Chapter 23
Testing the Quality of Large Language Models
"The trust we place in AI systems stems not just from their capabilities, but from our ability to rigorously test and understand their limitations." — Fei-Fei Li
Chapter 23 of LMVR presents a thorough exploration of testing the quality of large language models (LLMs) using Rust. It covers a wide range of testing methodologies, including automated frameworks, manual evaluations, and human-in-the-loop approaches, ensuring that LLMs meet high standards of accuracy, fluency, robustness, and fairness. The chapter also delves into critical aspects such as bias detection, security assessments, and the integration of continuous quality assurance through CI/CD pipelines. Through practical implementations and case studies, readers gain the tools and strategies necessary to rigorously evaluate and maintain the quality of LLMs, ensuring they are reliable, trustworthy, and ethically sound.
23.1. Quality Testing in Large Language Models (LLMs)
Testing the quality of Large Language Models (LLMs) is essential to ensure these models deliver high-quality, reliable, and ethical results, particularly as they become widely used in critical areas like healthcare, finance, education, and customer service. The quality of LLM responses must be evaluated across several dimensions, including accuracy, fluency, robustness, fairness, and contextual relevance, each of which plays a vital role in the model’s real-world performance. A structured and multi-faceted approach to testing—incorporating automated testing, manual assessments, and human-in-the-loop processes—is required to effectively address these diverse aspects.
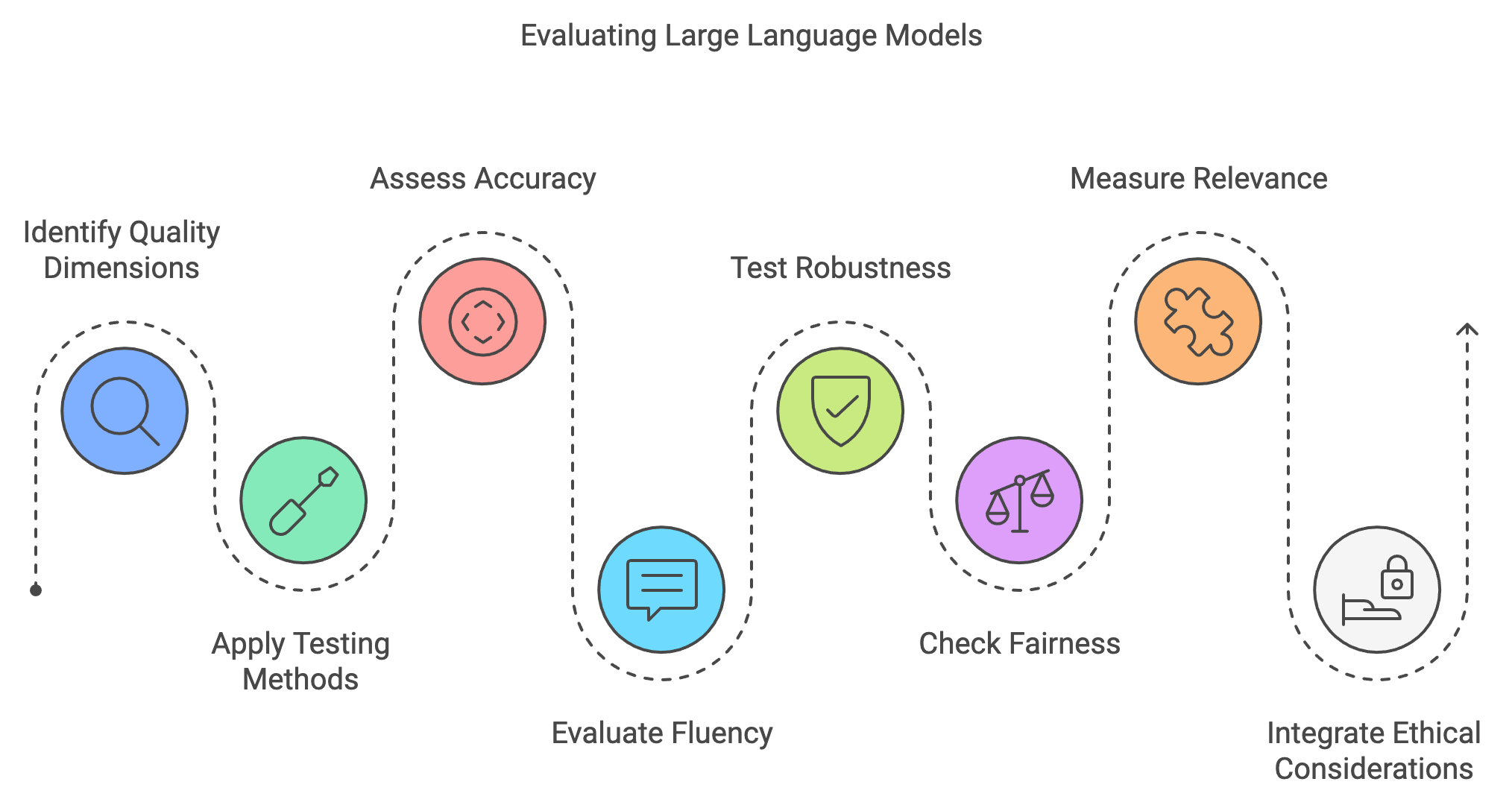
Figure 1: Common process to evaluate LLM quality.
Accuracy is a key metric in evaluating LLM quality, as it assesses the model's ability to provide correct and contextually appropriate answers. This metric is particularly crucial for applications in high-stakes fields, where incorrect responses could lead to significant consequences for users. In healthcare, for example, responses must be factually precise, whereas, in finance, the model should accurately interpret technical queries. Testing accuracy often involves task-specific benchmarks or datasets designed to evaluate knowledge in a given domain, supplemented by expert assessments to ensure accuracy in complex fields.
Fluency, another core quality metric, measures the model’s ability to produce grammatically correct, readable, and natural-sounding language. For LLMs used in end-user interactions, fluency is crucial for effective communication and user trust. Automated metrics like perplexity, which measures the uncertainty in the model’s predictions, can offer some insights into fluency, but human evaluations are often necessary to gauge whether the output meets conversational standards and sounds natural.
Robustness is the model’s resilience to varied or adversarial inputs. To perform well, an LLM must handle a range of inputs, including ambiguous or noisy queries, without generating misleading or erroneous responses. Testing for robustness often involves adversarial testing, in which challenging or edge-case inputs are presented to the model, as well as evaluating its ability to generalize beyond the training data. Techniques like stress testing and mutation testing, where inputs are intentionally modified, are commonly used to assess this dimension of quality.
Fairness in LLMs is essential for preventing inappropriate or biased outputs, as bias can reinforce harmful stereotypes, misrepresent groups, or produce unequal responses across demographic lines. Fairness testing involves evaluating model responses across various demographic groups and examining any potential disparities in response quality or content. Metrics like demographic parity, equalized odds, and fairness auditing techniques help monitor potential biases. In cases where bias is subtle or complex, human reviewers play an indispensable role in ensuring the model’s outputs are fair and unbiased.
Relevance and coherence go beyond factual accuracy, as they measure the contextual appropriateness and logical flow of the model’s responses. This is particularly important for multi-turn interactions where each response should logically build upon prior exchanges. Assessing relevance often relies on human evaluations, particularly for applications like customer support or educational content where response appropriateness and logical consistency are vital.
Various testing methods and metrics help evaluate these quality dimensions. Automated evaluation metrics, such as BLEU (Bilingual Evaluation Understudy), measure the overlap between the model's output and reference responses, especially useful in tasks like translation or paraphrasing. BLEU is calculated as
$$ \text{BLEU} = \exp \left( \frac{1}{N} \sum_{n=1}^{N} \log P_n \right) \cdot BP $$
where $P_n$ represents the precision for each n-gram level, and $BP$, the brevity penalty, discourages excessively short responses. While BLEU offers a quantitative measure of similarity, it often fails to capture subtleties like semantic coherence or creativity. Another automated metric, perplexity, measures the model’s uncertainty in generating responses, with lower perplexity indicating higher fluency and stability in output.
Human evaluation is crucial, especially when automated metrics cannot capture qualities like creativity, contextual nuance, and conversational tone. Human-in-the-loop evaluations provide feedback on whether a response, for example, feels empathetic in a customer service interaction or is age-appropriate in educational content. For domain-specific applications, task-specific metrics and benchmarks further assess whether the model meets particular regulatory standards or domain-specific expectations, such as those in healthcare or legal contexts.
Evaluating LLMs is uniquely challenging due to the vast and variable nature of language. Unlike deterministic models, LLMs generate probabilistic outputs, meaning a single prompt can yield multiple valid responses. Additionally, the influence of ambiguous language, cultural variations, and context sensitivity make it challenging to comprehensively evaluate model quality. To overcome these challenges, a combination of quantitative and qualitative assessments is necessary to achieve a balanced understanding of the model’s capabilities.
Balancing rigorous testing with efficient development cycles is essential, and continuous testing offers a solution. This approach allows testing to occur iteratively throughout the development process, making it possible to identify and address issues early while avoiding the risk of delaying development. Continuous testing strategies include regression testing, which ensures that new model updates do not degrade prior performance, and A/B testing, which compares different model versions in live settings to see which performs better according to user feedback. Incorporating real-world user feedback provides valuable insights, especially for tasks with high variability, allowing the model to improve incrementally.
A well-rounded approach to LLM testing not only covers accuracy, fluency, robustness, fairness, and relevance but also integrates ethical considerations. Testing protocols must include privacy and security safeguards, along with transparency around the model's limitations. Ensuring ethical deployment involves clear guidelines for data handling, user consent, and communication of potential model limitations.To facilitate LLM testing in Rust, developers can implement a basic testing framework that assesses key metrics like accuracy, fluency, and perplexity. Rust’s performance, memory safety, and robust concurrency make it well-suited for such a task, enabling scalable and efficient testing environments.
This Rust code demonstrates an approach to evaluating language model outputs by computing BLEU and Perplexity scores on generated responses. The task is structured as a two-step process: generating an initial answer to a question and refining that answer based on a follow-up reflection prompt. The code leverages the llm-chain library to create and execute prompts sequentially. For each answer generated, the code calculates a BLEU score to measure similarity between the generated response and a reference answer, as well as a Perplexity score to assess the fluency and coherence of the output.
