Chapter 16
LLMs in Legal and Compliance
"The deployment of AI in legal contexts requires a delicate balance between innovation and responsibility, ensuring that technology enhances rather than undermines the principles of justice and fairness." — Fei-Fei Li
Chapter 16 of LMVR explores the application of large language models (LLMs) in the legal and compliance sectors, addressing the unique challenges and opportunities in these fields. The chapter covers the entire process, from building specialized data pipelines and training models on complex legal and regulatory data to deploying them in secure, compliant environments. It emphasizes the importance of accuracy, interpretability, and ethical considerations, ensuring that LLMs are both effective and responsible in high-stakes legal applications. The chapter also discusses strategies for monitoring and maintaining deployed models, ensuring they remain compliant with evolving legal standards and regulations. Through practical examples and case studies, readers gain insights into the development and deployment of LLMs in legal and compliance using Rust.
16.1. Introduction to LLMs in Legal and Compliance
Large language models (LLMs) have the potential to significantly transform the legal and compliance sectors, where vast amounts of textual data, regulatory guidelines, and documentation need to be parsed, analyzed, and interpreted. In applications like contract analysis, regulatory compliance verification, and legal research, LLMs can streamline processes that traditionally require manual oversight. By analyzing contracts, LLMs can identify key clauses, flag potential risks, and verify compliance with legal standards. For instance, a legal LLM might detect non-standard clauses in a contract, helping lawyers assess the implications before finalizing agreements. Similarly, in compliance, LLMs can automatically scan regulatory texts to ensure that organizations adhere to relevant laws and guidelines. Rust’s speed, memory safety, and concurrency make it a valuable choice for building high-performance applications in these fields, where data privacy, accuracy, and regulatory compliance are paramount. Rust’s secure handling of sensitive information aligns well with the stringent requirements in legal contexts, while its efficiency allows real-time analysis, crucial for applications like contract review and compliance monitoring.
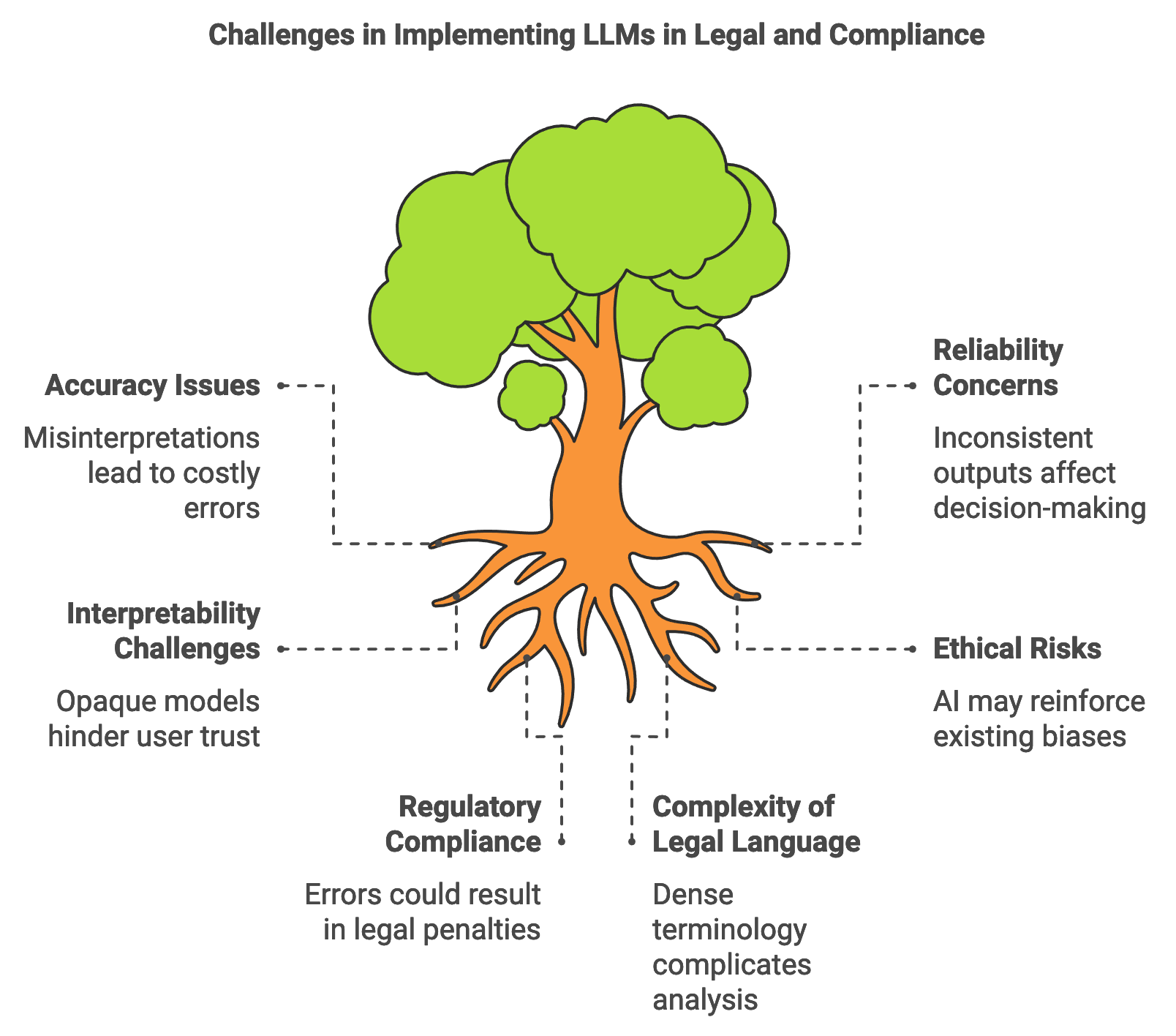
Figure 1: Key Challenges of LLMs in Legal and Compliance.
Legal and compliance applications require particular care in handling complex language, given that legal terminology is dense, highly specific, and often open to multiple interpretations. LLMs deployed in these domains must be accurate and reliable, as errors could have serious consequences. For instance, in contract analysis, an LLM’s misinterpretation of a clause could lead to costly oversights. In compliance, errors in identifying regulatory non-compliance could result in legal penalties. Mathematically, the accuracy of a model can be represented by the function $\text{Acc}(M) = \frac{|C|}{|T|}$, where $M$ is the model, $C$ is the set of correct outputs, and $T$ is the total set of outputs. High accuracy is particularly critical in legal contexts where precise interpretation directly impacts decision-making. Additionally, model reliability—consistency in producing correct outputs—can be represented by measuring the standard deviation of model accuracy over multiple test samples, ensuring that the model performs well across varied legal documents.
The interpretability of LLMs in legal and compliance is equally essential, as legal professionals and compliance officers must be able to understand the basis of model decisions. The opaque nature of large language models, often referred to as “black boxes,” poses challenges for adoption in fields where decisions need to be traceable and explainable. Explainability techniques such as attention maps or Shapley values can make LLM decisions more transparent, allowing users to view which parts of a document influenced the model’s output. In legal applications, this interpretability could mean highlighting specific contract clauses or phrases that contributed to a “risky” classification, thereby supporting more informed decision-making. Rust’s type safety and precision offer a strong foundation for implementing explainability tools, as developers can avoid the pitfalls of undefined behavior or memory errors that could interfere with clear and reliable model outputs.
LLMs in legal and compliance also introduce ethical and regulatory considerations. In automating tasks like contract review or regulatory scanning, LLMs may influence decision-making processes traditionally reserved for human professionals, raising questions about accountability and the risk of over-reliance on AI. For instance, automating contract review with an LLM could inadvertently reinforce biases present in historical contract language, impacting certain groups disproportionately. Bias mitigation techniques, such as reweighting or adversarial debiasing, are critical to address these risks. Mathematically, bias in model outputs can be monitored by calculating the average divergence between predicted outcomes for distinct demographic groups, ensuring that outcomes are equitable. In Rust, these methods can be implemented with a focus on efficiency and precision, allowing developers to monitor bias in real-time and make adjustments as necessary to promote fairness and ethical AI use in legal applications.
To illustrate a practical application of LLMs in legal and compliance, consider a contract review tool. This tool would ingest contracts, identify key clauses, and assess compliance with specified legal standards. The pseudocode below demonstrates a legal contract review tool powered by a Large Language Model (LLM). The tool ingests contract text, identifies key clauses, and flags those that may need further legal review to ensure compliance with specific standards. This example leverages an LLM for efficient contract processing, aiming to assist legal professionals by highlighting clauses such as non-compete and indemnity, which often require careful examination. With a secure API structure, the tool allows legal teams to process lengthy contracts quickly and efficiently.
# Import necessary modules for API, data handling, and model inference
# Define the application state to hold the model for contract analysis
CLASS AppState:
FUNCTION __init__(self, model):
# Initialize the model within a thread-safe structure
SET self.model TO a thread-safe reference to the LLM model
# Define a structure to receive contract input from users
CLASS ContractInput:
ATTRIBUTE text: STRING
# Define the endpoint for handling contract review requests
FUNCTION review_contract_endpoint(input: ContractInput, state: AppState) -> LIST of STRINGS:
# Securely access the model by locking the state to prevent data races
ACQUIRE lock on state.model OR RETURN "Model lock error"
# Tokenize the contract text for model processing
SET tokens TO model.tokenizer.encode(input.text)
# Run inference on the tokenized text to extract clauses
SET output TO model.forward(tokens) OR RETURN "Inference error"
# Simulate clause extraction and flagging for legal review
SET flagged_clauses TO [
"Non-compete clause may limit future employment options.",
"Indemnity clause may increase liability risk."
