Chapter 18
Creative Applications of LLMs
“Artificial intelligence is the most profound technology that humanity will ever develop and work on. But we have to be careful that we use it in ways that are aligned with our values and that allow human creativity to flourish alongside it.”\
- Sundar Pichai
Chapter 18 of LMVR explores the exciting and transformative potential of large language models (LLMs) in creative fields such as content generation, music composition, and visual art. The chapter covers the entire process, from building specialized data pipelines and training models on diverse creative datasets to deploying them in real-time, interactive environments. It emphasizes the importance of balancing creativity with coherence, originality, and ethical considerations, ensuring that LLMs contribute meaningfully to creative processes without infringing on the rights of human creators. Through practical examples, case studies, and discussions on the ethical and legal frameworks, this chapter equips readers with the knowledge to develop innovative and responsible creative applications using Rust.
18.1. Introduction to Creative Applications of LLMs
Large language models (LLMs) are emerging as transformative tools in creative fields, with applications spanning content generation, music composition, visual art, and storytelling. These models have demonstrated remarkable capabilities in generating text, lyrics, artwork concepts, and even entire musical compositions, pushing the boundaries of what AI can achieve in creative domains. Creative applications of LLMs bring unique challenges and opportunities, particularly in balancing creativity with coherence and ensuring originality in generated content. Unlike traditional applications, where outputs are typically factual or task-driven, creative applications demand novelty, stylistic variation, and engagement. Rust’s high-performance capabilities, memory safety, and concurrency support make it an ideal language for developing such applications, where fast and efficient processing of complex, multi-step generation tasks is essential. By leveraging Rust, developers can harness the full potential of LLMs to create responsive, scalable, and reliable tools that cater to the intricate demands of creative professionals and users alike.
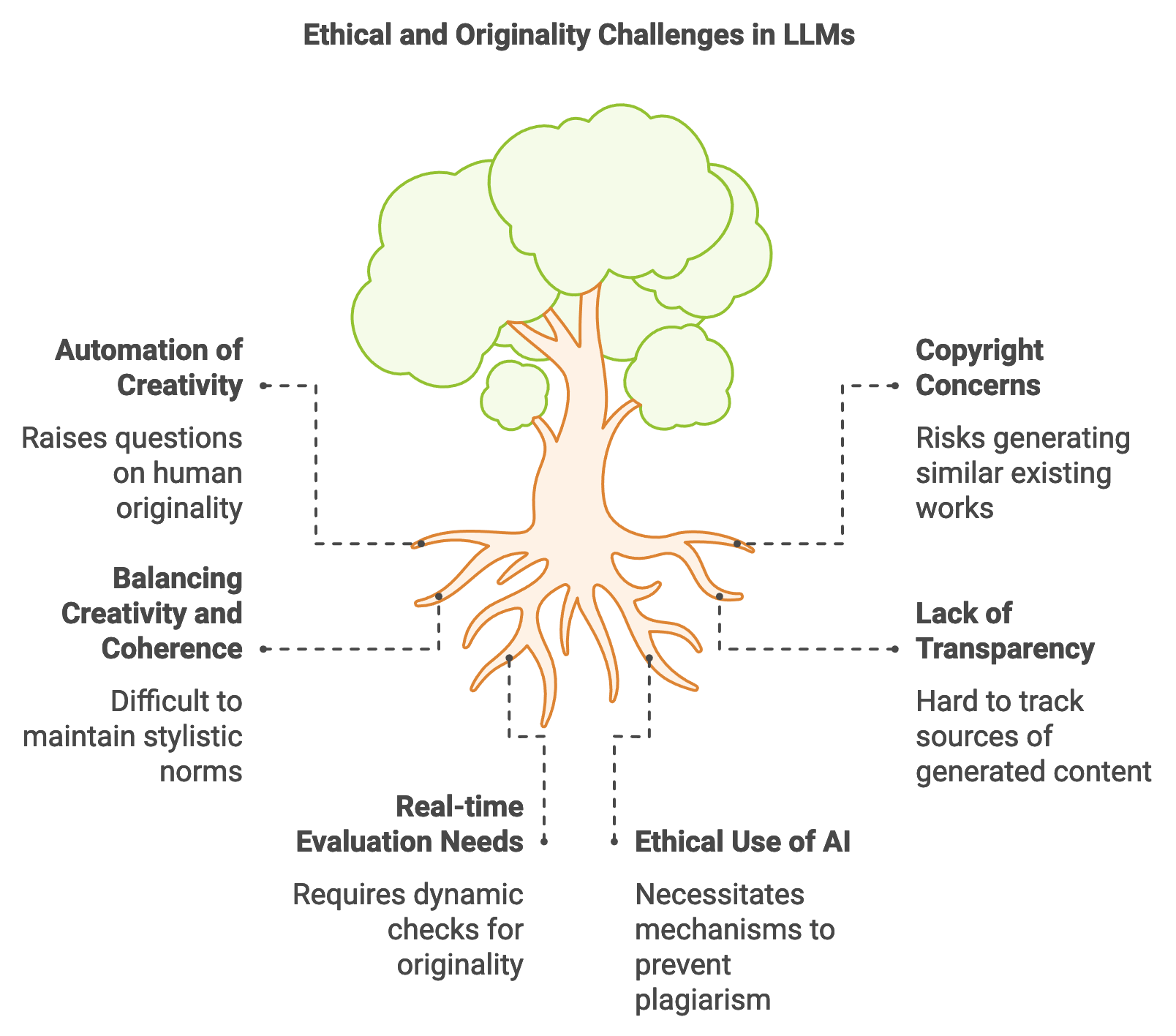
Figure 1: Key challenges in LLMs for Creative Apps.
The creative potential of LLMs lies in their ability to generate outputs that blend originality with relevance to prompts or themes. For example, in poetry generation, an LLM must balance creativity with language coherence, ensuring that generated verses adhere to stylistic norms while maintaining poetic flair. Mathematically, this balance can be modeled as optimizing a trade-off function $F(c, o)$, where $c$ denotes coherence (e.g., grammatical correctness, thematic consistency) and ooo denotes originality (e.g., lexical novelty, stylistic divergence). A high score in ccc indicates strong alignment with language rules and logical flow, while a high score in $o$ represents creative divergence. Adjusting this trade-off involves tuning model parameters and response generation algorithms to produce outputs that capture unique perspectives or styles while remaining intelligible. Rust’s fine-grained control over computational resources and efficient memory management ensures that such parameter tuning can be done dynamically, allowing for the real-time generation of creative content with variable stylistic emphasis.
In the creative industries, LLMs offer both innovative potential and disruptive challenges. They enable novel approaches to content generation and design, providing artists, musicians, and writers with new tools for ideation, collaboration, and production. For instance, LLMs can assist songwriters by generating lyric suggestions based on a theme, mood, or specific keywords, enabling artists to explore creative directions they might not have considered otherwise. Additionally, content creators can leverage story generators to brainstorm narratives or even generate preliminary drafts for longer pieces. However, the automation of creative processes raises questions about the role of human originality and the ethical implications of using AI to produce art. There are concerns about copyright, as LLMs trained on vast corpora may inadvertently generate content similar to existing works, raising issues around originality and ownership. Rust’s robust data handling and control mechanisms support ethical use by allowing developers to apply filters, track model outputs, and enforce checks for originality, helping prevent plagiarism or excessive similarity to copyrighted material.
Ethical considerations in creative applications of LLMs are significant, especially in ensuring that AI complements human creativity without undermining it. While LLMs can quickly produce vast amounts of text, music, or visual concepts, the human touch remains essential in refining, curating, and interpreting AI-generated content. An LLM-driven system, for instance, may generate a poem in the style of a famous poet, but its purpose should be to inspire rather than replace human artistry. To encourage ethical practices, developers can implement mechanisms for tracking the sources or influences of generated content, allowing users to see how much of the model’s knowledge aligns with existing works. Mathematically, this can involve computing a similarity metric $S(g, e)$ between generated output $g$ and known examples $e$ from the training data. High values of $S$ indicate close similarity, which can be flagged for further review. Rust’s concurrency features facilitate these checks by allowing similarity evaluations to run in parallel with generation tasks, enabling real-time feedback on originality without disrupting the creative flow.
To demonstrate Rust’s capability in supporting creative applications, consider the following code, which implements a basic poetry generator using an LLM. This pseudocode describes a poetry generation system that leverages a Large Language Model (LLM) to create unique verses based on user-specified themes and styles. By accepting input on a desired theme (e.g., “sunset”) and style (e.g., “romantic” or “haiku”), the model generates text in the form of poetry. Designed for interactive applications, this setup allows multiple poem requests to be processed concurrently, optimizing responsiveness for real-time use.
