Chapter 22
Advanced Prompt Engineering Techniques
"Advanced prompting techniques are essential for unlocking the full potential of language models, allowing us to guide their behavior and enhance their performance in increasingly sophisticated ways." — Yann LeCun
Chapter 22 delves into advanced prompt engineering techniques for large language models, focusing on innovative methods that extend beyond traditional few-shot and zero-shot prompting. It covers Chain of Thought Prompting, which enhances model interpretability by generating intermediate reasoning steps; Meta Prompting, which influences model behavior through strategically crafted prompts; Self-Consistency Prompting, which ensures reliability by generating multiple outputs for consistency; and Generate Knowledge Prompting, which leverages prompts to elicit specific knowledge. Additionally, it explores advanced techniques like Prompt Chaining, Tree of Thoughts, Automatic Prompt Engineering, Active-Prompt, ReAct Prompting, Reflexion Prompting, Multi-Modal Chain of Thought, and Graph Prompting, each offering unique ways to improve model performance and adaptability using the llm-chain Rust crate.
22.1. Chain of Thought Prompting
Chain of Thought (CoT) prompting is an advanced technique in natural language processing designed to encourage large language models (LLMs) to generate intermediate reasoning steps before arriving at a final answer. This approach is invaluable in scenarios demanding multi-step reasoning, logical deduction, or the breakdown of complex information, as it leads the model to "think aloud." By emulating human problem-solving methods, CoT prompting enhances both the accuracy and interpretability of model outputs, enabling the model to achieve clearer and more reliable conclusions. Structuring prompts to request these intermediate steps enables models to simulate a coherent thought process, improving transparency and enabling users to follow the model's logic more closely, which is particularly beneficial for applications where decision paths must be clear and justified.
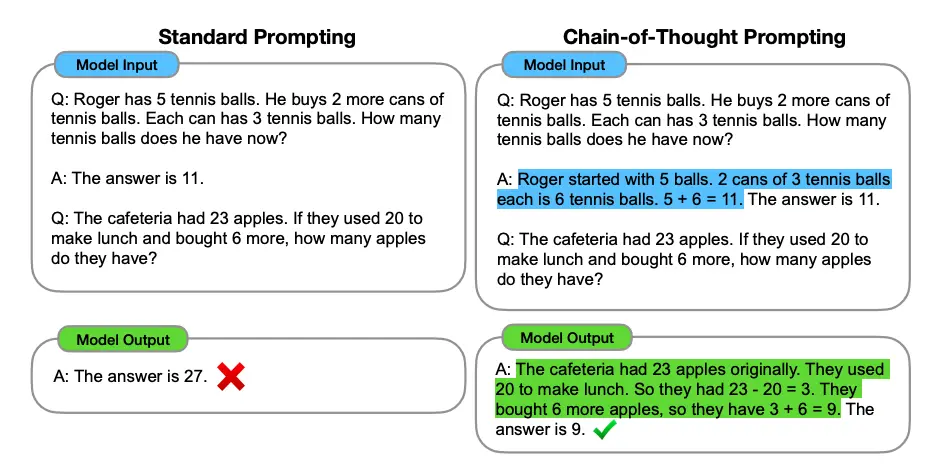
Figure 1: Illustration of CoT from https://www.promptingguide.ai.
In CoT prompting, a model’s output is structured to follow a sequence of reasoning steps, represented mathematically as $R = (r_1, r_2, \ldots, r_n)$, where each $r_i$ is an intermediate step leading to the final answer $A$. This structure transforms the output into a conditional sequence, defined as $P(A | X) = \prod_{i=1}^n P(r_i | r_{1:i-1}, X)$, where $X$ is the initial input. Each step $r_i$ becomes a layer in the decision-making path, allowing users to observe and verify each component of the reasoning chain. This structure not only enhances transparency but also allows for targeted corrections if errors are found in any step, increasing robustness and reliability in high-stakes applications.
Beyond improved performance, CoT prompting is transformative for interpretability, especially in fields like law and healthcare where transparent decision paths are essential. In legal contexts, for instance, CoT prompts can guide a model to elaborate on each principle or case precedent it considers, offering a transparent view of the rationale behind a judgment. Similarly, in healthcare, CoT prompts can help the model explain each inference based on patient history and test results, giving clinicians insight into each step that contributed to the final diagnosis. This interpretability fosters trust in the model’s outputs and allows professionals to make more informed decisions.
Implementing CoT prompting in Rust is facilitated by the llm-chain crate, which supports prompt chaining to create intermediate reasoning steps within model responses. The example code below shows a CoT setup for a math problem, where each prompt explicitly directs the model to handle individual calculations step-by-step, ensuring clarity and reducing the risk of cumulative errors.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
tokenizers = "0.20.3"
reqwest = { version = "0.12", features = ["blocking"] }
rayon = "1.10.0"
regex = "1.11.1"
llm-chain = "0.13.0"
llm-chain-openai = "0.13.0"
tokio = "1.41.1"
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
// CoT Prompt Setup: Prompt for multi-step reasoning
fn chain_of_thought_prompt() -> Step {
let prompt_content = "Solve the problem step-by-step:\n\n\
Problem: A train travels 60 miles in 1 hour, then 80 miles in 2 hours. What is the total distance covered?\n\
Step 1: Determine the distance covered in the first hour.\n\
Step 2: Determine the distance covered in the next two hours.\n\
Step 3: Sum the distances from each step to find the total distance.\n\
Solution:";
let template = StringTemplate::from(prompt_content);
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Initialize options with the API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Execute CoT Prompting
let cot_chain = Chain::new(vec![chain_of_thought_prompt()]);
let cot_result = cot_chain.run(parameters!(), &exec).await?;
println!("Chain of Thought Result: {}", cot_result.to_string());
Ok(())
}
This Rust code demonstrates a structured CoT prompt guiding the model through each logical step for solving a math problem. Each stage of reasoning is laid out in the prompt, leading the model to handle individual calculations before reaching a conclusion. By leveraging the llm-chain crate, developers can implement such multi-step logic efficiently, transforming complex problems into smaller, manageable components. This setup not only enhances transparency but also ensures that each reasoning step is clear and reduces potential errors by isolating logical steps, making it suitable for applications where precision is crucial.
Evaluating CoT prompting effectiveness requires a mix of quantitative metrics like accuracy scores and qualitative assessments of reasoning clarity, coherence, and logical flow. Rust's performance and concurrency support make it ideal for automating evaluations across extensive datasets, enabling systematic testing of different CoT strategies. Advanced real-world applications include financial analysis, educational tutoring, and legal decision-making, all of which benefit from CoT's ability to provide a structured approach to complex problems. Emerging trends in CoT, such as dynamic CoT and reinforcement learning integration, enable adaptive and optimized reasoning, offering exciting potential for responsive, transparent, and high-stakes AI applications.
The real-world applications of CoT prompting span a wide range of fields. In financial analysis, for example, CoT prompting can break down complex calculations and comparisons needed for risk assessment, enabling auditors or analysts to trace each financial inference made by the model. In educational settings, CoT prompting can assist students in learning by generating step-by-step solutions for math problems, programming challenges, or scientific explanations. By explaining each step, the model serves not only as an answer generator but also as a tutor, guiding learners through the logic behind each answer. These applications highlight the versatility of CoT prompting in situations that require a structured, transparent approach to complex problems.
One of the emerging trends in CoT prompting is dynamic CoT, where intermediate steps are not pre-defined but generated adaptively based on user queries or model feedback. For instance, in a dynamic CoT setup, a user query might initiate a chain of reasoning, with the model generating each subsequent step based on the results of previous steps. This approach leverages feedback loops to ensure that the CoT remains relevant and coherent, particularly in situations where initial assumptions or partial conclusions may need adjustment. Implementing dynamic CoT systems in Rust benefits from Rust’s concurrency support, allowing for real-time feedback and adaptive adjustment in interactive applications.
Another trend involves the integration of reinforcement learning into CoT prompting to optimize intermediate reasoning paths. Here, CoT prompts are fine-tuned through feedback loops, where desirable reasoning sequences are rewarded, refining the model’s logical structure over time. Reinforcement learning further strengthens CoT’s potential for high-stakes applications, as models learn to prioritize logical clarity and coherence based on evaluated outcomes. Rust’s performance characteristics make it an ideal choice for such adaptive systems, as it allows developers to handle continuous feedback efficiently, refining CoT structures dynamically in response to live user interactions.
Ethical considerations are essential in CoT prompting, especially when the generated reasoning affects decision-making in areas like healthcare, finance, or criminal justice. For example, bias in intermediate reasoning steps could skew the model’s conclusions, potentially leading to incorrect or unfair outcomes. To mitigate such risks, CoT prompts can be designed with fairness and transparency as key principles, encouraging balanced reasoning steps and explicitly addressing potential biases within the chain of thought. By carefully monitoring and refining CoT prompts, developers can ensure that outputs are fair, balanced, and reflective of diverse perspectives.
In conclusion, Chain of Thought prompting represents a significant advancement in improving the transparency, accuracy, and interpretability of LLMs. By guiding models through intermediate reasoning steps, CoT prompts align AI-driven problem-solving with human logic, making outputs more reliable and understandable. Rust’s llm-chain crate offers a powerful toolkit for implementing and customizing CoT prompts, enabling developers to structure prompts for even the most complex reasoning tasks. As research in CoT prompting continues to progress, dynamic CoT and reinforcement learning integration are emerging as promising avenues, paving the way for increasingly adaptive and responsive CoT systems. By incorporating best practices and ethical considerations, developers can leverage CoT prompting to deploy robust, transparent AI solutions across diverse industries, setting a new standard for responsible AI.
22.2. Meta Prompting
Meta prompting is a sophisticated technique in prompt engineering that allows developers to influence not just the content but also the tone, style, adaptability, and overall behavior of language model responses. By moving beyond simple direct prompts, meta prompting creates a layer of abstraction where initial prompts define specific guidelines, instructions, or criteria that the model will follow when generating subsequent responses. This approach enables the model to dynamically adjust its output based on context, user intent, or specific requirements, fostering more nuanced, adaptable interactions. Through meta prompting, developers can effectively guide the model to meet complex objectives, such as adopting a particular tone, varying response complexity, or prioritizing creativity, which enhances the model's ability to handle intricate or context-sensitive tasks.
Meta prompting, as outlined by Zhang et al. (2024), is characterized by a structure-oriented approach that emphasizes the format and pattern of prompts, focusing more on the organization of problems and solutions than on specific content. It leverages syntax as a guiding framework, allowing the prompt's structure to inform the expected response. This technique often incorporates abstract examples that illustrate problem-solving frameworks without delving into details, providing a versatile and adaptable foundation applicable across diverse domains. By emphasizing categorization and logical arrangement, meta prompting applies a categorical approach rooted in type theory, which aids in structuring components logically within a prompt. These characteristics make meta prompting particularly effective in producing flexible, context-aware responses that align with a wide variety of complex tasks.

Figure 2: Illustration of Meta prompting from https://www.promptingguide.ai.
In mathematical terms, we can define meta prompting as an iterative, self-referential function where a prompt $P$ does not directly yield a response $R$ but instead produces a refined prompt $P'$ that shapes subsequent model outputs. If $f$ is the function representing the model’s output generation, then in meta prompting, we aim to design $P$ such that $f(P) = P'$ and $f(P') = R$. This approach enables developers to establish a multi-layered interaction with the model, where prompts themselves undergo transformation before arriving at a final output. By controlling the way these prompts influence one another, we can create a structured pipeline of responses that adapts dynamically to varying requirements, fostering more nuanced and targeted interactions.
Meta prompting is particularly useful in applications that require adaptability and subtlety in response generation. For instance, in educational applications, a meta prompt could first instruct the model to adopt a tone and vocabulary level appropriate for a young audience. Once this style is set, the model could then respond to specific questions using simplified language, aligning with educational objectives. In customer service, meta prompting can be used to influence responses based on customer emotion or urgency. An initial meta prompt might detect the sentiment in a customer’s message and guide the model to respond empathetically in cases of negative sentiment, thus shaping responses that align with customer support protocols. The adaptability of meta prompting supports applications across industries, enabling a level of interaction that goes beyond simple, single-stage prompts.
The llm-chain crate in Rust offers a robust framework for implementing meta prompting, allowing developers to define and manage prompt sequences dynamically. The following Rust code demonstrates how to implement a meta prompting approach using llm-chain. In this example, the initial meta prompt shapes the model’s response style by setting a specific tone before the actual question is asked. This example can be particularly useful in customer support or educational settings where tone and approachability are key.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
// Meta Prompt Setup: Defining the tone and style for responses
fn meta_prompt_tone() -> Step {
let template = StringTemplate::from("For this conversation, adopt a friendly and conversational tone suitable for young students.");
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Main Prompt Setup: Crafting the response based on the meta prompt
fn question_prompt() -> Step {
let template = StringTemplate::from("Explain the concept of gravity in simple terms.");
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Initialize options with the API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Create a chain with both the meta prompt for tone setting and the main question prompt
let chain = Chain::new(vec![meta_prompt_tone(), question_prompt()]);
// Execute the chain
let response = chain.run(parameters!(), &exec).await?;
println!("Response with Meta Prompting: {}", response.to_string());
Ok(())
}
The program defines two functions, meta_prompt_tone and question_prompt, to format and structure the prompts. The meta_prompt_tone function initializes the conversational tone using StringTemplate, which is then converted into a Step that serves as the first part of the prompt sequence. The question_prompt function formats the question about gravity, also as a Step. These steps are combined in a Chain to ensure that the model first considers the tone-setting prompt before processing the question prompt. In the asynchronous main function, the chain is executed using an API key and prints the model’s response, reflecting the conversational tone established by the meta prompt. This setup demonstrates how meta prompting can dynamically adjust a model’s output to align with specific stylistic requirements.
Meta prompting’s power lies in its ability to modulate and customize the model’s behavior in real-time, making it well-suited for applications requiring adaptability. In dialogue systems, for instance, a meta prompt can guide the model to follow predefined conversational rules or adhere to a specific user’s preferences. In creative applications, meta prompting can allow the model to experiment with various narrative voices or genres, guiding the response format while maintaining a creative edge. This adaptability is invaluable in scenarios like interactive storytelling, where user engagement and contextual relevance are crucial. The control over tone, style, and approach provided by meta prompting transforms LLMs into flexible conversational agents capable of adapting to different roles or user expectations on demand.
However, implementing meta prompting requires careful testing and refinement to ensure that prompts produce the intended behavior consistently. Variations in prompt phrasing or content may lead to shifts in the model’s response style, especially if prompts lack specificity. To address this, iterative refinement and A/B testing can be employed to gauge the effectiveness of different meta prompt configurations. Evaluating meta prompts involves both qualitative assessments—examining the coherence and tone of outputs—and quantitative methods, such as measuring user engagement or sentiment. By analyzing these metrics, developers can identify which prompt structures yield the most reliable and context-appropriate responses, fine-tuning meta prompting strategies over time.
