Chapter 20
Introduction to Prompt Engineering
"The quality of the prompts we create directly influences the intelligence and effectiveness of the models we build. It’s not just about the data or the algorithms; it’s about asking the right questions." — Andrew Ng
Chapter 20 of LMVR provides a comprehensive introduction to prompt engineering, emphasizing the crucial role that well-crafted prompts play in guiding the behavior of large language models (LLMs). The chapter covers the fundamentals of prompt design, the development of prompt engineering tools using Rust, and the application of advanced techniques to enhance model performance across various tasks. It also delves into the ethical and practical considerations of prompt engineering, ensuring that the deployed models are fair, transparent, and effective. Through practical examples and case studies, readers gain the skills necessary to create, refine, and deploy prompts that maximize the potential of LLMs in real-world applications.
20.1. Fundamentals of Prompt Engineering
Prompt engineering is a foundational skill for guiding large language models (LLMs) towards producing specific, accurate, and contextually relevant responses. As LLMs become more powerful and integrated into diverse applications, the ability to shape their output through carefully crafted prompts is becoming essential for developers and researchers alike. Prompt engineering involves designing inputs—prompts—that direct the model’s response patterns, tone, and content, effectively acting as a bridge between the model’s underlying capabilities and the desired output. This section explores prompt engineering fundamentals, from the principles of prompt design to practical techniques for enhancing model behavior using Rust.
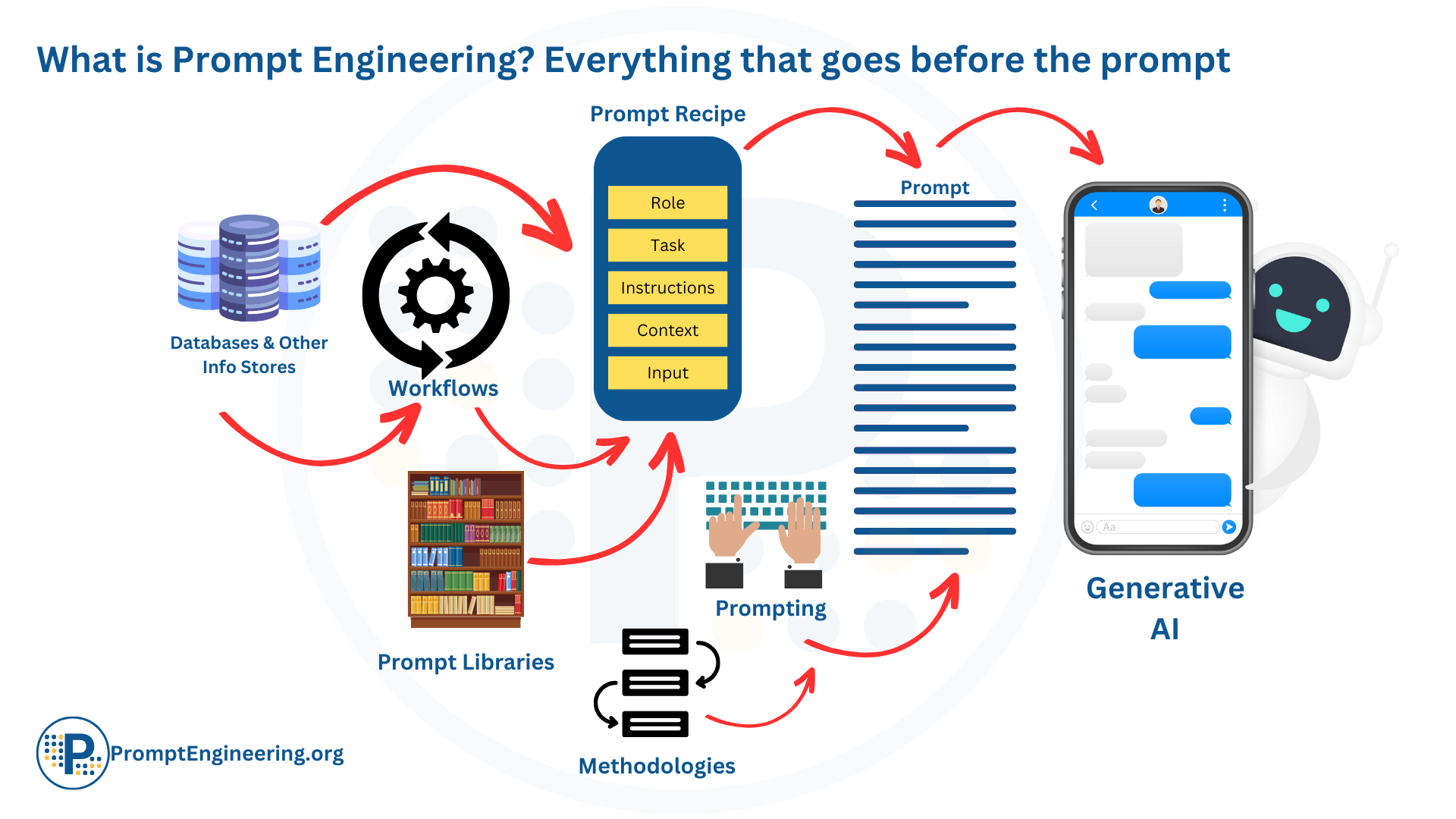
Figure 1: Prompt Engineering and GenAI/LLM Apps.
At its core, prompt engineering centers on understanding the relationship between the input prompt and the model’s generated output. The structure, wording, and length of prompts all influence the way LLMs interpret and respond to user queries. For example, instructional prompts provide explicit instructions to guide the model, while conversational prompts are designed to facilitate a natural, back-and-forth interaction. Mathematically, prompt engineering can be framed as a function $f: P \rightarrow R$, where $P$ represents the prompt space and $R$ denotes the response space. By controlling the structure and content of $P$, developers can influence the likelihood of certain desirable outputs in RRR, such as relevance, coherence, and tone consistency. Understanding this relationship is key to developing effective prompts, as it allows for fine-grained control over model responses in applications like chatbots, virtual assistants, and automated summarization tools.
The impact of prompt design on model responses is profound, particularly when prompts are tailored to specific tasks. For instance, a task-specific prompt for a sentiment analysis task might contain words that clearly specify the emotional tone being sought, while an instructional prompt for code generation might contain language that delineates coding conventions or error-handling expectations. Prompt length and wording specificity also play crucial roles in output accuracy, relevance, and coherence. A prompt that is too vague may produce ambiguous or irrelevant results, whereas overly complex prompts might lead to errors or unintended interpretations. These nuances underscore the importance of prompt structure in shaping LLM behavior, emphasizing clarity, relevance, and simplicity to maximize model effectiveness.
Crafting effective prompts requires awareness of common challenges, such as the potential for prompts to introduce bias. An example might involve using culturally loaded language or biased assumptions that can skew the LLM’s output, inadvertently reinforcing stereotypes or producing exclusionary responses. To address these risks, developers must employ prompt engineering techniques that are sensitive to context and inclusive in language. For instance, when developing a prompt for a recommendation system, ensuring that language is inclusive and diverse can help broaden the model’s response range, leading to fairer and more accurate recommendations. Bias mitigation techniques, such as testing prompts against diverse inputs, provide additional safeguards, helping developers fine-tune prompts to be both accurate and ethically responsible.
Implementing prompt engineering in Rust offers several advantages, including memory safety, performance, and robust error handling. By building prompt engineering tools in Rust, developers can create efficient workflows for constructing, testing, and refining prompts at scale. The following Rust code demonstrates a simple prompt engineering pipeline, where different prompts are formatted, tokenized, and evaluated for effectiveness in generating desired model outputs.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
tokenizers = "0.20.3"
reqwest = { version = "0.12", features = ["blocking"] }
use tokenizers::{Tokenizer, Encoding};
use std::fs;
use std::path::Path;
use reqwest::blocking::get;
use std::io::Write;
// Define prompt structures for different tasks
enum PromptType {
Instructional(String),
Conversational(String),
TaskSpecific(String),
}
// Function to create prompt formats based on PromptType
fn create_prompt(prompt_type: PromptType) -> String {
match prompt_type {
PromptType::Instructional(text) => format!("Please follow the instructions carefully: {}", text),
PromptType::Conversational(text) => format!("Let's have a conversation: {}", text),
PromptType::TaskSpecific(text) => format!("Task for the model: {}", text),
}
}
// Function to tokenize and encode the prompt
fn tokenize_prompt(prompt: &str, tokenizer: &Tokenizer) -> Encoding {
tokenizer.encode(prompt, true).expect("Tokenization failed")
}
// Download tokenizer file if it doesn't exist
fn ensure_tokenizer_file_exists() -> &'static str {
let file_path = "bert-base-uncased.json";
if !Path::new(file_path).exists() {
println!("Downloading tokenizer file...");
let url = "https://huggingface.co/bert-base-uncased/resolve/main/tokenizer.json";
let response = get(url).expect("Failed to download tokenizer file");
let mut file = fs::File::create(file_path).expect("Failed to create tokenizer file");
file.write_all(&response.bytes().expect("Failed to read response bytes"))
.expect("Failed to write tokenizer file");
println!("Tokenizer file downloaded successfully.");
}
file_path
}
fn main() {
// Ensure tokenizer file exists
let tokenizer_file = ensure_tokenizer_file_exists();
// Initialize tokenizer from the file
let tokenizer = Tokenizer::from_file(tokenizer_file).expect("Failed to load tokenizer");
// Define prompts for testing
let prompt_inst = PromptType::Instructional("Generate a summary of the following document.".to_string());
let prompt_conv = PromptType::Conversational("What is the weather like today?".to_string());
let prompt_task = PromptType::TaskSpecific("Classify this message as spam or not.".to_string());
// Generate and tokenize prompts
let prompt_inst_text = create_prompt(prompt_inst);
let prompt_conv_text = create_prompt(prompt_conv);
let prompt_task_text = create_prompt(prompt_task);
let encoded_inst = tokenize_prompt(&prompt_inst_text, &tokenizer);
let encoded_conv = tokenize_prompt(&prompt_conv_text, &tokenizer);
let encoded_task = tokenize_prompt(&prompt_task_text, &tokenizer);
println!("Instructional prompt tokens: {:?}", encoded_inst.get_ids());
println!("Conversational prompt tokens: {:?}", encoded_conv.get_ids());
println!("Task-specific prompt tokens: {:?}", encoded_task.get_ids());
}
In this example, different prompt types are defined, each catering to a specific purpose. The create_prompt function applies unique formatting to each prompt type, while the tokenize_prompt function tokenizes the prompt into a format suitable for the LLM. Rust’s performance and error-handling capabilities ensure the prompt engineering process is efficient and robust, even when applied to large datasets. I
Case studies highlight the efficacy of prompt engineering in various applications. In customer support, for example, companies have improved response accuracy and user engagement by designing prompts that contextualize responses, using phrases like “Based on our records” or “To assist you further.” This contextual framing helps narrow down model responses, increasing relevance and customer satisfaction. In educational technology, prompt engineering has been used to guide models in explaining complex topics at a suitable level for students, with prompts crafted to consider factors like the student’s age, grade level, and learning objectives. By shaping the model’s response based on prompt input, educational applications can deliver more personalized and accessible explanations, enhancing the overall learning experience.