# Import necessary modules for model inference and text processing
# Define a structure to represent a poetry prompt
CLASS PoetryPrompt:
ATTRIBUTE theme: STRING # The theme of the poem, e.g., "sunset"
ATTRIBUTE style: STRING # The style of the poem, e.g., "romantic", "haiku"
# Function to generate a poem based on the specified theme and style
FUNCTION generate_poem(model: MODEL, prompt: PoetryPrompt) -> STRING:
# Construct input text using the theme and style
SET input_text TO formatted string of prompt.theme and prompt.style
# Encode the input text for model processing
SET tokens TO model.tokenizer.encode(input_text)
SET output TO model.forward(tokens)
# Convert model output into poem lines (simplified for illustration)
SET poem TO output converted to text format
RETURN poem
# Main function to configure the model and generate a sample poem
FUNCTION main() -> SUCCESS or ERROR:
# Configure and load the model onto the specified device (e.g., CPU)
SET config TO default configuration for the model
SET device TO CPU
SET model TO load GPT-2 model with config on device
# Define a sample prompt for generating a romantic poem
SET prompt TO new instance of PoetryPrompt with:
theme as "sunset"
style as "romantic"
# Generate a poem based on the prompt
SET poem TO generate_poem(model, prompt)
# Output the generated poem
PRINT "Generated Poem:", poem
RETURN success
# Execute the main function to start the poetry generation process
CALL main()
This pseudocode illustrates a poetry generator that uses a user-defined theme and style to create custom verses. The PoetryPrompt class captures the theme and style attributes, which are passed to the generate_poem function. In this function, the theme and style are formatted into an input string, tokenized, and fed into the model to generate text. The resulting output is formatted as a poem. In main, the model is loaded, a sample prompt is created, and a poem is generated and printed. This setup demonstrates a creative application of LLMs, allowing multiple themes to be processed in parallel for real-time poetry generation.
Case studies in creative applications illustrate how LLMs can enhance productivity and innovation across artistic fields. For instance, a publishing company used an LLM to generate story prompts and character sketches, which served as inspiration for writers during brainstorming sessions. This process significantly accelerated the ideation phase, allowing authors to explore diverse narrative directions quickly. Another case study involves a music production company that used an LLM to generate lyrical content based on specific genres or emotional tones, streamlining the songwriting process. In both cases, Rust’s performance and memory efficiency enabled large-scale data handling and rapid response generation, supporting real-time creative workflows essential for high-demand environments. These applications reveal that LLMs, when integrated thoughtfully, can complement human creativity by providing artists with a dynamic source of inspiration and ideas.
Emerging trends in creative applications of LLMs point to the rise of multi-modal and interactive content generation, where models process inputs across text, image, and audio formats. For example, a multi-modal model could generate a poem based on an uploaded image or suggest musical accompaniments based on textual descriptions. This advancement enables richer, more immersive creative experiences and opens new possibilities in fields like digital art, immersive storytelling, and mixed-media production. Mathematically, multi-modal generation can be formalized as learning a joint distribution $P(y | x_1, x_2, \dots, x_n)$, where each $x_i$ represents a different input modality (e.g., text, image). Rust’s systems programming capabilities make it ideal for implementing these multi-modal applications, as it supports complex data integration, real-time feature extraction, and memory management essential for processing multi-modal inputs without performance bottlenecks.
The future of LLMs in creative applications lies in developing more adaptive and user-responsive models, capable of customizing outputs based on real-time feedback and iterative inputs. Adaptive LLMs could, for instance, evolve a poem’s structure or tone in response to user preferences, allowing creators to interactively refine generated content. Rust’s low-latency capabilities make it well-suited for supporting such interactive applications, as they require constant updates and recalculations of model outputs in response to user feedback. Furthermore, federated learning presents an opportunity for models to learn from individual user preferences while preserving privacy, as training occurs locally without transmitting personal data to central servers. Rust’s efficiency and security features make it a strong candidate for implementing federated learning in creative applications, ensuring personalized and secure model updates.
In conclusion, LLMs offer groundbreaking possibilities for creative applications, from content generation and music composition to interactive storytelling and visual art. By leveraging Rust’s performance, concurrency, and memory management strengths, developers can build efficient, responsive systems that support real-time content generation and adaptive creativity. This section highlights Rust’s potential to empower artists, musicians, and writers with innovative AI tools that enhance the creative process while addressing ethical considerations and technical challenges. As creative industries continue to explore the possibilities of AI, Rust stands out as a powerful language for building the next generation of creative applications that bridge the gap between artificial intelligence and human expression.
18.2. Building Data Pipelines for Creative Applications
Building data pipelines for creative applications of LLMs involves handling diverse types of content, including text corpora, music datasets, and visual art collections. Unlike structured datasets, creative data often lacks a uniform format, requiring careful preprocessing, curation, and augmentation to maintain its originality and artistic nuances. LLMs for creative purposes, such as poetry generation, music composition, or art synthesis, need high-quality data that captures a wide range of stylistic elements, emotions, and themes. Rust’s performance capabilities and data safety make it an ideal language for building these pipelines, especially when handling large, unstructured datasets that need efficient processing. Rust-based tools and crates, such as serde for data serialization, reqwest for HTTP requests, and rayon for parallel data processing, provide the foundation for creating scalable, responsive data pipelines that support creative LLM applications.
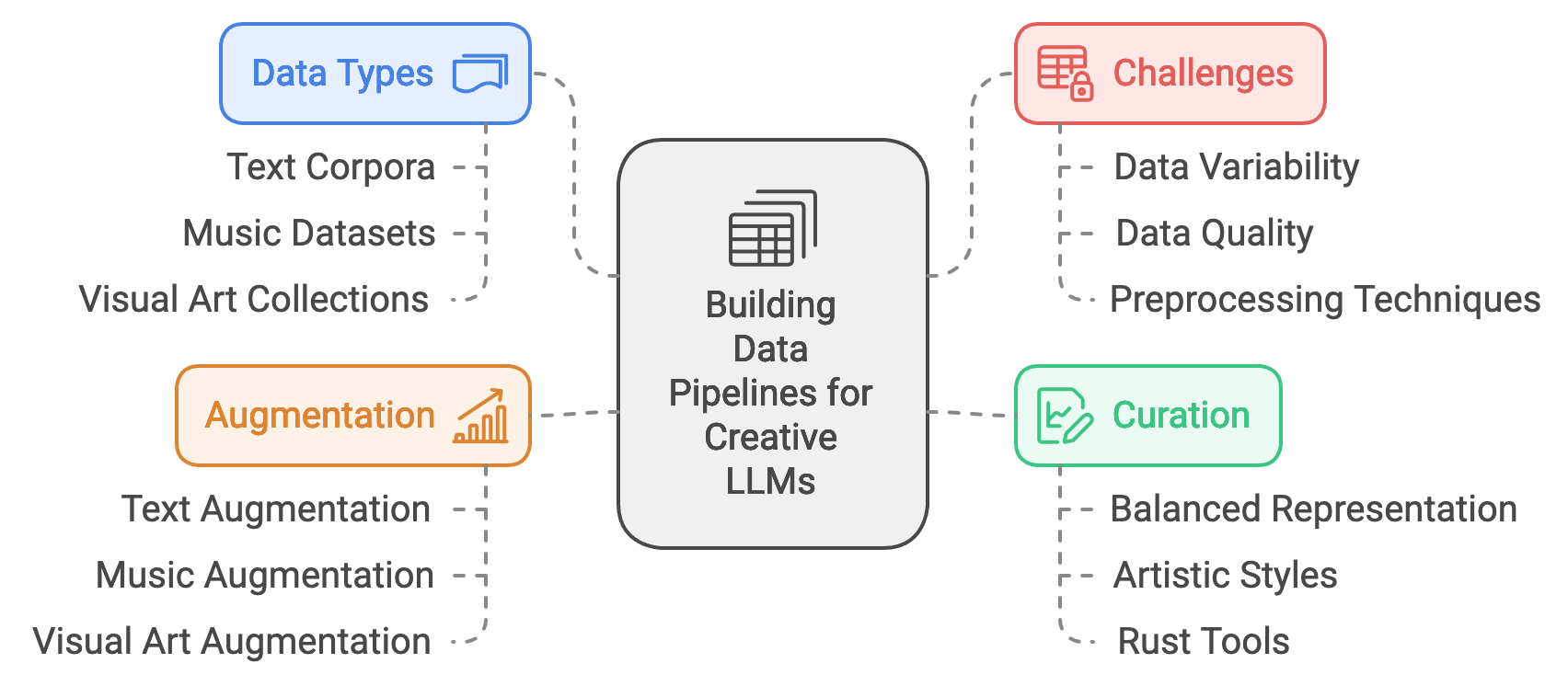
Figure 2: Complexities of building data pipeline.
One of the primary challenges in constructing data pipelines for creative LLMs is dealing with the variability and quality of data. Text datasets, for instance, may come from different sources, genres, and styles, each with unique syntactic and semantic characteristics. To ensure the quality and relevance of the data, preprocessing techniques such as tokenization, filtering, and normalization are essential. Mathematically, let each data sample $x$ in dataset $D$ represent a creative instance (e.g., a line of poetry, a melody, or an image). The preprocessing function $P(x) \rightarrow x'$ cleans and transforms $x$ into a standardized format $x'$ that enhances model training by reducing noise without compromising the creative essence. Rust’s memory management and error handling features allow developers to implement robust preprocessing workflows that systematically process large volumes of data, minimizing data corruption and ensuring high-quality inputs.
Data curation is a key component in developing high-performance creative LLMs. Curation involves selecting and organizing data to provide a balanced representation of different artistic styles, genres, and themes, which helps LLMs generate more diverse and innovative content. For example, in a poetry generation pipeline, curating a dataset with a mix of classical, romantic, and modern poetry would encourage the model to produce varied outputs. A curated dataset $D_{curated} \subset D$ can be constructed by selecting samples that meet criteria for quality and diversity, ensuring a broad representation of styles. Using Rust’s efficient data filtering and sorting capabilities, developers can create curation scripts that handle vast datasets, ensuring they retain artistic depth and stylistic diversity. Moreover, Rust’s concurrency model allows developers to parallelize the curation process, speeding up operations on extensive datasets and making real-time adjustments feasible in interactive applications.