[dependencies]
tokio = { version = "1", features = ["full", "rt-multi-thread"] }
llm-chain = "0.13.0"
rayon = "1.10.0"
itertools = "0.13.0"
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
use std::error::Error;
use std::collections::HashMap;
use std::f64;
// Function to create the initial prompt for answering a question
fn initial_prompt(question: &str) -> Step {
let template = StringTemplate::from(format!(
"Answer the question: '{}'. Please provide a comprehensive answer.",
question
).as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Function to create the reflection prompt to refine the previous answer
fn reflection_prompt(previous_answer: &str) -> Step {
let template = StringTemplate::from(format!(
"Reflect on the following answer: '{}'. Identify any inaccuracies or improvements, and refine the answer for better accuracy and clarity.",
previous_answer
).as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Function to compute BLEU score
fn compute_bleu_score(candidate: &str, reference: &str, n: usize) -> f64 {
let candidate_tokens: Vec<&str> = candidate.split_whitespace().collect();
let reference_tokens: Vec<&str> = reference.split_whitespace().collect();
let mut candidate_ngrams = HashMap::new();
for ngram in candidate_tokens.windows(n).map(|window| window.join(" ")) {
*candidate_ngrams.entry(ngram).or_insert(0) += 1;
}
let mut reference_ngrams = HashMap::new();
for ngram in reference_tokens.windows(n).map(|window| window.join(" ")) {
*reference_ngrams.entry(ngram).or_insert(0) += 1;
}
let mut overlap_count = 0;
for (ngram, &count) in candidate_ngrams.iter() {
if let Some(&ref_count) = reference_ngrams.get(ngram) {
overlap_count += count.min(ref_count);
}
}
let bleu_precision = if candidate_tokens.len() > 0 {
overlap_count as f64 / candidate_tokens.len() as f64
} else {
0.0
};
bleu_precision
}
// Function to compute Perplexity score (simplified as inverse length for demonstration)
fn compute_perplexity(candidate: &str) -> f64 {
// This is a placeholder; perplexity usually requires model-specific probability scores.
let length = candidate.split_whitespace().count() as f64;
if length > 0.0 {
f64::consts::E.powf(-1.0 / length)
} else {
f64::MAX // Infinite perplexity for empty output
}
}
// Asynchronous function to perform initial answering and reflexive refinement
async fn answer_and_reflect(exec: &impl llm_chain::traits::Executor, question: &str) -> Result<(), Box<dyn Error>> {
// Step 1: Generate an initial answer
let initial_chain = Chain::new(vec![initial_prompt(question)]);
let initial_answer = initial_chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in generating the initial answer".to_string());
println!("Initial Answer: {}", initial_answer);
// Reference answer (for demonstration purposes)
let reference_answer = "The main causes of the fall of the Roman Empire included economic troubles, overreliance on slave labor, military overspending, government corruption, and the arrival of the Huns and other barbarian tribes.";
// Compute BLEU and Perplexity scores for initial answer
let bleu_score = compute_bleu_score(&initial_answer, reference_answer, 2); // Bi-gram BLEU
let perplexity_score = compute_perplexity(&initial_answer);
println!("BLEU Score (Initial Answer): {:.2}", bleu_score);
println!("Perplexity Score (Initial Answer): {:.2}", perplexity_score);
// Step 2: Refine the initial answer through reflection
let reflection_chain = Chain::new(vec![reflection_prompt(&initial_answer)]);
let refined_answer = reflection_chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in reflection process".to_string());
println!("Refined Answer: {}", refined_answer);
// Compute BLEU and Perplexity scores for refined answer
let refined_bleu_score = compute_bleu_score(&refined_answer, reference_answer, 2); // Bi-gram BLEU
let refined_perplexity_score = compute_perplexity(&refined_answer);
println!("BLEU Score (Refined Answer): {:.2}", refined_bleu_score);
println!("Perplexity Score (Refined Answer): {:.2}", refined_perplexity_score);
Ok(())
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Define the question for the initial answer and reflection
let question = "What were the main causes of the fall of the Roman Empire?";
// Run the answer and reflection sequence
answer_and_reflect(&exec, question).await
}
In the code, the initial_prompt and reflection_prompt functions create text prompts for the model, with answer_and_reflect handling the core logic of generating responses and refining them. After each answer is generated, BLEU and Perplexity metrics are computed. The BLEU score counts overlapping bi-grams (two-word sequences) between the generated and reference answers, providing an indication of similarity. Perplexity is simplified as the inverse length of the answer, serving as a proxy for fluency by approximating the model's confidence. The program initializes an executor with an API key and asynchronously runs the answer and reflection sequence, outputting both the raw answers and their respective BLEU and Perplexity scores.
Case studies across various industries underscore the importance of robust testing in LLM deployment. For instance, in customer support automation, companies have found that models with thorough quality testing perform significantly better in terms of user satisfaction. Testing for conversational fluency and user sentiment has allowed these companies to fine-tune responses, leading to higher engagement rates and customer satisfaction. In healthcare, rigorous testing has proven essential for models designed to assist in patient interactions, where accuracy and contextual understanding directly impact user trust and patient safety. By applying a continuous testing approach, these organizations were able to improve their LLMs iteratively, achieving reliability and adherence to compliance standards.
As the field advances, trends in LLM quality testing are evolving towards more sophisticated, multi-metric evaluations. With the advent of multimodal models, quality testing now encompasses not only text-based metrics but also visual and audio assessments. Additionally, human-in-the-loop testing has become more structured, with specific rubrics to evaluate models on criteria such as appropriateness, creativity, and factuality. The development of advanced human-AI feedback loops further refines these assessments, allowing models to learn from human input in real-time, thus continuously improving quality.
Despite these advancements, challenges in LLM quality testing persist. As models grow in complexity, ensuring consistency and minimizing variability in responses remain difficult. Evaluators must account for the model’s probabilistic nature, which can lead to fluctuating outputs for similar inputs. Bias detection is also a growing focus, requiring testing frameworks to include fairness metrics that evaluate whether a model's responses vary unfairly across demographic groups or reflect harmful stereotypes.
In conclusion, quality testing for LLMs is a comprehensive process involving automated metrics, manual evaluation, and continuous testing methodologies to achieve reliable and ethical AI performance. Rust’s efficiency and safety make it an excellent choice for implementing robust testing frameworks, ensuring that LLMs are rigorously evaluated before deployment. This foundational section provides an introduction to the critical components of LLM quality testing, laying the groundwork for the more specialized techniques and advanced evaluations that follow in this chapter. As models continue to evolve, so too must the practices and tools used to test them, positioning quality testing as a dynamic and essential part of LLM development in an ever-expanding field of applications.
23.2. Automated Testing Techniques for LLMs
Automated testing has become an essential component in ensuring the quality of large language models (LLMs), providing a scalable and systematic approach to evaluating various performance aspects. In Rust, a range of testing frameworks and libraries are available that allow developers to build robust automated testing pipelines specifically designed to assess LLMs. Automated tests for LLMs can cover a multitude of scenarios, from verifying basic grammatical correctness to evaluating the model's ability to provide coherent and contextually relevant responses. By integrating these tests into Rust’s efficient ecosystem, we can achieve high-performance and repeatable quality assessments, making it easier to maintain LLM performance as models evolve over time.
The advantages of automated testing lie in its ability to quickly and consistently cover a broad spectrum of potential model behaviors. For example, tests can be developed to check for response coherence by comparing the model’s output against expected patterns or to measure fluency using statistical metrics. Rust’s toolset allows us to construct these automated tests with precision and control over execution, leveraging the language’s memory safety and concurrency features to handle multiple tests simultaneously without compromising system stability. Libraries like proptest enable property-based testing where we can define properties (such as coherence or fluency rules) and validate the model’s responses against these, ensuring reliability across a large range of inputs. Rust’s concurrency capabilities also facilitate the parallel execution of tests, allowing for the efficient processing of complex test suites.
Automated tests in Rust can be designed to cover core quality metrics such as fluency, coherence, and response time. For fluency, automated tests can employ a combination of language modeling metrics such as perplexity, which assesses how well the LLM predicts the next word in a sequence, providing a quantitative measure of how “natural” the output sounds. Perplexity ($P$) can be computed as:
$$ P = 2^{-\frac{1}{N} \sum_{i=1}^N \log_2 p(x_i)} $$
where $p(x_i)$ is the probability of the word xix_ixi given the context. Lower perplexity values indicate better fluency and alignment with natural language patterns, helping to validate the linguistic quality of the LLM output. By implementing such computations in Rust, the tests can run efficiently, even on large datasets.
Beyond basic fluency checks, contextual coherence tests evaluate the model’s ability to generate responses that are relevant and consistent with the prompt context. Coherence tests can involve comparing the model’s response against predefined sets of valid responses or using embeddings to measure semantic similarity. Rust libraries such as rust-bert can be used to generate embeddings for both the prompt and the response, calculating cosine similarity to determine coherence. By combining these tests with Rust's efficient memory management, we can create a comprehensive suite to validate the LLM's context-handling capabilities.
For instance, consider a Rust-based testing suite designed to evaluate coherence and response times of an LLM model. This setup can utilize Rust’s tokio for asynchronous handling, enabling prompt and response comparisons to be executed concurrently. Below is an example that uses both fluency and coherence checks, leveraging tokio and the proptest library to handle a range of input scenarios.
[dependencies]
llm-chain-openai = "0.13.0"
tokio = { version = "1", features = ["full", "rt-multi-thread"] }
llm-chain = "0.13.0"
rayon = "1.10.0"
itertools = "0.13.0"
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use llm_chain_openai::chatgpt::Executor;
use tokio::time::{timeout, Duration};
use std::error::Error;
use std::sync::Arc;
// Placeholder structs for Fluency and Coherence metrics
struct FluencyMetric;
impl FluencyMetric {
fn new() -> Self {
FluencyMetric
}
fn calculate(&self, output: &str) -> f64 {
// Simplified fluency calculation; typically would analyze sentence structure, grammar, etc.