In industry applications, meta prompting has demonstrated substantial advantages. In automated content creation, for instance, a publishing platform implemented meta prompting to tailor articles to different audience demographics. The meta prompts were designed to adapt tone and complexity, making content more accessible to various reader segments without altering core information. Similarly, in virtual assistant applications, meta prompting has been used to adjust the assistant’s style and formality based on user interaction history, creating a more personalized and responsive experience. These real-world examples highlight the practical benefits of meta prompting in enhancing user engagement and tailoring responses to meet diverse needs.
Emerging trends in meta prompting research are focused on further enhancing prompt adaptability and responsiveness. One promising direction is dynamic meta prompting, where meta prompts are adjusted in real-time based on feedback or contextual changes within an ongoing interaction. For instance, a virtual assistant might adjust its tone mid-conversation based on detected shifts in user sentiment, switching from a neutral tone to a more empathetic one. This dynamic adaptability can be achieved by coupling meta prompts with real-time sentiment analysis, where Rust’s high concurrency support is advantageous in handling multiple feedback signals efficiently. By continuously adapting to interaction contexts, dynamic meta prompting can create more fluid and responsive conversational systems.
Another frontier in meta prompting is reinforcement learning, where models are trained to prioritize certain response styles or behaviors based on contextual relevance and user feedback. By assigning rewards to responses that align well with meta prompt objectives, reinforcement learning algorithms can fine-tune model outputs, optimizing for coherence, tone, and engagement over time. Rust’s performance efficiency and stability make it well-suited for developing reinforcement learning pipelines for meta prompting, supporting the complex feedback-driven training loops required by such systems.
Ethical considerations in meta prompting are also paramount, especially in scenarios where tone or response style could affect user perceptions or emotional well-being. In customer support, for example, a meta prompt that unintentionally encourages an overly casual tone could risk misinterpretation in serious interactions, leading to potential user dissatisfaction. To address this, developers should design meta prompts with sensitivity to different contexts, ensuring that tone and style adjustments align with user expectations. Transparency around the use of meta prompts is equally essential, particularly in applications like social media moderation or automated content creation, where prompt-driven behavior can influence public discourse. Implementing safeguards within the meta prompting framework, such as tone-checking prompts or response validation steps, can mitigate risks and ensure ethical deployment.
In summary, meta prompting enhances the adaptability and contextual sensitivity of LLMs by enabling prompts to influence the model’s behavior, style, and tone dynamically. Through Rust’s llm-chain crate, developers can implement flexible meta prompts that cater to specific interaction needs, guiding the model’s responses based on predefined or real-time context. Meta prompting not only improves user engagement but also enables applications across diverse fields, from customer service to creative content generation. As research advances in dynamic and reinforcement-based meta prompting, we can expect even greater adaptability and precision in AI-driven interactions. This technique offers a powerful tool for building AI systems that resonate with users, setting new standards for interactive, contextually-aware applications in natural language processing.
22.3. Self-Consistency Prompting
Self-consistency prompting is an advanced and powerful technique in prompt engineering, proposed by Wang et al. (2022), that aims to enhance the reliability and accuracy of large language model (LLM) outputs, particularly in chain-of-thought (CoT) prompting tasks. This method seeks to improve upon the traditional single-response generation approach by replacing the naive greedy decoding typically used in CoT prompting with a strategy that samples multiple, diverse reasoning paths. By leveraging few-shot CoT, self-consistency prompting generates multiple responses to the same prompt, exploring varied reasoning paths to arrive at the answer. The most consistent answer across these different reasoning paths is then selected as the final output, helping to address common challenges in LLM outputs, such as variability due to language nuances, minor prompt adjustments, or the inherent probabilistic nature of generative models.
Self-consistency prompting significantly boosts the performance of CoT prompting on tasks that require logical deduction, arithmetic calculations, and commonsense reasoning. By embracing the natural variability of LLM responses and using it as a mechanism to confirm accuracy, this technique reduces errors, minimizes fluctuations in output, and ultimately leads to more dependable results. Self-consistency is particularly advantageous in high-stakes applications—such as healthcare, finance, and legal services—where reliable, consistent, and precise model outputs are critical for decision-making. This approach not only enhances the robustness of responses but also aligns well with applications where accountability and interpretability are paramount, marking self-consistency as a key innovation in the quest for dependable AI systems.
Mathematically, self-consistency can be represented as a voting or consensus mechanism among multiple responses generated by the model. Let $R = \{r_1, r_2, \ldots, r_n\}$ be a set of $n$ responses generated for a given prompt $P$. In self-consistency prompting, the final output $R_{\text{consistent}}$ is selected based on the frequency or coherence of these responses. One approach is to measure the similarity or overlap among responses and choose the response that aligns most closely with the majority. This can be represented as:
$$ R_{\text{consistent}} = \operatorname{arg\,max}_{r \in R} \sum_{i \neq j} \text{similarity}(r_i, r_j) $$
where $\text{similarity}(r_i, r_j)$ denotes a metric, such as cosine similarity or lexical overlap, that quantifies the agreement between two responses. By selecting the most consistent response, self-consistency prompting acts as a quality filter, reducing the likelihood of producing outlier or biased outputs.
The implementation of self-consistency prompting in Rust is facilitated by the llm-chain crate, which enables the chaining of multiple prompt generations, allowing developers to efficiently create multiple responses and evaluate their consistency. In the following Rust code example, we demonstrate how to implement self-consistency prompting by generating several responses to the same question and selecting the response with the highest similarity score among the set.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use llm_chain::traits::Executor; // Import the Executor trait
use tokio;
use std::collections::HashMap;
// Function to create a prompt for the specified question
fn create_prompt() -> Step {
let prompt_content = "What are the key benefits of using Rust for system programming?";
let template = StringTemplate::from(prompt_content);
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Function to generate multiple responses for self-consistency
async fn generate_responses(prompt: &Step, exec: &impl Executor, num_responses: usize) -> Vec<String> {
let mut responses = Vec::new();
for _ in 0..num_responses {
let chain = Chain::new(vec![prompt.clone()]);
if let Ok(response) = chain.run(parameters!(), exec).await {
responses.push(response.to_string());
}
}
responses
}
// Function to evaluate and select the most consistent response
fn select_consistent_response(responses: &[String]) -> Option<String> {
let mut frequency_map = HashMap::new();
// Count frequency of each response
for response in responses {
*frequency_map.entry(response.clone()).or_insert(0) += 1;
}
// Select response with highest frequency
frequency_map.into_iter().max_by_key(|&(_, count)| count).map(|(response, _)| response)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Create the main prompt for generating responses
let prompt = create_prompt();
// Generate multiple responses asynchronously for self-consistency
let responses = generate_responses(&prompt, &exec, 5).await;
// Select the most consistent response
if let Some(consistent_response) = select_consistent_response(&responses) {
println!("Most Consistent Response: {:?}", consistent_response);
} else {
println!("No consistent response found.");
}
Ok(())
}
In this example, the generate_responses function generates multiple responses for a given prompt, storing each in a vector. The select_consistent_response function then identifies the response with the highest frequency, selecting the most consistent output as the final answer. This code implementation is particularly useful for questions with factual answers or where consistent response phrasing is crucial. By selecting the most frequently generated response, this approach reduces the impact of anomalies or one-off answers, providing a more stable and reliable output.
Self-consistency is invaluable in applications where the accuracy and stability of answers are critical. In the legal domain, for example, self-consistency prompting can reduce ambiguity in contract analysis or legal interpretations, where varying interpretations of the same prompt can lead to significant differences in understanding. Similarly, in healthcare, where patient outcomes may hinge on the accuracy of model-driven advice, self-consistency prompting helps ensure that recommendations are dependable. These high-stakes contexts benefit greatly from a consistency-focused approach, as it helps mitigate the risks associated with random variability or potentially misleading responses.
Evaluating the effectiveness of self-consistency prompting requires both qualitative and quantitative metrics. From a quantitative perspective, accuracy can be assessed by comparing self-consistency outputs with ground truth data or known answers, while stability can be measured by the reduction in response variability across multiple prompt trials. Qualitatively, human evaluators can examine whether consistent responses demonstrate greater clarity, relevance, and coherence. In practice, evaluation can also involve comparisons with single-response prompting to confirm improvements, using metrics like response similarity scores or manual accuracy assessments.
In terms of industry applications, self-consistency prompting has shown impressive results in fields such as customer service, where the consistency of answers across repeated queries can impact user trust. For instance, a company used self-consistency prompting to enhance the accuracy of its customer support chatbot, achieving uniformity in responses to frequently asked questions. Another application in financial services involved using self-consistency prompting to review investment summaries, reducing the risk of conflicting advice in portfolio recommendations. These real-world implementations underscore the utility of self-consistency prompting in reinforcing accuracy and reliability, critical factors in customer-facing roles where brand reputation depends on dependable responses.
Emerging trends in self-consistency prompting focus on refining the methods of response selection and exploring adaptive consistency mechanisms. One area of research is dynamic weighting, where response consistency is evaluated based on contextual relevance or user feedback. For instance, rather than simply selecting the most frequent response, a dynamic weighting approach could prioritize responses that align with specific keywords or domain-specific concepts. Rust’s high performance and memory safety features make it ideal for building these adaptive self-consistency systems, which require efficient processing of feedback and contextual adjustments.
Another promising trend is integrating reinforcement learning into self-consistency prompting, where models are fine-tuned based on the quality of their consistent outputs. In this approach, models receive rewards for generating responses that align closely with previously consistent answers, gradually reinforcing preferred patterns of response. Rust’s concurrency capabilities facilitate the implementation of reinforcement learning loops, allowing for real-time adjustments to prompt structures or selection criteria based on user feedback. This integration of reinforcement learning enhances the model’s ability to self-correct over time, producing outputs that align more reliably with established consistency criteria.
Ethical considerations in self-consistency prompting are crucial, especially in applications that affect decision-making in sensitive areas. For instance, consistency in financial advice or medical recommendations must be aligned with best practices and ethical standards to prevent the model from producing responses that are consistently wrong or biased. Additionally, there is a risk of over-reliance on consensus, where the selection of consistent responses may inadvertently mask outlier perspectives that could offer valuable insights. To address these risks, developers should implement monitoring mechanisms to ensure that self-consistent responses remain accurate and ethically sound, especially in applications with potentially life-altering impacts.
In conclusion, self-consistency prompting enhances the reliability and accuracy of large language model outputs by selecting the most consistent response from multiple generated outputs. This technique leverages the inherent variability in LLM responses to filter out anomalous or inconsistent answers, improving stability in high-stakes applications. Through Rust’s llm-chain crate, developers can efficiently implement self-consistency prompting, generating dependable results across diverse contexts. As trends in reinforcement learning and dynamic weighting emerge, self-consistency prompting is set to become even more adaptable, paving the way for robust, accurate AI-driven decision-making. In applications where consistency is paramount, self-consistency prompting offers an advanced tool for building trustworthy, reliable LLM systems.
22.4. Generate Knowledge Prompting
Generate Knowledge Prompting is an advanced prompt engineering technique aimed at eliciting informative, contextually rich, and knowledge-driven responses from large language models (LLMs). Unlike standard prompts that focus on direct answers, generate knowledge prompting encourages the model to draw upon its underlying representations and “generate” knowledge in the form of explanations, insights, or elaborations on specific topics. This approach enhances the model’s utility in applications that require nuanced understanding, such as education, research, and information retrieval, where context-rich responses add significant value to end-users. By designing prompts that guide the model toward deeper, more expansive responses, generate knowledge prompting capitalizes on the model’s ability to synthesize information, improving the quality and relevance of outputs.

Figure 3: Illustration of Generate Knowledge prompting from https://www.promptingguide.ai.
Mathematically, generate knowledge prompting can be seen as a multi-stage response function, where each generated response $R$ is not merely a direct answer but a collection of knowledge elements $K = \{k_1, k_2, \dots, k_n\}$. Given a prompt $P$ that encourages knowledge generation, the output function $f(P)$ produces a response $R$ where each $k_i$ represents an individual knowledge component, such as a fact, insight, or contextual clarification. This can be represented as:
$$R = f(P) = \sum_{i=1}^{n} k_i$$
where $n$ is the number of distinct knowledge components generated in response to the prompt. By guiding the model to activate its knowledge components in response to prompts, generate knowledge prompting enhances the model’s effectiveness in information-dense tasks, creating responses that are more than simple answers—they are contextually aware explanations.
An effective approach to implementing generate knowledge prompting involves designing prompts that explicitly request background information, reasoning, or detailed explanations. For instance, in an educational application, a prompt might ask the model not only to define a term but also to discuss its historical significance and applications. Such prompts are structured to encourage the model to retrieve and articulate knowledge, fostering a more comprehensive response. Generate knowledge prompting is particularly valuable in applications like tutoring, where understanding the "why" behind an answer enhances the learning experience. It also benefits information retrieval tasks by producing responses that go beyond surface-level information, offering users a more in-depth view of a given topic.
The llm-chain crate in Rust provides a powerful framework for implementing generate knowledge prompting. With llm-chain, prompts can be organized and sequenced to guide the model into producing rich, knowledge-driven responses. The following Rust code demonstrates how to implement generate knowledge prompting by constructing a prompt that encourages the model to elaborate on a topic. In this example, the model is asked not only to define a concept but to discuss its applications and implications, leading to a more informative output.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use llm_chain::traits::Executor;
use tokio;
// Knowledge Prompt Setup: Encouraging the model to elaborate on a topic in-depth
fn generate_knowledge_prompt() -> Step {
let prompt_content = "Explain the concept of 'ecosystem' in ecology. Discuss its components, functions, and provide examples of different types.";
let template = StringTemplate::from(prompt_content);
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Execute Knowledge Prompting with the generated knowledge prompt
let knowledge_chain = Chain::new(vec![generate_knowledge_prompt()]);
let response = knowledge_chain.run(parameters!(), &exec).await;
match response {
Ok(result) => println!("Knowledge-Driven Response: {}", result.to_string()),
Err(e) => eprintln!("Error generating response: {:?}", e),
}
Ok(())
}
This Rust code uses the llm_chain library to generate a comprehensive knowledge-driven response on the ecological concept of an "ecosystem." The program defines a function, generate_knowledge_prompt, to structure a detailed prompt requesting the model to explain components, functions, and examples of ecosystems. This prompt is created as a StringTemplate, then wrapped in Data::text, and finally encapsulated in a Step for sequential execution. In the asynchronous main function, a ChatGPT executor is initialized with an API key, and the knowledge prompt is added to a Chain, enabling the prompt to run as part of a structured sequence. Using the tokio runtime, the program executes the chain asynchronously and prints the model’s response. This setup promotes depth and thoroughness in the generated response, as the model is guided to provide an elaborative answer. Error handling is also included to manage any issues that arise during execution, ensuring a smooth process.
Generate knowledge prompting has proven especially valuable in scenarios that demand depth and context in responses. In educational applications, for example, generate knowledge prompting allows for explanations that go beyond rote definitions, enriching the learning process with historical context, applications, and cross-disciplinary insights. In customer support, this approach can be used to provide clients with comprehensive answers, explaining both solutions and relevant background information, which fosters a deeper understanding and increases satisfaction. In professional research contexts, knowledge-rich prompts can assist with synthesizing literature or providing quick overviews of complex topics, enabling researchers to access concise yet thorough summaries of key information.
