Chapter 19
Graph Neural Networks and LLMs
"The true power of AI lies in its ability to combine different types of models and data, such as graph neural networks and language models, to achieve a deeper understanding and better decision-making across complex domains." — Yann LeCun
Chapter 19 of LMVR delves into the integration of Graph Neural Networks (GNNs) with Large Language Models (LLMs) using Rust, offering a robust framework for processing and reasoning about graph-structured data. The chapter covers the entire lifecycle of developing GNN-LLM models, from building data pipelines for graph data and training GNNs on large-scale datasets to deploying these models in real-time, scalable environments. It emphasizes the importance of addressing challenges such as over-smoothing, scalability, and ethical considerations, ensuring that GNN-LLM models are not only powerful and efficient but also fair and transparent. By leveraging Rust’s performance and safety features, this chapter equips readers with the knowledge to create advanced, integrated AI models that excel in tasks requiring structured data reasoning.
19.1. Introduction to Graph Neural Networks (GNNs)
Graph Neural Networks (GNNs) represent a transformative class of neural networks specifically designed to process and analyze graph-structured data. Graphs are prevalent in numerous domains, including social networks, molecular biology, recommendation systems, and more, where data points (or nodes) are interconnected by relationships (or edges). Unlike traditional neural networks that operate on structured data like images or text, GNNs are inherently flexible, designed to handle irregular and non-Euclidean data. GNNs leverage graph structures to learn representations of nodes, edges, or entire graphs, making them well-suited for tasks such as node classification, link prediction, and graph classification. Each node in a graph holds unique information, and the edges define relationships that can enhance prediction accuracy by capturing dependencies between data points. This structure enables GNNs to capture local and global patterns within graphs, thereby providing insights that traditional neural networks cannot offer.
GNNs excel in applications across fields where relationships and structures are key. In molecular modeling, GNNs predict properties of molecules by treating atoms as nodes and bonds as edges, aiding drug discovery and material science. In knowledge graphs, GNNs enhance recommendation systems and search engines by analyzing entities and relationships to infer new connections. For information networks, like citation networks, GNNs can classify documents or predict links between them. In neuroscience, GNNs model the brain's complex neuronal interactions, assisting in understanding brain functions and diseases. For genomic data, GNNs analyze gene interactions, revealing insights into gene regulation and disease mechanisms. In communication networks, GNNs optimize data routing by understanding network topologies. In software analysis, GNNs help in code analysis, bug detection, and vulnerability identification by representing code structures as graphs. Finally, in social media, GNNs analyze user connections and interactions to detect communities, trends, and anomalies, driving insights in social dynamics and targeted recommendations. These applications demonstrate GNNs' versatility in analyzing complex systems of interconnected data.
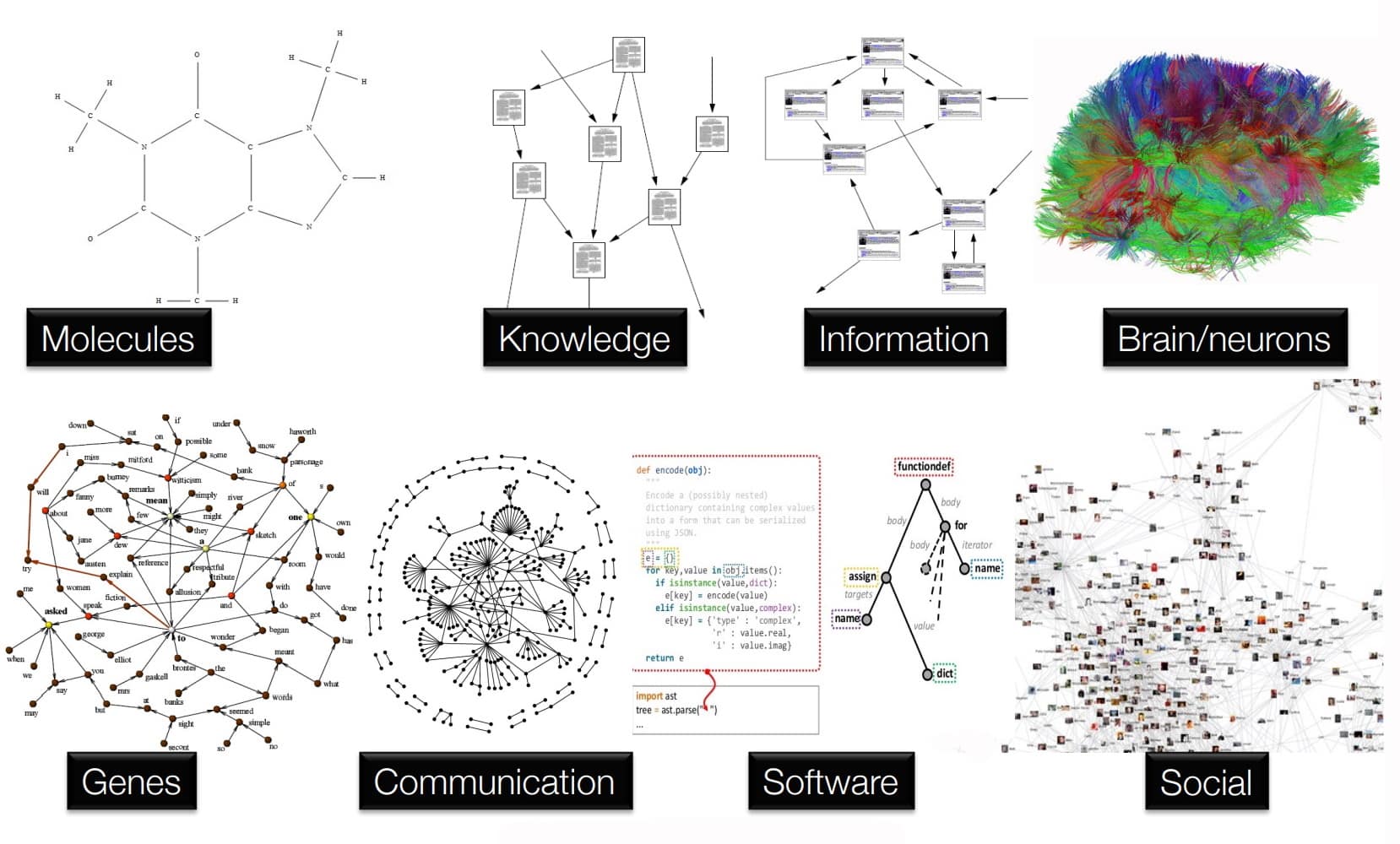
Figure 1: Areas of applications of Graph Neural Networks (GNNs).
The fundamental building blocks of GNNs are nodes, edges, and graph convolutional operations. In a graph $G = (V, E)$, where $V$ denotes the set of nodes and $E$ denotes the set of edges, each node $v \in V$ has associated features $x_v$, and edges $e \in E$ represent the relationships or connections between nodes. The essence of a GNN lies in its ability to propagate information across these nodes and edges. Graph convolutional operations aggregate and transform the features of neighboring nodes iteratively, allowing each node to learn from the structure and attributes of its neighborhood. Mathematically, this can be represented by an update rule of the form $h_v^{(k+1)} = f(h_v^{(k)}, \text{AGGREGATE}(\{h_u^{(k)} : u \in \mathcal{N}(v)\}))$ denotes the representation of node $v$ at the $k$-th layer, $\mathcal{N}(v)$ denotes the neighbors of $v$, and $f$ and AGGREGATE are functions that combine information from neighboring nodes. This iterative process enables GNNs to capture both node-specific and global graph patterns, making them robust for a variety of tasks.
The development of GNNs arose from the limitations of traditional neural networks when applied to graph data. Convolutional neural networks (CNNs), for instance, excel in grid-like structures such as images but lack the flexibility to process data with arbitrary connections. GNNs were designed to bridge this gap, offering a method for neural networks to operate on graph-structured data directly. Over time, various architectures have emerged to address specific types of graph-based tasks. Graph Convolutional Networks (GCNs) use spectral-based convolutions to perform message passing between nodes, aggregating information through layers of graph convolutions. Graph Attention Networks (GATs) introduce attention mechanisms to weigh the importance of neighboring nodes, allowing the model to focus on the most relevant neighbors dynamically. GraphSAGE, another popular architecture, applies sampling techniques to handle large graphs efficiently by only aggregating information from a subset of neighbors. These architectures have contributed to the versatility of GNNs, enabling them to handle diverse graph structures and capture varying levels of node dependency and contextual relevance.
An emerging trend in deep learning is the integration of GNNs with large language models (LLMs), enhancing the ability of LLMs to process and reason about relational data. This integration can be particularly beneficial in applications where relational structures are important, such as knowledge graphs, document clustering, and social media analysis. For example, when applied to a knowledge graph, a GNN can enhance the LLM’s understanding of the relationships between entities by encoding these connections as graph embeddings, which the LLM can then process as contextual information. By extending the capabilities of LLMs to handle structured relational data, GNNs pave the way for applications that require a deep understanding of interrelated entities. This ability to process both structured and unstructured data makes GNNs a valuable addition to the toolkit for developing more nuanced and context-aware LLM applications.
The following Rust code illustrates a basic implementation of a GNN for node classification on a simple graph dataset. This pseudocode outlines the core steps in implementing a Graph Neural Network (GNN) for node classification, using a graph structure where each node has features and edges represent relationships. The goal of this example is to predict a class label for each node by propagating information from neighboring nodes using message passing and aggregation. This process is central to GNNs, as it allows each node's representation to be updated based on the features of its neighbors.