1.0 - (output.len() as f64 / 100.0).min(1.0)
}
}
struct CoherenceMetric;
impl CoherenceMetric {
fn new() -> Self {
CoherenceMetric
}
fn calculate(&self, output: &str, context: &str) -> f64 {
// Simplified coherence calculation; would typically involve semantic similarity.
if output.contains(context) { 1.0 } else { 0.5 }
}
}
// Main struct for automated testing
struct LLMAutomatedTester {
executor: Arc<Executor>,
fluency_metric: FluencyMetric,
coherence_metric: CoherenceMetric,
}
impl LLMAutomatedTester {
async fn new(api_key: &str) -> Result<Self, Box<dyn Error>> {
// Initialize executor with the API key for ChatGPT
let options = options! { ApiKey: api_key.to_string() };
let exec = executor!(chatgpt, options)?;
Ok(Self {
executor: Arc::new(exec),
fluency_metric: FluencyMetric::new(),
coherence_metric: CoherenceMetric::new(),
})
}
async fn test_fluency(&self, input: &str) -> f64 {
let output = self.generate_text(input).await;
self.fluency_metric.calculate(&output)
}
async fn test_coherence(&self, input: &str, expected_context: &str) -> f64 {
let output = self.generate_text(input).await;
self.coherence_metric.calculate(&output, expected_context)
}
async fn test_response_time(&self, input: &str) -> Result<(), &'static str> {
let duration = Duration::from_millis(500);
timeout(duration, self.generate_text(input))
.await
.map_err(|_| "Response too slow")?;
Ok(())
}
async fn generate_text(&self, input: &str) -> String {
let template = StringTemplate::from(format!("Generate a response for: '{}'", input).as_str());
let prompt = Data::text(template);
let step = Step::for_prompt_template(prompt);
let chain = Chain::new(vec![step]);
chain
.run(parameters!(), &*self.executor)
.await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error generating response".to_string())
}
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let tester = LLMAutomatedTester::new("API_KEY_HERE").await?; // Replace with your actual API key
let input = "What is the capital of France?";
let expected_context = "Capital cities of European countries";
let fluency_score = tester.test_fluency(input).await;
let coherence_score = tester.test_coherence(input, expected_context).await;
println!("Fluency Score: {}", fluency_score);
println!("Coherence Score: {}", coherence_score);
match tester.test_response_time(input).await {
Ok(_) => println!("Response time is acceptable."),
Err(e) => println!("{}", e),
}
Ok(())
}
This Rust code defines an automated testing framework for language models, specifically using OpenAI’s ChatGPT through the llm-chain library. The LLMAutomatedTester struct manages an executor to interact with the model and includes metrics for fluency and coherence. The generate_text function prompts the model for a response, while the test_fluency and test_coherence methods use placeholders to score the output on fluency and coherence. test_response_time ensures the model’s response time stays within a specified limit, using tokio::time::timeout for asynchronous timing. In the main function, the framework tests the model’s response to a sample input and outputs scores for fluency, coherence, and response time. This approach allows developers to evaluate model output quality and responsiveness in an automated, structured manner.
Automated testing, however, does have limitations. While it is highly effective for evaluating metrics like response time, fluency, and basic coherence, it often falls short in capturing nuanced elements such as cultural context or ethical considerations. Automated tests cannot yet reliably determine if a response is socially sensitive or if it inadvertently reflects bias. These subtleties usually require human evaluators or more advanced interpretability techniques. Integrating manual review steps alongside automated tests provides a balanced approach, where automated testing handles routine quality checks while human evaluators address higher-level concerns.
In industries such as healthcare or finance, where regulatory compliance and ethical considerations are paramount, automated testing can be extended to include rule-based filters that flag certain language patterns or terms. For instance, healthcare applications could implement filters for terminology alignment with clinical guidelines, ensuring that outputs are in line with professional standards. Similarly, financial applications can incorporate compliance-based testing to confirm that generated financial advice adheres to regulations, with Rust’s error handling and type safety helping prevent runtime failures in these critical areas.
Automated testing is increasingly becoming a mainstay in the LLM quality testing ecosystem. With the integration of tools like tokio for asynchronous tasks and libraries such as proptest for extensive property-based testing, Rust provides an optimal platform for implementing efficient, scalable, and precise automated tests. The use of automated testing also aligns with recent trends in ML Ops, where continuous testing in CI/CD pipelines helps maintain model reliability throughout development cycles, allowing teams to identify performance issues and adapt to changing application requirements proactively.
To conclude, automated testing is an essential element in the lifecycle of LLM development, enabling scalable and repeatable assessments of model quality. By leveraging Rust’s high-performance capabilities, developers can implement a wide array of tests to validate fluency, coherence, response time, and domain-specific compliance. Though automated testing has its limitations, when combined with manual evaluations, it provides a comprehensive approach to model quality assurance. The structured and efficient nature of Rust’s testing ecosystem ensures that LLMs are rigorously vetted, contributing to more reliable, effective, and trustworthy language models in real-world applications.
23.3. Manual Testing and Human-in-the-Loop Approaches
Manual testing and human-in-the-loop (HITL) methodologies offer crucial insights into the quality and reliability of large language models (LLMs), especially in areas that are challenging to assess via automated techniques alone. LLMs produce diverse and complex outputs, and automated testing, while effective for quantitative metrics, often cannot fully capture qualitative aspects like ethical sensitivity, contextual relevance, or creativity. HITL approaches enable human evaluators to directly interact with model outputs, leveraging their intuition, domain expertise, and nuanced understanding of language to evaluate performance in areas where machine-driven tests might overlook critical details.
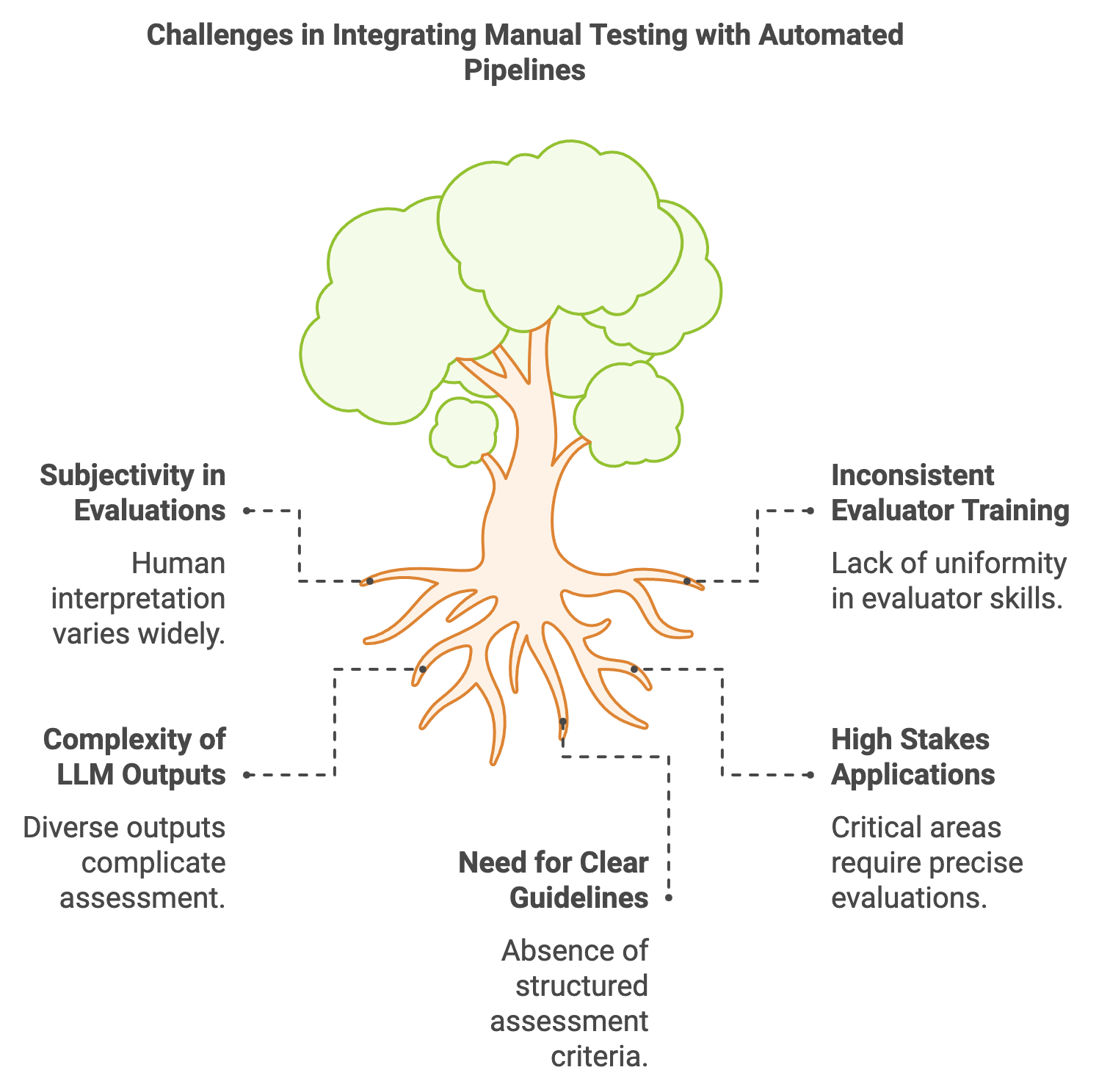
Figure 2: Challenges in integrating manual and automated testings.
Manual testing methodologies, such as qualitative analysis, error annotation, and scenario-based evaluations, provide flexible yet rigorous ways to assess LLMs. Qualitative analysis involves in-depth assessment of output by human reviewers who can detect subtle issues of tone, style, and appropriateness that may not be immediately quantifiable. Error annotation involves a detailed marking of specific issues within the model output, from factual inaccuracies to cultural insensitivity. Scenario-based evaluations are another powerful approach, where evaluators assess outputs in predefined contexts, such as legal or medical scenarios, to ensure that the responses align with professional standards and ethical guidelines. Scenario-based testing also allows for the exploration of model behavior under stress conditions or edge cases, shedding light on how well the model generalizes.
Human evaluators bring invaluable perspectives, but integrating their assessments with automated testing pipelines presents unique challenges. Unlike automated tests, manual assessments can introduce subjectivity, as human interpretation may vary. To mitigate this, careful selection and training of evaluators are essential, particularly in applications with high stakes, such as medical advice or legal consultations. A consistent framework for evaluators, using clear guidelines and checklists, can help maintain reliability. For example, in a medical scenario, evaluators might assess an output based on criteria like clarity, accuracy of medical terminology, and compliance with medical ethics. By defining concrete metrics, human judgment is made more reliable, allowing for structured assessments of otherwise subjective qualities.
Human-in-the-loop systems complement automated testing by bridging the gap between quantitative metrics and qualitative assessments. In a Rust-based HITL testing process, automation and human review are harmoniously combined. Using Rust’s concurrency features, one could create an evaluation pipeline where initial automated tests filter out outputs based on quantitative criteria (e.g., fluency, grammatical accuracy), followed by routing the outputs for which automated tests are inadequate to human evaluators.
This Rust code implements a human-in-the-loop (HITL) system for evaluating responses generated by a language model. It uses the llm-chain library with OpenAI's ChatGPT API to automate response evaluation based on fluency, coherence, and response time. If any evaluation metric falls below a certain threshold, the response is flagged and sent to a human evaluator for further review. The system combines automated testing with human oversight to ensure that model outputs meet quality and ethical standards.
