Chapter 15
Financial Applications of LLMs
"In finance, the difference between success and failure often hinges on milliseconds and precision. The integration of AI, particularly LLMs, offers unprecedented opportunities to gain an edge, but only with the right balance of innovation and responsibility." — Andrew Ng
Chapter 15 of LMVR explores the transformative applications of large language models (LLMs) in the financial sector, focusing on the unique challenges and opportunities in this high-stakes environment. The chapter covers the entire lifecycle of financial LLMs, from building robust data pipelines and training models on complex financial data to deploying them in compliance with stringent financial regulations. It addresses the ethical considerations and regulatory requirements essential for the responsible use of AI in finance, emphasizing the importance of transparency, accuracy, and fairness. Through practical examples and case studies, the chapter equips readers with the tools and knowledge to develop and deploy LLMs in finance using Rust, ensuring these powerful models are both effective and compliant with industry standards.
15.1. Introduction to LLMs in Finance
The financial sector has rapidly adopted large language models (LLMs) for applications that demand high accuracy and speed, including fraud detection, sentiment analysis, algorithmic trading, and risk management. By processing vast amounts of unstructured data, such as news articles, earnings reports, and social media posts, LLMs can extract valuable insights that inform financial decisions. For instance, in fraud detection, an LLM can analyze patterns in transaction data to detect anomalies, while sentiment analysis enables market participants to assess the public mood around specific stocks or economic events. Algorithmic trading uses LLMs to parse and interpret financial news, enabling real-time trading strategies that react to new information. The ability of LLMs to identify patterns in diverse datasets also supports risk management by predicting potential market downturns or assessing credit risk. However, deploying LLMs in finance poses specific challenges, such as handling large volumes of sensitive data and adhering to strict regulatory requirements like those set by the SEC (Securities and Exchange Commission) and FINRA (Financial Industry Regulatory Authority). Rust’s performance, memory safety, and concurrency make it particularly suited for implementing LLMs in financial applications, ensuring both high performance and data security.
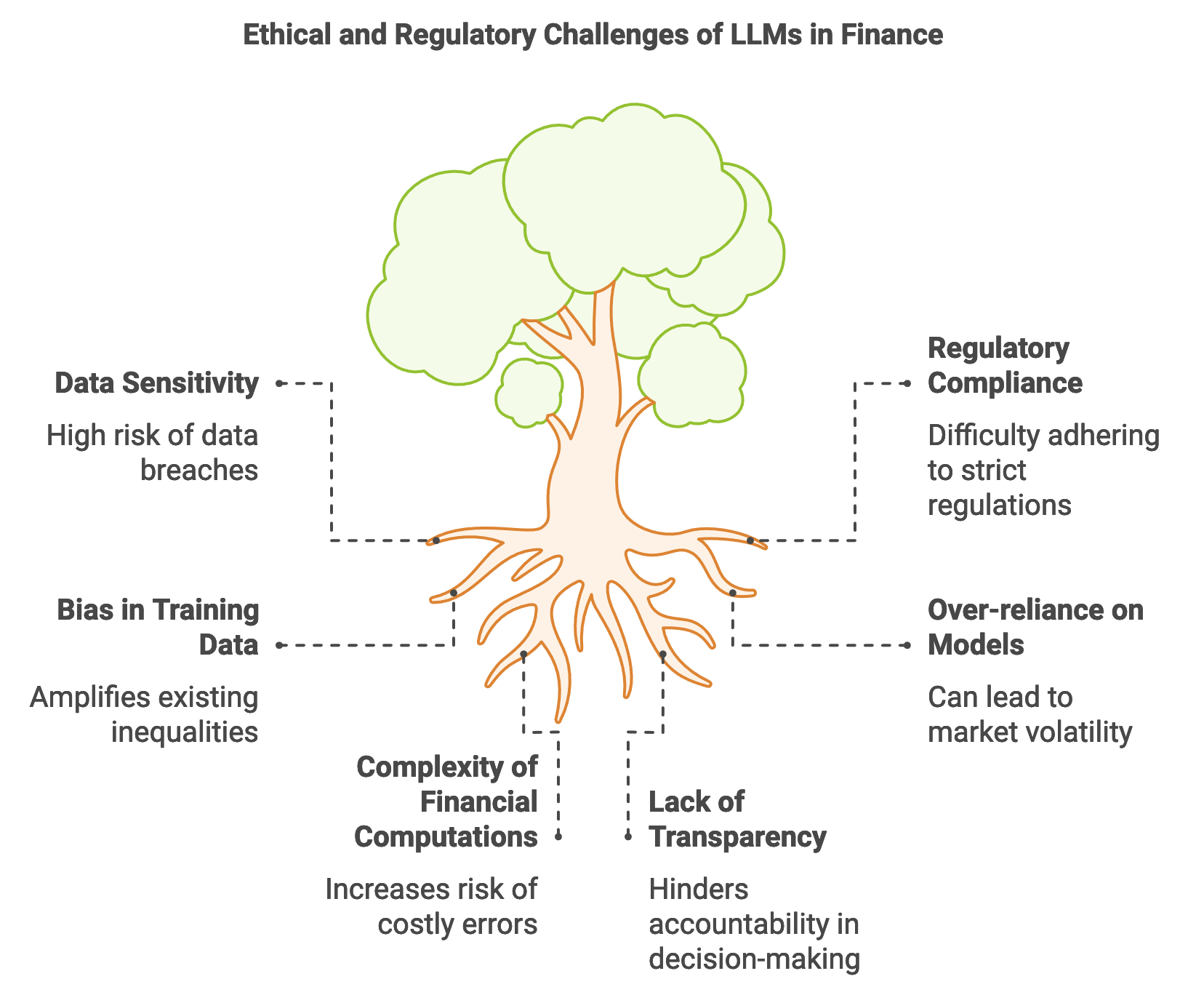
Figure 1: Key challenges on LLMs in Finance.
In finance, real-time data processing and rapid decision-making are essential, as market conditions can shift in milliseconds. LLMs deployed in high-frequency trading, for example, must interpret and react to market data nearly instantaneously. Mathematically, the decision-making process can be modeled as a function $(x, t) \rightarrow a$, where $x$ represents the market data at time $t$, and aaa denotes the recommended action, such as a buy, hold, or sell signal. Since financial applications often handle enormous data streams, the LLM must operate efficiently without sacrificing accuracy. Rust’s asynchronous programming and low-level memory management provide a foundation for achieving these performance requirements. For instance, Rust’s concurrency features allow the model to process multiple data streams simultaneously, enabling faster and more efficient trading algorithms. Furthermore, Rust’s strong type system helps manage the complexity of financial computations, reducing the risk of errors that could lead to costly financial mistakes.
The use of LLMs in finance also raises ethical considerations, particularly concerning bias and algorithmic decision-making. An LLM trained on biased historical data may amplify existing inequalities or make skewed predictions, impacting individuals’ financial wellbeing. For example, if an LLM used in credit scoring has been trained on data with discriminatory patterns, it may unjustly deny loans to certain demographics. Furthermore, algorithmic decision-making in finance introduces risks of over-reliance on models, where decisions made by LLMs can influence market behavior and, in some cases, amplify volatility. These risks underscore the need for responsible AI practices in financial applications, including regular auditing of model predictions and using explainability techniques to allow financial analysts to interpret and validate model outputs. Techniques such as feature importance analysis, represented mathematically by calculating $\phi(x_i)$ for each input feature $x_i$ in a prediction function $f(x)$, allow analysts to see which factors most influence a model’s decision, thereby promoting transparency and accountability.
The pseudo-code below represents an advanced sentiment analysis tool designed to interpret public sentiment around financial assets, such as stocks. This tool uses a shared model to analyze text input (such as news headlines or social media posts), predicting sentiment as positive, neutral, or negative. It incorporates a caching mechanism to optimize repeated sentiment requests and employs specific preprocessing steps to handle financial terms and entities. The model’s sentiment predictions provide valuable insights into public sentiment trends, supporting informed financial decision-making.
// Define input data structure
STRUCTURE TextInput:
text: STRING
// Define shared application state structure
STRUCTURE AppState:
model: SHARED_RESOURCE(SentimentModel)
cache: SHARED_RESOURCE(Cache) // Cache to store recent sentiment results for efficiency
// Main function to initialize and run the API server
FUNCTION main():
CONFIGURE device AS "CPU"
LOAD configuration FOR SentimentModel
// Load pre-trained model with advanced configuration
model = LOAD_MODEL(SentimentModel, configuration, device)
// Set up shared state with model and cache
state = AppState(
model = CREATE_SHARED_RESOURCE(model),
cache = CREATE_SHARED_RESOURCE(Cache)
)
// Start API server with sentiment analysis endpoint
START_API_SERVER(state, "/sentiment", sentiment_analysis)
// API endpoint for sentiment analysis
FUNCTION sentiment_analysis(input: TextInput, state: AppState) RETURNS JSON_RESPONSE:
// Check if input text sentiment is cached
IF state.cache.contains(input.text):
RETURN state.cache.get(input.text) // Return cached result
// Tokenize and preprocess input text for complex sentiment analysis
tokens = tokenize_and_preprocess(input.text)
// Acquire shared model for inference
model = ACQUIRE_RESOURCE(state.model)
// Perform sentiment inference on tokenized input
sentiment_score = model.perform_inference(tokens)
// Release model after inference
RELEASE_RESOURCE(state.model)
// Interpret sentiment score into detailed categories (e.g., strongly positive, positive, neutral, negative, strongly negative)
sentiment_result = interpret_sentiment_score(sentiment_score)
// Store result in cache for future requests
state.cache.store(input.text, sentiment_result)
RETURN JSON_RESPONSE(sentiment_result)
// Function to tokenize and preprocess input text with advanced preprocessing steps
FUNCTION tokenize_and_preprocess(text: STRING) RETURNS TOKENIZED_DATA:
// Convert to lowercase, remove special characters, and handle common abbreviations
processed_text = preprocess_text(text)
// Use financial-specific tokenizer for advanced entity recognition (e.g., company names, stock symbols)
tokens = tokenizer.encode(processed_text)
RETURN tokens
// Function to interpret sentiment score based on financial thresholds
FUNCTION interpret_sentiment_score(score: FLOAT) RETURNS STRING:
IF score > 0.8:
RETURN "Strongly Positive"
ELSE IF score > 0.5:
RETURN "Positive"
ELSE IF score > -0.5:
RETURN "Neutral"
ELSE IF score > -0.8:
RETURN "Negative"
ELSE:
RETURN "Strongly Negative"
// Function to preprocess text by removing noise and handling abbreviations
FUNCTION preprocess_text(text: STRING) RETURNS STRING:
text = TO_LOWERCASE(text)
text = REMOVE_SPECIAL_CHARACTERS(text)
text = HANDLE_ABBREVIATIONS(text)
RETURN text
// Function to load the model with given configuration
FUNCTION LOAD_MODEL(model_type, config, device) RETURNS SentimentModel:
RETURN new SentimentModel(config, device)
// Define cache structure to store recent analysis results
STRUCTURE Cache:
// Store result with time-to-live for cache efficiency
FUNCTION store(key, value)
FUNCTION contains(key) RETURNS BOOLEAN
FUNCTION get(key) RETURNS VALUE IF EXISTS
The tool works by receiving a text input, checking a cache to see if a recent sentiment result already exists for the text, and if not, tokenizing and preprocessing the text for analysis. It then acquires a shared model resource to perform sentiment inference on the input. The model’s output, a sentiment score, is interpreted into detailed categories like "Strongly Positive" or "Negative" based on predefined thresholds, enhancing its applicability for financial analysis. The result is stored in the cache to improve performance for future requests. This design ensures efficient, context-aware sentiment analysis that leverages caching and domain-specific tokenization.