]
# Return flagged clauses in a JSON response
RETURN JSON response containing flagged_clauses
# Main function to initialize and configure the contract review API
FUNCTION main() -> SUCCESS or ERROR:
# Set model configuration and device (CPU or GPU) for inference
SET config TO default configuration for the model
SET device TO CPU
# Load the contract analysis LLM onto the specified device
SET model TO load DistilBERT model with config on device
# Initialize application state with the loaded model
SET state TO new instance of AppState with model
# Build and configure the API:
INITIALIZE API framework
REGISTER endpoint "/review" with review_contract_endpoint
ATTACH application state for secure model access
# Launch the API server for processing contract review requests
START the API server
# Execute the main function to deploy the contract review tool
CALL main()
The pseudocode defines a secure API pipeline for reviewing legal contracts using an LLM. The AppState class stores the model in a thread-safe structure to allow multiple concurrent review requests. Incoming contract data is structured through ContractInput for consistency in processing. The review_contract_endpoint function tokenizes the contract text, runs it through the model to identify key clauses, and simulates flagging clauses that may need legal review, such as non-compete or indemnity clauses. The main function configures the model and the API, setting up the necessary device and model configuration before launching the server to handle incoming requests. This structure enables efficient, high-performance legal analysis by identifying potential risks within contracts in real time.
Real-world applications of LLMs in legal and compliance demonstrate the utility of these models in streamlining complex legal tasks. For example, an international law firm deployed an LLM to assist with regulatory compliance, where the model scanned new legal mandates and mapped them to existing policies. This reduced the time required for legal teams to adapt to regulatory changes, allowing more agile compliance processes. The implementation also addressed the challenge of multilingual compliance, as the LLM processed legal texts in multiple languages, making it adaptable across diverse jurisdictions. Rust’s concurrency capabilities were critical in processing these high-throughput data streams, as they enabled parallelized processing of documents, maintaining speed and accuracy.
Emerging trends in legal technology suggest that LLMs will play an increasing role in predictive analytics and case law research. By analyzing historical case data, LLMs can predict the likelihood of case outcomes, assisting lawyers in forming case strategies based on empirical data. Predictive analytics in law involves analyzing features of past cases $x_i$ to estimate the probability $P(y | x_i)$ of specific outcomes $y$, such as a favorable verdict. Rust’s strong type system and efficient data handling make it ideal for implementing such models, where real-time predictions and accuracy are paramount. Furthermore, as legal systems worldwide explore AI-driven document generation, LLMs could potentially draft routine legal documents, such as contracts or compliance reports, reducing the administrative burden on legal professionals.
Despite the advantages, challenges remain in realizing the full potential of LLMs in legal and compliance. Data availability is a persistent challenge, as legal texts are often proprietary or restricted by confidentiality agreements, limiting the datasets available for training. Model interpretability is also a critical concern, as the “black box” nature of LLMs may conflict with the need for transparent decision-making in legal settings. Regulatory barriers further complicate deployment, as some jurisdictions require human oversight in legal decisions, limiting the automation potential of LLMs. Addressing these challenges will require ongoing advancements in data accessibility, explainability techniques, and compliance frameworks that allow AI models to be safely and effectively integrated into legal workflows.
In conclusion, LLMs hold transformative potential for legal and compliance applications, enabling more efficient contract analysis, regulatory scanning, and legal research. By leveraging Rust’s strengths in performance, safety, and concurrency, developers can build secure, scalable, and compliant legal AI applications that meet the high standards of the legal profession. This section highlights the unique requirements of deploying LLMs in legal and compliance, emphasizing the importance of accuracy, interpretability, and regulatory compliance in ensuring that these tools are both useful and responsible. As the legal industry increasingly adopts AI, Rust provides a solid foundation for developing applications that support transparency, ethical decision-making, and enhanced legal services.
16.2. Building Legal and Compliance Data Pipelines
Building data pipelines for legal and compliance applications involves handling vast volumes of text data, including structured documents like regulations and contracts, as well as unstructured data from case law, legal texts, and court opinions. Unlike standard text data, legal documents are often lengthy, complex, and require precise interpretation, which makes preprocessing, normalization, and annotation critical. For legal and compliance-focused LLMs, the data pipeline must transform these documents into standardized formats that the model can analyze effectively, ensuring that important legal terminology and context are preserved. Rust offers performance, memory safety, and concurrency advantages, which are crucial for processing high-throughput, text-heavy legal datasets. By leveraging Rust-based tools and crates, such as serde for data serialization and regex for text processing, developers can construct reliable, efficient data pipelines tailored to the nuances of legal text.
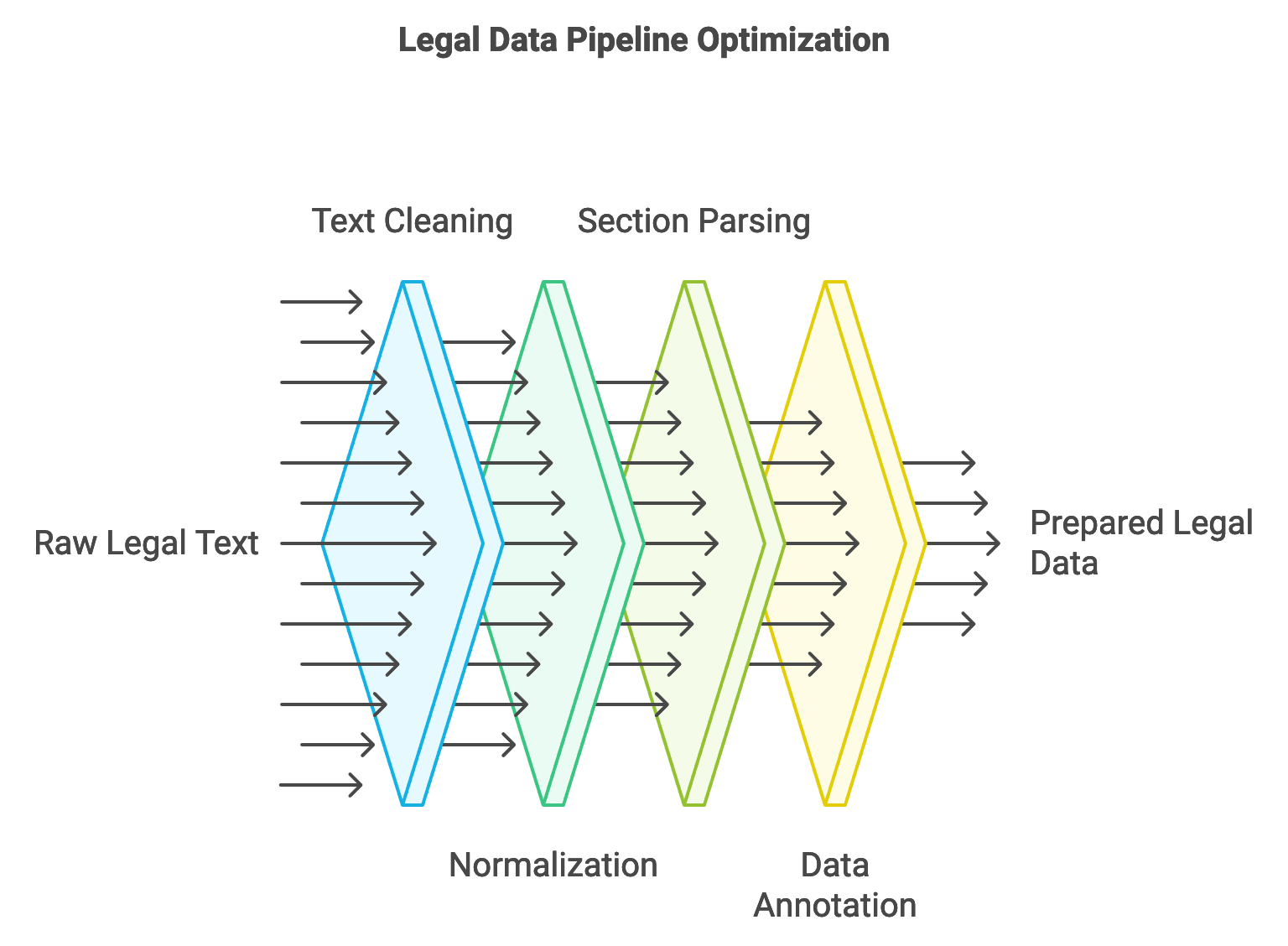
Figure 2: Data preprocessing pipeline for legal and compliance LLMs.
