Chapter 21
Few-Shot and Zero-Shot Prompting with LLMs
Few-shot and zero-shot learning represent the frontier of AI’s ability to generalize from minimal data, transforming how we interact with and utilize large language models." - Geoffrey Hinton
Chapter 21 of LMVR explores the implementation and application of few-shot and zero-shot prompting techniques using the llm-chain Rust crate. It begins by defining these prompting methods and comparing them to traditional supervised learning, highlighting their importance in NLP tasks. The chapter then delves into practical implementation, focusing on designing effective prompts and leveraging the llm-chain crate to execute few-shot and zero-shot tasks. It covers both conceptual and practical aspects, including prompt engineering, context utilization, and performance evaluation. The chapter aims to provide a comprehensive guide to applying these advanced prompting techniques in Rust-based LLM applications.
21.1. Introduction to Zero-Shot and Few-Shot Promptings
Zero-shot and few-shot prompting represent significant advancements in natural language processing, empowering large language models (LLMs) to generalize across a wide array of tasks with minimal task-specific input. By leveraging vast pre-training on diverse data sources, these prompting techniques enable models to adapt to new tasks without requiring extensive labeled datasets. This capability marks a departure from traditional supervised learning, which relies heavily on labeled examples for each unique task. Through the effective use of structured prompts, zero-shot and few-shot prompting provide flexibility in task handling, allowing LLMs to operate seamlessly across diverse applications such as sentiment analysis, summarization, and translation with minimal additional guidance.
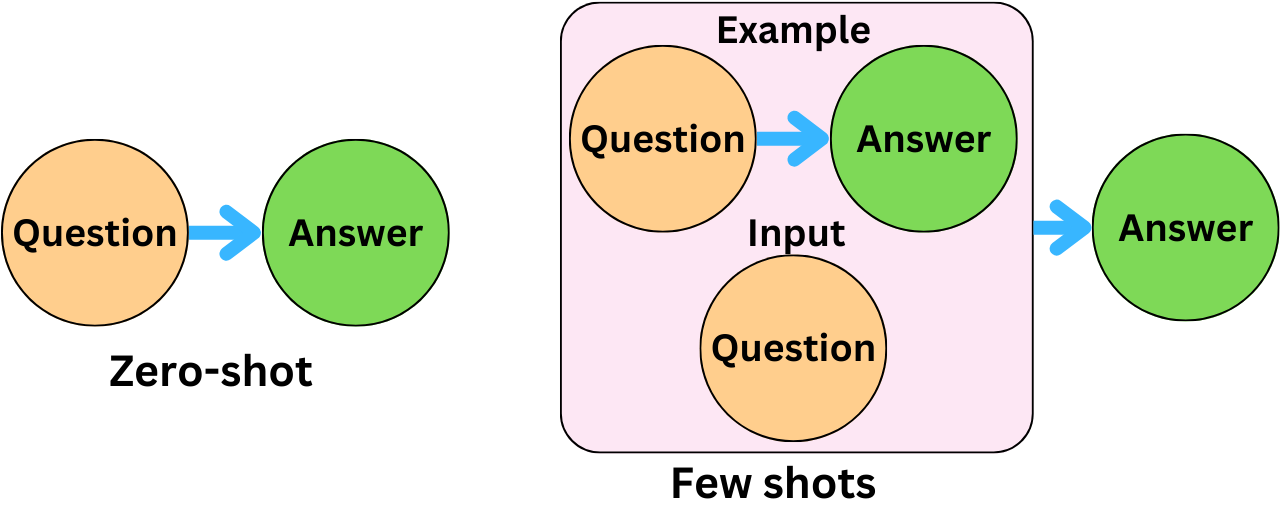
Figure 1: Illustration on Zero-shot vs Few-shot promptings.
In zero-shot prompting, the model operates solely on a clear task description without the aid of task-specific examples. For instance, a prompt might direct the model to “classify the sentiment of this statement” or “summarize the following text in one sentence.” Despite the absence of examples, the model can often fulfill these tasks accurately by drawing on its pre-trained understanding of language, context, and meaning. The model’s autoregressive framework underpins this ability, as it predicts each token in a sequence $X = (x_1, x_2, \dots, x_n)$ with a probability defined by the formula:
$$P(X) = \prod_{i=1}^n P(x_i | x_{1:i-1}),$$
where each term $P(x_i | x_{1:i-1})$ represents the likelihood of a token given its preceding context. This probabilistic formulation allows the model to generate coherent outputs by sequentially interpreting each token, aligning its response with the task description embedded in the prompt. Consequently, zero-shot prompting can effectively guide the model through tasks that require straightforward instructions, though it may encounter challenges with complex reasoning or specialized knowledge, which can benefit from examples.
Few-shot prompting enhances this process by incorporating a limited set of task-specific examples within the prompt, which serves as in-context demonstrations. For example, in a language translation task, the prompt might present a few translations before requesting a new translation from the model. These examples enable the model to recognize and generalize patterns relevant to the task, fostering an in-context learning process where the model adapts its output without altering its internal parameters. The examples within a few-shot prompt act as conditioning agents, helping the model understand and replicate desired structures in its response. This is particularly effective in scenarios where zero-shot prompting may lack specificity, as few-shot examples provide immediate context that clarifies the task requirements.
Few-shot prompting’s strength lies in its ability to handle tasks demanding contextual understanding or complex structures by refining the model’s grasp of task-specific patterns. By observing consistent formatting and structural cues from the provided examples, the model can navigate nuanced requirements and produce more accurate responses. Few-shot prompting thus balances brevity with clarity, allowing the model to handle complex queries effectively within token constraints. This approach mitigates potential ambiguities in zero-shot scenarios, making it particularly useful for tasks that benefit from demonstrated examples, such as text completion, analogy generation, and sentiment classification.
