Chapter 14
LLMs in Healthcare
"The integration of AI in healthcare offers unprecedented opportunities to improve patient outcomes, but it requires careful consideration of ethical, regulatory, and technical challenges to realize its full potential." — Fei-Fei Li
Chapter 14 of LMVR - Large Language Models via Rust explores the transformative potential of large language models (LLMs) in healthcare, focusing on the unique challenges and opportunities in this critical sector. The chapter covers the entire lifecycle of healthcare LLMs, from building robust data pipelines and training models on domain-specific data to deploying and maintaining them in compliance with stringent healthcare regulations. It addresses the ethical considerations and regulatory requirements essential for the responsible use of AI in healthcare, emphasizing the importance of transparency, accuracy, and patient safety. Through practical examples and case studies, the chapter provides readers with the tools and knowledge to develop and deploy LLMs in healthcare using Rust, ensuring that these powerful models are both effective and compliant with industry standards.
14.1. Introduction to LLMs in Healthcare
Large language models (LLMs) hold significant potential in healthcare, offering new capabilities for diagnostics, patient care, medical research, and more. These models can parse and interpret complex medical data, generate accurate responses to patient symptoms, assist in clinical decision-making, and support healthcare providers in research and documentation. For instance, LLMs can serve as diagnostic assistants by analyzing patient symptoms and medical history, providing initial assessments that help clinicians make informed decisions. Additionally, in patient care, LLMs can enhance patient engagement through conversational applications that answer health-related queries, promote adherence to treatment plans, and monitor patient symptoms. LLMs also play a transformative role in medical research by summarizing vast amounts of medical literature and providing insights that would otherwise be difficult to uncover manually.
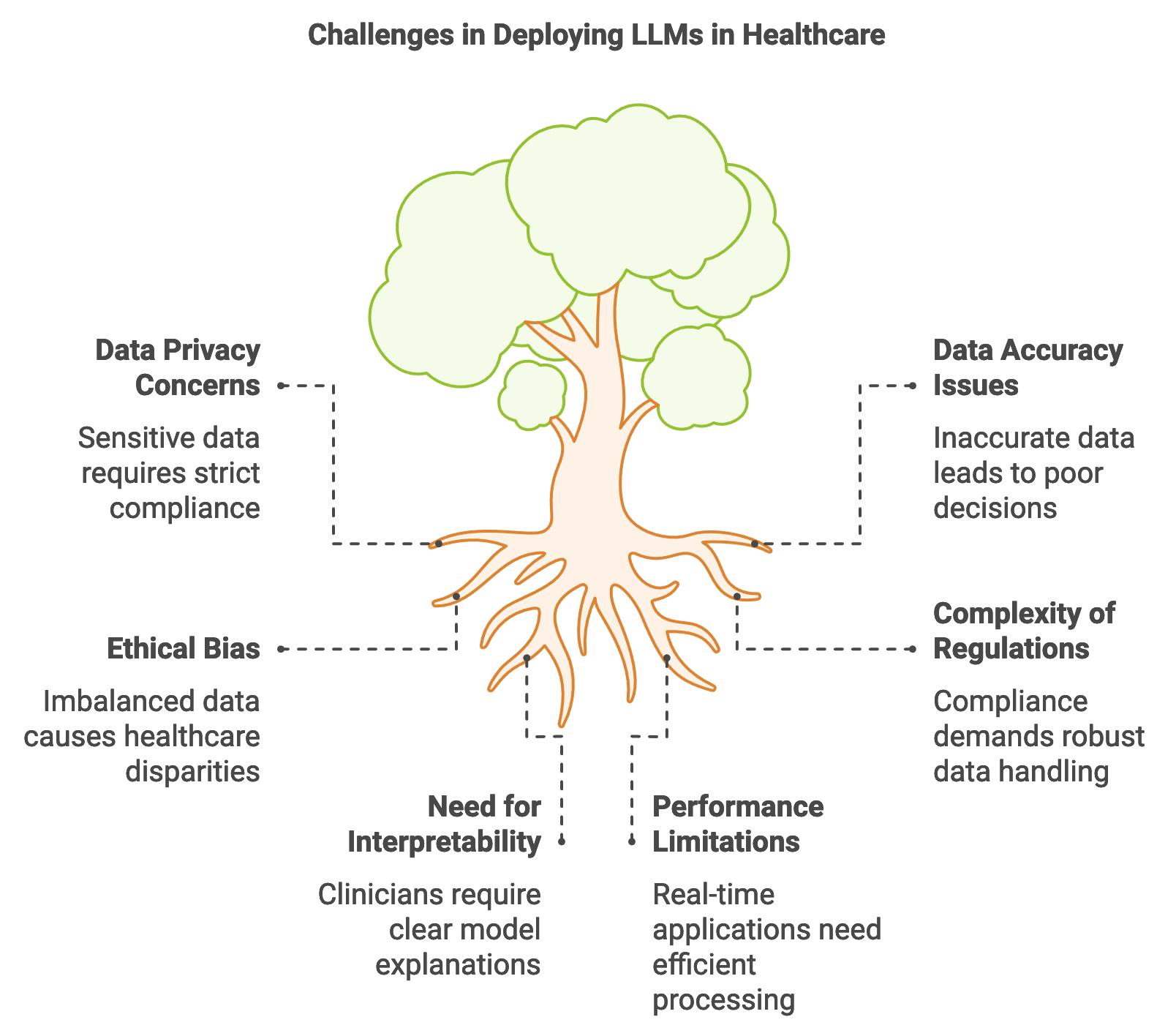
Figure 1: Key challenges in LLM implementation in Healthcare.
However, the healthcare sector presents unique challenges when it comes to deploying LLMs. Foremost among these are data privacy concerns, as healthcare data is highly sensitive and subject to regulations such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States and the General Data Protection Regulation (GDPR) in Europe. Compliance with these regulations requires robust mechanisms for data anonymization, secure data handling, and strict access control. Rust’s performance and safety features make it a suitable language for healthcare LLM applications, as Rust’s memory safety guarantees help prevent vulnerabilities that could lead to unauthorized data exposure. Additionally, Rust’s concurrency and performance optimization enable LLMs to operate efficiently in real-time applications, crucial for scenarios such as emergency diagnostic support where latency must be minimized.
Data accuracy, interpretability, and reliability are critical in healthcare-related LLM applications. In the medical field, inaccurate data or misleading model outputs can lead to poor clinical decisions, impacting patient health outcomes. Rust’s strong type system and memory safety features facilitate rigorous data handling, reducing the likelihood of errors during data preprocessing and model inference. Moreover, Rust’s support for transparency in code enables developers to clearly define and monitor each step in the LLM’s decision-making process, ensuring the interpretability of model outputs. This is particularly important in healthcare, where clinicians must be able to justify and understand the basis of model-generated suggestions. Mathematically, the interpretability of LLMs can be supported by calculating feature importance or relevance scores for each input token, helping to identify which aspects of patient data contribute most to the model’s recommendations.
The deployment of LLMs in healthcare has far-reaching implications for patient outcomes and healthcare delivery efficiency. For example, by streamlining administrative tasks like summarizing medical records, LLMs free up clinicians’ time to focus on patient care. Additionally, models that assist in early diagnosis or symptom checking can enable faster responses to health concerns, potentially reducing hospital admissions and improving preventative care. However, the ethical implications of deploying LLMs in healthcare are substantial. Bias in medical LLMs, arising from imbalanced training data or inherent biases in model algorithms, can result in disparities in healthcare recommendations. Ensuring fairness involves both careful dataset curation and continuous monitoring of model outputs across different demographic groups to identify and mitigate biased predictions. Rust’s transparency and monitoring capabilities can aid in addressing these ethical concerns, allowing developers to track and document model behavior comprehensively.