Data augmentation, particularly important in creative applications, introduces controlled variability into the dataset, helping LLMs explore novel combinations and variations. For text data, augmentation can include synonym replacement, paraphrasing, or sentence shuffling, which maintain the essence of the text while altering its structure or vocabulary. Mathematically, let $A(x)$ represent an augmentation transformation applied to data sample $x$, where $A(x)$ yields a modified sample that retains creative elements. In music, augmentation might involve altering tempo or key while preserving the melody, while in visual art, it may involve color adjustments or rotation. Rust’s ability to handle complex transformations with memory safety makes it an excellent choice for implementing data augmentation pipelines, as it minimizes risks of data corruption and enables developers to apply a wide array of transformations safely and efficiently.
This pseudocode outlines a data pipeline for preparing a collection of creative text samples for training a Large Language Model (LLM). The pipeline handles ingestion, preprocessing, and augmentation of text data, helping to maintain data quality while introducing variability. By processing each sample for consistency and replacing certain words with synonyms, this approach ensures diverse and novel content for creative applications. Designed for efficiency, this pipeline is optimized to handle large datasets with concurrent processing.
# Import necessary modules for data handling, file I/O, and parallel processing
# Define a structure for storing each text sample with content and style
CLASS TextSample:
ATTRIBUTE content: STRING # The main text content
ATTRIBUTE style: STRING # The style of the text, e.g., "romantic", "haiku"
# Function to preprocess text samples by normalizing and filtering content
FUNCTION preprocess_text(sample: TextSample) -> OPTIONAL TextSample:
# Normalize content to lowercase for consistency
SET normalized_content TO lowercase version of sample.content
# Filter out samples that do not meet quality criteria (e.g., minimum length)
IF length of normalized_content < 10 THEN
RETURN None
# Return preprocessed sample with normalized content
RETURN new instance of TextSample with:
content as normalized_content
style as sample.style
# Function to apply data augmentation by replacing words with synonyms
FUNCTION augment_text(sample: TextSample) -> LIST of TextSample:
# Define a list of words and their synonyms for replacement
SET synonyms TO list of tuples, e.g., ("love", "affection"), ("beauty", "elegance")
# Initialize augmented_samples with the original sample
INITIALIZE augmented_samples as list containing sample
# Create variations by replacing words with synonyms
FOR each (word, synonym) in synonyms:
IF word in sample.content THEN
SET new_content TO sample.content with word replaced by synonym
ADD new instance of TextSample with:
content as new_content
style as sample.style
TO augmented_samples
RETURN augmented_samples
# Main function to ingest, preprocess, and augment text data
FUNCTION main() -> SUCCESS or ERROR:
# Load text data from file
SET data_path TO "path/to/dataset.txt"
INITIALIZE file with lines read from data_path
# Ingest, preprocess, and augment data in parallel
SET samples TO list where each line in file is converted to:
- TextSample instance with content as line text and style as "romantic"
- Then filtered and normalized by preprocess_text function
# Apply augmentation to introduce content variability
SET augmented_samples TO list where each sample in samples is processed by augment_text function
# Output preprocessed and augmented data
PRINT "Preprocessed and augmented data:", augmented_samples
RETURN success
# Execute the main function to run the data pipeline
CALL main()
This pseudocode demonstrates a data pipeline that prepares creative text samples by processing and augmenting them for use in training an LLM. The TextSample class structures each sample’s content and style. The preprocess_text function standardizes the content by converting it to lowercase and filters out short samples. The augment_text function then creates variations by replacing specific words with synonyms to introduce diversity. In main, the pipeline loads text data, preprocesses and augments each sample, and outputs the final dataset. This setup leverages concurrent processing, enabling efficient handling of large datasets, which is crucial for real-time creative applications requiring diverse, high-quality input data.
Industry applications of data pipelines for creative LLMs highlight the need for high-quality, diverse, and ethically curated datasets. For instance, a music production company used a curated and augmented dataset of lyrics to train an LLM capable of generating song lyrics across multiple genres. This model assisted songwriters in exploring new lyrical themes, styles, and rhyme patterns, enhancing their creative process without sacrificing artistic integrity. Rust’s data management capabilities played a critical role in handling the large dataset, ensuring that all preprocessing, augmentation, and curation steps maintained both data quality and model relevance. Similarly, a digital publishing company used a data pipeline in Rust to curate and preprocess a vast collection of historical literary texts, creating a training set for an LLM that generates poems inspired by classical literature. Rust’s performance and memory management allowed the pipeline to efficiently handle large volumes of text while preserving the unique characteristics of each literary style, resulting in an LLM capable of producing creative, stylistically rich content.
As LLMs continue to gain popularity in creative fields, trends in data curation and augmentation are shifting toward greater interactivity and adaptability. Data pipelines are now being designed to incorporate real-time data from users, enabling models to adapt their creative output based on immediate user feedback or preferences. For example, a live art generation system could analyze user preferences to refine its style, producing more relevant content over time. Rust’s support for high-speed data processing and real-time updates allows these adaptive pipelines to handle large data flows and quick adjustments, facilitating interactive creative applications. Additionally, federated learning is beginning to play a role in creative LLM data pipelines, allowing artists and musicians to contribute to model training locally while preserving their data privacy. Rust’s secure data handling makes it a suitable choice for federated learning implementations, supporting decentralized data pipelines that align with user privacy standards.
In conclusion, building data pipelines for creative applications of LLMs requires a balance between efficiency, data quality, and creativity preservation. By leveraging Rust’s robust data handling, memory safety, and concurrency features, developers can create scalable pipelines that preprocess, curate, and augment diverse datasets, ensuring that the resulting LLMs can generate novel, stylistically rich content. This section underscores Rust’s suitability for managing the complex and often unstructured data demands of creative applications, enabling high-quality content generation while meeting the artistic and ethical standards of modern creative industries. Through thoughtful pipeline design, Rust empowers developers to build the next generation of LLM-driven creative tools that inspire, assist, and amplify human creativity.
18.3. Training LLMs on Creative Data
Training large language models (LLMs) on creative data introduces unique challenges and opportunities, requiring a fine balance between creativity and coherence. Unlike traditional NLP tasks that prioritize factual accuracy and clarity, creative applications demand outputs that inspire, engage, and retain artistic qualities. Models used for poetry generation, music composition, or visual art creation must blend originality with structural coherence, generating content that is both novel and contextually appropriate. Rust’s performance, memory safety, and concurrency features make it an effective language for developing training pipelines for creative LLMs, enabling efficient handling of vast, complex datasets. Additionally, Rust-based frameworks and tools such as burn, candle, and tch-rs offer powerful support for training and fine-tuning LLMs, providing robust data processing, model handling, and optimization capabilities tailored to the specific needs of creative applications.
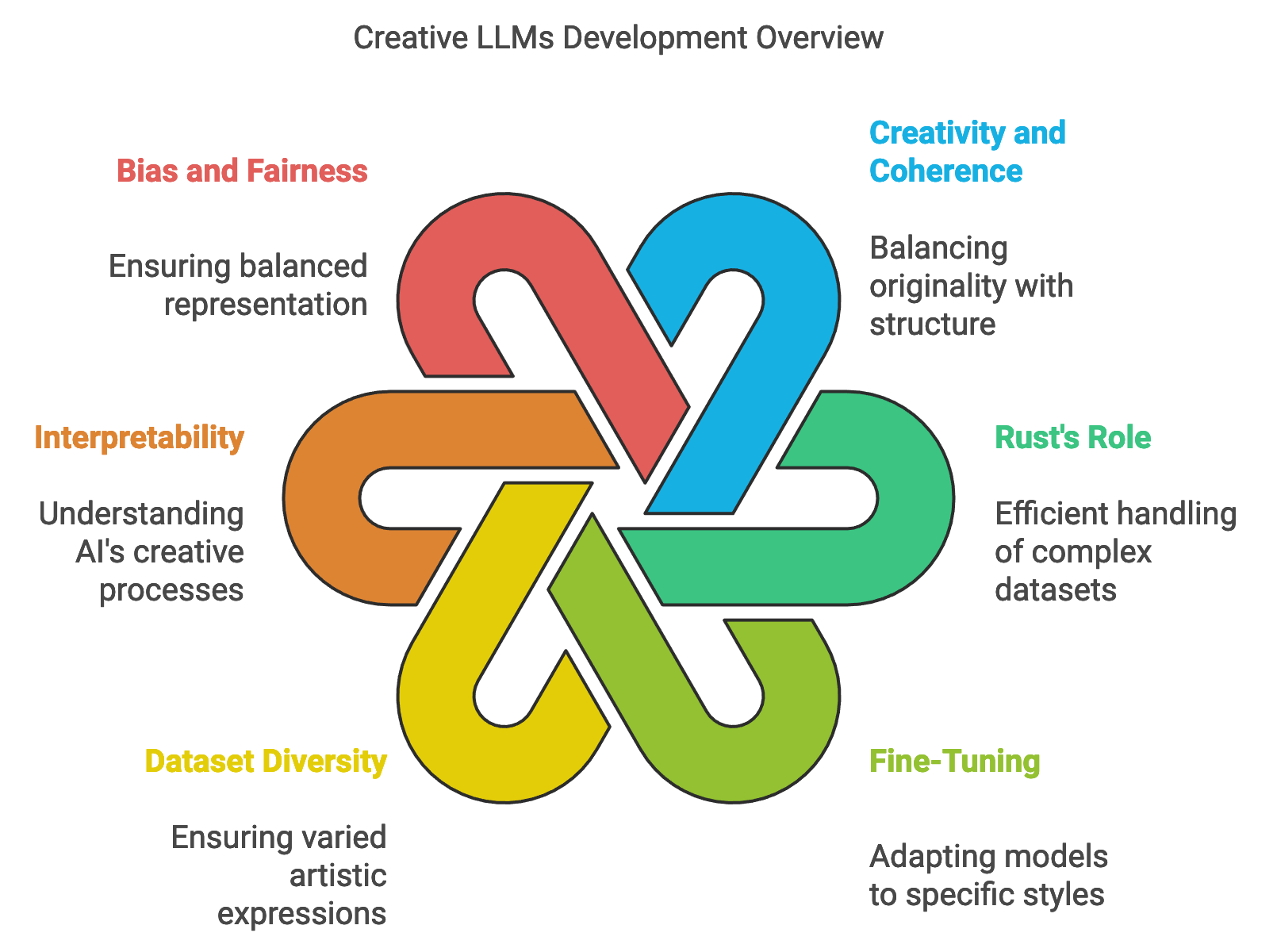
Figure 3: Development scopes and complexities.
