Chapter 17
Customer Service and E-commerce
"In the intersection of AI and customer experience, the real challenge lies not just in automating interactions, but in creating meaningful connections that resonate with each individual user." — Andrew Ng
Chapter 17 of LMVR delves into the transformative potential of large language models (LLMs) in customer service and e-commerce. The chapter covers the end-to-end process of developing, deploying, and maintaining LLMs in these domains, addressing challenges such as handling diverse customer queries, ensuring real-time responsiveness, and maintaining user privacy. It explores the use of Rust for building robust data pipelines, training models on complex customer and e-commerce data, and deploying them in scalable, secure environments. The chapter also emphasizes the importance of ethical considerations and regulatory compliance, ensuring that LLMs are not only effective but also fair and transparent. Through case studies and practical examples, readers gain insights into the development and deployment of LLMs in customer service and e-commerce, with a focus on enhancing user experience and operational efficiency.
17.1. Introduction to LLMs in Customer Service and E-commerce
Large language models (LLMs) are becoming integral to customer service and e-commerce, where they enhance the user experience through applications like intelligent chatbots, personalized product recommendations, and automated customer support systems. In customer service, LLMs can interpret user queries, engage in natural conversation, and provide accurate, context-aware responses, helping businesses handle a high volume of customer inquiries without requiring human intervention. In e-commerce, LLMs personalize the shopping experience by recommending products based on user preferences and behavior, increasing the likelihood of conversions and improving customer satisfaction. These models can also aid in customer sentiment analysis, enabling businesses to adapt their service strategies in real-time based on user feedback. Rust, with its performance, concurrency, and safety features, is particularly suited to the demands of these applications, as it enables low-latency responses, ensures safe data handling, and supports scalable architectures essential for e-commerce and customer service platforms.
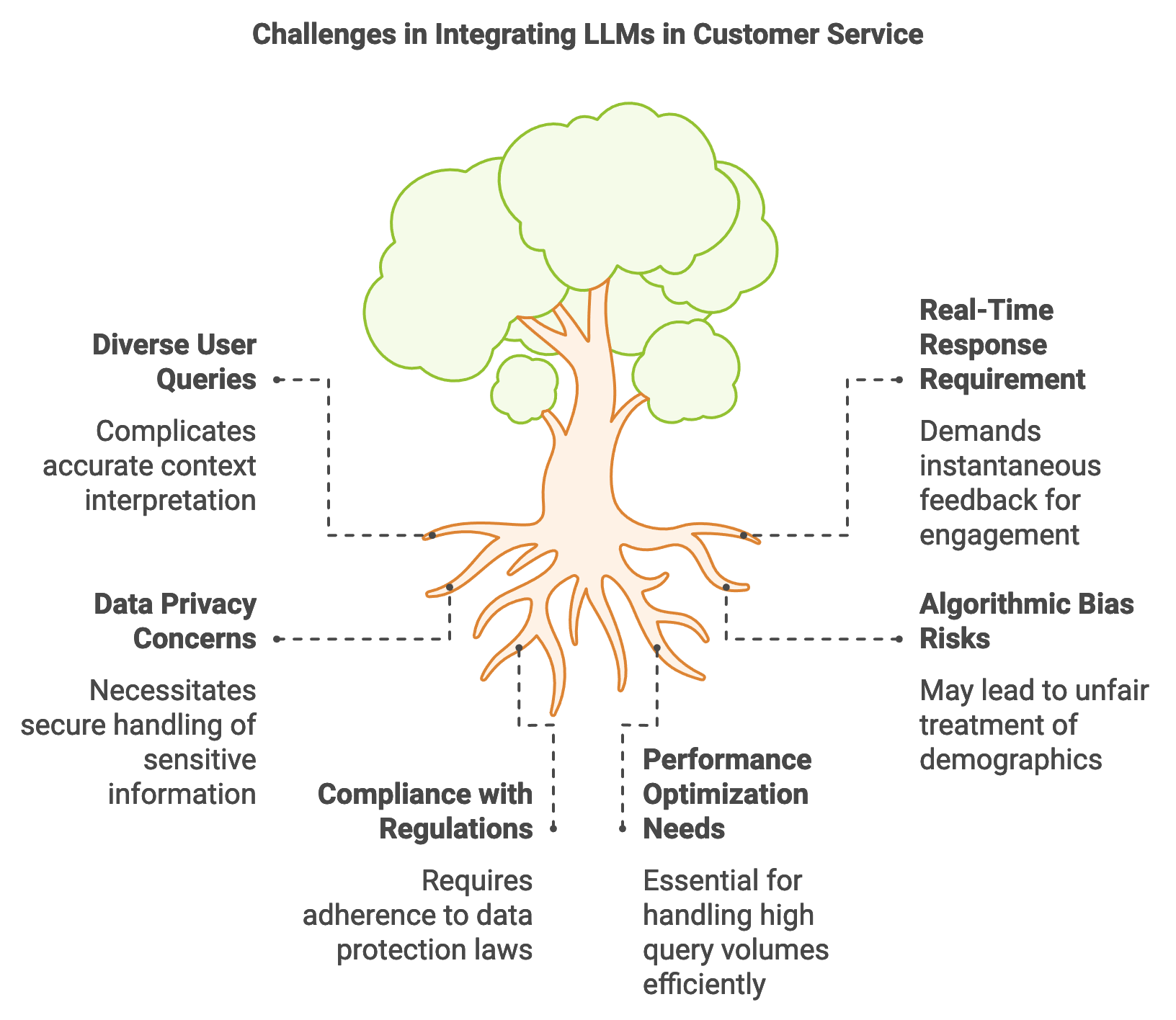
Figure 1: Key challenges in integrating LLMs in Customer Service.
Incorporating LLMs into customer service systems involves unique challenges due to the diversity and unpredictability of user queries. For instance, customer questions can vary widely in language, tone, and complexity, requiring models to accurately interpret context and intent. The need for real-time response further complicates this task, as customer service interactions demand instantaneous feedback to maintain user engagement. Rust’s memory safety, type-checking, and concurrency enable developers to build efficient, responsive systems that can handle high query volumes without compromising performance. Additionally, Rust’s secure data handling is crucial for maintaining user privacy, which is particularly important given the sensitive nature of customer interactions, such as account details or purchase history.
The impact of LLMs in customer service and e-commerce is measurable in terms of user experience, sales conversions, and operational efficiency. With chatbots and automated customer support systems, businesses can reduce the need for extensive customer service teams while still providing quality support. Personalized recommendation engines powered by LLMs enhance the shopping experience by suggesting relevant products, which has been shown to increase average order values and improve customer retention. Mathematically, the recommendation process can be framed as a function $f(u, i) \rightarrow s$, where uuu represents a user profile, $i$ is an item, and $s$ is the similarity score. This score, based on user behavior and preferences, is used to rank products, delivering those with the highest scores as recommendations. Rust’s high performance enables the rapid processing of user profiles and item databases, making it possible to deliver these recommendations in real time, even for large datasets.
Ethical considerations are paramount when deploying LLMs in customer service and e-commerce, especially around data privacy, algorithmic bias, and transparency. For instance, while personalization can improve customer experience, it must be done in a way that respects user privacy and complies with regulations like GDPR. Customer data must be handled securely, and LLMs should only process information necessary for their task, a practice known as data minimization. Rust’s safety features support secure memory handling, which reduces the risk of data leaks or unintended data access. Bias in recommendations or responses is another challenge; an LLM trained on biased data may inadvertently favor certain demographics over others, affecting customer experience and potentially leading to reputational damage. Mitigation strategies, such as reweighting training data or performing regular audits of model outputs, are essential to ensure fairness. Rust’s precision and efficiency make it possible to implement bias monitoring in real time, ensuring that deployed models continuously align with ethical standards.
This pseudocode outlines a customer service chatbot designed to handle user questions in real time by leveraging a pre-trained Large Language Model (LLM). The chatbot takes user input, interprets it through the LLM, and generates responses, simulating an interactive and responsive experience for customers. This approach showcases how LLMs can be used in customer service to answer questions, provide information, or offer assistance with minimal human intervention. The pseudocode also demonstrates secure, concurrent handling of multiple queries, allowing the chatbot to scale effectively for high-demand applications.
# Import necessary modules for model inference, API handling, and text processing
# Define a structure to receive query input from users
CLASS QueryInput:
ATTRIBUTE question: STRING
# Define the application state to hold the chatbot model
CLASS AppState:
FUNCTION __init__(self, model):
# Store the model in a secure, thread-safe structure
SET self.model TO a thread-safe reference to the LLM model
# Define the endpoint for handling user queries
FUNCTION handle_query_endpoint(input: QueryInput, state: AppState) -> STRING:
# Securely access the model by locking the state
ACQUIRE lock on state.model OR RETURN "Model lock error"
# Tokenize and process the question text for model inference
SET tokens TO model.tokenizer.encode(input.question)
SET output TO model.forward(tokens) OR RETURN "Inference error"
# Generate a response based on the model output (simulated response for demo)
SET response TO "This is a response to your question: " + input.question
# Return the response in a JSON format
RETURN JSON response containing response
# Main function to configure the model and launch the chatbot API
FUNCTION main() -> SUCCESS or ERROR:
# Initialize model configuration and device (e.g., CPU) for inference
SET config TO default configuration for the model
SET device TO CPU
# Load the pre-trained DistilBERT model onto the specified device
SET model TO load DistilBERT model with config on device
# Set up the application state with the loaded model
SET state TO new instance of AppState with model
# Build and configure the API:
INITIALIZE API framework
REGISTER endpoint "/query" with handle_query_endpoint
ATTACH application state for secure, concurrent access
# Launch the API server to handle incoming customer queries
START the API server
# Execute the main function to deploy the chatbot
CALL main()
This pseudocode describes a chatbot application designed to interpret and respond to customer questions. The QueryInput class standardizes user questions, while AppState securely stores the model, enabling concurrent access. In the handle_query_endpoint function, user input is tokenized and processed through the model to generate a response, simulating a real-time answer to the question. The main function sets up the model and API, configuring the necessary resources and launching the server to handle queries. This design highlights the chatbot’s ability to process multiple requests securely and efficiently, illustrating how LLMs can enhance customer service with fast, accurate, and scalable responses.