Real-world applications of LLMs in finance are rapidly evolving, with prominent examples in predictive modeling and risk assessment. For instance, LLMs are employed in credit risk scoring, where they analyze applicant data alongside external news or economic trends to predict the likelihood of default. This prediction process can be represented as a function $f(x, y) \rightarrow r$, where $x$ denotes applicant data and $y$ represents external economic indicators, producing a risk score $r$ that informs lending decisions. LLMs are also used in algorithmic trading to model price movements, generating trading signals based on the probability of future price fluctuations. These models frequently incorporate reinforcement learning techniques to optimize trading strategies over time, allowing them to adapt to changing market dynamics.
Current trends indicate that LLMs will play an even larger role in finance, particularly in personalized financial advisory services and automated compliance monitoring. Personalized financial advisory services are emerging, where LLMs provide customized investment advice by analyzing clients’ financial goals, risk tolerance, and market conditions. Rust’s speed and concurrency are advantageous in this context, enabling real-time responses as clients interact with advisory systems. Automated compliance monitoring is another promising application, where LLMs scan and analyze large volumes of financial communications to detect regulatory violations. In this use case, Rust’s memory safety and efficient data handling reduce the risk of data breaches and ensure compliance with strict financial regulations.
The future potential of LLMs in finance is vast, but achieving widespread adoption will require overcoming challenges related to data privacy, interpretability, and scalability. As financial data is sensitive, ensuring compliance with regulations like GDPR (General Data Protection Regulation) and the California Consumer Privacy Act (CCPA) is essential for all LLM applications. Additionally, interpretability remains a significant hurdle. As models make increasingly complex predictions, financial analysts and regulators need to understand how predictions are derived. Techniques like layer-wise relevance propagation (LRP) and attention mechanisms in transformer models can help illuminate the decision-making process, but more advancements in explainability are necessary to meet the demands of the finance industry.
In conclusion, LLMs have the potential to transform the financial industry, from real-time sentiment analysis to advanced risk assessment and automated compliance. Rust provides an ideal foundation for building these applications, offering the performance, concurrency, and safety needed to handle the demands of high-stakes financial environments. By addressing the unique challenges posed by financial applications, such as data privacy and regulatory compliance, Rust-based LLMs are positioned to drive significant innovation in finance. This section underscores the critical role of LLMs in finance and the opportunities Rust offers to create efficient, secure, and compliant AI-driven financial solutions.
15.2. Building Financial Data Pipelines with Rust
Financial data pipelines form the backbone of large language model (LLM) applications in finance, providing the structured and unstructured data required for training and inference. The data used in financial LLMs is highly diverse, encompassing structured datasets such as balance sheets, income statements, and trading records, as well as unstructured sources like news articles, earnings calls, and social media posts. Structured data is typically organized in well-defined formats, making it easier to parse and analyze, while unstructured data requires sophisticated preprocessing to convert text and multimedia content into machine-readable formats. Financial data pipelines must be designed to handle the sheer volume, velocity, and variety of financial data, ensuring that the data is clean, timely, and relevant to the LLM’s objectives. Rust’s performance, memory safety, and rich ecosystem of data-handling crates make it well-suited for developing robust financial data pipelines that operate efficiently and reliably.
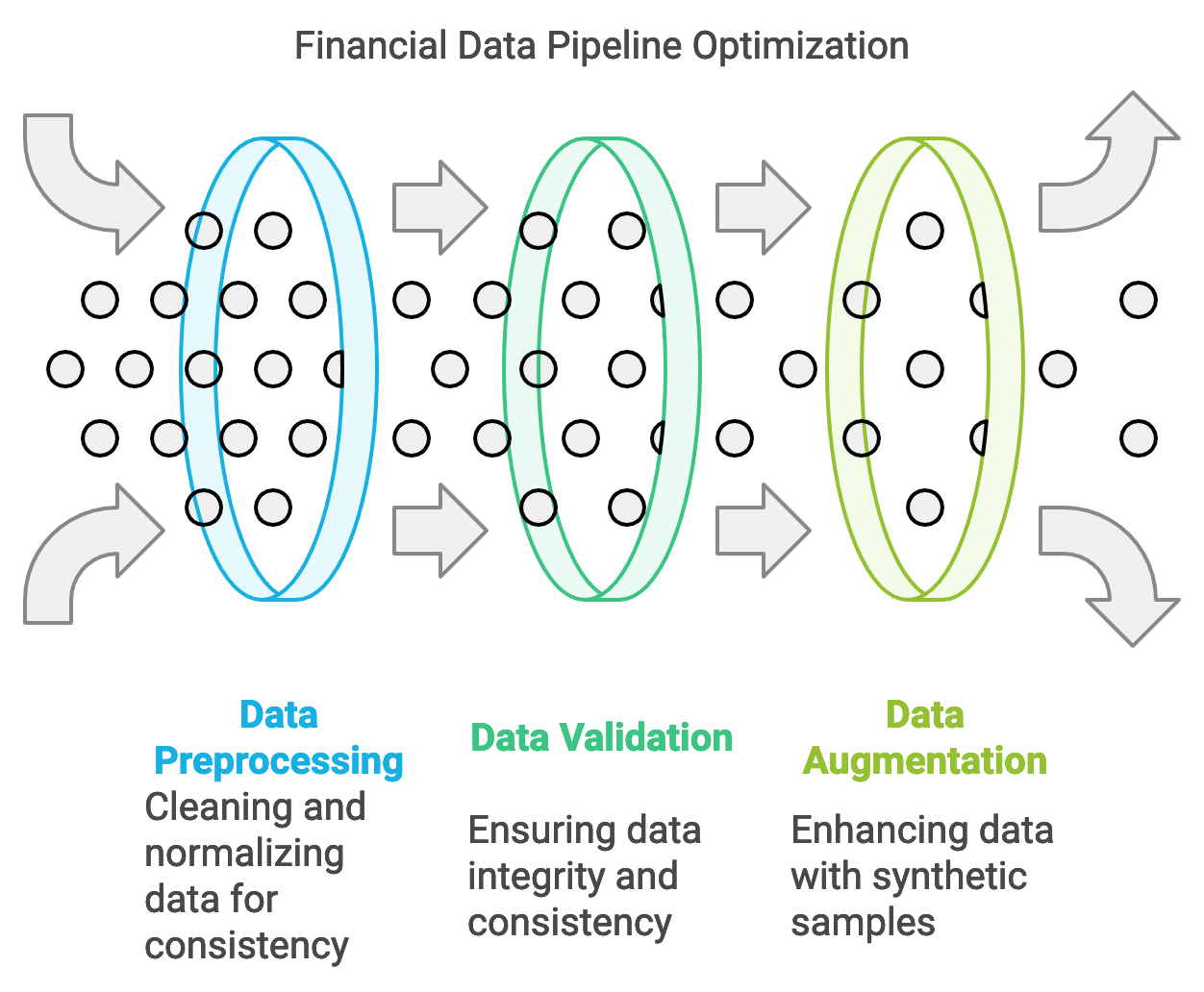
Figure 2: Typical data pipeline and preprocessing in Finance.
A fundamental aspect of financial data pipelines is data preprocessing, which includes cleaning, normalization, and feature extraction. Financial data often contains noise or missing values that can degrade model performance if not addressed. For instance, stock prices may be affected by one-off events that need to be identified and potentially excluded from training data. Mathematically, data preprocessing can be represented as a transformation $T(x) \rightarrow x'$, where $x$ is the raw data and $x'$ is the cleaned and normalized data, suitable for model input. This transformation is crucial for ensuring that the LLM receives consistent and high-quality input, which in turn improves its predictive accuracy. Rust’s strict type-checking and error handling help prevent issues during preprocessing, enabling developers to build pipelines that rigorously handle edge cases, such as missing values or out-of-range financial metrics, thereby maintaining data quality across all processing stages.
Working with diverse and volatile financial data sources presents unique challenges. Financial data is subject to rapid changes, especially in scenarios like market trading, where real-time data updates are critical. Additionally, data from multiple sources may vary in quality, format, and structure. For example, financial statements follow standard accounting formats, while social media sentiment data is unstructured and often includes slang, jargon, or incomplete sentences. To address these issues, data pipelines in Rust can be structured to include validation layers that check for data integrity, ensuring consistency and reliability throughout the process. Techniques like deduplication, outlier detection, and temporal alignment are implemented to maintain consistency across time-series data, which is especially relevant in applications like predictive modeling. Rust’s concurrency features allow developers to process data streams from multiple sources simultaneously, optimizing pipeline throughput without sacrificing data quality.