Fine-tuning pre-trained models is a crucial step when training LLMs for creative tasks. Creative-specific fine-tuning involves adapting a general-purpose LLM, such as GPT-2 or GPT-3, to produce outputs in particular creative styles or genres. For instance, in poetry generation, fine-tuning could help a model learn the structure of different poetic forms or align with specific aesthetic themes. Mathematically, let $\theta$ represent the model parameters, and $L_{creative}(\theta)$ denote the loss function tailored for creative outputs, where creativity may include elements like surprise, novelty, and coherence with artistic form. By minimizing $L_{creative}(\theta)$ on a creative dataset, we can adjust the model parameters to reflect stylistic nuances while preserving language structure. Rust’s performance and memory management capabilities ensure that the fine-tuning process is both efficient and scalable, making it possible to train models on large creative datasets without compromising on resource efficiency.
Training LLMs on creative data requires carefully curated and diverse datasets that capture a range of artistic expressions, from romantic poetry to abstract visual art. One of the main challenges is ensuring diversity in output, as overfitting to specific styles or themes may lead to repetitiveness and limit the model’s creative versatility. To avoid this, developers can use regularization techniques and data augmentation strategies, where each creative instance $x$ in the dataset $D$ is modified using transformations $T(x)$, producing augmented versions $T(x_1), T(x_2), \dots, T(x_n)$ that retain artistic qualities. This expanded dataset allows the model to generalize better across different creative contexts, resulting in more varied outputs. Rust’s strong typing and efficient data handling facilitate the implementation of data transformations, enabling developers to introduce diversity systematically and without loss of quality, thereby improving the model’s ability to generate fresh, creative content across varied artistic genres.
Model interpretability and explainability are also essential considerations in creative applications, as users may want to understand the inspiration or reasoning behind generated outputs. For instance, a user might be interested in the influences shaping a poem generated by an LLM or the musical patterns present in a composition. Interpretable models can provide insights into these creative processes, fostering a deeper connection between the user and the AI’s output. One approach to interpretability is attention-based analysis, where the model’s attention weights $A(x)$ on input tokens $x$ are visualized, highlighting which aspects of the input influenced specific parts of the generated text. By exposing this information, developers can help users understand the AI’s creative choices. Rust’s concurrency model enables real-time tracking of attention weights, allowing models to run attention analysis in parallel with output generation. This parallelization supports interactive applications, such as real-time poetry composition, where users can view the LLM’s thought process as it generates content.
Bias and fairness are critical in creative LLMs, as models trained on limited or homogenous datasets may inadvertently perpetuate a narrow range of artistic styles, cultural references, or creative voices. To ensure balanced representation, training data should include a variety of perspectives, styles, and voices. Let $P(y | c)$ represent the probability distribution of outputs $y$ conditioned on a creative style $c$; achieving fairness involves ensuring $P(y | c_1) \approx P(y | c_2)$ across diverse styles $c_1, c_2, \dots, c_n$. This balance prevents the model from favoring one style excessively and encourages an inclusive creative space. Rust’s data handling capabilities make it feasible to implement fairness checks by evaluating output distributions and ensuring they are representative of diverse styles. Bias mitigation strategies, such as re-weighting underrepresented styles or augmenting data from marginalized perspectives, can also be integrated into Rust-based pipelines to foster fair and representative creative outputs.
This pseudocode describes a training pipeline to fine-tune a Large Language Model (LLM) on a dataset of poetry. By preprocessing and tokenizing poetry samples, the pipeline prepares the text data for model training. The model learns to generate poetry by training on these processed samples, adjusting its weights over multiple epochs. This setup highlights the suitability of efficient data handling and concurrent processing for creative applications like poetry generation.
# Import necessary modules for tensor operations, model handling, and parallel processing
# Define a structure to represent a poetry sample for training
CLASS PoetrySample:
ATTRIBUTE text: STRING # The text content of the poem
ATTRIBUTE style: STRING # The style of the poem, e.g., "romantic", "haiku"
# Function to preprocess poetry data, including tokenization
FUNCTION preprocess_poetry_data(samples: LIST of PoetrySample, model: MODEL) -> LIST of TENSOR:
RETURN list where each sample in samples is processed in parallel as:
- Tokenized representation of sample.text using model.tokenizer
# Function to fine-tune the model on poetry data
FUNCTION train_poetry_model(model: MODEL, data: LIST of TENSOR, epochs: INTEGER) -> SUCCESS or ERROR:
FOR each epoch in range(epochs):
FOR each input in data:
# Perform forward pass to generate model output
SET output TO model.forward(input)
# Calculate loss using Mean Squared Error (MSE) as a simple metric
SET loss TO (output - input) squared and summed
# Perform backpropagation and update model weights
CALL loss.backward()
CALL model.update_weights()
RETURN success
# Main function to initialize model, load data, and start training
FUNCTION main() -> SUCCESS or ERROR:
# Configure and load the model onto the specified device (e.g., CPU)
SET config TO default configuration for the model
SET device TO CPU
SET model TO load GPT-2 model with config on device
# Define poetry samples for training
SET samples TO list containing instances of PoetrySample, e.g.,
PoetrySample with text as "The sun sets in fiery hue...", style as "romantic"
PoetrySample with text as "Haiku speaks in brevity...", style as "haiku"
# Preprocess the poetry samples to prepare them for training
SET processed_data TO preprocess_poetry_data(samples, model)
# Fine-tune the model using the processed poetry data
CALL train_poetry_model(model, processed_data, epochs = 10)
PRINT "Fine-tuning completed successfully"
RETURN success
# Execute the main function to run the poetry training pipeline
CALL main()
This pseudocode outlines a training pipeline to fine-tune an LLM on poetry data. The PoetrySample class structures each sample’s text and style. The preprocess_poetry_data function tokenizes each poem, transforming it into a format that the model can use for training. In train_poetry_model, the model learns by iterating over the data and adjusting weights based on Mean Squared Error (MSE) loss, refining its ability to generate poetry-like outputs. The main function initializes the model and data, runs preprocessing, and calls the training function. This pipeline serves as a foundation for creative applications in LLMs, allowing for efficient and responsive handling of large datasets.
Industry applications demonstrate how fine-tuning creative LLMs can unlock new possibilities in content creation and user engagement. For example, a media company implemented a fine-tuned LLM to generate unique poems and short stories for their online platform, enhancing user engagement by offering personalized, creative content. The LLM was trained on diverse literary styles, enabling it to produce varied outputs that aligned with different genres and themes. Rust’s efficient data handling and low memory overhead allowed the company to fine-tune the model regularly, updating it with new content to keep the generated outputs fresh and relevant. This deployment highlights the effectiveness of Rust in maintaining high-performance and adaptable creative applications.
Trends in training LLMs on creative data are moving toward interactive and adaptive models, which allow users to guide and influence the AI’s output. These models adjust their generation patterns based on user input, providing a collaborative creative experience where human and AI creativity merge. Rust’s low-latency capabilities support these adaptive models by enabling fast parameter updates and dynamic adjustments, essential for real-time interaction. Additionally, the rise of multi-modal LLMs allows models to learn from multiple types of data, such as images, music, and text, enabling richer creative outputs. Multi-modal learning requires processing diverse data types in parallel, a task well-suited for Rust due to its ability to handle complex, concurrent processing efficiently.
In conclusion, training LLMs on creative data using Rust offers powerful solutions for generating engaging, diverse, and original content. By leveraging Rust’s performance, memory safety, and concurrency support, developers can create pipelines that handle the specific demands of creative data processing, from data curation to fine-tuning. This section underscores the potential of Rust in fostering innovative AI tools for the creative industry, supporting applications that blend human and machine creativity in ways that are both artistically enriching and technically robust. As creative fields continue to embrace AI, Rust’s strengths make it a compelling choice for developing the next generation of creative, responsive, and ethically-aligned LLMs.