The contrast between zero-shot and few-shot prompting illustrates the adaptability of LLMs and the transformative role of structured prompts in enhancing model performance. While zero-shot prompting provides a minimalist solution for simpler tasks, relying purely on clear instructions, few-shot prompting offers an expanded capacity to generalize across more sophisticated tasks by including examples. Both techniques rest on the same autoregressive architecture, utilizing probability distributions to generate coherent outputs. However, the added context in few-shot prompts often reduces ambiguity, increasing accuracy in tasks where zero-shot approaches may fall short.
As model scale continues to grow, the capacity for zero-shot and few-shot prompting has broadened, allowing LLMs to tackle increasingly complex applications. These prompting methods reduce the need for extensive labeled datasets, promoting rapid task adaptation and marking a critical advancement in NLP scalability and efficiency. With continued refinement, zero-shot and few-shot prompting techniques promise to further extend the versatility of LLMs, positioning them as flexible and accessible tools for a wide array of real-world applications, from customer support to content generation and interactive learning environments.
To implement few-shot and zero-shot prompting in Rust, we can leverage the llm-chain crate, which supports chainable operations for building and managing complex LLM tasks. The following Rust code demonstrates how to perform zero-shot and few-shot prompting with a language model using the llm_chain crate. It initializes prompts for two types of tasks: summarizing text without examples (zero-shot) and summarizing with examples (few-shot), showing how to interact with a language model in a structured and efficient way. The tokio asynchronous runtime enables concurrent execution, handling tasks that interact with remote APIs, such as calling a model from ChatGPT.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
tokenizers = "0.20.3"
reqwest = { version = "0.12", features = ["blocking"] }
rayon = "1.10.0"
regex = "1.11.1"
llm-chain = "0.13.0"
llm-chain-openai = "0.13.0"
tokio = "1.41.1"
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
// Sample task description for zero-shot prompting
fn zero_shot_prompt() -> Step {
let template = StringTemplate::from("Summarize the following text in one sentence.");
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
// Few-shot examples for summarization task
fn few_shot_prompt() -> Step {
let prompt_content = "Below are some examples of text summarization:\n\n\
Text: The Rust programming language offers safety and speed.\n\
Summary: Rust provides both safety and efficiency.\n\n\
Text: Large language models are transforming NLP.\n\
Summary: LLMs revolutionize natural language processing.\n\n\
Text: This book introduces readers to advanced machine learning topics.\nSummary:";
let template = StringTemplate::from(prompt_content);
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Initialize options for the ChatGPT model
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Perform zero-shot prompting
let zero_shot_chain = Chain::new(vec![zero_shot_prompt()]);
let zero_shot_result = zero_shot_chain.run(parameters!(), &exec).await?;
println!("Zero-Shot Summary: {}", zero_shot_result.to_string());
// Perform few-shot prompting
let few_shot_chain = Chain::new(vec![few_shot_prompt()]);
let few_shot_result = few_shot_chain.run(parameters!(), &exec).await?;
println!("Few-Shot Summary: {}", few_shot_result.to_string());
Ok(())
}
The code defines two functions, zero_shot_prompt and few_shot_prompt, which set up specific prompts by converting text into the format expected by the llm_chain library. These prompts are wrapped in Step objects and added to Chain sequences, representing tasks for the model to execute. In the main function, the code initializes the API with an executor configured with an API key for ChatGPT. Each prompt is run asynchronously with .run(...), and results are awaited and printed. This setup allows the model to generate summaries based on zero-shot and few-shot prompts, showcasing how different prompt structures affect model responses.
Few-shot and zero-shot prompting also face limitations, particularly when attempting to perform tasks that require extensive domain knowledge or specialized reasoning. The primary challenge is that these methods rely heavily on the pre-trained knowledge encoded in the model, which may not fully cover specialized tasks. Few-shot prompting may be insufficient if the task-specific examples do not encompass the necessary nuances, while zero-shot prompting relies entirely on the model’s ability to generalize based on the task description. Consequently, the effectiveness of these techniques varies across applications, with some tasks requiring additional fine-tuning or more detailed prompts to ensure accuracy and relevance.
Performance benchmarking is crucial to evaluating the effectiveness of few-shot and zero-shot prompting techniques. Quantitative metrics, such as accuracy, F1 score, or BLEU (Bilingual Evaluation Understudy) score, can help gauge prompt quality across tasks, while qualitative assessment is useful for evaluating more subjective aspects like coherence and relevance. Rust’s performance characteristics make it suitable for high-frequency benchmarking tasks, as it enables efficient memory management and concurrency, which are valuable when performing repeated prompt testing on large datasets. Through iterative benchmarking, developers can adjust the prompt structure, examples, or task instructions to refine model responses, ensuring that few-shot and zero-shot prompting setups yield optimal results.
In industry, few-shot and zero-shot prompting are increasingly used in customer service automation, where responses need to be generated accurately without extensive fine-tuning. For instance, a few-shot setup might be used to handle queries related to specific products, where prompts include a few examples of typical questions and responses. Zero-shot prompting is valuable for answering open-ended queries, as it allows the model to interpret the user’s question based on the task description alone. These prompting strategies save both time and resources, as they eliminate the need for labor-intensive dataset curation and model retraining, allowing companies to deploy adaptable, efficient systems that respond to diverse user inputs.