A fundamental step in preparing legal data for LLMs is preprocessing, which includes cleaning and normalizing the text. Legal data often contains formatting artifacts, such as section headers, footnotes, and metadata tags, which can introduce noise and reduce model accuracy if left unprocessed. Text cleaning removes extraneous information, while normalization standardizes terms and formats, ensuring that the data aligns with a predefined structure. Mathematically, normalization can be defined as a function $N(x) \rightarrow x'$, where $x$ is the raw text and $x'$ is the normalized, standardized version suitable for model input. Standardizing terms across multiple documents, such as abbreviating “section” to “§” or converting legal citations to a consistent format, ensures that the model recognizes these elements uniformly across documents. Rust’s strong type system and error handling support this process by catching inconsistencies early, enabling developers to build dependable pipelines that maintain data integrity.
Legal data often comes from diverse sources, each with its own structure and language conventions, presenting unique challenges in data consistency and integrity. For instance, contracts differ in structure and terminology depending on the jurisdiction or industry, and regulations vary significantly across regions. One strategy for achieving consistency is by employing regular expressions to identify and parse standard sections, such as “Definitions,” “Indemnity,” or “Governing Law,” across different legal documents. These sections can be labeled and extracted as standardized components, which helps the LLM understand the general document structure and recognize similar clauses across varying contracts. Rust’s regex crate is especially useful here, as it enables high-performance text parsing, allowing the pipeline to handle multiple documents concurrently without sacrificing speed. Additionally, by structuring the pipeline to validate data at each stage, developers can ensure accuracy and consistency across the entire dataset, a requirement essential for maintaining reliability in legal AI applications.
Data annotation and labeling are crucial steps in preparing legal and compliance data for LLM training. In legal contexts, annotation often involves marking key entities, such as parties to a contract, obligations, clauses, and defined terms. This labeling helps the LLM understand the roles and relationships within a document, enhancing its ability to interpret legal language accurately. For example, entity recognition can be represented as a function $f(x) \rightarrow \{e_1, e_2, \ldots, e_n\}$, where $x$ is a text passage and $e_i$ are the identified entities, each tagged with its respective category, such as “Obligation” or “Party.” Annotating data with Rust is achievable through structured data handling, where labeled data can be represented using enums or structs. Rust’s type safety ensures that entities are correctly annotated without data corruption, and its high-speed processing capabilities enable the pipeline to handle large datasets, which is vital in legal applications where datasets can span millions of documents.
To demonstrate a practical legal data pipeline in Rust, consider an example where we preprocess and annotate legal contracts to prepare them for LLM training. This pseudocode illustrates a legal data processing pipeline designed to preprocess and annotate legal documents, making them suitable for training a Large Language Model (LLM). The pipeline ingests a contract, cleans and normalizes the text for consistency, and applies annotations to key legal terms, producing structured data that is ready for machine learning applications. By identifying and labeling important terms, this pipeline enables the model to learn patterns and relationships within legal language, ultimately enhancing its ability to interpret similar documents.
# Import necessary modules for data handling and regular expressions
# Define a structure for storing legal document data
CLASS LegalDocument:
ATTRIBUTE title: STRING
ATTRIBUTE text: STRING
# Define a structure for storing annotated document data
CLASS AnnotatedDocument:
ATTRIBUTE title: STRING
ATTRIBUTE text: STRING
ATTRIBUTE annotations: LIST of Annotation
# Define a structure for storing individual annotations
CLASS Annotation:
ATTRIBUTE term: STRING
ATTRIBUTE category: STRING
ATTRIBUTE position: INTEGER
# Function to normalize text by removing special characters and converting to lowercase
FUNCTION normalize_text(text: STRING) -> STRING:
# Define a regular expression to match non-alphanumeric characters
SET regex TO regex matching all non-alphanumeric characters
# Remove matches and convert text to lowercase
SET normalized_text TO remove regex matches from text and convert to lowercase
RETURN normalized_text
# Function to annotate specific legal terms within the text
FUNCTION annotate_text(text: STRING) -> LIST of Annotation:
INITIALIZE empty list annotations
SET terms TO ["indemnity", "liability", "confidentiality"]
FOR each term in terms:
SET regex TO regex matching the whole word term
FOR each match in regex matches within text:
CREATE new Annotation with:
term as term
category as "LegalTerm"
position as start index of match
ADD Annotation to annotations
RETURN annotations
# Function to process a legal document by normalizing and annotating its text
FUNCTION process_document(doc: LegalDocument) -> AnnotatedDocument:
SET normalized_text TO normalize_text(doc.text)
SET annotations TO annotate_text(normalized_text)
RETURN new AnnotatedDocument with:
title as doc.title
text as normalized_text
annotations as annotations
# Main function to demonstrate document processing
FUNCTION main() -> SUCCESS or ERROR:
CREATE sample LegalDocument with:
title as "Sample Contract"
text as "This contract includes indemnity and confidentiality clauses."
SET processed_doc TO process_document(sample LegalDocument)
PRINT "Annotated Document:", processed_doc
RETURN success
The pseudocode defines a preprocessing pipeline that prepares legal documents for machine learning by normalizing and annotating text. The LegalDocument and AnnotatedDocument classes store the original and processed document data, while Annotation captures details about each identified legal term. The normalize_text function removes special characters and converts the text to lowercase to ensure consistency, and annotate_text identifies key terms within the document, such as "indemnity" or "liability," storing their positions and categories. In the process_document function, both normalization and annotation are applied to a LegalDocument, and the result is saved as an AnnotatedDocument. Finally, the main function demonstrates this pipeline with a sample contract, producing a structured, annotated document ready for LLM training. This pseudocode provides a scalable approach for large collections of legal documents, supporting efficient processing and structured data output.
Real-world applications demonstrate the effectiveness of data pipelines in automating legal tasks. For example, a global law firm deployed an LLM pipeline for contract analysis, where the model annotated and classified clauses to expedite the contract review process. The pipeline handled high volumes of contracts by preprocessing text and labeling key terms, enabling lawyers to focus on high-risk areas flagged by the model. Rust’s speed and concurrency were crucial in managing this large-scale operation, as the pipeline processed thousands of contracts in parallel, ensuring both accuracy and timely insights for legal teams.
Current trends in legal AI emphasize the importance of integrating data from multiple jurisdictions and languages, as legal teams increasingly operate across international borders. This trend has spurred innovation in multi-lingual annotation and normalization techniques, allowing LLMs to process legal documents in diverse legal systems. For example, an LLM may need to process both common law contracts and civil law agreements, requiring region-specific annotations. Rust’s adaptability to different data structures allows developers to create flexible pipelines that accommodate regional variations in legal language, terminology, and structure, enabling more comprehensive and adaptable legal applications.
In addition to multi-lingual capabilities, advancements in synthetic data generation for legal applications are becoming more prevalent. Synthetic data, generated by modifying real-world legal documents, offers a valuable training resource when sensitive data is unavailable due to privacy constraints. For example, a synthetic document generation function $S(x) \rightarrow x'$ might introduce variations in clause wording, jurisdiction, or parties involved, creating new training instances while retaining the core structure of legal language. Rust’s control over memory and execution makes it ideal for generating large volumes of synthetic legal data efficiently, supporting LLMs in legal applications where data availability is limited.
In conclusion, data pipelines play a foundational role in preparing legal and compliance data for LLM training, ensuring that the information is clean, standardized, and annotated for effective analysis. Rust’s performance and memory safety enable the construction of reliable pipelines that meet the stringent requirements of legal applications, where data accuracy and integrity are paramount. By addressing challenges in data preprocessing, standardization, and annotation, Rust-based pipelines facilitate the development of LLMs that can support contract review, regulatory compliance, and other legal tasks with accuracy and efficiency. This section emphasizes the critical role of well-designed data pipelines in harnessing the potential of LLMs in legal and compliance, laying a solid groundwork for more advanced AI-driven solutions in these fields.
16.3. Training LLMs on Legal and Compliance Data
Training large language models (LLMs) for legal and compliance tasks requires a specialized approach to ensure that models not only understand general language but also interpret complex legal terminology and regulatory nuances. Legal and compliance data is distinct in both its language and its structure, as legal texts often include domain-specific terminology, archaic language, and precise phrasing that carries critical legal significance. This makes domain-specific knowledge essential for training LLMs in this sector, as models must grasp the implications of specific clauses, conditions, and terminology to provide actionable insights. Furthermore, legal datasets often exhibit class imbalance; for example, certain types of legal clauses (e.g., confidentiality or liability clauses) may appear much more frequently than others. This imbalance requires careful handling to prevent models from underperforming on rare but important categories. Rust-based frameworks provide an efficient and safe environment for handling large-scale, complex datasets, allowing developers to build robust training pipelines tailored to the demands of legal applications.