18.4. Inference and Deployment of Creative LLMs
Deploying large language models (LLMs) in creative applications requires special consideration of latency, accuracy, and scalability, as these models are often integrated into tools used by artists, writers, musicians, and other creatives in real-time or high-demand environments. Inference for creative LLMs, such as those used in live performance tools or interactive content generators, must be optimized to deliver responses instantaneously, providing users with a seamless experience that aligns with their creative flow. Rust’s high performance and concurrency capabilities make it particularly well-suited for implementing inference pipelines for these models, enabling rapid response times and smooth integration with existing creative software. By utilizing Rust for inference, developers can ensure that creative LLMs operate efficiently, even under heavy workloads, while maintaining high accuracy and quality in generated content.
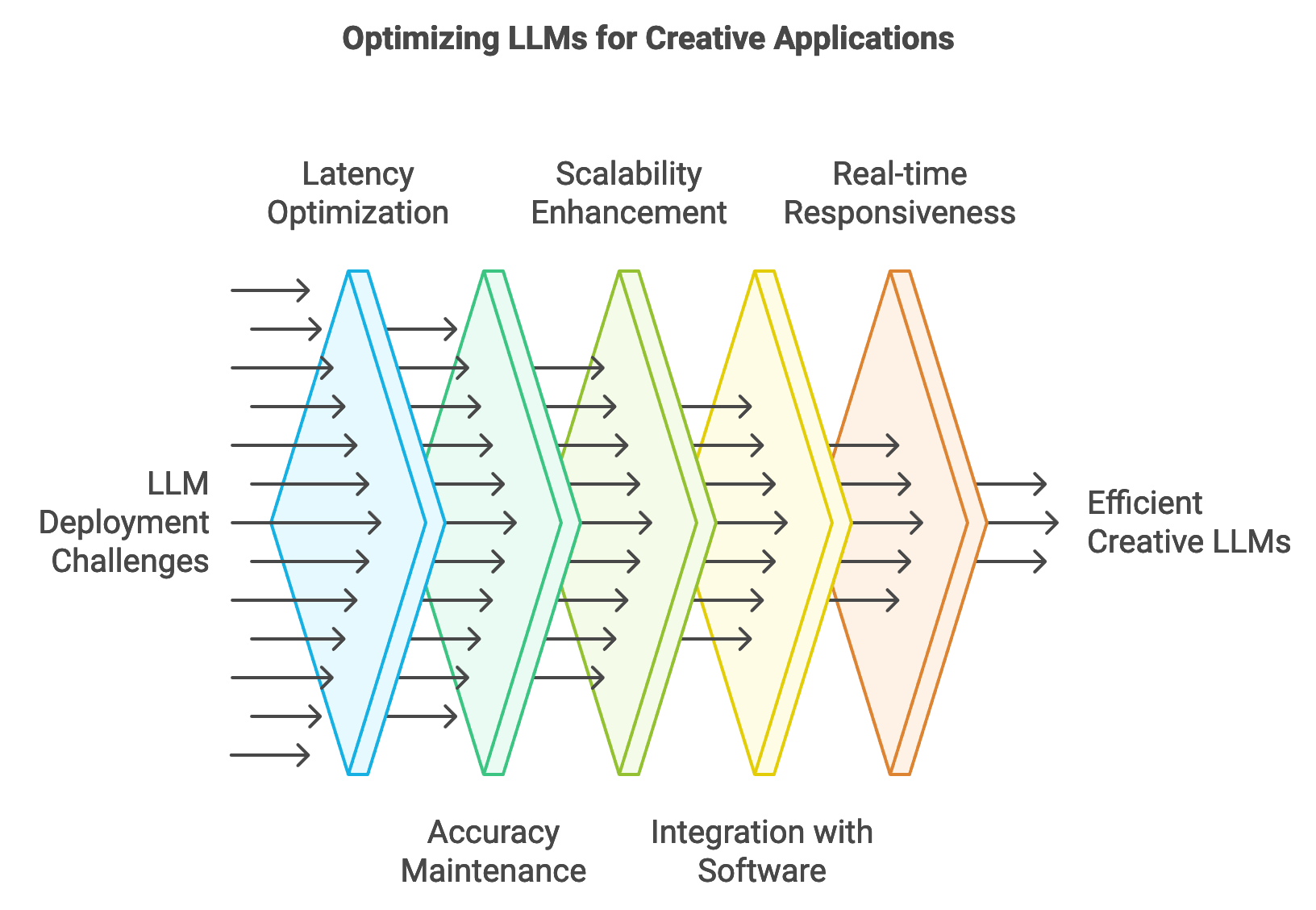
Figure 4: LLMs Optimization Pipeline.
One of the key challenges in deploying creative LLMs is the need to balance model complexity with inference speed. Complex models, which may have billions of parameters, offer greater expressivity and nuanced responses but can introduce latency that disrupts the creative process. For instance, a model used to generate real-time poetic responses in a live performance setting must produce outputs in milliseconds to maintain the performance’s rhythm and flow. Mathematically, let $T(f(x))$ represent the inference time of the function $f(x)$, where $f$ denotes the model and $x$ is the input prompt. Reducing $T(f(x))$ without compromising the quality of $f(x)$ is crucial, which can be achieved by applying optimizations such as model pruning, quantization, or knowledge distillation. Rust’s control over low-level memory and resource management allows developers to implement these optimizations effectively, ensuring that the LLM’s complexity is managed efficiently, enabling high-quality outputs with minimal latency.
Integration with existing creative software is another critical aspect of deploying LLMs in creative environments. These models are often embedded in digital audio workstations (DAWs), graphic design software, or content management systems, where they function as plugins or assistive tools. Seamless integration requires not only compatibility with various file formats and software APIs but also the ability to process user inputs in real-time. Rust’s interoperability with other programming languages and APIs, combined with its efficient handling of complex data, makes it a strong choice for building connectors and plugins that integrate LLMs with creative platforms. For example, a poetry generator plugin integrated into a writing platform might require instantaneous processing of text prompts, generating outputs that align stylistically with the user’s writing. Rust’s performance ensures that this processing happens without noticeable delay, allowing the user to interact with the model as if it were a natural extension of the platform.
Real-time inference is crucial for applications such as interactive art installations, where the model’s outputs need to adjust instantly to changes in user input or environmental factors. In such settings, LLMs must be able to respond dynamically, generating content that evolves based on user actions, environmental changes, or audience interactions. For instance, an LLM-driven visual art tool might generate unique patterns based on the colors or shapes a user selects. Mathematically, let $G(y | x)$ represent the conditional generation of outputs $y$ based on the evolving input $x$; maintaining low latency in $G(y | x)$ is essential to achieve real-time responsiveness. Rust’s concurrency model enables parallel processing of multiple inputs and outputs, allowing the LLM to handle a continuous stream of user interactions without delay. By leveraging Rust’s asynchronous processing capabilities, developers can create responsive, immersive creative tools that adapt to user inputs in real time, enhancing user engagement and creative expression.
Deploying creative LLMs also involves ongoing monitoring and maintenance to ensure model relevance and alignment with user expectations. As trends in art, music, and literature evolve, models may experience “model drift,” where their outputs no longer reflect current styles, themes, or creative standards. A monitoring system for creative LLMs tracks output quality and style consistency over time, alerting developers to deviations from baseline performance. This can involve calculating stylistic similarity metrics $S(y, y')$ between current outputs $y$ and reference outputs $y'$ to detect changes in model behavior. High values of $S$ indicate consistency, while deviations suggest model drift. Rust’s logging and error-handling features make it easy to implement such monitoring systems, allowing developers to identify and address issues early, keeping the model aligned with the creative needs of its users.
To illustrate a Rust-based inference pipeline for a creative LLM, the following example demonstrates a basic setup that ingests user input, processes it through an LLM, and returns the generated output in real time. This pseudocode outlines a real-time inference pipeline for a creative Large Language Model (LLM) that processes user prompts to generate creative content. By accepting a user’s input and passing it through the model, the pipeline produces immediate, generated text, making it ideal for applications that require instant feedback, such as interactive storytelling or live performances. The design is optimized for handling multiple requests concurrently, ensuring low latency and efficient resource usage.
# Import necessary modules for model inference, API handling, and concurrency
# Define a structure to capture user input as a creative prompt
CLASS CreativePrompt:
ATTRIBUTE prompt: STRING # The user's input prompt for creative content generation
# Define application state to store the model for concurrent access
CLASS AppState:
FUNCTION __init__(self, model):
# Store the model in a secure, thread-safe structure
SET self.model TO a thread-safe reference to the LLM model
# Function to handle user prompt and generate creative content in real-time
FUNCTION generate_content(input: CreativePrompt, state: AppState) -> STRING:
# Securely access the model by locking the state
ACQUIRE lock on state.model OR RETURN "Model lock error"
# Tokenize the user prompt and generate content using the model
SET tokens TO model.tokenizer.encode(input.prompt)
SET output TO model.forward(tokens)
# Convert model output into text format
SET generated_text TO output as a string
RETURN generated_text
# Main function to set up the model and launch the API server
FUNCTION main() -> SUCCESS or ERROR:
# Configure and load the model onto the specified device (e.g., CPU)
SET config TO default configuration for the model
SET device TO CPU
SET model TO load GPT-2 model with config on device
# Initialize application state with the loaded model
SET state TO new instance of AppState with model
# Build and configure the API server
INITIALIZE API framework
REGISTER endpoint "/generate" with generate_content function
ATTACH application state for secure, concurrent access
# Launch the API server to handle incoming prompts
START the API server
# Execute the main function to start the inference pipeline
CALL main()
The pseudocode describes a real-time inference pipeline designed for generating creative content. The CreativePrompt class captures user prompts, while AppState securely manages the model’s access for concurrent requests. The generate_content function tokenizes the user input and generates text based on the prompt by passing it through the model, which returns the generated text. In main, the model is loaded with the necessary configuration, and an API server is initialized to manage incoming requests. By enabling concurrent processing and low latency, this pipeline efficiently handles high-traffic environments, making it ideal for interactive and real-time creative applications like storytelling or content generation tools.