Data augmentation and synthetic data generation are increasingly important in financial LLM training, as they enable models to learn from diverse scenarios and rare events. Financial markets are influenced by unique events such as economic crises or pandemics, which may not be well-represented in historical data. By generating synthetic data, developers can simulate such rare scenarios, improving the model’s robustness and generalization. Synthetic data generation can be represented by a function $S(x) \rightarrow x_{\text{synth}}$, where $S$ is a generative process that produces synthetic samples $x_{\text{synth}}$ from original data $x$. This approach is valuable in risk management models, where the goal is to predict outcomes under extreme market conditions. Rust’s low-level control and efficient data processing make it suitable for generating and handling large volumes of synthetic data, ensuring that the pipeline remains performant even with augmented datasets.
To demonstrate a practical financial data pipeline, consider the following example, which ingests financial news articles, preprocesses the text, and normalizes the data for LLM training. The pseudo-code below represents a robust financial data pipeline designed to ingest, preprocess, normalize, and extract features from financial news articles, preparing the data for training large language models (LLMs) or other analyses. This advanced pipeline fetches articles from an external API, cleans and tokenizes the content, removes irrelevant words, and focuses on financial keywords, providing relevant insights into public financial sentiment. Additionally, the pipeline implements caching to optimize repeated access to processed articles.
// Define structure for news articles
STRUCTURE NewsArticle:
title: STRING
content: STRING
published_date: DATE
// Function to clean and preprocess text data
FUNCTION preprocess_text(text: STRING) RETURNS STRING:
// Remove special characters, convert to lowercase, and tokenize text
cleaned_text = REMOVE_SPECIAL_CHARACTERS(text)
tokenized_text = TOKENIZE_TEXT(cleaned_text)
RETURN TO_LOWERCASE(tokenized_text)
// Function to normalize data by removing stopwords, filtering keywords, and lemmatizing
FUNCTION normalize_text(text: STRING) RETURNS STRING:
DEFINE stopwords AS ["the", "is", "at", "of", "on", "and", "a", "to"]
DEFINE financial_keywords AS ["stock", "market", "finance", "investment", "shares"]
filtered_words = []
FOR word IN SPLIT_WORDS(text):
IF word NOT IN stopwords AND word IN financial_keywords:
lemmatized_word = LEMMATIZE(word)
APPEND lemmatized_word TO filtered_words
RETURN JOIN(filtered_words, " ")
// Function to extract key financial features from the text
FUNCTION extract_features(text: STRING) RETURNS FEATURE_VECTOR:
DEFINE features AS EMPTY_VECTOR
IF "price increase" IN text OR "bullish" IN text:
features["sentiment"] = "positive"
IF "price drop" IN text OR "bearish" IN text:
features["sentiment"] = "negative"
features["word_count"] = COUNT_WORDS(text)
RETURN features
// Asynchronous function to fetch and process data from an external API
ASYNC FUNCTION fetch_and_process_data(client: HttpClient, url: STRING) RETURNS NewsArticle:
response = client.GET(url)
article = PARSE_JSON(response, NewsArticle)
// Preprocess and normalize article content
cleaned_content = preprocess_text(article.content)
normalized_content = normalize_text(cleaned_content)
// Extract financial features from the normalized content
features = extract_features(normalized_content)
// Return processed article with extracted features
RETURN NewsArticle(
title = article.title,
content = normalized_content,
published_date = article.published_date,
features = features
)
// Function to cache processed articles for performance optimization
FUNCTION cache_article(article: NewsArticle, cache: Cache):
IF cache.contains(article.title):
RETURN cache.get(article.title)
cache.store(article.title, article)
RETURN article
// Main function to initialize HTTP client and start processing
ASYNC FUNCTION main():
client = INITIALIZE_HTTP_CLIENT()
url = "https://api.example.com/news/latest"
// Fetch and process data from API
article = fetch_and_process_data(client, url)
// Cache the processed article for quick future access
processed_article = cache_article(article, Cache)
DISPLAY(processed_article)
The pipeline begins by fetching a news article from an external API asynchronously, which is then processed through several stages. First, the article content is cleaned by removing special characters and converting text to lowercase. It then passes through normalization, where stopwords are removed, and only key financial terms are retained. Next, relevant features, such as sentiment and word count, are extracted from the text. The final processed article, including extracted features, is cached to reduce redundant processing. This efficient design ensures that the data is consistently preprocessed, normalized, and optimized for quick access, supporting scalable and accurate financial sentiment analysis.
Feature extraction is another critical step in preparing financial data for LLMs. For unstructured text, feature extraction often involves identifying keywords, topics, or sentiment indicators. These features can be derived using statistical or machine learning techniques, transforming raw data into meaningful inputs that an LLM can interpret. For instance, the frequency of certain terms in news articles may indicate market sentiment or volatility, which can be extracted using term frequency-inverse document frequency (TF-IDF) methods. Mathematically, TF-IDF is represented as $\text{TF-IDF}(t, d) = \text{tf}(t, d) \times \text{idf}(t)$, where $\text{tf}(t, d)$ is the term frequency of $t$ in document $d$ and $\text{idf}(t)$ is the inverse document frequency. Rust’s strong type-checking ensures that features are extracted accurately, reducing the risk of errors that could affect model training.
Real-world applications of Rust-based data pipelines in finance demonstrate the importance of data quality and consistency. For example, a global investment firm used a Rust pipeline to process news data for risk assessment, allowing them to identify emerging threats or opportunities in real-time. By implementing deduplication, sentiment analysis, and anomaly detection, the pipeline maintained high data integrity and reduced latency, providing analysts with timely insights. This use case highlights the role of Rust in ensuring that financial data pipelines are efficient, secure, and aligned with the fast-paced demands of the financial industry.
The latest trends in financial data pipelines emphasize the integration of diverse data sources, including alternative data such as social media sentiment, climate data, and supply chain metrics. These data sources provide unique insights into market trends and risks but require extensive preprocessing to align with traditional financial datasets. Rust’s concurrency and memory safety make it an ideal language for handling these complex data workflows, enabling developers to build scalable pipelines that support high-throughput data processing. Additionally, synthetic data generation is gaining traction, as it helps models learn from scenarios that are rare but critical, such as economic recessions. Rust’s efficiency in handling large-scale data generation further supports this trend, allowing LLMs to be trained on diverse datasets that enhance predictive accuracy.
In conclusion, Rust’s capabilities make it a powerful tool for building financial data pipelines that support LLM applications. From handling diverse financial data sources to implementing robust preprocessing and feature extraction, Rust’s speed and reliability ensure that financial data is prepared to meet the demands of modern LLMs. By addressing key challenges such as data quality, timeliness, and scalability, Rust-based pipelines contribute to more accurate, interpretable, and impactful financial applications, paving the way for future innovations in LLM-driven finance. This section highlights the critical role of well-architected data pipelines in unlocking the full potential of LLMs in the financial sector.
15.3. Training LLMs on Financial Data Using Rust
Training large language models (LLMs) on financial data presents unique challenges that require careful handling of data characteristics, precision, and regulatory compliance. Financial data is highly sensitive to market fluctuations and must be processed with high precision to capture subtle patterns that influence decision-making. Additionally, financial datasets often exhibit class imbalance, where certain events (e.g., fraud instances or market crashes) are rare yet critical for training an effective model. Handling this imbalance is crucial, as models trained on unbalanced data risk overfitting to common patterns and underperforming on rare but high-impact cases. Rust’s efficiency, memory safety, and concurrency capabilities make it an ideal choice for developing robust training pipelines that can handle the high volume and precision requirements of financial data, while its expanding ecosystem of machine learning crates provides essential tools for building and training LLMs efficiently.
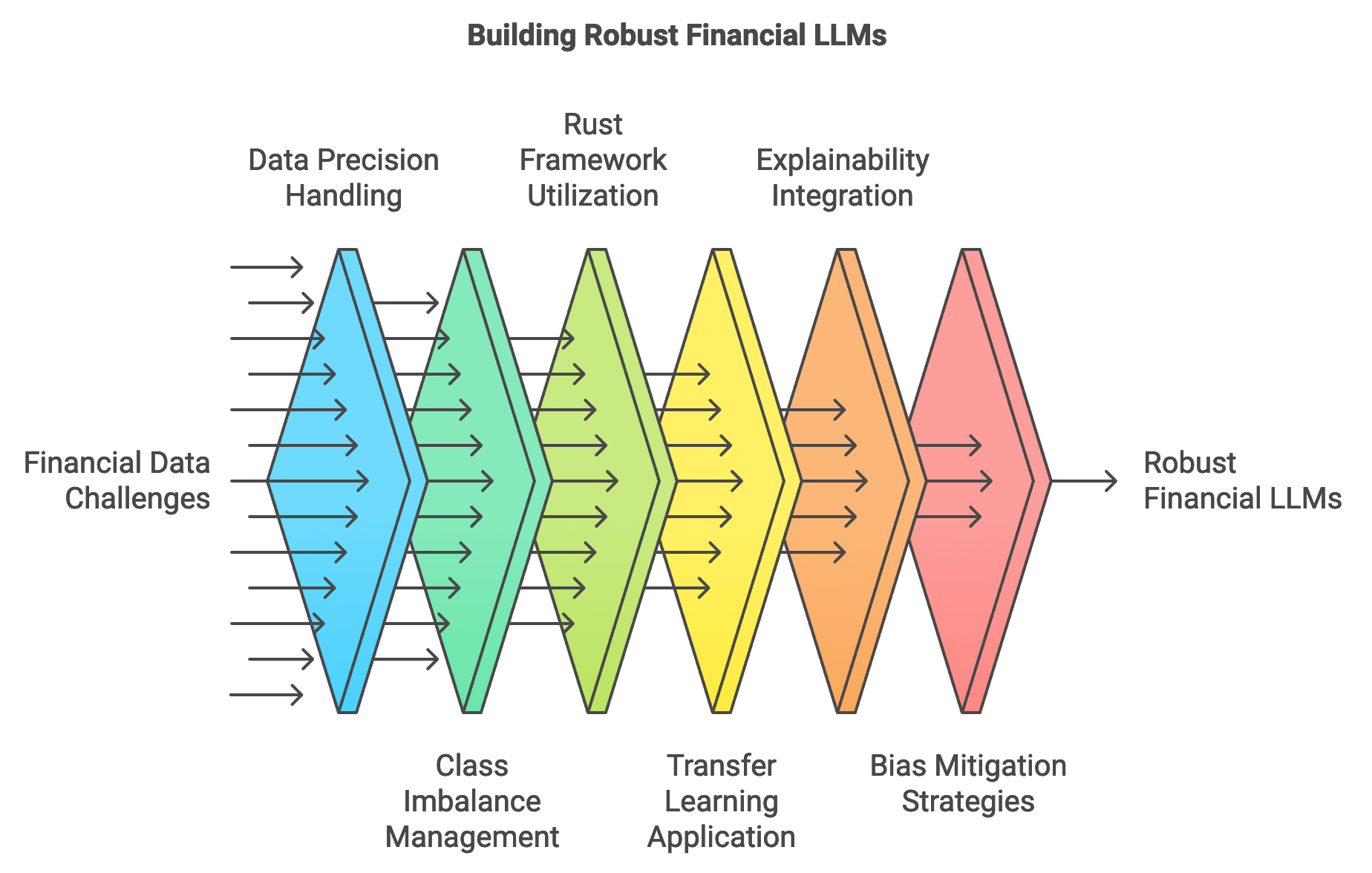
Figure 3: LLM development phases for Finance.