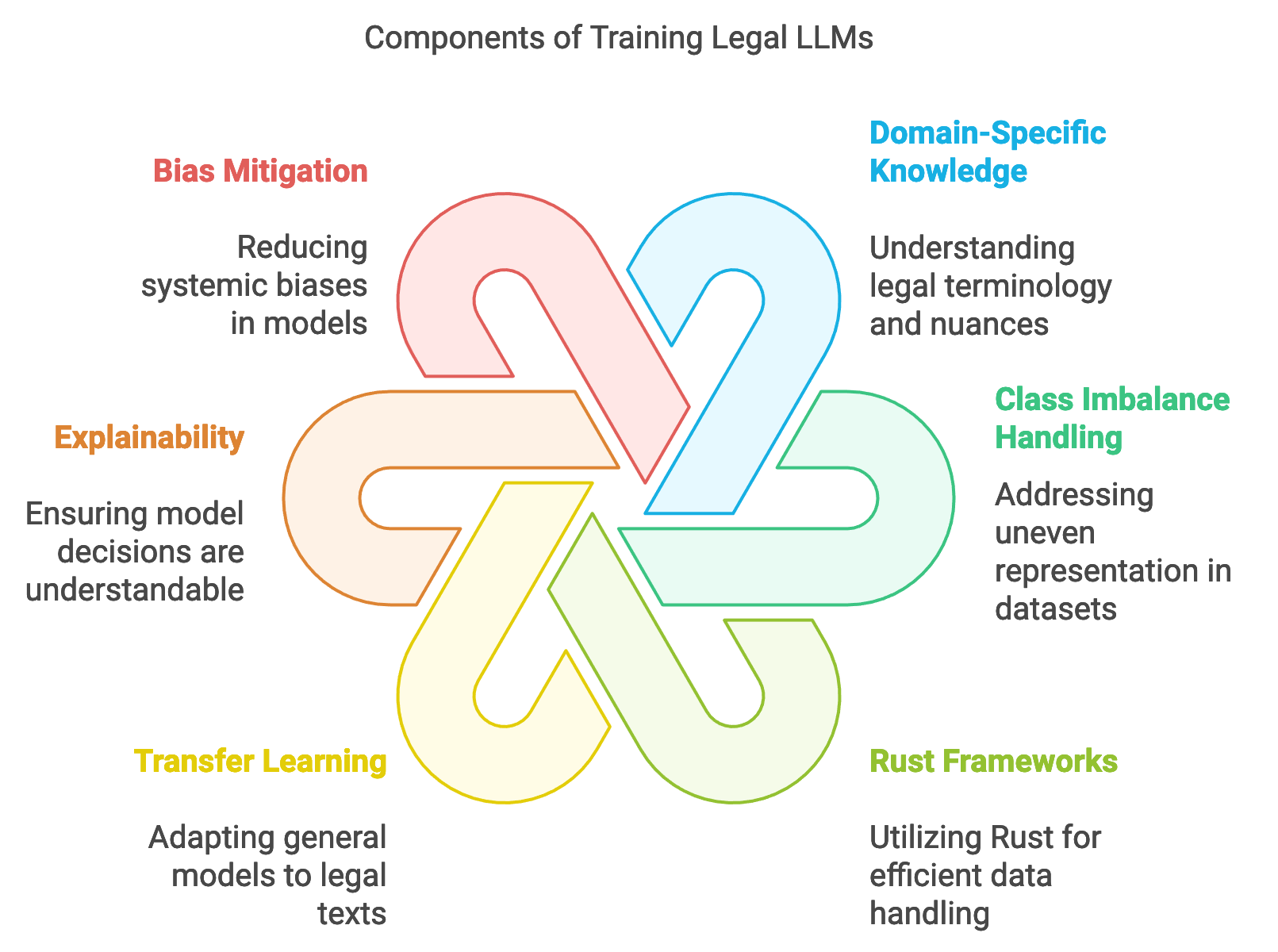
Figure 3: Key considerations in training LLMs.
Rust’s machine learning ecosystem includes emerging frameworks and libraries, such as burn and candle, which offer foundational tools for implementing LLMs and training them on extensive legal datasets. For training legal LLMs, transfer learning and fine-tuning pre-trained models have proven to be effective strategies. Transfer learning allows a general-purpose LLM, which is trained on a vast corpus of general text, to adapt to the specific language and structure of legal texts. Mathematically, this can be described as optimizing the model parameters $\theta$ on a target legal dataset $D_t$ after pre-training on a general dataset $D_g$. Formally, the objective is to minimize the loss $L(\theta | D_t)$ while retaining the general knowledge encoded during pre-training. Fine-tuning enables the model to learn nuances in legal language without requiring extensive computational resources to train from scratch. Rust’s performance characteristics ensure that even with the high computational demands of transfer learning, the training process remains efficient and manageable.
Training LLMs with legal data introduces specific challenges, particularly regarding the complexity and interpretability of the language used in laws, contracts, and regulations. Legal language is dense and often ambiguous, requiring models to understand context and discern subtle differences in phrasing. For example, “shall” and “may” have distinct implications in legal texts, with the former indicating a requirement and the latter a possibility. Additionally, the hierarchical structure of legal documents—such as nested clauses, references to statutes, and citations—requires the model to maintain contextual awareness across different document sections. Rust’s type safety and structured error handling allow developers to implement data preprocessing steps that preserve these complexities, ensuring that the training data accurately reflects the structure and language of real-world legal documents.
Explainability and interpretability are critical in legal applications, as LLMs deployed in this sector must produce outputs that are both understandable and legally sound. Legal professionals and compliance officers need to trace and understand the model’s reasoning, especially when it influences high-stakes decisions, such as contract approvals or compliance checks. Techniques like attention visualization, layer-wise relevance propagation, or Shapley values can help clarify the model’s decision-making process, making it possible to pinpoint the sections of a document that contributed most to the model’s predictions. In Rust, implementing these explainability techniques involves tracking feature importance throughout the inference pipeline and recording decision paths. Such implementations benefit from Rust’s performance and reliability, ensuring that explainability modules operate smoothly even as models process large documents.
Bias mitigation is another essential consideration when training legal and compliance LLMs, as biased models could perpetuate systemic inequalities or unfair practices. For example, a model trained on historical case law may inherit gender, racial, or socioeconomic biases present in past legal decisions. Strategies for addressing these biases include reweighting the dataset to ensure balanced representation or using adversarial training to reduce model sensitivity to certain biased features. Mathematically, bias mitigation can be represented by adjusting sample weights $w_i$ for each instance $x_i$, balancing the influence of underrepresented classes and promoting fairness across the model’s predictions. Rust’s concurrency features support the implementation of real-time bias monitoring, enabling developers to identify and mitigate biases throughout training, rather than solely as a post-processing step.
A practical Rust-based training pipeline for a legal LLM would involve data preprocessing, model selection, and transfer learning. This pseudocode outlines a training pipeline for fine-tuning a legal Large Language Model (LLM) on contract analysis tasks. This pipeline encompasses data preprocessing, model selection, and transfer learning by leveraging a pre-trained model adapted for legal tasks. By fine-tuning the LLM on labeled legal data, the model learns to identify specific clauses or features in contracts, enabling it to perform tasks such as clause extraction or risk assessment more accurately.
# Import necessary modules for device management, tensor operations, and model configuration
# Function to preprocess and tokenize legal text for model input
FUNCTION preprocess_text(text: STRING) -> TENSOR:
# Assume tokenization and encoding to token IDs
RETURN placeholder tensor representing tokenized text
# Define training loop to fine-tune the legal LLM using labeled legal data
FUNCTION train_model(model: MODEL, data: LIST of TENSOR, labels: LIST of FLOAT) -> SUCCESS or ERROR:
FOR each (input, label) in paired data and labels:
# Perform a forward pass to generate model predictions
SET prediction TO model.forward(input)
# Calculate loss (example: Mean Squared Error between prediction and label)
SET loss TO (prediction - label) squared, then summed
# Perform backpropagation to update model weights
CALL loss.backward()
RETURN success
# Main function to configure, initialize, and train the model
FUNCTION main() -> SUCCESS or ERROR:
# Set up the model configuration and device (CPU or GPU) for training
SET config TO default configuration
SET device TO CPU
# Load the pre-trained model onto the specified device
SET model TO load DistilBERT model with config on device
# Example training data for contract analysis
SET data TO list containing preprocessed tensors for contract examples
SET labels TO list containing corresponding labels (e.g., 1.0 for presence of key clause)
# Fine-tune the model on the training data
CALL train_model(model, data, labels)
PRINT "Training completed successfully"
RETURN success
# Execute the main function to start the training pipeline
CALL main()
This pseudocode outlines a training pipeline designed to adapt a pre-trained LLM for contract analysis tasks in the legal domain. The preprocess_text function prepares and tokenizes contract text, converting it into a tensor format suitable for model input. The train_model function performs the fine-tuning, iterating through each example in the training data, performing a forward pass to generate predictions, and computing the loss using Mean Squared Error (MSE). The loss is then backpropagated to adjust the model’s weights accordingly. In main, the model is loaded with the appropriate configuration and device, sample data and labels are created, and the training loop is executed. This pipeline showcases a high-performance, scalable approach for training LLMs on domain-specific legal tasks, preparing the model to recognize and analyze contract clauses effectively.
Industry use cases provide further insights into the impact of legal LLMs. A prominent law firm recently implemented a fine-tuned LLM for contract review, where the model identified and flagged risk clauses across large volumes of contracts. The model’s training pipeline included data preprocessing, bias monitoring, and explainability tools to ensure that flagged clauses were relevant and accurate. Rust’s speed and concurrency made it possible to process these documents efficiently, enabling lawyers to focus on high-risk areas rather than reviewing each clause manually. The deployment saved significant time and allowed legal teams to improve service delivery to clients by offering faster contract assessments.