As research and technology evolve, we see emerging trends in few-shot and zero-shot prompting that further extend their utility. Dynamic prompt generation, for example, adapts prompt structures based on previous interactions, optimizing prompt configuration in real time. This approach improves LLM flexibility and responsiveness, particularly in complex environments where user needs and inputs are unpredictable. The use of reinforcement learning in prompt refinement is another promising area, enabling prompts to be adjusted based on user feedback and model performance metrics. These advancements enhance few-shot and zero-shot prompting methods, allowing LLMs to become even more capable in handling new and complex tasks without extensive customization.
In summary, few-shot and zero-shot prompting are revolutionary techniques that enable LLMs to generalize and adapt to new tasks with minimal or no additional data. By leveraging autoregressive modeling and self-supervised learning, these approaches allow models to provide contextually relevant responses based on limited or zero explicit training. Implementing these techniques in Rust using the llm-chain crate provides a robust framework for designing and deploying prompt configurations suited for various applications. Although limitations exist, particularly in specialized domains, emerging techniques such as dynamic prompting and reinforcement learning offer promising directions for future development. Few-shot and zero-shot prompting continue to redefine the landscape of NLP, enabling scalable, adaptable systems that meet the needs of diverse industries with unprecedented efficiency and flexibility.
21.2. Implementing Zero-Shot Prompting with llm-chain
Zero-shot prompting represents a transformative approach in natural language processing, where models perform tasks without any explicit examples or task-specific training. In zero-shot prompting, an LLM leverages its extensive pre-trained knowledge to interpret and execute tasks based purely on natural language instructions provided in the prompt. This technique is particularly valuable when there is limited or no labeled data for a specific task, as the model generalizes its responses based on patterns it has learned during pre-training. Unlike few-shot prompting, which uses task-specific examples to guide the model, zero-shot prompting depends entirely on the model’s ability to transfer and apply prior knowledge in unfamiliar contexts.
Zero-shot prompting is grounded in the principles of transfer learning, where a model trained on one set of tasks transfers its knowledge to new tasks. In the context of LLMs, transfer learning allows a model to perform a range of functions, from text generation to classification, without further task-specific adjustments. This capability is based on the model’s internal representation of language, built through extensive exposure to diverse textual data during pre-training. Mathematically, zero-shot prompting can be represented as a function $f(P) \rightarrow O$, where $P$ is the task description in the prompt and $O$ is the model’s output. The model relies on its generalized understanding of language to map $P$ to $O$, achieving an implicit form of generalization.
Zero-shot prompting can be applied to both generative and predictive tasks. In generative tasks, such as summarization or text generation, the prompt serves as an instruction, guiding the model to produce a coherent output based on the information it has previously learned. For instance, a prompt like “Summarize the following article in one sentence” can instruct the model to generate a summary without prior examples of how to summarize. Predictive tasks, such as text classification or entity recognition, also benefit from zero-shot prompting. Here, the prompt serves as a query, asking the model to make a prediction based on its understanding of language patterns. By framing prompts appropriately, developers can guide the model to perform a variety of NLP tasks even when explicit training data is unavailable.
To implement zero-shot prompting in Rust, the llm-chain crate provides a flexible and efficient framework for structuring and executing prompts. This Rust program demonstrates how to perform a zero-shot text summarization task using the llm_chain library, which facilitates interaction with large language models (LLMs) such as ChatGPT. The program is designed to prompt the model to summarize a given text in one sentence without providing any examples, showcasing the model's ability to infer task requirements directly from the prompt.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
// Function to create a zero-shot prompt for text summarization
fn zero_shot_summary_prompt() -> Step {
let prompt_content = "Summarize the following text in one sentence:\n\n\
Text: Rust is a systems programming language focused on safety, speed, and concurrency.";
let template = StringTemplate::from(prompt_content);
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Perform zero-shot prompting for text summarization
let zero_shot_chain = Chain::new(vec![zero_shot_summary_prompt()]);
let zero_shot_result = zero_shot_chain.run(parameters!(), &exec).await?;
println!("Zero-Shot Summary Result: {}", zero_shot_result.to_string());
Ok(())
}
In the code, a function zero_shot_summary_prompt constructs the summarization prompt by embedding a sentence about the Rust programming language within a StringTemplate. This template is wrapped in a Data::text object, which is then formatted as a Step in a Chain—a sequence that the model can execute. In the main function, the program initializes the API executor with an API key, runs the summarization prompt asynchronously via Chain, and retrieves the result. The output is then printed, displaying the model’s response based on its zero-shot understanding of the task. This setup exemplifies how zero-shot prompting can enable models to generalize across tasks with minimal input.
Zero-shot prompting’s applicability extends to various NLP tasks, from sentiment analysis to question answering. In a sentiment analysis setup, for instance, a prompt like “Determine whether the following statement is positive or negative” can guide the model to classify sentiment without training examples. Similarly, in entity extraction, a prompt such as “Identify the organizations mentioned in the following sentence” can direct the model to recognize entities, leveraging its general language understanding to perform the task. These examples highlight the versatility of zero-shot prompting, as developers can define complex tasks with minimal prompt engineering, allowing the model to adapt to diverse applications with ease.
Assessing the performance of zero-shot prompts requires a mix of quantitative and qualitative evaluation methods. For predictive tasks, quantitative metrics like accuracy and F1 score provide a basis for evaluating prompt effectiveness, as they measure the model’s ability to make accurate predictions based on the prompt alone. For generative tasks, qualitative evaluation is equally important, as it helps gauge aspects like coherence, relevance, and clarity in the generated outputs. In Rust, benchmarking tools can be used to automate these assessments, providing a scalable solution for evaluating large numbers of zero-shot prompts across different tasks. The llm-chain crate’s efficient execution model makes it suitable for high-frequency evaluation workflows, enabling developers to refine prompt structures rapidly.