[dependencies]
llm-chain-openai = "0.13.0"
tokio = { version = "1", features = ["full", "rt-multi-thread"] }
llm-chain = "0.13.0"
rayon = "1.10.0"
itertools = "0.13.0"
use tokio::sync::mpsc;
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use llm_chain_openai::chatgpt::Executor;
use tokio::time::{timeout, Duration};
use std::error::Error;
use std::sync::Arc;
struct FluencyMetric;
impl FluencyMetric {
fn new() -> Self {
FluencyMetric
}
fn calculate(&self, output: &str) -> f64 {
1.0 - (output.len() as f64 / 100.0).min(1.0)
}
}
struct CoherenceMetric;
impl CoherenceMetric {
fn new() -> Self {
CoherenceMetric
}
fn calculate(&self, output: &str, context: &str) -> f64 {
if output.contains(context) { 1.0 } else { 0.5 }
}
}
struct LLMAutomatedTester {
executor: Arc<Executor>,
fluency_metric: FluencyMetric,
coherence_metric: CoherenceMetric,
}
impl LLMAutomatedTester {
async fn new(api_key: &str) -> Result<Self, Box<dyn Error>> {
let options = options! { ApiKey: api_key.to_string() };
let exec = executor!(chatgpt, options)?;
Ok(Self {
executor: Arc::new(exec),
fluency_metric: FluencyMetric::new(),
coherence_metric: CoherenceMetric::new(),
})
}
async fn evaluate(&self, input: &str, expected_context: &str) -> Result<EvaluationResult, Box<dyn Error>> {
let output = self.generate_text(input).await;
let fluency_score = self.fluency_metric.calculate(&output);
let coherence_score = self.coherence_metric.calculate(&output, expected_context);
let response_time_result = timeout(Duration::from_millis(500), self.generate_text(input)).await.is_ok();
Ok(EvaluationResult {
fluency_score,
coherence_score,
response_time_ok: response_time_result,
})
}
async fn generate_text(&self, input: &str) -> String {
let template = StringTemplate::from(format!("Generate a response for: '{}'", input).as_str());
let prompt = Data::text(template);
let step = Step::for_prompt_template(prompt);
let chain = Chain::new(vec![step]);
chain
.run(parameters!(), &*self.executor)
.await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error generating response".to_string())
}
}
struct EvaluationResult {
fluency_score: f64,
coherence_score: f64,
response_time_ok: bool,
}
impl EvaluationResult {
fn is_flagged(&self) -> bool {
self.fluency_score < 0.7 || self.coherence_score < 0.7 || !self.response_time_ok
}
}
struct HumanInLoop {
automated_tester: Arc<LLMAutomatedTester>,
tx: mpsc::Sender<String>,
}
impl HumanInLoop {
fn new(automated_tester: Arc<LLMAutomatedTester>, tx: mpsc::Sender<String>) -> Self {
Self { automated_tester, tx }
}
async fn process_output(&self, input: &str, expected_context: &str) -> Result<(), &'static str> {
let initial_test = self.automated_tester.evaluate(input, expected_context).await.map_err(|_| "Evaluation Error")?;
if initial_test.is_flagged() {
self.tx.send(input.to_string()).await.map_err(|_| "Send Error")?;
}
Ok(())
}
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let (tx, mut rx) = mpsc::channel(100);
let automated_tester = Arc::new(LLMAutomatedTester::new("API_KEY_HERE").await?); // Replace with your actual API key
let hitl = HumanInLoop::new(automated_tester.clone(), tx);
tokio::spawn(async move {
while let Some(output) = rx.recv().await {
println!("Manual review needed for: {}", output);
// Here, a human evaluator would access the flagged output
}
});
// Example input that requires ethical evaluation
hitl.process_output("Example input that requires ethical evaluation", "Ethical evaluation context").await.unwrap();
Ok(())
}
The LLMAutomatedTester struct is responsible for evaluating model responses, using placeholder metrics for fluency and coherence and an actual response time check. Its evaluate method generates model responses and calculates scores, returning an EvaluationResult that indicates if a response is flagged for review. The HumanInLoop struct manages this evaluation process and sends flagged responses to a tokio asynchronous channel, where a human reviewer can inspect them. In the main function, flagged responses are received in a separate asynchronous task, enabling real-time human oversight in a system that primarily relies on automated testing.
One significant application of HITL testing is in identifying ethical considerations. For example, HITL processes have been applied in fields such as content moderation and news generation, where the potential for bias or misinformation is high. Case studies from the industry show that models deployed for these applications benefit from regular human oversight. In content moderation, for instance, humans assess language that might be ambiguous or culturally sensitive, making decisions that require a nuanced understanding of societal norms and language subtleties.
While HITL testing adds depth to model evaluations, it also brings scalability challenges. Unlike automated tests, which can process millions of data points in minutes, manual evaluations require careful coordination and time management. Many organizations leverage crowdsourcing platforms to expand their evaluation capacity; however, these solutions can sacrifice quality unless the evaluators are carefully vetted and trained. Recent trends emphasize hybrid HITL setups, where a small, highly trained core team performs primary reviews, supported by a secondary pool for simpler tasks or lower-priority evaluations.
To achieve a balanced HITL framework, organizations might incorporate techniques such as random sampling and weighted scoring, where human evaluators review only a representative portion of outputs, focusing on high-risk or low-confidence results. This helps ensure comprehensive evaluation while controlling for resource costs. For example, in a complex model designed for legal document generation, HITL testing can focus on checking the correctness and legal compliance of randomly selected samples from higher-complexity responses, thus optimizing evaluation without extensive resources.
The future of HITL testing also points toward further integration with machine learning. Techniques in active learning, for instance, identify high-uncertainty cases where models are most likely to fail, routing them to humans for labeling. Using this feedback, model retraining can be more focused and efficient, adapting to areas where human input is critical. Rust’s robust and efficient concurrency handling makes it well-suited for implementing such an active learning system, ensuring smooth coordination between machine evaluations and human assessments.
In conclusion, HITL testing provides an indispensable layer in LLM quality evaluation, particularly for ethical concerns, contextual accuracy, and creativity. Rust’s concurrency and efficient channel communication system enable a streamlined integration of automated and manual processes, allowing LLM developers to achieve nuanced, context-sensitive assessments. Combining automated metrics with structured human feedback yields a more comprehensive evaluation framework, paving the way for language models that are not only powerful but also trustworthy and aligned with societal values.
23.4. Bias and Fairness Testing in LLMs
Bias and fairness testing in large language models (LLMs) has emerged as a critical component in ensuring that these systems produce outputs that are both equitable and socially responsible. As LLMs become increasingly embedded in applications across industries, from hiring platforms to healthcare decision support, their outputs impact a wide range of user groups. Without proper testing for bias, LLMs risk perpetuating and amplifying societal stereotypes or systemic discrimination embedded in training data. Thus, the purpose of bias and fairness testing is to rigorously evaluate the language model’s behavior, uncover sources of bias, and implement interventions that reduce harm while retaining performance quality.
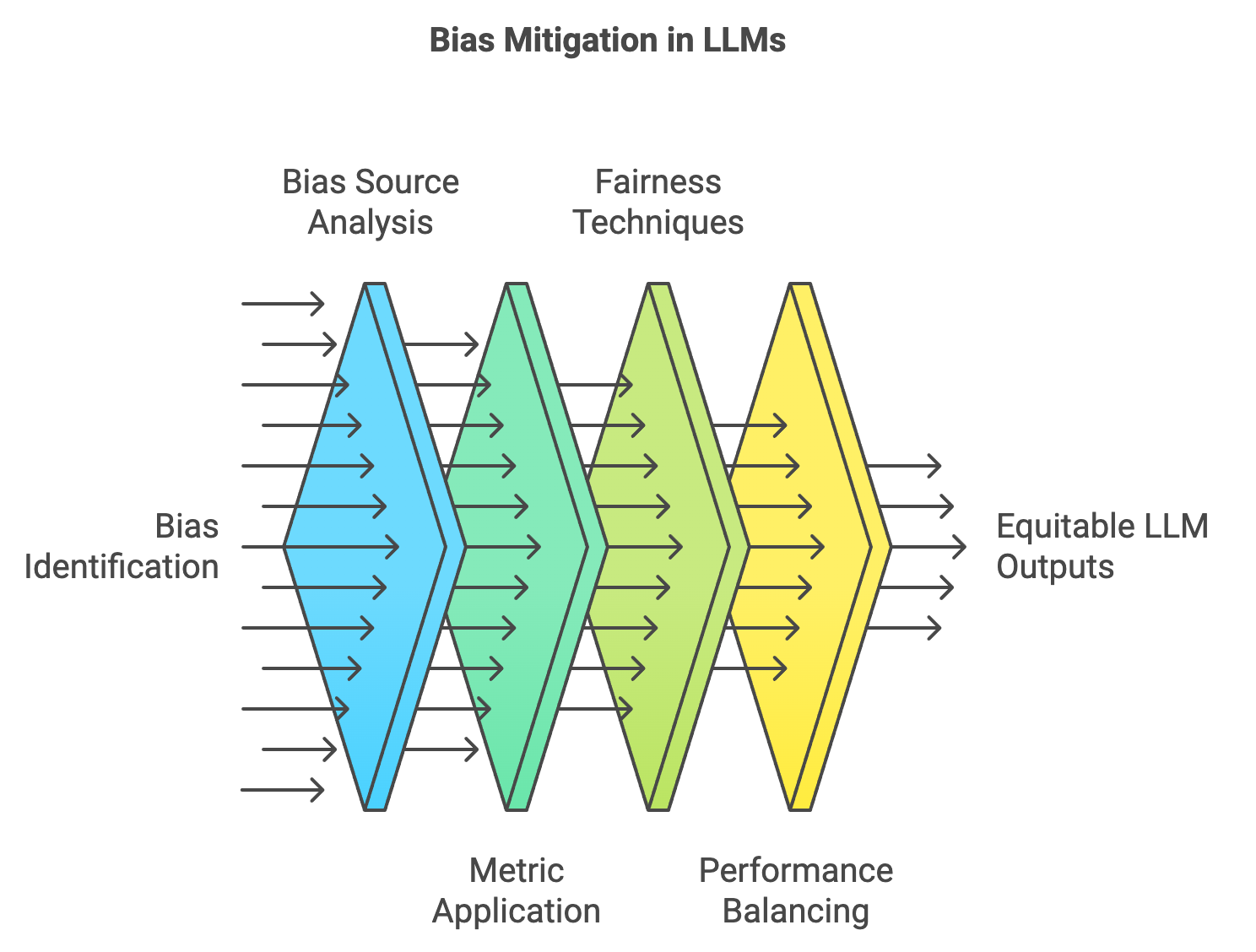
Figure 3: Process of bias identification in LLMs.
One common source of bias in LLMs is the training data, which often reflects societal inequalities and stereotypes. Data-driven biases arise when a model trains on corpora that over-represent or under-represent certain demographics, viewpoints, or behaviors. Algorithmic bias, on the other hand, occurs when model architecture or optimization processes inadvertently amplify these biases. Understanding these biases requires a robust framework to measure their presence and severity. Metrics such as demographic parity, equalized odds, and disparate impact ratio have been introduced to assess how model outputs differ across demographic groups. For language models, these metrics often translate into statistical comparisons between language generated for different identity groups, assessing both lexical choices and sentiment.