The field of prompt engineering is evolving rapidly, with trends focusing on greater prompt specificity and the integration of prompt engineering into end-to-end workflows. Advanced techniques such as prompt chaining—where multiple prompts are sequenced to refine or elaborate on a response—allow for greater depth and nuance in model outputs. For example, in a legal context, an initial prompt may request a summary of a case, while subsequent prompts clarify specific legal terms or precedents. Rust’s memory safety and concurrency control allow developers to implement these techniques in resource-efficient pipelines, enabling prompt sequences to be processed rapidly, even in high-demand applications.
Another emerging area is the automated generation and evaluation of prompts. With advancements in prompt analysis, developers can analyze the effects of different prompt variations to find optimal structures automatically. This process, often referred to as prompt tuning, involves adjusting the prompt format based on performance metrics such as response accuracy or relevance. In Rust, developers can build prompt evaluation systems that analyze the relationship between prompt variations and model outputs, refining prompts through iterative improvements. Automated prompt generation and tuning allow for more consistent and reliable LLM performance across applications, minimizing manual prompt design and expanding the scalability of prompt engineering.
In conclusion, prompt engineering plays a central role in refining the behavior of large language models, guiding their responses to meet specific needs in diverse domains. Rust’s efficient handling of data structures and concurrency provides a solid foundation for implementing prompt engineering techniques, allowing developers to create scalable, high-performance pipelines that improve model relevance, accuracy, and interpretability. This section has illustrated the core principles and practical strategies of prompt engineering, showcasing how the thoughtful design of prompts can significantly enhance the effectiveness of LLMs in real-world applications. As prompt engineering continues to advance, developers will have more tools at their disposal to craft sophisticated, nuanced interactions between users and language models, shaping the future of AI-driven communication and decision-making.
20.2. Building Prompt Engineering Tools with Rust
Building an effective prompt engineering toolkit requires a modular approach that balances performance, concurrency, and adaptability. Rust’s ecosystem is particularly well-suited to the demands of prompt engineering, as it provides robust tools for managing text, controlling memory, and leveraging concurrency for efficient data handling. In prompt engineering, the toolkit components often include prompt templates for structuring inputs, testing frameworks to validate prompt effectiveness, and output analyzers to measure the accuracy, relevance, and quality of model responses. Together, these components streamline the process of designing, testing, and iterating on prompts to guide Large Language Models (LLMs) in producing reliable, contextually relevant outputs.
In constructing a prompt engineering toolkit, developers can utilize several key Rust crates that support text manipulation, tokenization, and model interaction. Crates such as tokenizers facilitate tokenization processes, essential for structuring input prompts in ways that align with LLM token expectations. The regex crate, known for high-performance pattern matching, can be used to identify and replace patterns in text, useful for adjusting prompt templates based on dynamic inputs or to sanitize responses. Moreover, Rust’s memory safety and efficient error handling allow for prompt engineering tools that operate reliably at scale, minimizing runtime errors and ensuring consistent prompt testing. For instance, by structuring the toolkit to handle prompt templates as modular components, developers can design reusable prompts that adapt to different contexts, reducing time and resources spent on prompt crafting.
Rust’s performance and concurrency features also enable parallel processing within prompt testing and output analysis. Prompt engineering often requires testing multiple prompt variations across large datasets to identify the most effective structures. Through multi-threaded execution, developers can test variations in parallel, gathering metrics on accuracy, response time, and relevance for each prompt. This can be formalized as a function $f(P) \rightarrow M$, where $P$ represents a set of prompts, and $M$ denotes a matrix of metrics for each prompt. By evaluating this mapping, developers can identify optimal prompts more efficiently, allowing them to scale prompt testing without sacrificing model response quality. Rust’s lightweight threading model provides a strong foundation for implementing this parallel evaluation, as it allows for low-latency processing that minimizes bottlenecks, making it feasible to test large prompt sets rapidly.
The following Rust code provides a simple example of how a prompt engineering toolkit can be implemented. Here, we build a modular toolkit with a prompt creator, a tester, and an output analyzer. These components are defined as separate functions and combined to create a reusable prompt engineering pipeline. The code highlights Rust’s ability to manage text inputs, tokenize prompts, and analyze outputs efficiently, forming the basis of a flexible and high-performance prompt engineering system.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
tokenizers = "0.20.3"
reqwest = { version = "0.12", features = ["blocking"] }
rayon = "1.10.0"
regex = "1.11.1"
use tokenizers::{Tokenizer, Encoding};
use std::collections::HashMap;
use rayon::prelude::*;
use std::fs;
use std::path::Path;
use reqwest::blocking::get;
use std::io::Write;
// Define a PromptTemplate struct for creating and formatting prompts
struct PromptTemplate {
template: String,
}
impl PromptTemplate {
fn new(template: &str) -> Self {
PromptTemplate { template: template.to_string() }
}
fn apply(&self, context: &HashMap<&str, &str>) -> String {
let mut result = self.template.clone();
for (key, value) in context {
let placeholder = format!("{{{{ {} }}}}", key);
result = result.replace(&placeholder, value);
}
result
}
}
// Function to tokenize prompts using a tokenizer
fn tokenize_prompt(prompt: &str, tokenizer: &Tokenizer) -> Encoding {
tokenizer.encode(prompt, true).expect("Tokenization failed")
}
// Function to download and save the tokenizer file if it doesn't exist
fn ensure_tokenizer_file_exists() -> &'static str {
let file_path = "bert-base-uncased.json";
if !Path::new(file_path).exists() {
println!("Downloading tokenizer file...");
let url = "https://huggingface.co/bert-base-uncased/resolve/main/tokenizer.json";
let response = get(url).expect("Failed to download tokenizer file");
let mut file = fs::File::create(file_path).expect("Failed to create tokenizer file");
file.write_all(&response.bytes().expect("Failed to read response bytes"))
.expect("Failed to write tokenizer file");
println!("Tokenizer file downloaded successfully.");
}
file_path
}
// Function for testing prompt effectiveness by analyzing model responses
fn test_prompts(prompts: Vec<PromptTemplate>, tokenizer: &Tokenizer) -> Vec<HashMap<&str, usize>> {
prompts.par_iter().map(|prompt| {
let sample_context = HashMap::from([("task", "Summarize the document"), ("language", "English")]);
let formatted_prompt = prompt.apply(&sample_context);
let encoded = tokenize_prompt(&formatted_prompt, tokenizer);
// Mock response analysis for demonstration
HashMap::from([
("token_count", encoded.len()),
("unique_tokens", encoded.get_ids().iter().collect::<std::collections::HashSet<_>>().len())
])
}).collect()
}
fn main() {
// Ensure the tokenizer file exists and initialize the tokenizer
let tokenizer_file = ensure_tokenizer_file_exists();
let tokenizer = Tokenizer::from_file(tokenizer_file).expect("Failed to load tokenizer");
// Define prompt templates for testing
let prompt_templates = vec![
PromptTemplate::new("Please complete the task: {{ task }} in {{ language }}."),
PromptTemplate::new("Perform the task in the {{ language }} language: {{ task }}."),
];
// Test prompt effectiveness and analyze results
let analysis_results = test_prompts(prompt_templates, &tokenizer);
println!("Prompt analysis results: {:?}", analysis_results);
}
In this example, PromptTemplate allows for flexible prompt creation by applying a context dictionary to substitute placeholders with specific values, enabling easy reuse and adaptation of prompts across different scenarios. The test_prompts function takes a list of prompts, applies context values, tokenizes them, and performs a simple analysis to return token counts and unique token IDs as metrics. Rust’s concurrency features, through rayon, facilitate parallel processing of prompts, allowing multiple prompt templates to be tested and analyzed simultaneously. This setup provides a foundational pipeline for prompt engineering that developers can expand by adding more advanced analysis functions and metrics.
In integrating prompt engineering tools into existing Rust-based LLM applications, modularity and reusability are paramount. A well-designed toolkit should provide APIs that interact seamlessly with various LLM tasks, such as summarization, question answering, or recommendation generation. The modular design allows different components, like prompt formatters and tokenizers, to be swapped in and out as requirements change. For example, in a chatbot application, a conversational prompt module can be introduced, while in a summarization tool, instructional prompts might take precedence. Rust’s type safety and error handling make it possible to create these modular components without introducing runtime inconsistencies, ensuring that prompt templates and testing frameworks function predictably across different application contexts.
Best practices for maintaining prompt engineering tools involve ensuring that these tools remain adaptable and capable of evolving with the model’s requirements. As LLMs become more sophisticated, prompt engineering demands may change, requiring more advanced prompt structures or specific analyses for prompt effectiveness. A prompt toolkit designed in Rust can include versioning systems for prompt templates, allowing developers to track prompt iterations over time and experiment with new formats without disrupting established workflows. Additionally, a continuous integration setup for prompt testing, where prompts are regularly evaluated and optimized based on model performance, can help maintain prompt quality as LLM behavior shifts.
The effectiveness of a prompt engineering toolkit can be evaluated through real-world case studies that illustrate how it improves LLM performance across diverse tasks. For example, in e-commerce, prompt engineering has been used to refine product recommendation prompts, enhancing relevance and personalization. Testing different prompt variations—such as framing questions about preferences or providing context-specific recommendations—enables companies to identify which prompts yield the most engaging recommendations. In language learning applications, prompt engineering tools have been used to guide LLMs to generate explanations or examples tailored to learners’ proficiency levels. Prompt testing frameworks that analyze response complexity or vocabulary levels ensure that prompts align with user needs, increasing engagement and learning effectiveness. By providing tools that automate prompt testing and analysis, Rust-based toolkits can make prompt engineering more efficient and reliable, supporting LLM optimization across these varied domains.