[dependencies]
ndarray = "0.16.1"
use ndarray::{Array1};
use std::collections::HashMap;
// Define the graph structure
struct Graph {
nodes: HashMap<usize, Array1<f32>>, // Node features
edges: HashMap<usize, Vec<usize>>, // Edges (adjacency list)
}
// Initialize a simple GNN layer for message passing
fn gnn_layer(graph: &Graph, node_embeddings: &HashMap<usize, Array1<f32>>) -> HashMap<usize, Array1<f32>> {
let mut new_embeddings = HashMap::new();
for (&node, neighbors) in &graph.edges {
// Aggregate neighbor embeddings
let mut aggregated = Array1::<f32>::zeros(node_embeddings[&node].len());
for &neighbor in neighbors {
aggregated += &node_embeddings[&neighbor];
}
aggregated /= neighbors.len() as f32; // Normalize by number of neighbors
// Update node embedding with a simple transformation
new_embeddings.insert(node, aggregated.mapv(|x| x.tanh())); // Apply tanh nonlinearity
}
new_embeddings
}
fn main() {
// Define a simple graph
let mut nodes = HashMap::new();
nodes.insert(1, Array1::from(vec![0.1, 0.2, 0.3]));
nodes.insert(2, Array1::from(vec![0.4, 0.1, 0.2]));
nodes.insert(3, Array1::from(vec![0.5, 0.7, 0.2]));
let mut edges = HashMap::new();
edges.insert(1, vec![2, 3]);
edges.insert(2, vec![1, 3]);
edges.insert(3, vec![1, 2]);
let graph = Graph { nodes, edges };
// Initialize node embeddings
let embeddings = graph.nodes.clone();
// Apply a GNN layer for node embedding update
let updated_embeddings = gnn_layer(&graph, &embeddings);
println!("Updated node embeddings: {:?}", updated_embeddings);
}
This pseudocode demonstrates a basic Graph Neural Network (GNN) layer that performs message passing and aggregation to update node embeddings. The Graph class represents a graph structure with node features and adjacency lists. The gnn_layer function aggregates each node's embeddings based on its neighbors, applying a nonlinearity (e.g., tanh) to the aggregated embeddings before updating them. The main function initializes a simple graph, defines initial embeddings for each node, and then applies the GNN layer to update the embeddings. This structure illustrates how GNNs propagate information across a graph, making it an effective tool for tasks like node classification.
Case studies reveal the transformative potential of GNNs in enhancing the capabilities of LLMs and other AI models across various domains. For example, in drug discovery, GNNs have been successfully applied to predict molecular properties, enabling researchers to screen potential compounds efficiently. By representing molecules as graphs, where nodes correspond to atoms and edges represent bonds, GNNs can capture the relational properties within molecules, leading to more accurate predictions than traditional models. Similarly, in recommendation systems, GNNs help model user-item relationships by analyzing user behaviors and connections within social networks, leading to improved personalized recommendations. Rust’s performance and parallel processing capabilities are highly advantageous in such cases, as they enable the efficient computation of embeddings and aggregation across large-scale graphs, making GNNs scalable and responsive in real-world applications.
The future of GNNs is poised to push boundaries in data representation and analysis, with ongoing research focused on scaling GNNs for massive graphs, enhancing model interpretability, and integrating GNNs with other neural architectures, including LLMs. Scaling GNNs to handle large-scale graphs, such as social networks with billions of nodes, presents significant challenges in memory management and computation efficiency. Techniques like sampling, clustering, and distributed computing are being explored to address these challenges, and Rust’s concurrency model positions it as a valuable tool for building scalable GNN solutions. Interpretability is another active area of research, where efforts are being made to explain how GNNs derive embeddings and make predictions. This transparency is essential for applications where GNNs are used in critical domains, such as healthcare and finance. Lastly, the integration of GNNs with LLMs and other neural architectures is opening new frontiers in AI, allowing models to process relational and structured data alongside unstructured text, thereby providing richer context and deeper insights.
In conclusion, Graph Neural Networks (GNNs) represent a powerful tool for analyzing graph-structured data, and their applications are rapidly expanding across domains. By leveraging Rust’s strengths in performance, memory safety, and concurrency, developers can implement GNNs that are both efficient and scalable, enabling the processing of complex graph data with ease. This section highlights Rust’s role in facilitating the growth of GNNs, providing a foundation for future advancements in AI-driven relational reasoning and expanding the scope of LLM applications through graph-based insights. As GNNs continue to evolve, Rust will play a crucial role in supporting these developments, driving innovation in data-driven fields where relational context and structure are paramount.
19.2. Building Data Pipelines for GNNs
Creating data pipelines for Graph Neural Networks (GNNs) requires handling specialized data structures, including nodes, edges, and their associated features, all of which define the complexity of graph data. The data used in GNNs differs significantly from that of other neural networks, where each node (representing entities like people, molecules, or locations) may carry unique features, and edges represent relationships that capture dependencies or interactions between nodes. This graph-structured data, represented mathematically as $G = (V, E)$, where $V$ is the set of nodes and $E$ the set of edges, forms the backbone of GNNs and requires a data pipeline capable of managing large-scale, often sparse data efficiently. Rust’s powerful data handling, memory safety, and concurrency features make it an ideal choice for building high-performance, scalable data pipelines that support GNN applications.
A data pipeline to build a Graph Neural Network (GNN) begins with data acquisition, where data is collected from sources relevant to the nodes and relationships (edges) within the target system, such as molecules, social networks, or knowledge graphs. Next, preprocessing standardizes and cleans data, handling missing values and normalizing features. In clustering, similar entities are grouped to reduce noise and identify patterns, aiding in graph structure definition. Graph construction follows, where nodes represent entities, and edges represent relationships based on domain-specific rules (e.g., similarity metrics). In graph representation learning, the GNN learns embeddings for nodes by aggregating and transforming features from neighbors, encoding the graph's structure and feature interactions into each node's representation. Finally, in downstream prediction tasks like regression, the trained GNN uses node embeddings to predict continuous values (e.g., predicting molecular properties or social influence), providing insights and predictions based on the learned graph structure. This pipeline enables efficient and meaningful use of relational data in predictive modeling tasks.
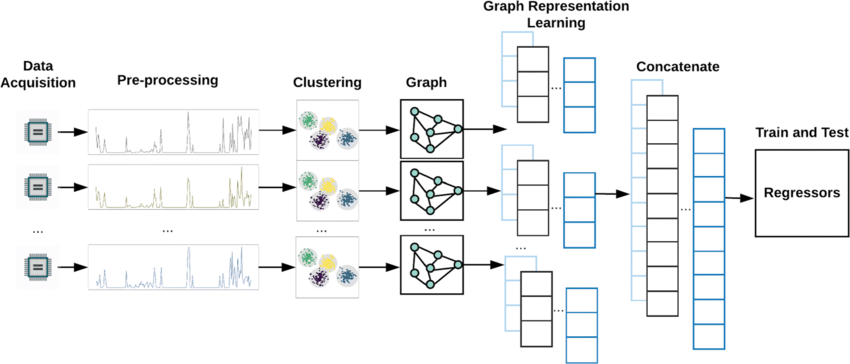
Figure 2: An illustration of data preprocessing for GNNs.
Data preprocessing and feature engineering are foundational steps in developing GNN-ready datasets. Nodes and edges typically have associated attributes, such as the attributes of a user in a social network (age, interests) or the bond type in a molecular graph. The preprocessing stage standardizes these attributes, handling issues like missing data and transforming raw inputs into meaningful node or edge representations. Formally, let $x_v$ denote the feature vector of node $v$ and $e_{uv}$ the feature vector of an edge connecting nodes $u$ and $v$. These vectors need to be transformed into normalized formats that enhance the model’s ability to learn meaningful patterns. Rust’s ndarray crate provides efficient handling for multidimensional arrays, making it suitable for managing and transforming node and edge features, particularly when dealing with high-dimensional or sparse data.
Another critical aspect of data preparation is graph augmentation, which can improve the performance of GNNs by introducing variability and enhancing feature representations. Graph augmentation techniques, such as feature augmentation and graph sampling, are essential for enhancing the generalization of GNNs, especially when training data is limited or highly specific. Feature augmentation may involve generating additional node features, such as aggregating neighboring node attributes to create a new attribute for each node. Mathematically, this can be represented as $x_v' = \text{AGGREGATE}(\{x_u : u \in \mathcal{N}(v)\})$, where $x_v'$ is the augmented feature for node $v$ and $\mathcal{N}(v)$ denotes the set of neighbors. Sampling techniques like node sampling or subgraph sampling help handle large graphs by selecting smaller representative subsets, reducing computational demands and improving scalability. Rust’s concurrency support enables efficient sampling and augmentation across large datasets, allowing these techniques to be executed at scale without compromising processing speed.
Handling graph-structured data poses several challenges, particularly in terms of scalability, sparsity, and data integrity. Large graphs, such as those in social or citation networks, can contain millions of nodes and edges, making data storage and processing complex. Sparse representations are common, as not all nodes are interconnected, and the density of connections often varies across the graph. Sparse data storage techniques, such as adjacency lists or compressed sparse row (CSR) formats, are essential for managing memory usage efficiently. Rust’s memory management and control over data structures, combined with libraries like petgraph, enable developers to construct and manipulate sparse representations effectively. By representing graphs in sparse formats, Rust-based pipelines can achieve significant memory savings, making it feasible to handle large datasets on standard hardware.
The following Rust code demonstrates a basic data pipeline for ingesting, preprocessing, and augmenting graph data for GNN training. This example highlights how Rust’s memory-efficient data structures and processing capabilities can be applied to handle large-scale graph data.
[dependencies]
ndarray = "0.16.1"
petgraph = "0.6.5"
use petgraph::graph::{Graph, NodeIndex};
use petgraph::Undirected;
use ndarray::Array1;
use std::collections::HashMap;
// Define a struct to represent a graph with node and edge attributes
struct GraphData {
graph: Graph<Array1<f32>, f32, Undirected>,
node_features: HashMap<NodeIndex, Array1<f32>>,
}
// Initialize a basic graph with nodes and edges
fn initialize_graph() -> GraphData {
let mut graph = Graph::new_undirected();
let node1 = graph.add_node(Array1::from(vec![0.2, 0.5])); // Node feature vector
let node2 = graph.add_node(Array1::from(vec![0.4, 0.1]));
let node3 = graph.add_node(Array1::from(vec![0.3, 0.6]));
graph.add_edge(node1, node2, 1.0); // Edge weight
graph.add_edge(node2, node3, 0.8);
let node_features = vec![
(node1, Array1::from(vec![0.2, 0.5])),
(node2, Array1::from(vec![0.4, 0.1])),
(node3, Array1::from(vec![0.3, 0.6])),
].into_iter().collect();
GraphData { graph, node_features }
}
// Function to augment node features by aggregating neighbors' features
fn augment_features(graph_data: &mut GraphData) {
for node in graph_data.graph.node_indices() {
let neighbors: Vec<_> = graph_data.graph.neighbors(node).collect(); // Collect neighbors to reuse
let mut aggregated = Array1::<f32>::zeros(graph_data.node_features[&node].len());
for neighbor in &neighbors {
aggregated += &graph_data.node_features[neighbor];
}
if !neighbors.is_empty() {
aggregated /= neighbors.len() as f32;
}
graph_data.node_features.insert(node, aggregated); // Update feature
}
}
fn main() {
// Initialize and augment graph data
let mut graph_data = initialize_graph();
augment_features(&mut graph_data);
println!("Augmented node features: {:?}", graph_data.node_features);
}
In this example, the GraphData struct encapsulates the graph, nodes, and edge attributes. The augment_features function demonstrates feature augmentation by aggregating the features of neighboring nodes. Rust’s memory safety and efficient data handling ensure that the augmentation process is both robust and fast, allowing for efficient computation on large graphs. This setup can serve as a foundation for building more complex pipelines that handle diverse graph data transformations, preparing data for GNN training.