Creative industry applications highlight the transformative potential of real-time LLM inference. For instance, a music production software company deployed an LLM-powered lyric generator that artists can interact with while composing. This integration allowed musicians to generate lyrics dynamically, offering instant suggestions based on mood, theme, or genre. By implementing the inference pipeline in Rust, the company ensured that the generator’s responses were immediate, supporting the musician’s creative flow without interrupting the composition process. Similarly, an interactive art installation used an LLM to generate descriptions and poetry based on visitor interactions, creating a personalized experience for each viewer. Rust’s efficient processing enabled the LLM to generate responses in real time, adapting to each viewer’s preferences and enhancing the engagement level of the installation.
Trends in creative LLM deployment indicate a move towards more interactive, adaptive, and user-driven experiences. Adaptive LLMs, which adjust their style or tone based on user feedback, are gaining traction in tools that offer personalized creative assistance, such as personalized story generation or music composition. This interactivity requires low-latency updates and real-time model adjustments, tasks well-suited to Rust’s concurrency and data management capabilities. Additionally, the rise of cloud-based creative platforms is driving the need for scalable LLM deployments that can handle a high volume of simultaneous users. Rust’s ability to optimize memory and manage resources efficiently supports the scalability required for cloud-native creative applications, allowing developers to deploy LLMs that can serve thousands of users concurrently without performance degradation.
In conclusion, deploying creative LLMs using Rust enables responsive, scalable, and efficient systems that meet the unique demands of creative applications. By optimizing inference pipelines, ensuring smooth integration with creative platforms, and implementing real-time monitoring, developers can leverage Rust’s strengths to deliver high-quality, interactive, and adaptable LLM-powered tools. This section underscores the importance of balancing model complexity with speed, maintaining model relevance, and fostering seamless user interactions, demonstrating how Rust can empower the next generation of creative technologies that merge human and AI creativity in meaningful ways. As creative fields continue to explore the possibilities of AI, Rust’s robust performance and flexibility make it an invaluable asset for deploying innovative, dynamic, and artistically engaging applications.
18.5. Ethical and Legal Considerations in Creative LLMs
Deploying large language models (LLMs) in creative fields introduces complex ethical and legal challenges, particularly around originality, copyright, and the preservation of human creativity. As these models generate content—be it text, music, or visual art—they inherently interact with issues of authorship and intellectual property. LLMs trained on vast datasets may produce works that resemble or draw inspiration from existing pieces, raising questions about their originality and ownership. For developers working in Rust to build LLM applications for creative purposes, it is crucial to implement safeguards that respect the contributions of original creators and comply with relevant copyright laws. Rust’s rigorous control over memory and data handling enables developers to incorporate mechanisms for tracking, detecting, and validating originality, thus ensuring that generated content aligns with ethical and legal standards.
Figure 5: Navigating challenges in LLMs deployment.
A core consideration in the ethical deployment of creative LLMs is the potential impact on human creators and originality. Creative LLMs often learn from extensive datasets comprising books, songs, and artworks, assimilating styles, themes, and structures from diverse sources. Mathematically, this process can be represented as finding a generative function $G(x)$ that maps input prompts $x$ to outputs $y$ that adhere to specific styles or genres. However, if $G(x)$ produces outputs that closely resemble existing works, it risks generating derivative or infringing content. Originality detection thus becomes vital. One approach is to calculate a similarity metric $S(y, y')$ between the generated output $y$ and existing works $y'$ in the dataset. High values of $S$ indicate potential overlap, prompting a further review to ensure that the output is sufficiently original. Rust’s performance and safety features support the development of such similarity-checking algorithms, allowing for real-time, efficient comparisons without compromising system integrity or speed.
Legal frameworks governing the use of AI in creative fields further complicate the landscape. Copyright laws in many jurisdictions offer protections to original works and prohibit unauthorized reproduction, adaptation, or distribution of copyrighted material. However, LLMs blur the line between inspiration and infringement. For example, models trained on copyrighted content may inadvertently generate outputs that replicate elements of these works, even when unintended. Developers working with Rust can address this risk by incorporating metadata tracking and compliance monitoring within the training and inference pipeline. For instance, tracking data sources and associated licenses within the model’s data pipeline helps ensure compliance with copyright restrictions. Rust’s data serialization and logging capabilities, particularly through libraries like serde and log, make it possible to embed data provenance information into the pipeline, preserving a traceable record of the model’s content sources and transformations.
Transparency and accountability are also essential in gaining trust from users, creators, and regulators. Users of creative LLMs need assurance that the model’s outputs are ethically sourced and that any content derived from existing works respects intellectual property rights. In practical terms, this transparency can involve implementing explainability features that reveal the influences and sources informing the model’s outputs. For example, a transparency module could trace stylistic influences in generated content by analyzing the distribution of similar themes or lexical patterns in the training data. Mathematically, this could involve calculating a stylistic similarity distribution $D(y)$ over the output $y$ to identify prevalent styles or sources, providing users with insights into the creative basis of the generated work. Rust’s efficient data processing and strong concurrency support make it feasible to run these checks in real time, offering users greater visibility into the model’s creative processes without compromising performance.
To illustrate how Rust can enforce originality detection and compliance within creative LLM applications, the following example demonstrates a function that checks for potential content similarity with an existing corpus. This pseudocode outlines a system for detecting originality in content generated by a Large Language Model (LLM) by comparing it to an existing dataset of creative works. By calculating cosine similarity between the generated work and known works in a corpus, this setup flags any outputs with high similarity scores, which may indicate potential overlap. This process helps maintain originality and compliance in creative applications, ensuring generated content does not inadvertently resemble existing works too closely.
# Import necessary modules for data handling and similarity calculations
# Define a structure to represent a creative work with word embeddings for similarity checking
CLASS CreativeWork:
ATTRIBUTE id: STRING # Identifier for the creative work
ATTRIBUTE embeddings: LIST of FLOAT # Embedding vector representation of the work
# Function to calculate cosine similarity between two creative works
FUNCTION cosine_similarity(work1: CreativeWork, work2: CreativeWork) -> FLOAT:
# Calculate the dot product of the two embedding vectors
SET dot_product TO sum of element-wise multiplication of work1.embeddings and work2.embeddings
# Calculate the norms of each embedding vector
SET norm1 TO square root of sum of squares of elements in work1.embeddings
SET norm2 TO square root of sum of squares of elements in work2.embeddings
# Return cosine similarity
RETURN dot_product / (norm1 * norm2)
# Function to check if a generated work is original by comparing it to known works
FUNCTION check_originality(generated_work: CreativeWork, corpus: DICTIONARY of STRING to CreativeWork, threshold: FLOAT) -> BOOLEAN:
# For each existing work in the corpus, calculate similarity to the generated work
FOR each existing_work in corpus.values:
IF cosine_similarity(generated_work, existing_work) > threshold THEN
RETURN False # Flag as potentially derivative if similarity is above threshold
RETURN True # Original if all similarities are below threshold
# Main function to test originality of a generated work
FUNCTION main() -> SUCCESS or ERROR:
# Define a generated creative work with an embedding vector
SET generated_work TO new instance of CreativeWork with:
id as "generated_poem"
embeddings as [0.1, 0.5, 0.3, 0.4] # Example embedding vector
# Define a corpus containing embeddings of existing works
INITIALIZE corpus as DICTIONARY with entries, e.g.,
"poem_1" maps to CreativeWork with id "poem_1", embeddings as [0.2, 0.4, 0.5, 0.3]
"poem_2" maps to CreativeWork with id "poem_2", embeddings as [0.1, 0.6, 0.3, 0.2]
# Check originality using a similarity threshold of 0.8
SET is_original TO check_originality(generated_work, corpus, threshold = 0.8)
# Output originality check result
PRINT "Is the generated work original?", is_original
RETURN success
# Execute the main function to run originality detection
CALL main()
This pseudocode describes an originality detection pipeline for creative LLM-generated content. The CreativeWork class represents each creative work using an embedding vector. The cosine_similarity function calculates the similarity between two works based on their embeddings. The check_originality function compares a generated work against known works in the corpus, using cosine similarity to identify overlaps that exceed a defined threshold, flagging them as potentially derivative. In main, the system sets up a generated work and a corpus, checks originality, and outputs the result. This approach helps enforce originality standards in creative applications, ensuring compliance with copyright regulations and protecting intellectual property.