Evaluating the effectiveness of generate knowledge prompting requires both qualitative and quantitative assessment metrics. Qualitatively, human evaluators can assess the coherence, completeness, and depth of the responses, ensuring that generated answers are informative and contextually relevant. Quantitatively, metrics such as response length, topic coverage, and lexical diversity can serve as proxies for measuring the richness of knowledge-based responses. Moreover, user satisfaction metrics, such as user ratings or engagement times, can provide insights into the practical impact of knowledge-rich prompts on end-user experiences.
Industry use cases underscore the transformative potential of generate knowledge prompting. In healthcare, for instance, medical databases have implemented knowledge-rich prompts to assist healthcare professionals in understanding complex conditions by generating summaries of symptoms, treatments, and underlying mechanisms. Similarly, in finance, generate knowledge prompting has been used in risk assessment tools to provide analysts with comprehensive insights into potential risks, including historical data, trends, and market analyses. These applications highlight the versatility of knowledge-driven prompting, demonstrating its value in providing users with meaningful, context-aware information across sectors.
Recent advancements in generate knowledge prompting focus on enhancing the model’s capacity to retrieve domain-specific knowledge and tailor responses based on user intent. One emerging trend is dynamic knowledge prompting, where prompts are adapted based on real-time user interactions or context changes. For example, an educational application might dynamically adjust prompts to align with a student’s learning progress, encouraging the model to elaborate on new topics or provide deeper explanations as needed. Rust’s efficiency and concurrency capabilities are well-suited for implementing dynamic prompting, enabling systems to adapt prompts responsively and in real-time, enhancing the interactivity and relevance of responses.
Another innovation in this area is the integration of external knowledge bases or databases with LLMs, allowing the model to cross-reference its internal representations with verified information sources. This approach ensures that generated knowledge is not only contextually rich but also accurate, providing users with reliable information. Rust’s performance and memory safety features make it an ideal choice for managing the integration of large knowledge databases with LLM pipelines, ensuring that responses are both knowledge-rich and precise.
Ethical considerations play an essential role in generate knowledge prompting, particularly in scenarios where misinformation could have serious consequences. For example, in healthcare or legal advice applications, knowledge-rich prompts must be designed with safeguards to prevent the model from producing inaccurate or misleading information. Developers should implement verification mechanisms to ensure that knowledge-rich responses align with established facts or guidelines. Additionally, transparency around the model’s sources and reasoning process is essential, especially in fields where the origin and reliability of knowledge are critical. By incorporating quality control measures, developers can mitigate risks and ensure that generate knowledge prompting serves as a trustworthy tool across applications.
In conclusion, generate knowledge prompting represents a powerful approach to extracting and presenting informative, contextually rich responses from LLMs. By structuring prompts to encourage knowledge generation, developers can leverage the model’s potential to provide comprehensive, multi-faceted answers that extend beyond simple definitions or direct responses. Rust’s llm-chain crate enables efficient implementation of generate knowledge prompting, providing a structured framework for crafting, managing, and refining knowledge-driven prompts. As trends in dynamic prompting and knowledge base integration continue to evolve, generate knowledge prompting is set to become an indispensable tool in applications that require depth, accuracy, and contextual richness. Whether in education, research, or customer support, generate knowledge prompting enables AI systems to function as reliable sources of insight and information, enhancing user engagement and trust across diverse fields.
22.5. Prompt Chaining
Prompt chaining is an advanced prompt engineering technique that improves the reliability and performance of large language models (LLMs) by breaking complex tasks into a sequence of smaller, interlinked prompts, or “chains.” Instead of presenting a detailed task all at once, prompt chaining allows the model to handle each subtask sequentially, using the response from one prompt as the input for the next. This structured approach preserves context across steps, enabling the model to tackle multi-step problems with clarity and precision. In each stage of the chain, prompts can perform transformations, additional analyses, or data extraction, ultimately building up to the final result. This method not only enhances performance but also boosts transparency, as developers can trace and debug the model’s response at each step.
Prompt chaining is particularly valuable for applications that demand structured analysis, such as document question answering, conversational AI, and complex data extraction tasks. For example, in document QA, the chain might start with a prompt that extracts relevant passages, followed by a second prompt that synthesizes these passages into a cohesive answer. This modular approach not only makes it easier to identify where performance improvements are needed but also increases the controllability and reliability of LLM-driven applications. By managing complex workflows in logical, sequential steps, prompt chaining empowers developers to build more precise, adaptable, and user-focused LLM-powered applications.
In mathematical terms, prompt chaining can be represented as a Markov process, where the state of each prompt $P_n$ depends on the state of the previous prompt $P_{n-1}$ and is used to inform the generation of the next prompt $P_{n+1}$. Let $R_n$ represent the response to prompt $P_n$, such that each prompt-response pair creates a step in a chain that guides the task execution process. The objective is to define a prompt sequence $\{P_1, P_2, \dots, P_n\}$ where each $R_n$ refines or narrows the scope of the task until the final response $R_f$ meets the desired objective. This can be described by the equation:
$$ R_f = f(P_1, R_1, P_2, R_2, \dots, P_n, R_n) $$
where $f$ is the aggregation function that incorporates each response into the final output. This approach ensures that each stage in the sequence is not only relevant to the initial prompt but also contextually aligned with previous stages, allowing the model to approach complex queries in a methodical, organized fashion.
Prompt chaining is especially effective in use cases that require structured analysis or decision-making. In customer service automation, for example, prompt chaining can streamline complex inquiries by dividing them into smaller questions that address different aspects of a customer’s issue, such as account verification, issue type, and potential solutions. In legal document analysis, a chain of prompts can guide the model through stages of extraction, summarization, and risk analysis, ensuring that each step builds on previous findings. This technique is also valuable in creative applications, where generating a complex storyline or structured narrative may benefit from prompts that introduce characters, settings, and plot progression in sequence.
The llm-chain crate in Rust enables prompt chaining by providing a framework for managing prompt sequences, storing responses, and ensuring each prompt is informed by previous outputs. This Rust program demonstrates a sophisticated approach to prompt chaining using the llm_chain library to guide a large language model (LLM) through a multi-step analysis. The task is structured as a series of prompts that gather background information on a company's market performance, identify key issues based on that background, and suggest solutions to those issues. By breaking down the problem into smaller, manageable stages, this code leverages prompt chaining to maintain context across steps, allowing the model to build on its responses progressively.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
use std::error::Error;
// Step 1: Define a background prompt to provide company performance details
fn background_prompt() -> Step {
let prompt_content = "Provide background information on the company’s recent performance in the market.";
let template = StringTemplate::from(prompt_content); // Using &str directly
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Step 2: Define an issues prompt to identify challenges based on background information
fn issues_prompt(previous_response: &str) -> Step {
let prompt_content = format!(
"Based on the following background, identify the key issues faced by the company: {}",
previous_response
);
let template = StringTemplate::from(prompt_content.as_str()); // Convert to &str
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Step 3: Define a solutions prompt to suggest solutions based on identified issues
fn solution_prompt(previous_response: &str) -> Step {
let prompt_content = format!(
"Considering the identified issues: {}, suggest solutions that could address these challenges.",
previous_response
);
let template = StringTemplate::from(prompt_content.as_str()); // Convert to &str
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Step 1: Gather background information
let background_chain = Chain::new(vec![background_prompt()]);
let background = background_chain.run(parameters!(), &exec).await?.to_string();
// Step 2: Identify issues based on background information
let issues_chain = Chain::new(vec![issues_prompt(&background)]);
let issues = issues_chain.run(parameters!(), &exec).await?.to_string();
// Step 3: Propose solutions based on identified issues
let solution_chain = Chain::new(vec![solution_prompt(&issues)]);
let solutions = solution_chain.run(parameters!(), &exec).await?.to_string();
// Final output combining results from all steps
println!("Background: {:?}", background);
println!("Identified Issues: {:?}", issues);
println!("Suggested Solutions: {:?}", solutions);
Ok(())
}
In the code, each step is defined as a function that creates a StringTemplate for a specific prompt and wraps it in Data::text, turning it into a Step compatible with the llm_chain library. The asynchronous main function orchestrates the sequence of these prompts using Chain. First, it runs a background_chain to retrieve market performance details. This response is passed to the issues_chain to identify challenges, and the issues response is subsequently provided to the solution_chain to generate solutions. Using the tokio runtime for asynchronous execution, each chain step is awaited, ensuring ordered and contextually aware responses from the model. This approach showcases how prompt chaining can improve response reliability and transparency, especially for complex multi-step tasks.
Prompt chaining has significant advantages in tasks that require sequential reasoning or multi-step problem-solving. In the healthcare sector, for example, a model could be used to assess patient symptoms, run through potential diagnoses, and suggest next steps or treatments, with each stage refining the information provided in previous steps. This approach can be applied in educational platforms, where a chain of prompts could guide students through problem-solving exercises by first reviewing key concepts, then applying them to examples, and finally encouraging independent solution attempts. The sequential nature of prompt chaining enables these complex interactions to be handled in a way that feels both logical and supportive to the end user.
To evaluate the effectiveness of prompt chaining, developers can use several qualitative and quantitative metrics. Qualitatively, evaluating coherence and relevance at each stage ensures that each prompt-response pair contributes constructively to the overall goal. Quantitatively, metrics such as task completion rate, response accuracy, and time to completion can provide insights into the efficiency and precision of the prompt chain. Additionally, user feedback or performance on structured tasks can offer real-world validation, as prompt chaining often provides a more granular and transparent process for model-driven interactions.
Real-world case studies demonstrate the powerful potential of prompt chaining. In finance, prompt chaining has been used to analyze complex financial transactions, where a sequence of prompts guides the model through stages of transaction extraction, risk assessment, and regulatory compliance checks. Another prominent application is in customer support systems that handle multifaceted issues, where chaining prompts enables the model to systematically diagnose the problem, search for solutions, and communicate a clear resolution plan to customers. The effectiveness of prompt chaining in these cases lies in its ability to maintain focus on specific aspects of a task, enabling deeper and more accurate insights as the chain progresses.
Emerging trends in prompt chaining research are focusing on dynamic and adaptive chaining strategies. One promising approach is the use of reinforcement learning to adjust prompt chains based on real-time feedback, where successful chains are reinforced to improve future performance. This can enable models to dynamically adjust the structure and content of a chain based on the complexity of the user’s input, creating a more tailored experience. Rust’s concurrency capabilities provide an advantage in this context, as it enables efficient handling of these adaptive chains even in high-demand scenarios. Dynamic chaining could also include real-time decision nodes within a chain, allowing models to pivot based on user responses or task progress, a feature well-suited for interactive applications.
Ethical considerations are crucial in prompt chaining, particularly in applications that impact users’ decision-making. Because each step in a chain builds on prior responses, errors or biases can propagate through the sequence, potentially magnifying their impact. For example, in applications such as legal advice or healthcare diagnostics, an initial inaccurate response could mislead subsequent steps, creating compounded inaccuracies. To mitigate these risks, developers should implement checkpoints or verification steps within chains to identify and correct issues before they escalate. Additionally, prompt chains used in sensitive applications should be transparent, allowing users to understand the rationale behind each step and fostering trust in model-driven outcomes.
In conclusion, prompt chaining represents a powerful, structured approach to handling complex tasks in large language models by breaking down interactions into sequential, manageable steps. This technique improves model performance in multi-step reasoning and task execution, enabling applications in fields as diverse as finance, healthcare, and education. Rust’s llm-chain crate provides an efficient foundation for implementing prompt chaining, supporting dynamic management of prompt sequences to ensure logical and coherent task progression. With advancements in dynamic chaining and adaptive reinforcement learning, prompt chaining is poised to become an essential tool in developing responsive, context-aware AI systems. This technique not only enhances the clarity and reliability of model outputs but also brings a level of transparency and control to complex interactions, making AI-driven solutions more accessible and effective for a wide range of applications.
22.6. Tree of Thoughts Prompting
Tree of Thoughts (ToT) is an advanced framework in prompt engineering, recently introduced by Yao et al. (2023) and Long (2023), to enhance language models (LLMs) in tackling complex tasks requiring strategic exploration and lookahead. Traditional prompt engineering methods, including chain-of-thought prompting, often fall short in tasks where exploring alternative reasoning paths or iterating through multi-step solutions is necessary. ToT addresses this by organizing the reasoning process into a tree structure, where each "thought" represents an intermediate step or sub-solution. This setup allows the model to generate, evaluate, and build upon thoughts through deliberate, systematic exploration, using search algorithms such as breadth-first search (BFS), depth-first search (DFS), or beam search to evaluate different thought paths.
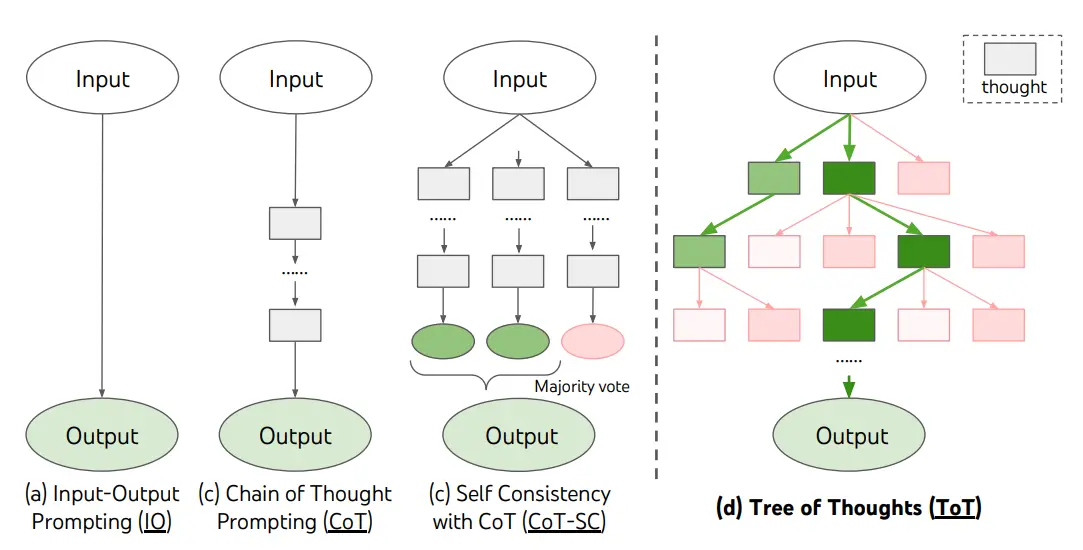
Figure 4: Illustration of CoT, CoT-SC and ToT from https://www.promptingguide.ai.
ToT’s approach involves specifying the number of candidate thoughts and steps at each decision point, enabling iterative refinement toward the solution. For example, in mathematical reasoning tasks like the Game of 24, the model decomposes the problem into multiple steps, keeping only the top candidates at each level of reasoning based on evaluations like "sure," "maybe," or "impossible." This process enables the model to narrow down on promising paths while discarding implausible ones early, guided by commonsense evaluations such as "too big/small." Advanced variations of ToT, such as those proposed by Long (2023), include reinforcement learning-driven ToT Controllers that adapt search strategies through self-learning, enhancing problem-solving capabilities beyond generic search techniques.