Bias and fairness testing metrics are typically grouped into direct and indirect assessments. Direct metrics include statistical measures, such as the occurrence frequency of specific words or phrases associated with gender, race, or other demographics. Indirect metrics examine broader patterns, such as sentiment disparities or contextual associations that reveal implicit bias. For instance, a sentiment analysis can measure if a model systematically associates certain demographic labels with positive or negative language, reflecting deeper biases. Rust’s strong type system and high efficiency make it a suitable language for implementing bias detection tools that quickly assess LLM outputs against these metrics, enabling fast iterations over extensive datasets.
In sensitive applications like law enforcement or healthcare, biased outputs can exacerbate real-world inequalities. For example, a biased model used in predictive policing could disproportionately target specific communities, while in healthcare, biased language recommendations may inadvertently prioritize certain groups over others. To tackle these issues, fairness-aware training techniques like adversarial debiasing, counterfactual data augmentation, and transfer learning from fairness-enhanced datasets are effective. Adversarial debiasing, for instance, involves training the model with an additional adversarial network aimed at reducing biased representations. In Rust, implementing such methods can be achieved through modularity, allowing components like adversarial networks or augmented training data to be integrated seamlessly into the model’s learning pipeline.
From an ethical perspective, balancing fairness with other quality metrics, such as accuracy and fluency, presents unique challenges. Interventions to mitigate bias can sometimes lead to reduced performance in other areas, raising questions about how to prioritize objectives. One approach is to use a Pareto frontier, a multi-objective optimization technique where different goals (e.g., fairness and accuracy) are optimized jointly, finding configurations where trade-offs are minimized. For instance, a Rust-based Pareto optimization function can be written to test different fairness interventions, tracking their impact on accuracy to guide adjustments to the model.
This Rust code demonstrates a human-in-the-loop (HITL) system for evaluating and ensuring the quality of responses generated by a language model. It employs automated testing to assess various aspects of model responses, including fluency, coherence, response time, and potential gender bias. If any issues are detected in these metrics, the system flags the output and sends it for human review, ensuring that the model responses meet high-quality and ethical standards.
use tokio::sync::mpsc;
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use llm_chain_openai::chatgpt::Executor;
use tokio::time::{timeout, Duration};
use std::error::Error;
use std::sync::Arc;
use std::collections::HashMap;
struct FluencyMetric;
impl FluencyMetric {
fn new() -> Self {
FluencyMetric
}
fn calculate(&self, output: &str) -> f64 {
1.0 - (output.len() as f64 / 100.0).min(1.0)
}
}
struct CoherenceMetric;
impl CoherenceMetric {
fn new() -> Self {
CoherenceMetric
}
fn calculate(&self, output: &str, context: &str) -> f64 {
if output.contains(context) { 1.0 } else { 0.5 }
}
}
struct BiasMetric {
gender_terms: HashMap<&'static str, Vec<&'static str>>,
}
impl BiasMetric {
fn new() -> Self {
let mut gender_terms = HashMap::new();
gender_terms.insert("male", vec!["engineer", "doctor", "scientist"]);
gender_terms.insert("female", vec!["nurse", "teacher", "receptionist"]);
BiasMetric { gender_terms }
}
fn detect_gender_bias(&self, text: &str) -> HashMap<&'static str, i32> {
let mut gender_count = HashMap::new();
for (gender, terms) in &self.gender_terms {
let count = terms.iter().filter(|&&term| text.contains(term)).count() as i32;
gender_count.insert(*gender, count);
}
gender_count
}
fn is_flagged(&self, bias_result: &HashMap<&str, i32>) -> bool {
bias_result.get("male").unwrap_or(&0) > &0 && bias_result.get("female").unwrap_or(&0) == &0
}
}
struct LLMAutomatedTester {
executor: Arc<Executor>,
fluency_metric: FluencyMetric,
coherence_metric: CoherenceMetric,
bias_metric: BiasMetric,
}
impl LLMAutomatedTester {
async fn new(api_key: &str) -> Result<Self, Box<dyn Error>> {
let options = options! { ApiKey: api_key.to_string() };
let exec = executor!(chatgpt, options)?;
Ok(Self {
executor: Arc::new(exec),
fluency_metric: FluencyMetric::new(),
coherence_metric: CoherenceMetric::new(),
bias_metric: BiasMetric::new(),
})
}
async fn evaluate(&self, input: &str, expected_context: &str) -> Result<EvaluationResult, Box<dyn Error>> {
let output = self.generate_text(input).await;
let fluency_score = self.fluency_metric.calculate(&output);
let coherence_score = self.coherence_metric.calculate(&output, expected_context);
let response_time_result = timeout(Duration::from_millis(500), self.generate_text(input)).await.is_ok();
let bias_result = self.bias_metric.detect_gender_bias(&output);
let bias_flagged = self.bias_metric.is_flagged(&bias_result);
Ok(EvaluationResult {
fluency_score,
coherence_score,
response_time_ok: response_time_result,
bias_flagged,
})
}
async fn generate_text(&self, input: &str) -> String {
let template = StringTemplate::from(format!("Generate a response for: '{}'", input).as_str());
let prompt = Data::text(template);
let step = Step::for_prompt_template(prompt);
let chain = Chain::new(vec![step]);
chain
.run(parameters!(), &*self.executor)
.await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error generating response".to_string())
}
}
struct EvaluationResult {
fluency_score: f64,
coherence_score: f64,
response_time_ok: bool,
bias_flagged: bool,
}
impl EvaluationResult {
fn is_flagged(&self) -> bool {
self.fluency_score < 0.7 || self.coherence_score < 0.7 || !self.response_time_ok || self.bias_flagged
}
}
struct HumanInLoop {
automated_tester: Arc<LLMAutomatedTester>,
tx: mpsc::Sender<String>,
}
impl HumanInLoop {
fn new(automated_tester: Arc<LLMAutomatedTester>, tx: mpsc::Sender<String>) -> Self {
Self { automated_tester, tx }
}
async fn process_output(&self, input: &str, expected_context: &str) -> Result<(), &'static str> {
let evaluation = self.automated_tester.evaluate(input, expected_context).await.map_err(|_| "Evaluation Error")?;
if evaluation.is_flagged() {
self.tx.send(input.to_string()).await.map_err(|_| "Send Error")?;
}
Ok(())
}
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let (tx, mut rx) = mpsc::channel(100);
let automated_tester = Arc::new(LLMAutomatedTester::new("API_KEY_HERE").await?); // Replace with your actual API key
let hitl = HumanInLoop::new(automated_tester.clone(), tx);
tokio::spawn(async move {
while let Some(output) = rx.recv().await {
println!("Manual review needed for: {}", output);
// Here, a human evaluator would access the flagged output
}
});
// Example input that requires ethical evaluation
hitl.process_output("Example input that requires ethical evaluation", "Ethical evaluation context").await.unwrap();
Ok(())
}
The main component, LLMAutomatedTester, is responsible for generating model responses and evaluating them across several metrics. Fluency and coherence are measured using simple calculations, while response time is monitored with a timeout. A BiasMetric struct identifies potential gender bias by counting the occurrence of gender-associated terms in the response. Results are stored in EvaluationResult, which includes a method to determine if the response should be flagged for manual review. The HumanInLoop struct coordinates this process, automatically passing flagged responses to a tokio channel where they can be accessed by a human evaluator. This setup allows for continuous monitoring and assessment of model outputs with both automated and human oversight.
Bias and fairness testing also demand attention to sensitive categories beyond gender, such as race, ethnicity, and age. Rust’s performance advantages facilitate running comprehensive bias detection across extensive datasets, while its safety features make it well-suited for handling sensitive data securely. Incorporating fairness benchmarks tailored to sensitive applications, such as equal opportunity or demographic parity in law enforcement, ensures that LLMs align with ethical standards and legal regulations.
Real-world case studies illustrate the critical role of bias and fairness testing. In the hiring industry, for instance, LLMs trained to assist with resume screening have faced scrutiny over biases that inadvertently favor specific demographic groups. By deploying fairness testing methodologies during development, these LLMs have been improved to mitigate biased outcomes. Similarly, in customer service automation, fairness testing has been used to ensure that language models respond equitably to customers from diverse backgrounds, fostering inclusivity and enhancing brand trust.
Ultimately, as LLMs become more pervasive, bias and fairness testing must evolve to address new ethical challenges and societal expectations. In Rust, building bias detection and fairness evaluation frameworks ensures that these critical assessments are efficient, reliable, and adaptable to different use cases. By fostering transparency in testing practices, developers can enhance the ethical integrity of LLM applications across industries. The future of bias and fairness testing in LLMs lies in the integration of automated, human-in-the-loop, and adaptive testing methodologies, allowing developers to deploy models that uphold both quality and fairness.
23.5. Robustness and Security Testing in LLMs
The robustness and security of large language models (LLMs) have become crucial in the modern landscape, where these models are widely deployed in applications spanning from customer support to sensitive data analysis. Robustness in LLMs refers to the model’s ability to handle diverse and unexpected inputs, such as noisy or adversarial data, without compromising output quality or reliability. Security, on the other hand, focuses on preventing misuse, safeguarding user data, and protecting the model from malicious exploitation. As LLMs are increasingly exposed to public and high-stakes applications, robustness and security testing have emerged as vital components of the development lifecycle, ensuring resilience against both unintentional and adversarial failures.