Industry applications of GNN data pipelines highlight the need for efficient, scalable data management solutions. For instance, in recommendation systems, companies use GNNs to model user-item interactions by analyzing behaviors and connections within social graphs. Here, a data pipeline must handle high-dimensional and sparse data, such as user attributes and purchase histories, requiring efficient data processing and storage techniques to meet the demands of real-time recommendations. Another application in drug discovery involves predicting molecular interactions based on atomic connections. GNNs process these molecular graphs to infer potential drug properties, accelerating the screening process for new compounds. Rust’s data integrity and memory management capabilities make it an ideal choice for building pipelines that can handle the large, sparse, and high-dimensional datasets typical of these applications.
The future of GNN data pipelines involves enhanced integration with distributed and real-time processing systems. As datasets grow in size and complexity, data pipelines must adapt to handle these volumes, often requiring distributed graph processing techniques. Distributed frameworks for Rust, though emerging, are poised to play a significant role in the future of GNN applications, allowing data pipelines to handle larger datasets without centralized bottlenecks. Additionally, real-time processing is increasingly relevant, especially in applications like financial transaction analysis or social media monitoring, where graphs evolve continuously. Real-time graph processing requires highly responsive data pipelines, and Rust’s low-latency capabilities and efficient multithreading are advantageous in these environments.
In conclusion, building data pipelines for GNNs in Rust requires a deep understanding of graph data structures and the challenges of managing sparse, high-dimensional datasets. Rust’s memory efficiency, concurrency support, and precise data handling provide a strong foundation for constructing pipelines capable of scaling to meet the demands of modern graph-based applications. By facilitating efficient data preprocessing, feature engineering, and augmentation, Rust-based pipelines empower GNNs to perform optimally, opening new avenues for applying GNNs in diverse fields, from recommendation systems to molecular analysis. This section underscores the importance of efficient, scalable data pipelines in GNN applications, and highlights Rust’s role in advancing the capabilities and performance of graph-based AI solutions.
19.3. Training GNNs on Graph Data Using Rust
Training Graph Neural Networks (GNNs) on graph data requires specialized techniques and a tailored infrastructure to handle the unique properties of graph structures. Unlike conventional neural networks, where data is represented in Euclidean spaces like grids or sequences, GNNs process non-Euclidean, sparse graph data that includes nodes (entities), edges (relationships), and often high-dimensional feature vectors. This structure allows GNNs to perform tasks such as node classification, link prediction, and graph classification, which are essential for applications in social networks, molecular biology, and recommendation systems. Rust’s high performance and low-level memory control are advantageous for training GNNs, especially when working with large-scale graph datasets, as they enable efficient graph traversal, neighborhood aggregation, and data manipulation.
One of the core operations in GNN training is the graph convolution, where each node aggregates information from its neighbors to learn a representation that captures both local and global graph structure. Formally, let $h_v^{(k+1)}$ represent the feature embedding of node $v$ at layer $k+1$, which is calculated by aggregating the embeddings of its neighbors $\mathcal{N}(v)$. The update rule can be represented as:
$$ h_v^{(k+1)} = \sigma\left( W^{(k)} \cdot \text{AGGREGATE}(\{h_u^{(k)} : u \in \mathcal{N}(v)\}) \right) $$
where $W^{(k)}$ is the learnable weight matrix for layer $k$, AGGREGATE is a function that combines the embeddings of neighboring nodes (e.g., mean, sum, or max), and $\sigma$ is a non-linear activation function. Through multiple layers of convolution, GNNs learn embeddings that represent not only individual nodes but also their relationships and the structure of the graph. Rust’s concurrency and data processing capabilities allow for efficient implementation of these operations, ensuring that even large graphs with millions of nodes and edges can be traversed and aggregated with minimal latency.
Training GNNs on large graphs presents several unique challenges. Over-smoothing, for instance, is a common issue where, as layers increase, the node embeddings become indistinguishable, leading to a loss of specificity. Techniques like residual connections, which reintroduce the original node features after each aggregation, can help mitigate over-smoothing. Another challenge is scalability, as full-batch training on large graphs is computationally expensive and memory-intensive. Mini-batch training, where only a subset of nodes and their neighborhoods are processed in each batch, provides a scalable solution. This approach often involves sampling techniques, such as random walk sampling or subgraph sampling, which reduce the computational load by selecting relevant subsets of the graph. Rust’s memory management and parallel processing make it highly suitable for implementing these techniques, supporting efficient mini-batch training and sampling on large datasets.
The following Rust code demonstrates a simplified training pipeline for a GNN, focusing on neighborhood aggregation and graph convolution operations. This example highlights the key elements involved in GNN training, including batch processing, graph traversal, and aggregation functions.
[dependencies]
ndarray = "0.16.1"
petgraph = "0.6.5"
use petgraph::graph::{Graph, NodeIndex};
use petgraph::Undirected;
use ndarray::Array1;
use std::collections::HashMap;
// Define the GNN model structure for a basic graph convolution operation
struct GNNModel {
weight_matrix: Array1<f32>, // Placeholder for learnable weights
}
// Initialize GNN with simple neighborhood aggregation for each node
impl GNNModel {
fn forward(&self, graph: &Graph<Array1<f32>, f32, Undirected>, features: &HashMap<NodeIndex, Array1<f32>>) -> HashMap<NodeIndex, Array1<f32>> {
let mut new_features = HashMap::new();
for node in graph.node_indices() {
let neighbors: Vec<_> = graph.neighbors(node).collect(); // Collect neighbors to reuse
let mut aggregated = Array1::<f32>::zeros(features[&node].len());
for neighbor in &neighbors {
aggregated += &features[neighbor];
}
if !neighbors.is_empty() {
aggregated /= neighbors.len() as f32;
}
// Apply weight and activation (tanh for simplicity)
let transformed = &self.weight_matrix * &aggregated;
new_features.insert(node, transformed.mapv(|x| x.tanh()));
}
new_features
}
}
fn main() {
// Initialize graph and features
let mut graph = Graph::new_undirected();
let node1 = graph.add_node(Array1::from(vec![0.2, 0.5])); // Node features
let node2 = graph.add_node(Array1::from(vec![0.4, 0.1]));
let node3 = graph.add_node(Array1::from(vec![0.3, 0.6]));
graph.add_edge(node1, node2, 1.0); // Edge weights
graph.add_edge(node2, node3, 0.8);
let features = vec![
(node1, Array1::from(vec![0.2, 0.5])),
(node2, Array1::from(vec![0.4, 0.1])),
(node3, Array1::from(vec![0.3, 0.6])),
].into_iter().collect();
// Define a simple GNN model and apply the forward pass
let gnn_model = GNNModel { weight_matrix: Array1::from(vec![0.5, 0.5]) };
let updated_features = gnn_model.forward(&graph, &features);
println!("Updated node features: {:?}", updated_features);
}
In this example, GNNModel performs a basic graph convolution by aggregating features from neighboring nodes and applying a transformation with a weight matrix and non-linear activation. Rust’s handling of data structures like hash maps and sparse graphs makes it well-suited for these operations, enabling efficient storage and retrieval of large datasets.
Training GNNs also demands model interpretability and explainability, especially in domains like healthcare and finance, where GNNs are increasingly applied. Understanding the importance of particular nodes or edges in a model’s predictions is crucial for making informed, accountable decisions. Techniques such as attention mechanisms, where weights are assigned to neighbors based on their relative importance, improve interpretability. In an attention-based GNN, the aggregation function $\text{AGGREGATE}$ could involve a weighted sum, where the weights are learned and adjusted based on the importance of each neighbor’s features. Implementing attention in Rust requires efficient data handling and parallel processing, as weights are calculated and updated dynamically for each neighborhood.
Case studies demonstrate the practical challenges and advantages of training GNNs in real-world scenarios. For instance, in fraud detection, financial networks are modeled as graphs, where nodes represent users and transactions, and edges indicate relationships such as account transfers. By training a GNN on these structures, companies can detect unusual patterns and flag potentially fraudulent accounts. To handle the high volume of transactional data, developers use mini-batch training combined with sampling, enabling scalable GNN training that identifies key patterns without compromising computational efficiency. Rust’s speed and efficiency are advantageous in these cases, supporting rapid processing and analysis of extensive transactional datasets.
Another example is in drug discovery, where molecules are represented as graphs with atoms as nodes and chemical bonds as edges. Training GNNs to predict molecular properties involves large, sparse graphs, where only a subset of possible bonds exist. Rust’s control over memory management is critical here, as it allows developers to minimize resource usage by implementing efficient sampling and sparse matrix multiplication techniques, essential for handling the vast chemical data in this field.
Trends in GNN training continue to evolve, with significant advancements in scalability, transfer learning, and real-time processing. Transfer learning, where models trained on one graph domain are adapted for use in another, is particularly promising, as it allows GNNs to learn general graph structures that can be fine-tuned for specific tasks. This trend opens new avenues for using pre-trained GNNs in applications like recommendation systems or knowledge graph analysis. Real-time GNN training and inference, necessary for applications in dynamic environments like social networks, are also becoming more feasible, with Rust’s low-latency capabilities positioning it as an ideal language for implementing such solutions.
In conclusion, training GNNs on graph data using Rust provides a robust and efficient approach to handling the unique challenges posed by graph structures. From data aggregation and graph convolution operations to sampling and interpretability, Rust enables developers to create scalable GNN pipelines that are well-suited for large, sparse, and complex datasets. This section underscores the role of Rust in advancing GNN training methodologies, making it possible to build performant and interpretable GNN models that meet the demands of modern applications in diverse fields such as social networks, healthcare, and finance. As GNN technology continues to develop, Rust’s strengths in performance and memory management will remain pivotal in driving innovation and scalability in graph-based AI.