In the future, the role of prompt engineering toolkits is likely to expand to include AI-driven prompt suggestion and optimization. Through reinforcement learning, toolkits could automatically suggest or refine prompts based on feedback from model outputs, creating a dynamic feedback loop that continually improves prompt efficacy. Additionally, as model interpretability becomes more critical, prompt engineering toolkits might include explainability functions that help developers understand how specific prompts influence model behavior. By harnessing Rust’s concurrency and performance capabilities, these advanced features can be implemented at scale, enabling prompt engineering workflows that remain both adaptable and high-performance.
In summary, building a prompt engineering toolkit in Rust offers a structured, efficient approach to managing the complexity of prompt design, testing, and analysis. With support for text manipulation, tokenization, and concurrency, Rust-based toolkits enable developers to create modular, reusable prompt workflows that improve model accuracy and relevance. Through case studies and practical examples, this section illustrates how a Rust prompt engineering toolkit can enhance LLM performance across diverse applications, providing a robust foundation for developers aiming to optimize AI-driven communication and decision-making. As prompt engineering continues to evolve, these tools will play an essential role in helping developers navigate the intricacies of LLM behavior, enabling more precise, context-aware model outputs.
20.3. Designing Effective Prompts for Different Applications
Designing effective prompts for various applications is a foundational aspect of prompt engineering, especially when aiming to optimize the accuracy and relevance of large language model (LLM) outputs across distinct tasks. Each LLM application—whether content generation, question answering, or summarization—requires carefully crafted prompts tailored to the nature of the task and the desired outcome. This section explores the principles of designing effective prompts, focusing on how domain knowledge, context specificity, and prompt length impact model performance, particularly in task-specific scenarios. By understanding these elements, developers can create prompts that leverage the full potential of LLMs, guiding models to generate outputs that are relevant, accurate, and contextually appropriate.
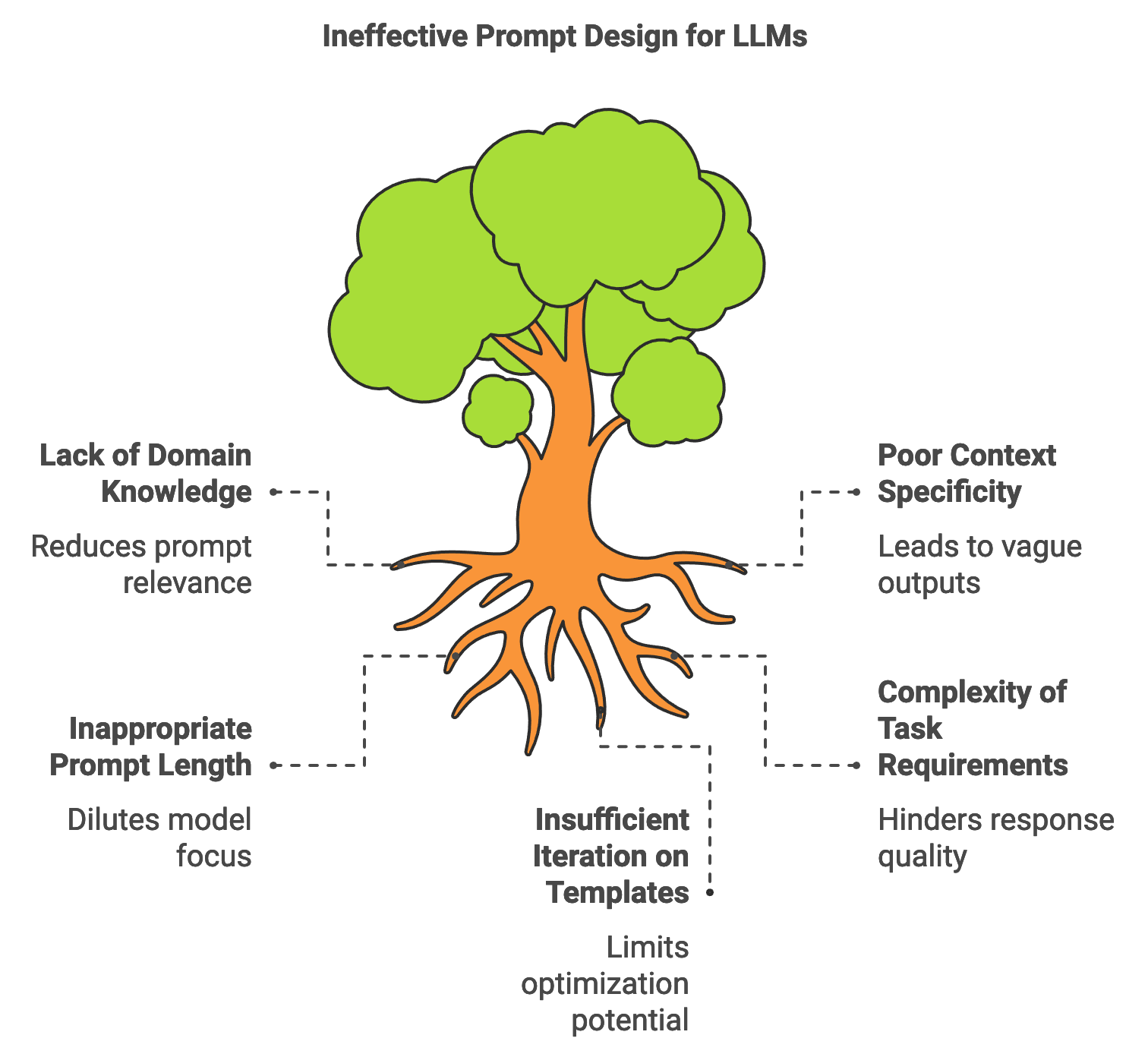
Figure 2: Challenges on prompt design.
The effectiveness of a prompt largely depends on how well it aligns with the specific requirements of the task. Mathematically, prompt design can be represented as an optimization problem where the objective is to maximize the model's response quality given a prompt $p$ and task requirements $T$. Formally, we define $f(p; T) \rightarrow R$, where $f$ is the function representing the model’s response generation, and $R$ is the response quality metric, such as relevance or coherence. For example, in content generation tasks, prompt structure may focus on setting a specific style or tone, whereas in question answering, prompts often need to clearly outline the context and scope of the inquiry. By framing prompt design as an optimization process, developers can iterate on prompt templates to maximize RRR, identifying formats that consistently yield high-quality responses.
Domain knowledge is essential in crafting prompts that are both effective and contextually accurate. For instance, prompts designed for legal document summarization may require technical legal terms and an understanding of the document structure, whereas medical information extraction may demand prompts that account for clinical terminology and sensitivity to patient privacy. In these cases, including domain-specific keywords and structures within the prompt provides the model with clearer guidance, enhancing the relevance and accuracy of the output. Domain knowledge also informs decisions about prompt length, as overly lengthy prompts can dilute the model’s focus, while overly brief prompts may lack sufficient context. Effective prompts balance detail and conciseness, helping LLMs maintain relevance without sacrificing response quality.
Challenges arise when designing prompts for complex tasks, such as creative content generation or multi-step reasoning. Creative content generation, for example, often requires prompts that maintain a balance between giving enough structure to guide the model and allowing flexibility for creative expression. Here, prompt length and specificity play a critical role. Longer, more detailed prompts may help establish the desired style or context but can sometimes lead to overly deterministic outputs, limiting the model's creativity. Conversely, too little structure can result in vague or incoherent outputs. In tasks requiring multi-step reasoning, prompts may need to be sequenced or chained, where each subsequent prompt builds on previous model responses. Rust’s performance capabilities enable developers to experiment with prompt chains and multi-step processes, allowing LLMs to perform complex tasks that involve stepwise reasoning or layered instructions.
A practical Rust-based implementation can showcase how different prompt designs impact LLM performance across applications. The following code snippet demonstrates a simple structure for designing and testing prompts for three distinct applications: content generation, question answering, and summarization. By varying the structure and content of the prompts, we can observe how these changes affect model responses, gaining insights into the most effective prompt designs for each task.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
tokenizers = "0.20.3"
reqwest = { version = "0.12", features = ["blocking"] }
rayon = "1.10.0"
regex = "1.11.1"
use tokenizers::Tokenizer;
use std::collections::HashMap;
use std::fs;
use std::path::Path;
use reqwest::blocking::get;
use std::io::Write;
// Define different types of prompts based on the application
enum PromptApplication {
ContentGeneration(String),
QuestionAnswering(String),
Summarization(String),
}
// Function to create task-specific prompts
fn create_prompt(application: PromptApplication) -> String {
match application {
PromptApplication::ContentGeneration(topic) => format!("Write a creative story about: {}", topic),
PromptApplication::QuestionAnswering(question) => format!("Answer the following question precisely: {}", question),
PromptApplication::Summarization(document) => format!("Summarize the following document concisely: {}", document),
}
}
// Function to ensure the tokenizer file exists (download if necessary)
fn ensure_tokenizer_file_exists() -> &'static str {
let file_path = "bert-base-uncased.json";
if !Path::new(file_path).exists() {
println!("Downloading tokenizer file...");
let url = "https://huggingface.co/bert-base-uncased/resolve/main/tokenizer.json";
let response = get(url).expect("Failed to download tokenizer file");
let mut file = fs::File::create(file_path).expect("Failed to create tokenizer file");
file.write_all(&response.bytes().expect("Failed to read response bytes"))
.expect("Failed to write tokenizer file");
println!("Tokenizer file downloaded successfully.");
}
file_path
}
// Function to simulate LLM response evaluation based on prompt type
fn evaluate_prompt<'a>(prompt: &'a str, tokenizer: &'a Tokenizer) -> HashMap<&'a str, usize> {
let encoding = tokenizer.encode(prompt, true).expect("Tokenization failed");
let token_count = encoding.len();
// Mock evaluation - In a real scenario, this would analyze the response quality.
HashMap::from([
("token_count", token_count),
("relevance_score", 90), // Placeholder value for relevance
("clarity_score", 85) // Placeholder value for clarity
])
}
fn main() {
// Initialize different prompt applications
let content_prompt = create_prompt(PromptApplication::ContentGeneration("a futuristic world".to_string()));
let question_prompt = create_prompt(PromptApplication::QuestionAnswering("What is the capital of France?".to_string()));
let summary_prompt = create_prompt(PromptApplication::Summarization("The document discusses...".to_string()));
// Ensure the tokenizer file exists and initialize the tokenizer
let tokenizer_file = ensure_tokenizer_file_exists();
let tokenizer = Tokenizer::from_file(tokenizer_file).expect("Failed to load tokenizer");
// Evaluate prompt effectiveness across applications
let content_eval = evaluate_prompt(&content_prompt, &tokenizer);
let question_eval = evaluate_prompt(&question_prompt, &tokenizer);
let summary_eval = evaluate_prompt(&summary_prompt, &tokenizer);
println!("Content Generation prompt evaluation: {:?}", content_eval);
println!("Question Answering prompt evaluation: {:?}", question_eval);
println!("Summarization prompt evaluation: {:?}", summary_eval);
}
In this example, the create_prompt function formats prompts based on application-specific requirements, such as providing a detailed topic for content generation, posing a question for question answering, or summarizing a document. The evaluate_prompt function, while simplified here, could be extended in real scenarios to analyze actual model outputs for quality metrics like relevance and clarity. Rust’s performance and memory safety enable rapid evaluation of different prompt designs, allowing developers to optimize for application-specific effectiveness and scalability.