Real-world case studies showcase how LLMs enhance customer service and e-commerce experiences. For instance, an e-commerce platform implemented an LLM-powered recommendation engine that analyzes browsing behavior, purchase history, and customer reviews to suggest relevant products. The implementation led to a noticeable increase in sales conversion rates and improved customer satisfaction, as users were presented with items aligned with their preferences. Rust’s memory safety features proved beneficial in handling the large datasets typical of e-commerce environments, as they reduced risks related to memory leaks and ensured stable, high-performance recommendations over time.
Current trends in customer service LLMs include the adoption of hybrid approaches combining rule-based and AI-driven responses. In customer service, combining traditional decision trees with LLMs enables bots to handle complex scenarios while retaining clear decision pathways. For example, a rule-based system may handle straightforward account inquiries, while the LLM addresses more complex questions. This approach balances efficiency with flexibility, as it ensures that simple queries are processed quickly, while more nuanced interactions benefit from the LLM’s natural language understanding capabilities. Rust’s low-level control makes it well-suited for managing hybrid systems, where different model components require efficient intercommunication and resource allocation.
Looking to the future, LLMs are expected to further revolutionize customer service and e-commerce, with more advanced features like proactive support and enhanced personalization. Proactive support leverages predictive analytics to anticipate customer needs and provide assistance before the user even initiates contact. For example, if a customer frequently purchases products around a particular time of year, the system could proactively recommend similar products based on that pattern. Mathematically, this is modeled as predicting future behavior $f(u) \rightarrow p$ based on user profile data $u$, with $p$ representing likely next actions. Rust’s performance capabilities support the rapid, continuous analysis needed for predictive models, making it possible to process real-time data and generate proactive recommendations at scale.
In conclusion, the application of LLMs in customer service and e-commerce has already shown significant potential to enhance user experience, improve operational efficiency, and drive sales. By leveraging Rust’s strengths in performance, concurrency, and safety, developers can create robust, scalable systems that deliver real-time responses, handle diverse queries, and ensure data privacy. This section highlights Rust’s unique suitability for building advanced customer service applications, providing a foundation for reliable and high-performing LLM solutions that meet the demands of modern e-commerce and customer service environments.
17.2. Building Data Pipelines for Customer Service and E-commerce
Data pipelines are the backbone of customer service and e-commerce applications that rely on large language models (LLMs), enabling them to process, integrate, and utilize vast and varied datasets. The types of data used in these domains include structured data, such as purchase histories and product catalogs, as well as unstructured data, like customer interaction logs and reviews. Together, these data sources provide the context and insights needed to train models that enhance customer experiences and drive sales. For example, an LLM may leverage purchase histories to recommend personalized products or analyze interaction logs to generate automated responses that align with customer sentiment. Building these pipelines in Rust is advantageous due to its performance, concurrency, and memory safety, all of which are crucial when handling large volumes of real-time, sensitive data. By using Rust-based tools and crates, developers can create efficient, reliable data pipelines that process, standardize, and enrich data for effective LLM training.
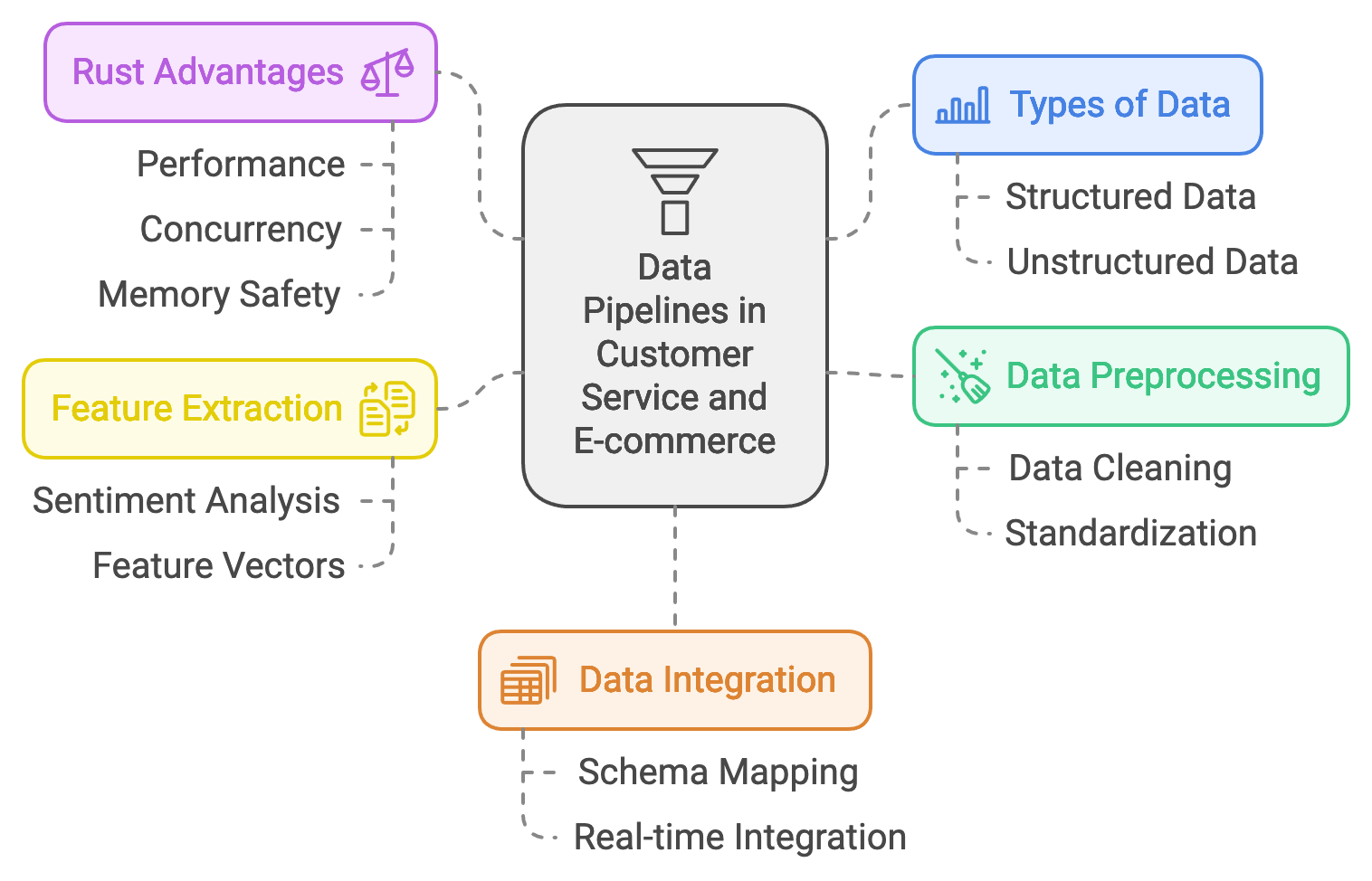
Figure 2: Complexities of building data pipeline for CS and e-Commerce.
Data preprocessing is an essential first step in building robust pipelines for customer service and e-commerce. In raw form, data from e-commerce platforms often contains inconsistencies, missing values, or irrelevant information that could reduce model accuracy. For instance, interaction logs may include non-relevant entries (e.g., “user logged in”) that add noise to training datasets. Data preprocessing cleanses this information, extracting only valuable elements and standardizing data formats. Mathematically, let the raw data $D$ consist of instances $x_i$, where each $x_i$ contains relevant features $f_r$ and noise $f_n$. The preprocessing step $P(D) \rightarrow D'$ isolates $f_r$ by filtering out $f_n$, yielding a refined dataset $D'$ with only relevant features for training. Rust’s serde crate offers powerful serialization and deserialization capabilities that streamline data cleaning and formatting, enabling the pipeline to handle high-throughput data efficiently.
Working with customer service and e-commerce data also necessitates feature extraction to transform unstructured information into structured, model-friendly inputs. For example, a user review might be parsed for sentiment, frequency of product mentions, and identified needs (e.g., “fast delivery”). Feature extraction converts this unstructured input into structured feature vectors, providing LLMs with consistent inputs for training. The transformation can be represented mathematically as a function $T(x) \rightarrow v$, where $x$ is a text input, and $v$ is a feature vector encapsulating sentiment scores, product mentions, and other extracted insights. Rust’s memory safety and type-checking ensure that feature extraction processes maintain data integrity, minimizing risks of corrupted data entries that could negatively impact model performance. By processing these feature vectors in parallel, Rust’s concurrency capabilities also support real-time feature extraction, which is critical for applications like chatbots and recommendation engines that operate in high-traffic environments.
One of the unique challenges of building data pipelines in customer service and e-commerce is managing the diversity and variability of data sources. Customer data may come from transactional databases, interaction logs, CRM systems, or external sources like social media. Each source uses distinct formats and conventions, requiring the pipeline to reconcile and normalize this data. Strategies like schema mapping and data alignment can be applied to harmonize different datasets, ensuring consistent representations. Schema mapping, for example, can transform different data representations into a unified schema, where features from each data source are matched and aggregated into a common format. Mathematically, schema mapping can be represented as a transformation $S(x_i) \rightarrow x_i'$, where $x_i$ from source $S$ is mapped into a common data format $x_i'$. Rust’s strong typing system enforces consistent data schemas, allowing developers to avoid mismatches during integration, while error handling ensures that missing or incompatible data entries are detected early.