The following code illustrates a Rust-based API that allows users to input symptoms and receive potential diagnoses. This system demonstrates a secure, memory-safe Rust application where a trained LLM model, deployed within a Rocket server, interprets symptom data and returns a list of possible conditions. This setup showcases Rust's capabilities for secure and efficient healthcare applications. The code defines a web API endpoint using the Rocket framework for diagnosing symptoms based on input data. It utilizes asynchronous processing to handle a POST request to the /diagnose route, which accepts a JSON payload containing symptoms. The backend logic includes a mock language model (LLMModel) and tokenizer for processing input text, where the model provides a placeholder diagnosis. The code is structured to load an LLM model and tokenizer at runtime, manage them with shared state, and process requests concurrently with the help of Arc and Mutex for thread-safe access to shared resources.
[dependencies]
anyhow = "1.0.93"
tokenizers = "0.20.3"
rocket = { version = "0.5.1", features = ["json"] }
serde = { version = "1.0", features = ["derive"] }
use rocket::{post, routes, serde::json::Json, State};
use serde::Deserialize;
use std::sync::{Arc, Mutex};
use tokenizers::Tokenizer; // Assume an LLM tokenizer is used
use anyhow::Result;
#[derive(Debug)]
struct AppState {
model: Arc<Mutex<LLMModel>>, // LLM model for inference
tokenizer: Arc<Tokenizer>,
}
#[derive(Deserialize)]
struct SymptomInput {
symptoms: String,
}
#[post("/diagnose", data = "<input>")]
async fn diagnose(
input: Json<SymptomInput>,
state: &State<AppState>,
) -> Result<Json<Vec<String>>, String> {
let symptoms = &input.symptoms;
let model = state.model.lock().map_err(|_| "Model lock error")?;
let tokenizer = &state.tokenizer;
// Tokenize input symptoms
let tokens = tokenizer.encode(symptoms, true).map_err(|_| "Tokenization error")?;
// Perform model inference
let diagnoses = model.predict(tokens).map_err(|_| "Inference error")?;
// Example output formatting
let diagnosis_output: Vec<String> = diagnoses.into_iter().map(|d| d.to_string()).collect();
Ok(Json(diagnosis_output))
}
#[rocket::main]
async fn main() -> Result<()> {
let model = LLMModel::load()?; // Assuming a custom LLM model loader
let tokenizer = Tokenizer::from_file("path/to/tokenizer.json").unwrap();
let state = AppState {
model: Arc::new(Mutex::new(model)),
tokenizer: Arc::new(tokenizer),
};
rocket::build()
.manage(state)
.mount("/", routes![diagnose])
.launch()
.await?;
Ok(())
}
The diagnose endpoint takes symptoms in a JSON format, tokenizes them using an LLM-compatible tokenizer, and performs inference with the model to provide diagnostic predictions. The LLMModel struct includes placeholder functions for loading the model and making predictions. AppState holds shared instances of the model and tokenizer to support multiple requests. The main function sets up and launches the Rocket server, initializing the model and tokenizer for inference. The code handles errors such as model loading and tokenization issues by returning error messages, making the system resilient to failures in these areas.
Addressing common challenges in healthcare LLM deployment, such as handling sensitive patient data, requires strict adherence to privacy standards. Rust’s memory-safe programming paradigm minimizes the risk of unauthorized data access, which is critical when dealing with confidential patient information. Secure data handling practices, such as tokenization and anonymization, ensure that patient data remains protected throughout the model’s inference pipeline. In cases where model transparency is a priority, Rust’s type safety and code readability make it easier to implement explainability features, allowing healthcare providers to trace how model outputs are derived. This is essential for gaining clinicians’ trust in LLM-powered healthcare tools, especially in applications where transparency and justification are legally mandated.
Real-world case studies illustrate the impact of LLMs on healthcare. In one instance, a Rust-based LLM was deployed to analyze medical literature for drug interaction research. Given the vast amount of clinical research available, the model helped researchers identify adverse drug reactions more efficiently, reducing the time required for manual literature reviews. This use case underscores the efficiency gains LLMs offer in healthcare research. Similarly, other case studies reveal how LLMs enhance patient engagement through virtual health assistants, which provide patients with timely answers to health-related questions. Rust’s performance capabilities enable these assistants to operate with minimal latency, ensuring smooth user interactions and quick responses.
In conclusion, LLMs offer transformative possibilities for healthcare, from diagnostics and patient support to medical research. Rust’s performance, memory safety, and low-level control make it an ideal language for healthcare applications, where efficiency, accuracy, and security are paramount. By leveraging Rust’s capabilities, developers can create reliable and secure LLM-based solutions that not only improve healthcare outcomes but also respect patient privacy and regulatory requirements. This section provides a foundational understanding of how to harness Rust’s strengths in developing healthcare applications, highlighting both the opportunities and responsibilities that come with deploying LLMs in this field.
14.2. Building Healthcare Data Pipelines with Rust
Healthcare data used in training large language models (LLMs) spans a diverse range of formats, including structured data like electronic health records (EHRs) and unstructured data such as clinical notes, diagnostic reports, and patient correspondence. Effective data pipelines are essential for preparing this data to meet the stringent requirements of healthcare applications. The development of healthcare data pipelines involves data ingestion, preprocessing, normalization, and anonymization, all of which ensure that data remains secure and useful. Rust’s capabilities in memory safety, concurrency, and performance make it an excellent choice for managing large volumes of sensitive healthcare data. Using Rust-based tools and crates, developers can build efficient, secure data pipelines that maintain data integrity while meeting regulatory requirements.
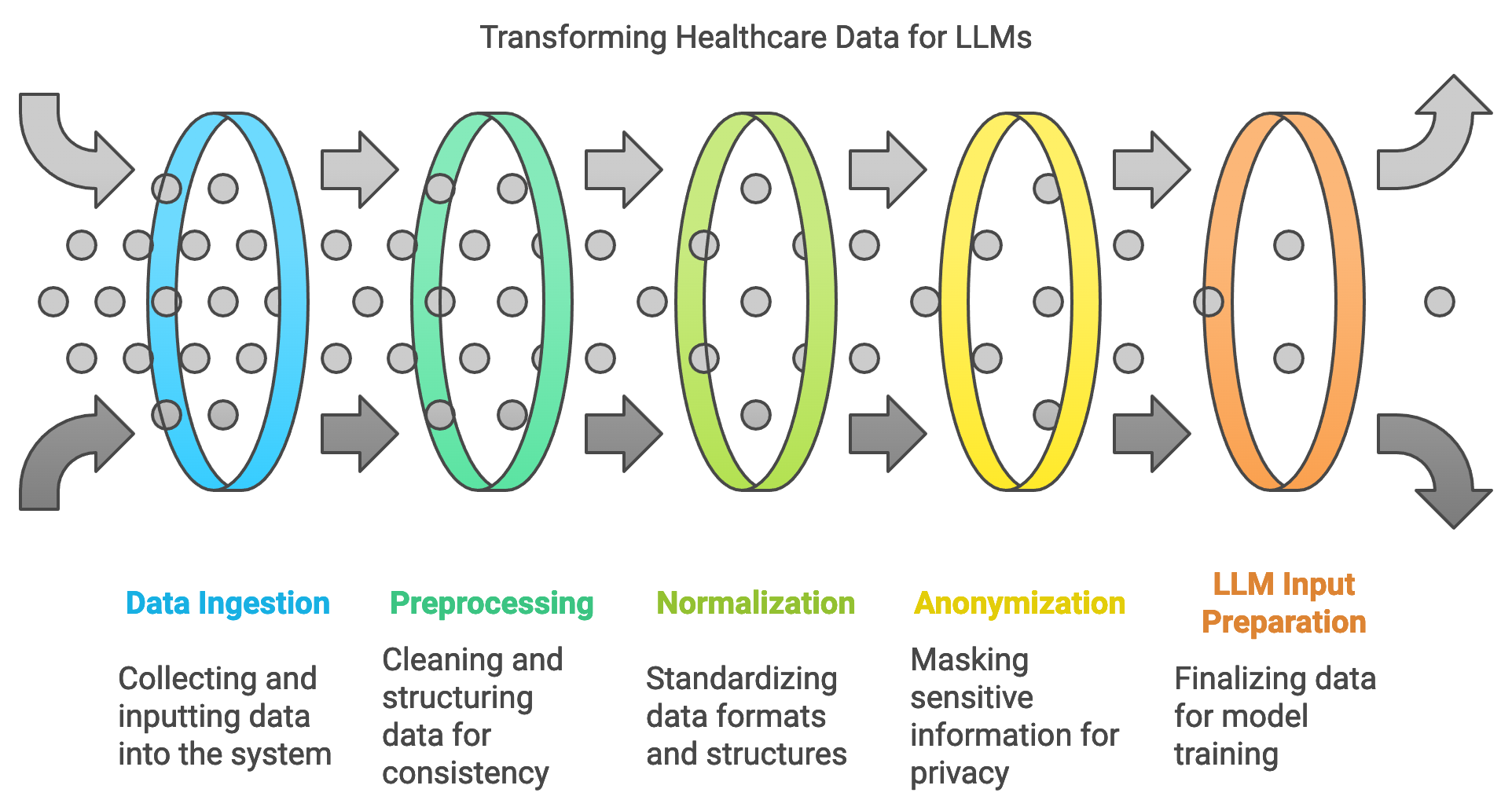
Figure 2: Data pipeline for LLM application.