Real-world use cases illustrate the benefits of applying task-specific prompt designs. In customer service applications, task-specific prompts can enable LLMs to generate responses that are informative and empathetic, particularly when dealing with customer complaints or technical inquiries. By structuring prompts to include phrases like “I understand that…” or “Could you provide more information on…,” developers create prompts that model empathetic language, which in turn fosters positive customer interactions. Another example can be seen in legal document processing, where prompts designed for summarization help extract key legal information from dense documents. Here, prompts that specify document sections or legal terms yield more targeted summaries, enabling lawyers and researchers to access relevant insights faster.
Current trends in prompt design emphasize the use of adaptive prompts that dynamically adjust based on real-time feedback. For instance, prompts may be structured to allow the model to generate intermediate responses, which can then be refined through subsequent prompts. This approach, known as iterative refinement, is particularly valuable for applications that involve detailed instructions or require clarification, such as generating technical documentation or translating nuanced legal language. With Rust, developers can implement prompt feedback loops that process each iteration efficiently, allowing LLMs to converge on more accurate or user-tailored responses over time.
In summary, designing effective prompts for different LLM applications requires a nuanced understanding of the task, domain, and target response characteristics. Rust’s robust text handling and performance-oriented features make it an ideal choice for implementing prompt engineering pipelines that evaluate and optimize prompts for task-specific applications. This section demonstrates how principles of prompt structure, domain-specific knowledge, and iterative experimentation contribute to optimizing LLM performance across content generation, question answering, summarization, and beyond. As prompt engineering evolves, these techniques will play a crucial role in aligning LLM capabilities with real-world application requirements, unlocking new potential for AI-driven insights and automation across industries.
20.4. Evaluating and Refining Prompts
Evaluating and refining prompts is a critical part of prompt engineering, enabling developers to optimize prompts for improved model accuracy, relevance, and adaptability across various tasks. Effective prompt evaluation involves both quantitative metrics, such as response relevance and accuracy, and qualitative assessments, like coherence and ethical alignment. In Rust, prompt evaluation frameworks can be constructed to support automated analysis, iterative refinements, and even human-in-the-loop feedback systems, all of which are essential for ensuring that prompt designs remain both effective and aligned with application requirements.
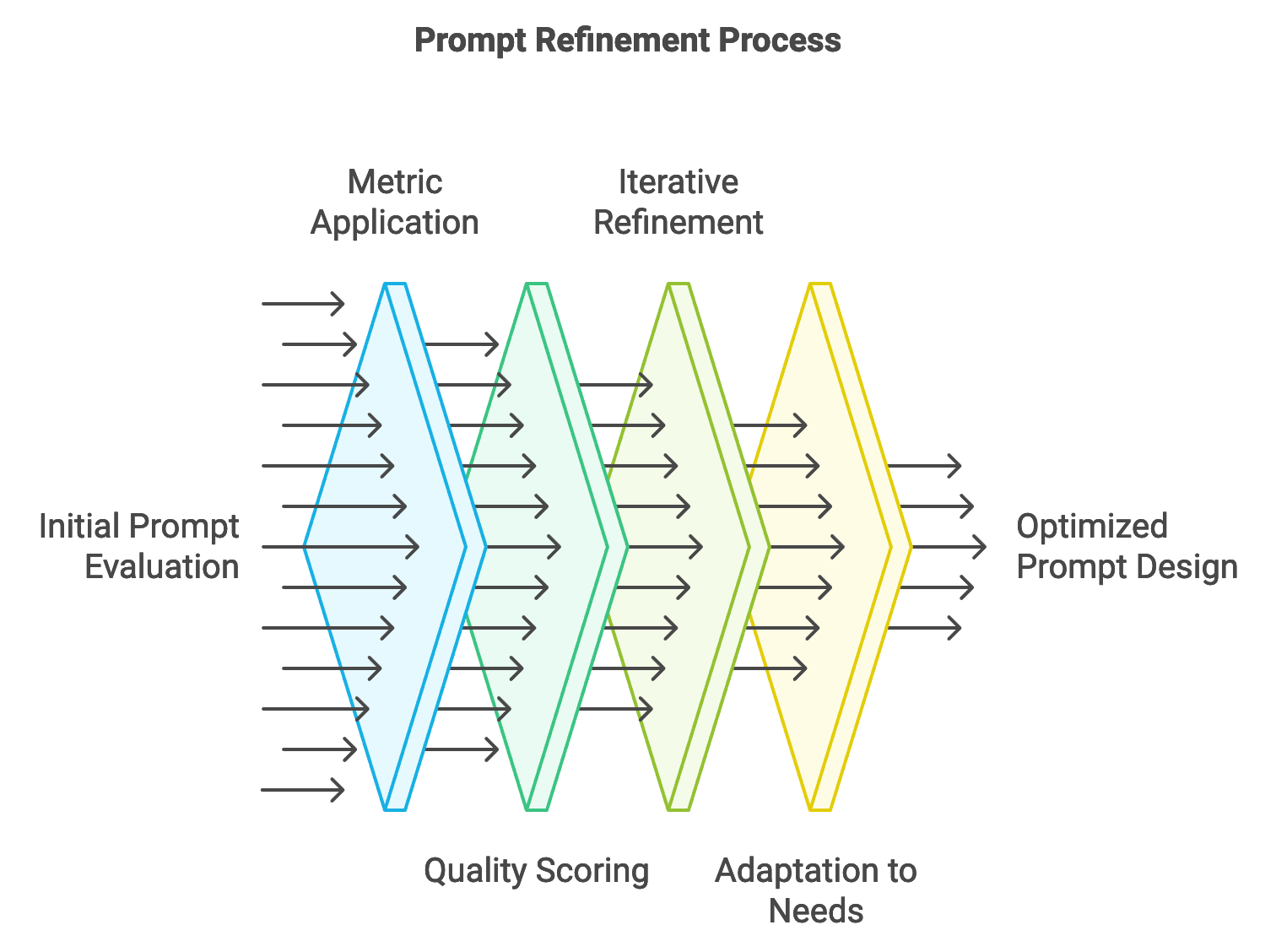
Figure 3: Process to optimize prompt design.
The process of prompt evaluation can be conceptualized as an optimization function $E: P \rightarrow Q$, where $E$ represents an evaluation metric applied to a prompt $P$, yielding a quality score $Q$. This score can be a composite metric, capturing multiple aspects of output quality, such as accuracy and clarity. In practice, evaluating a prompt often involves gathering multiple QQQ scores, representing different facets of the response. For example, developers may use token-level metrics (e.g., token overlap or perplexity) to quantify syntactic and semantic alignment with desired outputs. Other metrics, like response diversity or user engagement, offer insight into more abstract qualities of model behavior. Balancing these diverse metrics allows for a comprehensive evaluation of prompt effectiveness, helping developers identify areas for refinement.
Continuous refinement is integral to adapting prompts as LLM capabilities and application needs evolve. Prompt refinement involves an iterative process, where initial prompts are adjusted based on evaluation feedback to improve output quality. This approach is especially valuable in high-stakes applications, such as legal text analysis or financial forecasting, where even slight improvements in prompt structure can lead to significant gains in accuracy. By analyzing the performance of different prompt variants, developers can identify patterns, refining prompts to balance complexity and performance. In Rust, this iterative process is supported by robust data handling capabilities, allowing developers to create tools that test and compare prompt versions efficiently, even across large datasets.
To illustrate, consider the following Rust-based code, which outlines a basic framework for evaluating and refining prompts. This example demonstrates how to implement a testing pipeline that supports both automated scoring and human feedback collection, enabling developers to iterate on prompt designs effectively.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
tokenizers = "0.20.3"
reqwest = { version = "0.12", features = ["blocking"] }
rayon = "1.10.0"
regex = "1.11.1"
use tokenizers::{Tokenizer, Encoding};
use std::fs;
use std::path::Path;
use reqwest::blocking::get;
use std::io::Write;
// Define metrics for evaluating prompt responses
#[derive(Debug)]
struct EvaluationMetrics {
relevance: f32,
clarity: f32,
diversity: f32,
}
// Function to ensure the tokenizer file exists (download if necessary)
fn ensure_tokenizer_file_exists() -> &'static str {
let file_path = "bert-base-uncased.json";
if !Path::new(file_path).exists() {
println!("Downloading tokenizer file...");
let url = "https://huggingface.co/bert-base-uncased/resolve/main/tokenizer.json";
let response = get(url).expect("Failed to download tokenizer file");
let mut file = fs::File::create(file_path).expect("Failed to create tokenizer file");
file.write_all(&response.bytes().expect("Failed to read response bytes"))
.expect("Failed to write tokenizer file");
println!("Tokenizer file downloaded successfully.");
}
file_path
}
// Function to calculate evaluation metrics based on tokenized response
fn evaluate_prompt_response(response: &str, expected: &str, tokenizer: &Tokenizer) -> EvaluationMetrics {
let response_tokens = tokenizer.encode(response, true).expect("Tokenization failed");
let expected_tokens = tokenizer.encode(expected, true).expect("Tokenization failed");
let relevance = calculate_relevance(&response_tokens, &expected_tokens);
let clarity = calculate_clarity(&response);
let diversity = calculate_diversity(&response_tokens);
EvaluationMetrics {
relevance,
clarity,
diversity,
}
}
// Mock functions for calculating relevance, clarity, and diversity
fn calculate_relevance(response_tokens: &Encoding, expected_tokens: &Encoding) -> f32 {
let overlap = response_tokens.get_ids().iter().filter(|&id| expected_tokens.get_ids().contains(id)).count();
overlap as f32 / response_tokens.len() as f32 * 100.0
}
fn calculate_clarity(response: &str) -> f32 {
if response.is_empty() {
0.0
} else {
85.0 // Placeholder for clarity score based on syntactic analysis
}
}
fn calculate_diversity(response_tokens: &Encoding) -> f32 {
let unique_tokens = response_tokens.get_ids().iter().collect::<std::collections::HashSet<_>>().len();
unique_tokens as f32 / response_tokens.len() as f32 * 100.0
}
// Example prompt refinement function
fn refine_prompt(prompt: &str, evaluation: &EvaluationMetrics) -> String {
if evaluation.relevance < 70.0 {
format!("{} {}", prompt, "Ensure accuracy in your response.")