Real-time data integration is increasingly important in e-commerce and customer service, where LLMs benefit from up-to-the-minute data to provide accurate responses and personalized recommendations. For instance, real-time data on inventory levels can inform product recommendations, ensuring that users are not suggested items that are out of stock. This type of streaming data is typically handled through a combination of event-based and micro-batching techniques, where data is ingested and processed in near real-time. Let $D_t$ represent data points at time $t$, and $P(D_t)$ the real-time processing function; by processing $D_t$ as it arrives, the pipeline maintains an updated dataset that reflects current customer behavior and inventory levels. Rust’s tokio crate, known for its asynchronous programming capabilities, supports high-performance real-time streaming, allowing the pipeline to handle large volumes of event data with minimal latency. This low-latency processing is essential for LLMs that drive customer-facing applications, where responsiveness significantly impacts user satisfaction.
To demonstrate the practical aspects of building a Rust-based data pipeline for customer service and e-commerce, consider an example where we preprocess, extract features, and integrate customer interaction data to prepare it for LLM training. This pseudocode outlines a data pipeline for preparing customer service and e-commerce queries for training a Large Language Model (LLM). The pipeline ingests raw customer interactions, preprocesses the text by cleaning and normalizing it, extracts key features such as sentiment and product mentions, and structures the data in a format ready for LLM training. By organizing and enriching customer data, this pipeline helps the LLM learn from relevant features, making it more effective in handling customer queries related to product inquiries, sentiments, and more.
# Import necessary modules for data handling and text processing
# Define a structure for raw customer queries
CLASS CustomerQuery:
ATTRIBUTE user_id: STRING
ATTRIBUTE query_text: STRING
# Define a structure for processed data with extracted features
CLASS ProcessedData:
ATTRIBUTE user_id: STRING
ATTRIBUTE sentiment_score: FLOAT
ATTRIBUTE product_mentions: LIST of STRING
# Function to preprocess and extract features from a customer query
FUNCTION process_query(query: CustomerQuery) -> ProcessedData:
# Preprocess the text by converting it to lowercase for normalization
SET normalized_text TO lowercase version of query.query_text
# Feature extraction:
# - Sentiment Analysis: Assign a sentiment score based on keywords
IF "great" in normalized_text THEN
SET sentiment_score TO 1.0
ELSE
SET sentiment_score TO 0.0
# - Product Mentions: Identify product mentions using regular expressions
INITIALIZE product_mentions as an empty LIST
SET product_mention_re TO regular expression matching patterns like "product\d+"
FOR each match in product_mention_re within normalized_text:
ADD matched product mention to product_mentions
# Return processed data with extracted features
RETURN new instance of ProcessedData with:
user_id as query.user_id
sentiment_score as sentiment_score
product_mentions as product_mentions
# Main function to process and display extracted data for each customer query
FUNCTION main():
# Define example raw customer queries
SET raw_queries TO list containing instances of CustomerQuery, e.g.,
CustomerQuery with user_id as "user123", query_text as "Product12 is great!"
CustomerQuery with user_id as "user456", query_text as "Is product34 available?"
# Process each query to extract features
SET processed_data TO list where each query in raw_queries is processed by process_query
# Display the processed data with extracted features
PRINT "Processed Data:", processed_data
# Execute the main function to run the data pipeline
CALL main()
This pseudocode details a data pipeline designed to preprocess and extract features from customer queries, preparing them for LLM training. The CustomerQuery class captures raw customer data, while ProcessedData structures the enriched data. The process_query function normalizes the query text, performs a basic sentiment analysis (assigning a score based on keywords), and uses regular expressions to identify any product mentions within the query. In main, a sample list of raw customer queries is processed using process_query, generating structured data with features like sentiment scores and product mentions, which are then displayed. This pipeline improves the quality of data available for LLM training, enabling more accurate responses to customer service inquiries.
Industry applications of such data pipelines highlight the impact of high-quality, real-time data on customer engagement and satisfaction. For example, a leading e-commerce platform implemented a pipeline to integrate purchase history, browsing behavior, and customer interactions in real time. This enriched dataset trained an LLM-powered recommendation engine, which dynamically adapted to customer preferences as they navigated the site. The results were significant, with increased user engagement, higher average order values, and a measurable boost in customer satisfaction. Rust’s performance and reliability enabled the platform to process these data streams with minimal latency, ensuring that recommendations were based on the latest customer interactions.
The latest trends in data pipelines for customer service and e-commerce emphasize the importance of streaming data and edge processing. Streaming data enables platforms to ingest data continuously, while edge processing allows data to be processed closer to the source, such as on customer devices or local servers. By processing data at the edge, businesses can reduce latency and enhance privacy, as sensitive information does not need to be transmitted to centralized servers. Rust’s support for low-level systems programming makes it ideal for developing edge processing solutions, enabling businesses to build data pipelines that operate directly on user devices or local servers, reducing network dependencies and enhancing responsiveness.
In conclusion, data pipelines are essential for harnessing the full potential of LLMs in customer service and e-commerce, enabling businesses to transform raw data into structured, actionable insights. By using Rust’s powerful data handling, memory safety, and concurrency, developers can build pipelines that efficiently process, extract, and integrate data, supporting real-time personalization and responsive customer interactions. This section emphasizes Rust’s unique advantages in building reliable, high-performance data pipelines for LLM-driven applications, paving the way for more responsive, personalized, and efficient customer service and e-commerce experiences.
17.3. Training LLMs on Customer Service and E-commerce Data
Training large language models (LLMs) on customer service and e-commerce data involves unique considerations that distinguish it from other domains. Customer service applications require handling diverse queries, ranging from basic information requests to complex problem resolutions, while e-commerce applications benefit from personalization that aligns recommendations and responses with individual user preferences. This diversity of user interactions creates challenges for training, as the model must learn to generalize effectively while maintaining the flexibility to respond to a wide variety of user needs. Additionally, user personalization is essential in e-commerce; models need to understand purchase patterns, browsing behaviors, and feedback to provide meaningful product recommendations and ensure customer satisfaction. Rust’s ecosystem, featuring libraries like burn and candle, provides efficient tools for building, training, and deploying LLMs on the large-scale datasets typically associated with customer service and e-commerce, enabling both robust data handling and high-performance processing.
For customer service and e-commerce applications, transfer learning and fine-tuning are invaluable techniques. Transfer learning leverages pre-trained models, such as GPT or BERT, which have been trained on extensive general-purpose datasets, and adapts them to customer-specific tasks. This process can be represented as minimizing the task-specific loss $L_{task}(\theta)$ on a dataset $D_{cs}$ specific to customer service or e-commerce, where $\theta$ represents the model parameters. Fine-tuning involves optimizing these parameters on the customer service data, enabling the model to retain the foundational language knowledge from the pre-trained model while specializing in the specific patterns, intents, and preferences typical of customer interactions. Rust’s high efficiency and low-level control support the fine-tuning process, as it allows developers to manage memory and processing tasks optimally, ensuring that even large datasets are handled effectively without incurring prohibitive computational costs.
Training LLMs on customer service and e-commerce data presents several challenges, especially given the variability in user queries. Customer interactions often lack structure, and language usage can vary greatly depending on the user’s style, mood, and cultural context. This variability requires models to be robust in generalizing across diverse inputs while still producing contextually relevant responses. Personalization adds an additional layer of complexity; for instance, when a user repeatedly purchases items in a specific category, the model must learn to incorporate this information to enhance future recommendations. To mathematically model personalization, let $U$ be the set of users, $I$ the set of items, and $f(u, i)$ the function predicting the relevance of item $i$ for user $u$. Personalization can then be implemented by maximizing $f(u, i)$ based on historical data for $u$, adapting the model to recommend the most relevant items in future interactions. Rust’s ability to handle complex data transformations with precision ensures that this information is integrated accurately and securely, supporting the development of models that can respond to the unique preferences of individual users.
Model explainability and interpretability are crucial in customer service applications, where model responses need to be clear and trustworthy to foster positive user interactions. In scenarios such as query resolution, users must feel confident that the system’s recommendations and responses are accurate and aligned with their needs. Explainability techniques, such as attention weights and attribution scores, help in understanding how models prioritize different words or sentences in a query, allowing developers to ensure that outputs are actionable and relevant. Let $A(x)$ represent the attention score assigned to token $x$ in an input sentence; high values of $A(x)$ suggest greater relevance to the final output. By tracking and evaluating these scores, developers can fine-tune the model to emphasize essential parts of a query. Rust’s structured error handling and debugging capabilities aid in developing explainable models by making it easier to trace model behaviors during training, ensuring that customer-facing applications provide responses that are both accurate and transparent.
Bias mitigation is also a fundamental aspect of training LLMs on customer service and e-commerce data, where biased recommendations or responses could adversely impact customer trust and satisfaction. For example, an LLM that over-recommends high-cost products may lead to user frustration and distrust. Bias in model training can be detected by evaluating output distributions across various demographic groups, ensuring fairness in recommendations and query responses. Mathematically, fairness can be quantified using the disparate impact ratio, $\frac{P(y|G=A)}{P(y|G=B)}$, which measures the model’s output consistency across demographic groups $A$ and $B$. Rust’s concurrency and performance make it feasible to monitor these metrics during model training, enabling continuous bias checks and adjustments. By implementing bias monitoring directly into the training pipeline, Rust-based applications can ensure that LLM outputs remain fair and balanced, supporting ethical AI practices in customer service and e-commerce.
The following example demonstrates a Rust-based training pipeline for fine-tuning a customer service-specific LLM. This pseudocode describes a training pipeline designed to fine-tune a customer service-specific Large Language Model (LLM). The pipeline prepares customer queries and responses, loading and training the model in batch iterations. Through data preprocessing, the pipeline transforms text data into tensors that the model can interpret. This allows the model to learn patterns in customer inquiries and appropriate responses, improving its performance in customer service interactions.