Preprocessing healthcare data is the first major step in preparing it for LLM training, and it often involves cleaning, structuring, and normalizing data from disparate sources. Structured data, such as EHRs, requires field standardization, where inconsistencies in format (e.g., date formats, numeric values) are aligned. Unstructured data, like clinical notes, undergoes tokenization, sentence segmentation, and formatting to make it suitable for LLM input. Rust’s strong type safety and precise memory control are particularly beneficial here, as they minimize errors during data transformations, ensuring high data integrity. Mathematically, the preprocessing process can be represented by a transformation $T$ applied to each data instance ddd, where $T(d)$ yields a normalized instance:
$$ T(d) = d' \quad \text{such that} \quad d' \in D_{\text{standardized}} $$
where $D_{\text{standardized}}$ represents the set of all standardized instances. This transformation is essential for ensuring that the LLM receives consistent input, which directly impacts model performance.
One of the key challenges in healthcare data pipelines is handling data from heterogeneous sources, which often differ in structure and standardization. For instance, data from different hospitals may vary in coding standards, naming conventions, and even the medical terminology used. To address this, developers rely on interoperability standards such as HL7 and FHIR, which provide standardized structures and formats for healthcare data. Rust’s ecosystem includes crates like serde for serialization and deserialization, allowing developers to convert data between these formats seamlessly. Additionally, Rust’s concurrency support allows data from multiple sources to be processed simultaneously, accelerating the standardization process and preparing diverse datasets for unified LLM input.
Another critical aspect of healthcare data pipelines is privacy preservation, particularly in light of regulations like HIPAA and GDPR. Anonymization techniques remove or mask personally identifiable information (PII) from healthcare data to protect patient privacy. For example, a simple anonymization approach for text data might involve replacing names, dates, and specific locations with generic placeholders. In Rust, this can be implemented by using regular expressions to detect and replace sensitive information, ensuring that the data is secure before it enters the LLM pipeline.
To demonstrate the process of creating a secure and efficient healthcare data pipeline in Rust, here’s an example pipeline that showcases data ingestion, normalization, anonymization, and standardization steps, preparing data for LLM training while ensuring privacy compliance. This example will involve structured and unstructured data, leveraging Rust’s capabilities for memory safety, concurrency, and type safety to ensure secure data handling. This code outlines a basic data pipeline using Rust’s serde crate for data serialization and deserialization, and regular expressions for anonymization of personally identifiable information (PII) in unstructured clinical notes.
This scenario involves processing Electronic Health Records (EHR) and clinical notes, where structured EHR data contains fields such as patient ID, diagnosis, treatment, and admission date, while unstructured clinical notes contain free-form text that may include personal identifiers and dates. The goal is to standardize date formats in the structured EHR data and anonymize personally identifiable information (PII) in the clinical notes, ensuring data consistency and privacy compliance.
[dependencies]
anyhow = "1.0.93"
tokenizers = "0.20.3"
rocket = { version = "0.5.1", features = ["json"] }
serde = { version = "1.0", features = ["derive"] }
regex = "1.11.1"
use serde::{Deserialize, Serialize};
use regex::Regex;
use std::sync::{Arc, Mutex};
use std::thread;
// Define a structure for structured EHR data
#[derive(Serialize, Deserialize, Debug)]
struct EHRRecord {
patient_id: String,
diagnosis: String,
treatment: String,
admission_date: String,
}
// Sample unstructured clinical note
#[derive(Debug)]
struct ClinicalNote {
text: String,
}
// Function to standardize date formats in EHR records
fn standardize_date_format(date: &str) -> String {
// Converts dates to a standard YYYY-MM-DD format
let re = Regex::new(r"(\d{2})/(\d{2})/(\d{4})").unwrap();
re.replace_all(date, "$3-$1-$2").to_string()
}
// Function to anonymize PII in clinical notes using regular expressions
fn anonymize_text(note: &str) -> String {
let name_re = Regex::new(r"(?i)\b(Dr\.?\s*\w+\s*\w*|Mr\.?\s*\w+|Ms\.?\s*\w+|[A-Z][a-z]+ [A-Z][a-z]+)\b").unwrap();
let date_re = Regex::new(r"\b\d{2}/\d{2}/\d{4}\b").unwrap();
// Replace names and dates with placeholders
let anonymized = name_re.replace_all(note, "[REDACTED_NAME]");
date_re.replace_all(&anonymized, "[REDACTED_DATE]").to_string()
}
// Function to simulate ingestion and concurrent processing of EHR data
fn process_data(records: Vec<EHRRecord>, notes: Vec<ClinicalNote>) {
let processed_records = Arc::new(Mutex::new(Vec::new()));
// Standardize and anonymize data in separate threads for concurrency
let mut handles = vec![];
// Process structured EHR data
let records_handle = {
let processed_records = Arc::clone(&processed_records);
thread::spawn(move || {
for mut record in records {
record.admission_date = standardize_date_format(&record.admission_date);
processed_records.lock().unwrap().push(record);
}
})
};
handles.push(records_handle);
// Process unstructured clinical notes
let notes_handle = thread::spawn(move || {
for note in notes {
let anonymized_text = anonymize_text(¬e.text);
println!("Anonymized Note: {}", anonymized_text);
}
});
handles.push(notes_handle);
// Wait for all threads to complete processing
for handle in handles {
handle.join().unwrap();
}
// Output processed structured data
let records = processed_records.lock().unwrap();
for record in records.iter() {
println!("Processed Record: {:?}", record);
}
}
fn main() {
// Sample EHR records and clinical notes
let ehr_records = vec![
EHRRecord {
patient_id: "123".to_string(),
diagnosis: "Hypertension".to_string(),
treatment: "Medication A".to_string(),
admission_date: "01/20/2023".to_string(),
},
EHRRecord {
patient_id: "456".to_string(),
diagnosis: "Diabetes".to_string(),
treatment: "Medication B".to_string(),
admission_date: "12/15/2022".to_string(),
},
];
let clinical_notes = vec![
ClinicalNote {
text: "Patient Mr. John Doe reported severe headaches on 01/20/2023.".to_string(),
},
ClinicalNote {
text: "Dr. Smith recommended Ms. Jane Roe for further tests on 12/15/2022.".to_string(),
},
];
// Run data processing pipeline
process_data(ehr_records, clinical_notes);
}
This Rust code demonstrates a healthcare data pipeline that standardizes, anonymizes, and processes structured and unstructured data for secure preparation in large language model (LLM) applications. The structured EHRRecord data (e.g., diagnoses and treatment plans) undergoes date standardization through the standardize_date_format function, ensuring all dates follow a consistent format, which is critical for data consistency. For unstructured ClinicalNote data, the anonymize_text function applies regular expressions to replace names and dates with placeholders like [REDACTED_NAME] and [REDACTED_DATE], thereby removing personally identifiable information (PII) in compliance with privacy regulations. The process_data function leverages Rust’s concurrency by using threads to process EHR records and clinical notes simultaneously, improving efficiency and reducing processing time for large datasets. In the main function, sample data for EHR records and clinical notes is initialized and processed, with standardized and anonymized data outputted, showcasing how Rust can be used to build secure, efficient data pipelines that maintain data integrity and privacy in healthcare applications.