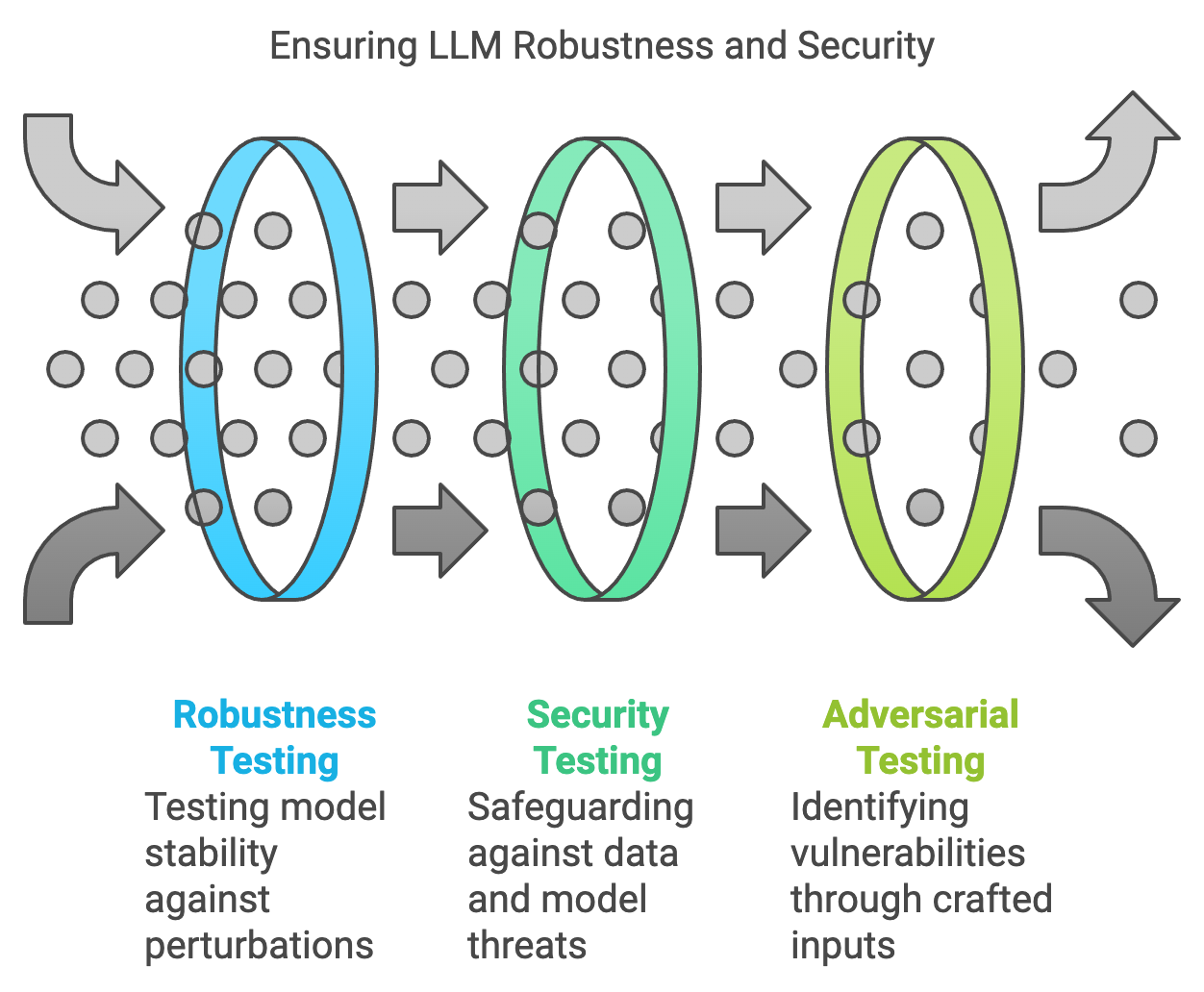
Figure 4: Robustness and Security Tests.
In mathematical terms, robustness in LLMs can be conceptualized through the lens of stability against perturbations. Let $f$ denote the LLM’s function, which maps an input $x$ to an output $y = f(x)$. For a model to be considered robust, minor perturbations in $x$, such as noise or adversarial modifications, should lead to minimal changes in $y$. Formally, this can be expressed as $|f(x + \delta) - f(x)| < \epsilon$ for small perturbations $\delta$ and a threshold $\epsilon$. Security testing, on the other hand, addresses a broader set of concerns, including preventing model inversion attacks—where adversaries attempt to reconstruct training data from model outputs—and protecting the model against adversarial inputs designed to manipulate or crash it. These security concerns are critical in applications dealing with sensitive or personal data, as compromised models can inadvertently expose private information or generate harmful outputs.
Robustness testing methodologies, including adversarial testing and stress testing, help assess the model’s behavior under challenging conditions. Adversarial testing involves generating inputs that are crafted to confuse or mislead the model, revealing vulnerabilities in its decision-making process. In Rust, adversarial testing can be implemented by applying perturbations to input text and observing the model’s response. For instance, an adversarial example might replace synonyms, insert misleading phrases, or introduce punctuation errors, pushing the model’s robustness boundaries. Rust’s high-performance capabilities make it particularly effective for these types of adversarial simulations, as it can handle extensive perturbation tests and large-scale input modifications efficiently.
This Rust code demonstrates a human-in-the-loop (HITL) system that evaluates the robustness, quality, and ethical considerations of responses generated by a language model, particularly under noisy input conditions. The code leverages random input perturbations to test how well the model can handle slightly altered, real-world data inputs. With automated metrics for fluency, coherence, response time, and bias detection, the system flags outputs that may require additional scrutiny, and then sends these flagged responses to human evaluators for further review.
[dependencies]
llm-chain-openai = "0.13.0"
tokio = { version = "1", features = ["full", "rt-multi-thread"] }
llm-chain = "0.13.0"
rayon = "1.10.0"
itertools = "0.13.0"
rand = "0.8.5"
use tokio::sync::mpsc;
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use llm_chain_openai::chatgpt::Executor;
use tokio::time::{timeout, Duration};
use std::error::Error;
use std::sync::Arc;
use rand::Rng;
use std::collections::HashMap;
struct FluencyMetric;
impl FluencyMetric {
fn new() -> Self {
FluencyMetric
}
fn calculate(&self, output: &str) -> f64 {
1.0 - (output.len() as f64 / 100.0).min(1.0)
}
}
struct CoherenceMetric;
impl CoherenceMetric {
fn new() -> Self {
CoherenceMetric
}
fn calculate(&self, output: &str, context: &str) -> f64 {
if output.contains(context) { 1.0 } else { 0.5 }
}
}
struct BiasMetric {
gender_terms: HashMap<&'static str, Vec<&'static str>>,
}
impl BiasMetric {
fn new() -> Self {
let mut gender_terms = HashMap::new();
gender_terms.insert("male", vec!["engineer", "doctor", "scientist"]);
gender_terms.insert("female", vec!["nurse", "teacher", "receptionist"]);
BiasMetric { gender_terms }
}
fn detect_gender_bias(&self, text: &str) -> HashMap<&'static str, i32> {
let mut gender_count = HashMap::new();
for (gender, terms) in &self.gender_terms {
let count = terms.iter().filter(|&&term| text.contains(term)).count() as i32;
gender_count.insert(*gender, count);
}
gender_count
}
fn is_flagged(&self, bias_result: &HashMap<&str, i32>) -> bool {
bias_result.get("male").unwrap_or(&0) > &0 && bias_result.get("female").unwrap_or(&0) == &0
}
}
struct LLMAutomatedTester {
executor: Arc<Executor>,
fluency_metric: FluencyMetric,
coherence_metric: CoherenceMetric,
bias_metric: BiasMetric,
}
impl LLMAutomatedTester {
async fn new(api_key: &str) -> Result<Self, Box<dyn Error>> {
let options = options! { ApiKey: api_key.to_string() };
let exec = executor!(chatgpt, options)?;
Ok(Self {
executor: Arc::new(exec),
fluency_metric: FluencyMetric::new(),
coherence_metric: CoherenceMetric::new(),
bias_metric: BiasMetric::new(),
})
}
// Function to introduce slight random perturbations into a given input
fn perturb_input(&self, input: &str) -> String {
let mut rng = rand::thread_rng();
input
.chars()
.map(|c| {
if rng.gen_bool(0.1) { // 10% chance of perturbing the character
if c.is_alphabetic() {
'X' // replace letters with 'X' as a simple perturbation
} else {
c
}
} else {
c
}
})
.collect()
}
async fn evaluate(&self, input: &str, expected_context: &str) -> Result<EvaluationResult, Box<dyn Error>> {
let perturbed_input = self.perturb_input(input);
let output = self.generate_text(&perturbed_input).await;
let fluency_score = self.fluency_metric.calculate(&output);
let coherence_score = self.coherence_metric.calculate(&output, expected_context);
let response_time_result = timeout(Duration::from_millis(500), self.generate_text(&perturbed_input)).await.is_ok();
let bias_result = self.bias_metric.detect_gender_bias(&output);
let bias_flagged = self.bias_metric.is_flagged(&bias_result);
Ok(EvaluationResult {
fluency_score,
coherence_score,
response_time_ok: response_time_result,
bias_flagged,
perturbed_input,
})
}
async fn generate_text(&self, input: &str) -> String {
let template = StringTemplate::from(format!("Generate a response for: '{}'", input).as_str());
let prompt = Data::text(template);
let step = Step::for_prompt_template(prompt);
let chain = Chain::new(vec![step]);
chain
.run(parameters!(), &*self.executor)
.await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error generating response".to_string())
}
}
struct EvaluationResult {
fluency_score: f64,
coherence_score: f64,
response_time_ok: bool,
bias_flagged: bool,
perturbed_input: String,
}
impl EvaluationResult {
fn is_flagged(&self) -> bool {
self.fluency_score < 0.7 || self.coherence_score < 0.7 || !self.response_time_ok || self.bias_flagged
}
}
struct HumanInLoop {
automated_tester: Arc<LLMAutomatedTester>,
tx: mpsc::Sender<String>,
}
impl HumanInLoop {
fn new(automated_tester: Arc<LLMAutomatedTester>, tx: mpsc::Sender<String>) -> Self {
Self { automated_tester, tx }
}
async fn process_output(&self, input: &str, expected_context: &str) -> Result<(), &'static str> {
let evaluation = self.automated_tester.evaluate(input, expected_context).await.map_err(|_| "Evaluation Error")?;
if evaluation.is_flagged() {
self.tx.send(format!("Flagged Input: {}\nPerturbed Input: {}", input, evaluation.perturbed_input)).await.map_err(|_| "Send Error")?;
}
Ok(())
}
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let (tx, mut rx) = mpsc::channel(100);
let automated_tester = Arc::new(LLMAutomatedTester::new("API_KEY_HERE").await?); // Replace with your actual API key
let hitl = HumanInLoop::new(automated_tester.clone(), tx);
tokio::spawn(async move {
while let Some(output) = rx.recv().await {
println!("Manual review needed for:\n{}", output);
// Here, a human evaluator would access the flagged output
}
});
// Example input that requires robust evaluation
hitl.process_output("Example input that requires robust evaluation", "Evaluation context").await.unwrap();
Ok(())
}
The main structure, LLMAutomatedTester, handles the model’s response generation and evaluation. A key component is the perturb_input function, which introduces random noise into inputs by replacing a small percentage of characters. This altered input, along with the original, is evaluated based on predefined metrics: fluency (to measure readability), coherence (for logical alignment with the context), response time (ensuring timely replies), and bias detection (using gender-related terms). The evaluation results, stored in EvaluationResult, include both the original and perturbed input. If the response fails any criteria, it is flagged, and the HumanInLoop component sends the flagged output to a human reviewer via a message channel. This setup provides a comprehensive approach for testing model responses in a controlled but realistic setting, combining automated and human evaluations.