# Import necessary modules for tensor operations, model configuration, and random data shuffling
# Define a structure to hold training data pairs of customer queries and responses
CLASS QueryResponsePair:
ATTRIBUTE query: STRING
ATTRIBUTE response: STRING
# Function to preprocess customer queries and responses for training
FUNCTION preprocess_data(data: LIST of QueryResponsePair) -> LIST of TUPLES (TENSOR, TENSOR):
RETURN list where each pair in data is converted to:
- input_tensor as a tensor representation of the query text
- response_tensor as a tensor representation of the response text
# Training loop to fine-tune the customer service model
FUNCTION train_model(model: MODEL, data: LIST of TUPLES (TENSOR, TENSOR), epochs: INTEGER) -> SUCCESS or ERROR:
FOR each epoch in range(epochs):
# Shuffle data at the beginning of each epoch
SET shuffled_data TO randomly shuffled copy of data
FOR each (input, target) in shuffled_data:
# Perform a forward pass to generate a prediction
SET prediction TO model.forward(input)
# Calculate loss (Mean Squared Error for simplicity)
SET loss TO (prediction - target) squared and summed
# Perform backpropagation and update model weights
CALL loss.backward()
CALL model.update_weights()
RETURN success
# Main function to initialize and run the training pipeline
FUNCTION main() -> SUCCESS or ERROR:
# Configure and load the model onto the specified device (e.g., CPU)
SET config TO default configuration for the model
SET device TO CPU
SET model TO load DistilBERT model with config on device
# Define sample training data with customer queries and responses
SET data TO list containing instances of QueryResponsePair, e.g.,
QueryResponsePair with query as "What is the return policy?", response as "You can return items within 30 days."
QueryResponsePair with query as "Is this item available in size medium?", response as "Yes, size medium is available."
# Preprocess the data to convert queries and responses to tensors
SET processed_data TO preprocess_data(data)
# Train the model using the processed data
CALL train_model(model, processed_data, epochs = 10)
PRINT "Training completed successfully"
RETURN success
# Execute the main function to start the training process
CALL main()
This pseudocode outlines a training pipeline for fine-tuning an LLM to handle customer service queries. The QueryResponsePair class holds pairs of customer inquiries and their corresponding responses, which are essential for training. The preprocess_data function processes this data by converting the queries and responses into tensors, making it suitable for model training. In train_model, a shuffled batch of data is used for each epoch, where the model makes predictions, calculates loss using Mean Squared Error, and updates its weights via backpropagation. The main function configures the model, preprocesses the training data, and initiates the training loop. This design showcases a structured and efficient pipeline that allows the LLM to learn and improve its ability to generate relevant responses to customer queries, making it suitable for customer service applications.
Industry applications underscore the impact of training customer service-specific LLMs. For instance, a global retail company implemented an LLM fine-tuned on customer queries, enabling it to provide personalized recommendations and answer product-related questions. This deployment improved response accuracy and customer satisfaction, as users received prompt, relevant answers to their questions. Rust’s speed and memory efficiency allowed the company to handle a large query volume without sacrificing response times, supporting real-time interactions and maintaining a high level of personalization in recommendations.
Emerging trends in training LLMs for customer service and e-commerce include adaptive models capable of learning from real-time user interactions. For example, models could adjust to changes in product availability or respond to trending customer inquiries without requiring extensive retraining. Transfer learning techniques, like zero-shot or few-shot learning, are also gaining traction, as they allow models to generalize from minimal examples, adapting quickly to new customer service scenarios. Rust’s capability to manage low-latency, continuous data processing makes it an ideal language for implementing these adaptive features, supporting real-time model updates and response adaptations.
In conclusion, training LLMs on customer service and e-commerce data using Rust offers a pathway to developing responsive, personalized, and fair AI applications. By addressing the challenges of diverse data handling, personalization, and bias mitigation, developers can leverage Rust’s performance, safety, and concurrency features to build training pipelines that meet the demands of modern customer-facing applications. This section highlights how Rust’s robust ecosystem supports efficient and scalable training solutions, enabling businesses to enhance user satisfaction and operational efficiency with high-performance, customer-centric LLMs.
17.4. Inference and Deployment
The inference process for customer service and e-commerce LLMs requires special attention to latency, accuracy, and scalability due to the real-time demands of these environments. In applications such as chatbots, recommendation engines, and customer support automation, even slight delays in response can impact the user experience, potentially reducing customer satisfaction and conversion rates. For instance, a chatbot must process customer inquiries, generate responses, and communicate them with minimal delay to create a natural, engaging interaction. In recommendation systems, LLMs generate personalized suggestions based on a user’s recent behavior and preferences, requiring efficient data processing to deliver up-to-date, relevant results. Rust’s performance optimization, memory safety, and concurrency capabilities make it an ideal choice for implementing inference pipelines that meet these high-performance requirements. By leveraging Rust’s strengths, developers can build scalable inference solutions capable of handling the high traffic typical of customer service and e-commerce platforms.
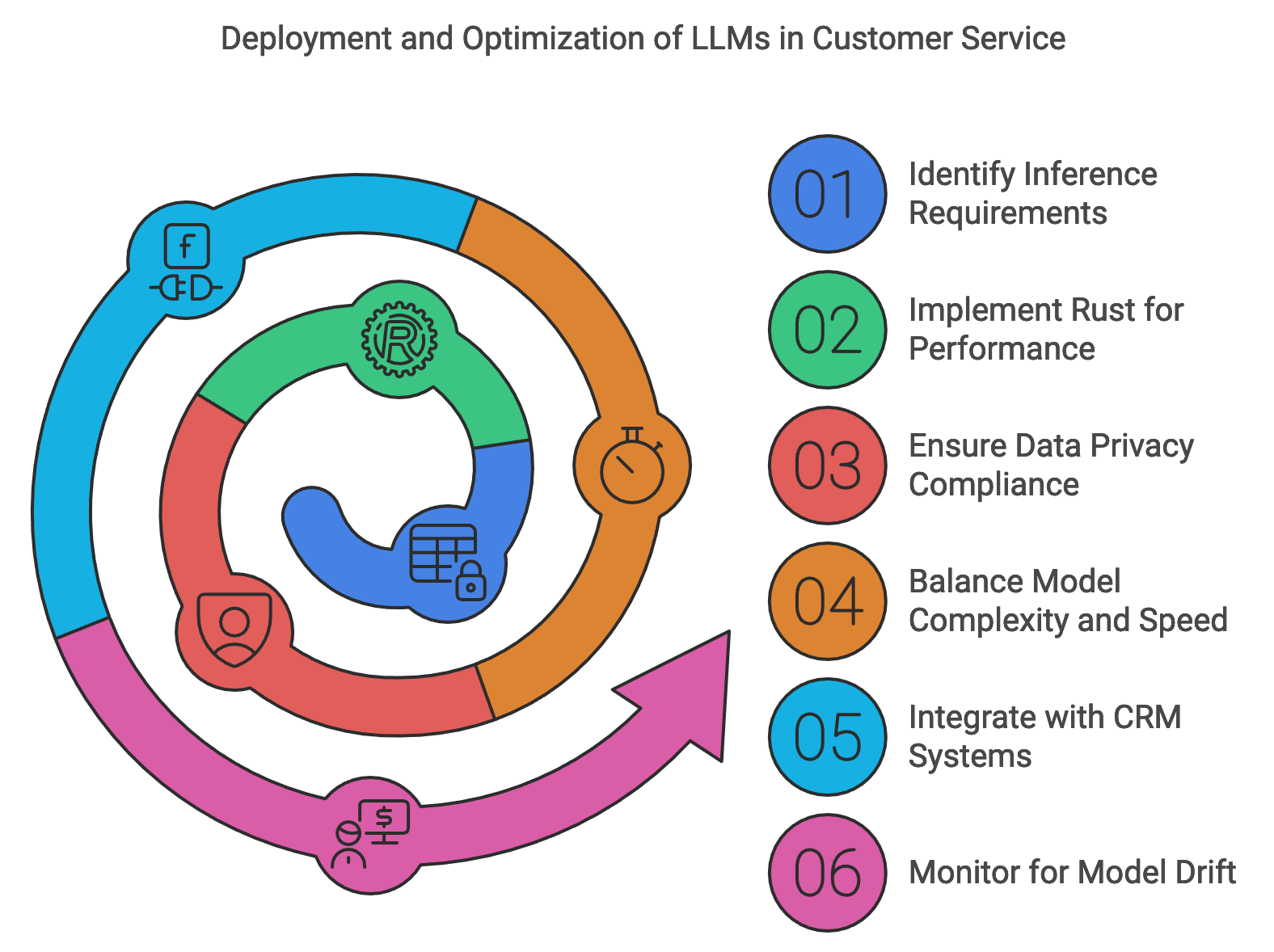
Figure 3: The flow of deployment and optimization.
Deployment strategies for customer service LLMs must also prioritize compliance with data privacy regulations, such as GDPR or CCPA, and adhere to industry-specific standards. Real-time inference systems often process sensitive customer data—such as personal identifiers, purchase histories, and interaction logs—which necessitates robust data handling practices. Rust’s memory safety and secure data handling help protect sensitive information during model inference, reducing the risk of data leaks and ensuring that the application remains compliant. Additionally, deployment strategies should incorporate data minimization, encrypt sensitive data in transit, and enforce strict access controls to safeguard user privacy. These measures allow customer service and e-commerce applications to use LLMs to enhance user experience while maintaining legal and ethical standards in data management.
In high-traffic environments like e-commerce, balancing model complexity and inference speed is crucial. Large and complex models can deliver higher accuracy and more nuanced responses, but they also incur greater latency and resource demands, which may hinder responsiveness. Mathematically, let $T(f(x))$ represent the latency of an inference function $f(x)$, where model complexity $C(f)$ affects the latency linearly or quadratically. Reducing $C(f)$ via techniques like model quantization, knowledge distillation, or caching strategies can minimize latency while retaining most of the model’s performance capabilities. For instance, quantization reduces the bit precision of model weights, decreasing memory and computational demands without significantly compromising accuracy. Rust’s control over low-level operations enables efficient implementation of such optimizations, as it can handle intensive mathematical operations required in quantization and caching effectively, creating an optimal balance between complexity and inference speed.