Recent adaptations, such as Hulbert's Tree-of-Thought Prompting, apply ToT principles in simpler prompt setups by having the LLM generate multiple intermediate steps within a single prompt. This version prompts the model to emulate a panel of "experts" who explore various reasoning paths collectively, allowing it to self-correct along the way. Furthermore, Sun (2023) has expanded on this idea with PanelGPT, benchmarking ToT prompting through large-scale experiments and introducing discussion-based approaches for generating balanced solutions. Overall, Tree of Thoughts represents a significant leap forward in enhancing the decision-making and problem-solving capabilities of LLMs, enabling them to systematically evaluate and refine complex tasks through multiple paths of reasoning.
Mathematically, Tree of Thoughts prompting can be modeled as a search over a tree structure, where each node represents a state or partial solution in the thought process, and each edge represents a step in reasoning from one state to another. Let $T(P)$ denote a tree structure rooted at the initial prompt $P$. The model generates multiple branches at each node $N$, with each branch $b_i$ representing a different approach or intermediate solution. The goal is to explore paths $\{b_1, b_2, \dots, b_k\}$ and evaluate the outcome of each path based on a scoring or selection function $f(b)$, ultimately selecting the path with the highest score. The overall decision-making process can be formalized as:
$$ \text{Best Path} = \operatorname{arg\,max}_{b \in T(P)} f(b) $$
where $f(b)$ is a function that evaluates the quality or effectiveness of each thought path $b$. This structured exploration allows the model to make more informed decisions, considering various perspectives and approaches before arriving at a final answer.
Tree of Thoughts prompting is particularly useful in applications where decisions require multi-step reasoning and benefit from evaluating diverse perspectives. For instance, in financial planning, generating multiple investment strategies and assessing each for risk and return allows the model to recommend the best approach tailored to specific goals. In healthcare, exploring multiple diagnostic paths based on patient symptoms and medical history enables the model to consider differential diagnoses before suggesting a final recommendation. This technique is also valuable in creative fields, such as narrative generation, where multiple story arcs can be generated and evaluated to select the most engaging storyline.
Implementing Tree of Thoughts prompting in Rust is made possible through the llm-chain crate, which supports branching and chaining of prompts. Using llm-chain, developers can construct a tree structure where each node represents a prompt, and each branch represents a different thought path. This Rust program demonstrates an advanced implementation of the Tree of Thoughts (ToT) framework using the llm_chain library to guide a large language model (LLM) through multiple reasoning paths for a complex task. The task involves generating and evaluating multiple approaches to improve user engagement on a social media platform. By prompting the LLM to suggest different strategies and scoring each response, the program helps the model identify the most optimal solution. This approach enables systematic exploration and selection of the best thought path, enhancing the model's ability to solve multi-step, nuanced problems.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
use std::collections::HashMap;
// Function to create the root prompt for generating initial thoughts
fn root_prompt() -> Step {
let prompt_content = "Suggest approaches for increasing user engagement on a social media platform.";
let template = StringTemplate::from(prompt_content);
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Function to generate multiple thought paths asynchronously
async fn generate_thought_paths(exec: &impl llm_chain::traits::Executor, prompt: &Step, num_paths: usize) -> Vec<String> {
let mut responses = Vec::new();
for _ in 0..num_paths {
let chain = Chain::new(vec![prompt.clone()]);
if let Ok(response) = chain.run(parameters!(), exec).await {
responses.push(response.to_string());
}
}
responses
}
// Custom scoring function to evaluate path quality based on defined criteria
fn evaluate_path_quality(path: &str) -> i32 {
// Example scoring logic: score based on length and keyword presence
let score = path.len() as i32;
let engagement_keywords = ["engagement", "retention", "growth"];
for keyword in &engagement_keywords {
if path.contains(keyword) {
return score + 10; // Higher score if specific keywords are found
}
}
score
}
// Function to evaluate and select the best thought path based on scoring
fn evaluate_paths(paths: Vec<String>) -> Option<String> {
let mut scores = HashMap::new();
for path in paths {
let score = evaluate_path_quality(&path);
scores.insert(path.clone(), score);
}
scores.into_iter().max_by_key(|&(_, score)| score).map(|(path, _)| path)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Generate the root prompt
let prompt = root_prompt();
// Generate and evaluate multiple thought paths
let paths = generate_thought_paths(&exec, &prompt, 3).await;
if let Some(best_path) = evaluate_paths(paths) {
println!("Best Thought Path: {}", best_path);
} else {
println!("No optimal path found.");
}
Ok(())
}
In this code, a root prompt is first set up to request engagement strategies. Using the generate_thought_paths function, the program creates three potential responses (thought paths) by running the root prompt multiple times with asynchronous execution, leveraging the tokio runtime for efficiency. Each response is scored based on criteria set in the evaluate_path_quality function, where certain keywords relevant to engagement boost the path’s score. The evaluate_paths function then selects the response with the highest score, representing the best thought path. This setup allows the LLM to explore diverse solutions in a structured manner, facilitating better decision-making for tasks with multiple solution paths.
Tree of Thoughts prompting offers significant advantages in domains where decisions require careful consideration of multiple factors. For example, in business strategy, generating alternative business plans and evaluating their feasibility allows for informed decision-making that weighs potential risks and returns. In educational tools, this approach enables the generation of alternative learning paths for students, evaluating each based on factors like difficulty and relevance to student goals. By guiding the model through a structured exploration of possibilities, Tree of Thoughts prompting facilitates decisions that are well-rounded, comprehensive, and tailored to complex scenarios.
To assess the effectiveness of Tree of Thoughts prompting, developers can employ both quantitative and qualitative evaluation techniques. Quantitative evaluation might involve scoring the selected path based on predefined criteria such as accuracy, relevance, or solution quality. Qualitative methods, including user feedback or expert review, can be used to assess whether the selected thought path aligns with domain-specific best practices or expectations. Additionally, metrics like completion time and consistency across multiple prompt chains provide insights into the efficiency and reliability of the Tree of Thoughts approach, helping developers refine the model’s exploration and selection processes.
Several real-world case studies highlight the impact of Tree of Thoughts prompting in enhancing decision-making. For example, in recommendation systems, Tree of Thoughts prompting enables the model to generate and evaluate various recommendation pathways based on user preferences and historical behavior. In risk management, this technique allows models to explore and rank mitigation strategies based on potential impact and cost-effectiveness, providing organizations with a robust decision framework. Such applications demonstrate how Tree of Thoughts prompting can improve outcomes by introducing a structured, evaluative approach to complex problem-solving.
Recent trends in Tree of Thoughts prompting are focused on integrating reinforcement learning to optimize path selection dynamically. By using reinforcement signals, models can learn to prioritize certain paths based on historical performance, adjusting their exploration strategies in real-time. Additionally, dynamic Tree of Thoughts prompting, where paths are generated and evaluated interactively based on user input, offers promising applications in fields like personalized tutoring or interactive storytelling. Rust’s concurrency features are particularly advantageous in these interactive setups, enabling rapid evaluation of paths and adaptive adjustment of the tree structure based on user responses or model feedback.
Ethical considerations are essential in the implementation of Tree of Thoughts prompting, especially in applications that impact user choices or behavior. For example, in recommendation systems, selecting paths based solely on engagement metrics could inadvertently reinforce addictive behavior or skewed content consumption. To mitigate these risks, developers should design scoring functions that balance user engagement with factors such as informational value or user well-being. Additionally, transparency mechanisms that reveal the model’s thought paths or decision rationale can help users understand the reasoning behind specific recommendations, fostering trust and accountability.
In conclusion, Tree of Thoughts prompting offers a robust framework for enhancing the decision-making capabilities of large language models. By generating and evaluating multiple thought paths, this technique enables models to explore complex decision spaces and arrive at well-reasoned conclusions, making it invaluable for applications that require structured reasoning and multi-step problem-solving. Rust’s llm-chain crate provides a suitable foundation for implementing this technique, supporting the creation, management, and evaluation of multi-path prompt structures. As trends in reinforcement learning and adaptive path selection continue to evolve, Tree of Thoughts prompting is set to become an increasingly valuable tool in developing models that are both insightful and reliable in their reasoning processes. This technique not only enhances model accuracy and relevance but also brings a level of rigor and transparency to AI-driven decision-making, empowering users with AI solutions that are both informative and ethically responsible.
22.7. Automatic Prompt Engineer
Automatic Prompt Engineering (APE) marks a groundbreaking advancement in prompt design for large language models (LLMs), transforming what was once a manual, iterative process into an automated, algorithm-driven approach. Traditionally, prompt engineering has required human expertise to craft and refine prompts through trial and error, often demanding deep knowledge and time-consuming experimentation. APE aims to eliminate this dependency by automating the creation, evaluation, and optimization of prompts, using sophisticated algorithms that generate and test prompts with minimal human intervention. By incorporating optimization techniques, heuristic evaluations, and black-box search strategies, APE significantly accelerates prompt fine-tuning, ensuring high-quality outputs while streamlining LLM deployment across diverse applications. The overarching goal of APE is to reduce both the time and expertise needed to develop effective prompts, making high-performance prompting more accessible and efficient.
Figure 5: Automatic Prompt Engineer prompting from https://www.promptingguide.ai.
In their 2022 study, Zhou et al. introduced the APE framework, which reframes prompt engineering as a problem of natural language synthesis and search. In this framework, LLMs generate a range of instruction candidates based on task-specific output demonstrations. These instructions undergo evaluation within a target model, with the most effective instruction selected based on calculated scores, guiding the search toward high-performing prompts. Notably, APE has demonstrated the potential to surpass manually crafted prompts, discovering zero-shot Chain-of-Thought (CoT) prompts that outperform the widely used "Let's think step by step" directive from Kojima et al. (2022). For example, the APE-generated prompt, "Let's work this out in a step by step way to be sure we have the right answer," improved accuracy in benchmarks like MultiArith and GSM8K. Key studies exploring prompt optimization further include Prompt-OIRL, which uses inverse reinforcement learning for query-dependent prompts; OPRO, where simple phrases like "Take a deep breath" have shown marked improvements in mathematical problem-solving; and techniques like AutoPrompt and Prompt Tuning, which automate prompt creation via gradient-guided search and backpropagation. Collectively, these advancements push the boundaries of LLM capabilities, setting a new standard for adaptable, high-efficiency prompt engineering.Mathematically, APE can be conceptualized as an optimization problem.
Let $P$ represent the space of possible prompts, and let $f(P)$ denote a function that evaluates the effectiveness of each prompt $P$. The goal of APE is to identify an optimal prompt $P^*$ that maximizes $f(P)$ based on evaluation metrics such as relevance, coherence, and task accuracy. Formally, this can be represented as:
$$P^* = \operatorname{arg\,max}_{P \in P} f(P)$$
This optimization may be achieved through various techniques, such as genetic algorithms, reinforcement learning, or gradient-based methods, where each iteration involves generating candidate prompts, evaluating them, and retaining those that best align with the target objective.
Automatic prompt generation is particularly valuable in dynamic environments, such as customer service and financial analysis, where LLM requirements frequently change. For instance, in customer service, a company may need prompts that are effective across different customer concerns and product lines. APE can quickly generate prompts tailored to these diverse contexts by autonomously exploring prompt variations. In e-commerce applications, where consumer demands and product categories evolve continuously, APE can adapt prompts in real-time to reflect these shifts, enabling the LLM to stay relevant and accurate.
Implementing Automatic Prompt Engineering in Rust can be effectively managed with the llm-chain crate, which provides robust support for managing and iterating on prompts. By using Rust’s performance and concurrency features, developers can create a pipeline that rapidly generates, tests, and refines prompts. The following example demonstrates how to set up an APE pipeline in Rust using llm-chain, where candidate prompts are generated, evaluated, and optimized over multiple iterations.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
use std::error::Error;
// Function to generate candidate prompts
fn generate_candidates(base_prompt: &str, variations: Vec<&str>) -> Vec<Step> {
variations
.into_iter()
.map(|v| {
let prompt_content = format!("{} {}", base_prompt, v);
let template = StringTemplate::from(prompt_content.as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
})
.collect()
}
// Function to evaluate prompt effectiveness (simple scoring logic based on response length)
async fn evaluate_prompt(exec: &impl llm_chain::traits::Executor, prompt: &Step) -> f32 {
let chain = Chain::new(vec![prompt.clone()]);
if let Ok(response) = chain.run(parameters!(), exec).await {
response.to_string().len() as f32 // Score based on response length
} else {
0.0 // Default score if evaluation fails
}
}
// Optimization loop for selecting the best prompt
async fn optimize_prompt(exec: &impl llm_chain::traits::Executor, base_prompt: &str, variations: Vec<&str>, iterations: usize) -> Step {
let mut best_prompt = Step::for_prompt_template(Data::text(StringTemplate::from(base_prompt)));
let mut best_score = 0.0;
for _ in 0..iterations {
let candidates = generate_candidates(base_prompt, variations.clone());
for candidate in candidates {
let score = evaluate_prompt(exec, &candidate).await;
if score > best_score {
best_score = score;
best_prompt = candidate.clone();
}
}
}
best_prompt
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Define the base prompt and variations
let base_prompt = "Analyze the current trends in social media engagement";
let variations = vec![
"with a focus on user growth",
"considering demographic data",
"including recent technological advances",
];
// Optimize the prompt
let optimized_prompt = optimize_prompt(&exec, base_prompt, variations, 5).await;
println!("Optimized Prompt: {:?}", optimized_prompt);
Ok(())
}
In this code, generate_candidates produces prompt variations by appending different phrases to the base prompt. Each candidate prompt is then evaluated in the evaluate_prompt function, which scores it based on the length of the generated response—a simple proxy for relevance and richness of the response, though more complex scoring functions could be implemented. The optimize_prompt function iteratively refines the prompts, selecting the one with the highest score as the most effective prompt for the given task.
Automatic Prompt Engineering has significant benefits across industries by reducing dependency on human intervention and enabling rapid adaptation to new contexts. In healthcare, for example, where medical terminology and protocols frequently evolve, APE allows models to update prompts without manual redesign, ensuring that responses remain clinically accurate and relevant. In content generation, APE can enhance creative applications by automatically generating diverse prompts that encourage unique outputs, such as varied narratives or stylistic choices in creative writing.
Evaluating the effectiveness of APE-generated prompts can be approached using both quantitative and qualitative metrics. Quantitative measures might include output coherence, relevance, and completion rate. Qualitatively, expert reviews and user satisfaction surveys provide insights into the practicality and applicability of the generated prompts in real-world scenarios. Further, APE pipelines can benefit from reinforcement learning, where successful prompts are reinforced and unsuccessful ones are adjusted or discarded based on feedback, creating a self-improving system that continuously refines its prompt generation strategy.
The benefits of APE are accompanied by challenges, particularly around the interpretability and reliability of generated prompts. Since APE relies on algorithms to generate prompts, it may produce prompts that are less aligned with specific human intentions, potentially leading to responses that are misinterpreted or off-target. This issue is especially pertinent in high-stakes applications, such as legal or financial consulting, where precise language and compliance with domain-specific standards are essential. To mitigate these risks, developers should implement validation layers to ensure that automatically generated prompts adhere to relevant guidelines and best practices.