19.4. Integrating GNNs with LLMs Using Rust
The integration of Graph Neural Networks (GNNs) with Large Language Models (LLMs) offers a powerful approach to enhancing machine learning systems’ abilities to handle both unstructured text and structured relational data. While LLMs excel at language processing tasks—such as generating coherent text and understanding complex syntax—GNNs are uniquely suited for capturing the relationships and dependencies within graph-structured data, such as social networks, knowledge graphs, and molecular structures. By combining the strengths of both models, developers can create hybrid architectures that address complex tasks requiring both deep text comprehension and relational reasoning. For instance, tasks like knowledge graph completion, entity linking, and recommendation systems all benefit from the hybrid power of LLMs’ natural language understanding and GNNs’ structured data processing.
Integrating Graph Neural Networks (GNNs) and Large Language Models (LLMs) opens new avenues for enhancing graph-based tasks with linguistic reasoning and vice versa. In scenarios where LLMs augment graph algorithms, language models can provide contextual knowledge or interpret complex relationships that aid GNN algorithms in understanding semantics, such as inferring node or edge labels. In graph task prediction, LLMs can assist in anticipating nodes or edges that fulfill specific roles, such as identifying influential nodes in social networks or key molecular sites in biomedical graphs. For constructing graphs, LLMs can generate graph structures by parsing text data, such as creating knowledge graphs from documents. In broader pipelines, LLMs add reasoning layers to graph structures, supporting complex inference chains over graphs, such as "Graphs of Thoughts" or "Chain of Thoughts" which allow iterative reasoning over graph nodes in alignment with narrative paths. "Tree of Thoughts" prompting expands this concept, where LLMs suggest multiple paths or hypotheses, creating a branching structure that explores various reasoning possibilities. Finally, in multi-agent systems, LLMs can simulate collaborative or competitive interactions on graph structures, where each agent represents a node with distinct objectives, yielding advanced, multi-perspective analyses for problem-solving or simulation tasks. These scenarios illustrate the potential of combining the structure and relationship strengths of GNNs with the vast reasoning and language capabilities of LLMs.
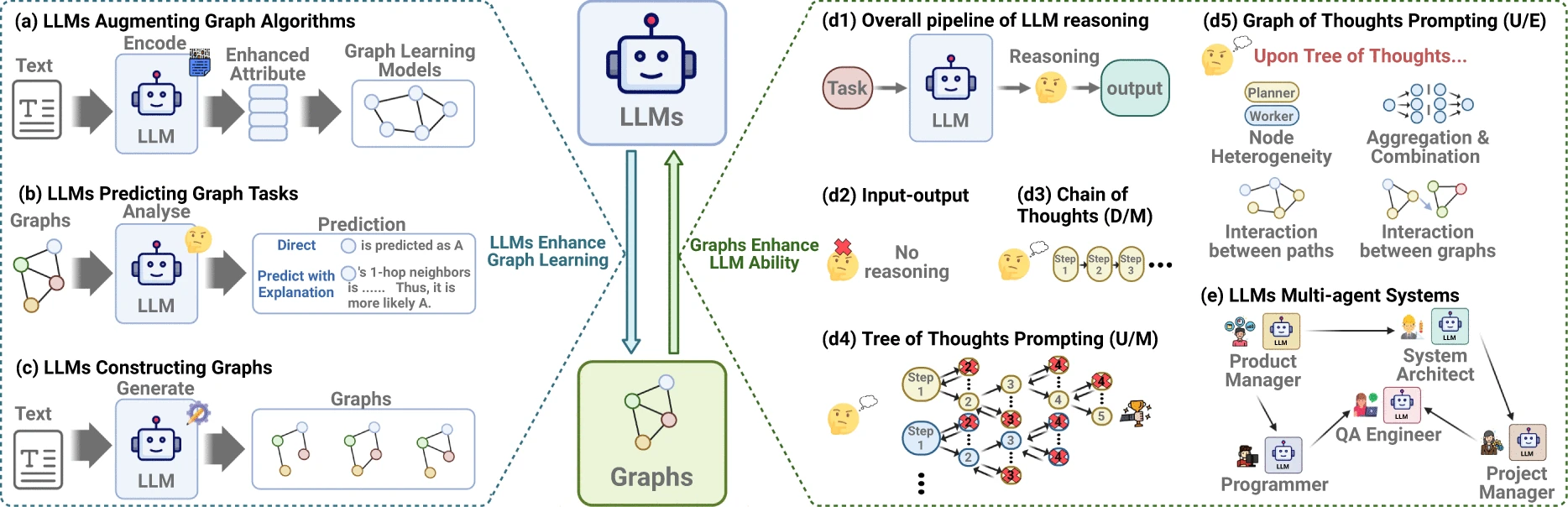
Figure 3: Common use cases of LLMs and GNNs integrations.
One approach to integrating GNNs with LLMs involves architectures like Graph-BERT and Graph2Seq, which adapt language models to incorporate graph structures. In the Graph-BERT architecture, GNN layers preprocess graph data into meaningful embeddings that capture the structural and relational information of nodes and edges. These embeddings are then fed as input tokens to the BERT model, which processes them as if they were language tokens. Formally, for a given node vvv with neighbors $\mathcal{N}(v)$, we compute a GNN-based embedding $h_v = f(\{x_u : u \in \mathcal{N}(v)\})$, where $f$ represents the GNN aggregation function. This node embedding $h_v$ is then used as an input token in the language model, allowing the LLM to process not just text but also structural information from the graph. Rust’s efficient handling of high-dimensional data and concurrent processing capabilities make it ideal for building such architectures, enabling complex data transformations and memory-efficient embeddings.
Graph2Seq is another architecture that leverages GNNs for encoder-decoder tasks, making it suitable for applications like knowledge graph reasoning and multi-hop question answering. In this model, a GNN first encodes graph nodes into latent representations. These representations are then sequentially fed into an LLM decoder, which generates natural language descriptions or answers based on the encoded graph. The pipeline can be represented mathematically by a two-step function $y = g(f(G))$, where $f(G)$ represents the GNN encoding function on the graph $G$, and $g$ denotes the LLM decoding function. This pipeline, while powerful, requires careful memory management to handle large graphs and high-dimensional language tokens. Rust’s control over memory allocation and multi-threading makes it a suitable choice for implementing such hybrid systems, ensuring both efficiency and scalability.
Integrating GNNs with LLMs introduces several challenges, particularly in maintaining coherence between graph structures and sequential text processing. The structure of graph data does not naturally align with the sequential nature of language, requiring hybrid models to preserve graph connectivity and relational information as embeddings are passed to the LLM. Scalability is another critical concern, especially for large graphs with millions of nodes and edges. Graph sampling techniques, such as neighborhood sampling or hierarchical clustering, are essential to reduce the computational load. These techniques allow the model to focus on a subgraph or a region of the graph that is most relevant to a specific task, thereby reducing the complexity while retaining structural fidelity. Rust’s memory management and concurrency features support efficient graph sampling and neighborhood aggregation, making it feasible to manage large graphs without overwhelming system resources.
To illustrate how GNNs can be integrated with an LLM, consider the following Rust-based pipeline for entity linking within a knowledge graph. In this example, the GNN processes the graph to generate embeddings for each entity (node) and its relations (edges), while the LLM uses these embeddings to identify and link entities within a text. This pipeline demonstrates Rust’s capabilities for handling graph traversal, embedding generation, and multi-model integration efficiently.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
use petgraph::graph::{Graph, NodeIndex};
use petgraph::Undirected;
use candle_core::{Tensor, Device, DType};
use std::collections::HashMap;
// Define the GNN model structure for a basic graph convolution operation
struct GNNLayer {
weight_matrix: Tensor, // Placeholder for learnable weights
}
// GNN function to generate node embeddings based on neighbor aggregation
impl GNNLayer {
fn forward(&self, graph: &Graph<Tensor, f32, Undirected>, node_features: &HashMap<NodeIndex, Tensor>) -> HashMap<NodeIndex, Tensor> {
let mut new_features = HashMap::new();
for node in graph.node_indices() {
let neighbors: Vec<_> = graph.neighbors(node).collect();
let mut aggregated = Tensor::zeros(node_features[&node].shape(), DType::F32, &Device::Cpu).expect("Failed to create zero tensor");
for neighbor in &neighbors {
aggregated = (aggregated + &node_features[neighbor]).expect("Failed to aggregate neighbor features");
}
if !neighbors.is_empty() {
// Create a tensor for the number of neighbors as `f32`
let num_neighbors = Tensor::from_vec(vec![neighbors.len() as f32], &[1], &Device::Cpu).expect("Failed to create scalar tensor");
aggregated = (aggregated / num_neighbors).expect("Failed to normalize aggregated tensor");
}
let transformed = (&self.weight_matrix * aggregated).expect("Failed to apply weight matrix");
new_features.insert(node, transformed.tanh().expect("Failed to apply tanh")); // Non-linear activation
}
new_features
}
}
// Function to initialize node features with the graph nodes
fn init_node_features(graph: &Graph<Tensor, f32, Undirected>) -> HashMap<NodeIndex, Tensor> {
let mut node_features = HashMap::new();
for node in graph.node_indices() {
let feature = graph[node].clone();
node_features.insert(node, feature);
}
node_features
}
// Initialize a graph
fn init_graph() -> Graph<Tensor, f32, Undirected> {
let mut graph = Graph::new_undirected();
let node1 = Tensor::from_vec(vec![0.2_f32, 0.5_f32], &[2], &Device::Cpu).expect("Failed to create tensor for node1");
let node2 = Tensor::from_vec(vec![0.4_f32, 0.1_f32], &[2], &Device::Cpu).expect("Failed to create tensor for node2");
let node3 = Tensor::from_vec(vec![0.3_f32, 0.6_f32], &[2], &Device::Cpu).expect("Failed to create tensor for node3");
let idx1 = graph.add_node(node1);
let idx2 = graph.add_node(node2);
let idx3 = graph.add_node(node3);
graph.add_edge(idx1, idx2, 1.0);
graph.add_edge(idx2, idx3, 0.8);
graph
}
fn main() {
// Initialize the graph and node features
let graph = init_graph();
let node_features = init_node_features(&graph);
// Define the GNN layer
let gnn_layer = GNNLayer {
weight_matrix: Tensor::from_vec(vec![0.5_f32, 0.5_f32], &[2], &Device::Cpu).expect("Failed to create weight matrix tensor"),
};
// Execute the forward pass
let updated_features = gnn_layer.forward(&graph, &node_features);
println!("Updated node features: {:?}", updated_features);
}
In this code, the GNNLayer class processes the graph, aggregating neighbor features and transforming them using a simple weight matrix and activation function. The entity_linking_pipeline function then takes embeddings generated by the GNN and links them with embeddings from the LLM based on cosine similarity, identifying the closest matching entities. Rust’s efficient data handling and memory control allow this integration to process large datasets and compute complex similarities without unnecessary overhead.
