, developers can build scalable, robust, and ethically sound AI systems that are equipped to meet the demands of transparency and accountability in the coming era of artificial intelligence.
24.8. Conclusion
Chapter 24 underscores the vital role of interpretability and explainability in ensuring that large language models are both powerful and trustworthy. By leveraging the techniques and tools discussed, readers can develop LLMs that are not only effective but also transparent and aligned with ethical standards, paving the way for responsible AI applications.
24.8.1. Further Learning with GenAI
Each prompt is crafted to challenge your understanding and encourage you to think critically about how these concepts can be practically applied using Rust.
Describe the key differences between interpretability and explainability in LLMs. How do these concepts impact the design and deployment of AI systems in real-world applications, and why are they crucial for building trust in AI?
Discuss the challenges of achieving interpretability in complex models like LLMs. How does model complexity hinder transparency, and what strategies can be employed to enhance interpretability without sacrificing performance?
Explain the role of feature attribution techniques in improving the interpretability of LLMs. How can Rust be used to implement feature attribution, and what insights can this technique provide into the decision-making processes of LLMs?
Analyze the trade-offs between model complexity and interpretability. How can simplifying a model improve its transparency, and what are the potential drawbacks of reducing model complexity? Provide examples of when and how to balance these trade-offs.
Explore the use of attention visualization in transformer-based LLMs. How does visualizing attention mechanisms contribute to understanding how these models process information, and how can Rust be used to develop tools for attention visualization?
Discuss the implementation of surrogate models as a method for enhancing interpretability in LLMs. How do surrogate models work, and what are the advantages and limitations of using them to approximate the behavior of more complex models?
Explain how SHAP (SHapley Additive exPlanations) can be applied to LLM outputs to provide interpretable explanations. How does SHAP work, and how can it be implemented using Rust to analyze specific decisions made by LLMs?
Explore the concept of LIME (Local Interpretable Model-agnostic Explanations) and its application to LLMs. How does LIME generate explanations, and what are the benefits and challenges of using LIME in the context of large language models?
Discuss the use of counterfactual explanations to understand LLM outputs. How do counterfactuals help identify the impact of small input changes on model decisions, and how can Rust be used to generate and analyze counterfactual explanations?
Differentiate between model-agnostic and model-specific interpretability techniques. When should each approach be used, and how can Rust be employed to implement these techniques for different types of LLMs?
Analyze the effectiveness of model-agnostic interpretability techniques in providing insights across different LLM architectures. What are the strengths and weaknesses of these techniques, and how can Rust be used to ensure their robustness and consistency?
Discuss the metrics and benchmarks used to evaluate the effectiveness of interpretability and explainability techniques. How can these metrics be implemented in Rust to assess how well LLMs meet interpretability standards?
Explore the role of user studies in evaluating the effectiveness of explainability techniques. How can feedback from users be collected and analyzed to improve the clarity and usefulness of LLM explanations, and how can Rust support this process?
Explain the ethical implications of deploying opaque LLMs in critical applications such as healthcare, finance, and law. How can interpretability and explainability help mitigate risks and ensure that AI systems are used responsibly?
Discuss the regulatory requirements for transparency in AI systems, particularly in sensitive domains. How can Rust-based tools be developed to ensure that LLMs comply with these regulations and maintain high standards of transparency and fairness?
Analyze the potential advancements in interpretability and explainability techniques for increasingly complex LLMs. What emerging trends and technologies could enhance our ability to understand and trust these models, and how can Rust play a role in this development?
Explore the concept of explainability-by-design. How can models be built with interpretability as a core feature from the outset, and what are the benefits and challenges of this approach? Provide examples of how Rust can be used to implement explainability-by-design.
Discuss the potential for AI-assisted interpretability, where machine learning techniques are used to generate and refine explanations. How could this approach improve the transparency of LLMs, and what role can Rust play in developing these AI-assisted tools?
Examine the interdisciplinary collaboration needed to advance interpretability in AI, involving fields such as cognitive science, ethics, and law. How can Rust be used to develop tools that incorporate insights from these disciplines to create more interpretable and explainable models?
Discuss the future directions of interpretability and explainability in LLMs. How might advancements in AI, natural language processing, and machine learning influence the development of new interpretability techniques, and how can Rust be positioned to support these innovations?
Each prompt encourages you to think critically about the ethical, technical, and practical aspects of deploying interpretable AI systems, helping you build models that are not only powerful but also trustworthy and aligned with responsible AI practices.
24.8.1. Further Learning with GenAI
Self-Exercise 24.1: Implementing Feature Attribution in LLMs
Objective: To implement feature attribution techniques in Rust that can identify and explain which input features are most influential in the outputs of a large language model (LLM).