Recent trends in APE research are focused on improving the interpretability and adaptability of generated prompts. Techniques such as reinforcement learning with human feedback (RLHF) are being explored to create more user-aligned prompts by incorporating human evaluators into the feedback loop. Another promising approach is few-shot learning combined with APE, where examples are embedded in prompts to provide contextual grounding, enhancing both specificity and relevance. Rust’s strong memory safety and performance capabilities support these advanced methodologies, allowing developers to integrate sophisticated feedback and validation mechanisms into their APE workflows without sacrificing speed or efficiency.
Ethically, APE raises questions about the potential risks associated with fully automated prompt generation. If left unchecked, APE could inadvertently generate prompts that reinforce biases, encourage misinformation, or produce harmful responses. To address these concerns, developers should prioritize transparency and accountability in their APE pipelines. Including explainability mechanisms that track and document the prompt generation process helps mitigate the risks associated with opaque algorithms. Additionally, periodic human oversight remains crucial in high-stakes applications to ensure that generated prompts align with ethical and safety standards.
In conclusion, Automatic Prompt Engineering represents a powerful advancement in prompt design, leveraging automation to streamline and optimize the generation of effective prompts. By using optimization techniques and reinforcement mechanisms, APE reduces dependency on manual intervention, enabling LLMs to adapt more rapidly to changing requirements. Rust’s capabilities, particularly its performance and concurrency features, provide a strong foundation for implementing APE in real-world applications. With emerging trends focusing on interpretability and alignment, APE is poised to transform prompt engineering across industries, making it faster, more efficient, and more adaptable than ever. However, as with all automated systems, ensuring ethical alignment and accountability remains essential, especially as APE continues to evolve and find new applications in diverse fields.
22.8. Automatic Reasoning
Automatic Reasoning is a powerful technique that significantly enhances the capabilities of large language models (LLMs), enabling them to autonomously handle complex reasoning tasks. Unlike basic question-answering, which provides straightforward responses, Automatic Reasoning empowers the model to infer conclusions, assess conditions, and apply structured logical reasoning without needing detailed, step-by-step instructions from users. This autonomous reasoning ability is invaluable across a variety of domains, from data analysis and scientific research to diagnostics and decision support, where depth and accuracy are essential for generating meaningful insights. By reducing the need for human intervention in setting up logical steps, Automatic Reasoning optimizes workflows, making processes more efficient, consistent, and accurate.
Figure 6: Illustration of Automatic Reasoning from https://www.promptingguide.ai.
An effective approach to enhance LLM performance on reasoning tasks involves combining Chain-of-Thought (CoT) prompting with interleaved tool use. This technique requires crafting task-specific demonstrations that guide the model through complex, multi-step tasks while strategically pausing to leverage external tools when necessary. Paranjape et al. (2023) introduced the Automatic Reasoning Tool (ART) framework, which leverages a frozen LLM to autonomously generate intermediate reasoning steps within a structured program. The ART framework is designed to select task-specific demonstrations that include multi-step reasoning and tool use from a predefined task library. At test time, ART pauses the generation whenever external tools are required, allowing the model to incorporate tool output before resuming the reasoning process. By encouraging zero-shot generalization, ART enables the LLM to decompose novel tasks and apply tools in appropriate locations, minimizing human oversight and improving adaptability. Additionally, ART’s extensibility allows users to update the task and tool libraries, refining reasoning steps or introducing new tools as needed, which enhances the model's ability to handle complex, evolving tasks.
The core of Automatic Reasoning in LLMs lies in their ability to simulate logical operations and perform structured inference. Mathematically, reasoning can be formalized as a sequence of logical transformations applied to input data to reach a conclusion. For example, given a set of propositions $P = \{p_1, p_2, \ldots, p_n\}$ and a set of logical rules $R$, the reasoning process involves deriving a new proposition $q$ by applying these rules, represented as:
$$ q = f(P, R) $$
where $f$ denotes the inference function, which synthesizes propositions and logical rules to yield new insights. This structure mirrors that of rule-based systems and knowledge graphs; however, in Automatic Reasoning, the LLM performs the inference contextually, guided by language-based prompts and leveraging both pre-trained knowledge and logical constructs encoded within the prompt. This setup enables LLMs to handle high-level reasoning tasks, such as evaluating evidence, simulating hypothetical scenarios, or making decisions based on conditions defined in the prompt.
Automatic Reasoning is particularly beneficial in fields that require interpreting large volumes of data or making complex decisions. In finance, for example, LLMs with Automatic Reasoning capabilities can evaluate investment opportunities by synthesizing financial conditions, forecasting market trends, and analyzing risk factors within a single prompt. In healthcare, these models can perform differential diagnoses by logically assessing patient symptoms against potential conditions, streamlining the diagnostic process. In research and development, Automatic Reasoning enables models to hypothesize and evaluate experimental conditions autonomously, accelerating discovery and innovation. In each of these applications, Automatic Reasoning provides rapid, yet thorough, insights that are crucial for decision support and real-time analysis.
Implementing Automatic Reasoning in Rust with the llm-chain crate provides both performance and flexibility, allowing developers to structure prompts that guide LLMs through logical inference steps. For instance, if a model is tasked with evaluating financial data to identify viable investment opportunities based on specific criteria, llm-chain enables developers to design prompts that direct the model through each criterion systematically, resulting in logical and interpretable conclusions. By using frameworks like ART and tools such as llm-chain, developers can unlock the advanced reasoning potential of LLMs, deploying them across diverse applications where accuracy, autonomy, and adaptability are critical.
In conclusion, Automatic Reasoning and tool integration provide LLMs with the ability to perform sophisticated reasoning processes. These capabilities, combined with frameworks that support structured logic within language contexts, extend LLM usability across a range of disciplines, ensuring that models operate with high precision and greater independence. By tapping into advanced reasoning functions, developers can leverage LLMs for a new level of analytic depth and operational efficiency across multiple fields.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
use std::error::Error;
// Function to create a prompt for automatic reasoning
fn reasoning_prompt() -> Step {
// Create the reasoning prompt with a string template
let template = StringTemplate::from("Evaluate the following investment options based on risk tolerance and expected return. \
Option 1: High return, high risk. Option 2: Moderate return, moderate risk. \
Option 3: Low return, low risk. Identify the best option for a conservative investor.");
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Function to perform automatic reasoning asynchronously
async fn perform_reasoning(exec: &impl llm_chain::traits::Executor, prompt: &Step) -> String {
// Create a chain with a single reasoning step
let chain = Chain::new(vec![prompt.clone()]);
// Run the chain with parameters and return the response
match chain.run(parameters!(), exec).await {
Ok(response) => response.to_string(),
Err(_) => "Error in reasoning process".to_string(),
}
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Set up prompt for automatic reasoning
let prompt = reasoning_prompt();
// Execute reasoning task asynchronously
let reasoning_result = perform_reasoning(&exec, &prompt).await;
println!("Reasoning Result: {}", reasoning_result);
Ok(())
}
In this example, the reasoning_prompt function defines a structured prompt where the model must evaluate three investment options for a conservative investor. The prompt is designed to elicit reasoning based on risk tolerance and return expectations, guiding the model to make a logical decision. The perform_reasoning function executes the reasoning task, and the model’s output is expected to include an inferred decision based on the input conditions. This setup leverages llm-chain to handle sequential logic, allowing developers to specify reasoning-based criteria without coding each logical step.
Automatic Reasoning provides substantial advantages in environments requiring rapid evaluation of conditions and synthesis of logical conclusions. In e-commerce, Automatic Reasoning allows LLMs to assess customer behavior patterns and determine optimal product recommendations in real-time. For law enforcement, it supports evidence-based reasoning, where the model evaluates case data, extracts relevant details, and suggests probable conclusions. Automatic Reasoning enables applications to be more responsive, accurate, and contextually aware by processing complex data points and applying logical constructs within the model.
Evaluating Automatic Reasoning effectiveness requires both quantitative and qualitative metrics. Quantitative evaluation can measure the accuracy and consistency of reasoning outputs by comparing them with expected conclusions across different scenarios. Precision, recall, and F1 scores can quantify the model’s accuracy, while qualitative evaluation involves assessing the logical coherence of the generated responses. Additionally, user feedback and expert review provide critical insights into the model’s alignment with domain-specific reasoning standards, ensuring its utility in practical applications.
Recent industry trends are pushing Automatic Reasoning towards real-time and contextually adaptive applications, driven by advancements in reinforcement learning and domain adaptation. Reinforcement learning techniques allow models to iteratively refine their reasoning strategies based on feedback, while domain-specific adaptation tunes the model to prioritize certain logical patterns relevant to particular industries. This evolution is particularly evident in fields such as healthcare, where models trained with medical logic can perform complex diagnostic reasoning, and in finance, where economic indicators guide investment reasoning processes. Rust’s speed and concurrency capabilities align well with these trends, supporting high-performance reasoning in real-time applications and enabling continuous model updates based on feedback.
However, Automatic Reasoning also presents unique challenges, particularly around interpretability and ethical use. In sensitive domains, such as law and healthcare, understanding the rationale behind model decisions is essential. If a reasoning process lacks transparency, it may lead to unintended consequences, such as biased or unfair decisions. To address these issues, developers should implement interpretability mechanisms that allow users to track and verify reasoning paths. Rust’s type safety and explicitness provide a strong foundation for such interpretability, allowing for structured logging and clear documentation of each reasoning step.
Ethically, Automatic Reasoning raises questions about the potential misuse of autonomous reasoning models in high-stakes applications. There is a risk of models making incorrect assumptions based on incomplete or biased data, leading to flawed conclusions. Developers should ensure that APE systems are rigorously tested against diverse and balanced datasets, and they should include safety checks to prevent undesirable behavior. Compliance with domain-specific regulations and ethical guidelines is also essential, especially in sectors like finance and healthcare, where model decisions can directly impact lives.
In conclusion, Automatic Reasoning extends the capabilities of large language models by enabling autonomous inference and decision-making. Through structured prompts and automated inference mechanisms, Automatic Reasoning transforms LLMs into powerful tools capable of processing complex data and generating logical conclusions without explicit human direction. Implementing this technique in Rust with the llm-chain crate provides developers with both control and performance, supporting a range of applications that benefit from high-speed, autonomous reasoning. By incorporating reinforcement learning and interpretability features, Automatic Reasoning is set to become an integral component of advanced LLM systems, empowering industries with reliable, rapid, and intelligent decision-making capabilities. As these models become more sophisticated, the balance between automation and ethical oversight will be critical, ensuring that Automatic Reasoning systems remain both innovative and responsible in their deployment.
22.9. Active-Prompt
Traditional Chain-of-Thought (CoT) methods rely on a fixed set of human-annotated examples, but these may not always be the most effective for different tasks or contexts. To address this, Diao et al. (2023) introduced a dynamic prompting approach known as Active-Prompt, designed to adapt Large Language Models (LLMs) to task-specific examples annotated with human-designed CoT reasoning. This innovation allows prompts to be continually refined in response to real-time feedback, creating a flexible, interactive prompt structure.
The Active-Prompt approach begins by querying the LLM, either with or without initial CoT examples, to generate a set of $k$ potential answers for a series of training questions. An uncertainty metric—often based on the level of disagreement among the answers—is calculated to assess the reliability of the generated responses. Questions with the highest uncertainty are then flagged for further human annotation. These newly annotated examples are subsequently integrated into the prompt structure to refine responses to similar questions, enhancing the model’s adaptability across varied contexts.
Active-Prompt represents a breakthrough in prompt engineering by creating an interactive and adaptive environment in which prompts evolve in response to feedback on the relevance and quality of generated outputs. Unlike static prompts, which remain fixed regardless of user interaction, Active-Prompt employs a feedback loop that enables the model to iteratively enhance the clarity, coherence, and accuracy of its responses over successive iterations. This iterative, feedback-driven prompting is especially beneficial in applications requiring continual user engagement, such as customer service, educational systems, and recommendation engines, where prompt accuracy and relevance are critical.
Mathematically, Active-Prompt functions as an adaptive optimization process. Let $P_0$ represent the initial prompt, and let $F_i$ denote the feedback received after each model response $R_i$. The prompt at each iteration $P_i$ is modified by an adjustment function $A$ based on $F_i$ and $R_i$:
$$ P_{i+1} = A(P_i, F_i, R_i) $$
This feedback loop iteratively adapts $P_i$ until the model's responses align with desired criteria for relevance and accuracy. The adjustment function $A$ varies depending on the feedback type; it may involve minor rephrasing for clarity or more complex modifications that incorporate new constraints or guidance, ensuring that each subsequent prompt is better aligned with the user’s needs. This adaptability ensures that each subsequent prompt is better aligned with the interaction’s objectives, creating a feedback loop that gradually optimizes the model’s performance within a specific context.
Active-Prompt is particularly valuable in customer service, where user queries may vary in specificity and complexity. A dynamically adjusted prompt can help a conversational agent clarify ambiguities and maintain coherence across interactions, enhancing the overall experience. In educational applications, Active-Prompt enables adaptive tutoring by adjusting prompts based on a student’s answers, focusing on areas where further guidance or explanation is required. This adaptive feedback loop provides personalized interaction, ensuring that each response progressively aligns with the user's needs.
Using Rust and the llm-chain crate, implementing Active-Prompt involves creating a prompt adjustment mechanism that evaluates responses and modifies prompts in real time. This mechanism can be built by adding a feedback function that assesses each model output and applies relevant modifications. Below is an example of an Active-Prompt system in Rust, where a customer service model dynamically refines its prompts based on user feedback:
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
use std::error::Error;
// Function to create the initial prompt
fn initial_prompt() -> Step {
let template = StringTemplate::from("Welcome to customer support. How can I assist you today?");
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Function to evaluate model response and adjust the prompt based on feedback
fn adjust_prompt(response: &str, feedback: &str) -> Step {
let adjusted_content = if feedback.contains("clarify") {
format!("Could you clarify your request? Here is what I understood: {}", response)
} else if feedback.contains("details") {
format!("Can you provide more details on: {}", response)
} else {
response.to_string() // Keep response unchanged if feedback is positive
};
let template = StringTemplate::from(adjusted_content.as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Asynchronous function to perform the interaction loop with adaptive prompts
async fn interactive_support(exec: &impl llm_chain::traits::Executor) -> Result<(), Box<dyn Error>> {
let mut prompt = initial_prompt();
for _ in 0..5 {
// Execute the model response with the current prompt
let chain = Chain::new(vec![prompt.clone()]);
let response = chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in reasoning process".to_string());
println!("Model Response: {}", response);
// Placeholder for user feedback; in a real application, this would be user-provided
let feedback = "clarify";
// Adjust the prompt based on the feedback
prompt = adjust_prompt(&response, feedback);
}
Ok(())
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Run the interactive support loop
interactive_support(&exec).await
}
In this code, the adjust_prompt function evaluates the model’s response and dynamically adjusts the prompt based on predefined feedback criteria. For simplicity, the feedback here is simulated as "clarify" or "details", but in a real-world application, it could be collected directly from users or a feedback mechanism. This structure allows for adaptive dialogue, where each iteration brings the prompt closer to meeting the user's needs, thus enhancing the relevance and usefulness of responses.