} else if evaluation.clarity < 70.0 {
format!("{} {}", prompt, "Provide a clear and concise answer.")
} else if evaluation.diversity < 70.0 {
format!("{} {}", prompt, "Try to include more varied information.")
} else {
prompt.to_string()
}
}
fn main() {
// Define a sample prompt and expected response
let prompt = "Summarize the following document accurately and concisely.";
let response = "The document discusses...";
let expected_response = "The document provides an overview of...";
// Ensure the tokenizer file exists and initialize the tokenizer
let tokenizer_file = ensure_tokenizer_file_exists();
let tokenizer = Tokenizer::from_file(tokenizer_file).expect("Failed to load tokenizer");
// Evaluate prompt response
let metrics = evaluate_prompt_response(response, expected_response, &tokenizer);
println!("Initial Evaluation Metrics: {:?}", metrics);
// Refine prompt based on evaluation feedback
let refined_prompt = refine_prompt(prompt, &metrics);
println!("Refined Prompt: {}", refined_prompt);
}
In this example, the evaluate_prompt_response function generates quantitative scores for relevance, clarity, and diversity by comparing the model’s response to an expected output. The evaluation framework employs token overlap for relevance, syntactic analysis for clarity, and token diversity to gauge response variation. The refine_prompt function iterates on the initial prompt based on evaluation results, adding specific guidance where metrics fall below thresholds, thus optimizing the prompt iteratively.
One practical approach in prompt refinement is to involve human-in-the-loop feedback systems. This strategy allows developers to collect qualitative insights into response quality, as human reviewers can provide detailed feedback on aspects like tone, coherence, and adherence to ethical standards. Rust’s interoperability with databases and efficient data handling can support human feedback collection, enabling real-time updates to prompt templates based on user insights. For instance, developers may use Rust to create feedback loops that automatically log evaluations and flag prompts requiring refinement, helping align model outputs with end-user expectations.
A key consideration in prompt evaluation is balancing complexity and model performance. Complex prompts can provide more context, potentially improving model response quality, but they also risk introducing ambiguity or cognitive overload. Overly simple prompts, while clear, may lack specificity, resulting in outputs that are too general or lack depth. By iterating on prompt complexity based on evaluation results, developers can achieve an optimal balance, ensuring the prompt is simple enough for clarity but precise enough to guide the model effectively. This trade-off is particularly relevant in real-time applications, such as customer service chatbots, where clear and accurate responses are prioritized.
Ethical considerations are also critical in prompt evaluation, especially in applications that involve sensitive topics, such as healthcare or financial advice. Evaluating prompts for potential bias—both in terms of content and phrasing—helps ensure that outputs are fair and inclusive. For example, prompts used in hiring applications should be assessed to avoid biases related to gender or ethnicity, which could influence the model’s recommendations. In Rust, developers can automate bias detection by integrating analysis functions that detect biased language patterns or measure demographic representation, ensuring that prompt designs align with ethical standards.
Real-world case studies highlight the importance of continuous prompt evaluation and refinement. In educational applications, prompt refinement has improved model performance in explaining complex concepts at appropriate difficulty levels for different age groups. By iterating on prompt specificity, developers have optimized model responses, ensuring that explanations remain accessible without sacrificing accuracy. Another example is in legal document summarization, where prompt refinement has enabled models to capture the essence of legal text while omitting irrelevant details. In these cases, prompt evaluation frameworks allowed developers to systematically adjust prompts, creating a process that produces legally sound, contextually appropriate summaries.
Emerging trends in prompt engineering emphasize automated and adaptive prompt refinement. Through reinforcement learning, prompt evaluation frameworks can be designed to adjust prompts based on the outcomes of prior interactions, creating dynamic prompts that evolve with user needs. Additionally, as LLMs become more advanced, prompt evaluation frameworks are likely to incorporate model-specific performance optimizations, allowing prompt templates to be tailored to the nuances of different LLM architectures. Rust’s high-performance concurrency and memory management make it an ideal language for implementing these automated frameworks, as it ensures efficient execution even in large-scale prompt evaluation pipelines.
In conclusion, prompt evaluation and refinement are essential processes in prompt engineering, enabling developers to systematically improve prompt designs for better model performance. By implementing quantitative and qualitative evaluation frameworks in Rust, developers can create robust, adaptable tools that support continuous prompt optimization. This section has explored the principles of prompt evaluation, illustrated practical implementation strategies, and highlighted the importance of balancing complexity, ethical considerations, and model responsiveness. As prompt engineering continues to evolve, these techniques will play an increasingly vital role in enhancing the accuracy, relevance, and ethical alignment of LLM outputs across diverse applications.
20.5. Advanced Prompt Engineering Techniques
Advanced prompt engineering techniques, such as few-shot prompting, zero-shot learning, and chain-of-thought prompting, significantly expand the capabilities of large language models (LLMs), enabling them to perform complex and multi-faceted tasks. These techniques allow LLMs to generalize across diverse tasks with minimal fine-tuning or additional data, an approach especially valuable in real-world scenarios where comprehensive training data is not always available. This section delves into the underlying concepts, applications, and implementation strategies of these advanced prompting methods, emphasizing how they leverage the intrinsic strengths of LLMs and reduce reliance on extensive data or computationally expensive model retraining.
Few-shot and zero-shot prompting are foundational techniques that use minimal examples (or none at all) to guide the model in performing new tasks. In few-shot prompting, the model is provided with a handful of examples within the prompt itself, which helps establish patterns that the model can follow. Mathematically, few-shot prompting can be represented as a mapping function $f: \{(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\} \rightarrow y_{n+1}$, where $(x_i, y_i)$ represents the example pairs included in the prompt. By encoding these examples directly in the input, few-shot prompts enable LLMs to infer task structure and produce an accurate response $y_{n+1}$ based on a new input $x_{n+1}$. In zero-shot prompting, the model relies purely on task instructions, without example pairs, using generalization skills acquired during pretraining. Zero-shot tasks can thus be formalized as $f(x) \rightarrow y$ without predefined input-output pairs. Both methods enable adaptive responses across tasks, from customer service to scientific research, where examples or explicit training may be limited.
Chain-of-thought prompting is another powerful technique that involves directing the LLM to break down complex tasks into sequential reasoning steps. In this case, the prompt encourages the model to approach the task in stages, promoting a systematic and logical solution process. This can be represented as a stepwise function $f(x) = (s_1, s_2, \dots, s_n) \rightarrow y$, where each $s_i$ represents a step in the reasoning chain that contributes to the final answer yyy. By decomposing complex problems, chain-of-thought prompting enables LLMs to handle tasks such as multi-step math problems, logical puzzles, or scientific explanations. For instance, in a decision-support system, a chain-of-thought prompt can guide the LLM to consider various factors sequentially—such as budget constraints, resource availability, and project timelines—leading to a well-reasoned recommendation.
Implementing these advanced techniques in Rust can enhance efficiency, especially in high-demand applications that require consistent, scalable performance. The following Rust code demonstrates how few-shot and zero-shot prompting can be structured in a simple prompt engineering framework. The example shows a few-shot prompt for summarization and a zero-shot prompt for a knowledge retrieval task, where the prompts are constructed based on the application context and task complexity.
use std::collections::HashMap;
// Define prompt structures for few-shot and zero-shot prompts
enum PromptType {
FewShot(Vec<(&'static str, &'static str)>), // Input-output pairs for few-shot
ZeroShot(&'static str), // Instruction-only for zero-shot
}
// Function to create formatted prompt based on PromptType
fn create_prompt(prompt_type: PromptType) -> String {
match prompt_type {
PromptType::FewShot(examples) => {
let mut prompt = String::new();
for (input, output) in examples {
prompt.push_str(&format!("Input: {}\nExpected Output: {}\n\n", input, output));
}
prompt.push_str("New Input: Provide a suitable output based on examples above.");
prompt
},
PromptType::ZeroShot(task_instruction) => format!("Task: {}\nAnswer concisely.", task_instruction),
}
}
// Function to evaluate prompt response (mock function for demonstration)
fn evaluate_response(_prompt: &str, response: &str) -> HashMap<&'static str, usize> {
// Placeholder: In real-world applications, use actual scoring metrics
let relevance = if response.contains("expected") { 90 } else { 75 };
HashMap::from([("relevance_score", relevance), ("clarity_score", 85)])
}
fn main() {
// Define few-shot and zero-shot examples
let few_shot_prompt = create_prompt(PromptType::FewShot(vec![
("Summarize: Rust is a memory-safe programming language.", "Rust offers memory safety."),
("Summarize: LLMs are powerful in language understanding.", "LLMs excel in language tasks."),
]));
let zero_shot_prompt = create_prompt(PromptType::ZeroShot("Explain the importance of Rust in systems programming."));
// Simulated model response
let response = "Rust is valuable in systems programming due to safety and performance.";
// Evaluate responses
let few_shot_evaluation = evaluate_response(&few_shot_prompt, response);
let zero_shot_evaluation = evaluate_response(&zero_shot_prompt, response);
println!("Few-shot Prompt Evaluation: {:?}", few_shot_evaluation);
println!("Zero-shot Prompt Evaluation: {:?}", zero_shot_evaluation);
}
This code demonstrates the construction of few-shot and zero-shot prompts. Few-shot prompts include pairs of inputs and expected outputs, enabling the model to infer response patterns, while zero-shot prompts focus on a task instruction without examples, guiding the model through generalization. The evaluation function provides relevance and clarity scores, offering insights into how each prompt type performs, although in practical applications, more sophisticated metrics would be applied.
These advanced prompting techniques offer substantial flexibility in real-world applications. For instance, few-shot prompting has proven effective in customer service, where it helps tailor responses based on past interactions, even when explicit training data is scarce. In knowledge-intensive fields, such as law or medicine, zero-shot prompts enable LLMs to answer complex questions based on pretrained knowledge, without requiring case-specific examples. Chain-of-thought prompting is particularly valuable in educational technologies, where it guides LLMs to solve step-by-step explanations, making it easier for students to follow complex solutions.
Recent trends in prompt engineering research emphasize adaptive prompting, where the prompt structure is automatically adjusted based on feedback from prior interactions. By combining reinforcement learning with prompt engineering, systems can automatically optimize prompt parameters, reducing the need for extensive prompt testing and manual fine-tuning. Rust’s performance and memory safety features make it a suitable choice for implementing adaptive prompt systems that operate at scale, processing feedback quickly and applying adjustments in real time.