Deploying LLMs in customer service environments also involves challenges related to integrating these models with existing Customer Relationship Management (CRM) systems, chat interfaces, and databases. In many cases, models must access real-time customer data, such as recent purchases or past interactions, to tailor responses accurately. Integration with CRM systems enables this access, but it also requires careful handling of data dependencies to avoid bottlenecks. For instance, a CRM-integrated LLM might pull recent interactions and purchase data to provide contextually relevant recommendations during a live chat session. Rust’s efficient, thread-safe concurrency model is ideal for these high-throughput integrations, allowing models to interact with CRM systems, APIs, and databases concurrently and securely. This enables the system to process multiple queries and generate responses at scale, a critical requirement in customer service applications where user interactions are often concurrent.
Monitoring and maintaining deployed LLMs is another vital component of successful deployment, especially given the need to manage model drift over time. Model drift occurs when a model’s accuracy decreases due to changes in data distribution or customer behavior patterns. For example, an LLM trained on customer queries may lose relevance as new slang or phrases emerge, reducing its ability to accurately interpret customer intentions. To detect model drift, a monitoring system can track key metrics such as accuracy, response relevance, and user satisfaction. Mathematically, let $P(y|x; \theta_t)$ represent the model’s predicted probability distribution at time ttt; changes in this distribution over time $\Delta P(y|x) = P(y|x; \theta_t) - P(y|x; \theta_0)$ indicate potential drift. Rust’s robust error handling and logging capabilities make it easy to set up real-time monitoring that alerts administrators to deviations from baseline metrics, facilitating timely updates to the model.
To demonstrate a practical implementation, the following Rust code provides a basic inference pipeline for a customer service LLM deployed as an API. This pseudocode outlines an inference pipeline for a customer service Large Language Model (LLM) deployed as a scalable API. The pipeline handles incoming user queries, processes them in real time, and returns model-generated responses. Optimized for concurrency, this design ensures the LLM can serve multiple customer requests simultaneously, making it suitable for high-traffic environments where prompt responses are essential.
# Import necessary modules for model inference, API handling, and concurrency management
# Define a structure to receive user query input
CLASS QueryInput:
ATTRIBUTE question: STRING
# Define application state to hold the LLM model for processing queries
CLASS AppState:
FUNCTION __init__(self, model):
# Store the model in a secure, thread-safe structure
SET self.model TO a thread-safe reference to the LLM model
# Define the endpoint to handle customer queries
FUNCTION handle_query_endpoint(input: QueryInput, state: AppState) -> STRING:
# Securely access the model by locking the state
ACQUIRE lock on state.model OR RETURN "Model lock error"
# Tokenize and process the query text for model inference
SET tokens TO model.tokenizer.encode(input.question)
SET output TO model.forward(tokens) OR RETURN "Inference error"
# Generate a response based on the model's output
SET response TO "Response: " + output.to_string()
# Return the response in a JSON format
RETURN JSON response containing response
# Main function to configure the model and launch the API server
FUNCTION main() -> SUCCESS or ERROR:
# Initialize model configuration and device (e.g., CPU) for inference
SET config TO default configuration for the model
SET device TO CPU
# Load the pre-trained DistilBERT model onto the specified device
SET model TO load DistilBERT model with config on device
# Set up the application state with the loaded model
SET state TO new instance of AppState with model
# Build and configure the API:
INITIALIZE API framework
REGISTER endpoint "/query" with handle_query_endpoint
ATTACH application state for secure, concurrent access
# Launch the API server to handle incoming customer queries
START the API server
# Execute the main function to deploy the inference pipeline
CALL main()
This pseudocode provides a structured approach to deploying a customer service LLM as an API, enabling real-time query handling. The QueryInput class stores the incoming user query text, while the AppState class securely manages the LLM model, ensuring thread-safe access for concurrent requests. In the handle_query_endpoint function, user input is tokenized and processed through the model, generating a response based on the model’s output. The main function initializes the model configuration and API framework, attaching the endpoint and enabling concurrent access to the model. This design is optimized for handling high traffic, making it an effective solution for real-time customer service applications that require reliable, efficient, and scalable query processing.
In industry, several organizations have successfully deployed LLMs in customer service to streamline operations and enhance user engagement. For example, an e-commerce platform integrated an LLM into its customer service chatbot, which efficiently handled common queries, processed product recommendations, and directed users to appropriate support channels. This deployment resulted in increased customer satisfaction and reduced wait times, as users received quick, accurate answers and personalized recommendations. Rust’s efficiency was instrumental in maintaining the platform’s response times, ensuring smooth user interactions even during peak traffic periods.
Current trends in LLM deployment for customer service and e-commerce highlight the growing importance of real-time recommendations and personalized user experiences. Real-time inference enables models to consider a user’s most recent interactions, such as items recently viewed or added to a cart, to generate recommendations. Rust’s performance characteristics are ideal for building these low-latency inference pipelines, as they allow the system to adapt to user behavior dynamically, creating a more engaging experience. Additionally, advancements in federated learning offer new deployment models where LLMs can be fine-tuned based on localized data, reducing the need for centralized data storage and enhancing user privacy. Rust’s security and low-level control make it a viable choice for implementing federated learning, supporting decentralized deployments that align with privacy-focused customer service solutions.
In conclusion, the deployment of LLMs in customer service and e-commerce applications requires carefully balanced considerations of latency, accuracy, scalability, and compliance. By using Rust’s high-performance capabilities, developers can create inference pipelines that deliver real-time, accurate responses while integrating with existing CRM systems and adhering to data privacy regulations. This section highlights how Rust’s strengths facilitate the development of secure, reliable, and scalable LLM deployments that enhance user experience and operational efficiency in customer service and e-commerce settings. With Rust, organizations can build robust AI-driven systems that respond to the unique demands of high-traffic environments, positioning them for future growth and innovation in customer engagement.
17.5. Ethical and Regulatory Considerations
Deploying large language models (LLMs) in customer service and e-commerce raises crucial ethical and regulatory concerns, including bias, fairness, and data privacy. These challenges are especially pertinent given the growing reliance on AI-driven systems to interact with customers, influence purchase decisions, and build brand reputation. In high-traffic environments, LLMs influence a large number of interactions daily, so maintaining ethical standards is essential to avoid amplifying biases or compromising user privacy. Bias in customer service LLMs, for example, could lead to differential treatment of customers based on gender, ethnicity, or socio-economic status. Rust’s features, including its strong type safety, memory security, and performance, make it a powerful tool for building ethical and reliable LLM systems. With Rust, developers can implement mechanisms that detect and mitigate biases, ensure transparency, and uphold data privacy, fostering user trust and compliance with regulatory standards.
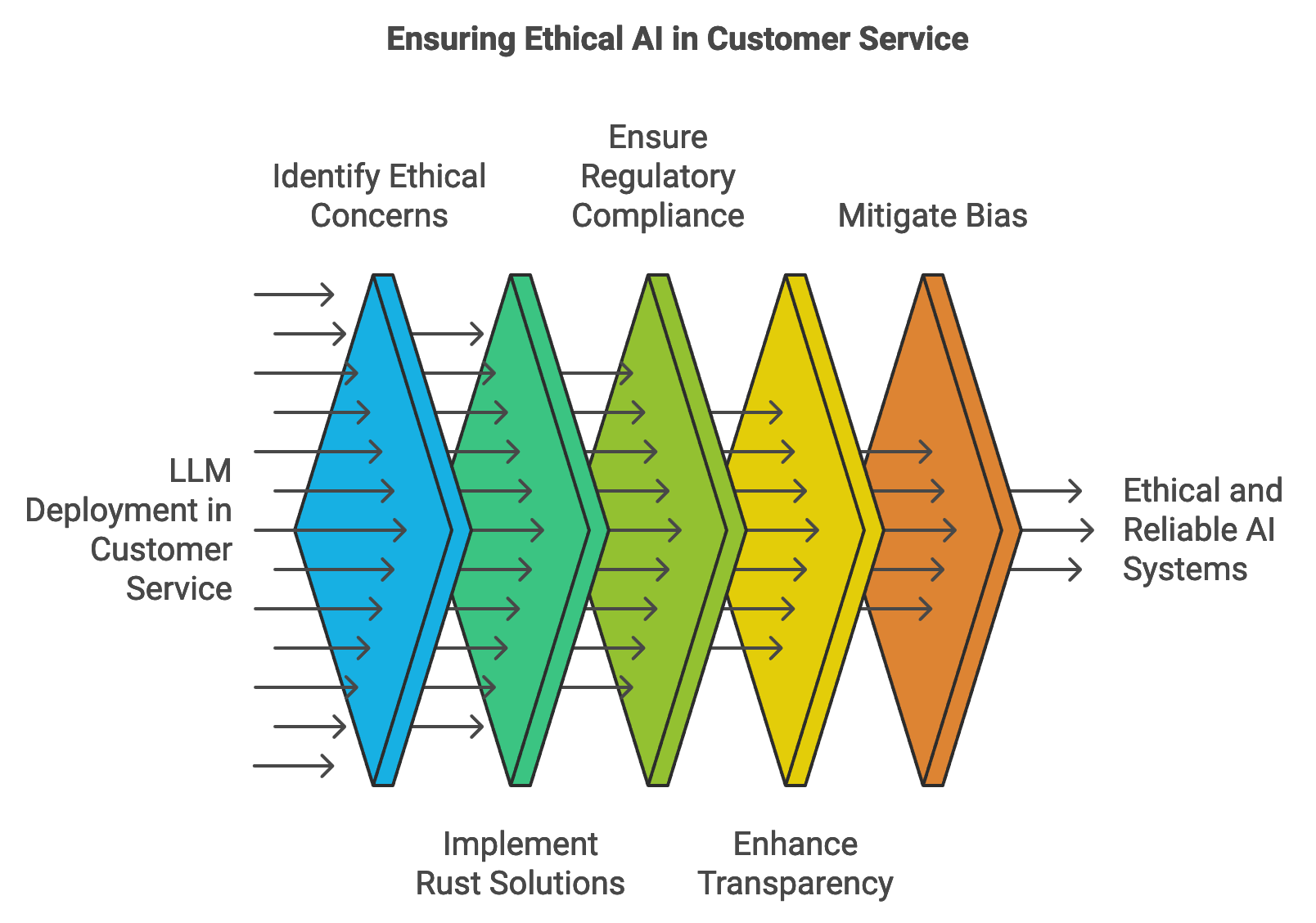
Figure 4: Process of Reliable and Ethical AI in Customer Service.