Rust-based frameworks and tools, such as candle and burn, offer high-performance capabilities for training LLMs on large-scale financial datasets. These frameworks are designed to be performant, leveraging Rust’s low-level control to optimize memory and computation, which is especially valuable when training on resource-intensive data. One of the core techniques for building financial LLMs is transfer learning, where a general-purpose model pre-trained on large corpora is fine-tuned on domain-specific data. Transfer learning allows financial applications to leverage the knowledge encoded in general LLMs while adapting the model to specific tasks like risk assessment, fraud detection, or sentiment analysis. Mathematically, let $M$ represent a pre-trained model trained on a general dataset $D_g$. Fine-tuning involves re-training $M$ on a financial dataset $D_f$ with a new objective function $L_f$ designed for the specific financial task. This process produces a model $M_f$ that retains general language understanding while being optimized for the nuances of financial data.
Training LLMs on financial data presents challenges due to the diversity and volatility of data sources. Market data, news articles, regulatory filings, and social media each provide distinct signals, and models must learn to interpret and prioritize these signals effectively. Furthermore, the dynamic nature of financial markets means that models must frequently update or adapt to remain relevant. In high-frequency trading, for example, the model needs to generate predictions in real-time based on the latest data. Training models capable of making reliable real-time predictions requires optimizing the pipeline for both speed and accuracy. Rust’s asynchronous capabilities and memory management features support this requirement, allowing efficient data handling and model updates as new data flows into the pipeline. By reducing latency and ensuring timely model predictions, Rust enables LLMs to perform effectively in the time-sensitive environment of financial markets.
Explainability and interpretability are critical in financial applications, where models often need to comply with strict regulatory requirements and gain stakeholder trust. Regulators and stakeholders must understand the rationale behind model predictions, especially in areas like credit scoring, risk assessment, and algorithmic trading. For example, a model’s decision to classify a transaction as “fraudulent” or “high risk” must be explainable in terms of specific features or patterns within the data. Techniques like Shapley values or layer-wise relevance propagation (LRP) can provide insight into feature importance, representing the contribution of each input $x_i$ to the output prediction $y$ as a relevance score $\phi(x_i)$ for each feature in the prediction function $f(x)$. In Rust, implementing explainability involves integrating these methods into the model pipeline, where the framework calculates and displays feature contributions, ensuring that decisions are transparent and interpretable.
Another critical consideration is bias mitigation, as biased models in finance can perpetuate or exacerbate inequalities in lending, hiring, and investing decisions. Addressing bias during training involves applying strategies such as reweighting or data augmentation to ensure balanced representation across demographic groups or market segments. For example, if a model shows a tendency to deny loans to certain demographic groups, developers can apply reweighting by assigning higher weights wiw_iwi to underrepresented samples, thereby balancing the model’s focus and reducing discriminatory patterns. Additionally, regular audits and fairness assessments are essential in finance, where biased models can have legal and ethical repercussions. Rust’s type-checking and performance characteristics facilitate the integration of bias detection and mitigation methods directly into the training pipeline, allowing developers to monitor and adjust model performance as needed.
The pseudo-code represents an advanced financial data pipeline designed to fine-tune a language model (LLM) specifically for detecting fraudulent transactions. The pipeline includes steps for data preprocessing, model setup, training with fairness constraints, and evaluation. Using transfer learning, the model is adapted from a pre-trained financial language model, enabling efficient fraud detection while ensuring fairness, accuracy, and interpretability.
// Function to preprocess raw financial transaction data
FUNCTION preprocess_data(raw_data: STRING) RETURNS Tensor:
// Step 1: Tokenize text and perform encoding
tokenized_text = TOKENIZE_AND_ENCODE(raw_data)
// Step 2: Convert tokenized text to tensor format with padding and truncation
tensor_data = CONVERT_TO_TENSOR(tokenized_text, SEQUENCE_LENGTH=128)
RETURN tensor_data
// Function to initialize the model with appropriate configuration for financial domain
FUNCTION initialize_model() RETURNS FinancialLLM:
CONFIGURE model_parameters WITH pretrained="FinancialBERT", hidden_layers=12, dropout=0.1
model = LOAD_MODEL(FinancialLLM, model_parameters)
RETURN model
// Function to calculate the fairness constraint for model predictions
FUNCTION fairness_constraint(predictions: LIST, labels: LIST) RETURNS FLOAT:
DEFINE fraud_ratio_threshold AS 0.05
actual_fraud_ratio = CALCULATE_RATIO(labels, label=1)
predicted_fraud_ratio = CALCULATE_RATIO(predictions, label=1)
RETURN ABS(predicted_fraud_ratio - actual_fraud_ratio) < fraud_ratio_threshold
// Training function to fine-tune the model with batched data and backpropagation
FUNCTION train_model(model: FinancialLLM, data: LIST OF Tensor, labels: LIST, epochs: INT) RETURNS FLOAT:
DEFINE batch_size AS 32
DEFINE learning_rate AS 0.0001
optimizer = INITIALIZE_OPTIMIZER(model.parameters, learning_rate)
DEFINE total_loss AS 0
FOR epoch IN RANGE(epochs):
// Shuffle data at the beginning of each epoch for improved generalization
SHUFFLE_DATA(data, labels)
FOR batch IN CREATE_BATCHES(data, labels, batch_size):
// Forward pass
predictions = model.forward(batch.inputs)
// Compute loss (e.g., cross-entropy for classification)
loss = CALCULATE_CROSS_ENTROPY(predictions, batch.labels)
// Apply fairness constraint during loss calculation
IF NOT fairness_constraint(predictions, batch.labels):
loss = INCREASE_LOSS_PENALTY(loss, amount=0.2)
// Backward pass and optimization
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss.value
PRINT("Epoch", epoch, "Loss:", total_loss / (epoch + 1))
RETURN total_loss / epochs
// Function to evaluate model performance on validation data
FUNCTION evaluate_model(model: FinancialLLM, validation_data: LIST OF Tensor, validation_labels: LIST) RETURNS DICT:
predictions = []
FOR input IN validation_data:
prediction = model.forward(input)
APPEND prediction TO predictions
// Calculate metrics such as accuracy, precision, recall, and F1 score
metrics = CALCULATE_METRICS(predictions, validation_labels)
RETURN metrics
// Main function to set up data, model, and initiate training
FUNCTION main():
// Load and preprocess training and validation datasets
raw_training_data = LOAD_DATASET("training_data.csv")
raw_validation_data = LOAD_DATASET("validation_data.csv")
training_data = []
training_labels = []
FOR record IN raw_training_data:
APPEND preprocess_data(record.text) TO training_data
APPEND record.label TO training_labels
validation_data = []
validation_labels = []
FOR record IN raw_validation_data:
APPEND preprocess_data(record.text) TO validation_data
APPEND record.label TO validation_labels
// Initialize model for fine-tuning
model = initialize_model()
// Train the model with fine-tuning process
epochs = 10
avg_loss = train_model(model, training_data, training_labels, epochs)
// Evaluate model performance on validation data
evaluation_metrics = evaluate_model(model, validation_data, validation_labels)
PRINT("Training completed with average loss:", avg_loss)
PRINT("Evaluation Metrics:", evaluation_metrics)
The pipeline begins by loading and preprocessing raw transaction data, converting it into a standardized tensor format. It then initializes a pre-trained financial language model and fine-tunes it using a training loop that includes fairness constraints, ensuring that predictions meet defined fraud ratio thresholds. During each epoch, the model processes data in batches, calculates the loss, applies backpropagation, and optimizes model parameters to reduce bias in fraud predictions. Once training completes, the model’s effectiveness is evaluated on validation data using key metrics such as accuracy, precision, and recall, providing insights into its fraud detection performance and readiness for deployment.
In real-world applications, financial institutions have leveraged LLMs trained on specific financial datasets to perform tasks such as credit risk assessment and portfolio management. For instance, a bank deployed a fine-tuned LLM to analyze borrower profiles, historical loan data, and economic indicators, enabling more accurate predictions of default risk. This model was trained using transfer learning, where a general-purpose LLM was fine-tuned on the bank’s proprietary dataset, improving accuracy without requiring extensive computational resources. Rust’s efficiency and scalability were essential in building the training pipeline, allowing the model to be continuously updated with new loan data as it became available.