Despite its advantages, zero-shot prompting also faces limitations. The model’s responses may vary significantly depending on the phrasing of the prompt, as zero-shot prompting relies heavily on the clarity and specificity of task instructions. In complex tasks, ambiguous prompts may result in incorrect outputs, as the model lacks explicit examples to guide its responses. Additionally, zero-shot prompting may struggle in specialized domains where the model’s pre-trained knowledge is limited. In such cases, domain-specific prompts may still fail to yield accurate results, requiring alternative approaches like few-shot prompting or fine-tuning to enhance performance.
In industry, zero-shot prompting has found applications in content moderation, customer support automation, and information retrieval. For example, in content moderation, a zero-shot prompt might instruct the model to flag inappropriate content based on a natural language description of moderation guidelines. Similarly, in customer support, zero-shot prompts can be used to generate responses to frequently asked questions, leveraging the model’s general understanding of language to provide accurate and relevant answers without extensive fine-tuning. These applications demonstrate the flexibility and efficiency of zero-shot prompting, as companies can implement powerful NLP solutions without the overhead of task-specific training data.
As research advances, trends in zero-shot prompting are moving toward more adaptive and context-aware approaches. Dynamic prompt adjustment, for instance, allows models to refine their responses based on real-time user interactions or system feedback. Reinforcement learning techniques are also being explored, where zero-shot prompts are optimized through feedback loops that reward desirable model outputs. Additionally, hybrid prompting techniques are emerging, where zero-shot prompts are combined with few-shot examples to enhance response consistency. Rust’s concurrency capabilities make it well-suited for implementing these adaptive methods, as it allows for efficient real-time prompt processing and interaction with complex models.
In summary, zero-shot prompting enables LLMs to perform tasks without explicit examples or task-specific training, making it an invaluable tool in NLP applications where labeled data is scarce. Through transfer learning and pre-trained knowledge, zero-shot prompting allows models to generalize across diverse tasks with minimal customization. The llm-chain crate in Rust provides a powerful framework for implementing and evaluating zero-shot prompts, offering developers a streamlined approach to harnessing the capabilities of large language models. While zero-shot prompting has limitations, its applications continue to expand, with emerging trends suggesting even greater adaptability and performance in future implementations. As zero-shot prompting matures, it will remain a central technique in advancing LLM applications, enabling more robust and versatile AI-driven solutions across industries.
21.3. Implementing Few-Shot Prompting with llm-chain
Few-shot prompting is a powerful technique in natural language processing, where a model is given a limited set of task-specific examples to guide its behavior in generating or classifying text. Unlike traditional supervised learning, which requires large labeled datasets, few-shot prompting allows a model to infer task structure and requirements with only a handful of illustrative examples. By providing these examples within the prompt, the model learns the task’s implicit rules and applies them to generate responses that align with the intended objective. This capability is particularly useful in situations where obtaining large amounts of labeled data is impractical, enabling rapid deployment across diverse applications.
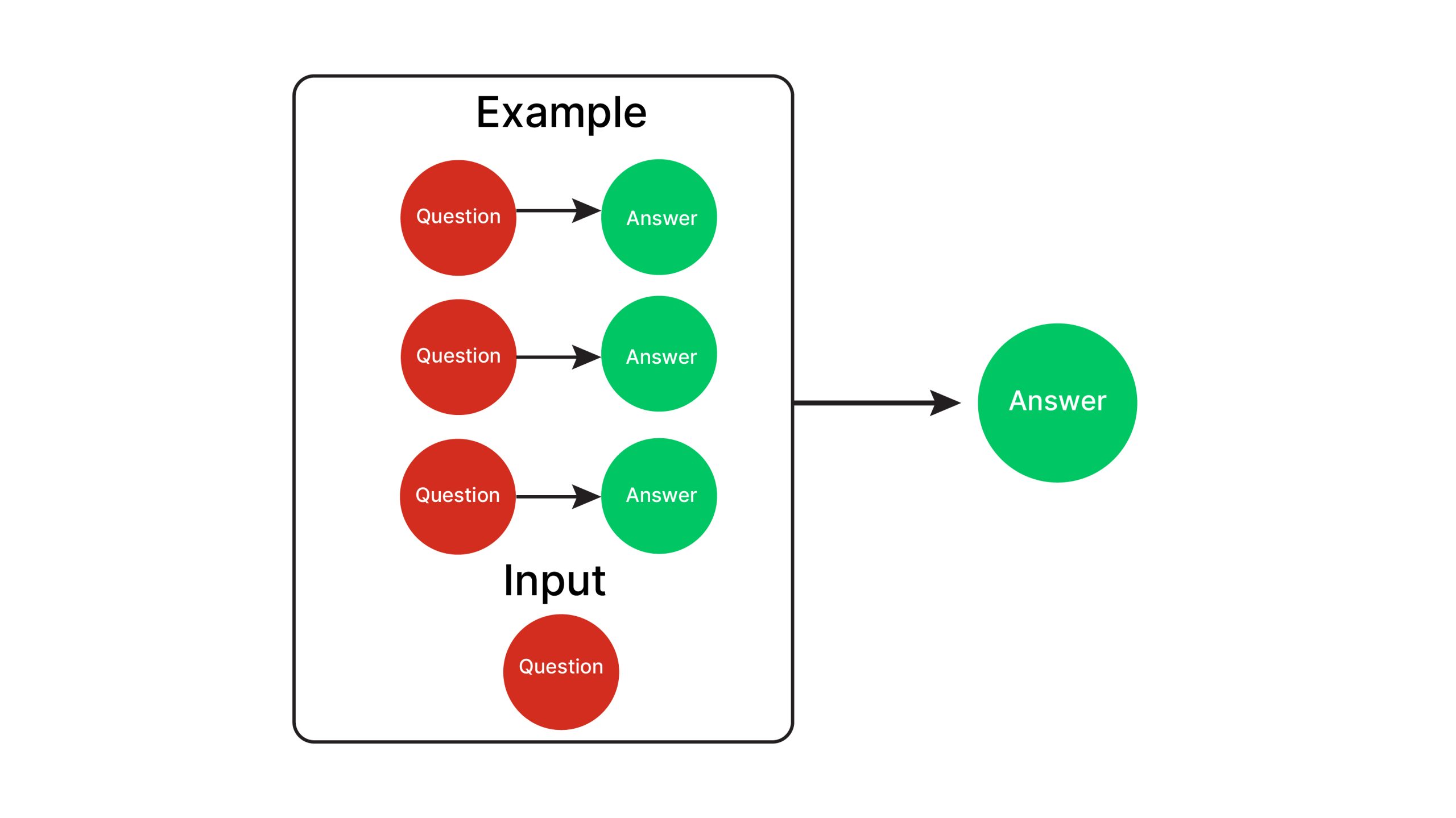
Figure 2: Key concept of few-shot prompting.