In customer service and e-commerce, regulatory frameworks like the General Data Protection Regulation (GDPR) in Europe, the California Consumer Privacy Act (CCPA) in the U.S., and industry-specific standards guide the responsible use of AI and data management. GDPR and CCPA enforce strict rules on data collection, user consent, and data processing, particularly emphasizing the right of users to access, delete, or control their personal data. For LLMs that process sensitive information—such as customer purchase histories or chat logs—compliance with these frameworks is essential. Rust’s memory safety and data management capabilities allow developers to implement secure data handling practices, including data minimization, anonymization, and encryption, reducing the risks of data leaks or unauthorized access. Compliance strategies built in Rust can include encryption at rest and in transit, as well as automated data purging mechanisms that ensure data retention policies are enforced within the model’s training and inference pipeline.
Transparency and accountability are critical for gaining user trust and meeting regulatory requirements in customer service AI applications. In high-stakes environments where LLMs influence customer support, product recommendations, and transaction processing, transparency about how decisions are made can prevent user frustration and build confidence. Explainability techniques, such as feature importance analysis and attention mapping, help clarify why a model suggested a particular response or recommendation. Mathematically, this can be formalized as calculating the attention weights $A(x)$ for each token $x$ in a query or input text, where higher values indicate the importance of specific tokens in generating the output. By tracking these weights, developers can identify which parts of the user input most influenced the model’s response. Rust’s robust error handling and debug capabilities support the development of transparent systems, as they allow detailed logging of model behaviors and enable developers to pinpoint factors influencing model outputs, especially in case of unexpected behaviors.
Bias detection and mitigation are key components of responsible AI deployment in customer service and e-commerce. An LLM trained on biased data may inadvertently favor or disadvantage certain groups, which can harm brand reputation and customer trust. Bias mitigation often involves identifying disparities in the model’s outputs across different demographic groups. For example, a model that consistently suggests higher-priced products to certain demographics may be exhibiting biased behavior. Bias can be quantified by comparing output distributions using metrics such as disparate impact ratio, $\frac{P(y|G=A)}{P(y|G=B)}P(y∣G=B)$, where $A$ and $B$ are distinct demographic groups. Rust’s efficient concurrency allows real-time monitoring of these metrics, making it feasible to implement bias checks directly within the model’s deployment pipeline. Additionally, mitigation techniques like reweighting and oversampling can be applied in the training phase, allowing Rust’s data processing capabilities to efficiently adjust sample weights or proportions, thereby ensuring fairer outcomes in the model’s predictions.
A practical Rust-based approach to bias detection in an e-commerce LLM involves tracking output patterns and flagging potential biases. This pseudocode illustrates a bias detection tool for an e-commerce recommendation system that identifies potential pricing biases across different demographic groups. By analyzing the average recommended product prices for each group, the tool highlights any discrepancies that may suggest unfair treatment or implicit bias in the model’s recommendations. Such a bias monitoring tool helps ensure equitable experiences for all users, which is essential in customer-facing applications.
# Import necessary modules for data handling and statistics
# Define a structure to store individual recommendations
CLASS Recommendation:
ATTRIBUTE user_id: STRING
ATTRIBUTE demographic: STRING # Demographic label, e.g., "gender_male"
ATTRIBUTE recommended_price: FLOAT # Average price of recommended products
# Function to calculate average recommended price by demographic group
FUNCTION detect_price_bias(recommendations: LIST of Recommendation) -> DICTIONARY of STRING to FLOAT:
INITIALIZE totals as an empty DICTIONARY with default FLOAT value 0.0
INITIALIZE counts as an empty DICTIONARY with default INTEGER value 0
# Sum recommended prices and counts for each demographic group
FOR each recommendation in recommendations:
SET group TO recommendation.demographic
ADD recommendation.recommended_price TO totals[group]
INCREMENT counts[group] by 1
# Calculate the average recommended price for each demographic group
SET bias_report TO an empty DICTIONARY
FOR each (group, total) in totals:
SET count TO counts[group]
SET average_price TO total / count
STORE average_price in bias_report[group]
RETURN bias_report
# Main function to demonstrate bias detection in recommendations
FUNCTION main():
# Define sample recommendation data with demographic labels and recommended prices
SET recommendations TO list containing instances of Recommendation, e.g.,
Recommendation with user_id as "user123", demographic as "gender_male", recommended_price as 150.0
Recommendation with user_id as "user456", demographic as "gender_female", recommended_price as 130.0
# Add more recommendations as needed
# Run price bias detection on the recommendation data
SET bias_report TO detect_price_bias(recommendations)
# Output the bias detection report
PRINT "Price Bias Detection Report:", bias_report
This pseudocode defines a bias detection pipeline to identify pricing disparities in an e-commerce recommendation system. The Recommendation class stores individual recommendations with attributes for user ID, demographic label, and the recommended product price. The detect_price_bias function iterates through the recommendation data, calculating the total prices and count of recommendations for each demographic group. It then computes the average price per group and stores these averages in bias_report. The main function demonstrates this tool with sample data, generating a report that flags potential pricing biases. This setup provides a straightforward yet effective means of monitoring model fairness and ensuring that recommendations align equitably across different demographic groups, enhancing the user experience.
Developing a compliance checklist for customer service and e-commerce LLMs can help ensure adherence to regulatory frameworks and ethical standards. A comprehensive compliance checklist might include data minimization practices (only collecting necessary data), user consent verification, automated data purging, and regular bias audits. Implementing these practices in Rust allows for precise control over data handling, memory management, and encryption, supporting secure and compliant AI systems. Rust’s error-handling capabilities enable developers to add compliance checkpoints within the inference pipeline, ensuring that data privacy standards are met continuously and that any compliance violations are flagged immediately.
Industry applications demonstrate the importance of ethical and regulatory compliance in AI-driven customer service and e-commerce. A global retailer recently implemented an LLM to assist with customer support and product recommendations, ensuring compliance with GDPR and other data protection regulations. The deployment included bias detection to monitor recommendation patterns and avoid inadvertently favoring certain customer demographics. Using Rust for this deployment ensured that data privacy controls were robust, data access was secure, and model outputs were continuously audited for fairness. This approach enabled the company to provide high-quality, AI-driven recommendations while aligning with regulatory requirements and ethical standards, thereby maintaining trust with its customer base.
Emerging trends in responsible AI for customer service emphasize the need for more explainable and user-controllable models. For example, personalized recommendation systems are moving towards providing users with control over their own recommendations, allowing them to adjust preferences or indicate disinterest in certain categories. These systems are made more secure and efficient with Rust’s memory safety and concurrency features, which support the real-time processing and security protocols required to protect user preferences and personal data. Furthermore, federated learning—a technique that enables models to be trained on decentralized data without sharing user information—offers a promising direction for ensuring data privacy while allowing models to continuously improve. Rust’s security features and performance make it suitable for federated learning applications, where maintaining data privacy across distributed devices is critical.
In conclusion, ethical and regulatory considerations in customer service and e-commerce LLMs are essential for building responsible, trustworthy AI systems. By addressing issues of bias, transparency, and data privacy, developers can ensure that LLM deployments align with both ethical and regulatory standards, fostering user trust and compliance with laws such as GDPR and CCPA. Rust’s performance, safety, and control over data handling make it an ideal choice for implementing responsible AI practices, supporting the development of fair, transparent, and secure LLM systems in customer service and e-commerce. This section emphasizes the need for continuous monitoring, compliance adherence, and transparent design in AI applications, underscoring Rust’s unique strengths in building ethical, high-performance customer service solutions that respect user rights and enhance brand reputation.
17.6. Case Studies and Future Directions
Case studies in customer service and e-commerce showcase the transformative impact of LLMs on customer interactions and operational efficiency. Companies leveraging LLMs in these areas often face significant challenges—such as scalability, latency, and personalization—but many have implemented innovative solutions that successfully address these issues. For example, a major e-commerce platform deployed an LLM-driven recommendation system that analyzes user purchase histories, browsing behaviors, and past interactions to generate hyper-personalized suggestions. By combining real-time data ingestion with model fine-tuning, this system continuously adapts to changing user preferences, ensuring that recommendations remain relevant. Rust’s performance capabilities were instrumental in supporting the high-volume, real-time data processing needed for such an application, as it provided low-latency responses essential to seamless customer interactions. Through these case studies, we observe that the combination of well-designed LLMs and Rust’s powerful performance features can enable customer service applications that handle complex tasks at scale, improving both user satisfaction and operational efficiency.