Data augmentation and synthetic data generation can be valuable tools in healthcare data pipelines, improving model robustness and generalization. Augmentation techniques involve modifying existing data to create slight variations, which can help the model generalize better and become resilient to minor input changes. For instance, synonyms can replace medical terminology, or numerical values in clinical notes can be shifted slightly within medically plausible ranges. Synthetic data generation, on the other hand, creates new data instances that resemble real patient data but do not correspond to actual individuals. This is especially valuable when training data is limited or when working with rare conditions. Mathematically, synthetic data $D_{\text{synth}}$ can be modeled as:
$$D_{\text{synth}} = \{ g(d) \mid d \in D_{\text{real}} \}$$
where $g$ represents a generative process that modifies or replicates instances from the real dataset $D_{\text{real}}$. Rust’s speed and low-level memory handling facilitate the efficient processing and generation of synthetic data, allowing developers to create diverse datasets without imposing heavy computational loads on the system.
In practical applications, healthcare data pipelines built with Rust are increasingly relevant. One case study involves deploying an LLM to assist clinicians by summarizing patient records and highlighting potential treatment options. This project used a Rust-based data pipeline to preprocess EHR data from multiple hospital systems, each with its own data standards. By converting these records into a unified format and anonymizing PII, the pipeline enabled a single, consolidated data source for the LLM. Real-time processing was achieved using Rust’s concurrency features, allowing data from various sources to be ingested and standardized in parallel, meeting the high-throughput requirements of a busy clinical environment. The resulting model provided clinicians with accurate summaries and treatment suggestions, enhancing the quality of patient care and reducing administrative burden.
In conclusion, Rust offers significant advantages in developing healthcare data pipelines, from handling large, heterogeneous datasets to ensuring compliance with stringent data privacy standards. Through preprocessing, normalization, and anonymization, Rust-based pipelines deliver reliable and consistent data for LLMs, enabling accurate and interpretable healthcare applications. By leveraging techniques such as data augmentation and synthetic data generation, these pipelines enhance model robustness and generalization, crucial in clinical settings where data diversity is vital. This section underscores Rust’s capability in building efficient, secure, and scalable data pipelines that meet the unique demands of healthcare, paving the way for advanced LLM applications that support clinicians, improve patient outcomes, and maintain regulatory compliance.
14.3. Training LLMs on Healthcare Data Using Rust
Training large language models (LLMs) on healthcare data requires a specialized approach that accounts for the unique characteristics of medical datasets. Healthcare data is typically highly domain-specific, containing terminology and contextual nuances that general-purpose LLMs may not fully understand. Additionally, healthcare data is often imbalanced, with certain conditions or treatments vastly underrepresented, which can lead to biased model predictions. To address these issues, training on healthcare data usually involves transfer learning and fine-tuning pre-trained models, allowing them to adapt to healthcare-specific tasks. Rust’s performance-oriented features, combined with a growing ecosystem of machine learning libraries, make it an effective choice for building and training LLMs that meet the stringent accuracy and interpretability demands of healthcare applications.
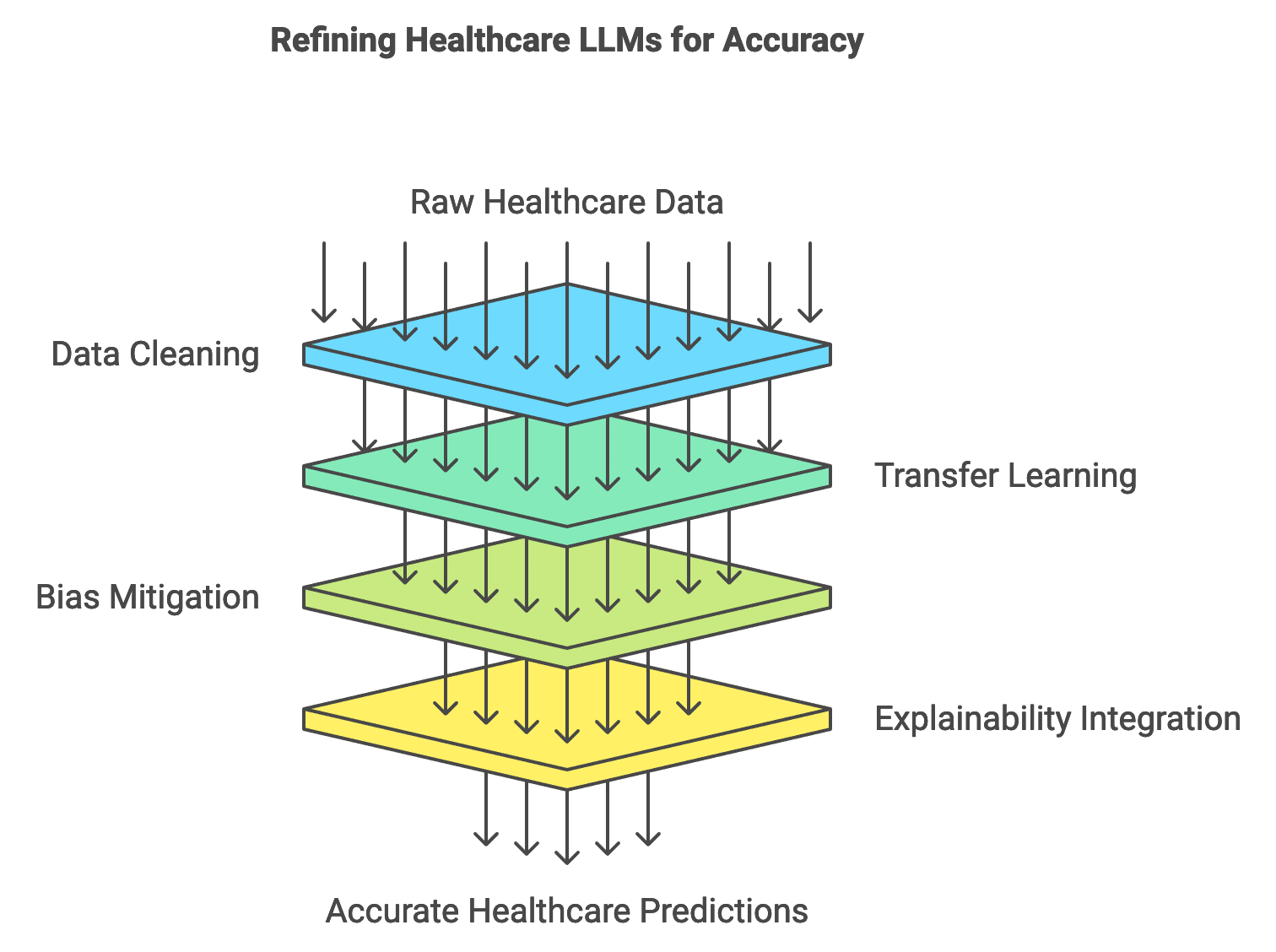
Figure 3: Accuracy pipeline for LLMs in Healthcare.