The latest trends in LLM training for finance include the use of reinforcement learning to adapt trading algorithms and the integration of multi-modal data to enhance predictions. Reinforcement learning techniques, where the model continuously optimizes based on feedback from the market environment, enable trading models to adapt dynamically to market conditions. For instance, a reinforcement learning-based LLM can adjust its trading strategy in real-time as it learns from reward signals. In addition, multi-modal training, where text data is combined with numerical, graphical, or geospatial data, offers a more holistic approach to financial decision-making. Rust’s capabilities for concurrent data processing and real-time inference make it well-suited for these complex, multi-modal applications, supporting diverse data sources and continuous learning.
In summary, training LLMs on financial data using Rust offers a powerful combination of efficiency, scalability, and precision. By addressing the specific requirements of financial applications—such as high precision, bias mitigation, and regulatory compliance—Rust-based pipelines enable the development of reliable, interpretable, and high-performance LLMs. Through transfer learning, Rust frameworks provide a cost-effective means of adapting general-purpose models to specialized financial tasks, helping financial institutions leverage the full potential of LLMs. This section demonstrates how Rust’s unique strengths are applied in the financial sector, where accurate, explainable, and fast LLMs have the potential to transform risk management, fraud detection, and algorithmic trading.
15.4. Inference and Deployment of Financial LLMs Using Rust
Inference and deployment of large language models (LLMs) in the financial sector require a strategic approach that balances performance, regulatory compliance, and real-time responsiveness. Financial applications, especially those involving high-frequency trading and risk management, demand rapid and accurate inferences. Latency is particularly critical in algorithmic trading, where decisions must be executed within milliseconds to capitalize on market opportunities. In such applications, the inference pipeline is designed to process live market data and execute trades based on LLM predictions. Rust, known for its speed, memory safety, and concurrency support, is well-suited for developing high-performance inference pipelines that operate reliably under the rigorous demands of financial markets. The use of Rust in this context ensures low-latency predictions, efficient memory handling, and robust error-checking, all essential for maintaining a secure and efficient trading environment.
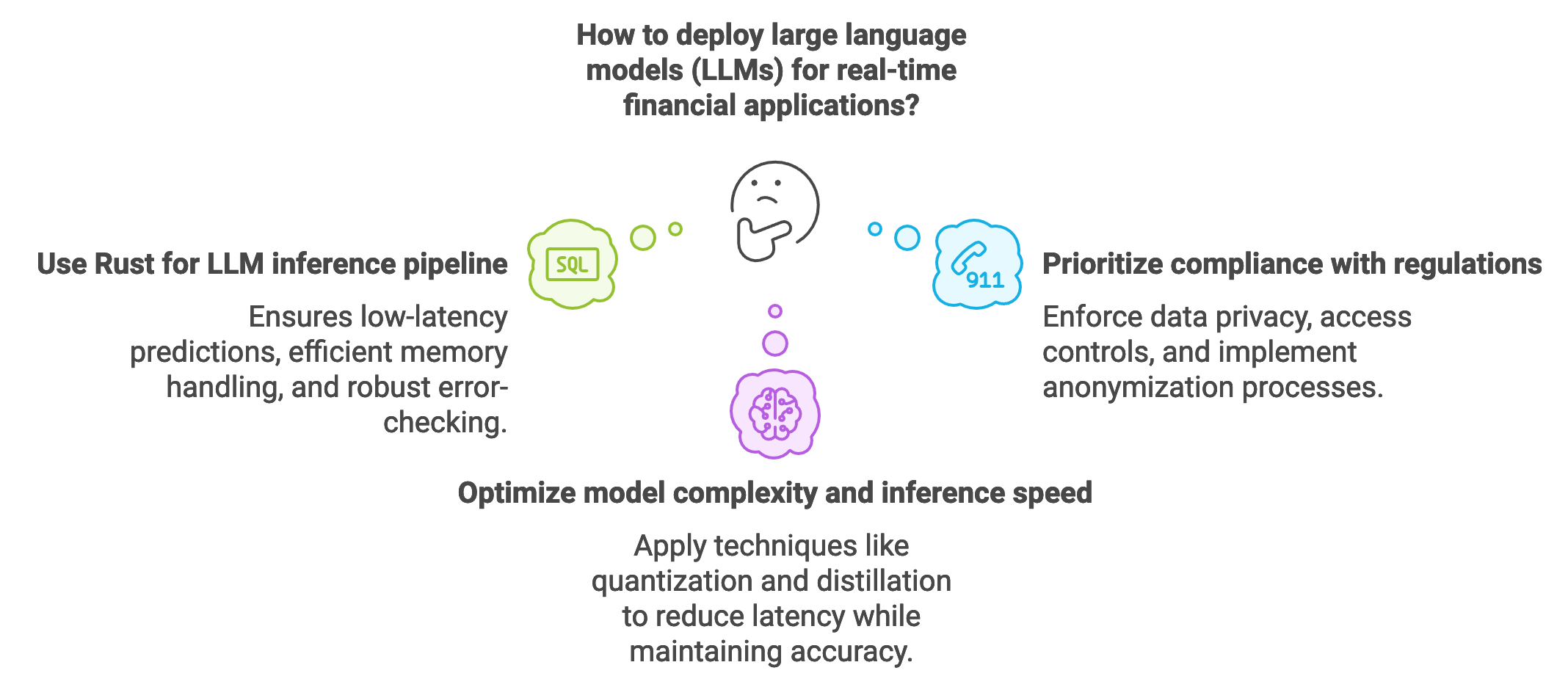
Figure 4: LLM deployment in Finance.
Deploying financial LLMs at scale introduces challenges that extend beyond technical considerations, including compliance with financial regulations such as those enforced by the SEC (Securities and Exchange Commission) and GDPR (General Data Protection Regulation). In high-stakes financial applications, ensuring data privacy and securing sensitive financial information are paramount. For example, GDPR mandates stringent data protection measures for European clients, necessitating data anonymization and restricted access to personal information. Model deployment strategies must incorporate these compliance requirements by enforcing access controls, logging data access, and implementing anonymization processes in the inference pipeline. Moreover, regulatory standards in finance demand auditability and transparency, meaning that any automated decisions made by LLMs—such as investment recommendations or risk assessments—must be explainable and subject to review. Rust’s secure memory management and support for concurrent processing facilitate building systems that adhere to these standards, providing a stable and compliant foundation for financial LLM deployments.
One of the core challenges in deploying LLMs for financial inference is achieving a balance between model complexity and inference speed. High-frequency trading applications, for instance, require models that can interpret vast streams of data nearly instantaneously, as even minor delays can lead to significant financial losses. This necessitates lightweight models with optimized architectures that reduce latency while maintaining predictive accuracy. In mathematical terms, let $f(x)$ represent the model function that maps input $x$ (market data) to an output $y$ (trading action). The latency $L(f)$ is a function of the model’s complexity $C(f)$, with a trade-off between $C(f)$ and $L(f)$. Techniques like quantization and distillation are often applied to reduce $C(f)$, resulting in a simplified version of the model without compromising essential predictive capabilities. By reducing the precision of model weights or distilling a large “teacher” model into a smaller “student” model, these techniques help achieve the necessary inference speeds for real-time financial applications. Rust’s performance optimizations make it ideal for implementing these model compression strategies, enabling developers to deploy smaller, faster models that can keep pace with financial markets.
The following pseudo-code presents a sophisticated real-time inference pipeline for a financial large language model (LLM) aimed at generating actionable trading signals. This advanced pipeline ingests real-time market data, preprocesses it, and uses a fine-tuned LLM to analyze the data and recommend actions like "Buy," "Hold," or "Sell," each with a confidence level. The pipeline includes features like batch inference, concurrency management, and latency monitoring to ensure high-speed, reliable performance in a financial setting where quick responses are essential.
// Define structure for market data input
STRUCTURE MarketData:
price: FLOAT
volume: FLOAT
volatility: FLOAT
sentiment_score: FLOAT // Sentiment score from market news or social media
// Function to preprocess market data into a tensor format suitable for model input
FUNCTION preprocess_data(data: MarketData) RETURNS Tensor:
normalized_data = NORMALIZE([data.price, data.volume, data.volatility, data.sentiment_score])
RETURN CONVERT_TO_TENSOR(normalized_data, shape=(1, 4))
// Asynchronous function to perform inference with a financial LLM model
ASYNC FUNCTION infer(model: SHARED_RESOURCE(FinancialLLM), data: MarketData) RETURNS STRING:
START_TIMER()
// Acquire model resource for inference
ACQUIRE_LOCK(model)
tensor_input = preprocess_data(data)
// Perform inference
output_tensor = model.forward(tensor_input)
RELEASE_LOCK(model)
// Convert model output to trading signal (e.g., Buy, Hold, Sell) with confidence score
trading_signal = interpret_output(output_tensor)
LOG("Inference latency:", STOP_TIMER())
RETURN trading_signal
// Function to interpret model output and generate trading signal with confidence level
FUNCTION interpret_output(output: Tensor) RETURNS STRING:
confidence_threshold = 0.7
IF output[0] > confidence_threshold:
RETURN "Buy (High Confidence)"
ELSE IF output[0] > 0.5:
RETURN "Hold (Moderate Confidence)"
ELSE:
RETURN "Sell (High Confidence)"
// Function to handle multiple inference requests in parallel
ASYNC FUNCTION batch_infer(model: SHARED_RESOURCE(FinancialLLM), data_batch: LIST OF MarketData) RETURNS LIST OF STRING:
DEFINE predictions AS EMPTY_LIST
FOR data IN data_batch:
prediction = await infer(model, data)
APPEND prediction TO predictions
RETURN predictions
// Function to monitor pipeline health and alert on errors or delays
FUNCTION monitor_inference_latency(latency: TIME):
IF latency > THRESHOLD:
SEND_ALERT("Inference latency exceeded threshold!")