Designing effective prompts for few-shot learning is crucial for maximizing the performance of language models. An optimal few-shot prompt balances context, clarity, and brevity to ensure the model can correctly infer the task pattern. For instance, each example within the prompt should contain distinct cues that delineate the task requirements while maintaining a consistent format across examples to reinforce the desired behavior. Mathematically, a few-shot prompt can be represented as a sequence of example pairs $(x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)$ followed by a query input $x_{n+1}$. The model is tasked with predicting $y_{n+1}$ based on the pattern observed in the prior pairs. This setup leverages the model’s ability to generalize and recognize analogies, allowing it to interpret the task rules and apply them effectively.
In crafting few-shot prompts, a key aspect is prompt engineering, the art of structuring input sequences to elicit optimal model performance. Effective prompt engineering for few-shot scenarios involves techniques such as ordering examples to reflect varied but relevant cases, using contextual hints within each example, and ensuring clear boundaries between examples and the query input. For example, a sentiment analysis prompt might include a few sentences labeled as either “Positive” or “Negative,” each clearly indicating sentiment. This not only helps the model infer the labeling scheme but also reduces ambiguity, allowing it to predict sentiment accurately on new, unseen inputs. The goal is to create a prompt that clearly communicates the task’s format and constraints, which, in turn, maximizes model consistency in response generation.
The llm-chain crate in Rust provides a flexible framework for implementing few-shot prompting setups. It allows developers to construct prompt sequences, chain them, and interact with LLMs for a range of applications. This Rust program demonstrates a few-shot prompting approach for sentiment classification using the llm_chain. The code is designed to classify the sentiment of sentences as either "Positive" or "Negative" by providing a few examples of sentiment-labeled sentences. It constructs a chain of steps to prompt a large language model (LLM), such as ChatGPT, to classify a new input sentence based on the provided examples. The program utilizes asynchronous execution to handle remote model interactions efficiently.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
// Function to create a few-shot prompt for sentiment classification
fn few_shot_sentiment_prompt() -> Step {
let prompt_content = "Classify the sentiment of each sentence as Positive or Negative:\n\n\
Sentence: I love the new Rust features! Sentiment: Positive\n\
Sentence: The program keeps crashing unexpectedly. Sentiment: Negative\n\
Sentence: I am very satisfied with the model’s performance. Sentiment: Positive\n\
Sentence: The new update has several bugs. Sentiment:";
let template = StringTemplate::from(prompt_content);
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Initialize options with your API key
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
// Create a ChatGPT executor
let exec = executor!(chatgpt, options)?;
// Perform few-shot prompting for sentiment classification
let few_shot_chain = Chain::new(vec![few_shot_sentiment_prompt()]);
let few_shot_result = few_shot_chain.run(parameters!(), &exec).await?;
println!("Sentiment Classification Result: {}", few_shot_result.to_string());
Ok(())
}
The code defines a function, few_shot_sentiment_prompt, which creates a prompt containing labeled examples of sentences with their respective sentiments. This prompt is formatted as a StringTemplate, wrapped in Data::text, and then embedded in a Step that represents a single unit of the chain for execution. The main function initializes API access using an executor with an API key and runs the sentiment classification prompt asynchronously through the Chain. After execution, the result is printed, showing the model’s sentiment classification based on the examples provided. This approach demonstrates how few-shot prompting can help the model generalize from examples to classify new text effectively.
Few-shot prompting has diverse applications, ranging from text classification to content generation. For instance, in legal or compliance settings, few-shot prompts can provide the model with examples of legal clauses, guiding it to identify similar clauses in new documents. In finance, few-shot prompting can assist with sentiment analysis on financial news, where a few labeled examples allow the model to classify the sentiment of new articles with high accuracy. By selecting representative examples, developers can adapt few-shot prompting for nearly any application, allowing models to generalize across tasks with minimal customization.
To evaluate the effectiveness of few-shot prompting, several metrics can be used. Quantitative metrics such as accuracy, F1 score, and recall provide a basis for assessing prompt quality, particularly in tasks like classification or summarization. Qualitative evaluation is also essential, especially in open-ended tasks where metrics alone may not capture subtleties in output quality. Human evaluation, in this case, can provide insights into aspects like relevance, coherence, and linguistic fluency. Rust’s efficiency and type safety facilitate the benchmarking of few-shot prompts across large datasets, making it possible to analyze performance at scale. By automating the evaluation of different prompt structures and example variations, developers can quickly identify the configurations that yield the best results.