One of the primary challenges in training healthcare-specific LLMs is data sparsity, which arises when there are limited records for rare diseases or treatments. This scarcity can make it difficult for models to generalize well on these infrequent cases. To mitigate this, developers often apply transfer learning by taking a general-purpose pre-trained model and fine-tuning it on a domain-specific healthcare dataset. Transfer learning can be mathematically represented as adapting a model $M$ pre-trained on dataset $D_{gen}$ to perform well on a new dataset $D_{health}$:
$$ M_{health} = \text{fine-tune}(M_{gen}, D_{health}) $$
where $M_{gen}$ represents the initial, general-purpose model, and $M_{health}$ is the fine-tuned model specialized in healthcare tasks. This approach leverages the broad knowledge encoded in the pre-trained model while adapting it to the nuances of healthcare data, allowing the model to achieve higher accuracy and relevance in its predictions.
Healthcare LLM training also faces challenges related to noisy labels, where data might be inconsistently labeled or contain errors. This noise can affect the quality of model predictions and lead to misinterpretations. To address label noise, a data-cleaning step is essential, where mislabelled or ambiguous entries are identified and corrected. This cleaning process often involves applying rule-based filters or statistical outlier detection methods, both of which can be efficiently implemented in Rust due to its robust handling of complex data structures and processing efficiency. Additionally, using techniques such as label smoothing, which modifies the hard label distribution to reduce the impact of individual mislabels, can improve model robustness in healthcare contexts.
Explainability and interpretability are crucial for healthcare LLMs, especially when the models are used in clinical decision support systems where physicians rely on model predictions for diagnosis or treatment suggestions. Clinicians must understand the reasoning behind model predictions to integrate them effectively into patient care. Techniques such as attention visualization, which highlights the tokens most influential to the model’s decision, offer insights into the model’s reasoning process. In Rust, explainability features can be integrated into the training pipeline, allowing models to output attention maps or token relevancies alongside predictions. Mathematically, token relevance can be quantified by calculating attention weights for each input token tit_iti in a sequence $T = \{t_1, t_2, \dots, t_n\}$:
$$ \text{relevance}(t_i) = \frac{\sum_{j=1}^n \alpha_{ij} \cdot \text{embedding}(t_j)}{\sum_{j=1}^n \alpha_{ij}} $$
where $\alpha_{ij}$ represents the attention weight between tokens $t_i$ and $t_j$. Such insights help clinicians assess whether the model’s reasoning aligns with medical standards and clinical expectations.
Bias mitigation is another significant consideration when training healthcare-specific LLMs, as bias in training data can lead to unequal treatment recommendations across different patient groups. Strategies for addressing bias include balancing the dataset to ensure diverse representation and using fairness-aware learning objectives that penalize biased predictions. For instance, training objectives can include penalty terms that reduce the influence of biased instances, promoting model fairness across demographics. Rust’s ability to handle data structures efficiently makes it easier to analyze and adjust dataset compositions, ensuring that models are trained on balanced data, thus reducing biased outcomes.
A practical example of a healthcare LLM training pipeline in Rust might involve fine-tuning a pre-trained model on a healthcare dataset, followed by evaluating the model on a validation set. The pseudocode outlines a process for fine-tuning a machine learning model on healthcare-specific data. The model undergoes iterative training over multiple epochs, where it learns to associate certain input symptoms with target diagnoses or outcomes. This process involves encoding inputs, making predictions, calculating the error or "loss" based on the difference between predictions and actual targets, and then updating model parameters to reduce this loss in subsequent iterations.
# Import necessary libraries and modules
IMPORT Tensor FROM candle_core
IMPORT Tokenizer FROM tokenizers
IMPORT Error handling utilities
# Define an Optimizer class for managing learning rate adjustments
CLASS Optimizer:
FUNCTION __init__(learning_rate):
SET self.learning_rate TO learning_rate
FUNCTION step():
# Placeholder for optimization step
RETURN success
# Define a Model class that acts as a placeholder for loading and running the model
CLASS Model:
FUNCTION from_file(path):
# Load the model from the specified file path
RETURN a new Model instance
FUNCTION forward(input):
# Simulate a forward pass (making predictions based on input)
RETURN simulated prediction as a Tensor
FUNCTION backward(loss):
# Simulate a backward pass (updating model weights based on loss)
RETURN success
# Define a function to compute the loss between predictions and target outputs
FUNCTION compute_loss(predictions, target_tokens):
# Placeholder for calculating loss
RETURN simulated loss as a Tensor
# Define a function for fine-tuning the model on healthcare data
FUNCTION fine_tune_model(model, data, tokenizer, epochs, learning_rate):
INITIALIZE optimizer AS Optimizer(learning_rate)
FOR each epoch in range(epochs):
FOR each (input_text, target_text) in data:
# Tokenize the input text and target text
SET input_tokens TO tokenizer.encode(input_text)
SET target_tokens TO tokenizer.encode(target_text)
# Perform a forward pass to get predictions
SET predictions TO model.forward(input_tokens)
# Calculate loss
SET loss TO compute_loss(predictions, target_tokens)
# Perform a backward pass to update model weights
model.backward(loss)
# Update optimizer after each training sample
optimizer.step()
PRINT "Epoch {epoch + 1} completed"
RETURN success
# Main function to set up model, tokenizer, and fine-tune the model
FUNCTION main():
# Load a model and tokenizer from specified file paths
SET model TO Model.from_file("path/to/model/file")
SET tokenizer TO Tokenizer.from_file("path/to/tokenizer/file")
# Define healthcare-specific training data
SET training_data TO [
("input text 1", "target output 1"),
("input text 2", "target output 2"),
...
]
# Fine-tune the model on the training data
fine_tune_model(model, training_data, tokenizer, epochs=10, learning_rate=0.0001)
RETURN success
# Execute the main function
CALL main()
In the pseudocode, several key components are defined: an Optimizer class to manage learning rate adjustments, a placeholder Model class to represent loading, predicting, and backpropagating updates, and a compute_loss function to calculate the difference between model predictions and actual targets. The fine_tune_model function handles the core training loop, iterating over the data for a specified number of epochs and updating the model's weights with each sample. In main, the model and tokenizer are initialized, sample training data is defined, and the fine-tuning process begins. This pseudocode captures the essential flow of a model training pipeline, emphasizing high-level operations without specific implementation details.
Evaluating the performance of the trained model on a validation dataset is critical to measure accuracy, interpretability, and bias. The validation process involves running the model on unseen examples and comparing its predictions to known labels. Metrics such as precision, recall, and F1-score provide insights into the model’s diagnostic accuracy. Explainability features, like attention weights, are reviewed to assess the model’s interpretability, ensuring that its predictions are clinically relevant. Bias metrics, such as disparate impact ratio, are also essential, indicating whether the model’s predictions show consistent fairness across different patient groups.
Industry applications of healthcare LLMs trained with Rust-based pipelines are on the rise. In one instance, a Rust-based LLM was fine-tuned to assist radiologists by identifying and summarizing abnormal findings in medical images. By training on radiology reports and diagnostic labels, the model could generate text summaries of radiological scans, providing radiologists with an initial assessment of potential abnormalities. This approach not only saved radiologists time but also increased diagnostic accuracy, particularly in busy clinical environments where timely analysis is crucial.