Furthermore, advanced prompt techniques help reduce the dependency on large, task-specific datasets by enabling more generalizable responses, allowing LLMs to perform well across varied tasks without extensive retraining. For instance, in creative applications like poetry or story generation, few-shot prompts that include examples of creative style or structure can help produce outputs that are stylistically aligned with the examples. In business decision-support systems, chain-of-thought prompting helps models make structured, stepwise recommendations, which are easier to validate and interpret.
The ethical dimensions of advanced prompting are also crucial, as these techniques shape the model’s interpretative approach to complex tasks. Few-shot and zero-shot prompts need to be designed carefully to avoid reinforcing biases or producing misleading responses, especially in fields where accuracy is critical. For instance, in healthcare, zero-shot prompts should be formulated to avoid speculative or unverified medical advice. Chain-of-thought prompts, while enabling structured responses, also introduce the risk of cascading errors, where one flawed reasoning step may propagate through the rest of the response. Continuous monitoring and refinement of prompt designs can help mitigate these ethical concerns, and Rust’s robust tooling and performance efficiency make it ideal for building prompt evaluation frameworks that ensure prompts meet high ethical and accuracy standards.
In conclusion, advanced prompt engineering techniques, including few-shot prompting, zero-shot learning, and chain-of-thought prompting, open up new possibilities for guiding LLMs through complex, nuanced tasks with minimal retraining. Rust’s high performance, memory safety, and concurrency capabilities support the development of prompt engineering frameworks that enable these techniques at scale. By combining adaptive prompt design with robust evaluation methods, developers can ensure that advanced prompts remain effective, ethical, and aligned with evolving application needs. As LLMs continue to integrate into diverse fields, these advanced prompting strategies will be pivotal in maximizing model utility and adaptability across complex, real-world applications.
20.6. Ethical and Practical Considerations in Prompt Engineering
Prompt engineering presents unique ethical and practical challenges that are particularly relevant as large language models (LLMs) find applications in high-stakes and sensitive areas. Ethical considerations in prompt engineering are critical, as poorly designed prompts can lead to biased, misleading, or even harmful outputs. For instance, prompts that subtly imply a bias or reinforce stereotypes can propagate these tendencies in model responses, which could adversely impact applications like content moderation or automated decision-making. Practical considerations, on the other hand, include the scalability and reliability of prompt-engineered systems, as well as the need to establish user trust through transparency and accountability. Addressing these ethical and practical aspects is essential to ensure that prompt-engineered LLMs serve their intended purpose responsibly and effectively.
A fundamental ethical challenge in prompt engineering is managing the risk of biased outputs. Mathematically, we can represent a model’s response as a function of the prompt $P$ and the model’s learned weights $W$, denoted $f(P, W) \rightarrow R$, where $R$ represents the response. Bias can be introduced if the prompt $P$ reinforces certain attributes in $W$ that result in skewed responses. For example, a prompt designed to provide hiring recommendations may inadvertently reflect gender or racial biases if it subtly favors certain characteristics. Detecting and mitigating such biases requires analyzing model responses for statistically significant deviations, often using bias metrics like Fairness Score or disparate impact ratios. Rust’s performance-oriented architecture supports the efficient implementation of these statistical analyses, making it an ideal choice for real-time bias detection and correction frameworks.
One approach to implement bias detection in Rust involves setting up a framework that automatically flags potentially biased responses based on defined metrics. The following Rust code demonstrates a simple bias detection mechanism. Here, the prompt output is analyzed using predefined keywords or sensitive terms, and if a bias threshold is exceeded, the prompt is flagged for further review. This method helps identify potentially problematic prompts and is a foundational step in establishing ethical prompt engineering practices.
use regex::Regex;
// Define a struct for handling bias metrics
struct BiasMetrics {
fairness_score: f32,
sensitive_term_count: usize,
}
// Function to calculate basic bias metrics based on keyword occurrences
fn detect_bias(response: &str, sensitive_terms: &[&str]) -> BiasMetrics {
let mut sensitive_count = 0;
for &term in sensitive_terms {
let re = Regex::new(&format!(r"\b{}\b", term)).unwrap();
sensitive_count += re.find_iter(response).count();
}
// Simple fairness score placeholder (in real scenarios, use statistical metrics)
let fairness_score = 100.0 - (sensitive_count as f32 * 5.0);
BiasMetrics {
fairness_score: fairness_score.max(0.0), // Ensure score is non-negative
sensitive_term_count: sensitive_count,
}
}
fn main() {
let response = "The applicant is likely suitable based on leadership and assertiveness.";
let sensitive_terms = ["gender", "race", "ethnicity"];
// Detect bias in the response
let metrics = detect_bias(response, &sensitive_terms);
println!("Bias Metrics: Fairness Score - {:.2}, Sensitive Term Count - {}", metrics.fairness_score, metrics.sensitive_term_count);
if metrics.fairness_score < 80.0 {
println!("Alert: Potential bias detected in the response.");
}
}
This example evaluates a response for bias by counting occurrences of sensitive terms and calculating a basic fairness score. In real-world applications, this scoring would likely be more sophisticated, incorporating data-driven fairness assessments and statistical metrics such as disparate impact ratios. Rust’s regex crate supports efficient term matching, while the language’s inherent performance and memory management strengths make it an excellent choice for implementing scalable, real-time bias detection.
Mitigating prompt engineering risks goes beyond bias detection to include transparency and accountability measures. In domains like content moderation, ensuring that LLMs operate with transparency is critical to maintaining user trust and compliance with regulatory guidelines. Transparency in LLM prompts can be facilitated through user-facing explanations, where each prompt’s intent and potential limitations are clearly communicated. This level of transparency may involve creating a compliance checklist that documents each prompt’s alignment with ethical guidelines and standards, particularly in sensitive areas like healthcare or finance. By systematically addressing factors like fairness, accuracy, and relevance, prompt engineers can uphold ethical standards and provide users with transparency on how prompt-generated outputs are crafted and evaluated.
A compliance checklist can serve as a foundation for responsible prompt engineering practices. Key items may include alignment with ethical guidelines, fairness assessments, and user feedback mechanisms to collect real-time input on prompt effectiveness. Rust’s type safety and structured error handling make it feasible to implement such a compliance checklist directly within the code, where specific prompts can be flagged for review based on defined criteria. This checklist approach allows engineers to monitor adherence to ethical standards continuously, enabling rapid adjustments when necessary.
Evaluating the ethical performance of prompt-engineered LLMs is an iterative process that involves continuous feedback and refinement. The ethical performance of these models can be quantitatively assessed using methods like differential testing, where prompts are tested across diverse demographic datasets to identify potential biases. Qualitatively, user feedback can be integrated as part of a human-in-the-loop system, ensuring that model outputs are evaluated in a real-world context and adjusted based on practical insights. Rust supports efficient logging and data handling, allowing developers to capture and analyze user interactions with prompt-engineered LLMs, ensuring that feedback is seamlessly incorporated into prompt evaluation workflows.
A significant industry example of ethical prompt engineering comes from automated hiring systems. For example, in applicant screening, prompts designed to assess soft skills must avoid biases that could result in discriminatory hiring practices. Advanced bias detection mechanisms are essential here, allowing companies to identify prompts that may reinforce gender, age, or ethnicity-based biases. Prompt transparency also plays a crucial role in automated decision-making. Companies are increasingly adopting prompt design practices that document each prompt’s purpose and ethical implications, thus enhancing accountability and reducing potential legal risks.
Emerging trends in prompt engineering underscore the importance of adaptive prompt refinement based on ethical evaluations. By using machine learning techniques, systems can learn from historical prompt data, adjusting for biases and improving fairness over time. This process, known as fairness-aware prompt optimization, allows prompts to evolve and adapt to user feedback dynamically. Rust’s concurrency capabilities enable developers to implement adaptive systems that respond to ethical assessments in real time, facilitating prompt adjustments that enhance ethical compliance while maintaining performance.
In conclusion, ethical and practical considerations are paramount in prompt engineering, as the design and deployment of prompts directly influence the outputs and impacts of LLMs. By implementing robust bias detection, transparency mechanisms, and compliance checklists in Rust, developers can address the ethical and practical challenges of prompt engineering effectively. This section highlights the importance of ongoing ethical evaluation, emphasizing how techniques like fairness-aware optimization and human-in-the-loop feedback can help LLMs operate responsibly and maintain user trust across sensitive applications. As prompt engineering techniques continue to evolve, maintaining high ethical standards and practical accountability will remain essential to advancing the field responsibly.
20.7. Case Studies and Future Directions in Prompt Engineering
Prompt engineering has proven to be a transformative tool in various fields, from healthcare to finance, where applications of large language models (LLMs) are pushing the boundaries of traditional automation and knowledge management. Through real-world case studies, we observe how prompt engineering has been applied to overcome specific challenges, optimize model performance, and meet the requirements of diverse, high-stakes environments. By examining these deployments, we can extract best practices and understand the fundamental role of prompt engineering in shaping LLM-driven applications, particularly in areas that demand high adaptability, scalability, and ethical considerations.