However, few-shot prompting does face limitations, particularly when applied to tasks that require extensive contextual understanding. In situations where the examples fail to capture the full complexity of the task, the model may struggle to generalize effectively. Additionally, the reliance on few-shot prompting can make outputs highly sensitive to the order and phrasing of examples. In our sentiment classification example, including highly ambiguous sentences could lead to varied interpretations, impacting the model’s output consistency. Consequently, the limitations of few-shot prompting are often mitigated through iterative refinement and optimization of prompts, enabling them to serve as effective stand-ins for full-scale training in constrained scenarios.
Emerging trends in few-shot prompting indicate a growing focus on automating the prompt design process and refining models to be more robust against prompt variability. One approach is reinforcement learning for prompt optimization, where prompt structures are adjusted dynamically based on model performance, allowing for adaptive few-shot setups that can respond to different data distributions. Additionally, prompt tuning—where prompts themselves are fine-tuned on a task-specific dataset—has shown promise in improving few-shot model performance, particularly for challenging NLP tasks. These developments signal an evolving landscape where few-shot prompting will likely become even more powerful and reliable, paving the way for highly adaptable, low-data NLP solutions.
In summary, few-shot prompting is an innovative technique that enables LLMs to generalize across tasks with minimal examples, offering a scalable solution for a variety of applications. By leveraging the llm-chain crate in Rust, developers can implement and evaluate few-shot prompts with high efficiency, harnessing the capabilities of large language models in tasks ranging from text classification to content generation. Despite its limitations, few-shot prompting continues to advance with the integration of automation and reinforcement learning, positioning it as a critical tool for future NLP deployments. Through effective prompt engineering and ongoing refinement, few-shot prompting is poised to revolutionize the way we interact with language models, making sophisticated AI solutions accessible even in data-limited scenarios.
21.4. Advanced Techniques and Customization
As prompt engineering matures, combining few-shot and zero-shot prompting techniques has emerged as a powerful approach for handling complex and nuanced tasks in natural language processing. Few-shot prompting provides the model with examples to infer task patterns, while zero-shot prompting relies solely on instructional descriptions, leveraging the model's internal knowledge. By combining these approaches, we can sequentially guide the model through complex tasks, setting up an initial zero-shot prompt to establish task understanding and using few-shot examples to reinforce and refine the model's output. This hybrid approach allows developers to navigate the strengths of both methods, achieving high performance even in specialized applications where one approach alone may fall short.
To illustrate the mathematical interplay between few-shot and zero-shot prompting, consider a task sequence represented as $S = (P_1, P_2, \dots, P_n)$, where each $P_i$ is a prompt that incrementally builds on the task objective. The few-shot components contribute example-based learning, represented as conditional probability terms $P(Y | X, E)$, where $X$ is the input text and $E$ are the examples provided. Zero-shot components, in turn, rely on generalization probability $P(Y | X, I)$, with $I$ as the instructional prompt. By layering these, we construct a probabilistic function that combines $E$ and $I$ to iteratively refine outputs. This hybrid technique is particularly advantageous for tasks that require multiple levels of abstraction or complex logical reasoning.
Within the llm-chain crate, customization options enable a flexible and modular approach to building these hybrid prompting strategies. The crate offers powerful tools for chaining prompts, adjusting response formats, and customizing token settings, providing developers with a fine-grained control over model interactions. Using these tools, developers can set up prompts that initiate with a zero-shot structure, followed by chained few-shot examples to reinforce accuracy. This level of customization is critical in applications where precision is paramount, such as in medical summaries or legal document analysis, where combining high-level instructions with specific cases enhances both coherence and relevance.
The following Rust code demonstrates how to customize a hybrid prompting chain using llm-chain to perform a two-step summarization task. In this example, an initial zero-shot prompt provides a high-level summary, followed by a few-shot prompt that asks the model to refine the summary based on specific examples of structured summaries. This Rust program uses the llm_chain to create a high-level and refined summary of a report on the Rust programming language through a sequence of zero-shot and few-shot prompts. First, a zero-shot prompt is used to generate an initial concise summary based on a brief description of Rust. This summary is then refined through a few-shot prompt with example sentences, allowing the language model to enhance the output by including key aspects of Rust's capabilities.
use llm_chain::{chains::sequential::Chain, executor, options, parameters, step::Step};
use llm_chain::prompt::{Data, StringTemplate};
use tokio;
fn zero_shot_summary_prompt() -> Step {
let template = StringTemplate::from("Summarize the following report in one concise sentence:\n\nReport: Rust is a language that prioritizes safety, performance, and concurrency.");
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
fn few_shot_refinement_prompt(initial_summary: &str) -> Step {
let prompt_content = format!(
"Refine the summary to include key components:\n\n\
Summary: Rust offers memory safety and performance for systems programming.\n\
Summary: Rust’s concurrency model ensures safe, parallel execution.\n\
Summary: Rust is optimized for both speed and stability.\n\n\
Initial Summary: {} Refined Summary:",
initial_summary
);
let template = StringTemplate::from(prompt_content.as_str());
let prompt = Data::text(template);
Step::for_prompt_template(prompt)
}
#[tokio::main(flavor = "current_thread")]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let options = options! {
ApiKey: "sk-proj-..." // Replace with your actual API key
};
let exec = executor!(chatgpt, options)?;
// Perform zero-shot prompting for the initial summary
let zero_shot_chain = Chain::new(vec![zero_shot_summary_prompt()]);
let zero_shot_summary = zero_shot_chain.run(parameters!(), &exec).await?;
println!("Zero-Shot Summary: {}", zero_shot_summary.to_string());
// Perform few-shot prompting to refine the summary
let refined_prompt_chain = Chain::new(vec![few_shot_refinement_prompt(&zero_shot_summary.to_string())]);
let refined_summary = refined_prompt_chain.run(parameters!(), &exec).await?;
println!("Refined Summary: {}", refined_summary.to_string());
Ok(())
}
The program defines two functions to create the prompts: zero_shot_summary_prompt generates the initial summary request, and few_shot_refinement_prompt provides a structured prompt to improve the initial summary. Each function formats a prompt as StringTemplate text, wraps it in Data::text, and converts it to a Step object to execute as part of a Chain. In the asynchronous main function, an executor is created to handle interactions with the language model via an API key. The initial summary is generated through a zero-shot prompt chain, and the result is used as input for the few-shot refinement prompt, which produces a more detailed summary. The refined output is then printed, showcasing how sequential prompting can guide the model in producing higher-quality responses.