Active-Prompt has numerous benefits across domains requiring real-time, adaptive interactions. In e-commerce, for example, an adaptive recommendation system can refine prompts based on user preferences, generating increasingly personalized product suggestions. In legal and compliance applications, Active-Prompt allows LLMs to iteratively clarify ambiguous questions, helping clients understand complex terms by adjusting language or context based on user feedback. This adaptability not only enriches the interaction but also minimizes misunderstandings and promotes effective engagement.
Evaluating the effectiveness of Active-Prompt systems involves both performance and relevance metrics. Quantitative assessments measure the model’s response accuracy and coherence, while qualitative metrics, such as user satisfaction and engagement rates, offer insights into the system’s usability. For instance, in an educational context, student feedback on comprehension and retention can serve as an effective measure of Active-Prompt’s success. These evaluations can also be looped back into the Active-Prompt system, providing an additional layer of refinement and feedback that improves prompt design over time.
Recent industry trends highlight the increasing importance of adaptive interaction frameworks, particularly as LLM applications expand into interactive and user-centric domains. Research into reinforcement learning with human feedback (RLHF) suggests that models can benefit from real-time user interaction data to continuously improve their prompts and responses. The integration of RLHF in Active-Prompt systems could enable LLMs to autonomously adjust prompts based on user engagement metrics, thus creating a self-optimizing interaction framework. Rust’s memory safety, type system, and concurrency support make it highly suitable for implementing these feedback-intensive frameworks, where rapid iteration and stability are essential for smooth user experiences.
However, Active-Prompt also presents challenges, especially around maintaining consistency and managing feedback from diverse user interactions. Continuous prompt adjustments can lead to prompt drift, where the iterative modifications accumulate unintended biases or diverge from the original intent. Developers must ensure that Active-Prompt systems incorporate safeguards to prevent such issues, such as resetting the prompt after specific conditions or maintaining a set of core prompt characteristics. Moreover, in sensitive applications like healthcare or finance, ethical considerations demand that adaptive prompts remain aligned with regulatory standards and user expectations to avoid potential risks.
Ethically, Active-Prompt poses both opportunities and risks. On one hand, adaptive prompts can improve transparency and foster trust by tailoring responses to user needs. On the other, they risk reinforcing biases if feedback loops are not carefully monitored. For example, in a financial advisory application, continuously reinforcing specific investment options based on user feedback could create biased financial guidance. Ethical safeguards, such as bias detection and controlled feedback integration, are critical in these contexts to ensure fairness and objectivity in adaptive systems.
In summary, Active-Prompt brings a transformative approach to prompt engineering, enabling real-time, dynamic adaptation of prompts based on interaction feedback. By refining prompts iteratively, Active-Prompt enhances the relevance, coherence, and quality of model outputs, making it particularly valuable in applications that demand high levels of user engagement and context sensitivity. The Rust-based implementation with llm-chain demonstrates the flexibility and control necessary to build adaptive prompts in real-world applications, supporting a wide range of use cases from customer support to personalized learning. As industry trends move toward greater adaptiveness and personalization, Active-Prompt techniques offer promising pathways for creating responsive, intelligent interactions that continuously align with user intent.
22.10. ReAct Prompting
In 2022, Yao et al. introduced a transformative framework named ReAct, designed to enable Large Language Models (LLMs) to produce both reasoning traces and task-specific actions in an interleaved fashion. ReAct prompts LLMs to dynamically alternate between generating reasoning traces and performing actions, creating a cohesive, adaptive approach that improves model accuracy, interpretability, and user trustworthiness.
The ReAct framework empowers LLMs to engage in complex reasoning by producing verbal reasoning traces. This capability enables the model to establish, monitor, and adapt action plans, handle exceptions, and respond to task-specific needs. Additionally, ReAct allows LLMs to interface with external sources—such as knowledge bases, databases, or real-time environments—integrating external knowledge to enhance response reliability and factual grounding. By interacting with these sources, ReAct effectively mitigates common issues in language models, such as fact hallucination and error propagation.

Figure 7: Illustration of ReAct prompting technique from https://www.promptingguide.ai.
ReAct is inspired by the cognitive processes humans use to make decisions and adjust actions based on reflective insights. Traditional Chain-of-Thought (CoT) prompting, as demonstrated by Wei et al. (2022), shows LLMs’ ability to perform sequential reasoning for tasks that involve arithmetic, commonsense reasoning, and more. However, CoT alone lacks access to external knowledge and real-time updates, limiting its ability to verify facts or integrate new information dynamically.
ReAct addresses these limitations by pairing CoT reasoning with actionable steps. In this dual-mode framework, the model interleaves reflection with action, iteratively building on prior reasoning to adapt its approach. For example, when handling a question, ReAct enables the model to generate a reflective trace to analyze the question, and then perform actions to retrieve relevant information from external sources like Wikipedia or other databases. This integrated approach enables the LLM to not only create but also refine plans dynamically, resulting in responses that are coherent, factual, and aligned with real-world data.
ReAct introduces a novel dual-mode prompting approach in which the model alternates between reflection and action. This alternation allows the model to produce layered responses that blend deep understanding with actionable outcomes. The reflection step prompts the model to process the prompt, examine various perspectives, and build insights. In contrast, the action step drives the model to apply these insights practically, interacting with external tools or generating conclusive responses.
The ReAct prompting sequence can be represented mathematically to capture the alternating logic:
$$ R_i = \begin{cases} \text{reflect}(R_{i-1}) & \text{if } i \text{ is odd} \\ \text{act}(R_{i-1}) & \text{if } i \text{ is even} \end{cases} $$
In this sequence, each prompt $P_i$ guides the model to either reflect or act based on the previous response $R_{i-1}$. When the model reflects, it internalizes information from the last action or prompt, while acting prompts it to synthesize this reflection into a purposeful, conclusive step. This sequential approach yields responses that are both thoughtful and directive, providing a nuanced solution that combines introspection with action.
ReAct prompting has proven especially effective in scenarios requiring adaptive decision-making and complex reasoning. For instance, in legal advisory systems, the reflection step allows the model to explore multiple interpretations of a law, after which the action step enables the model to provide specific recommendations based on the analyzed perspectives. This reflective-then-active approach generates responses that are informed, context-sensitive, and practically applicable.
In educational environments, ReAct prompting can simulate a tutoring experience. The model reflects on a student's answer to identify areas for improvement, then acts by suggesting targeted exercises or additional resources. This dual approach supports a comprehensive learning journey, where responses are tailored to the learner’s progress and specific needs. Likewise, in customer service, ReAct can clarify user inquiries through reflection, then deliver precise solutions or steps, resulting in an interactive, adaptive user experience.
The ReAct framework enhances user experience by allowing LLMs to engage in deeper, contextual understanding before delivering concrete guidance. This adaptive approach minimizes misunderstandings and improves response relevance, as the model dynamically adjusts to the user’s evolving needs. By alternating between reasoning and action, ReAct prompts the model to continuously update and refine its understanding, resulting in outputs that are both accurate and easy to interpret.
Furthermore, the interleaved structure of ReAct enhances interpretability and trustworthiness. Users can follow the model’s reasoning trace, understand the decisions leading to each response, and trust that the model is synthesizing information with care and factual grounding. This transparency is particularly valuable in applications where reliability and user trust are essential, such as financial advising or healthcare consultations.
Studies show that ReAct outperforms many state-of-the-art baselines on language understanding and decision-making tasks. By combining reasoning with external actions, ReAct enhances the LLM’s ability to produce reliable, fact-based outputs and mitigates issues like hallucination and inconsistency. Best results are achieved when ReAct is combined with Chain-of-Thought (CoT) prompting, leveraging both internal reasoning and external information retrieval for holistic task-solving.
The ReAct framework represents a forward-thinking paradigm in prompt engineering and model design, blending cognitive processes with actionable output. This framework holds immense potential across domains, from enhancing customer service and tutoring systems to supporting legal, financial, and medical advisory tasks. As LLMs evolve, ReAct’s dynamic approach will likely be a key enabler in creating AI systems that respond with greater accuracy, context-awareness, and reliability in real-world applications.
Implementing ReAct Prompting in Rust using the llm-chain crate involves creating a structured prompt sequence that alternates between reflection and action states. Below is an example in Rust, where a model designed for financial advice uses ReAct Prompting to assess a user’s investment question by first reflecting on their risk tolerance before providing an investment recommendation.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
use std::error::Error;
// Function to create the initial reflection prompt
fn reflect_prompt(user_question: &str) -> Step {
let template = StringTemplate::from(format!(
"Considering the user's question on investments: '{}', analyze their risk tolerance and investment goals before offering advice.",
user_question
).as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Function to create the action prompt based on reflection
fn action_prompt(reflection: &str) -> Step {
let template = StringTemplate::from(format!(
"Based on the analysis: '{}', provide a specific investment recommendation that aligns with a conservative risk profile.",
reflection
).as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Asynchronous function to perform reflection and action prompts
async fn reflect_and_act(exec: &impl llm_chain::traits::Executor, user_question: &str) -> Result<(), Box<dyn Error>> {
// Step 1: Reflect on the user's question
let reflect_chain = Chain::new(vec![reflect_prompt(user_question)]);
let reflection = reflect_chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in reflection process".to_string());
println!("Reflection: {}", reflection);
// Step 2: Act based on the reflection
let action_chain = Chain::new(vec![action_prompt(&reflection)]);
let action = action_chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in action process".to_string());
println!("Actionable Advice: {}", action);
Ok(())
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// User question for investment advice
let user_question = "What type of investment would be best for my retirement planning?";
// Run the reflection and action sequence
reflect_and_act(&exec, user_question).await
}
In this code, the reflect_prompt function prompts the model to analyze the user’s question, considering elements like risk tolerance and goals, while the action_prompt function directs the model to provide a specific investment suggestion based on that reflection. This setup effectively balances analysis and action, creating responses that are thoughtful yet goal-oriented. Such a prompt structure enhances user confidence, as they receive responses that address their needs both comprehensively and directly.
ReAct Prompting is highly applicable in scenarios requiring both empathy and precision. In mental health support applications, for example, the model can reflect on a user’s emotional state before suggesting coping strategies, creating a more supportive interaction. Similarly, in medical advisory systems, a ReAct model can analyze symptoms in the reflection phase and provide actionable guidance in the subsequent step, such as recommending diagnostic tests. These applications demonstrate how ReAct Prompting can create empathetic, context-sensitive responses that align with user expectations in sensitive areas.
Evaluating the effectiveness of ReAct Prompting requires metrics that capture both the quality of reflection and the relevance of actions. Quantitative assessments may include accuracy scores, where reflective responses are checked for coherence and accuracy, while actions are evaluated for practical alignment with user goals. Qualitative feedback from users provides additional insight, particularly in high-stakes applications where the perceived thoughtfulness and usefulness of the response play a critical role in user satisfaction. Using both qualitative and quantitative evaluations enables comprehensive assessment, guiding developers in refining the reflection-action balance.
The evolution of ReAct Prompting is increasingly aligned with trends in reinforcement learning and human feedback loops. In future iterations, reinforcement learning techniques could enable the model to automatically optimize the reflection-action cycle based on user interactions, adjusting the depth of reflection or specificity of actions according to observed user satisfaction. This enhancement would be particularly useful in domains like customer support and healthcare, where response precision and empathy significantly impact user outcomes. Rust’s high-performance capabilities and type safety make it well-suited to support these dynamic adjustments, ensuring stable, responsive models capable of real-time, adaptive reasoning.
However, ReAct Prompting presents unique challenges, especially around balancing the reflection and action phases. Excessive reflection may lead to overly verbose responses, while insufficient action can result in vague or unsatisfactory guidance. Developers must carefully calibrate this balance, using user feedback to fine-tune each phase’s duration and specificity. Furthermore, ethical considerations arise, especially in applications involving sensitive topics like mental health or legal advice, where overly directive actions may be inappropriate. To address these issues, developers can implement safeguards to ensure that action steps remain within acceptable boundaries and include disclaimers when necessary.
Ethically, ReAct Prompting’s dual approach poses both opportunities and responsibilities. While thoughtful, reflective responses contribute positively to user experience, there is a risk of the model imposing prescriptive guidance if the action phase is too forceful or directive. In high-stakes applications, developers must ensure that ReAct Prompting aligns with ethical standards, providing support without overstepping advisory boundaries. Transparency mechanisms, such as clearly indicating reflection and action phases, can also help users understand the model’s reasoning process, increasing trust and acceptance.
In conclusion, ReAct Prompting offers a compelling framework for generating thoughtful, actionable responses by alternating between reflection and action. This approach brings a unique depth to prompt engineering, enabling LLMs to perform complex reasoning tasks that require both understanding and decision-making. By implementing ReAct Prompting in Rust with the llm-chain crate, developers can create sophisticated models capable of providing nuanced, user-aligned interactions in applications that demand both empathy and precision. As adaptive learning and user-centered design continue to shape the future of AI, ReAct Prompting stands out as a valuable technique for developing intelligent, responsive models that meet diverse user needs. This dual approach of reflection and action not only enhances response quality but also creates a more engaging, adaptive user experience, setting new standards for interaction quality in the field of large language models.
22.11. Reflexion Prompting
Reflexion Prompting is an advanced technique in prompt engineering that enables a model to engage in self-reflection, assessing and potentially revising its own responses to enhance accuracy, coherence, and relevance. By incorporating self-reflection, Reflexion Prompting introduces an introspective layer where the model critically evaluates its outputs, allowing it to detect and correct errors, identify ambiguities, or refine explanations. This technique is highly valuable in applications requiring a high degree of precision and self-correction, such as scientific inquiry, legal advisory, or educational tutoring, where model responses benefit from careful validation and iterative improvement.
The theoretical foundation of Reflexion Prompting can be formalized as a two-step process. Given an initial prompt $P$ and an initial response $R_0$, the model’s response in each iteration $R_{i+1}$ is influenced by its reflection on the previous response $R_i$. Let $f$ represent the reflexion function that evaluates and revises the response. The recursive formulation is given by:
$$ R_{i+1} = f(P, R_i) $$
where $f$ may involve criteria such as internal consistency, factual accuracy, and alignment with the prompt’s intent. This iterative refinement continues until the model achieves a response $R_n$ that meets the desired quality or relevance threshold. By embedding this feedback loop within the model’s reasoning process, Reflexion Prompting enables the model to address its own limitations, producing outputs that are not only more accurate but also more thoughtfully aligned with user needs.
In practical scenarios, Reflexion Prompting serves as an effective tool for applications in which high-quality responses are essential. For instance, in academic settings, Reflexion Prompting can assist students in verifying the accuracy of explanations or answers. By guiding the model to reflect on and validate its own responses, this technique fosters a deeper level of understanding and reliability. Similarly, in legal research, Reflexion Prompting can help ensure that responses are well-reasoned and free of critical oversights, contributing to more reliable legal advice and analysis.