Best practices for deploying LLMs in creative fields emphasize compliance with both ethical and legal standards, which helps prevent copyright infringement and foster fair use. A compliance checklist for creative LLM deployments could include requirements for originality detection, adherence to fair use, and data documentation practices. Regular audits to assess adherence to this checklist can further ensure that models align with both legal standards and the expectations of creative communities. Rust’s capabilities in automated testing and structured logging support the implementation of compliance routines, enabling developers to create robust systems for verifying that models respect intellectual property and creative rights.
Industry case studies highlight the importance of responsible AI practices in creative LLM applications. For instance, an AI-driven music platform used an LLM to generate instrumental compositions, but with safeguards to prevent copying existing melodies. Using similarity detection algorithms in Rust, the platform identified and filtered out compositions that showed excessive similarity to copyrighted tracks. Another company deploying an AI art generator embedded traceability into its workflow, allowing users to view the inspirations or stylistic influences that informed generated images. This transparency not only built user trust but also provided a valuable tool for curators assessing the originality of AI-generated artworks.
The future of creative LLMs is likely to focus on more granular control over ethical and legal compliance, as emerging trends call for adaptive models that adjust their behavior based on user input, regional regulations, or content-type-specific rules. For instance, adaptive models could dynamically modify content generation to fit within fair use guidelines or prevent generating material in restricted creative genres. Federated learning, which allows models to be trained across decentralized devices without centralizing sensitive data, also shows promise for creative applications, as it can enable content personalization while preserving user privacy. Rust’s support for secure data handling and privacy protocols makes it a viable choice for federated learning setups, allowing developers to build compliance-focused creative LLMs that respect users’ rights and data privacy.
In conclusion, the ethical and legal considerations surrounding creative LLMs are integral to responsible AI deployment in the arts and entertainment sectors. Through strategies such as originality detection, compliance monitoring, and transparent content sourcing, developers can build systems that honor the rights of original creators and foster trust in AI-driven creative tools. Rust’s strengths in performance, security, and data management provide a robust foundation for implementing these safeguards, enabling developers to build creative applications that balance innovation with ethical responsibility. This section underscores the importance of ethical alignment in creative LLM deployments, emphasizing Rust’s role in supporting AI applications that are both artistically enriching and legally compliant.
18.6. Case Studies and Future Directions
The implementation of LLMs in creative fields has led to a new wave of artistic possibilities, where AI can co-create with human artists, composers, and storytellers. Successful case studies in generative art, music composition, and interactive storytelling highlight the transformative potential of LLMs in expanding artistic expression and production efficiency. These examples also shed light on the challenges of scalability, originality, and engagement, demonstrating how LLMs can be designed and fine-tuned to align with the diverse needs of creative users. By examining these real-world applications, we gain insight into the practical and conceptual considerations of deploying LLMs for creative tasks and the role of Rust as a high-performance language that supports responsive, efficient, and reliable creative tools.
Figure 6: Rust offers harmonious blend of developing LLM apps.
One prominent case study involves an LLM-powered interactive storytelling platform designed to create immersive narratives that adapt to user input in real time. The platform required fast response times to ensure seamless user engagement, as well as scalable processing to support a large number of simultaneous interactions. Mathematically, this type of application can be represented as a real-time function $G(s | u) \rightarrow r$, where $s$ is the state of the story, $u$ is the user input, and $r$ is the generated narrative response. The challenge lay in maintaining coherence and originality across diverse narrative branches while preserving the user’s sense of agency in the story. Rust’s concurrency model and efficient memory management enabled developers to implement a responsive architecture that could handle rapid input-output cycles without sacrificing the quality or creativity of the generated content. By leveraging Rust’s performance, the platform successfully scaled to support thousands of users while delivering high-quality, adaptive storytelling experiences.
In music, another case study highlights the use of an LLM for AI-assisted composition, where musicians could interact with the model to generate lyrics, chord progressions, or melodic lines. The model, trained on a dataset of genre-specific musical pieces, allowed artists to customize the style, mood, and structure of the generated outputs. However, ensuring originality and avoiding over-reliance on training data patterns posed a significant challenge. To address this, developers introduced augmentation techniques and regularization methods to enhance diversity in the model’s outputs. Rust was instrumental in implementing these techniques, as its memory safety and precise control over low-level processes allowed the team to fine-tune the model with minimal computational overhead. The result was a composition tool that assisted artists in exploring new musical directions while maintaining creative agency, paving the way for more collaborative and experimental music production workflows.
Emerging trends in the creative applications of LLMs point to further integration of these models into generative art, personalized content, and immersive experiences. Generative art, for example, leverages LLMs to interpret and synthesize visual patterns, blending stylistic influences from a wide array of artistic traditions. An LLM can take input descriptions, such as colors, emotions, or thematic elements, and generate prompts that guide an associated visual model to create artwork. These generative systems require real-time adaptability, as artists often modify prompts iteratively to achieve their desired aesthetic. Rust’s low-latency capabilities make it ideal for real-time feedback loops, enabling artists to interact dynamically with the model, refining prompts until the desired artistic expression is achieved.
Looking to the future, the potential of LLMs in creative industries is immense, with applications ranging from automated content creation to collaborative tools that enhance artistic workflows. For instance, a creative writing tool could leverage an LLM to generate stylistically diverse suggestions for narrative development, enhancing both speed and innovation in storytelling. Mathematically, this can be formalized as a sequence generation task $f(\theta, x) \rightarrow y$, where $\theta$ represents stylistic parameters, $x$ is the user’s narrative input, and $y$ is the model’s creative output. This iterative approach allows the model to learn and adapt to unique narrative styles, fostering a blend of AI and human creativity. Rust’s strength in handling large, complex data structures and real-time processing ensures that such interactive applications remain responsive, creating a seamless experience for writers, artists, and musicians.
However, several challenges must be addressed to unlock the full potential of LLMs in creative applications. One significant issue is data availability, as high-quality, diverse datasets are essential for training models that can produce varied and original outputs. In many creative fields, there is limited access to large-scale, labeled datasets, which hinders the development of models that can generalize across styles and genres. Furthermore, maintaining model interpretability and transparency is critical to fostering trust among users and ensuring that outputs align with creative intentions. Ethical considerations, such as originality and copyright, are also pivotal, as creative LLMs must balance inspiration with respect for intellectual property. Rust’s control over data handling and efficient parallel processing supports efforts to address these challenges, making it easier to implement transparent, fair, and adaptable creative systems.
To illustrate the implementation of a small-scale version of a creative application, consider the following Rust code for a lyric generation tool. This pseudocode outlines a real-time lyric generation tool that uses a Large Language Model (LLM) to create song lyrics based on user-defined themes or styles. By allowing users to input a theme, the model can respond with lyrics that align with the given prompt. The design leverages concurrent processing to ensure responsiveness and efficiency, making it suitable for real-time creative applications such as live music sessions or interactive lyric generation.
# Import necessary modules for model inference, API handling, and concurrency
# Define a structure to capture user input as a theme for lyric generation
CLASS LyricPrompt:
ATTRIBUTE theme: STRING # The user's theme or style input for generating lyrics
# Define application state to store the model for concurrent access
CLASS AppState:
FUNCTION __init__(self, model):
# Store the model in a secure, thread-safe structure
SET self.model TO a thread-safe reference to the LLM model
# Function to handle user theme input and generate lyrics
FUNCTION generate_lyrics(input: LyricPrompt, state: AppState) -> STRING:
# Securely access the model by locking the state
ACQUIRE lock on state.model OR RETURN "Model lock error"
# Tokenize the theme input and generate content using the model
SET tokens TO model.tokenizer.encode(input.theme)
SET output TO model.forward(tokens)
# Convert model output into lyrics format
SET lyrics TO output as a string
RETURN lyrics
# Main function to set up the model and launch the lyric generation API server
FUNCTION main() -> SUCCESS or ERROR:
# Configure and load the model onto the specified device (e.g., CPU)
SET config TO default configuration for the model
SET device TO CPU
SET model TO load GPT-2 model with config on device
# Initialize application state with the loaded model
SET state TO new instance of AppState with model
# Build and configure the API server
INITIALIZE API framework
REGISTER endpoint "/generate_lyrics" with generate_lyrics function
ATTACH application state for secure, concurrent access
# Launch the API server to handle incoming lyric generation requests
START the API server
# Execute the main function to start the lyric generation pipeline
CALL main()
This pseudocode outlines a lyric generation system that accepts a user-defined theme or style, using it as a prompt for an LLM to produce relevant lyrics. The LyricPrompt class stores the user’s input theme, while AppState manages the model, allowing concurrent access for multiple requests. The generate_lyrics function tokenizes the theme and passes it to the model to generate lyrics, returning the output in text format. In main, the model is loaded and an API server is initialized to manage lyric generation requests in real time. By enabling concurrent processing, this system can handle multiple user requests efficiently, making it ideal for interactive music applications.
The future of creative LLMs involves an increasingly adaptive and user-driven approach, where models dynamically adjust their style or content based on user feedback. Advances in real-time adaptation and personalization are opening new doors for applications such as personalized interactive storytelling, where users influence the direction and tone of the narrative. Additionally, multi-modal creative LLMs are emerging, enabling tools that combine text, image, and audio generation for more immersive and flexible creative experiences. Rust’s capabilities in handling diverse data types and maintaining efficient, concurrent processes will play a crucial role in supporting these complex, interactive applications, enabling developers to build rich, multi-modal systems that cater to a wide range of creative needs.