Security testing in LLMs aims to protect the model from misuse and to secure user data. Key techniques here include penetration testing, where the system is intentionally attacked to identify vulnerabilities, and input sanitization, which filters potentially malicious inputs before they reach the model. For instance, data poisoning attacks can occur when adversaries inject harmful data into the training process, subtly influencing the model’s behavior. Similarly, model inversion attacks exploit the LLM’s structure to reconstruct training data, posing severe privacy risks. Input sanitization, implemented through text preprocessing, removes suspicious patterns or characters that may serve as attack vectors. Rust’s strong concurrency and safety guarantees make it highly effective for implementing such preprocessing at scale.
To illustrate, here’s an example in Rust for input sanitization, which removes potential SQL injection patterns from the input text:
fn sanitize_input(input: &str) -> String {
input.replace("--", "").replace(";", "").replace("'", "")
}
fn main() {
let user_input = "DROP TABLE users; -- SQL Injection attempt";
let sanitized_input = sanitize_input(user_input);
println!("Sanitized Input: {}", sanitized_input);
// Pass `sanitized_input` to the LLM instead of `user_input` for improved security
}
This simple function replaces potentially malicious SQL syntax to prevent injection attacks, providing a foundational approach for securing inputs before they interact with the model. For sensitive applications, more sophisticated sanitization and filtering techniques can be implemented to guard against broader threats.
Real-world cases underscore the importance of robustness and security testing. For instance, in the financial sector, LLMs used in automated trading or risk assessment must be resilient to adversarial inputs that could lead to incorrect trading decisions or expose client data. In another example from healthcare, models assisting in diagnosis need to handle noisy or incomplete patient data reliably. Failures in robustness here can lead to misdiagnoses, affecting patient safety and healthcare outcomes. These case studies reveal that the stakes of robustness and security testing are high, and models must be rigorously assessed to prevent costly or harmful failures.
The trade-off between robustness and performance complexity is a key consideration in model design. More robust models often require additional computational resources, impacting inference speed and scalability. A balanced approach is to employ adversarial training, where models are trained on adversarial examples, boosting resilience while managing performance impacts. Rust’s performance efficiency allows developers to implement and experiment with adversarial training without incurring high overhead costs, making it a powerful tool for achieving this balance.
In summary, robustness and security testing are critical for building resilient, safe, and trustworthy LLMs. Techniques like adversarial testing, penetration testing, and input sanitization in Rust provide a framework for evaluating and hardening LLMs against both accidental and malicious failures. With Rust’s performance capabilities, developers can create robust and secure testing environments that handle extensive evaluations efficiently. As LLMs continue to expand into sensitive domains, these testing practices will only grow in importance, ensuring that LLMs remain secure, dependable, and ready for real-world deployment across diverse applications.
23.6. Case Studies and Best Practices in LLM Quality Testing
Large Language Models (LLMs) have become integral to various industries, and as their deployment grows, so does the importance of rigorous quality testing frameworks. Case studies from diverse fields like healthcare, finance, and customer support reveal how organizations navigate the challenges of testing LLMs for accuracy, scalability, and fairness. Analyzing these real-world implementations provides valuable insights into best practices and industry standards that ensure high-quality LLM outputs. This section presents several case studies, illustrating the key takeaways from successful testing implementations and outlining methodologies that can be adapted and applied in Rust.
A notable case study comes from the financial services industry, where a company implemented LLMs to assist in fraud detection and customer support. The company faced challenges in maintaining the model's accuracy while scaling its deployment across diverse languages and transaction types. The testing framework they used involved a blend of automated and manual tests to validate accuracy and fairness across different demographics. By analyzing performance metrics across scenarios, they employed a two-tiered validation approach: automated scripts that flagged errors in core metrics, and human-in-the-loop (HITL) evaluations to validate interpretability and bias. Their implementation illustrates how a hybrid testing approach can address both quantitative metrics, like response time and error rate, and qualitative assessments, like fairness and relevance. This example demonstrates the importance of layered testing frameworks, where the first layer focuses on automated validation while the second layer employs HITL assessments for nuanced testing criteria.
In Rust, leveraging property-based testing with crates like proptest and performance benchmarking with criterion can enhance the reliability and efficiency of language models (LLMs) in real-world applications. For instance, automated tests can continuously verify critical metrics such as response time, fluency, and stability across model updates. The following example demonstrates benchmarking response time for an LLM, a key metric for ensuring quality and performance in high-demand environments. By evaluating how quickly the model responds, this test helps ensure that the LLM maintains optimal latency, directly impacting user experience in real-time applications like customer support. Additionally, integrating randomized input variations helps assess the model's robustness to unexpected data.
[dependencies]
llm-chain-openai = "0.13.0"
tokio = { version = "1", features = ["full", "rt-multi-thread"] }
llm-chain = "0.13.0"
rayon = "1.10.0"
itertools = "0.13.0"
rand = "0.8.5"
criterion = "0.5.1"
use criterion::{black_box, Criterion, criterion_group, criterion_main};
use tokio::runtime::Runtime;
use std::sync::Arc;
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use llm_chain_openai::chatgpt::Executor;
use std::error::Error;
/// This function benchmarks the response time of an LLM for a given prompt.
/// It initializes a Tokio runtime to handle asynchronous operations and uses
/// the LLMAutomatedTester struct to generate responses. Criterion's `bench_function`
/// and `black_box` are used to measure and prevent optimizations on the benchmarked code.
fn benchmark_response_time(c: &mut Criterion) {
// Create a Tokio runtime to handle asynchronous execution
let rt = Runtime::new().expect("Failed to create runtime");
// Initialize LLMAutomatedTester with an API key for the LLM executor
let tester = rt.block_on(LLMAutomatedTester::new("API_KEY_HERE"))
.expect("Failed to initialize LLMAutomatedTester"); // Replace with actual API key
c.bench_function("LLM response time", |b| {
b.iter(|| {
let input = black_box("Sample prompt text");
// Run the generate_text method asynchronously within the runtime
let response = rt.block_on(tester.generate_text(input));
// Ensure the response is not empty to validate the LLM's output
assert!(!response.is_empty());
})
});
}
/// LLMAutomatedTester is a struct that provides an interface to generate text
/// responses using a language model via the llm_chain library.
struct LLMAutomatedTester {
executor: Arc<Executor>,
}
impl LLMAutomatedTester {
/// Initializes a new LLMAutomatedTester with an API key for accessing the LLM.
async fn new(api_key: &str) -> Result<Self, Box<dyn Error>> {
let options = options! { ApiKey: api_key.to_string() };
let exec = executor!(chatgpt, options)?;
Ok(Self { executor: Arc::new(exec) })
}
/// Asynchronously generates text from a given input prompt.
async fn generate_text(&self, input: &str) -> String {
let template = StringTemplate::from(format!("Generate a response for: '{}'", input).as_str());
let prompt = Data::text(template);
let step = Step::for_prompt_template(prompt);
let chain = Chain::new(vec![step]);
chain
.run(parameters!(), &*self.executor)
.await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error generating response".to_string())
}
}
// Criterion group and main function to register and run the benchmarks
criterion_group!(benches, benchmark_response_time);
criterion_main!(benches);
This Rust code uses the criterion crate to benchmark the response time of a language model (LLM) by repeatedly generating outputs from a sample prompt. Within benchmark_response_time, a Tokio runtime is set up to run asynchronous code, and an instance of LLMAutomatedTester is created, initialized with an API key for interacting with the model via the llm_chain library. The LLMAutomatedTester’s generate_text method constructs a prompt using llm_chain, sends it to the model, and captures the output. In the benchmark function, criterion repeatedly invokes generate_text, measuring the response time for each run. The use of black_box on the prompt input prevents compiler optimizations that could skew timing results, and a simple assertion checks that the model produces a valid (non-empty) output. By tracking the time taken to generate responses, this code assesses the LLM's performance, enabling developers to ensure responsiveness in high-demand, real-time applications.
Another case study highlights LLM deployment in healthcare, where data privacy and model interpretability are primary concerns. Here, the institution employed bias detection tests and interpretability checks as part of their CI/CD pipeline. They automated bias testing by evaluating LLM outputs for sensitive topics across demographic categories. For example, they used differential testing to compare model responses for similar prompts with varied demographic information to identify inconsistencies. The results were then further evaluated by human experts to ensure the absence of unintended biases, particularly in life-impacting decisions like medical diagnoses.
The evolving landscape of LLM testing calls for continually adaptive approaches, particularly as models grow in complexity and application breadth. Emerging trends include the adoption of adversarial testing, which evaluates model resilience against inputs designed to mislead or confuse it. In Rust, adversarial testing can be implemented using quickcheck, where properties of adversarial inputs can be generated and validated to identify vulnerabilities. This method is crucial in identifying edge cases that may cause model failures or degrade user trust.
Through these case studies, best practices in LLM quality testing emerge. The first principle is the necessity of layered testing frameworks, combining both automated and human-based testing methods. Automated testing excels in covering large data sets and repetitive testing of core metrics, while human evaluators are essential for nuanced assessments like ethical implications and creative content evaluation. Secondly, integrating testing into the CI/CD pipeline is essential for maintaining quality across model updates. Tools like GitHub Actions or GitLab CI, combined with Rust’s testing and benchmarking libraries, enable rapid feedback on model changes and facilitate a robust continuous integration process.
For organizations looking to implement these best practices, a practical starting point in Rust involves setting up a two-layered testing framework. This framework can incorporate automated tests for fluency, accuracy, and latency as the first layer, while scenario-based human evaluations compose the second. Additionally, adversarial testing can be embedded within this structure, periodically generating inputs designed to probe model weaknesses and adjusting the model accordingly. By following these structured, multi-layered testing processes, developers can ensure that LLMs maintain high performance, ethical alignment, and resilience against edge cases.
The future of LLM quality testing will likely see advancements in automated interpretability testing and adaptive bias detection. As research progresses, the integration of these tools into testing frameworks will enable organizations to achieve a more comprehensive understanding of model performance, particularly in sensitive applications. Automated interpretability methods, such as relevance attribution, which assigns importance scores to individual prompt components, can enhance model transparency and user trust. Rust’s performance and safety features make it an ideal language for developing these increasingly complex testing frameworks, allowing teams to create scalable, efficient solutions for maintaining LLM quality over time.
In conclusion, case studies and best practices underscore the importance of an adaptable, multi-faceted testing strategy for LLMs. By implementing hybrid testing frameworks, leveraging CI/CD pipelines, and incorporating emerging techniques like adversarial testing, organizations can uphold the quality of their LLM applications across diverse and evolving use cases. Rust, with its rich ecosystem for testing and benchmarking, provides the necessary tools to build and sustain these high standards. Through continuous refinement and integration of advanced testing techniques, developers can ensure that LLMs remain effective, fair, and robust in their respective domains.
23.7. Conclusion
Chapter 23 underscores the importance of comprehensive quality testing in the development and deployment of large language models. By mastering the techniques and tools discussed, readers can ensure that their LLMs deliver high performance while adhering to essential standards of fairness, security, and reliability, paving the way for responsible AI applications.