ELSE:
LOG("Inference latency within acceptable limits")
// Main function to initialize the model and start the real-time inference pipeline
ASYNC FUNCTION main():
// Initialize model configuration and load LLM
model_config = {"pretrained": "FinancialBERT", "device": "CPU"}
model = INITIALIZE_SHARED_RESOURCE(FinancialLLM, model_config)
// Start receiving market data in real-time
WHILE market_open:
market_data = RECEIVE_REAL_TIME_MARKET_DATA()
// Process incoming data in batches
data_batch = COLLECT_MARKET_DATA_BATCH(market_data, batch_size=10)
// Perform batch inference
predictions = await batch_infer(model, data_batch)
// Display predictions and monitor latency
DISPLAY(predictions)
monitor_inference_latency(latency=CALCULATE_AVERAGE_LATENCY(predictions))
The pipeline begins by receiving real-time market data, which it preprocesses to extract relevant metrics (e.g., price, volume, volatility, and sentiment scores) and formats these into tensors suitable for model input. For each batch of data, the pipeline performs asynchronous inference using the LLM, where the model’s output is interpreted as a trading recommendation with a confidence level based on predefined thresholds. It then monitors the latency of each inference operation and triggers alerts if processing time exceeds acceptable limits, ensuring that the pipeline meets real-time requirements. This setup enables the system to efficiently process high volumes of market data and generate timely trading recommendations for financial applications.
Once deployed, financial LLMs must be monitored and maintained to prevent model drift—a common challenge where a model’s performance degrades over time due to changes in the underlying data distribution. In financial markets, evolving trends, regulatory changes, and economic shifts can all impact model relevance. Monitoring strategies involve evaluating the distribution $D_t$ of input data over time $t$ and comparing it to the initial distribution $D_0$ on which the model was trained. When $D_t$ diverges significantly from $D_0$, retraining or fine-tuning is required to realign the model with current data. Mathematically, this divergence can be measured using a metric like Kullback-Leibler (KL) divergence $\text{KL}(D_t \| D_0)$. Implementing this in Rust can be achieved by periodically sampling incoming data, calculating divergence metrics, and initiating retraining workflows if thresholds are exceeded.
Real-world applications demonstrate how financial institutions utilize LLMs for automated trading and fraud detection, where regulatory compliance and explainability are paramount. A recent deployment involved a large bank using an LLM for real-time risk assessment in high-frequency trading. The LLM analyzed transaction data to identify potential risks and flagged high-risk transactions for human review. The deployment pipeline was configured to meet SEC regulations by logging all model inferences, enabling auditability and transparency. Rust’s error-handling and memory safety were instrumental in creating a stable and compliant system that could handle high-throughput trading data while preventing data leaks and breaches.
Current trends in financial LLM deployment include the use of hybrid cloud and edge deployments to support latency-sensitive applications. By deploying models on edge servers close to trading floors, firms minimize latency, ensuring that predictions reach decision-makers faster. Rust’s performance efficiency makes it ideal for edge environments, where resource constraints demand highly optimized software. Additionally, financial firms are exploring the integration of Rust-based monitoring systems that automatically track model accuracy and detect anomalies, triggering model updates or retraining when necessary. These monitoring systems not only enhance performance but also ensure compliance by documenting model behavior over time, an increasingly important requirement as regulators mandate greater transparency in AI-driven financial applications.
In conclusion, deploying financial LLMs using Rust offers significant advantages in terms of speed, security, and regulatory compliance. By building efficient inference pipelines, optimizing model architectures, and implementing comprehensive monitoring systems, Rust enables financial institutions to leverage LLMs in time-sensitive and high-stakes applications. From algorithmic trading to real-time risk assessment, Rust provides a solid foundation for deploying reliable, compliant, and high-performance LLMs in finance. This section emphasizes the critical role of Rust in creating inference and deployment systems that meet the rigorous demands of the financial industry, supporting a new era of AI-driven financial decision-making.
15.5. Ethical and Regulatory Considerations in Financial LLMs
The deployment of large language models (LLMs) in finance introduces a host of ethical and regulatory challenges that must be addressed to ensure fairness, transparency, and accountability. Financial LLMs, which can perform tasks ranging from sentiment analysis to automated trading, have far-reaching implications for market behavior and investor outcomes. However, these models may also amplify biases present in historical data or operate in ways that lack transparency, creating ethical dilemmas in high-stakes financial environments. Bias in financial LLMs, if left unchecked, can result in inequitable outcomes, such as skewed credit scoring or discriminatory lending practices. Moreover, models that operate as “black boxes” raise concerns for transparency and accountability, particularly when model outputs influence major investment decisions. Rust, with its emphasis on type safety and reliability, provides a robust foundation for implementing ethical AI practices, including bias mitigation, explainability, and compliance with regulatory standards, supporting the responsible deployment of LLMs in finance.
Figure 5: Ethical and regulatory consideration of LLM in Finance.
In the financial industry, AI applications are governed by strict regulations from bodies such as the Securities and Exchange Commission (SEC) in the United States, the European Union’s Markets in Financial Instruments Directive II (MiFID II), and the General Data Protection Regulation (GDPR). These frameworks impose specific requirements on data protection, transparency, and fairness. For instance, GDPR mandates data privacy and restricts the processing of personally identifiable information (PII), impacting how financial institutions can store and process customer data within LLM workflows. MiFID II emphasizes transparency and investor protection, requiring that financial models used in advisory or trading activities demonstrate compliance and avoid conflicts of interest. Rust’s ecosystem of tools for secure data handling, such as serde for serialization and deserialization, combined with its ability to enforce memory safety, supports compliance with these regulations by providing secure and auditable data management practices. Ensuring adherence to these regulatory requirements throughout the model’s lifecycle—from training and inference to deployment—is essential for any financial application.
One of the primary ethical challenges in deploying financial LLMs is the risk of bias, particularly in applications involving credit scoring, lending, or asset management. If an LLM is trained on historical financial data containing biases, it may perpetuate or even amplify these biases, leading to unfair outcomes. To counteract this, developers can implement bias mitigation strategies, such as reweighting or debiasing techniques. Mathematically, debiasing can be represented by assigning a weight wiw_iwi to each data instance $x_i$, where weights are adjusted inversely to the frequency of each class or group within the dataset. This reweighting reduces the model’s tendency to overfit on majority groups, promoting fairness across demographic segments. Rust’s rigorous error handling and type-checking enable developers to implement these techniques accurately, reducing the likelihood of mistakes that could inadvertently introduce new biases.
Transparency is crucial in financial AI applications, where decisions influenced by LLMs impact investor confidence and market fairness. Explainability techniques, such as feature importance scores, enable financial institutions to interpret the factors contributing to a model’s output. For example, Shapley values, a popular method for model interpretability, assign a relevance score $\phi(x_i)$ to each input feature $x_i$ by computing its marginal contribution to the output in all possible feature combinations. This ensures that decisions made by the LLM can be explained in terms of specific, quantifiable factors, aiding compliance with transparency requirements from regulatory bodies like the SEC. Implementing these explainability methods in Rust involves calculating relevance scores for model inputs, which can then be documented for audit purposes. By making model outputs interpretable, financial institutions can provide regulators and investors with confidence in the model’s decision-making process, fostering a more transparent financial environment.
Ensuring compliance with financial regulations involves developing a comprehensive checklist that covers data privacy, model transparency, and bias monitoring. For instance, models deployed in the EU must comply with GDPR, which mandates data minimization, data anonymization, and user consent for data processing.
The pseudo-code below outlines a compliance-focused data processing pipeline for a financial application, ensuring data privacy, model transparency, and fairness in machine learning inference. Designed for regulatory environments, this pipeline applies anonymization, data minimization, logging, and bias monitoring to secure compliance with requirements such as GDPR. By anonymizing sensitive data, minimizing unnecessary information, and tracking model inferences and biases, the pipeline enables financial institutions to deploy machine learning models responsibly.
// Define structure for financial transaction records
STRUCTURE TransactionRecord:
account_id: STRING
transaction_details: STRING
transaction_amount: FLOAT
transaction_date: DATE
// Function to anonymize sensitive data fields to ensure data privacy
FUNCTION anonymize_data(record: TransactionRecord) RETURNS TransactionRecord:
DEFINE id_pattern AS REGEX("\d{8}") // Matches 8-digit account IDs
anonymized_id = REPLACE_PATTERN(record.account_id, id_pattern, "[REDACTED_ID]")
anonymized_details = MASK_SENSITIVE_TERMS(record.transaction_details)
RETURN TransactionRecord(
account_id = anonymized_id,
transaction_details = anonymized_details,
transaction_amount = record.transaction_amount,
transaction_date = record.transaction_date
)
// Function to ensure data minimization by removing unnecessary fields before processing
FUNCTION minimize_data(record: TransactionRecord) RETURNS TransactionRecord:
minimized_record = COPY(record)
REMOVE_FIELD(minimized_record, "account_id") // Remove field if not required for analysis
RETURN minimized_record
// Function to log model inference details for transparency and auditing
FUNCTION log_inference_details(record: TransactionRecord, inference_result: STRING):
audit_log = {
"record_id": HASH(record.transaction_details),
"inference_result": inference_result,
"timestamp": CURRENT_TIMESTAMP(),
"model_version": "v2.3"
}
STORE_IN_LOG(audit_log)
// Function to monitor model bias across different demographic groups for fairness
FUNCTION monitor_bias(model_predictions: LIST, demographic_data: LIST) RETURNS BIAS_REPORT:
DEFINE bias_threshold AS 0.05
FOR group IN demographic_data:
group_predictions = FILTER_PREDICTIONS(model_predictions, group)
group_bias_score = CALCULATE_BIAS_SCORE(group_predictions)
IF group_bias_score > bias_threshold:
ADD_TO_REPORT("Bias detected in", group)
RETURN bias_report
// Main function to process transaction data in compliance with data privacy and regulatory requirements
FUNCTION main():
transaction_data = LOAD_TRANSACTION_DATA("transactions.csv")
processed_data = []
FOR record IN transaction_data:
// Anonymize and minimize data before passing to model
anonymized_record = anonymize_data(record)
minimized_record = minimize_data(anonymized_record)
// Perform inference and log for transparency
inference_result = MODEL_INFERENCE(minimized_record)
log_inference_details(minimized_record, inference_result)
// Append processed record to data list
APPEND(inference_result TO processed_data)
// Monitor model bias to ensure fairness
demographic_data = LOAD_DEMOGRAPHIC_DATA("demographics.csv")
bias_report = monitor_bias(processed_data, demographic_data)
PRINT(bias_report)
The pipeline begins by loading transaction data and applying data privacy steps: sensitive data is anonymized, and only essential fields are retained, reducing exposure to unnecessary information. Each record is then processed by a machine learning model for inference, with the result and model details logged for transparency and traceability. The system monitors bias across demographic groups to ensure fairness, flagging any bias that exceeds acceptable thresholds. This setup enables a compliant and ethical data pipeline that meets stringent financial regulatory standards, supporting accurate and responsible model usage.