Tasks:
Research and select a feature attribution method suitable for LLMs, such as SHAP or Integrated Gradients.
Implement the selected feature attribution method using Rust, ensuring that it can be applied to LLM outputs for detailed analysis.
Apply the feature attribution method to a sample LLM to identify the most influential input features for various outputs.
Analyze the results, comparing the influence of different features across various test cases, and document the insights gained.
Deliverables:
A Rust-based implementation of the feature attribution method, including source code and documentation.
A detailed report analyzing the results of the feature attribution, highlighting key insights and the influence of different input features.
Recommendations for refining the LLM based on the feature attribution analysis, focusing on improving model interpretability.
Self-Exercise 24.2: Visualizing Attention Mechanisms in Transformer-based LLMs
Objective: To develop a tool in Rust that visualizes the attention mechanisms in transformer-based LLMs, helping to interpret how these models process information and make decisions.
Tasks:
Study the architecture of transformer-based models, focusing on how attention mechanisms operate within these models.
Design and implement a Rust-based tool that can visualize the attention patterns within a transformer-based LLM, allowing for the exploration of how the model focuses on different parts of the input data.
Apply the visualization tool to various examples, analyzing how attention shifts across different layers of the model for different input sequences.
Evaluate the usefulness of the visualization tool in improving the interpretability of the model’s decisions and document the findings.
Deliverables:
A Rust-based tool for visualizing attention mechanisms in transformer models, including source code and usage documentation.
A set of visualizations demonstrating attention patterns in a sample LLM, with detailed analysis and interpretation.
A report evaluating the effectiveness of attention visualization in enhancing model interpretability, with suggestions for further improvements.
Self-Exercise 24.3: Generating Counterfactual Explanations for LLM Outputs
Objective: To create a Rust-based framework that generates counterfactual explanations for LLM outputs, providing insights into how small changes in input data can alter the model’s predictions.
Tasks:
Research the concept of counterfactual explanations and how they can be applied to LLMs to improve explainability.
Design and implement a Rust framework that generates counterfactual explanations by identifying minimal changes to input data that lead to different model outputs.
Test the framework on a variety of LLM outputs, generating counterfactuals and analyzing how changes in input affect the model’s decisions.
Document the findings, focusing on the interpretability of the counterfactual explanations and their ability to provide actionable insights into the model’s behavior.
Deliverables:
A Rust-based framework for generating counterfactual explanations, complete with source code and usage documentation.
A collection of counterfactual explanations for a sample LLM, accompanied by detailed analysis and interpretation.
A report on the effectiveness of counterfactual explanations in enhancing the interpretability of LLMs, with recommendations for further development.
Self-Exercise 24.4: Developing Model-Agnostic Interpretability Techniques
Objective: To implement model-agnostic interpretability techniques in Rust that can be applied to various LLM architectures to provide consistent insights into model behavior.
Tasks:
Research model-agnostic interpretability techniques, such as LIME or SHAP, that can be applied across different LLM architectures.
Implement the selected model-agnostic technique using Rust, ensuring that it can be adapted to work with different types of LLMs.
Apply the technique to a variety of LLM architectures, comparing the interpretability insights gained across models with different structures and complexities.
Analyze the robustness and consistency of the model-agnostic technique, documenting any variations in interpretability across different LLMs.
Deliverables:
A Rust-based implementation of the model-agnostic interpretability technique, including source code and documentation.
A comparative analysis of the interpretability insights provided by the technique across different LLM architectures.
A report evaluating the robustness and consistency of the model-agnostic technique, with suggestions for enhancing its applicability across diverse LLMs.
Self-Exercise 24.5: Evaluating Interpretability Techniques with User Studies
Objective: To design and conduct user studies that evaluate the effectiveness of different interpretability techniques implemented in Rust, focusing on how well these techniques help users understand LLM outputs.
Tasks:
Select a range of interpretability techniques (e.g., feature attribution, attention visualization, counterfactual explanations) that have been implemented in Rust.
Design a user study that evaluates how effectively these techniques help users understand and trust the outputs of LLMs, including the creation of evaluation criteria and user feedback forms.
Conduct the user study with a diverse group of participants, gathering feedback on the clarity, usefulness, and impact of the interpretability techniques.
Analyze the feedback, identifying strengths and weaknesses in each technique’s ability to enhance interpretability, and document the findings.
Deliverables:
A detailed design of the user study, including evaluation criteria, feedback forms, and participant selection guidelines.
A comprehensive report analyzing the results of the user study, focusing on user feedback and the effectiveness of each interpretability technique.
Recommendations for improving the interpretability techniques based on user feedback, with a focus on enhancing their practical application in real-world scenarios.
Comments