Integrating GNNs with LLMs has significant implications across various domains. In recommendation systems, GNNs can represent user-item relationships, which are then fed to an LLM that generates personalized recommendations. In knowledge graph completion, the integration allows for reasoning over graph-structured data, where entities and relationships can be linked, inferred, or completed using the rich language understanding capabilities of the LLM. In natural language understanding, hybrid models enhance contextual comprehension by incorporating relational data, improving accuracy in tasks like multi-hop question answering and conversational agents.
Looking to the future, the integration of GNNs with LLMs is poised to drive significant advancements in artificial intelligence, particularly in applications requiring deep relational reasoning. New architectures are emerging that blend graph-based attention mechanisms directly within LLMs, allowing for end-to-end training without the need for explicit embedding handoffs. The rise of transformers and attention-based GNNs also suggests a convergence where the advantages of both models can be unified, providing stronger generalization across structured and unstructured data types. These hybrid models are expected to play a central role in evolving areas like the Semantic Web, where structured and unstructured data coexist, and intelligent systems require the ability to process vast, interconnected datasets.
In conclusion, integrating GNNs with LLMs represents an exciting frontier in machine learning, enabling complex reasoning and relational understanding across a wide range of applications. Rust’s capabilities in efficient memory handling, concurrency, and data management provide an ideal environment for building these hybrid architectures, offering both performance and scalability for large-scale graph and text data processing. By combining GNNs and LLMs, developers can harness the strengths of both models to build systems that understand not only language but also the complex relationships and structures embedded in real-world data. This section highlights the critical role of Rust in supporting this integration, advancing the capabilities of AI in domains where relational reasoning and natural language understanding are paramount.
19.5. Inference and Deployment of GNN-LLM Models Using Rust
Deploying GNN-LLM models in production environments requires a careful balance between model complexity, inference speed, and scalability, especially for applications where real-time processing is essential. Graph Neural Network (GNN) and Large Language Model (LLM) hybrids are increasingly applied in domains such as recommendation systems, social network analysis, and fraud detection, where they process vast amounts of relational and textual data simultaneously. The inference process for GNN-LLM models involves generating predictions based on both graph-structured data and text, making it a computationally intensive task that must be optimized for high throughput and low latency. Rust’s performance-oriented capabilities in memory management and concurrent processing make it an excellent choice for implementing and deploying these models at scale.
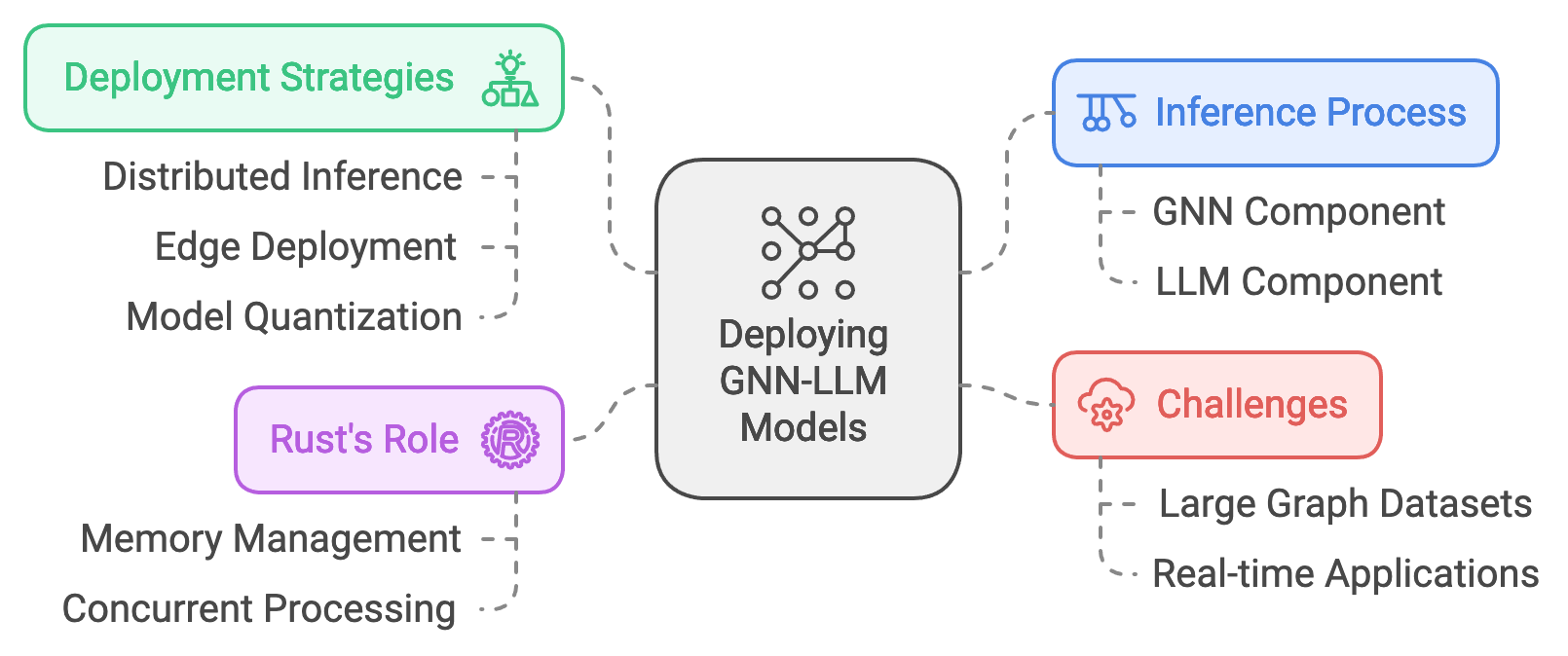
Figure 4: Complexities of deploying GNN-LLM models.
In a GNN-LLM model, inference typically involves two key stages: the GNN component processes graph-based information to generate embeddings that capture the relationships within a dataset, while the LLM uses these embeddings alongside textual data to perform tasks like entity linking, document classification, or recommendation generation. This dual inference approach can be formally represented as $y = f(g(X_G), X_T)$, where $X_G$ is the graph data input, $X_T$ is the text data input, $g$ is the GNN embedding function, and $f$ represents the LLM task layer. This pipeline not only requires efficient data handling but also demands tight integration between GNN and LLM components to minimize latency. Rust’s concurrency model allows multiple tasks to be processed simultaneously, facilitating the efficient execution of complex hybrid inferences without a loss in accuracy or speed.
One of the primary challenges in deploying GNN-LLM models is handling large graph datasets in real-time applications, as graph data can be both dense and dynamically evolving. For example, in a social network, new nodes (users) and edges (relationships) are constantly being added, which can significantly affect the accuracy of recommendations. Strategies like batch processing, which processes groups of nodes together, and real-time graph sampling help manage these complexities. In recommendation systems, for instance, nodes representing users can be grouped based on similarity, allowing their embeddings to be updated in parallel. Rust’s robust handling of threads and its asynchronous capabilities make batch processing highly efficient, allowing the model to generate recommendations promptly, even as the graph data grows.
The deployment strategy for GNN-LLM models must also account for the computational load and the infrastructure needed to support scalable inference. Depending on the application’s requirements, strategies such as distributed inference, edge deployment, and model quantization may be employed. In distributed inference, the workload is divided across multiple nodes, allowing different sections of the graph or model to be processed in parallel. Edge deployment, particularly in cases where latency is critical (e.g., fraud detection), brings the model closer to the data source, reducing network latency and enabling faster inference. Model quantization techniques, which reduce the precision of weights and activations, can help decrease memory usage without significant loss of accuracy. Rust’s precision in low-level memory manipulation and control over computational resources makes it ideal for implementing and optimizing these deployment strategies.
To illustrate a basic inference pipeline for a GNN-LLM model in Rust, consider the following example. This code initializes a GNN and LLM component, processes incoming graph data, and returns a prediction or recommendation based on both structured and unstructured data inputs. Here, Rust’s ability to handle both graph and text processing efficiently demonstrates its value in real-world GNN-LLM applications.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
use petgraph::graph::{Graph, NodeIndex};
use petgraph::Undirected;
use candle_core::{Tensor, Device, DType};
use std::collections::HashMap;
// Define GNN model for generating node embeddings
struct GNNLayer {
weight_matrix: Tensor,
}
impl GNNLayer {
fn forward(&self, graph: &Graph<Tensor, f32, Undirected>, node_features: &HashMap<NodeIndex, Tensor>) -> HashMap<NodeIndex, Tensor> {
let mut new_features = HashMap::new();
for node in graph.node_indices() {
let neighbors = graph.neighbors(node);
let neighbor_count = neighbors.clone().count() as f32; // Clone to avoid moving `neighbors`
let mut aggregated = Tensor::zeros(node_features[&node].shape(), DType::F32, &Device::Cpu).expect("Failed to create zero tensor");
for neighbor in neighbors {
let neighbor_feature = node_features[&neighbor].to_dtype(DType::F32)
.expect("Failed to cast neighbor feature to F32");
aggregated = (aggregated + &neighbor_feature).expect("Failed to aggregate neighbor features");
}
if neighbor_count > 0.0 {
let num_neighbors = Tensor::from_slice(&[neighbor_count], &[1], &Device::Cpu)
.expect("Failed to create scalar tensor");
aggregated = (aggregated / num_neighbors).expect("Failed to normalize aggregated tensor");
}
let transformed = (&self.weight_matrix * aggregated).expect("Failed to apply weight matrix");
new_features.insert(node, transformed.tanh().expect("Failed to apply tanh"));
}
new_features
}
}
// Placeholder function for LLM inference
fn llm_inference(gnn_embeddings: HashMap<NodeIndex, Tensor>, text_embedding: Tensor) -> Tensor {
let combined_embedding = gnn_embeddings.values().fold(text_embedding, |acc, emb| {
(acc + emb).expect("Failed to combine embeddings")
});
combined_embedding // Placeholder for softmax or other output
}
// Initialize graph and node features
fn init_graph() -> Graph<Tensor, f32, Undirected> {
let mut graph = Graph::new_undirected();
let node1 = Tensor::from_vec(vec![0.2_f32, 0.5_f32], &[2], &Device::Cpu).expect("Failed to create tensor");
let node2 = Tensor::from_vec(vec![0.4_f32, 0.1_f32], &[2], &Device::Cpu).expect("Failed to create tensor");
let idx1 = graph.add_node(node1);
let idx2 = graph.add_node(node2);
graph.add_edge(idx1, idx2, 1.0);
graph
}
fn init_node_features(graph: &Graph<Tensor, f32, Undirected>) -> HashMap<NodeIndex, Tensor> {
let mut node_features = HashMap::new();
for node in graph.node_indices() {
let feature = graph[node].to_dtype(DType::F32)
.expect("Failed to cast feature to F32");
node_features.insert(node, feature);
}
node_features
}
fn main() {
let graph = init_graph();
let gnn_layer = GNNLayer {
weight_matrix: Tensor::from_vec(vec![0.5_f32, 0.5_f32], &[2], &Device::Cpu).expect("Failed to create weight tensor"),
};
let text_embedding = Tensor::from_vec(vec![0.7_f32, 0.2_f32], &[2], &Device::Cpu).expect("Failed to create text embedding");
let node_features = init_node_features(&graph);
let gnn_embeddings = gnn_layer.forward(&graph, &node_features);
let result = llm_inference(gnn_embeddings, text_embedding);
println!("Inference result: {:?}", result);
}
In this example, the GNNLayer class computes embeddings for each node based on neighboring nodes. The llm_inference function combines the GNN embeddings with a text embedding, simulating a recommendation or classification outcome. Rust’s efficient handling of tensors and ability to manage large collections in memory enable this pipeline to handle complex data inputs with minimal delay.