In practice, financial firms deploying LLMs must continuously monitor model outputs for fairness and regulatory compliance. Model drift, where model performance changes over time due to shifts in data distribution, can lead to biases re-emerging in a deployed model. Monitoring drift involves comparing the distribution of current data $D_t$ to the initial distribution $D_0$ at the time of training. Metrics such as Kullback-Leibler (KL) divergence $\text{KL}(D_t \| D_0)$ quantify these shifts, indicating when retraining or fine-tuning is required to restore compliance and fairness. Rust’s efficient handling of statistical calculations enables the integration of such drift monitoring systems directly into deployment pipelines, ensuring that models remain accurate, fair, and compliant over time.
Industry use cases of ethical LLM deployment in finance highlight the need for transparency and compliance. For instance, a global asset management firm recently deployed an LLM for customer portfolio management, which automatically suggested investment adjustments based on market trends. To comply with MiFID II, the firm implemented transparency measures that allowed clients and regulators to view the factors influencing each investment decision. Additionally, regular audits were conducted to ensure the model adhered to fairness guidelines, preventing bias in asset allocation. Rust’s robustness and safety features enabled the firm to create a reliable, secure inference pipeline, ensuring compliance while maintaining high performance in real-time portfolio management.
Recent trends in financial AI highlight an increased focus on responsible AI practices. Financial institutions are exploring the use of hybrid explainability methods, combining local and global interpretability techniques to provide a comprehensive view of model behavior. Additionally, there is a shift towards integrating explainability directly into the model training process, allowing developers to monitor feature importance and relevance scores as the model learns. By embedding transparency in every stage of model development, institutions aim to build AI systems that comply with regulatory standards and gain the trust of clients and regulators. Rust’s performance and memory safety make it an ideal language for developing these advanced explainability techniques, allowing developers to build models that are both interpretable and secure.
In conclusion, ethical and regulatory considerations are paramount in deploying LLMs for financial applications, where model outputs have significant implications for investor confidence and market stability. By addressing bias, enhancing transparency, and ensuring regulatory compliance, Rust-based financial LLMs offer a path to responsible AI deployment. With Rust’s capabilities for secure data handling, high-performance computing, and robust error-checking, developers can build LLM systems that meet the stringent ethical and regulatory demands of the financial industry. This section underscores the importance of ethical practices in financial LLMs, highlighting how Rust provides a reliable foundation for creating transparent, compliant, and fair AI applications in finance.
15.6. Case Studies and Future Directions
As the adoption of large language models (LLMs) in finance accelerates, real-world case studies illustrate both the promise and complexity of applying AI-driven insights in areas like trading, risk assessment, and financial advisory services. These case studies provide valuable insights into how financial institutions are leveraging LLMs to enhance scalability, improve accuracy, and meet regulatory demands. For instance, a major global investment bank implemented an LLM for portfolio management, where the model analyzed market reports, financial news, and earnings calls to provide investment recommendations. This deployment faced challenges, particularly with model drift due to evolving market conditions, but continuous model monitoring and periodic retraining helped maintain relevance and performance. The case study highlighted the importance of robust monitoring systems, a lesson crucial for future financial LLM projects where model performance and regulatory compliance must be maintained over time.
Figure 6: Applications of LLMs in Finance.
Emerging trends in finance suggest that LLMs will play an increasingly transformative role in areas such as decentralized finance (DeFi), predictive analytics, and AI-driven advisory services. DeFi, which aims to create financial services outside traditional banking infrastructure, offers unique opportunities for LLMs to analyze decentralized transaction patterns, provide fraud detection, and assess risk in decentralized lending markets. Predictive analytics, already a staple in algorithmic trading, can benefit significantly from LLMs that process diverse data sources—including social media sentiment and macroeconomic indicators—to identify emerging trends. AI-driven financial advisory services are also gaining traction, where LLMs provide personalized advice to retail investors by understanding their financial goals, risk tolerance, and market conditions. In these applications, LLMs can adaptively refine investment strategies or flag portfolio adjustments in real time, using predictive insights derived from large datasets. Rust’s performance capabilities, especially in handling high-throughput data, are invaluable here, allowing these applications to scale and respond quickly to new information.
One of the most important lessons from existing LLM deployments in finance is the need for scalability and efficient resource use. Financial institutions operate in environments with high data volumes and low tolerance for latency, especially in trading applications. Scalability in LLMs involves both computational scaling—where models handle large datasets—and adaptability to changing market conditions, which often requires real-time updates. Rust’s memory safety and concurrency support facilitate building scalable systems that avoid common pitfalls, such as memory leaks or concurrency errors, making it ideal for financial applications with heavy data loads. Another key lesson is the necessity of ensuring model interpretability and transparency, as regulatory agencies demand explanations for AI-driven decisions. This is particularly relevant in credit scoring and loan approvals, where institutions must comply with laws that protect against algorithmic discrimination. By implementing explainability tools in Rust, financial institutions can provide regulators with insights into model behavior, fostering trust and reducing regulatory risk.
Looking to the future, LLMs present numerous opportunities for innovation in financial markets. One promising area is the development of advanced investment strategies, where LLMs analyze not only historical market data but also alternative data sources, such as climate impact reports and geopolitical news, to adjust investment portfolios in a more holistic manner. For example, LLMs could be designed to prioritize environmentally sustainable investments by integrating environmental, social, and governance (ESG) data. This application can be represented by a function $f(x) \rightarrow y$, where $x$ includes traditional financial metrics and non-traditional ESG data, and $y$ is the investment recommendation. Similarly, LLMs could support risk management by analyzing risk signals in real-time and providing early warnings for potential market downturns. However, achieving these capabilities requires overcoming several challenges, including data availability, model interpretability, and complex regulatory landscapes. The need for high-quality, diverse financial data remains a key obstacle, as access to reliable and timely information is essential for training LLMs that can generalize well across different market conditions.
The pseudo-code below represents an example of sentiment analysis tool designed to support financial market predictions by interpreting news headlines in real-time and providing trading recommendations. This system is built to evaluate the sentiment of incoming financial news, generating “Buy,” “Hold,” or “Sell” signals, and includes features such as data caching for efficiency, model performance monitoring, and scheduled parameter adjustments to maintain high accuracy. The tool's design makes it suitable for automated trading environments where rapid and informed decision-making is critical.
// Define structure for incoming headline input
STRUCTURE HeadlineInput:
headline: STRING
// Define shared state for managing the model resource and application state
STRUCTURE AppState:
model: SHARED_RESOURCE(FinancialSentimentModel)
cache: SHARED_RESOURCE(Cache) // Optional cache for recently analyzed headlines
// Function to tokenize and preprocess the headline text for model input
FUNCTION preprocess_headline(headline: STRING) RETURNS TokenizedData:
cleaned_headline = CLEAN_TEXT(headline)
tokens = TOKENIZE(cleaned_headline)
RETURN tokens
// Function to perform inference and generate a sentiment-based recommendation
FUNCTION predict_sentiment(headline: HeadlineInput, state: AppState) RETURNS STRING:
IF state.cache.contains(headline.headline):
RETURN state.cache.get(headline.headline) // Use cached result if available
ACQUIRE_LOCK(state.model)
tokenized_headline = preprocess_headline(headline.headline)
// Perform inference to get sentiment score
sentiment_score = state.model.infer(tokenized_headline)
RELEASE_LOCK(state.model)
// Interpret sentiment score to generate recommendation
IF sentiment_score > 0.7:
recommendation = "Buy"
ELSE IF sentiment_score < -0.7:
recommendation = "Sell"
ELSE:
recommendation = "Hold"
// Store result in cache for efficiency
state.cache.store(headline.headline, recommendation)
RETURN recommendation
// Function to monitor model performance and update parameters for accuracy
FUNCTION monitor_and_adjust_model(state: AppState):
DEFINE performance_metrics AS GET_MODEL_METRICS(state.model)
IF performance_metrics["accuracy"] < 0.85:
ADJUST_MODEL_PARAMETERS(state.model, learning_rate=0.001, regularization=0.0001)
// Main function to initialize and start the API server for real-time inference
FUNCTION main():
model_config = {"pretrained": "FinancialSentimentBERT", "device": "CPU"}
model = INITIALIZE_SHARED_RESOURCE(FinancialSentimentModel, model_config)
cache = INITIALIZE_SHARED_RESOURCE(Cache)
state = AppState(model=model, cache=cache)
START_API_SERVER(state, endpoint="/predict", handler=predict_sentiment)
// Periodically monitor model performance and adjust as needed
SCHEDULE_TASK(monitor_and_adjust_model, interval="daily", args=[state])
The system operates by receiving a headline input, checking for a cached sentiment result, and, if unavailable, pre-processing and tokenizing the headline text to prepare it for model inference. The financial sentiment model then analyzes the tokenized headline, generating a sentiment score that is converted into a trading recommendation based on predefined thresholds. The result is stored in the cache for future reference, improving processing efficiency for similar inputs. In addition, a background task periodically monitors model performance, adjusting parameters as necessary to ensure accuracy and responsiveness in a live trading setting. This setup allows the tool to deliver reliable, actionable insights in real time, supporting robust financial decision-making.