Implementing Reflexion Prompting in Rust using the llm-chain crate involves creating prompts that instruct the model to critically assess its own answers. Below is an example of how this can be implemented in Rust, where the model is asked to verify its response to a complex historical question, iteratively improving its answer through reflexion:
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
use std::error::Error;
// Function to create the initial prompt for answering a question
fn initial_prompt(question: &str) -> Step {
let template = StringTemplate::from(format!(
"Answer the question: '{}'. Please provide a comprehensive answer.",
question
).as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Function to create the reflection prompt to refine the previous answer
fn reflection_prompt(previous_answer: &str) -> Step {
let template = StringTemplate::from(format!(
"Reflect on the following answer: '{}'. Identify any inaccuracies or improvements, and refine the answer for better accuracy and clarity.",
previous_answer
).as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Asynchronous function to perform initial answering and reflexive refinement
async fn answer_and_reflect(exec: &impl llm_chain::traits::Executor, question: &str) -> Result<(), Box<dyn Error>> {
// Step 1: Generate an initial answer
let initial_chain = Chain::new(vec![initial_prompt(question)]);
let initial_answer = initial_chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in generating the initial answer".to_string());
println!("Initial Answer: {}", initial_answer);
// Step 2: Refine the initial answer through reflection
let reflection_chain = Chain::new(vec![reflection_prompt(&initial_answer)]);
let refined_answer = reflection_chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in reflection process".to_string());
println!("Refined Answer: {}", refined_answer);
Ok(())
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Define the question for the initial answer and reflection
let question = "What were the main causes of the fall of the Roman Empire?";
// Run the answer and reflection sequence
answer_and_reflect(&exec, question).await
}
In this example, the initial prompt generates a response to the historical question, while the reflexion_prompt function then evaluates the initial answer for potential inaccuracies, prompting the model to refine it. This reflexive process encourages the model to critique and improve its response, leading to a final output that is more accurate and comprehensive.
Reflexion Prompting proves especially effective in domains that demand meticulous attention to detail. For instance, in scientific and technical fields, where factual precision is paramount, this technique can drive the model to re-evaluate its initial outputs, reducing the likelihood of errors. In customer service or helpdesk applications, Reflexion Prompting allows the model to cross-check its guidance or instructions, ensuring that responses align accurately with customer needs and product specifications. By instilling this self-checking layer, Reflexion Prompting enables the model to produce outputs that are consistently reliable and fit for high-stakes applications.
Evaluating the performance of Reflexion Prompting involves both quantitative and qualitative assessments. Quantitative metrics may include measures of accuracy and response coherence, comparing initial outputs with reflexively improved ones to quantify the improvement. Qualitatively, user feedback plays a crucial role, especially in real-world applications where the model’s perceived quality and trustworthiness are paramount. In academic or professional contexts, for example, user evaluations of response clarity and factual correctness can provide insights into the reflexion process’s effectiveness. Moreover, evaluation metrics may include precision-recall and F1 scores in contexts where the model’s correctness can be objectively scored.
In industry, Reflexion Prompting aligns with recent advances in AI safety and reliability, where self-assessment mechanisms are increasingly embedded to ensure model performance. For example, the application of Reflexion Prompting in medical diagnostics could allow models to review and cross-check their assessments of symptoms, improving diagnostic reliability. In automated trading, reflexive prompts can support the model in assessing the risks associated with trading decisions, creating a safeguard against potentially costly errors. As models become more autonomous and are entrusted with higher-stakes tasks, the integration of reflexive techniques like Reflexion Prompting is likely to play a key role in ensuring accountability and accuracy.
However, Reflexion Prompting introduces its own set of challenges, especially around ensuring that self-reflection is both effective and efficient. Overly extensive reflexion can lead to unnecessary verbosity, while insufficient reflexion may result in minimal improvements. Striking an optimal balance is crucial, as excessive iterations may lead to diminishing returns or prompt drift, where the response diverges from the intended goal. Techniques to manage prompt drift, such as anchoring reflexion steps to the original query, are essential in achieving consistent results without compromising accuracy.
Ethical considerations also emerge, particularly when Reflexion Prompting is used in applications involving sensitive or high-stakes decision-making. Reflexion Prompts must be carefully designed to avoid reinforcing biases, as reflexive responses could inadvertently amplify initial inaccuracies or biases if not adequately managed. In financial advisory applications, for instance, reflexive prompts must ensure impartiality in investment advice, and similar safeguards are necessary in fields such as healthcare and legal advice to uphold ethical standards and avoid potential harm.
In summary, Reflexion Prompting represents a sophisticated approach to prompt engineering that leverages self-reflection to enhance response quality and accuracy. By guiding models to engage in introspection, Reflexion Prompting enables the creation of outputs that are more thoughtful, reliable, and relevant to complex user needs. The Rust-based implementation with the llm-chain crate demonstrates the feasibility of applying Reflexion Prompting to real-world scenarios, with applications across domains where precise, accurate responses are crucial. As the field of AI continues to prioritize model reliability and self-assessment capabilities, Reflexion Prompting is likely to become an integral technique, empowering LLMs to deliver higher-quality responses in increasingly diverse and demanding applications. This iterative process of self-correction not only builds trust in model outputs but also sets new standards for accuracy and responsibility in AI-driven decision-making systems.
22.12. Multi-Modal Chain of Thought Prompting
Multi-Modal Chain of Thought (CoT) Prompting is a groundbreaking framework that enables large language models (LLMs) to process and integrate inputs from multiple data types, such as text, images, and audio. By leveraging these varied modalities, Multi-Modal CoT Prompts empower models to generate responses enriched with a broader range of contextual cues, leading to higher quality, interpretability, and contextual relevance in outputs. This approach is particularly impactful in domains requiring sophisticated reasoning across diverse data sources—such as medical diagnostics, scientific research, and interactive education—where textual, visual, and quantitative information often intersect to inform well-rounded conclusions.
Figure 8: Illustration of multi-modal CoT prompt from https://www.promptingguide.ai.
Zhang et al. (2023) introduced a pioneering multimodal CoT prompting approach that extends traditional CoT (focused solely on language) by incorporating both text and visual data into a cohesive, two-stage reasoning framework. In the first stage, the model generates a rationale using multimodal inputs, synthesizing information from each source to establish a detailed context. In the second stage, the model leverages this rationale to infer a final answer, integrating insights from both the textual and visual data to create a more comprehensive response.
Let $T$ and $I$ represent text and image inputs, respectively, and let $f$ denote the model’s multimodal chain-of-thought reasoning function. For a given prompt PPP, the multi-modal reasoning process can be described as a sequential integration of text and image data:
$$ f(P) = f(T, I) = f(f_{\text{text}}(T), f_{\text{image}}(I)) $$
In this formulation:
$f_{\text{text}}(T)$ represents the model’s reasoning over the text input, processing language-based insights.
$f_{\text{image}}(I)$ captures the model’s interpretation of visual data, such as patterns, spatial relationships, or visual cues.
The combined output $f(T, I)$ reflects the enhanced reasoning that emerges from integrating both modalities, allowing the model to reach more nuanced conclusions by drawing on the complementary strengths of textual and visual information. For instance, in medical imaging tasks, the model can analyze radiology images alongside diagnostic notes, each reinforcing the other to yield a more accurate diagnosis. In interactive educational settings, a model can process diagrams with textual explanations to clarify complex scientific or historical concepts, using visual elements to provide layers of understanding that text alone might lack.
The Multi-Modal CoT framework has shown exceptional value across various fields that require comprehensive data analysis:
Healthcare: In clinical settings, Multi-Modal CoT Prompts enable models to interpret medical images, such as MRIs or X-rays, while simultaneously considering patient histories or lab results. This integration allows the model to provide diagnoses that are not only visually informed but also contextually aligned with patient-specific information. By combining these modalities, the model supports clinicians in making more informed and accurate diagnoses, reducing diagnostic errors and improving patient outcomes.
Scientific Research: In fields like biology or physics, researchers can leverage Multi-Modal CoT to analyze complex datasets that include both graphical representations (e.g., cell images, charts) and experimental data. The model can examine visual evidence while cross-referencing textual data or numerical metrics, producing insights that are deeply contextualized and scientifically robust. This approach accelerates hypothesis generation and data interpretation in complex scientific studies.
Interactive Learning: Multi-Modal CoT Prompts can greatly enhance educational platforms by allowing models to explain subjects with both visual aids and textual narratives. For example, a model could break down physics concepts using diagrams alongside descriptive explanations, helping learners understand the underlying principles more intuitively. In history or geography lessons, maps and images combined with text-based discussions can bring abstract concepts to life, fostering a richer and more engaging learning experience.
With Multi-Modal CoT Prompting, user interactions become more natural and informative, as the model draws from multiple data sources to provide responses with greater depth and relevance. In applications like customer support, the model can process both textual descriptions and relevant images (e.g., product photos or troubleshooting screenshots) to offer more effective assistance. In educational tools, students can engage with models that respond not only with explanations but also with illustrative examples, fostering a learning environment that adapts to diverse learning styles.
The multimodal framework also improves interpretability and trustworthiness by providing users with a transparent, step-by-step reasoning process that aligns with real-world data from different sources. This transparency enables users to trace the rationale behind each response, making complex conclusions easier to understand and trust.
As AI applications continue to expand, Multi-Modal CoT Prompting offers a promising pathway toward more intelligent, context-aware systems capable of synthesizing insights across diverse data types. The capacity to reason across modalities enables LLMs to operate in environments where single-modality data would be insufficient, offering AI systems the ability to respond to multifaceted questions with the same flexibility as human experts. With further research and development, this approach could set the stage for advanced multimodal assistants in fields such as law, finance, and urban planning, where decisions are best informed by a variety of data inputs.
Implementing Multi-Modal Chain of Thought Prompting in Rust using the llm-chain crate requires creating prompts that can handle multiple inputs and processing these data types in a cohesive chain of reasoning. Below is an example of how to set up a multi-modal CoT prompt in Rust. Here, we use both text and an image URL as inputs for an educational application that describes historical artifacts by analyzing both textual information and visual cues.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
use std::error::Error;
// Function to create the text-based prompt
fn text_prompt(text: &str) -> Step {
let template = StringTemplate::from(format!(
"Based on the description: '{}', analyze the historical significance and provide insights.",
text
).as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Function to create the image-based prompt
fn image_prompt(image_url: &str) -> Step {
let template = StringTemplate::from(format!(
"Analyze the artifact visible at '{}'. Describe its features and historical context.",
image_url
).as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Asynchronous function to perform multimodal analysis
async fn multimodal_analysis(exec: &impl llm_chain::traits::Executor, description: &str, image_url: &str) -> Result<(), Box<dyn Error>> {
// Step 1: Text-based reasoning
let text_chain = Chain::new(vec![text_prompt(description)]);
let text_response = text_chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in text analysis".to_string());
println!("Text Analysis: {}", text_response);
// Step 2: Image-based reasoning
let image_chain = Chain::new(vec![image_prompt(image_url)]);
let image_response = image_chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in image analysis".to_string());
println!("Image Analysis: {}", image_response);
// Combine responses for final reasoning
let combined_response = format!("{} Additionally, the visual analysis suggests {}.", text_response, image_response);
println!("Combined Multimodal Analysis: {}", combined_response);
Ok(())
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Text and image inputs for a historical artifact
let description = "An ancient bronze helmet used by Greek warriors in the 5th century BCE.";
let image_url = "https://example.com/ancient-bronze-helmet.jpg";
// Run the multimodal analysis
multimodal_analysis(&exec, description, image_url).await
}
In this code, the text_prompt function generates a prompt for analyzing the text description, while the image_prompt function focuses on interpreting the image’s historical context. The combined response integrates insights from both modalities, leading to a richer, more comprehensive output. This example illustrates the utility of Multi-Modal CoT Prompts in educational tools, where providing context from both textual and visual data can significantly enhance understanding.
Multi-Modal CoT Prompting excels in applications where diverse data types contribute to decision-making. For instance, in e-commerce, it can be used to generate comprehensive product descriptions by combining images with user reviews or product specifications, providing potential buyers with both aesthetic and practical insights. In scientific research, Multi-Modal CoT enables models to analyze data such as visualizations of molecular structures along with textual research papers, aiding researchers in cross-referencing visual data with scientific literature. This approach enriches the model’s understanding and generates outputs that reflect a more complete perspective.
Evaluating Multi-Modal CoT prompting requires metrics that capture the quality of integration across different modalities. Precision and recall measures can assess the coherence and relevance of responses, while domain-specific evaluations may consider the accuracy of visual interpretations or alignment with textual information. Qualitative feedback from users is also valuable, as it provides insight into whether the multimodal responses are perceived as cohesive and contextually accurate. This is especially important in professional fields like healthcare and education, where user trust hinges on the model’s ability to synthesize varied data types accurately.
In industry, Multi-Modal CoT Prompting aligns with recent advancements in multimodal AI research, where models capable of processing multiple types of inputs are increasingly sought after. For example, in autonomous vehicles, multimodal models that combine visual road data with contextual map data enhance navigation decisions, improving both accuracy and safety. This trend underscores the growing demand for AI systems that can process and integrate diverse data sources in real-time applications, and Rust’s performance capabilities make it particularly suited to support these data-intensive tasks.
However, Multi-Modal CoT Prompting introduces challenges in handling complex multimodal data. Ensuring that the model accurately correlates insights from different modalities without creating conflicting interpretations requires careful prompt design. Furthermore, multimodal integration can increase computational overhead, so efficiency becomes crucial, especially in real-time applications. Techniques like parallel processing for different modalities, and selectively prioritizing relevant information from each input type, are strategies that developers can employ to manage these complexities.
Ethically, Multi-Modal CoT Prompting raises considerations around data privacy and the potential for over-reliance on AI. In healthcare, for example, multimodal models interpreting images and text from medical records must prioritize patient confidentiality and ensure that outputs are validated by human experts. Additionally, ethical considerations around the potential biases in visual or textual data inputs must be managed to prevent skewed outputs, especially in applications like hiring or legal analysis where multimodal data may reflect sensitive individual characteristics.
In conclusion, Multi-Modal Chain of Thought Prompting represents an advanced technique in prompt engineering that extends the capabilities of LLMs by integrating multiple data types into the reasoning process. By synthesizing information across modalities, this approach enables models to deliver richer, more comprehensive responses that are well-suited for complex applications demanding multi-faceted insights. Implementing Multi-Modal CoT in Rust with the llm-chain crate enables developers to design prompts that can process and interpret diverse data in tandem, facilitating enhanced performance in applications from education and research to healthcare and beyond. This approach not only enriches model responses but also expands the scope of LLM applications, enabling more versatile and intelligent interaction frameworks for end-users.
22.13. Graph Prompting
Graph Prompting introduces a structured approach to prompt engineering by leveraging graph-based representations of knowledge. This technique integrates knowledge graphs—data structures that represent entities and their relationships—to improve model understanding and response generation. By using graphs to encode hierarchical and relational information, Graph Prompting enables models to interpret complex dependencies between concepts more effectively than through text alone. In fields such as scientific research, financial analysis, and semantic search, where relationships between entities play a crucial role, Graph Prompting significantly enhances the model’s capacity to provide insightful, contextually relevant answers.
Figure 9: Motivation of Graph Prompting from Liu et.al (https://arxiv.org/pdf/2302.08043).