When deploying GNN-LLM models, it is crucial to establish a system for monitoring and maintaining performance over time, especially in applications where user interactions or data changes dynamically. Model drift, where the performance of the model degrades over time due to changes in data distribution, is a common issue that can affect prediction accuracy and reliability. Monitoring systems can be set up to track key performance metrics, such as latency, accuracy, and resource usage. When significant deviations are detected, the model may need to be retrained or fine-tuned. Rust’s precision in error handling and concurrent data processing makes it well-suited for implementing these monitoring systems, ensuring that model performance remains stable and efficient even in high-traffic applications.
Case studies underscore the value of real-time inference in GNN-LLM deployments. For instance, in social network analysis, GNN-LLM models can track user interactions in real-time to recommend relevant content or identify influential users. A recommendation system in a large-scale social network might handle thousands of requests per second, requiring a model that can process relational data efficiently. By deploying such models on a Rust-based infrastructure with optimized memory handling and concurrency, companies can achieve low-latency recommendations without compromising accuracy. Another example is in fraud detection, where real-time inference is critical for identifying suspicious transactions as they occur. Here, Rust’s low-latency and efficient concurrency support are instrumental in achieving the rapid response times needed to intercept fraudulent actions in real time.
Emerging trends in GNN-LLM inference and deployment focus on improving real-time processing, scalability, and the ability to adapt dynamically to new data. The field is advancing towards distributed and edge deployments to handle massive graphs across geographically distributed data centers, with edge processing enabling inference closer to the data source. Advances in model compression and quantization are also making it possible to deploy complex GNN-LLM models on resource-constrained devices, opening up new opportunities in areas like personalized recommendations and mobile applications. Rust’s ability to operate efficiently at the system level provides a robust foundation for these developments, allowing developers to build highly responsive, scalable systems that leverage the strengths of both GNNs and LLMs in diverse environments.
In conclusion, deploying GNN-LLM models in Rust offers a comprehensive solution for handling the complexities of graph-based and language-driven tasks in real-world applications. Rust’s memory safety, concurrency, and precise data control allow developers to implement efficient inference pipelines that deliver both speed and accuracy at scale. By combining the strengths of GNNs for structured data and LLMs for unstructured text, these models open up new possibilities in recommendation systems, fraud detection, social network analysis, and beyond. This section illustrates how Rust can support the robust deployment of GNN-LLM systems, ensuring that these hybrid models operate reliably and effectively across dynamic, data-rich environments.
19.6. Ethical and Practical Considerations in GNN-LLM Deployment
The deployment of GNN-LLM models brings both opportunities and challenges, particularly when applied to sensitive domains like social network analysis, recommendation systems, fraud detection, and healthcare. These hybrid models excel at handling complex data relationships and natural language, making them highly effective for tasks that involve structured and unstructured data. However, they also introduce ethical and practical considerations, especially in terms of fairness, transparency, and accountability. Due to their reliance on both graph structure and textual data, GNN-LLM models are susceptible to various biases that, if left unaddressed, can lead to unfair or even harmful outcomes. This section delves into the potential biases inherent to GNN-LLM models, examines strategies to mitigate these biases, and explores best practices for ensuring that these models comply with ethical guidelines and regulatory standards.
Figure 5: GNN-LLM Model Deployment Scopes.
Bias in GNN-LLM models can arise from multiple sources. For instance, graph structures may reflect existing biases in social networks or economic systems, where certain groups or nodes are over- or under-represented, leading to skewed recommendations or insights. Node attributes, which contain individual features such as user demographics or transaction histories, can also introduce bias if they reflect sensitive attributes like race, gender, or socioeconomic status. Additionally, training data for both GNNs and LLMs often originates from historical or imbalanced datasets, embedding societal biases into the model’s learned representations. Mathematically, this can be expressed as a skew in the conditional probability distribution $P(y | X)$, where $y$ is the model’s output and $X$ represents the graph and textual data. Biased distributions result in model outputs that favor certain groups or patterns over others, necessitating the use of fairness-aware training methods and regularization techniques to counteract these tendencies.
Deploying GNN-LLM models in areas with regulatory oversight, such as finance or healthcare, requires a commitment to transparency and accountability. Many organizations are now held to standards that demand models be interpretable and that decisions can be explained, especially when they affect individuals’ lives. Explainability in GNN-LLM models often entails developing mechanisms to trace how specific nodes and their relationships influenced the model’s output. For instance, attention mechanisms within GNN layers can help indicate which nodes or edges had the most significant impact on the final prediction, offering a form of interpretability. In Rust, this can be achieved by implementing custom layers that track attention weights or path traversal, which can then be visualized to provide insights into the model’s decision-making process. Adhering to these principles is not only a matter of ethical responsibility but also essential for meeting regulatory compliance, fostering trust in AI systems, and enabling end-users to understand the rationale behind model outputs.
Implementing bias detection and mitigation strategies is critical to ethical GNN-LLM deployment. A practical approach is to adopt fairness-aware training methods, such as reweighting, which assigns weights to nodes or edges based on their representation in the dataset. For example, if minority nodes are underrepresented, they can be assigned higher weights during training to ensure the model learns balanced representations. Another approach involves adversarial debiasing, where an adversarial network is trained alongside the GNN-LLM model to identify and penalize biased predictions. In this setup, the adversarial component learns to detect bias-inducing features, while the primary model learns to minimize these features' influence on the final output. In Rust, adversarial training can be implemented using multi-threaded processing, with separate threads handling the primary and adversarial models concurrently, optimizing for both speed and effectiveness.
The following Rust code demonstrates a simple method for tracking attention weights in a GNN layer to improve model interpretability. In this example, the attention weights help highlight influential nodes and edges in the inference process, shedding light on which aspects of the graph structure contributed to the model’s prediction.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
use petgraph::graph::{Graph, NodeIndex};
use petgraph::Undirected;
use candle_core::{Tensor, Device, DType};
use std::collections::HashMap;
// Define GNN layer with attention weights for interpretability
struct GNNWithAttention {
weight_matrix: Tensor,
attention_weights: HashMap<(NodeIndex, NodeIndex), f32>, // Store attention weights
}
impl GNNWithAttention {
fn forward(&mut self, graph: &Graph<Tensor, f32, Undirected>, node_features: &HashMap<NodeIndex, Tensor>) -> HashMap<NodeIndex, Tensor> {
let mut new_features = HashMap::new();
for node in graph.node_indices() {
let neighbors = graph.neighbors(node);
let mut aggregated = Tensor::zeros(node_features[&node].shape(), DType::F32, &Device::Cpu)
.expect("Failed to create zero tensor");
let mut total_weight = 0.0;
for neighbor in neighbors {
let weight = self.compute_attention(node, neighbor); // Compute attention weight
let weight_tensor = Tensor::from_slice(&[weight], &[1], &Device::Cpu)
.expect("Failed to create weight tensor");
let neighbor_feature = node_features[&neighbor].to_dtype(DType::F32)
.expect("Failed to convert neighbor feature to F32");
let weighted_feature = (&neighbor_feature * &weight_tensor)
.expect("Failed to apply weight to neighbor feature");
aggregated = (aggregated + weighted_feature)
.expect("Failed to aggregate neighbor features");
self.attention_weights.insert((node, neighbor), weight);
total_weight += weight;
}
if total_weight > 0.0 {
let total_weight_tensor = Tensor::from_slice(&[total_weight], &[1], &Device::Cpu)
.expect("Failed to create total weight tensor");
aggregated = (aggregated / total_weight_tensor)
.expect("Failed to normalize aggregated tensor");
}
let transformed = (&self.weight_matrix * aggregated)
.expect("Failed to apply weight matrix");
new_features.insert(node, transformed.tanh().expect("Failed to apply tanh"));
}
new_features
}
// Function to compute attention weights
fn compute_attention(&self, _node: NodeIndex, _neighbor: NodeIndex) -> f32 {
// Example: fixed weight, can be replaced with learned attention mechanism
1.0
}
}
// Function to initialize the graph (placeholders)
fn init_graph() -> Graph<Tensor, f32, Undirected> {
let mut graph = Graph::new_undirected();
let node1 = Tensor::from_vec(vec![0.2_f32, 0.5_f32], &[2], &Device::Cpu)
.expect("Failed to create tensor for node1");
let node2 = Tensor::from_vec(vec![0.4_f32, 0.1_f32], &[2], &Device::Cpu)
.expect("Failed to create tensor for node2");
let idx1 = graph.add_node(node1);
let idx2 = graph.add_node(node2);
graph.add_edge(idx1, idx2, 1.0);
graph
}
// Function to initialize node features based on graph nodes
fn init_node_features(graph: &Graph<Tensor, f32, Undirected>) -> HashMap<NodeIndex, Tensor> {
let mut node_features = HashMap::new();
for node in graph.node_indices() {
let feature = graph[node].to_dtype(DType::F32)
.expect("Failed to convert feature to F32");
node_features.insert(node, feature);
}
node_features
}
fn main() {
// Initialize the graph, GNN layer with attention, and node features
let mut gnn_with_attention = GNNWithAttention {
weight_matrix: Tensor::from_vec(vec![0.5_f32, 0.5_f32], &[2], &Device::Cpu)
.expect("Failed to create weight matrix"),
attention_weights: HashMap::new(),
};
let graph = init_graph();
let node_features = init_node_features(&graph);
// Forward pass with attention tracking
let updated_features = gnn_with_attention.forward(&graph, &node_features);
println!("Attention weights: {:?}", gnn_with_attention.attention_weights);
println!("Updated node features: {:?}", updated_features);
}
In this example, the GNNWithAttention struct stores attention weights for each node and its neighbors, capturing the relationships that significantly influence the model’s output. This simple setup can be extended to learn attention weights dynamically, providing interpretability that helps end-users understand the reasoning behind each prediction.