Current trends in training LLMs for legal applications highlight advancements in multi-modal learning, where models integrate text with other data types, such as images or structured data from legal forms. This enables the model to interpret documents with embedded tables or annotated figures, which are common in legal and regulatory documents. For example, a multi-modal legal LLM could process both the written provisions of a contract and any accompanying financial tables, giving a more comprehensive understanding of contractual obligations. Rust’s low-level data handling capabilities and efficient processing make it a fitting language for implementing multi-modal pipelines, where text and visual data must be integrated in real-time.
Another emerging trend is the use of synthetic data to address the scarcity of labeled legal data, particularly in niche areas such as rare contract clauses or jurisdiction-specific regulations. Synthetic data generation creates variations of existing legal documents to expand the training dataset, helping LLMs generalize across legal documents with similar structures but distinct language. Mathematically, synthetic data generation can be represented by a function $S(x) \rightarrow x'$, where $S$ is a transformation applied to an original document $x$ to generate a new instance $x'$ with varied language but consistent legal meaning. Rust’s memory safety and control over execution make it effective for generating and handling large volumes of synthetic data, supporting robust and scalable model training for specialized legal tasks.
In conclusion, training LLMs on legal and compliance data involves unique considerations, including handling domain-specific language, ensuring model interpretability, and mitigating bias. By using Rust’s robust ecosystem and performance features, developers can build reliable training pipelines that address the challenges of legal applications, from data preprocessing to transfer learning. As legal AI evolves, Rust’s secure, efficient, and versatile environment supports innovative solutions that extend beyond traditional text-based tasks to include multi-modal and synthetic data-driven models. This section emphasizes the importance of structured, ethical, and precise training approaches in legal LLMs, providing a foundation for high-performance, legally sound, and interpretable AI solutions in the legal domain.
16.4. Inference and Deployment of Legal and Compliance LLMs
Inference and deployment in legal and compliance applications are critical phases for large language models (LLMs), where latency, accuracy, and scalability directly impact real-time analysis and decision-making. Legal applications such as contract analysis, compliance monitoring, and regulatory scanning require low-latency inference to produce timely results, as delays can compromise the effectiveness of these tools. For example, in contract review, an LLM that identifies high-risk clauses in real time allows legal professionals to act swiftly. In compliance monitoring, real-time inference capabilities enable companies to detect and address regulatory issues before they escalate. Given these requirements, Rust is an ideal choice for building inference pipelines that balance performance with compliance, offering concurrency for low-latency operations, memory safety for secure handling of sensitive data, and fine-grained control over system resources.
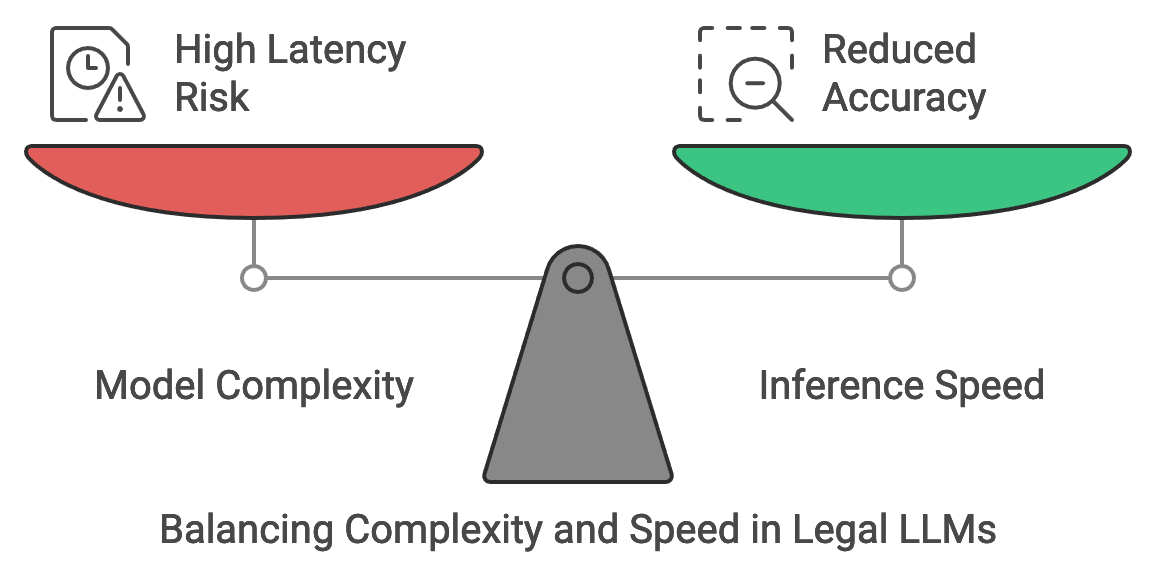
Figure 4: Balancing Accuracy vs Latency.
The deployment of LLMs in legal settings brings with it stringent requirements for regulatory compliance and data privacy, particularly when dealing with regulations such as the General Data Protection Regulation (GDPR) in the European Union. GDPR mandates strict guidelines on data access, processing, and storage, requiring robust systems for data encryption, anonymization, and logging. In the context of legal LLMs, these regulations impact both how inference is handled (e.g., anonymizing client data before processing) and how deployment infrastructure is managed (e.g., logging access to data used in model predictions). To meet these standards, Rust’s secure data handling and error-checking mechanisms make it possible to implement compliant, reliable, and secure inference systems. By using Rust’s type safety and concurrency support, developers can deploy LLMs that not only comply with data protection laws but also deliver real-time analysis with minimal risk of memory-related vulnerabilities.
In legal applications, the trade-off between model complexity and inference speed is a key consideration, particularly for scenarios requiring immediate feedback. Highly complex LLMs, while accurate, can introduce latency, which may be unacceptable in time-sensitive legal tasks. Mathematically, let $T(f(x))$ represent the latency for an inference function $f$ with input $x$, where latency is proportional to the model complexity $C(f)$. To optimize, the complexity $C(f)$ can be reduced through techniques like model quantization and distillation, which lower the computational demands of the model without significant loss in accuracy. Quantization, for instance, reduces the precision of model weights, which decreases both memory and processing time, making it feasible to deploy the LLM for real-time applications in legal environments. Rust’s performance characteristics support these optimizations, allowing legal and compliance-focused LLMs to achieve fast inference times without compromising accuracy.
This pseudocode outlines a legal inference pipeline designed to analyze legal documents in real time using a pre-trained Large Language Model (LLM). The pipeline processes incoming text, runs it through the model to identify important clauses, and returns insights related to legal compliance. This system supports real-time analysis of complex legal language, making it useful for legal professionals who need to quickly assess contracts or other documents. The pseudocode demonstrates the components required for a high-performance, concurrent pipeline capable of scaling to handle multiple requests simultaneously.
# Import necessary modules for model inference, text processing, and API handling
# Define application state to hold the legal analysis model
CLASS AppState:
FUNCTION __init__(self, model):
# Store the model in a secure, thread-safe structure
SET self.model TO a thread-safe reference to the LLM model
# Define a structure to receive document input from users
CLASS DocumentInput:
ATTRIBUTE text: STRING
# Define the endpoint to handle document analysis requests
FUNCTION analyze_document_endpoint(input: DocumentInput, state: AppState) -> LIST of STRINGS:
# Securely access the model by locking the state
ACQUIRE lock on state.model OR RETURN "Model lock error"
# Tokenize the document text to prepare for model input
SET tokens TO model.tokenizer.encode(input.text)
# Perform inference with the model to extract relevant clauses
SET output TO model.forward(tokens) OR RETURN "Inference error"
# Simulate analysis result for demonstration purposes
SET analysis_result TO [
"Clause: Non-compete - Restrictive and may limit employment options.",
"Clause: Confidentiality - Enforced with extensive penalties for breach."
]
# Return the analysis result in a JSON response
RETURN JSON response containing analysis_result
# Main function to configure the model and launch the API for document analysis
FUNCTION main() -> SUCCESS or ERROR:
# Initialize model configuration and device (e.g., CPU) for inference
SET config TO default configuration for the model
SET device TO CPU
# Load the pre-trained DistilBERT model with specified configuration and device
SET model TO load DistilBERT model with config on device
# Set up the application state with the loaded model
SET state TO new instance of AppState with model
# Build and configure the API:
INITIALIZE API framework
REGISTER endpoint "/analyze" with analyze_document_endpoint
ATTACH application state for secure, concurrent access
# Launch the API server to handle incoming analysis requests
START the API server
# Execute the main function to deploy the inference pipeline
CALL main()
This pseudocode describes a high-level pipeline for real-time legal document analysis using an LLM. The AppState class stores the model securely, allowing for concurrent access by multiple requests. The DocumentInput structure standardizes incoming text data, preparing it for analysis. The analyze_document_endpoint function tokenizes the document text, processes it through the model, and returns a structured list of insights. For this example, the output includes simulated annotations identifying potential legal issues, such as non-compete and confidentiality clauses. The main function configures the model and API server, attaching the model to the endpoint and allowing the API to handle concurrent analysis requests. This setup enables legal teams to quickly evaluate large volumes of documents, enhancing efficiency and responsiveness in high-demand legal environments.