In conclusion, creative LLMs represent a major opportunity to expand artistic possibilities, enhance content production, and foster new collaborative dynamics between humans and machines. By examining case studies, we see how Rust’s efficiency, concurrency, and memory safety enable developers to overcome the unique challenges of creative applications, from real-time response requirements to scalability and originality. As trends in generative art, personalized content, and immersive experiences continue to evolve, Rust will remain a foundational language for building the next generation of creative applications. The section underscores the transformative potential of LLMs in creative fields, providing a roadmap for future innovations and exploring the ways Rust can empower developers to build adaptive, ethical, and artistically engaging LLM-driven tools for the creative industries.
18.7. Conclusion
Chapter 18 empowers readers to explore and harness the creative potential of large language models using Rust. By mastering the techniques and ethical considerations discussed, readers can develop innovative applications that enhance creative processes while respecting the contributions of human artists and creators. This chapter serves as a guide to responsibly integrating AI into the arts, ensuring that technology enhances rather than replaces human creativity.
18.7.1. Further Learning with GenAI
These prompts cover a wide range of topics, from building data pipelines for creative content and training models on diverse datasets to deploying LLMs in real-time, interactive environments.
Explain the role of large language models (LLMs) in creative fields such as content generation, music composition, and visual art. How can LLMs enhance creative processes and what are the potential risks?
Discuss the key challenges of applying LLMs in creative applications, particularly in maintaining creativity, originality, and user engagement. How can Rust be leveraged to address these challenges?
Describe the importance of balancing creativity with coherence and relevance in generated content. How can Rust-based models be designed to achieve this balance in creative applications?
Analyze the impact of LLMs on creative industries. What are the potential benefits and risks of using LLMs for artistic expression and content production?
Explore the ethical considerations of deploying LLMs in creative fields, particularly regarding originality, copyright, and the role of human creativity. How can Rust-based systems be designed to mitigate these ethical issues?
Explain the process of building a robust data pipeline for creative applications using Rust. What are the essential steps for ensuring data quality, diversity, and creativity when handling large volumes of creative content?
Discuss the challenges of working with diverse and often unstructured creative data sources. How can Rust-based tools be used to preprocess, curate, and augment creative data for LLM training?
Analyze the role of data curation and augmentation in enhancing the creative output of LLMs. How can Rust be used to implement these techniques effectively?
Explore the specific considerations for training LLMs on creative data, including balancing creativity with coherence and maintaining user engagement. How can Rust be used to implement a robust training pipeline?
Discuss the importance of fine-tuning pre-trained models for creative-specific tasks. What are the key challenges and benefits of adapting general-purpose LLMs to creative applications?
Explain the role of model interpretability and explainability in creative applications. How can Rust-based models be designed to ensure that their outputs align with user expectations and creative intent?
Analyze the challenges of deploying LLMs in creative environments, particularly in terms of latency, accuracy, and scalability. How can Rust be used to build and deploy efficient inference pipelines for creative LLMs?
Discuss the legal frameworks that govern the use of AI in creative applications, such as copyright laws and intellectual property rights. How can developers ensure that their Rust-based LLM applications comply with these regulations?
Explore the potential risks of deploying LLMs in creative contexts, including the impact on human creators and the potential for generating derivative or infringing works. How can Rust-based systems be designed to detect and mitigate these risks?
Discuss the importance of real-time inference capabilities in critical creative applications, such as live performance tools and interactive content generation. How can Rust be used to optimize inference pipelines for speed, accuracy, and scalability in these scenarios?
Analyze the role of continuous monitoring and maintenance in ensuring the long-term reliability of deployed creative LLMs. How can Rust-based systems be set up to track performance and implement updates based on user interaction and feedback?
Explore the challenges of integrating LLMs into existing creative software and tools. How can Rust-based models be deployed in a way that ensures compatibility and minimal disruption to creative workflows?
Discuss the future potential of LLMs in creative fields, including emerging trends like generative art, AI-assisted music composition, and interactive storytelling. How can Rust be leveraged to innovate in these areas?
Explain the key lessons learned from existing case studies of LLM deployments in creative fields. What best practices can be derived from these experiences, and how can they inform the development of future Rust-based creative applications?
Analyze the broader implications of using LLMs in creative fields. How can these technologies be harnessed to enhance artistic expression and content production while ensuring adherence to ethical and legal standards?
Embrace these challenges with curiosity and determination, knowing that the knowledge and skills you gain will position you at the forefront of AI innovation in the creative industries.
18.7.2. Hands On Practices
Self-Exercise 18.1: Building a Data Pipeline for Creative Content Using Rust
Objective: To design and implement a robust data pipeline for creative applications using Rust, focusing on preprocessing, curation, and augmentation of diverse creative datasets.
Tasks:
Set up a Rust-based data pipeline to ingest, preprocess, and curate creative data, such as text corpora, music datasets, or visual art collections, ensuring data quality and diversity.
Implement data augmentation techniques to introduce variability and enhance the creativity of the dataset, ensuring that the pipeline supports a wide range of creative outputs.
Test the pipeline with different types of creative data, identifying and addressing challenges related to data quality, diversity, and creativity preservation.
Experiment with different preprocessing and augmentation methods to optimize the pipeline for generating high-quality, original creative content.
Deliverables:
A Rust codebase for a creative data pipeline that includes preprocessing, curation, and augmentation components.
A detailed report on the implementation process, including challenges encountered and solutions applied.
A performance evaluation of the pipeline, focusing on its ability to handle and enhance diverse creative datasets effectively.
Self-Exercise 18.2: Training a Creative-Specific LLM with Rust
Objective: To train a large language model on creative data using Rust, with a focus on generating original and engaging creative content, such as poetry, music, or visual art.
Tasks:
Prepare a dataset of creative content, ensuring it is properly preprocessed and labeled for training a large language model.
Implement a Rust-based training pipeline, incorporating techniques to balance creativity with coherence and maintain originality in the generated outputs.
Experiment with different fine-tuning techniques to adapt a pre-trained LLM to specific creative tasks, such as generating poetry or composing music.
Evaluate the trained model on a validation dataset, analyzing its creativity, originality, and relevance to the creative task.
Deliverables:
A Rust codebase for training a creative-specific large language model, including data preprocessing and fine-tuning techniques.
A training report detailing the model’s performance on creative tasks, with a focus on creativity, originality, and user engagement.
A set of recommendations for further improving the model’s performance and applicability in creative applications.
Self-Exercise 18.3: Deploying a Real-Time Creative Application Using Rust
Objective: To deploy a large language model for real-time creative applications, such as live performance tools or interactive content generation, focusing on optimizing latency, accuracy, and user interaction.
Tasks:
Implement an inference pipeline in Rust that serves a creative application, optimizing for low latency and high accuracy in generating real-time creative content.
Deploy the creative application in a secure and scalable environment, ensuring seamless integration with existing creative tools and platforms.
Set up a real-time monitoring system to track the performance of the deployed model, focusing on key metrics such as response time, creativity, and user satisfaction.
Analyze the monitoring data to identify potential issues with the application’s performance, and implement updates or adjustments as needed based on user interaction and feedback.
Deliverables:
A Rust codebase for deploying and serving a real-time creative application, including real-time inference capabilities.
A deployment report detailing the steps taken to optimize performance and ensure seamless integration with creative tools.
A monitoring report that includes performance metrics and an analysis of the application’s real-time behavior, with recommendations for ongoing maintenance and updates.
Self-Exercise 18.4: Ensuring Ethical and Legal Compliance in Creative LLM Deployment
Objective: To design and implement strategies for ensuring ethical and legal compliance in the deployment of large language models in creative fields, focusing on originality detection, copyright compliance, and protecting human creativity.
Tasks:
Implement originality detection techniques in a deployed creative LLM, ensuring that the generated content is original and does not infringe on existing works.
Develop methods to enhance the transparency of the model’s decision-making processes, making them understandable for both users and regulators, especially in terms of copyright compliance.
Integrate continuous monitoring for ethical and legal compliance, including mechanisms to detect and respond to potential violations of copyright or creative ethics.
Conduct a thorough evaluation of the deployed model’s ethical and legal performance, focusing on originality, copyright compliance, and adherence to ethical standards.
Deliverables:
A Rust codebase with integrated originality detection and copyright compliance features for a deployed creative large language model.
An ethical and legal compliance report detailing the strategies used to ensure originality and compliance, including detection results.
An evaluation report on the model’s ethical and legal performance, with recommendations for improving compliance in future deployments.
Self-Exercise 18.5: Innovating Creative Applications with LLMs: Case Study Implementation
Objective: To analyze a real-world case study of large language model deployment in creative fields and implement a small-scale version using Rust, focusing on replicating the critical aspects of the deployment.
Tasks:
Select a case study of a successful LLM deployment in creative fields, analyzing the key challenges, solutions, and outcomes.
Implement a small-scale version of the case study using Rust, focusing on the most critical components such as data handling, model training, and deployment.
Experiment with the implementation to explore potential improvements or adaptations, considering factors such as model creativity, scalability, and compliance.
Evaluate the implemented model against the original case study, identifying key takeaways and lessons learned for future creative LLM projects.
Deliverables:
A Rust codebase that replicates a small-scale version of the selected creative LLM case study, including key deployment components.
A case study analysis report that details the original deployment’s challenges, solutions, and outcomes, along with insights gained from the implementation.
A performance evaluation of the implemented model, with a comparison to the original case study and recommendations for future innovations in creative LLM deployments.
Comments