In conclusion, training LLMs on healthcare data requires specialized methods to ensure model accuracy, interpretability, and fairness. Rust’s speed, memory safety, and efficient data handling support these objectives, enabling the development of robust healthcare-specific LLMs. Transfer learning and fine-tuning are essential in adapting general-purpose LLMs to the medical domain, while interpretability and bias mitigation strategies ensure that models are reliable and fair in clinical applications. This section provides a framework for building Rust-based LLM training pipelines that meet the stringent requirements of healthcare, enhancing model performance and reliability in patient care and clinical decision support.
14.4. Inference and Deployment of Healthcare LLMs Using Rust
Inference and deployment of large language models (LLMs) in healthcare require precision, speed, and strict adherence to privacy regulations. In clinical environments, real-time or near-real-time responses are often crucial, such as when an LLM assists in decision-making during emergency diagnostics or treatment recommendations. For healthcare LLMs, the inference process encompasses several critical considerations: latency, accuracy, and reliability. Inference latency, defined as the time taken for a model to generate predictions from input data, must be minimized to ensure responsive interactions with healthcare providers, especially in scenarios like telemedicine or patient monitoring. Meanwhile, accuracy and reliability are paramount, as misdiagnoses or erroneous treatment recommendations due to model errors can significantly impact patient outcomes. Deploying healthcare LLMs in a compliant, regulated environment adds additional layers of complexity. For instance, healthcare-specific regulations such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States mandate strict data privacy protections, impacting both the design of the inference pipeline and the deployment strategy. Thus, creating an efficient, secure inference system for healthcare LLMs in Rust requires an intricate balance between performance and regulatory adherence.
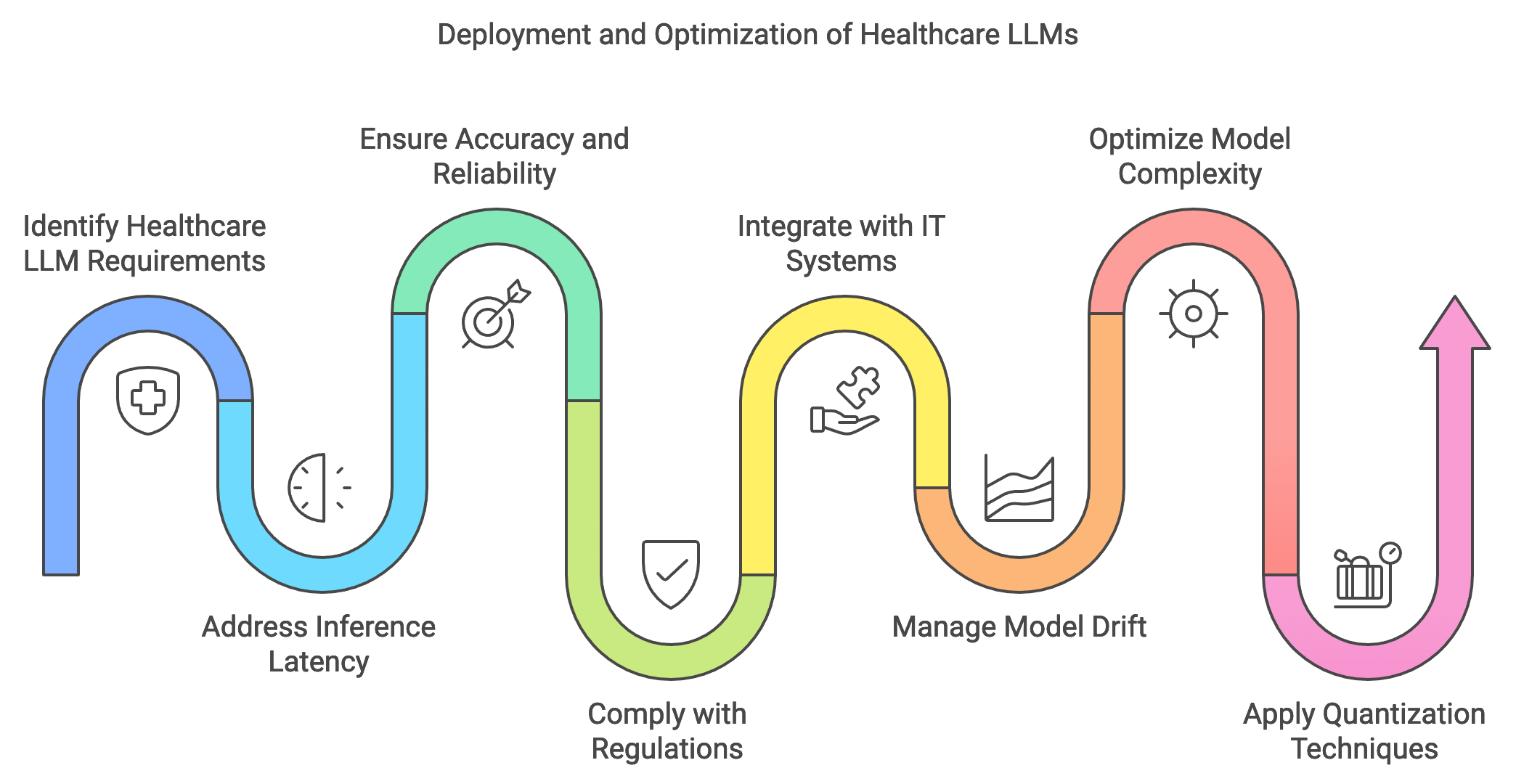
Figure 4: Deployment process of LLM applications in Healthcare.
The deployment of healthcare LLMs faces unique challenges, particularly when integrating with existing healthcare IT systems. Healthcare infrastructures often operate legacy systems with limited support for real-time AI models, posing barriers for seamless integration. Furthermore, deploying an LLM in healthcare entails ongoing model maintenance to prevent issues like model drift, where the model’s performance degrades over time due to evolving data distributions. Managing model drift is essential in healthcare, as new research, updated clinical guidelines, and patient demographic changes continuously influence the data landscape. Advanced monitoring systems are critical to detect and respond to performance drops by triggering model retraining or fine-tuning as necessary. Conceptually, this monitoring process can be represented by tracking a function $M_t(X)$where $M$ is the model and $X$ represents the input data distribution at time $t$. A significant deviation in $M_t(X)$ from the model's initial performance can indicate drift, necessitating updates to maintain accuracy and reliability in predictions.
In time-sensitive healthcare applications, model complexity directly impacts inference speed, as larger, more complex models require more computational resources and time per prediction. Optimizing healthcare LLMs often involves balancing these trade-offs by reducing model size or employing techniques such as quantization and knowledge distillation to maintain high performance while improving speed. Quantization, for instance, reduces the model’s numerical precision, leading to a smaller memory footprint and faster inference. Mathematically, this process can be represented as transforming model weights $W$ to $W_q$ where$W_q = Q(W)$, with $Q$ being the quantization function. Although quantization may reduce the model’s predictive accuracy slightly, it is often a viable solution in healthcare contexts where rapid inference is prioritized. Additionally, distillation techniques can be used to create smaller “student” models that retain the core functionality of larger “teacher” models, allowing healthcare applications to deploy less resource-intensive models with similar performance.
Practically, implementing an inference pipeline in Rust for a healthcare LLM involves creating a robust and secure API that enables rapid model deployment and scalability. Rust’s performance, concurrency support, and memory safety make it an ideal language for developing high-performance inference pipelines where speed and accuracy are crucial. The pseudocode below presents an advanced inference pipeline for a healthcare Large Language Model (LLM) designed to handle patient data securely and efficiently. This setup leverages an API to provide real-time predictions based on patient symptoms, showcasing the model’s ability to interpret clinical data at scale. With support for concurrency, the pipeline allows multiple requests to be processed simultaneously, making it ideal for deployment in clinical settings where rapid and accurate response times are critical.