Deploying legal LLMs also requires continuous monitoring and model maintenance to ensure that model predictions remain reliable and compliant with evolving regulations. Legal language and standards change frequently, making model drift a concern, where a model’s accuracy deteriorates over time due to data distribution shifts. Monitoring systems can evaluate drift by tracking key performance metrics, such as prediction accuracy and confidence scores. Mathematically, drift can be quantified using statistical measures, such as the Kullback-Leibler (KL) divergence $D_{\text{KL}}(P \| Q)$, where $P$ is the initial data distribution and $Q$ represents the current data distribution. High divergence indicates a shift in language or structure, suggesting the need for model retraining or fine-tuning. Rust’s real-time data handling capabilities make it feasible to integrate drift detection directly into the inference pipeline, triggering alerts or updates as needed to maintain model accuracy and compliance.
Real-world applications of legal LLMs deployed at scale illustrate the value of Rust in managing inference and deployment requirements. For instance, a legal tech company deployed a contract analysis tool that leveraged an LLM to flag potential risks, such as non-standard indemnity clauses or restrictive confidentiality agreements. The LLM was integrated into a legal practice management system, which provided real-time clause analysis during contract review sessions. Rust’s performance was crucial in enabling the system to process lengthy contracts with low latency, while the type-safe environment ensured that no sensitive client data was accidentally exposed. This deployment demonstrated how Rust supports both the operational speed and security demanded by high-stakes legal applications, reducing the workload for legal professionals while maintaining compliance with strict data protection regulations.
The latest trends in legal LLM deployment highlight an increasing emphasis on integrating LLMs with existing legal and compliance management tools, such as case management systems, e-discovery platforms, and document review software. These integrations enable legal teams to use LLMs in conjunction with their current tools, creating seamless workflows that enhance productivity. Additionally, as the volume of digital legal documents continues to grow, legal LLMs are being deployed in hybrid cloud environments, where certain sensitive data remains on-premise, while less sensitive processes leverage cloud infrastructure. Rust’s efficiency and versatility allow it to excel in hybrid deployments, supporting both local and cloud-based inference while maintaining security and performance standards.
In conclusion, the deployment of LLMs in legal and compliance requires a balanced approach that considers the unique demands of the sector: real-time inference, data protection, and regulatory compliance. By building inference pipelines and deployment strategies in Rust, developers can take advantage of the language’s memory safety, concurrency, and performance to deliver scalable, compliant, and high-performance LLM solutions tailored to legal applications. This section underscores the importance of a carefully structured deployment process for legal LLMs, highlighting Rust as a valuable tool for enabling reliable, interpretable, and regulatory-compliant AI in legal and compliance.
16.5. Ethical and Regulatory Considerations
Deploying large language models (LLMs) in legal and compliance introduces a unique set of ethical and regulatory challenges. As these models are increasingly relied upon to provide insights, automate tasks, and even offer initial interpretations of legal texts, concerns around bias, fairness, and transparency have become critical. Legal professionals and clients depend on AI systems to uphold high standards of objectivity and trustworthiness. However, the data used to train LLMs can inadvertently introduce biases, potentially skewing model outputs in ways that impact fairness. For example, if a model is trained on historical data that reflects biased legal judgments or socio-economic disparities, it may produce recommendations that unintentionally reinforce these biases. Rust’s precision and safety features enable developers to incorporate bias detection and mitigation mechanisms directly into LLMs, allowing early detection and correction of biased tendencies, thereby supporting fairer, more reliable AI-driven legal applications.
Figure 5: Ethical and Regulatory Aspects.
Compliance with regulatory frameworks such as the General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA), and other industry-specific standards is paramount when deploying LLMs in the legal field. GDPR, for example, enforces strict guidelines on how personal data should be collected, processed, and stored, and requires organizations to implement measures for data minimization and anonymization. HIPAA, governing the handling of health information in the United States, mandates stringent privacy protections, impacting any LLM handling health-related legal documents or cases. Rust’s emphasis on memory safety and its ecosystem of libraries for data handling provide a secure foundation for building applications that meet these standards. By incorporating robust error handling and secure data handling techniques, developers can build pipelines that process sensitive data compliantly, providing audit trails and encryption to ensure data privacy. These measures align with both legal requirements and industry best practices, reducing risks associated with sensitive client information exposure.
Transparency and accountability are fundamental to legal AI applications, particularly because legal decisions often affect high-stakes outcomes. Legal professionals, clients, and regulators must understand how an LLM arrived at a particular recommendation or analysis. For example, if an LLM suggests modifications to a contract or flags a clause as high-risk, it’s essential to provide a rationale that explains the underlying reasoning. Model explainability tools, such as attention visualizations and Shapley values, allow users to identify which parts of the input data contributed most to the model’s output. Mathematically, Shapley values $\phi_i$ for a feature iii in an input $x$ can be used to determine the contribution of iii to the overall prediction $f(x)$. By implementing these techniques in Rust, developers can ensure that explanations are not only accurate but also efficiently generated, thanks to Rust’s high-performance capabilities. This level of transparency helps legal teams trust the model’s recommendations, supports compliance with legal standards, and builds confidence in AI-driven systems among clients.
Bias in legal LLMs represents a particularly pressing ethical challenge, as biased outputs can have far-reaching consequences. For instance, if an LLM tasked with reviewing case law exhibits racial or gender biases, its analysis could unfairly favor certain demographic groups over others. Bias detection and mitigation involve evaluating model outputs across different demographic segments, ensuring balanced representation. This can be achieved by calculating performance metrics such as the disparate impact ratio, which measures the relative outcome distribution across demographic groups. Rust’s concurrency features and strong type safety facilitate implementing real-time bias monitoring in LLMs, allowing developers to track and report any emerging patterns of bias. Mitigating bias might involve reweighting or oversampling underrepresented groups in the dataset, techniques that Rust can handle efficiently due to its memory control and performance advantages, ensuring that the bias mitigation process doesn’t hinder model speed.
This pseudocode demonstrates a framework for detecting and mitigating potential bias in a legal Large Language Model (LLM) by examining output distributions across demographic groups. The goal is to analyze model predictions on a legal dataset and identify any skewed patterns that could indicate bias. This approach helps ensure that the model provides equitable results across different demographics, such as gender, age, or ethnicity, supporting fair outcomes in legal contexts.
# Import necessary modules for data handling and statistics
# Define a structure to represent individual legal cases
CLASS LegalCase:
ATTRIBUTE case_text: STRING # Text of the legal case
ATTRIBUTE demographics: STRING # Demographic label, e.g., "gender_male"
ATTRIBUTE prediction: FLOAT # Model's prediction score, e.g., risk score
# Function to detect potential bias by calculating average prediction scores for demographics
FUNCTION detect_bias(cases: LIST of LegalCase) -> DICTIONARY of STRING to FLOAT:
INITIALIZE demographic_totals as an empty DICTIONARY with default FLOAT value 0.0
INITIALIZE demographic_counts as an empty DICTIONARY with default INTEGER value 0
# Sum prediction scores and counts for each demographic group
FOR each case in cases:
SET demographic TO case.demographics
ADD case.prediction TO demographic_totals[demographic]
INCREMENT demographic_counts[demographic] by 1
# Calculate the average prediction score for each demographic
SET bias_report TO an empty DICTIONARY
FOR each (group, total) in demographic_totals:
SET count TO demographic_counts[group]
SET average_score TO total / count
STORE average_score in bias_report[group]
RETURN bias_report
# Main function to demonstrate bias detection
FUNCTION main():
# Define a sample dataset with legal cases and demographic labels
SET cases TO list containing instances of LegalCase, e.g.,
LegalCase with case_text as "Case A", demographics as "gender_male", prediction as 0.8
LegalCase with case_text as "Case B", demographics as "gender_female", prediction as 0.6
# Add more cases as needed
# Run bias detection on the dataset
SET bias_report TO detect_bias(cases)
# Output the bias detection results
PRINT "Bias Detection Report:", bias_report
This pseudocode outlines a structured approach to detecting potential bias in model predictions across demographic groups. The LegalCase class represents individual cases with attributes for the case text, demographic labels, and the model's prediction score. The detect_bias function calculates the average prediction score for each demographic group by iterating through the dataset, summing scores and counting cases per group. It then calculates and stores the average scores in a bias_report dictionary. The main function demonstrates the pipeline by creating a sample dataset, running the bias detection function, and outputting the results. This setup helps developers analyze model behavior, identify potential biases, and work toward mitigating any disparities in model predictions across demographic categories, promoting fairness in legal AI applications.
In real-world applications, organizations deploying legal LLMs are increasingly developing compliance checklists to ensure adherence to ethical and regulatory standards. A compliance checklist for legal LLM deployments might include data minimization practices (to avoid processing unnecessary personal data), periodic audits of model outputs for bias, and ensuring data encryption during processing and storage. By using Rust’s error handling and memory-safe operations, developers can build compliance checkpoints directly into the LLM pipeline. This approach enables seamless logging and auditing, allowing organizations to maintain compliance with frameworks like GDPR and HIPAA without compromising performance. Additionally, by incorporating monitoring and logging mechanisms, Rust can provide a traceable record of data access, ensuring that compliance teams have a clear view of how data is processed and used throughout the LLM lifecycle.