23.7.1. Further Learning with GenAI
By engaging with these exercises, you will delve into the full spectrum of testing methodologies, from automated and manual evaluations to bias detection and robustness assessments.
Describe in detail the various dimensions of quality in large language models (LLMs), such as accuracy, fluency, robustness, and fairness. How do these dimensions interact with each other, and what are the trade-offs involved in optimizing for one dimension over the others? Provide examples of how these trade-offs manifest in real-world applications.
Discuss the specific challenges inherent in testing LLMs compared to traditional software systems. How do the complexity of natural language, contextual understanding, and the vast range of potential outputs influence the design and implementation of testing frameworks? Provide detailed examples of scenarios where traditional testing approaches fall short.
Outline the process of designing and implementing an automated testing framework for LLMs using Rust. What are the key architectural components, such as data preprocessing, test execution, and result analysis, and how do they interact to provide comprehensive coverage of LLM performance? Include examples of how this framework can be adapted to test different types of language models.
Analyze the effectiveness of various metrics, such as BLEU scores, perplexity, and human evaluation, in assessing the quality of LLM outputs. What are the limitations of these metrics, particularly in capturing the nuances of language generation and contextual relevance? How can these metrics be supplemented or improved to provide a more accurate assessment of model performance?
Explore the role of automated testing in LLM quality assurance. How can automated tests be designed to effectively cover a wide range of linguistic, contextual, and domain-specific scenarios? Discuss the limitations of automated testing, such as its inability to capture subtle linguistic nuances, and suggest ways to address these gaps through complementary testing methods.
Explain the concept and implementation of human-in-the-loop (HITL) testing for LLMs. How does integrating human judgment into the testing process improve the evaluation of complex tasks, such as ethical decision-making, contextual understanding, and creative content generation? Provide a detailed example of a HITL testing workflow and discuss the challenges of scaling this approach.
Discuss in detail the methodologies for detecting and mitigating bias in LLMs. How can Rust-based tools be employed to systematically identify biases in model outputs, and what are the best practices for addressing these biases without compromising other quality metrics, such as accuracy or fluency? Provide examples of biases that are commonly found in LLMs and how they can be corrected.
Examine the complexities involved in balancing fairness with other quality metrics when testing LLMs. How can fairness be quantified and tested alongside accuracy, fluency, and robustness? Discuss specific challenges that arise when optimizing for fairness in LLMs and propose strategies to address these challenges, using Rust-based tools for implementation.
Analyze the importance of robustness testing in LLMs, focusing on their ability to handle noisy inputs, adversarial attacks, and unexpected scenarios. How can robustness be systematically tested and improved using Rust? Provide detailed examples of robustness tests and discuss the implications of robustness on the overall reliability and security of LLMs.
Explain the security considerations involved in deploying LLMs. What techniques can be used to assess and mitigate vulnerabilities, such as susceptibility to adversarial examples, data poisoning, and model inversion attacks? Discuss how Rust can be utilized to implement security tests, and provide examples of potential security threats and their countermeasures.
Discuss the role of continuous quality assurance in the lifecycle of LLM development. How can CI/CD pipelines be designed to automate the testing and deployment of LLMs, ensuring that quality tests are consistently applied with every update? Provide detailed examples of CI/CD integration using Rust, highlighting the challenges and benefits of this approach.
Explore the integration of LLM testing into CI/CD workflows. What are the challenges of achieving scalability, performance, and comprehensive test coverage in a continuous integration environment? Discuss how these challenges can be addressed using Rust, and provide examples of CI/CD pipelines that effectively manage these issues.
Describe the process of setting up a continuous monitoring system for deployed LLMs. How can this system be used to detect and address quality regressions in real-time, ensuring that the LLMs maintain their performance and reliability over time? Provide a detailed implementation plan using Rust, and discuss the key metrics and alerts that should be monitored.
Discuss the ethical implications of biased LLM outputs, particularly in sensitive applications such as hiring, law enforcement, and healthcare. How can ethical testing practices be integrated into the development pipeline to ensure that LLMs produce fair and equitable outputs? Provide examples of ethical testing frameworks and discuss how Rust can be used to implement them.
Analyze the lessons learned from case studies of LLM testing. What best practices have emerged, particularly in terms of ensuring scalability, accuracy, and ethical compliance? Discuss how these practices can be applied to future projects, and propose a Rust-based framework for systematically incorporating these lessons into LLM development.
Explore the use of adversarial testing in assessing the robustness of LLMs. How can Rust-based tools be used to simulate and evaluate the model’s response to adversarial inputs? Provide detailed examples of adversarial testing techniques and discuss the implications of these tests for improving the overall security and robustness of LLMs.
Discuss the importance of transparency and accountability in LLM quality testing. How can the testing processes and results be documented, shared, and verified to build trust with users and stakeholders? Propose a system for maintaining detailed records of LLM testing, using Rust to automate and manage this process.
Examine the potential for innovation in LLM quality testing. What emerging tools, methodologies, and frameworks could enhance the testing process, particularly in terms of scalability, adaptability, and ethical considerations? Discuss how Rust can be used to develop and implement these innovations, providing examples of future directions in LLM testing.
Analyze the trade-offs between manual and automated testing approaches in LLM quality assurance. How can a hybrid approach be designed to maximize coverage, efficiency, and reliability? Provide examples of how Rust-based tools can facilitate the integration of manual and automated tests, and discuss the challenges of balancing these approaches.
Discuss the future directions of LLM quality testing. How might advancements in AI and natural language processing influence the testing methodologies and standards applied to LLMs? Propose a forward-looking framework for LLM testing, using Rust to address emerging challenges and opportunities in this evolving field.
Embrace these challenges as an opportunity to master the intricacies of LLM testing, knowing that your efforts will contribute to the responsible and ethical deployment of AI systems in real-world applications.
23.7.2. Hands On Practices
Self-Exercise 23.1: Designing an Automated Testing Framework for LLMs
Objective: To design and implement an automated testing framework using Rust that comprehensively evaluates large language models (LLMs) across various quality dimensions, including accuracy, fluency, and robustness.
Tasks:
Research and outline the key quality metrics (e.g., BLEU scores, perplexity, robustness) that your automated testing framework will assess.
Develop a Rust-based framework to execute these tests, incorporating components for data preprocessing, test execution, and result analysis.
Implement the framework with a sample LLM, testing it against a predefined dataset to measure its performance across the selected quality metrics.
Refine the framework by adding custom tests that address specific challenges, such as handling ambiguous or adversarial inputs.
Deliverables:
A Rust-based automated testing framework, complete with source code and documentation.
A detailed report on the design and implementation process, including the rationale for selected metrics and the results of initial tests.
Recommendations for further development of the framework based on the findings from the initial implementation.
Self-Exercise 23.2: Implementing Bias Detection and Mitigation in LLM Outputs
Objective: To implement bias detection tools using Rust and apply them to evaluate and mitigate potential biases in LLM outputs, particularly in sensitive areas such as gender, race, and ethnicity.
Tasks:
Identify a task or dataset prone to bias (e.g., sentiment analysis, hiring recommendations) and outline the types of biases you expect to find.
Implement Rust-based tools to systematically detect biases in the LLM's outputs, focusing on identifying patterns that indicate gender, racial, or ethnic bias.
Develop and apply mitigation strategies, such as re-balancing the training data or refining prompts, to reduce or eliminate the detected biases.
Re-test the LLM using the bias detection tools to evaluate the effectiveness of the mitigation strategies.
Deliverables:
A Rust-based bias detection tool, including the source code and documentation.
A detailed report on the biases detected in the LLM outputs, with examples and analysis of the identified issues.
A refined set of LLM outputs, showing the improvements made through the bias mitigation strategies, and a final evaluation report.
Self-Exercise 23.3: Developing a Human-in-the-Loop (HITL) Testing Process
Objective: To design and implement a human-in-the-loop testing process that integrates human judgment into the evaluation of LLM outputs, focusing on tasks requiring nuanced understanding, such as ethical decision-making or creative content generation.
Tasks:
Select a complex task that requires human judgment (e.g., evaluating the ethical implications of generated content or assessing the creativity of outputs).
Develop guidelines for human evaluators to ensure consistency and reliability in their assessments, including specific criteria and examples.
Implement a HITL testing workflow where human evaluators assess the LLM outputs alongside automated metrics, using Rust to manage the process.
Analyze the results, comparing the human evaluations with the automated metrics, and identify areas where human judgment added valuable insights.
Deliverables:
A detailed guide for human evaluators, including assessment criteria and examples.
A Rust-based workflow for managing the HITL process, complete with source code and documentation.
A report comparing the results of human evaluations with automated metrics, highlighting the value added by human judgment and recommendations for future testing.
Self-Exercise 23.4: Conducting Robustness and Security Testing on LLMs
Objective: To design and implement a comprehensive set of tests to assess the robustness and security of LLMs, focusing on their ability to handle noisy inputs, adversarial attacks, and potential vulnerabilities.
Tasks:
Define the robustness and security criteria that your tests will evaluate, such as handling adversarial examples or resistance to data poisoning.
Implement a series of Rust-based tests to assess the LLM's performance under these criteria, simulating various attack scenarios and input anomalies.
Analyze the results to identify vulnerabilities and areas where the model's robustness can be improved, and propose strategies for enhancement.
Implement the proposed strategies, re-test the LLM, and evaluate the improvements in robustness and security.
Deliverables:
A set of Rust-based robustness and security tests, complete with source code and documentation.
A detailed vulnerability report outlining weaknesses identified in the LLM, including examples of how the model was compromised.
A re-evaluation report showing the effectiveness of the enhancements, with recommendations for further robustness and security improvements.
Self-Exercise 23.5: Integrating LLM Testing into a CI/CD Pipeline
Objective: To integrate automated LLM testing into a continuous integration/continuous deployment (CI/CD) pipeline, ensuring ongoing quality assurance and rapid feedback during the development process.
Tasks:
Design a CI/CD pipeline that incorporates automated LLM testing at key stages of the development process, such as code commits, builds, and deployments.
Implement the pipeline using Rust, integrating your automated testing framework to automatically run tests and report results.
Test the CI/CD pipeline with a sample LLM project, evaluating its ability to provide timely feedback and catch quality issues before deployment.
Optimize the pipeline for performance and scalability, ensuring it can handle larger projects and more complex testing scenarios.
Deliverables:
A fully implemented CI/CD pipeline integrated with automated LLM testing, including source code and configuration files.
A report on the pipeline’s performance during testing, highlighting its strengths, areas for improvement, and scalability considerations.
A set of recommendations for scaling the pipeline to accommodate larger LLM projects or more comprehensive testing requirements.
Comments