# Import necessary modules for API, data handling, and model inference
IMPORT necessary API modules
IMPORT modules for data serialization, error handling, concurrency, and the LLM model
# Define the global application state
CLASS AppState:
FUNCTION __init__(self, model):
# Initialize the model within a thread-safe structure
SET self.model TO a thread-safe reference to the LLM model
# Define the structure for incoming patient data
CLASS PatientInput:
# A class or structure to store incoming patient symptoms text
ATTRIBUTE symptoms: STRING
# Define the endpoint for handling inference requests
FUNCTION inference_endpoint(input: PatientInput, state: AppState) -> STRING:
# Lock the model for secure access and handle lock errors
ACQUIRE lock on state.model OR RETURN "Model lock error"
# Tokenize the patient's symptom input using the model's tokenizer
SET tokens TO model.tokenizer.encode(input.symptoms)
# Run the model inference to generate predictions
SET predictions TO model.forward(tokens) OR RETURN "Inference error"
# Convert the model's tensor output to a readable string format
SET result TO convert predictions to a string
# Return the inference result as a JSON response
RETURN JSON response containing result
# Define the main function to initialize and launch the API
FUNCTION main() -> SUCCESS or ERROR:
# Initialize the device (CPU or GPU) for running the model inference
SET device TO CPU or GPU based on environment
# Load the healthcare LLM model onto the specified device
SET model TO load Whisper model onto device
# Set up the application state with the loaded model
SET state TO new instance of AppState with model
# Build the API:
INITIALIZE API framework
REGISTER endpoint "/inference" with inference_endpoint
ATTACH application state for concurrent access management
# Launch the API server and handle requests
START the API server
# Execute the main function to start the inference pipeline
CALL main()
The code initializes a secure API environment that encapsulates the model in a thread-safe structure within the AppState class, allowing safe concurrent access. Incoming patient symptom data is captured in the PatientInput class, which standardizes input data for tokenization and model processing. The inference_endpoint function then processes each request by tokenizing the input, running it through the model, and returning a JSON-formatted prediction. Finally, the main function sets up the hardware environment, loads the model, and configures the API server to handle requests. This structure provides a high-performance, scalable approach for deploying healthcare-focused LLMs, with careful handling of data compliance and concurrency management.
Industry use cases highlight the critical role of real-time inference capabilities for healthcare LLMs. For example, healthcare providers use real-time LLMs to assist in patient triage by assessing symptoms and suggesting immediate interventions. This type of deployment necessitates low-latency processing, as delayed responses could compromise patient care. Additionally, Rust’s speed enables deployment on resource-constrained hardware, such as edge devices in hospitals, where quick data processing can reduce network reliance and enhance data privacy.
Current trends in LLM deployment include integrating Rust-based monitoring systems to track model accuracy, detect model drift, and trigger updates. Monitoring systems in healthcare rely on continuous evaluation against key performance indicators (KPIs) such as prediction accuracy, latency, and compliance status. As new patient data becomes available, the system can analyze incoming data distributions and retrain models if deviations are detected. Mathematically, this monitoring process is defined as comparing $D_{\text{current}}$ (current data distribution) with $D_{\text{initial}}$ (initial data distribution) by computing the divergence $\text{div}(D_{\text{initial}}, D_{\text{current}})$. When this divergence exceeds a threshold, the system initiates updates, ensuring that the model remains aligned with evolving medical standards and patient needs.
Overall, deploying LLMs in healthcare using Rust provides a robust foundation for building reliable, secure, and efficient applications. Rust’s concurrency model supports real-time inference pipelines critical in time-sensitive applications, while its safety guarantees ensure data privacy and regulatory compliance. Through optimized inference pipelines and continuous model monitoring, Rust enables developers to build healthcare applications that are both effective and safe, advancing the integration of AI in clinical environments and ultimately enhancing patient care.
14.5. Ethical Considerations and Regulatory Compliance
Deploying large language models (LLMs) in healthcare necessitates careful attention to ethical and regulatory requirements, as these models directly impact patient care, decision-making, and data privacy. One of the primary ethical concerns in healthcare AI is bias, where models may inadvertently learn and replicate biases present in the training data. This can lead to disparities in healthcare recommendations, particularly for underrepresented or vulnerable populations. Fairness in AI is essential for building trust in healthcare applications, and it requires the development of bias detection and mitigation strategies to ensure that LLMs provide equitable recommendations across demographic groups. Additionally, obtaining informed consent for using patient data is a critical ethical requirement. Patients must understand how their data will be used, stored, and protected, especially when it contributes to LLM training or real-time inference. Transparency and accountability play central roles here, as healthcare providers and developers are responsible for ensuring that AI applications operate fairly and ethically. Rust, known for its safety and transparency, offers a strong foundation for building ethical LLM-based healthcare systems.
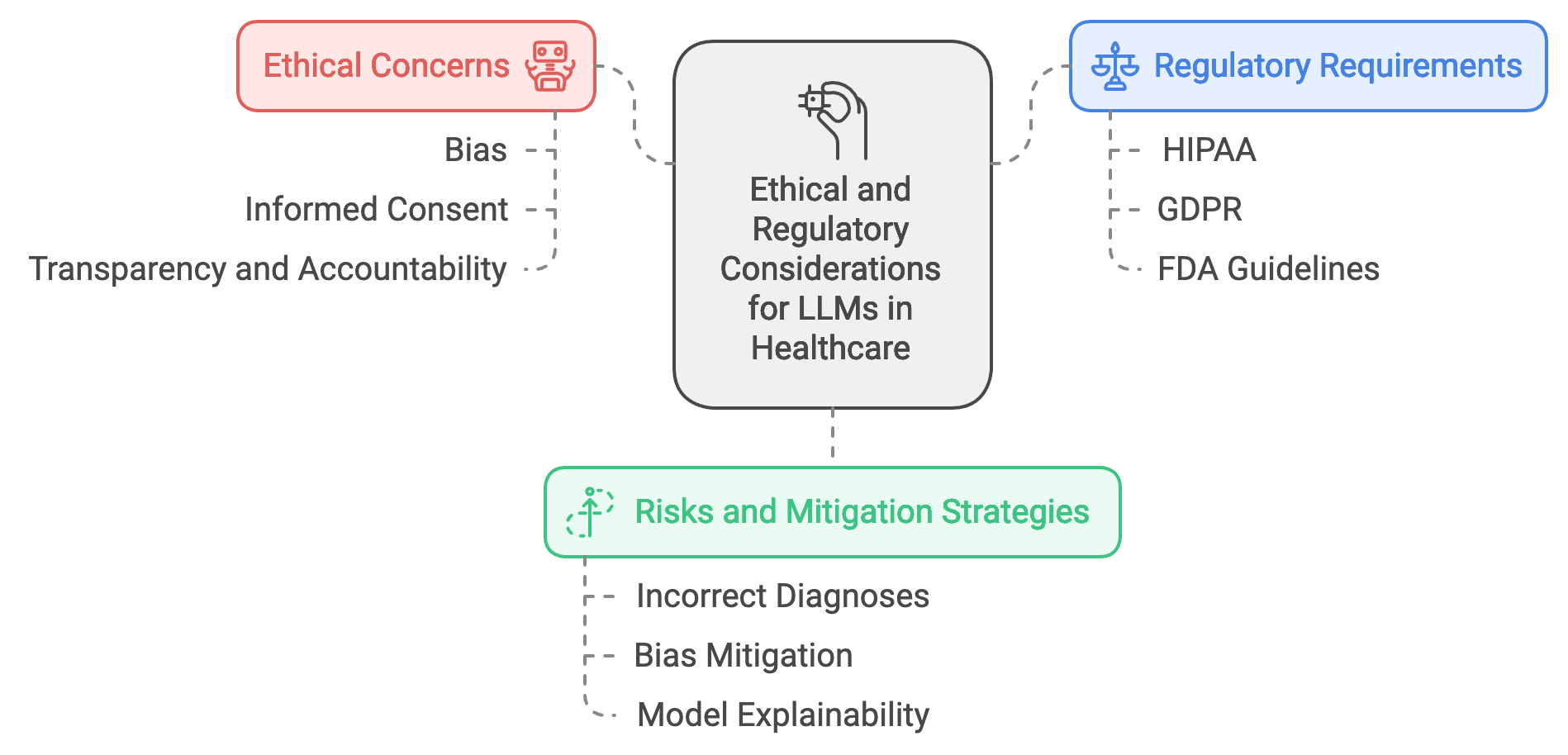
Figure 5: Ethical and regulatory concerns of LLM apps in Healthcare.