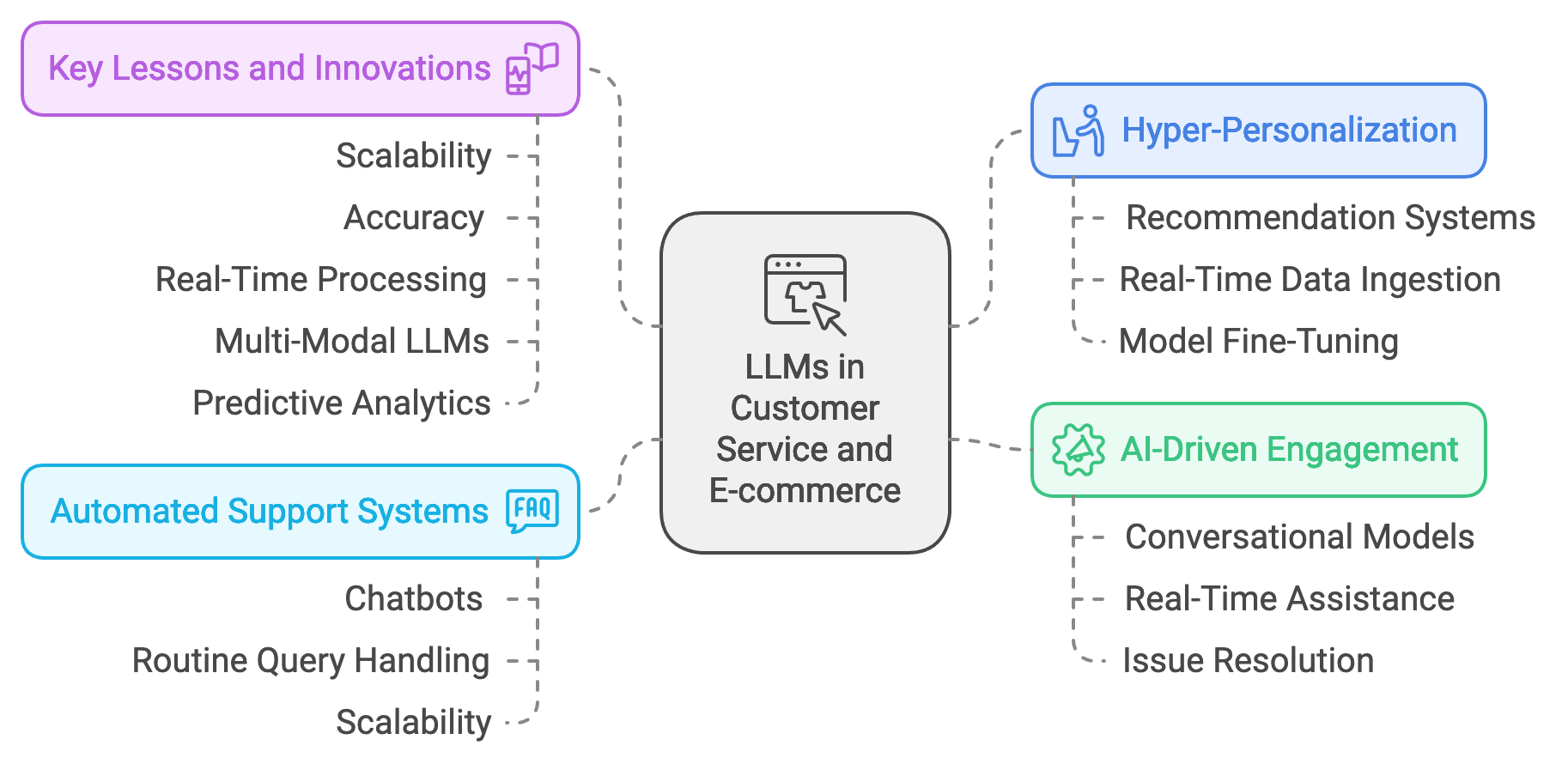
Figure 5: Trends of LLMs in CS and e-Commerce.
Emerging trends in the use of LLMs for customer service and e-commerce highlight a shift towards hyper-personalization and AI-driven customer engagement. In hyper-personalized recommendation systems, models are fine-tuned to capture subtle nuances in user preferences, behaviors, and context. These models often employ additional techniques, such as real-time feature engineering and reinforcement learning, to optimize their recommendations. Mathematically, we can represent the personalization function as $f(u, p, t) \rightarrow r$, where $u$ is the user profile, $p$ is the product information, $t$ represents the context (e.g., time of day, season), and $r$ is the relevance score of the recommendation. Rust’s memory control and concurrency capabilities make it ideal for implementing these complex calculations in real-time, supporting the high-speed data retrieval and processing required to generate meaningful, hyper-personalized recommendations on demand. AI-driven customer engagement, on the other hand, leverages conversational models to provide real-time assistance, resolve customer issues, and answer queries, reducing the load on human support agents and enhancing the customer experience.
LLMs also hold promise in transforming the customer service landscape through automated support systems. LLMs trained on past customer interactions can answer routine queries, assist with order tracking, and provide product information, delivering support that is accessible, consistent, and available 24/7. For instance, a global retailer deployed a chatbot capable of handling more than 70% of customer inquiries without human intervention, thanks to an LLM fine-tuned on a diverse dataset of customer support cases. This resulted in significant time savings for support teams, allowing them to focus on more complex cases. The model’s inference speed, supported by Rust, ensured that the system could respond to queries in under a second, maintaining customer engagement and satisfaction. This deployment also demonstrated the importance of scalability, as the model handled thousands of interactions simultaneously across global markets.
Analyzing these case studies reveals several key lessons and best practices for future customer service and e-commerce LLM projects. Scalability is a consistent theme; successful deployments are designed to handle high volumes of concurrent users with minimal latency. Accuracy and user satisfaction also remain central goals, achieved through ongoing model fine-tuning and bias monitoring. Additionally, these cases underscore the importance of real-time data processing. Hyper-personalized applications often require the integration of live data streams from CRM systems or purchase histories to ensure that the model’s responses and recommendations reflect the most recent user behavior. Rust’s low-level control over memory management, along with its ability to handle concurrent processing, makes it especially suited for these scenarios. The language’s efficiency allows systems to process live data, update models on-the-fly, and handle high-demand environments without compromising response times or data accuracy.
Opportunities for innovation using LLMs in customer service and e-commerce are expanding, especially as businesses seek new ways to engage users. For instance, the development of multi-modal LLMs—capable of processing text, image, and audio inputs—enables richer, more interactive customer interactions. A multi-modal model could allow a user to upload a photo of an item they’re looking for, which the model could then match to similar products in an e-commerce catalog. This requires real-time feature extraction across different data modalities, a computationally intensive task well-suited for Rust’s performance advantages. Another area ripe for innovation is predictive analytics, where LLMs are used to forecast customer behavior, recommend proactive support measures, or identify patterns in customer feedback to improve services. Mathematically, predictive analytics can be represented as $P(y | X)$, where $y$ is the predicted behavior (e.g., likelihood to purchase) and $X$ represents the set of features derived from customer interactions. Rust’s capabilities in handling large datasets make it a practical choice for implementing predictive analytics in customer-facing applications, allowing models to deliver timely, data-driven insights.
Implementing a small-scale version of one of these case studies in Rust demonstrates the feasibility of building an LLM-powered recommendation engine that adapts to user preferences. This pseudocode describes a personalized recommendation engine that uses a Large Language Model (LLM) to adapt product suggestions based on user interactions. The system processes user activity data, such as purchase frequency or ratings, to identify patterns in each user’s preferences. This approach offers a basic foundation for creating more advanced recommendation engines by dynamically adjusting suggestions to align with individual user behavior.
# Import necessary modules for model inference and data handling
# Define a structure to store each user interaction with products
CLASS UserInteraction:
ATTRIBUTE user_id: STRING
ATTRIBUTE product_id: STRING
ATTRIBUTE interaction_score: FLOAT # e.g., purchase frequency or rating
# Function to process user interactions and generate product recommendations
FUNCTION generate_recommendations(user_id: STRING, interactions: LIST of UserInteraction, model: MODEL) -> LIST of STRING:
# Aggregate interactions specific to the given user
INITIALIZE user_interactions as an empty DICTIONARY with default FLOAT value 0.0
FOR each interaction in interactions:
IF interaction.user_id equals user_id THEN
STORE interaction.interaction_score in user_interactions[interaction.product_id]
# Generate personalized product recommendations based on interaction scores
INITIALIZE recommended_products as an empty LIST
FOR each (product_id, score) in user_interactions:
ADD formatted string of product_id and score to recommended_products
RETURN recommended_products
# Main function to set up and run the recommendation engine
FUNCTION main() -> SUCCESS or ERROR:
# Initialize model configuration and device (e.g., CPU) for inference
SET config TO default configuration for the model
SET device TO CPU
SET model TO load DistilBERT model with config on device
# Define sample interaction data
SET interactions TO list containing instances of UserInteraction, e.g.,
UserInteraction with user_id as "user123", product_id as "productA", interaction_score as 0.9
UserInteraction with user_id as "user123", product_id as "productB", interaction_score as 0.8
# Generate product recommendations for a specific user
SET recommendations TO generate_recommendations("user123", interactions, model)
# Output the recommended products
PRINT "Recommended Products:", recommendations
RETURN success
# Execute the main function to start the recommendation system
CALL main()
This pseudocode provides a high-level structure for a recommendation engine that personalizes product suggestions based on recent user interactions. The UserInteraction class stores each user’s activity with products, including an interaction score indicating engagement or preference. The generate_recommendations function filters interactions by user ID, creating a list of recommended products based on the user’s scores. In main, the model is loaded with the required configuration, sample interactions are defined, and the generate_recommendations function is called to generate recommendations for a specific user. This system can be expanded with additional features, such as real-time data processing, to create a highly responsive recommendation engine suited to large-scale e-commerce applications.
The future potential of LLMs in customer service and e-commerce is substantial, with advancements likely to focus on creating more adaptive, transparent, and efficient models. Adaptive LLMs, which adjust to user behavior in real time, are becoming increasingly feasible as data collection and model update capabilities improve. These systems can respond to changing user preferences, adapt to seasonal trends, and dynamically update recommendations, leading to richer, more engaging user experiences. Rust’s low-latency capabilities make it a prime candidate for developing these systems, as it allows for fast data processing and model adaptation without performance trade-offs.
However, there are challenges to overcome to realize this potential fully. Data availability remains a significant barrier; while customer data is abundant, privacy regulations limit the extent to which it can be utilized. Additionally, model interpretability and transparency are critical to gaining user trust. As LLMs take on more customer-facing roles, clear explanations for recommendations or responses become essential, allowing users to understand and control the AI-driven suggestions they receive. Finally, regulatory considerations will continue to shape the deployment of LLMs in customer service and e-commerce, as organizations must comply with evolving privacy laws and ethical guidelines.