Advanced prompting strategies often involve complex interactions with the model, especially in use cases requiring multi-step reasoning or contextual awareness. For instance, in customer support applications, a hybrid prompting approach might initiate with a zero-shot instruction to identify the user’s issue category, followed by a few-shot prompt to suggest specific solutions based on the identified issue. By organizing prompts in logical sequences, developers can guide the model through nuanced workflows, improving both relevance and user satisfaction. The modular nature of llm-chain makes it straightforward to implement these structured workflows, allowing prompts to be dynamically adjusted based on previous responses, thereby enhancing contextual coherence across interactions.
Ethical considerations are critical in the design and deployment of advanced prompting techniques, particularly as complex prompts can inadvertently introduce biases or unintended behaviors. For instance, a prompting chain with implicit assumptions could bias the model’s output, affecting tasks where fairness and neutrality are essential, such as in hiring recommendations or judicial analysis. To mitigate such risks, developers should carefully evaluate each prompt’s wording, especially when dealing with sensitive topics. Strategies like rephrasing prompts, using unbiased language, and including diverse examples in few-shot contexts can help minimize biases. Additionally, the llm-chain crate can be configured to monitor and adjust prompts dynamically, offering transparency and accountability in high-stakes applications.
Real-world case studies demonstrate the impact of advanced prompting techniques across industries. In e-commerce, for example, a retailer implemented a hybrid prompting system to streamline product recommendations, using zero-shot prompting to identify product categories and few-shot prompts to refine recommendations based on customer preferences. This setup significantly improved customer engagement, as the combined approach allowed the model to adapt recommendations in real time. Another case in legal technology involved a hybrid prompt design for document review, where the model initially classified documents by type using zero-shot prompts, followed by few-shot examples to extract specific clauses. This multi-layered approach reduced document review time by nearly 40%, demonstrating the efficiency gains achievable through prompt customization.
Emerging trends in advanced prompt engineering include dynamic prompt generation and adaptive prompting, where the structure and content of prompts are adjusted based on user input or system feedback. Dynamic prompt generation uses feedback loops to refine prompts iteratively, adapting them to different contexts or user needs in real time. In adaptive prompting, reinforcement learning algorithms are employed to optimize prompt sequences, rewarding the model for outputs that align closely with desired outcomes. Rust’s concurrency and low-level control capabilities make it an ideal language for implementing these adaptive prompting systems, which require efficient handling of model interactions to support real-time updates and feedback-driven adjustments.
In conclusion, combining few-shot and zero-shot prompting with customized chains provides a robust solution for handling complex, nuanced tasks in natural language processing. The llm-chain crate in Rust offers a flexible toolkit for implementing hybrid prompting strategies, enabling developers to tailor prompt structures to specific applications with high precision. As advanced prompting continues to evolve, incorporating ethical considerations and modularity will be essential to deploying robust, adaptable AI systems across industries. With tools like llm-chain, developers can create powerful, customized prompting workflows that leverage the best of both few-shot and zero-shot capabilities, laying the foundation for more responsive, context-aware AI solutions.
21.5. Conclusion
In conclusion, Chapter 21 offers a thorough exploration of few-shot and zero-shot prompting with LLMs using the llm-chain crate. By mastering these techniques, readers can leverage the power of LLMs to perform complex tasks with minimal data, paving the way for more flexible and efficient AI applications. The chapter underscores the transformative potential of advanced prompting methods in Rust-based model development.
21.5.1. Further Learning with GenAI
These prompts are designed to thoroughly explore the concepts and applications of few-shot and zero-shot prompting with LLMs, using the llm-chain Rust crate.
Detail the theoretical distinctions between few-shot and zero-shot prompting in large language models (LLMs). How do these methods utilize pre-trained knowledge to achieve their objectives, and what are the specific mechanisms that differentiate their performance?
Analyze the role of self-supervised learning in the development and effectiveness of few-shot and zero-shot prompting. How does self-supervised learning facilitate the model's ability to generalize from minimal or no task-specific examples?
Provide a comprehensive overview of how the
llm-chaincrate supports few-shot and zero-shot prompting in Rust. Include details on its core functionalities, architecture, and how these features are integrated to perform advanced prompting tasks.Discuss the key considerations and methodologies involved in designing effective prompts for few-shot learning. What are the principles behind prompt construction, and how can prompt design be optimized for various NLP tasks?
Identify and explain the main limitations and challenges associated with implementing few-shot prompting using the
llm-chaincrate. What strategies and best practices can be employed to overcome these challenges and improve model performance?Examine the role of autoregressive models in enhancing zero-shot prompting capabilities. How do autoregressive models generate sequential text from limited or no prior examples, and what are the advantages and limitations of this approach?
Elucidate how prompt engineering affects the performance of zero-shot models. What are the critical factors in crafting prompts that lead to effective zero-shot learning, and how can prompt engineering be tailored to specific applications?