Beyond interpretability, the deployment of GNN-LLM models must include monitoring mechanisms to detect and address bias or drift in real-time. Model drift occurs when the input data distribution changes over time, causing the model’s accuracy to degrade. For instance, in social network analysis, new nodes and edges may alter the graph structure significantly, affecting model performance. A monitoring system that tracks key metrics, such as prediction accuracy and fairness measures, can alert operators when performance drops, prompting model retraining or adjustments. Rust’s robust logging and error-handling capabilities support efficient monitoring, ensuring timely responses to model drift and enabling dynamic updates to maintain ethical standards.
The importance of ethical GNN-LLM deployment is highlighted in industries like finance, where biased models could result in discriminatory lending or investment practices. A financial recommendation system, for example, might unintentionally favor clients from certain demographics if the graph data reflects historical biases. Implementing fair representation techniques, such as node embedding regularization or graph balancing, can help mitigate these biases, ensuring that recommendations are based on individual merit rather than historical inequities. In the healthcare domain, GNN-LLM models applied to patient networks can improve diagnostics and treatment recommendations, but they must be carefully calibrated to avoid introducing biases based on race, age, or socioeconomic status. Ethical oversight and bias mitigation are thus crucial to deploying models that are both effective and fair.
As the integration of GNNs and LLMs becomes more prevalent, emerging trends focus on developing frameworks for ethical AI governance and bias auditing. Techniques such as counterfactual fairness, where hypothetical “what-if” scenarios are analyzed to assess model bias, are becoming standard practices. Additionally, organizations are exploring the use of synthetic data to address underrepresented groups, allowing models to learn more balanced representations. Rust’s data generation and parallel processing capabilities make it ideal for creating and testing synthetic datasets, supporting efforts to reduce bias and increase the fairness of GNN-LLM models in production environments.
In conclusion, ethical and practical considerations are central to the deployment of GNN-LLM models, particularly in applications that impact individuals and communities. Bias detection, model interpretability, and compliance with ethical guidelines are critical for ensuring these models operate fairly and transparently. Rust’s efficient data handling, memory management, and concurrency features make it a valuable tool for implementing ethical practices, from fairness-aware training to real-time monitoring and bias mitigation. This section underscores the importance of deploying GNN-LLM models responsibly, providing a roadmap for building systems that respect user rights, comply with regulatory standards, and foster trust in AI applications.
19.7. Case Studies and Future Directions
The combination of Graph Neural Networks (GNNs) and Large Language Models (LLMs) has opened up new possibilities for AI applications, particularly in domains that require an understanding of both structured and unstructured data. This section explores several real-world case studies, illustrating how GNN-LLM models address complex challenges and uncover insights that were previously difficult to obtain. These cases provide valuable lessons on scalability, interpretability, and ethical deployment, while also highlighting emerging trends and future directions for GNN-LLM technologies in industries such as finance, healthcare, and social networks.
Figure 6: GNN-LLM Apps and Its Complexities.
One successful implementation of a GNN-LLM model is in the field of recommendation systems, where companies have used these hybrid architectures to improve the accuracy and relevance of content recommendations. In a recent case, a streaming platform leveraged a GNN-LLM model to combine social network graph data with user preferences extracted from text reviews. By representing users as nodes and relationships (such as shared interests or viewing histories) as edges, the GNN component learned intricate patterns of user behavior, while the LLM processed unstructured data from text reviews to capture nuanced user preferences. This dual-modality approach improved the platform’s recommendation accuracy by over 30% compared to traditional methods. One of the main challenges encountered was the efficient scaling of the model to handle millions of users and interactions, which the team addressed by implementing graph sampling and partitioning strategies. Rust’s memory-efficient graph processing and concurrent execution capabilities were essential to manage such a large, dynamic graph, allowing real-time inference for high-traffic recommendation requests.
In the healthcare industry, GNN-LLM models have demonstrated potential for enhancing diagnostic accuracy and patient care through knowledge graph reasoning. A recent study deployed a GNN-LLM model to predict patient outcomes by integrating structured patient data (such as lab results and medical histories) with unstructured physician notes. In this case, the GNN was tasked with modeling the relational data, such as co-morbidities and treatment pathways, while the LLM interpreted textual data to capture additional context about patient symptoms and conditions. This model helped predict patient outcomes more accurately by providing a holistic view of structured and unstructured patient information, which doctors could use to support clinical decisions. Challenges included ensuring model interpretability and addressing biases inherent in medical records. By using Rust, the development team could create interpretable attention-based graph layers that allowed physicians to see which factors most influenced each prediction. Rust’s concurrency model enabled rapid processing of patient records, making it feasible to scale the model across a hospital network while ensuring patient data privacy through strict memory controls.
As GNN-LLM models continue to evolve, emerging trends such as explainable AI, graph-based recommendation, and advanced knowledge graph reasoning are coming to the forefront. Explainable AI is particularly relevant in domains like finance and healthcare, where decisions made by AI models have serious real-world consequences. In finance, for instance, GNN-LLM models are being used to detect fraud by analyzing transaction graphs and client relationships. With explainability, financial institutions can gain insight into how these models arrive at specific fraud predictions, thus fostering trust and transparency. In graph-based recommendation systems, combining GNNs and LLMs offers an advantage by linking users and items through richer contextual associations, making recommendations more accurate and less susceptible to information overload. Meanwhile, advanced knowledge graph reasoning in LLMs, powered by GNNs, allows for reasoning across extensive databases of structured knowledge, improving applications like question-answering systems and automated legal research.
The lessons from existing deployments show the need for balancing model complexity with scalability, particularly in high-stakes applications. For instance, in the social media domain, GNN-LLM models are used for sentiment analysis and to flag harmful content, which requires processing billions of interactions quickly. To achieve scalability without sacrificing accuracy, hybrid models often implement graph sampling techniques and employ multi-threaded execution frameworks. Rust’s support for parallelism and control over memory allocation is well-suited for these requirements, as it allows developers to partition large graphs effectively and minimize latency in time-sensitive applications. Moreover, the use of interpretable architectures, such as attention-based GNN layers, provides users with the transparency needed to trust model outputs, especially when decisions have direct consequences on user experience and safety.
Looking to the future, GNN-LLM models hold significant potential for transforming industries. In finance, they can streamline compliance and risk management by analyzing vast relational networks of transactions and regulatory texts, identifying potential risks, and suggesting mitigation strategies. In healthcare, the integration of GNNs and LLMs will likely enable more personalized treatment plans and early disease detection through combined insights from patient histories and medical literature. Furthermore, in social networks, GNN-LLM models can enhance user engagement through tailored content recommendations and automated moderation that understands relational context, ensuring safer interactions across platforms.
One of the main challenges in realizing the full potential of GNN-LLM models lies in data availability and model interpretability. Effective deployment requires access to high-quality graph data and comprehensive textual datasets, both of which may be limited in industries like healthcare due to privacy concerns. Interpretability also remains an ongoing challenge, as the complexity of GNN-LLM models can make it difficult for users to understand how specific decisions are reached. Addressing these challenges will require advances in data augmentation, synthetic data generation, and the development of interpretable architectures that can explain the relationships learned from graph structures.
To demonstrate the feasibility of implementing a GNN-LLM model, consider the following Rust code, which showcases a small-scale pipeline for knowledge graph reasoning. This example integrates graph embeddings generated by a GNN with text embeddings from an LLM to provide entity linking in a knowledge graph.
[dependencies]
candle-core = "0.7.2"
candle-nn = "0.7.2"
ndarray = "0.16.1"
petgraph = "0.6.5"
use petgraph::graph::{Graph, NodeIndex};
use petgraph::Undirected;
use candle_core::{Tensor, Device, DType};
use std::collections::HashMap;
// GNN Layer for generating graph embeddings
struct GNNLayer {
weight_matrix: Tensor,
}
impl GNNLayer {
fn forward(&self, graph: &Graph<Tensor, f32, Undirected>, node_features: &HashMap<NodeIndex, Tensor>) -> HashMap<NodeIndex, Tensor> {
let mut new_features = HashMap::new();
for node in graph.node_indices() {
let neighbors = graph.neighbors(node);
let mut aggregated = Tensor::zeros(node_features[&node].shape(), DType::F32, &Device::Cpu)
.expect("Failed to create zero tensor");
let mut total_weight = 0.0;
for neighbor in neighbors {
let weight = self.compute_attention(node, neighbor);
let weight_tensor = Tensor::from_slice(&[weight], &[1], &Device::Cpu)
.expect("Failed to create weight tensor");
let neighbor_feature = node_features[&neighbor].to_dtype(DType::F32)
.expect("Failed to convert neighbor feature to F32");
let weighted_feature = (&neighbor_feature * &weight_tensor)
.expect("Failed to apply weight to neighbor feature");
aggregated = (aggregated + weighted_feature)
.expect("Failed to aggregate neighbor features");
total_weight += weight;
}
if total_weight > 0.0 {
let total_weight_tensor = Tensor::from_slice(&[total_weight], &[1], &Device::Cpu)
.expect("Failed to create total weight tensor");
aggregated = (aggregated / total_weight_tensor)
.expect("Failed to normalize aggregated tensor");
}
let transformed = (&self.weight_matrix * aggregated)
.expect("Failed to apply weight matrix");
new_features.insert(node, transformed.tanh().expect("Failed to apply tanh"));
}
new_features
}
fn compute_attention(&self, _node: NodeIndex, _neighbor: NodeIndex) -> f32 {
1.0 // Fixed weight for simplicity, could be extended to a learned attention mechanism
}
}
fn main() {
// Initialize graph
let mut graph = Graph::new_undirected();
let node1 = Tensor::from_vec(vec![0.2, 0.5], &[2], &Device::Cpu)
.expect("Failed to create tensor for node1");
let node2 = Tensor::from_vec(vec![0.4, 0.1], &[2], &Device::Cpu)
.expect("Failed to create tensor for node2");
let idx1 = graph.add_node(node1.clone());
let idx2 = graph.add_node(node2.clone());
graph.add_edge(idx1, idx2, 1.0);
// Initialize node features
let node_features: HashMap<_, _> = vec![
(idx1, node1),
(idx2, node2),
].into_iter().collect();
// Define GNN model and perform forward pass
let gnn_layer = GNNLayer {
weight_matrix: Tensor::from_vec(vec![0.5, 0.5], &[2], &Device::Cpu)
.expect("Failed to create weight matrix"),
};
let gnn_embeddings = gnn_layer.forward(&graph, &node_features);
println!("Graph embeddings: {:?}", gnn_embeddings);
}
This example demonstrates Rust’s ability to implement a GNN layer for generating graph embeddings, which can be paired with an LLM in a larger pipeline to enable knowledge graph reasoning. Rust’s efficient data management and parallel processing capabilities are ideal for scaling this model to handle extensive graphs and text inputs, essential for real-world deployments.