In conclusion, case studies of LLMs in customer service and e-commerce illustrate the transformative impact of these models on user experience, operational efficiency, and business innovation. By harnessing Rust’s performance, concurrency, and data handling strengths, developers can build scalable, responsive LLM-powered systems tailored to meet the demands of modern e-commerce and customer service environments. With opportunities for multi-modal recommendations, predictive analytics, and real-time user adaptation, LLMs offer immense potential for future developments in these sectors. This section provides a roadmap for leveraging Rust to implement reliable, high-performance AI applications, setting the stage for the next generation of customer-focused, data-driven solutions.
17.7. Conclusion
Chapter 17 provides readers with the knowledge and tools to harness the power of large language models in customer service and e-commerce using Rust. By applying these techniques, readers can develop applications that enhance customer engagement, drive sales, and operate within ethical and regulatory frameworks, ensuring that AI-driven customer service and e-commerce solutions are both innovative and responsible.
17.7.1. Further Learning with GenAI
Each prompt encourages critical thinking and technical experimentation, helping readers understand the complexities and challenges involved in developing AI-driven customer service and e-commerce solutions.
Explain the role of large language models (LLMs) in customer service and e-commerce. How can LLMs enhance applications such as chatbots, personalized recommendations, and automated customer support?
Discuss the key challenges of applying LLMs in customer service and e-commerce, particularly in handling diverse customer queries and ensuring real-time responses. How can Rust be leveraged to address these challenges effectively?
Describe the importance of user experience, accuracy, and responsiveness in customer service and e-commerce applications. How can Rust-based models be designed to meet these requirements?
Analyze the impact of LLMs on customer satisfaction and sales conversion rates. What are the potential benefits and risks of using LLMs for customer interaction in e-commerce platforms?
Explore the ethical considerations of deploying LLMs in customer service and e-commerce, particularly regarding data privacy, bias, and fairness. How can Rust-based systems be designed to mitigate these ethical issues?
Explain the process of building a robust data pipeline for customer service and e-commerce applications using Rust. What are the essential steps for ensuring data quality, relevance, and privacy when handling large volumes of customer data?
Discuss the challenges of working with diverse data sources in customer service and e-commerce. How can Rust-based tools be used to preprocess, normalize, and integrate customer interaction data for LLM training?
Analyze the role of real-time data processing and streaming in enhancing the responsiveness of customer service applications. How can Rust be used to implement real-time data integration for LLMs?
Explore the specific considerations for training LLMs on customer service and e-commerce data, including handling variability in customer queries and maintaining high accuracy. How can Rust be used to implement a robust training pipeline?
Discuss the importance of transfer learning and fine-tuning pre-trained models for customer service-specific tasks. What are the key challenges and benefits of adapting general-purpose LLMs to customer service and e-commerce?
Explain the role of explainability and interpretability in customer service LLMs. How can Rust-based models be designed to ensure that their outputs are understandable and actionable for customer service representatives and end-users?
Analyze the challenges of deploying LLMs in customer service environments, particularly in terms of latency, accuracy, and scalability. How can Rust be used to build and deploy efficient inference pipelines for customer service LLMs?
Discuss the regulatory requirements for deploying AI in customer service and e-commerce contexts, such as GDPR, CCPA, and industry-specific standards. How can developers ensure that their Rust-based LLM applications comply with these regulations?
Explore the potential risks of deploying biased or opaque LLMs in customer service and e-commerce. How can Rust-based systems be designed to detect and mitigate these risks, ensuring fairness and transparency?
Discuss the importance of real-time inference capabilities in critical customer service applications, such as chatbots and personalized recommendations. How can Rust be used to optimize inference pipelines for speed, accuracy, and scalability in these scenarios?
Analyze the role of continuous monitoring and maintenance in ensuring the long-term reliability of deployed customer service and e-commerce LLMs. How can Rust-based systems be set up to track performance and implement updates as needed?
Explore the challenges of integrating LLMs into existing customer relationship management (CRM) systems and e-commerce platforms. How can Rust-based models be deployed in a way that ensures compatibility and minimal disruption?
Discuss the future potential of LLMs in customer service and e-commerce, including emerging trends like hyper-personalized recommendations and AI-driven customer engagement. How can Rust be leveraged to innovate in these areas?
Explain the key lessons learned from existing case studies of LLM deployments in customer service and e-commerce. What best practices can be derived from these experiences, and how can they inform the development of future Rust-based customer service applications?
Analyze the broader implications of using LLMs in customer service and e-commerce. How can these technologies be harnessed to improve customer experience and operational efficiency while ensuring adherence to ethical and regulatory standards?
By engaging with these exercises, you will build a deep understanding of how to create robust, compliant, and high-performance systems that enhance customer experience and drive business success.
17.7.2. Hands On Practices
Self-Exercise 17.1: Building a Real-Time Data Pipeline for E-commerce Using Rust
Objective: To design and implement a real-time data pipeline for e-commerce applications using Rust, focusing on preprocessing, integration, and streaming of customer interaction data.
Tasks:
Set up a Rust-based data pipeline to ingest, preprocess, and stream real-time customer interaction data, ensuring data integrity, quality, and privacy.
Implement feature extraction techniques to convert unstructured customer interaction data into structured inputs suitable for training and real-time inference by a large language model.
Integrate the pipeline with an existing e-commerce platform, ensuring seamless data flow and real-time updates.
Test the pipeline with a variety of customer interaction data, identifying and addressing challenges related to data consistency, latency, and relevance.
Deliverables:
A Rust codebase for a real-time data pipeline that includes preprocessing, feature extraction, and integration components.
A detailed report on the implementation process, including challenges encountered and solutions applied.
A performance evaluation of the pipeline, focusing on its ability to handle and stream large volumes of real-time e-commerce data effectively.
Self-Exercise 17.2: Training a Personalized Recommendation System Using Rust
Objective: To train a large language model on e-commerce data using Rust, with a focus on building a personalized recommendation system that enhances user experience and sales conversion rates.
Tasks:
Prepare a dataset of customer purchase histories and interaction logs, ensuring it is properly preprocessed and labeled for training a personalized recommendation system.
Implement a Rust-based training pipeline, incorporating techniques to handle the variability in customer preferences and achieve high accuracy in recommendations.
Experiment with different personalization strategies, such as collaborative filtering and content-based filtering, to enhance the model’s ability to make relevant recommendations.
Evaluate the trained model on a validation dataset, analyzing its accuracy, relevance, and impact on user satisfaction and sales conversions.
Deliverables:
A Rust codebase for training a personalized recommendation system, including data preprocessing and personalization techniques.
A training report detailing the model’s performance on e-commerce recommendation tasks, with a focus on accuracy, relevance, and impact on user engagement.
A set of recommendations for further improving the model’s performance and applicability in e-commerce settings.
Self-Exercise 17.3: Deploying a Customer Service Chatbot for Real-Time Support
Objective: To deploy a large language model as a customer service chatbot for real-time support in an e-commerce environment, focusing on optimizing latency, accuracy, and user satisfaction.
Tasks:
Implement an inference pipeline in Rust that serves a customer service chatbot, optimizing for low latency and high accuracy in responding to diverse customer queries.
Deploy the chatbot in a secure and scalable environment, ensuring compliance with data privacy regulations such as GDPR and CCPA.
Set up a real-time monitoring system to track the chatbot’s performance, focusing on key metrics such as response time, accuracy, and user satisfaction.
Analyze the monitoring data to identify potential issues with the chatbot’s performance, and implement updates or adjustments as needed.
Deliverables:
A Rust codebase for deploying and serving a customer service chatbot, including real-time inference capabilities.
A deployment report detailing the steps taken to ensure compliance with data privacy regulations and optimize chatbot performance.
A monitoring report that includes performance metrics and an analysis of the chatbot’s real-time behavior, with recommendations for ongoing maintenance and updates.
Self-Exercise 17.4: Ensuring Ethical Compliance in E-commerce LLM Deployment
Objective: To design and implement strategies for ensuring ethical compliance in the deployment of large language models in e-commerce, focusing on bias detection, fairness, and transparency.
Tasks:
Implement bias detection techniques in a deployed e-commerce LLM, ensuring that the model’s recommendations and interactions are fair and equitable across different customer demographics.
Develop methods to enhance the transparency of the model’s decision-making processes, making them understandable for both customers and e-commerce platform operators.
Integrate continuous monitoring for ethical compliance, including mechanisms to detect and respond to potential ethical violations or model drift.
Conduct a thorough evaluation of the deployed model’s ethical performance, focusing on bias, fairness, and adherence to industry standards and regulations.
Deliverables:
A Rust codebase with integrated bias detection and transparency features for a deployed e-commerce large language model.
An ethical compliance report detailing the strategies used to ensure fairness and transparency, including bias detection results.
An evaluation report on the model’s ethical performance, with recommendations for improving ethical compliance in future deployments.
Self-Exercise 17.5: Innovating Customer Service with LLMs: Case Study Implementation
Objective: To analyze a real-world case study of large language model deployment in customer service and implement a small-scale version using Rust, focusing on replicating the critical aspects of the deployment.
Tasks:
Select a case study of a successful LLM deployment in customer service, analyzing the key challenges, solutions, and outcomes.
Implement a small-scale version of the case study using Rust, focusing on the most critical components such as data handling, model training, and deployment.
Experiment with the implementation to explore potential improvements or adaptations, considering factors such as model performance, scalability, and compliance.
Evaluate the implemented model against the original case study, identifying key takeaways and lessons learned for future customer service LLM projects.
Deliverables:
A Rust codebase that replicates a small-scale version of the selected customer service LLM case study, including key deployment components.
A case study analysis report that details the original deployment’s challenges, solutions, and outcomes, along with insights gained from the implementation.
A performance evaluation of the implemented model, with a comparison to the original case study and recommendations for future innovations in customer service LLM deployments.
Comments