Looking ahead, financial institutions are likely to explore new applications for LLMs, such as automated compliance monitoring and AI-driven customer support. In compliance monitoring, LLMs could automatically scan financial records, emails, and transaction logs to detect potential regulatory violations, such as insider trading or market manipulation, while notifying compliance officers of suspicious activity. This application could be represented as a classification function $f(x) \rightarrow \{0, 1\}$, where $x$ is a transaction record and the output $\{0, 1\}$ indicates compliance or non-compliance. For AI-driven customer support, LLMs could handle complex client queries, provide financial advice, or assist with account management. Rust’s type safety, secure memory management, and low-latency processing capabilities make it particularly suitable for these real-time, high-stakes applications, where performance and security are essential.
In conclusion, case studies demonstrate that LLMs are already impacting finance by enhancing scalability, improving accuracy, and enabling new services. The future of LLMs in finance is promising, with emerging applications in decentralized finance, predictive analytics, and advanced compliance monitoring. However, realizing the full potential of financial LLMs will require addressing challenges in data availability, model interpretability, and compliance with complex regulatory standards. By leveraging Rust’s strengths in performance, safety, and concurrency, developers can build scalable, secure, and transparent financial applications that meet the demands of modern financial markets. This section underscores the transformative power of LLMs in finance, offering a path forward for the responsible and innovative use of AI in the financial sector.
15.7. Conclusion
Chapter 15 provides readers with a deep understanding of how to develop and deploy large language models in the financial sector using Rust. By mastering these techniques, readers can create powerful financial applications that are not only innovative but also compliant with regulatory standards, ensuring both effectiveness and ethical responsibility in AI-driven finance.
15.7.1. Further Learning with GenAI
Each prompt is crafted to encourage deep engagement with the material, helping readers to understand the complexities and technical challenges involved in developing financial applications with LLMs.
Explain the role of large language models (LLMs) in the financial sector. How do LLMs enhance applications such as fraud detection, sentiment analysis, algorithmic trading, and risk management?
Describe the key challenges of applying LLMs in finance, particularly in handling vast amounts of unstructured data and ensuring compliance with regulatory requirements. How can Rust be leveraged to address these challenges?
Discuss the importance of real-time data processing and decision-making in financial applications. How can Rust’s concurrency and performance features be utilized to build efficient real-time systems?
Analyze the impact of LLMs on financial markets. What are the potential benefits and risks of using LLMs for predictive modeling and risk assessment?
Explore the ethical considerations of deploying LLMs in finance, particularly regarding bias, fairness, and algorithmic decision-making. How can Rust-based systems be designed to detect and mitigate these ethical issues?
Explain the process of building a robust financial data pipeline using Rust. What are the essential steps for ensuring data integrity, consistency, and reliability when handling large volumes of financial data?
Discuss the challenges of working with diverse and volatile financial data sources. How can Rust-based tools be used to preprocess, normalize, and extract meaningful features from financial data?
Explore the role of data augmentation and synthetic data generation in enhancing LLM training for financial applications. How can Rust be used to implement these techniques effectively?
Analyze the specific considerations for training LLMs on financial data, including handling imbalanced datasets and ensuring high precision. How can Rust be used to implement a robust training pipeline?
Discuss the importance of transfer learning and fine-tuning pre-trained models for financial-specific tasks. What are the key challenges and benefits of adapting general-purpose LLMs to finance?
Explore the role of explainability and interpretability in financial LLMs. How can Rust-based models be designed to ensure that their outputs are understandable and actionable for financial professionals?
Explain the challenges of deploying LLMs in financial environments, particularly in terms of latency, accuracy, and scalability. How can Rust be used to build and deploy efficient inference pipelines for financial LLMs?
Discuss the regulatory requirements for deploying AI in finance, such as SEC, MiFID II, and GDPR. How can developers ensure that their Rust-based LLM applications comply with these regulations?
Analyze the trade-offs between model complexity and inference speed in high-frequency trading and real-time risk assessment scenarios. How can Rust-based models be optimized to balance these factors effectively?
Explore the importance of real-time inference capabilities in critical financial applications, such as algorithmic trading. How can Rust be used to optimize inference pipelines for speed and accuracy in these scenarios?
Discuss the potential risks of deploying biased or opaque LLMs in finance. How can Rust-based systems be designed to detect and mitigate these risks, ensuring fairness and transparency?
Analyze the role of continuous monitoring and maintenance in ensuring the long-term reliability of deployed financial LLMs. How can Rust-based systems be set up to track performance and implement updates?
Explore the challenges of integrating LLMs into existing financial IT infrastructure. How can Rust-based models be deployed in a way that ensures compatibility and minimal disruption?
Discuss the future potential of LLMs in finance, including emerging trends like decentralized finance (DeFi) and AI-driven financial advisory services. How can Rust be leveraged to innovate in these areas?
Explain the key lessons learned from existing case studies of LLM deployments in finance. What best practices can be derived from these experiences, and how can they inform the development of future Rust-based financial applications?
Embrace these challenges with determination and curiosity, knowing that the knowledge and skills you gain will position you at the forefront of AI innovation in the financial industry.
15.7.2. Hands On Practices
Self-Exercise 15.1: Building a Financial Data Pipeline Using Rust
Objective: To design and implement a robust data pipeline for financial applications using Rust, focusing on preprocessing, normalization, and feature extraction from diverse financial data sources.
Tasks:
Set up a Rust-based data pipeline to ingest, preprocess, and normalize financial data from multiple sources, ensuring data integrity and consistency.
Implement feature extraction techniques to convert unstructured financial data (e.g., news articles, social media posts) into structured inputs suitable for training a large language model.
Test the pipeline with a diverse dataset, identifying and addressing challenges related to data quality, timeliness, and feature relevance.
Experiment with different preprocessing methods to optimize the pipeline for robustness and accuracy in downstream tasks.
Deliverables:
A Rust codebase for a financial data pipeline that includes preprocessing, normalization, and feature extraction components.
A detailed report on the implementation process, including challenges encountered and solutions applied.
A performance evaluation of the pipeline, focusing on its ability to handle large volumes of diverse financial data effectively.
Self-Exercise 15.2: Training a Financial-Specific LLM with Rust
Objective: To train a large language model on financial data using Rust, with a focus on handling imbalanced datasets, achieving high precision, and ensuring model interpretability.
Tasks:
Prepare a financial-specific dataset, ensuring it is properly preprocessed and annotated for training a large language model.
Implement a Rust-based training pipeline, incorporating techniques to handle imbalanced datasets and achieve high precision in model predictions.
Experiment with different methods to enhance model interpretability, ensuring that the outputs are understandable for financial professionals.
Evaluate the trained model on a validation dataset, analyzing its accuracy, interpretability, and performance in financial-specific tasks.
Deliverables:
A Rust codebase for training a financial-specific large language model, including data preprocessing and model interpretability techniques.
A training report detailing the model’s performance on financial tasks, with a focus on accuracy, precision, and interpretability.
A set of recommendations for further improving the model’s performance and applicability in financial applications.
Self-Exercise 15.3: Deploying a Financial LLM for Real-Time Inference
Objective: To deploy a large language model for real-time inference in a financial environment, focusing on optimizing latency, accuracy, and scalability.
Tasks:
Implement an inference pipeline in Rust that serves a financial-specific large language model, optimizing for low latency and high accuracy.
Deploy the model in a secure and scalable environment, ensuring compliance with financial regulations such as the SEC and GDPR.
Set up a real-time monitoring system to track the performance of the deployed model, focusing on key metrics such as latency, accuracy, and throughput.
Analyze the monitoring data to identify potential issues with the model’s performance, and implement updates or adjustments as needed.
Deliverables:
A Rust codebase for deploying and serving a financial large language model, including real-time inference capabilities.
A deployment report detailing the steps taken to ensure compliance with financial regulations and optimize inference performance.
A monitoring report that includes performance metrics and an analysis of the deployed model’s real-time behavior, with recommendations for ongoing maintenance and updates.
Self-Exercise 15.4: Ensuring Ethical Compliance in Financial LLM Deployment
Objective: To design and implement strategies for ensuring ethical compliance in the deployment of large language models in finance, focusing on bias detection, fairness, and transparency.
Tasks:
Implement bias detection techniques in a deployed financial LLM, ensuring that the model’s predictions are fair and equitable across different demographic groups.
Develop methods to enhance the transparency of the model’s decision-making processes, making them understandable for stakeholders, including regulators and investors.
Integrate continuous monitoring for ethical compliance, including mechanisms to detect and respond to potential ethical violations or model drift.
Conduct a thorough evaluation of the deployed model’s ethical performance, focusing on bias, fairness, and adherence to financial regulations.
Deliverables:
A Rust codebase with integrated bias detection and transparency features for a deployed financial large language model.
An ethical compliance report detailing the strategies used to ensure fairness and transparency, including bias detection results.
An evaluation report on the model’s ethical performance, with recommendations for improving ethical compliance in future deployments.
Self-Exercise 15.5: Innovating Financial Applications with LLMs: Case Study Implementation
Objective: To analyze a real-world case study of large language model deployment in finance and implement a small-scale version using Rust, focusing on replicating the critical aspects of the deployment.
Tasks:
Select a case study of a successful LLM deployment in finance, analyzing the key challenges, solutions, and outcomes.
Implement a small-scale version of the case study using Rust, focusing on the most critical components such as data handling, model training, and deployment.
Experiment with the implementation to explore potential improvements or adaptations, considering factors such as model performance, scalability, and compliance.
Evaluate the implemented model against the original case study, identifying key takeaways and lessons learned for future financial LLM projects.
Deliverables:
A Rust codebase that replicates a small-scale version of the selected financial LLM case study, including key deployment components.
A case study analysis report that details the original deployment’s challenges, solutions, and outcomes, along with insights gained from the implementation.
A performance evaluation of the implemented model, with a comparison to the original case study and recommendations for future innovations in financial LLM deployments.
Comments