Compare and contrast the performance of few-shot and zero-shot prompting methods across different NLP tasks, such as text classification, summarization, and translation. What variables influence the efficacy of each method, and how do they perform under varying conditions?
Explore the impact of context utilization in few-shot prompting. How does incorporating additional context or information into prompts enhance model performance, and what are some practical examples of context-rich prompting?
Describe the methodologies for benchmarking and evaluating the performance of few-shot and zero-shot models implemented using the
llm-chaincrate. What evaluation metrics and techniques are most effective for assessing model accuracy and utility?Explain the concept of “prompt chaining” and its application in few-shot and zero-shot scenarios. How can prompt chaining be implemented using the
llm-chaincrate, and what are the benefits of this approach in complex prompting tasks?Detail the differences in implementing few-shot versus zero-shot prompting with the
llm-chaincrate. What are the specific implementation strategies and considerations for each method, and how do they affect the overall performance?Investigate the impact of model size and architecture on the effectiveness of few-shot and zero-shot prompting. How do variations in model complexity influence the ability of models to perform with limited or no specific training data?
Discuss how the
llm-chaincrate can be extended or modified to support additional functionalities for few-shot and zero-shot prompting. What are some advanced features or customizations that could enhance its capabilities?Analyze the trade-offs between computational cost and performance when using few-shot and zero-shot prompting techniques. How can developers balance these factors to optimize the efficiency and effectiveness of their models?
Explore the ethical considerations and potential risks associated with deploying few-shot and zero-shot prompting models in real-world applications. What are the implications of these techniques on privacy, fairness, and model reliability?
Evaluate different strategies for fine-tuning models to improve few-shot and zero-shot performance. What are the best practices for fine-tuning in the context of limited data availability?
Discuss the role of transfer learning in enhancing few-shot and zero-shot prompting. How can transfer learning techniques be leveraged to improve the performance of models with minimal task-specific data?
Describe the process of integrating few-shot and zero-shot prompting techniques with other machine learning workflows using the
llm-chaincrate. How can these techniques be combined with other methods for improved results?Investigate recent advancements and future directions in the field of few-shot and zero-shot prompting. What are the emerging trends and technologies that are likely to influence the development and application of these techniques?
Embrace the challenge, explore the cutting-edge features of the llm-chain crate, and push the boundaries of what’s possible with minimal data. Your expertise will contribute to shaping the future of AI, driving advancements that can transform industries and redefine the limits of machine learning.
21.5.2. Hands On Practices
Self-Exercise 21.1: Comparative Analysis of Prompting Methods
Objective: Understand and differentiate the performance of few-shot versus zero-shot prompting in various NLP tasks using GenAI.
Tasks:
Choose two distinct NLP tasks (e.g., text classification and summarization).
Design a set of prompts for both few-shot and zero-shot scenarios for each task.
Implement these prompts using a GenAI tool to generate outputs.
Analyze and compare the performance of few-shot and zero-shot prompting for each task, noting differences in accuracy, coherence, and relevance.
Deliverables:
A detailed report comparing the effectiveness of few-shot and zero-shot prompting for the selected tasks.
Performance metrics and qualitative analysis of generated outputs for each prompting method.
Exercise 21.2: Implementing and Optimizing Prompts
Objective: Develop and optimize effective prompts for few-shot learning using GenAI, and evaluate their impact on model performance.
Tasks:
Create a few-shot learning prompt for a specific NLP task, including multiple examples.
Experiment with variations of the prompt to test different prompt designs and configurations.
Implement these variations using GenAI to generate outputs.
Evaluate and compare the performance of the prompts, focusing on factors such as accuracy, fluency, and task relevance.
Deliverables:
A collection of different prompt variations and their corresponding implementations.
Performance evaluation results for each prompt variation, including a summary of which design was most effective and why.
Exercise 21.3: Addressing Challenges in Few-Shot Prompting
Objective: Identify and address challenges in few-shot prompting with GenAI, and develop strategies for overcoming these issues.
Tasks:
Research common challenges associated with few-shot prompting, such as insufficient context or example quality.
Design a few-shot prompting scenario affected by these challenges.
Propose and implement solutions to mitigate these issues using GenAI.
Test the effectiveness of these solutions and document the improvements in prompt performance.
Deliverables:
An analysis of the challenges encountered and the solutions implemented.
Before-and-after performance metrics demonstrating the impact of the proposed solutions.
Exercise 21.4: Autoregressive Model Evaluation
Objective: Examine the role of autoregressive models in zero-shot prompting and assess their performance in generating coherent text.
Tasks:
Select an autoregressive model configuration for zero-shot prompting.
Design zero-shot prompts and use the selected model to generate outputs.
Evaluate the generated text for coherence, relevance, and quality.
Compare the results with outputs from non-autoregressive models if possible, and analyze the differences.
Deliverables:
A detailed evaluation of the autoregressive model’s performance in zero-shot prompting.
Comparative analysis of autoregressive versus non-autoregressive model outputs.
Exercise 21.5: Benchmarking Few-Shot and Zero-Shot Models
Objective: Benchmark the performance of few-shot and zero-shot models across various NLP tasks and understand the trade-offs between these methods.
Tasks:
Implement both few-shot and zero-shot models for multiple NLP tasks using GenAI.
Define appropriate benchmarking criteria and performance metrics (e.g., accuracy, precision, recall).
Conduct a series of tests to gather performance data for each model and task.
Analyze and document the trade-offs in performance, computational cost, and output quality for each method.
Deliverables:
Benchmarking data and performance metrics for few-shot and zero-shot models across the chosen tasks.
A comprehensive analysis report detailing the trade-offs and performance differences between the two methods.
Comments