Trends in the legal AI industry reveal a growing focus on responsible AI practices, including efforts to improve model explainability and mitigate bias. As more legal firms adopt AI to assist with document review, regulatory compliance, and client interactions, the need for ethical AI grows in parallel. Emerging techniques in responsible AI, such as adversarial debiasing and federated learning, offer new ways to improve fairness in legal LLMs. Federated learning, for instance, allows models to be trained on decentralized data sources, reducing the need for raw data centralization and thus enhancing data privacy. Rust’s concurrency and data handling features make it well-suited to support federated learning implementations, allowing secure and compliant model training across decentralized datasets, which is essential in privacy-sensitive sectors like law.
In conclusion, the ethical and regulatory considerations in deploying LLMs for legal and compliance applications are integral to building responsible and trustworthy AI systems. By addressing issues of bias, transparency, and data protection, developers can ensure that legal LLMs operate within ethical and regulatory boundaries, providing fair, accountable, and compliant AI solutions. Rust’s emphasis on memory safety, performance, and secure data handling makes it a valuable tool in this context, enabling the development of reliable and compliant legal AI applications. This section underscores the critical importance of ethical AI practices in legal and compliance, highlighting how Rust’s robust feature set supports the creation of AI systems that uphold the values of fairness, transparency, and accountability in high-stakes legal environments.
16.6. Case Studies and Future Directions
Case studies of large language models (LLMs) in legal and compliance illustrate both the opportunities and challenges of deploying AI in high-stakes legal settings. One notable example is the deployment of LLMs in AI-driven contract analysis, where models parse and analyze contracts to identify key clauses, assess risk, and ensure compliance with legal standards. These LLMs streamline the review process by flagging sections that may require legal attention, such as confidentiality, indemnity, and liability clauses. This allows legal professionals to focus their time on high-risk areas, rather than manually reviewing entire documents. However, deploying these models introduced challenges, including the need to ensure interpretability so that legal teams understand the basis for the model’s recommendations. Rust’s memory-safe and concurrency-focused ecosystem provides the reliability needed for real-time, high-precision inference, making it well-suited for applications like contract analysis that require both speed and accuracy.
Figure 6: Some areas of AI transformations in legal and compliance.
Automated compliance monitoring is another field where LLMs have shown promise. In this application, models continuously monitor documents and workflows to ensure that organizational practices align with regulations, such as GDPR or HIPAA. For example, a compliance monitoring system might analyze internal communications and flag mentions of sensitive information, ensuring that organizations remain compliant with data privacy laws. These models often work in tandem with rule-based systems to ensure high accuracy while minimizing false positives. Rust’s performance characteristics make it possible to build real-time monitoring systems, as it supports efficient handling of large document streams without compromising processing speed. The challenges encountered in this deployment highlight the importance of maintaining up-to-date models, as regulatory changes require frequent updates to ensure compliance. Rust’s compile-time checks and memory safety features facilitate model updates by making code refactoring less error-prone, ensuring compliance systems remain robust even as legal requirements evolve.
Looking to the future, LLMs hold transformative potential in legal research. Legal research tools powered by LLMs can assist professionals in rapidly gathering case law, analyzing judicial opinions, and exploring relevant statutes. By understanding the context of legal decisions, these tools can surface similar cases, suggest interpretations, and outline precedents that may apply to a current case. This approach can be formalized by representing legal decisions as vectors in a high-dimensional space, where similarity scores between vectors indicate the relevance of past cases to new legal questions. Mathematically, this similarity could be calculated by computing the cosine similarity between the vector representation $\vec{d_1}$ of a legal case $d_1$ and a new document $\vec{d_2}$, where a higher cosine similarity indicates stronger relevance. Rust’s low-level control over performance optimizations allows for the efficient implementation of such vector operations, making it ideal for scaling LLM-powered legal research tools that process vast case law databases.
Analyzing case studies of LLM deployments in legal and compliance yields valuable insights for future projects. One significant lesson is the need for scalability, especially as legal teams handle increasingly large datasets. By leveraging Rust’s concurrency model, developers can design pipelines that process multiple documents simultaneously, ensuring scalability as case law and regulatory documents grow. Another lesson is the importance of accuracy and regulatory compliance; any model used in legal settings must undergo rigorous evaluation to confirm that its outputs are legally sound and meet regulatory standards. For instance, an LLM used in compliance monitoring must be regularly evaluated against updated regulatory frameworks. This can be achieved by incorporating test cases for different compliance scenarios into the deployment pipeline, ensuring that the model continues to perform accurately as legal standards evolve.
There are also opportunities for innovation in LLMs for legal and compliance. The development of adaptive LLMs capable of learning from user interactions presents one such opportunity. For example, if a legal team repeatedly adjusts an LLM’s recommendations in contract analysis, adaptive models could integrate these adjustments, improving over time by learning the specific preferences and priorities of each legal team. Federated learning presents another exciting avenue, allowing legal firms to train models on decentralized datasets without sharing sensitive information. Federated learning distributes model training across multiple local devices, updating the central model without exposing proprietary or confidential legal data. Rust’s focus on security, coupled with its performance optimization capabilities, makes it an excellent choice for implementing federated learning algorithms, which require efficient data handling and security protocols to maintain client confidentiality across distributed networks.
This pseudocode describes a legal contract analysis tool designed to process contract text, identify high-risk clauses, and flag them for legal review. The tool uses a Large Language Model (LLM) to parse and analyze the contract text, highlighting clauses that could pose potential risks, such as non-compete and indemnity clauses. This example showcases a high-performance pipeline for contract analysis, leveraging concurrency and memory safety to handle multiple requests simultaneously, making it suitable for real-time document processing in legal contexts.
# Import necessary modules for model inference, text processing, and API handling
# Define a structure to receive contract input from users
CLASS ContractInput:
ATTRIBUTE text: STRING
# Define the application state to hold the LLM model for contract analysis
CLASS AppState:
FUNCTION __init__(self, model):
# Store the model in a secure, thread-safe structure
SET self.model TO a thread-safe reference to the LLM model
# Define the endpoint for analyzing contract clauses
FUNCTION analyze_contract_endpoint(input: ContractInput, state: AppState) -> LIST of STRINGS:
# Securely access the model by locking the state
ACQUIRE lock on state.model OR RETURN "Model lock error"
# Tokenize and process the contract text for model inference
SET tokens TO model.tokenizer.encode(input.text)
SET output TO model.forward(tokens) OR RETURN "Inference error"
# Flag high-risk clauses (simulated for demonstration purposes)
SET flagged_clauses TO [
"Non-compete clause - Restrictive, potential legal risk.",
"Indemnity clause - High liability risk for client."
]
# Return the flagged clauses in a JSON response
RETURN JSON response containing flagged_clauses
# Main function to configure the model and launch the API for contract analysis
FUNCTION main() -> SUCCESS or ERROR:
# Initialize model configuration and device (e.g., CPU) for inference
SET config TO default configuration for the model
SET device TO CPU
# Load the pre-trained DistilBERT model onto the specified device
SET model TO load DistilBERT model with config on device
# Set up the application state with the loaded model
SET state TO new instance of AppState with model
# Build and configure the API:
INITIALIZE API framework
REGISTER endpoint "/analyze" with analyze_contract_endpoint
ATTACH application state for secure, concurrent access
# Launch the API server to handle incoming contract analysis requests
START the API server
# Execute the main function to deploy the contract analysis tool
CALL main()
The pseudocode details a contract analysis tool that ingests legal documents, processes them through an LLM, and flags high-risk clauses for review. The ContractInput class structures the incoming contract text, while AppState securely stores the model for concurrent access. The analyze_contract_endpoint function tokenizes and processes the contract text, running it through the model to generate predictions. For demonstration, it simulates flagging clauses like non-compete and indemnity, which may carry legal risks. The main function sets up the model configuration and device, initializes the API, and launches the server to handle concurrent contract analysis requests. This setup ensures efficient, scalable processing of legal documents, with Rust’s memory safety and concurrency model providing robustness for high-throughput applications.
Looking ahead, LLMs have immense potential to transform legal services and compliance management. Future advancements could see LLMs supporting predictive legal analytics, where models forecast the likelihood of case outcomes based on historical legal data. Such models would be invaluable to legal teams in strategy development, helping them assess probable case trajectories and prepare accordingly. Another area of growth is AI-driven contract generation, where LLMs could be trained to draft contracts autonomously based on specified clauses and terms, helping legal professionals draft standardized documents with greater efficiency. Rust’s performance capabilities are particularly relevant here, as predictive analytics and automated contract generation require fast, reliable processing of complex legal inputs.
To fully realize the potential of LLMs in legal and compliance, several challenges must be addressed. Data availability is one, as high-quality, labeled legal datasets are limited due to privacy and confidentiality constraints. Enhancing model interpretability is also essential; as LLMs take on more significant roles in legal analysis, understanding how models arrive at conclusions is critical for trust and transparency. Finally, regulatory barriers may arise as governments and legal bodies seek to impose limits on AI-driven decision-making in law, necessitating models that can justify their recommendations with clear, explainable reasoning. Rust’s secure memory management and ability to handle complex data structures make it ideal for building systems that prioritize data integrity, compliance, and explainability.
In conclusion, the case studies of LLMs in legal and compliance illustrate the considerable impact these models can have in transforming traditional legal processes, from contract analysis to compliance monitoring and legal research. By leveraging Rust’s performance, concurrency, and memory safety, developers can create robust, efficient LLM systems tailored to the unique demands of the legal field. As the legal industry continues to embrace AI, Rust provides a powerful foundation for building ethical, transparent, and high-performance LLM applications that support legal professionals and enhance compliance management. This section underscores the transformative potential of LLMs in legal and compliance, highlighting how Rust’s unique strengths make it an ideal language for pioneering advancements in this critical area.