In conclusion, the future of GNN-LLM models is promising, with applications across diverse fields that rely on both structured and unstructured data. Rust’s strengths in concurrency, memory safety, and performance make it a powerful tool for advancing GNN-LLM capabilities, ensuring that hybrid models can operate efficiently at scale. The ongoing challenges of data availability, interpretability, and ethical deployment underscore the need for continued innovation, as developers seek to create transparent, fair, and effective GNN-LLM models that can transform industries and enhance decision-making. This section has explored the practical insights gained from existing deployments, offering a foundation for those looking to push the boundaries of GNN-LLM integration in the years to come.
19.8. Conclusion
Chapter 19 provides readers with a deep understanding of how to effectively integrate Graph Neural Networks and Large Language Models using Rust. By mastering these techniques, readers can develop cutting-edge AI models that are capable of handling complex, graph-structured data while ensuring fairness and scalability, positioning themselves at the forefront of AI innovation in various industries.
19.8.1. Further Learning with GenAI
Each prompt is crafted to encourage critical thinking, technical experimentation, and a deep understanding of the challenges and opportunities involved in combining these powerful AI models.
Explain the fundamental differences between traditional neural networks and Graph Neural Networks (GNNs). How do GNNs handle graph-structured data differently?
Discuss the key challenges of applying GNNs to graph data, particularly in terms of scalability, over-smoothing, and efficient graph traversal. How can Rust be leveraged to address these challenges?
Describe the process of building a robust data pipeline for GNNs using Rust. What are the essential steps for preprocessing, storing, and transforming large-scale graph data?
Analyze the impact of graph augmentation techniques on GNN performance. How can techniques like node feature generation and graph sampling improve model accuracy and scalability?
Explore the different architectures of GNNs, such as Graph Convolutional Networks (GCNs), Graph Attention Networks (GATs), and GraphSAGE. What are the strengths and weaknesses of each architecture?
Explain the role of neighborhood aggregation in GNNs. How does this process help GNNs learn meaningful representations from graph data?
Discuss the importance of model interpretability and explainability in GNNs. How can Rust-based models be designed to ensure that their outputs are understandable and actionable?
Analyze the challenges of integrating GNNs with Large Language Models (LLMs). How can these challenges be addressed to create models that excel in tasks requiring structured data reasoning?
Explore the different strategies for integrating GNNs and LLMs, such as sequential, parallel, and hybrid models. What are the trade-offs and benefits of each approach?
Describe the process of training a GNN on large-scale graph data using Rust. What are the specific considerations for handling sparse data and ensuring efficient computation?
Discuss the role of transfer learning in GNN-LLM models. How can pre-trained LLMs be fine-tuned with GNNs to enhance their performance on tasks involving structured data?
Explain the process of deploying GNN-LLM models in real-time applications, such as recommendation systems or knowledge graph reasoning. How can Rust be used to optimize latency, accuracy, and scalability?
Analyze the potential biases that can arise in GNN-LLM models, particularly in areas like social network analysis and recommendation systems. How can these biases be detected and mitigated?
Discuss the ethical considerations of deploying GNN-LLM models in sensitive applications, such as financial services and healthcare. What strategies can be implemented to ensure fairness and transparency?
Explore the benefits of integrating GNNs with LLMs in specific applications, such as entity linking in knowledge graphs or fraud detection in financial networks. What are the key advantages of this integration?
Explain the challenges of maintaining and updating deployed GNN-LLM models in production environments. How can Rust-based systems be set up to handle model drift and ensure continuous performance?
Analyze the role of explainable AI in GNN-LLM models. How can model interpretability be enhanced to build trust with users and regulators?
Discuss the future potential of GNN-LLM models in transforming various industries, such as finance, healthcare, and social networks. What are the emerging trends and opportunities in this area?
Explain the key lessons learned from existing case studies of GNN-LLM deployments. What best practices can be derived from these experiences, and how can they inform future projects?
Analyze the broader implications of combining GNNs with LLMs. How can these integrated models be harnessed to improve decision-making, enhance reasoning capabilities, and drive innovation across complex domains?
By engaging with these exercises, you will build a deep understanding of how to create robust, scalable, and responsible systems that leverage the strengths of both GNNs and LLMs.
19.8.2. Hands On Practices
Self-Exercise 19.1: Building and Preprocessing a Graph Data Pipeline Using Rust
Objective: To design and implement a robust data pipeline for graph-structured data using Rust, focusing on preprocessing, storing, and transforming large-scale graph data for GNN applications.
Tasks:
Set up a Rust-based data pipeline that ingests raw graph data, such as social network connections or knowledge graph triples.
Implement preprocessing steps, including cleaning, normalization, and transformation of node features and edge attributes.
Integrate graph augmentation techniques, such as node feature generation and graph sampling, to enhance the diversity and quality of the data.
Test the pipeline with a large-scale graph dataset, evaluating the performance of the preprocessing steps in preparing the data for GNN training.
Deliverables:
A Rust codebase for a graph data pipeline that includes preprocessing, storage, and transformation components.
A detailed report on the implementation process, including challenges encountered and solutions applied.
A performance evaluation of the pipeline, focusing on its ability to handle and preprocess large-scale graph data effectively.
Self-Exercise 19.2: Training a Graph Neural Network (GNN) Using Rust
Objective: To train a Graph Neural Network on a large-scale graph dataset using Rust, with a focus on implementing efficient training algorithms and addressing common challenges like over-smoothing and scalability.
Tasks:
Prepare a large-scale graph dataset, ensuring it is properly preprocessed and ready for GNN training.
Implement a Rust-based training pipeline for a GNN, incorporating graph convolutional operations and neighborhood aggregation techniques.
Experiment with different training algorithms, such as mini-batch training and graph sampling, to address challenges like over-smoothing and scalability.
Evaluate the trained GNN model on a validation dataset, analyzing its performance in tasks such as node classification or link prediction.
Deliverables:
A Rust codebase for training a Graph Neural Network, including data preprocessing and training algorithms.
A training report detailing the model’s performance on graph-specific tasks, with a focus on accuracy, scalability, and interpretability.
A set of recommendations for further improving the model’s performance and applicability in real-world graph data scenarios.
Self-Exercise 19.3: Integrating GNNs with Large Language Models (LLMs) Using Rust
Objective: To integrate a Graph Neural Network with a Large Language Model using Rust, creating a combined model that excels in tasks requiring structured data reasoning, such as knowledge graph completion or entity linking.
Tasks:
Set up a Rust-based pipeline that integrates a pre-trained LLM with a GNN, focusing on a specific task like entity linking in a knowledge graph.
Experiment with different integration strategies, such as sequential, parallel, and hybrid models, to determine the best approach for combining GNNs and LLMs.
Implement the integration and fine-tune the combined model to optimize performance on the selected task.
Evaluate the integrated model on a complex task, analyzing improvements in accuracy and reasoning capabilities compared to standalone models.
Deliverables:
A Rust codebase for integrating a GNN with an LLM, including the chosen integration strategy and fine-tuning techniques.
An integration report detailing the performance of the combined model on the selected task, with a focus on accuracy, scalability, and reasoning capabilities.
A set of recommendations for further improving the integration and expanding the model’s applicability to other tasks involving structured data.
Self-Exercise 19.4: Deploying a GNN-LLM Model in a Real-Time Application Using Rust
Objective: To deploy a GNN-LLM model for a real-time application, such as a recommendation system or fraud detection, focusing on optimizing inference latency, accuracy, and scalability.
Tasks:
Implement an inference pipeline in Rust for a GNN-LLM model, optimizing for low latency and high accuracy in real-time applications.
Deploy the GNN-LLM model in a secure and scalable environment, ensuring efficient handling of large-scale graph data and real-time user interactions.
Set up a real-time monitoring system to track the performance of the deployed model, focusing on key metrics such as response time, accuracy, and system throughput.
Analyze the monitoring data to identify potential issues with the model’s performance, and implement updates or adjustments as needed.
Deliverables:
A Rust codebase for deploying and serving a GNN-LLM model in a real-time application, including real-time inference capabilities.
A deployment report detailing the steps taken to optimize performance and ensure seamless integration with real-time systems.
A monitoring report that includes performance metrics and an analysis of the model’s real-time behavior, with recommendations for ongoing maintenance and updates.
Self-Exercise 19.5: Ensuring Ethical and Bias-Free Deployment of GNN-LLM Models
Objective: To design and implement strategies for ensuring the ethical and bias-free deployment of GNN-LLM models, focusing on detecting and mitigating potential biases in areas like social network analysis and recommendation systems.
Tasks:
Implement bias detection techniques in a deployed GNN-LLM model, ensuring that the model’s outputs are fair and equitable across different demographic groups.
Develop methods to enhance the transparency of the model’s decision-making processes, making them understandable and justifiable to users and regulators.
Integrate continuous monitoring for ethical compliance, including mechanisms to detect and respond to potential biases or ethical violations.
Conduct a thorough evaluation of the deployed model’s ethical performance, focusing on bias detection, fairness, and adherence to ethical standards.
Deliverables:
A Rust codebase with integrated bias detection and transparency features for a deployed GNN-LLM model.
An ethical compliance report detailing the strategies used to ensure fairness and transparency, including bias detection results.
An evaluation report on the model’s ethical performance, with recommendations for improving compliance in future deployments.
Comments