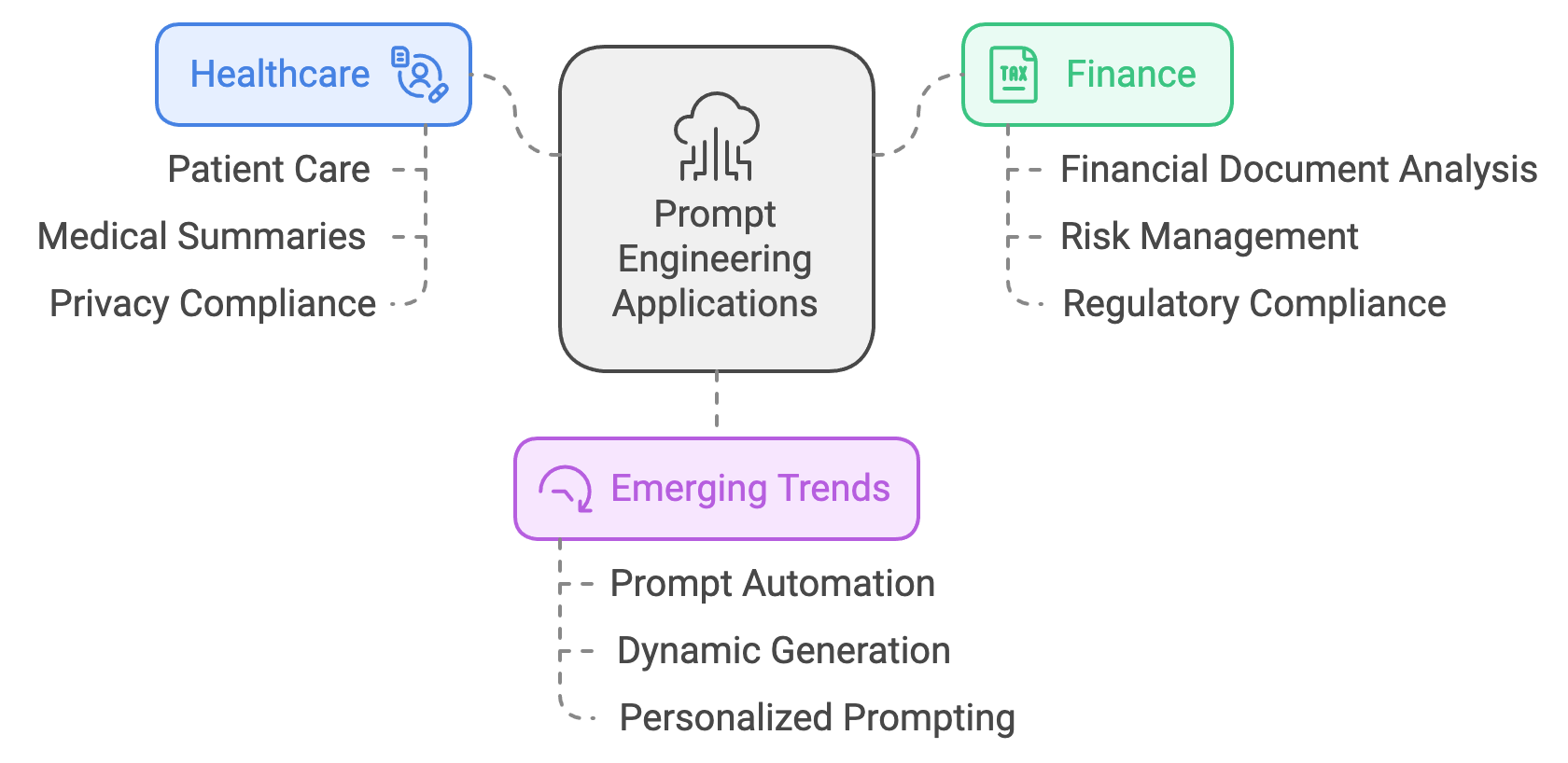
Figure 4: Examples of LLM applications in some industries like Healthcare and Finance.
A notable case study in healthcare demonstrates how prompt engineering has been used to support patient care by guiding an LLM to generate accurate, actionable medical summaries. This application faced unique challenges, as the model had to provide reliable information while adhering to strict privacy regulations. The prompt design carefully balanced specificity and brevity to ensure that generated summaries were relevant without overloading the response with unnecessary detail. Additionally, privacy compliance was a key consideration; prompts were crafted to avoid exposing any personally identifiable information (PII). This case study highlighted the importance of prompt engineering in addressing both performance and ethical requirements, showcasing how thoughtful prompt design can ensure that LLMs remain reliable tools in sensitive domains.
Prompt engineering in the finance sector has likewise proven valuable, particularly in automating the analysis of complex financial documents. Here, prompts are designed to interpret and synthesize information from diverse financial records, reports, and market analyses. This requires a dynamic approach to prompt engineering, where prompts are structured to elicit the most relevant financial insights based on shifting market conditions. For instance, prompts may be adjusted in real time to focus on emerging risks during volatile periods, enabling financial analysts to receive timely updates. Rust’s efficient processing capabilities support the rapid adaptation of prompts in high-demand financial applications, allowing prompt-engineered LLMs to assist in risk management and regulatory compliance. In these applications, prompt engineering also reduces the need for model retraining, as dynamically crafted prompts can quickly align the LLM’s output with new financial contexts without altering the model’s parameters.
As prompt engineering continues to evolve, emerging trends such as prompt automation, dynamic prompt generation, and personalized prompting are gaining traction. Prompt automation allows for the efficient deployment of prompts in applications with large-scale data needs, where prompts can be generated and evaluated in real time. Dynamic prompt generation enables prompts to be adapted on the fly based on feedback loops, allowing LLMs to adjust their outputs according to evolving requirements. Personalized prompting tailors the model’s responses based on user profiles or historical interactions, enhancing relevance in applications such as customer service or personalized learning. These approaches leverage reinforcement learning and real-time analytics to refine prompts iteratively, allowing models to better align with user needs over time. Rust’s concurrency and performance-oriented architecture make it an ideal choice for building these adaptive prompt systems, as they require high efficiency to handle rapid prompt adjustments without sacrificing response time.
In the future, prompt engineering holds the potential to become a critical layer of model interaction, particularly in domains such as healthcare, finance, and education. In healthcare, for instance, prompt engineering could support diagnostic applications by guiding LLMs to ask targeted questions, gathering detailed patient information while ensuring regulatory compliance. In finance, prompt engineering can streamline decision-making processes, enabling LLMs to provide tailored insights for risk assessment or market forecasting based on specific business rules. Educational applications stand to benefit from adaptive prompts that customize learning materials based on a student’s progress and comprehension level, creating personalized learning experiences that cater to individual needs.
The mathematical foundation of adaptive prompt engineering can be understood in terms of function composition. If $f(P)$ represents the function mapping prompt $P$ to output $O$, adaptive prompting can be represented as an iterative process: $f(P_n) \rightarrow O_n$, where each prompt $P_n$ is adjusted based on the evaluation of $O_{n-1}$. Over successive iterations, the prompt $P_n$ converges toward an optimal structure that yields the highest quality output $O$ based on predefined performance criteria. This iterative approach enables prompt engineers to achieve fine-grained control over model behavior, guiding LLMs to produce outputs that are both relevant and contextually appropriate.
An example implementation of adaptive prompting in Rust involves designing a dynamic prompt generator that takes real-time feedback into account. This Rust code snippet shows how prompts can be adjusted based on response evaluations, forming an adaptive loop where each prompt version is incrementally optimized.
// Struct to handle prompt evaluations
struct PromptEvaluation {
relevance_score: f32,
clarity_score: f32,
}
// Adaptive prompt generator that updates prompts based on feedback
struct AdaptivePromptGenerator {
base_prompt: String,
}
impl AdaptivePromptGenerator {
fn new(prompt: &str) -> Self {
AdaptivePromptGenerator {
base_prompt: prompt.to_string(),
}
}
fn generate_prompt(&mut self, evaluation: &PromptEvaluation) -> String {
let mut refined_prompt = self.base_prompt.clone();
if evaluation.relevance_score < 75.0 {
refined_prompt.push_str(" Ensure accuracy in the response.");
}
if evaluation.clarity_score < 75.0 {
refined_prompt.push_str(" Provide a clear and structured answer.");
}
refined_prompt
}
}
// Function to simulate prompt evaluation (in practice, use actual feedback)
fn evaluate_response(_response: &str) -> PromptEvaluation {
// Placeholder scores for demonstration
PromptEvaluation {
relevance_score: 80.0,
clarity_score: 72.0,
}
}
fn main() {
let mut generator = AdaptivePromptGenerator::new("Summarize the document concisely.");
let response = "The document discusses...";
// Evaluate and adapt prompt based on feedback
let evaluation = evaluate_response(response);
let new_prompt = generator.generate_prompt(&evaluation);
println!("Adapted Prompt: {}", new_prompt);
}
This code defines an AdaptivePromptGenerator that refines prompts based on relevance and clarity scores. The iterative feedback mechanism demonstrates how prompt engineering can be applied dynamically, refining prompts as new insights are gained. In practical applications, such adaptive prompting systems could utilize real-time response data, enabling LLMs to continually improve their alignment with user expectations.
Looking forward, prompt engineering faces both opportunities and challenges as it scales across various applications. The development of new frameworks for dynamic and personalized prompting offers the potential to further extend the adaptability and responsiveness of LLMs. However, challenges remain, particularly in ensuring that advanced prompts do not inadvertently introduce biases or complexity that could reduce transparency. In user-centric applications, balancing prompt sophistication with user engagement and accessibility is essential. Moreover, prompt automation and real-time adaptation introduce complexity that demands efficient, reliable frameworks—areas where Rust’s concurrency and type safety provide a strong foundation for building scalable prompt engineering systems.
The development of LLM applications follows a structured pipeline, beginning with foundational models and progressing through prompt engineering, tuning, validation, and finally deployment. First, a foundational LLM is selected or trained, typically a general-purpose model with extensive pre-training. Then, prompts and instructions are designed to guide the model's responses toward specific tasks, followed by prompt tuning—a fine-tuning phase where the model adapts to custom prompts to improve alignment with the intended application. Agents, or task-specific wrappers around the model, are then created to ensure the LLM follows the defined instructions effectively. Testing agents assess model performance against benchmarks to verify the quality and relevance of outputs, and validation processes further refine the model to eliminate biases and errors. Once validated, the model transitions into production, where it is integrated into an interface to accept live user inputs. A monitoring system is deployed to track output quality, usage patterns, and performance metrics, ensuring the model consistently meets expectations. Through this pipeline, the LLM application becomes a user-ready solution, delivering accurate and relevant responses in real-time with ongoing oversight for continuous improvement.