Formally, let $G = (V, E)$ represent a knowledge graph, where $V$ is a set of vertices (nodes) representing entities, and $E$ is a set of edges defining relationships between entities. For a prompt $P$, we design a function fff that integrates the graph structure, allowing the model to query $G$ based on both entities and relations. For example, given a query about a financial transaction between entities, Graph Prompting can identify paths between nodes representing the entities in question, enriching the prompt with structured relationships that influence the model’s output:
$$ f(P, G) = \text{Generate Response} \left( P, \{ (v_i, v_j) \in E \mid \text{relationship}(v_i, v_j) \text{ aligns with } P \} \right) $$
This approach guides the model in focusing on relevant nodes and edges within the graph, producing responses that reflect underlying relationships. In financial applications, for instance, this might mean tracing relationships between company nodes to analyze mergers, acquisitions, or investment patterns, creating a response that is informed by both direct and indirect relationships within the graph.
In practice, Graph Prompting proves valuable for domains where structured knowledge and relationship-driven reasoning are essential. For instance, in healthcare, using a knowledge graph of diseases, symptoms, and treatments enables the model to generate diagnoses that account for complex co-occurrences and dependencies. Similarly, in legal contexts, Graph Prompting can reference a knowledge graph of statutes, case laws, and precedents, allowing the model to provide legally sound interpretations by identifying and analyzing relevant legal relationships.
Implementing Graph Prompting in Rust with the llm-chain crate requires designing prompts that query graph structures and extract contextually relevant relationships for model input. Below is an example of how to set up a graph-based prompt using llm-chain. Here, we create a simple knowledge graph of academic disciplines and use it to provide context in response to a question about the relationship between two fields of study:
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use std::collections::HashMap;
use tokio;
use std::error::Error;
// Define a simple graph structure for academic disciplines
struct KnowledgeGraph {
edges: HashMap<String, Vec<String>>, // Maps a node to its connected nodes
}
impl KnowledgeGraph {
fn new() -> Self {
let mut edges = HashMap::new();
edges.insert("Physics".to_string(), vec!["Mathematics".to_string(), "Engineering".to_string()]);
edges.insert("Biology".to_string(), vec!["Chemistry".to_string(), "Medicine".to_string()]);
Self { edges }
}
// Retrieve related nodes based on a query
fn related_nodes(&self, node: &str) -> Vec<String> {
self.edges.get(node).cloned().unwrap_or_else(Vec::new)
}
}
// Define a graph-based prompt function
fn graph_prompt(query: &str, graph: &KnowledgeGraph) -> Step {
let related_nodes = graph.related_nodes(query);
let context = related_nodes.join(", ");
let template = StringTemplate::from(format!(
"Explain the relationship between {} and its related disciplines: {}.",
query, context
).as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Asynchronous function to generate response based on graph-based prompt
async fn generate_graph_response(exec: &impl llm_chain::traits::Executor, query: &str, graph: &KnowledgeGraph) -> Result<(), Box<dyn Error>> {
let prompt_step = graph_prompt(query, graph);
let chain = Chain::new(vec![prompt_step]);
let response = chain.run(parameters!(), exec).await
.map(|output| output.to_string())
.unwrap_or_else(|_| "Error in generating response".to_string());
println!("Graph-Based Analysis: {}", response);
Ok(())
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Initialize the knowledge graph and query it
let graph = KnowledgeGraph::new();
generate_graph_response(&exec, "Physics", &graph).await
}
In this code, the KnowledgeGraph struct defines a simple academic graph, where each node has connections to related disciplines. The graph_prompt function retrieves these connections for the queried node and incorporates them into the prompt, creating a response that reflects the interconnectedness of academic fields. This type of graph-based approach enhances the response by leveraging structured relationships within the data, leading to more insightful and comprehensive explanations.
Graph Prompting is particularly effective in recommendation systems, where understanding the relationships between items, users, or preferences allows the model to suggest personalized recommendations based on a user’s interactions with related items. In e-commerce, a knowledge graph might link products based on customer reviews, purchase patterns, or complementary categories, enabling the model to provide recommendations that align closely with customer preferences. This relationship-centric approach improves both the quality of recommendations and customer satisfaction by offering suggestions that reflect an understanding of complex patterns.
Evaluating Graph Prompting involves both qualitative and quantitative metrics to assess the quality of the model’s use of graph-based relationships. Accuracy measures how well the model interprets and uses graph information in responses, while relevance scores can help determine how effectively the incorporated relationships enhance contextual alignment with the prompt. User feedback also plays a role, particularly in applications where user engagement depends on the coherence and informativeness of graph-based responses. In research domains, for instance, users might evaluate the effectiveness of Graph Prompting by assessing the accuracy of relationships between scientific concepts, providing insight into the model’s reasoning depth.
In the industry, the trend toward knowledge graphs and graph-based machine learning aligns with the increasing need for models to navigate structured data effectively. In social networks, where Graph Prompting can be used to analyze relationships between users and content, the model can identify influential nodes and suggest content that reflects user interests. Additionally, in the cybersecurity field, Graph Prompting aids in analyzing networks by highlighting connections between entities such as IP addresses, servers, and network events, helping identify potential threats and vulnerabilities.
However, Graph Prompting introduces challenges in data curation and graph complexity. Knowledge graphs require careful construction and regular updates to maintain accuracy, particularly in dynamic fields like scientific research. Ensuring that the graph structure aligns well with real-world relationships without introducing noise or redundant connections is essential for effective Graph Prompting. Computational overhead also increases with graph size, so managing large-scale graphs efficiently is a critical consideration, particularly in applications that require real-time responses.
Ethical considerations for Graph Prompting primarily concern data privacy and transparency. In sensitive domains such as healthcare, graph-based data should be handled in compliance with privacy regulations like HIPAA, ensuring that relationships between patients, treatments, and medical conditions are protected. Transparency is also essential; in financial or legal applications, the model’s reliance on specific graph relationships must be clear to avoid misinterpretations that could impact decision-making.
In conclusion, Graph Prompting offers a structured approach to enhancing prompt engineering by embedding knowledge graphs within the prompting process. By incorporating graph-based relationships, models gain the ability to interpret complex dependencies, producing responses that reflect a richer understanding of interconnected data. The Rust-based implementation with llm-chain demonstrates the practicality of applying Graph Prompting in real-world applications, where graph-based reasoning enhances the model’s interpretive depth and relevance. From healthcare to social networks and cybersecurity, Graph Prompting is transforming how models interact with data, bringing new layers of insight and contextual awareness to AI-driven responses. This structured approach empowers models to deliver responses that are both contextually rich and practically useful, setting new standards for structured and intelligent AI interaction frameworks.
22.14. Conclusion
In conclusion, Chapter 22 provides a comprehensive exploration of advanced prompt engineering techniques using the llm-chain crate. By mastering these techniques, readers can significantly enhance the effectiveness and flexibility of large language models, driving forward the capabilities of AI applications.
22.14.1. Further Learning with GenAI
These prompts cover theoretical foundations, practical implementations, and detailed examples of each technique. By exploring these prompts, readers will gain a thorough understanding of how to effectively use advanced prompting methods with the llm-chain Rust crate to enhance large language model (LLM) performance and versatility.
Describe the Chain of Thought (CoT) prompting technique in depth. How does it function to decompose complex problems into intermediate reasoning steps, and what specific mechanisms are involved in generating these steps? Discuss its impact on model interpretability and performance, and provide examples of tasks where CoT is particularly effective.
Explain Meta Prompting in detail, focusing on its ability to influence the generation of subsequent prompts or responses. How does the meta-prompting framework work, and what are the key strategies for designing meta-prompts that guide the model's behavior effectively? Include examples of how Meta Prompting can be applied in various NLP applications.
Discuss the Self-Consistency Prompting method, including its approach to generating multiple outputs and selecting the most consistent one. How does this technique improve the reliability of model responses, and what are the best practices for implementing and tuning Self-Consistency Prompting to achieve optimal results?
Analyze Generate Knowledge Prompting and its role in eliciting specific types of knowledge from a model. How can this technique be utilized to target particular areas of knowledge or expertise, and what are the practical steps involved in designing prompts that effectively generate desired knowledge outputs?
Detail the Prompt Chaining technique, where multiple prompts are linked together to build complex interactions. How does chaining enhance the model’s ability to handle intricate tasks or dialogues, and what are the key considerations for creating and managing effective prompt chains in Rust using the
llm-chaincrate?Explain the Tree of Thoughts (ToT) Prompting approach, focusing on its structured framework for organizing and visualizing model reasoning. How does ToT enable a more systematic exploration of ideas and solutions, and what are the challenges and benefits of implementing this technique in large-scale NLP tasks?
Describe Automatic Prompt Engineering and its mechanisms for optimizing prompt design through automation. How does this technique leverage machine learning or other methods to automatically generate and refine prompts, and what are the implications for prompt quality and efficiency?
Discuss Active-Prompt and how it dynamically adjusts prompts based on real-time model feedback. What are the benefits of using Active-Prompt in interactive and adaptive applications, and how can it be implemented to enhance user interaction and model responsiveness?
Examine ReAct Prompting and its methodology for integrating reasoning and action into the prompting process. How does ReAct Prompting improve decision-making capabilities of the model, and what practical steps are involved in applying this technique to complex tasks?
Outline Reflexion Prompting and its approach to self-evaluation and improvement. How does Reflexion Prompting enable models to refine their outputs based on internal or external feedback, and what are the practical considerations for implementing this technique effectively?
Explore Multi-Modal Chain of Thought Prompting and its application in combining multiple data modalities (e.g., text and images). How does this technique benefit models that handle diverse input types, and what are the challenges of integrating multi-modal information in prompting?
Detail Graph Prompting and its use of graph-based representations to enhance model understanding and reasoning. How does Graph Prompting leverage graph structures to improve output relevance and accuracy, and what are the steps involved in implementing this technique in Rust?
Analyze the impact of different prompt lengths and structures on model performance. How does varying the length and complexity of prompts affect the quality and coherence of generated outputs, and what are the guidelines for designing effective prompts?
Discuss how prompt engineering can be tailored to specific domains or industries (e.g., legal, medical). What techniques and considerations are necessary for adapting prompts to specialized contexts, and how can Rust be used to implement domain-specific prompts effectively?
Evaluate the trade-offs between prompt specificity and generality. How do specific versus general prompts influence model performance, and what strategies can be used to balance these factors for different applications?
Explore the role of prompt temperature and other hyperparameters in controlling the creativity and coherence of model outputs. How do these parameters impact the generated text, and what are the best practices for tuning them in Rust applications?
Investigate the potential for combining multiple advanced prompting techniques in a single application. How can techniques like CoT and Meta Prompting be integrated to achieve enhanced model performance, and what are the challenges and benefits of such integrations?
Describe the use of feedback loops in advanced prompting techniques. How can real-time or iterative feedback be incorporated into prompt design to continuously improve model outputs, and what are the practical considerations for implementing feedback loops in Rust?
Discuss the ethical considerations of advanced prompt engineering. What potential biases or unintended consequences might arise from sophisticated prompting techniques, and how can developers mitigate these issues?
Analyze the impact of prompt engineering on model training and fine-tuning. How do advanced prompting techniques influence the training process, and what are the implications for model accuracy and generalization?
Embrace the opportunity to experiment, innovate, and refine your skills with the llm-chain crate, and you'll contribute to the forefront of AI development. Your dedication to understanding and applying these techniques will drive impactful advancements in the field, empowering the next generation of intelligent systems.
22.14.2. Hands On Practices
Self-Exercise 22.1: Implementing Chain of Thought Prompting
Objective: Develop and evaluate a Chain of Thought prompting system to improve model interpretability and response quality in complex problem-solving scenarios.
Tasks:
Design a Chain of Thought Prompt: Create a multi-step prompt for a complex problem that requires intermediate reasoning. Ensure each step logically leads to the next.
Implement in GenAI: Use the provided Rust crates to set up and run the Chain of Thought prompts.
Evaluate Performance: Assess the output for clarity and correctness. Compare it with outputs from simpler, less detailed prompts.
Iterate and Improve: Refine the prompt based on performance evaluation, focusing on enhancing the model's intermediate reasoning accuracy.
Deliverables:
A detailed Chain of Thought prompt design.
Code snippet demonstrating the implementation in Rust.
Evaluation report comparing the results of Chain of Thought prompting with baseline prompts.
Refined prompt based on evaluation feedback.
Exercise 22.2: Crafting and Utilizing Meta Prompts
Objective: Create and test Meta Prompts to influence model behavior and generate adaptive responses.
Tasks:
Design Meta Prompts: Develop several meta-prompts that can guide the model’s behavior in generating responses or creating further prompts.
Implement in GenAI: Use Rust to integrate and test these meta-prompts in various scenarios.
Analyze Model Responses: Evaluate how the meta-prompts influence the model’s responses. Document any patterns or changes in behavior.
Optimize Prompts: Refine the meta-prompts based on observed model behavior to improve effectiveness.
Deliverables:
Collection of Meta Prompts with explanations.
Rust code implementing these meta-prompts.
Analysis report on how each meta-prompt influences model behavior.
Revised meta-prompts based on analysis findings.
Self-Exercise 22.3: Exploring Self-Consistency Prompting
Objective: Implement Self-Consistency Prompting to ensure reliable outputs and assess its effectiveness in generating consistent results.
Tasks:
Create Self-Consistency Prompts: Design prompts that require generating multiple responses to assess consistency.
Run Experiments: Implement these prompts in Rust, generating multiple outputs for each prompt.
Evaluate Consistency: Analyze the consistency of the outputs, noting any variations or discrepancies.
Adjust and Optimize: Refine the prompts or the approach to improve output consistency.
Deliverables:
Set of Self-Consistency prompts with detailed instructions.
Rust code demonstrating the implementation and generation of multiple outputs.
Evaluation report on output consistency.
Optimized prompts based on evaluation results.
Self-Exercise 22.4: Applying Generate Knowledge Prompting
Objective: Utilize Generate Knowledge Prompting to extract specific knowledge and evaluate its effectiveness in targeted knowledge retrieval.
Tasks:
Design Knowledge-Focused Prompts: Create prompts designed to elicit specific knowledge or information from the model.
Implement and Test: Use Rust to set up these prompts and generate responses.
Assess Knowledge Accuracy: Evaluate the accuracy and relevance of the knowledge retrieved.
Refine Prompts: Adjust the prompts based on the accuracy and relevance of the responses to improve knowledge extraction.
Deliverables:
Collection of knowledge-focused prompts with explanations.
Rust code for implementing and testing these prompts.
Accuracy and relevance assessment report.
Refined prompts based on evaluation feedback.
Self-Exercise 22.5: Developing and Testing Prompt Chaining
Objective: Create a system of Prompt Chaining to manage complex interactions and evaluate its impact on handling intricate tasks.
Tasks:
Design a Chain of Prompts: Develop a sequence of interconnected prompts that build on each other to handle a complex task.
Implement in GenAI: Use Rust to link these prompts and execute the chain.
Test and Evaluate: Assess how well the prompt chain handles the complexity of the task, noting any strengths and weaknesses.
Iterate and Enhance: Refine the prompt chain based on performance evaluation to improve overall handling of the task.
Deliverables:
Detailed design of the prompt chain with explanation of each link.
Rust code for implementing and executing the prompt chain.
Performance evaluation report on the prompt chain’s effectiveness.
Refined prompt chain based on evaluation findings.
Comments