16.7. Conclusion
The chapter covers the entire process, from building specialized data pipelines and training models on complex legal and regulatory data to deploying them in secure, compliant environments. It emphasizes the importance of accuracy, interpretability, and ethical considerations, ensuring that LLMs are both effective and responsible in high-stakes legal applications. The chapter also discusses strategies for monitoring and maintaining deployed models, ensuring they remain compliant with evolving legal standards and regulations. Through practical examples and case studies, readers gain insights into the development and deployment of LLMs in legal and compliance using Rust.
16.7.1. Further Learning with GenAI
Each prompt is crafted to encourage critical thinking and technical experimentation, helping readers to understand the complexities and challenges involved in developing and deploying LLMs in these sensitive and high-stakes fields.
Explain the role of large language models (LLMs) in the legal sector. How can LLMs enhance applications such as contract analysis, legal research, and regulatory compliance?
Discuss the key challenges of applying LLMs in legal and compliance contexts, particularly in handling complex legal language and ensuring data privacy. How can Rust be leveraged to address these challenges?
Describe the importance of accuracy, reliability, and interpretability in legal and compliance-related LLM applications. How can Rust-based models be designed to meet these requirements?
Analyze the potential impact of LLMs on legal processes and compliance management. What are the benefits and risks of automating legal tasks using LLMs?
Explore the ethical considerations of deploying LLMs in legal and compliance, particularly regarding bias, fairness, and the implications of automating decision-making processes. How can Rust-based systems be designed to mitigate these ethical issues?
Explain the process of building a robust data pipeline for legal and compliance applications using Rust. What are the essential steps for ensuring data integrity, accuracy, and privacy when handling legal data?
Discuss the challenges of working with complex, structured, and unstructured legal data. How can Rust-based tools be used to preprocess, normalize, and annotate legal data for LLM training?
Analyze the role of data annotation and labeling in enhancing LLM training for legal and compliance applications. How can Rust be used to implement effective data annotation strategies?
Explore the specific considerations for training LLMs on legal and compliance data, including handling imbalanced datasets and ensuring high precision. How can Rust be used to implement a robust training pipeline?
Discuss the importance of transfer learning and fine-tuning pre-trained models for legal-specific tasks. What are the key challenges and benefits of adapting general-purpose LLMs to legal applications?
Explain the role of explainability and interpretability in legal LLMs. How can Rust-based models be designed to ensure that their outputs are understandable and actionable for legal professionals?
Analyze the challenges of deploying LLMs in legal environments, particularly in terms of latency, accuracy, and scalability. How can Rust be used to build and deploy efficient inference pipelines for legal LLMs?
Discuss the regulatory requirements for deploying AI in legal and compliance contexts, such as GDPR, HIPAA, and industry-specific standards. How can developers ensure that their Rust-based LLM applications comply with these regulations?
Explore the potential risks of deploying biased or opaque LLMs in legal contexts. How can Rust-based systems be designed to detect and mitigate these risks, ensuring fairness and transparency?
Discuss the importance of real-time inference capabilities in critical legal applications, such as contract analysis and compliance monitoring. How can Rust be used to optimize inference pipelines for speed and accuracy in these scenarios?
Analyze the role of continuous monitoring and maintenance in ensuring the long-term reliability of deployed legal and compliance LLMs. How can Rust-based systems be set up to track performance and implement updates?
Explore the challenges of integrating LLMs into existing legal practice management systems. How can Rust-based models be deployed in a way that ensures compatibility and minimal disruption?
Discuss the future potential of LLMs in legal and compliance, including emerging trends like AI-driven contract analysis and automated compliance monitoring. How can Rust be leveraged to innovate in these areas?
Explain the key lessons learned from existing case studies of LLM deployments in legal and compliance. What best practices can be derived from these experiences, and how can they inform the development of future Rust-based legal applications?
Analyze the broader implications of using LLMs in the legal and compliance sectors. How can these technologies be harnessed to improve the efficiency and fairness of legal processes while ensuring adherence to ethical and regulatory standards?
By engaging with these exercises, you will build a deep understanding of how to create robust, compliant, and high-performance legal systems that leverage the power of LLMs.
16.7.2. Hands On Practices
Self-Exercise 16.1: Building a Legal Data Pipeline Using Rust
Objective: To design and implement a robust data pipeline for legal applications using Rust, focusing on preprocessing, normalization, and annotation of complex legal documents.
Tasks:
Set up a Rust-based data pipeline to ingest, preprocess, and normalize legal data, ensuring data integrity and accuracy across diverse document types.
Implement annotation techniques to label important legal entities (e.g., parties, dates, clauses) in the data, making it suitable for training a large language model.
Test the pipeline with a variety of legal documents, identifying and addressing challenges related to data consistency, standardization, and annotation quality.
Experiment with different preprocessing methods to optimize the pipeline for accuracy and reliability in downstream legal tasks.
Deliverables:
A Rust codebase for a legal data pipeline that includes preprocessing, normalization, and annotation components.
A detailed report on the implementation process, including challenges encountered and solutions applied.
A performance evaluation of the pipeline, focusing on its ability to handle and annotate large volumes of legal data effectively.
Self-Exercise 16.2: Training a Legal-Specific LLM with Rust
Objective: To train a large language model on legal data using Rust, with a focus on handling complex legal language, ensuring high precision, and maintaining model interpretability.
Tasks:
Prepare a legal-specific dataset, ensuring it is properly preprocessed and annotated for training a large language model.
Implement a Rust-based training pipeline, incorporating techniques to handle the complexity of legal language and achieve high precision in model predictions.
Experiment with different methods to enhance model interpretability, ensuring that the outputs are understandable and actionable for legal professionals.
Evaluate the trained model on a validation dataset, analyzing its accuracy, interpretability, and performance in legal-specific tasks.
Deliverables:
A Rust codebase for training a legal-specific large language model, including data preprocessing and model interpretability techniques.
A training report detailing the model’s performance on legal tasks, with a focus on accuracy, precision, and interpretability.
A set of recommendations for further improving the model’s performance and applicability in legal applications.
Self-Exercise 16.3: Deploying a Legal LLM for Real-Time Inference
Objective: To deploy a large language model for real-time inference in a legal environment, focusing on optimizing latency, accuracy, and scalability.
Tasks:
Implement an inference pipeline in Rust that serves a legal-specific large language model, optimizing for low latency and high accuracy.
Deploy the model in a secure and scalable environment, ensuring compliance with legal regulations such as GDPR and HIPAA.
Set up a real-time monitoring system to track the performance of the deployed model, focusing on key metrics such as latency, accuracy, and throughput.
Analyze the monitoring data to identify potential issues with the model’s performance, and implement updates or adjustments as needed.
Deliverables:
A Rust codebase for deploying and serving a legal large language model, including real-time inference capabilities.
A deployment report detailing the steps taken to ensure compliance with legal regulations and optimize inference performance.
A monitoring report that includes performance metrics and an analysis of the deployed model’s real-time behavior, with recommendations for ongoing maintenance and updates.
Self-Exercise 16.4: Ensuring Ethical Compliance in Legal LLM Deployment
Objective: To design and implement strategies for ensuring ethical compliance in the deployment of large language models in legal contexts, focusing on bias detection, fairness, and transparency.
Tasks:
Implement bias detection techniques in a deployed legal LLM, ensuring that the model’s predictions are fair and equitable across different demographic groups.
Develop methods to enhance the transparency of the model’s decision-making processes, making them understandable for stakeholders, including legal professionals and clients.
Integrate continuous monitoring for ethical compliance, including mechanisms to detect and respond to potential ethical violations or model drift.
Conduct a thorough evaluation of the deployed model’s ethical performance, focusing on bias, fairness, and adherence to legal standards.
Deliverables:
A Rust codebase with integrated bias detection and transparency features for a deployed legal large language model.
An ethical compliance report detailing the strategies used to ensure fairness and transparency, including bias detection results.
An evaluation report on the model’s ethical performance, with recommendations for improving ethical compliance in future deployments.
Self-Exercise 16.5: Innovating Legal Applications with LLMs: Case Study Implementation
Objective: To analyze a real-world case study of large language model deployment in legal contexts and implement a small-scale version using Rust, focusing on replicating the critical aspects of the deployment.
Tasks:
Select a case study of a successful LLM deployment in legal or compliance contexts, analyzing the key challenges, solutions, and outcomes.
Implement a small-scale version of the case study using Rust, focusing on the most critical components such as data handling, model training, and deployment.
Experiment with the implementation to explore potential improvements or adaptations, considering factors such as model performance, scalability, and compliance.
Evaluate the implemented model against the original case study, identifying key takeaways and lessons learned for future legal LLM projects.
Deliverables:
A Rust codebase that replicates a small-scale version of the selected legal LLM case study, including key deployment components.
A case study analysis report that details the original deployment’s challenges, solutions, and outcomes, along with insights gained from the implementation.
A performance evaluation of the implemented model, with a comparison to the original case study and recommendations for future innovations in legal LLM deployments.
Comments