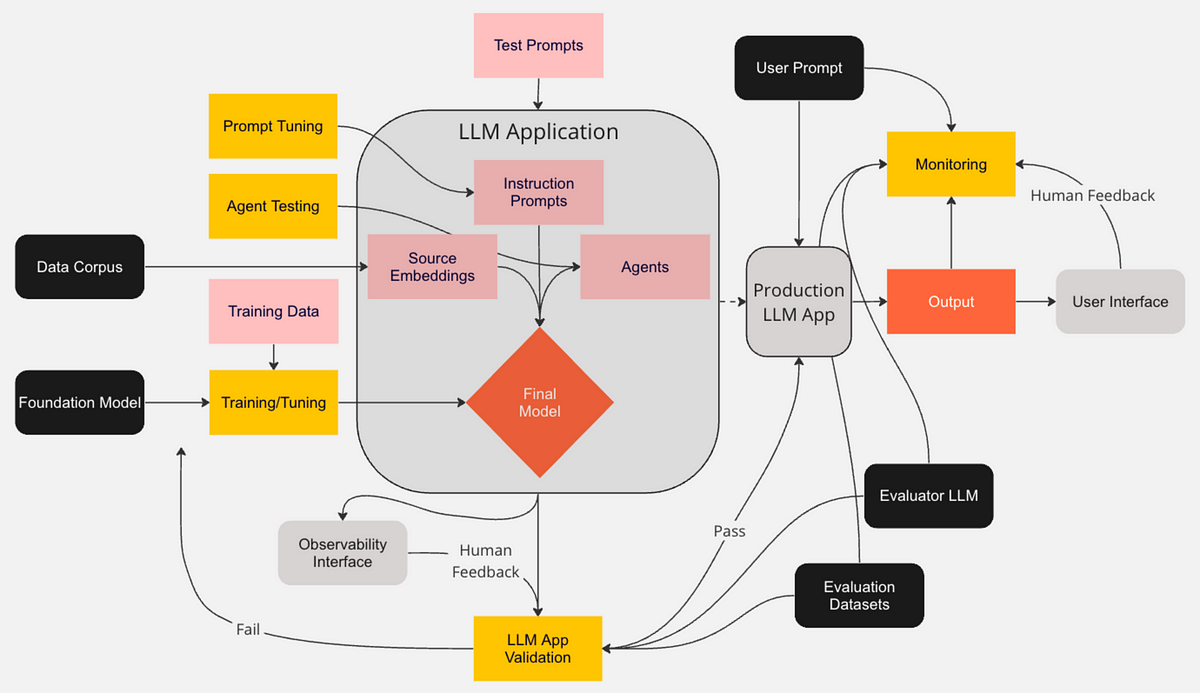
Figure 5: The common architecture of LLM Application with Prompt Engineering.
In conclusion, prompt engineering has become a cornerstone for effectively deploying LLMs across diverse fields, and the case studies presented illustrate its impact in real-world applications. Rust’s performance and memory safety make it an ideal choice for implementing adaptive, scalable prompt engineering frameworks, especially as emerging trends like dynamic and personalized prompting continue to gain traction. By advancing techniques in prompt automation, personalization, and ethical compliance, prompt engineering will continue to shape the future of LLM applications, enabling more nuanced, contextually aware, and user-responsive model outputs across industries.
20.8. Conclusion
Chapter 20 equips readers with the knowledge and tools to master prompt engineering using Rust. By understanding the nuances of prompt design and its impact on model behavior, readers can craft prompts that optimize LLM performance while adhering to ethical guidelines. This chapter lays the foundation for developing intelligent, responsible AI systems that effectively address real-world challenges.
20.8.1. Further Learning with GenAI
These prompts cover fundamental concepts, practical implementation, advanced techniques, and ethical considerations, providing a comprehensive understanding of how to design, refine, and deploy effective prompts that optimize the performance of large language models (LLMs).
Explain the fundamental principles of prompt engineering. How does prompt design influence the behavior and outputs of large language models (LLMs)?
Discuss the key challenges in crafting effective prompts for LLMs. What strategies can be used to avoid ambiguity, bias, and unintended outcomes in model responses?
Describe the process of building a Rust-based toolkit for prompt engineering. What are the essential components of such a toolkit, and how do they facilitate prompt creation and testing?
Analyze the impact of prompt structure on LLM outputs. How do variations in prompt length, specificity, and context affect the accuracy and relevance of model responses?
Explore the role of domain knowledge in designing prompts for specific applications. How can prompts be tailored to optimize LLM performance in specialized fields like healthcare, finance, or education?
Explain the iterative process of refining prompts based on evaluation results. What metrics and methods can be used to assess the effectiveness of prompts in different tasks?
Discuss the importance of modular and reusable prompt engineering tools. How can Rust’s features be leveraged to create efficient, adaptable tools that streamline the prompt design process?
Describe advanced prompt engineering techniques such as few-shot prompting, zero-shot learning, and chain-of-thought prompting. How do these techniques enhance the capabilities of LLMs in complex tasks?
Analyze the ethical implications of prompt engineering. What are the potential risks of biased or misleading prompts, and how can these risks be mitigated through careful prompt design and evaluation?
Explain the process of integrating prompt engineering into existing Rust-based LLM applications. What are the challenges and benefits of this integration, and how can it improve model performance?
Discuss the trade-offs between prompt complexity and model performance. How can prompt engineers balance simplicity with precision to achieve optimal results in various tasks?
Explore the use of prompt engineering in content generation. How can prompts be designed to guide LLMs in creating coherent, creative, and contextually appropriate content?
Analyze the role of prompt engineering in enhancing the interpretability and explainability of LLM outputs. How can prompts be crafted to make model reasoning more transparent and understandable?
Discuss the practical considerations of deploying prompt-engineered LLMs in real-world applications. What are the key factors to ensure scalability, reliability, and user trust?
Explain how bias detection and mitigation techniques can be incorporated into prompt engineering workflows. How can these techniques be implemented using Rust to ensure fairness and transparency?
Explore the future potential of dynamic and personalized prompting. How can these advanced prompt engineering techniques be developed and deployed to enhance LLM adaptability and user engagement?
Discuss the challenges of designing prompts for multi-step reasoning and decision-making tasks. How can prompts be structured to guide LLMs through complex, logical sequences?
Analyze the lessons learned from existing prompt engineering case studies. What best practices can be derived from these experiences, and how can they inform future projects?
Explain the role of user feedback in refining prompts. How can a feedback loop be established to continuously improve prompt designs based on real-world usage?
Discuss the broader implications of prompt engineering in AI development. How can effective prompt design shape the future of AI applications, particularly in terms of ethical considerations and user interaction?
Embrace these challenges with curiosity and determination, knowing that the skills you acquire will empower you to contribute meaningfully to the advancement of AI technology.
20.8.2. Hands On Practices
Self-Exercise 20.1: Crafting Effective Prompts for Task-Specific Applications
Objective: To design and implement effective prompts for a specific application, such as content generation or question answering, focusing on maximizing the accuracy, relevance, and coherence of the LLM outputs.
Tasks:
Identify a specific application (e.g., content generation for a blog post, or question answering in a customer support scenario) that requires prompt engineering.
Design a set of initial prompts tailored to the chosen application, considering factors such as context, specificity, and desired outcomes.
Experiment with variations of the prompts, adjusting their structure, length, and language to optimize the model's performance.
Evaluate the outputs generated by the model for each prompt variation, analyzing the impact of different prompt designs on the quality of the responses.
Deliverables:
A report detailing the initial prompt designs, including the reasoning behind each prompt structure.
A series of refined prompts based on the experimental results, with a discussion of how each modification affected the model’s outputs.
An evaluation summary comparing the effectiveness of the different prompt variations in achieving the desired application outcomes.
Self-Exercise 20.2: Building and Testing a Prompt Engineering Toolkit Using Rust
Objective: To develop a Rust-based toolkit for prompt engineering that includes components for prompt creation, testing, and analysis, focusing on building a modular and reusable system.
Tasks:
Design the architecture of a prompt engineering toolkit in Rust, identifying key components such as prompt templates, testing frameworks, and output analyzers.
Implement the toolkit, ensuring that each component is modular, efficient, and easy to integrate into existing LLM workflows.
Test the toolkit by using it to create and evaluate prompts for a specific LLM task, such as text summarization or sentiment analysis.
Refine the toolkit based on the testing results, improving its functionality and ease of use for future prompt engineering projects.
Deliverables:
A Rust codebase for the prompt engineering toolkit, including detailed documentation for each component.
A test report demonstrating the toolkit’s effectiveness in creating and evaluating prompts for the chosen LLM task.
A set of recommendations for further improvements to the toolkit, focusing on enhancing its modularity, efficiency, and usability.
Self-Exercise 20.3: Refining Prompts Through Iterative Evaluation
Objective: To refine and optimize prompts through an iterative evaluation process, focusing on improving model performance across different tasks using quantitative and qualitative metrics.
Tasks:
Design a set of initial prompts for a specific LLM task, such as generating technical explanations or summarizing complex documents.
Develop an evaluation framework to assess the effectiveness of the prompts, incorporating both automated metrics (e.g., BLEU score, accuracy) and manual review criteria (e.g., coherence, relevance).
Implement an iterative process to refine the prompts based on evaluation feedback, making incremental adjustments to improve model outputs.
Conduct a final evaluation of the refined prompts, comparing their performance to the initial versions and documenting the improvements.
Deliverables:
A series of refined prompts along with the evaluation framework used for assessment.
A detailed report on the iterative refinement process, including the specific changes made to each prompt and their impact on model performance.
A comparison of the initial and final prompts, highlighting the key improvements achieved through the iterative process.
Self-Exercise 20.4: Implementing Advanced Prompt Engineering Techniques
Objective: To explore and implement advanced prompt engineering techniques, such as few-shot prompting and chain-of-thought prompting, focusing on their application to complex LLM tasks.
Tasks:
Choose a complex LLM task, such as multi-step reasoning, creative content generation, or decision support, that would benefit from advanced prompting techniques.
Implement few-shot prompting by designing prompts that include examples of desired outputs, guiding the model to generate similar responses.
Experiment with chain-of-thought prompting, structuring prompts to lead the model through a step-by-step reasoning process to arrive at the correct answer or output.
Evaluate the effectiveness of these advanced techniques, comparing their performance to standard prompting methods in achieving the desired outcomes.
Deliverables:
A set of advanced prompts, including few-shot and chain-of-thought examples, tailored to the chosen LLM task.
An evaluation report comparing the effectiveness of advanced prompting techniques to standard methods, with a focus on accuracy, reasoning ability, and output quality.
A set of guidelines for implementing advanced prompt engineering techniques in future LLM tasks, based on the results of the experiment.
Self-Exercise 20.5: Addressing Ethical Considerations in Prompt Engineering
Objective: To identify and address ethical considerations in prompt engineering, focusing on detecting and mitigating biases in LLM outputs through careful prompt design and evaluation.
Tasks:
Select an LLM task that is sensitive to ethical considerations, such as content moderation, automated decision-making, or personalized recommendations.
Design a series of prompts for the task, paying special attention to the potential for bias or unintended consequences in the model’s responses.
Implement bias detection techniques to evaluate the prompts, identifying any areas where the model outputs could be unfair, misleading, or harmful.
Refine the prompts to mitigate identified biases, ensuring that the final prompts produce fair, accurate, and ethically sound outputs.
Deliverables:
A set of ethically sound prompts designed for the chosen LLM task, including documentation of the potential biases identified and mitigated during the process.
An evaluation report on the effectiveness of the bias detection and mitigation techniques used, including examples of how the final prompts improved the fairness and accuracy of model outputs.
A set of best practices for ethical prompt engineering, providing guidelines for detecting and addressing biases in future LLM projects.
Comments