Healthcare LLM deployments must also navigate a complex regulatory landscape, adhering to laws such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States, the General Data Protection Regulation (GDPR) in Europe, and guidelines from regulatory bodies like the FDA for AI in medical devices. HIPAA mandates strict privacy and security requirements for managing patient data, including guidelines on data encryption, access control, and patient consent. GDPR, with its principles of data minimization, right to be forgotten, and explicit consent requirements, adds further challenges to healthcare AI deployments. Compliance with these regulations ensures that patient privacy is maintained, data breaches are prevented, and healthcare AI systems operate within the bounds of the law. The FDA, particularly in the U.S., regulates AI-based software as a medical device (SaMD), providing guidelines to ensure that AI in healthcare meets safety, effectiveness, and accountability standards. Rust’s strong type system, memory safety, and performance characteristics make it well-suited for developing compliant healthcare AI applications, allowing developers to build systems that can enforce these regulatory requirements with precision and reliability.
The risks of deploying biased or inaccurate LLMs in healthcare are substantial. If a model provides incorrect diagnoses or recommendations, it could lead to harmful outcomes for patients, particularly in time-sensitive or critical care situations. Mathematically, we can represent the probability of an incorrect prediction P(e)P(e)P(e) based on model bias and error. To minimize P(e)P(e)P(e), bias mitigation techniques such as reweighting, data augmentation, or adversarial debiasing can be applied. For example, in reweighting, weights wiw_iwi are assigned to each instance xix_ixi in the training set based on underrepresented features, ensuring a more balanced distribution and reducing model bias in predictions. Another key aspect is model explainability, which is essential for gaining trust from healthcare professionals. Explainability techniques provide insight into why a model made a specific prediction, helping clinicians understand the model’s decision-making process. Techniques like SHAP (Shapley Additive Explanations) or LIME (Local Interpretable Model-Agnostic Explanations) can quantify each feature’s contribution to a prediction, represented mathematically as ϕ(xi)\\phi(x_i)ϕ(xi) for each input feature xix_ixi in an explanation vector Φ={ϕ(x1),ϕ(x2),...,ϕ(xn)}\\Phi = \\{\\phi(x_1), \\phi(x_2), ..., \\phi(x_n)\\}Φ={ϕ(x1),ϕ(x2),...,ϕ(xn)}. This transparency fosters trust, as clinicians can evaluate the model’s reasoning and cross-reference it with medical expertise.
Ensuring compliance in healthcare LLMs involves developing a detailed checklist that addresses each regulatory requirement at every stage of the LLM lifecycle—from data collection and preprocessing to inference and deployment. For instance, data anonymization can be implemented using Rust’s regular expression capabilities to redact personally identifiable information (PII) from text data before it enters the LLM pipeline. Below is an example of how Rust can be used to detect and redact sensitive data fields, helping maintain regulatory compliance and data privacy in healthcare LLMs:
use regex::Regex;
use serde::{Deserialize, Serialize};
#[derive(Deserialize, Serialize, Debug)]
struct PatientRecord {
name: String,
birth_date: String,
medical_notes: String,
}
// Function to anonymize patient data by redacting names and dates
fn anonymize_data(record: &PatientRecord) -> PatientRecord {
let name_re = Regex::new(r"(?i)\b(?:Dr\.?|Mr\.?|Ms\.?)?\s*[A-Z][a-z]*\s+[A-Z][a-z]*\b").unwrap();
let date_re = Regex::new(r"\b\d{4}-\d{2}-\d{2}\b").unwrap();
let redacted_name = name_re.replace_all(&record.name, "[REDACTED_NAME]");
let redacted_date = date_re.replace_all(&record.birth_date, "[REDACTED_DATE]");
PatientRecord {
name: redacted_name.to_string(),
birth_date: redacted_date.to_string(),
medical_notes: record.medical_notes.clone(),
}
}
fn main() {
let patient = PatientRecord {
name: "John Doe".to_string(),
birth_date: "1980-04-22".to_string(),
medical_notes: "Patient reports persistent headaches.".to_string(),
};
let anonymized_patient = anonymize_data(&patient);
println!("Anonymized Record: {:?}", anonymized_patient);
}
This code provides a basic framework for anonymizing patient data, replacing PII like names and dates with placeholders. By ensuring that sensitive information is redacted, developers can better adhere to HIPAA and GDPR requirements, safeguarding patient privacy before data is used for LLM training or inference.
In real-world applications, continuous monitoring of healthcare LLMs is essential for ethical deployment. This involves regularly evaluating the model’s performance and identifying any shifts in predictions due to changes in the underlying data distribution or population demographics. For example, a healthcare provider could track the distribution DtD_tDt of model inputs over time ttt and compare it to a reference distribution D0D_0D0 using divergence metrics such as Kullback-Leibler divergence. When divergence exceeds a predefined threshold, the model may need retraining or adjustment to realign with patient expectations and regulatory standards.
Industry case studies reflect the importance of ethical LLM deployment in healthcare. For example, a recent project implemented an LLM to assist clinicians with preliminary diagnoses based on patient-reported symptoms. To address ethical concerns, the deployment incorporated bias detection algorithms that flagged instances of over- or under-representation of specific demographic groups in the dataset. Additionally, the system included an interpretability module that allowed clinicians to examine the model’s reasoning, further enhancing the model’s trustworthiness. These features align with industry trends that emphasize ethical AI practices and the development of transparent, explainable healthcare applications. Moreover, leading healthcare AI providers are increasingly adopting compliance frameworks that automate regulatory checks, ensuring LLMs in production meet all HIPAA, GDPR, and FDA requirements continuously.
In conclusion, deploying LLMs in healthcare necessitates a comprehensive approach to ethics and compliance. Rust’s performance, safety, and concurrency make it an ideal language for developing secure healthcare AI applications that adhere to stringent regulations and ethical standards. Through bias mitigation, anonymization, and monitoring, developers can ensure healthcare LLMs provide equitable, transparent, and reliable support to clinicians. By fostering trust and maintaining compliance, Rust-based healthcare LLMs hold the potential to revolutionize patient care while respecting the privacy and integrity of healthcare data.
14.6. Case Studies and Future Directions
Large language models (LLMs) are beginning to revolutionize healthcare by enabling sophisticated applications that range from personalized diagnostics to AI-driven patient support. Real-world case studies highlight both the successes and the challenges encountered when deploying LLMs in healthcare settings. For example, one recent implementation involved deploying an LLM for automated clinical documentation, where the model transcribed patient interactions and generated structured medical notes. This solution reduced clinician workload and allowed healthcare providers to dedicate more time to patient care. However, challenges such as maintaining model accuracy across diverse patient demographics and ensuring the model adhered to strict privacy regulations emerged. These case studies illustrate that while LLMs have significant potential to streamline healthcare operations, successful deployment requires careful handling of data privacy, model interpretability, and real-time performance to meet clinical standards.
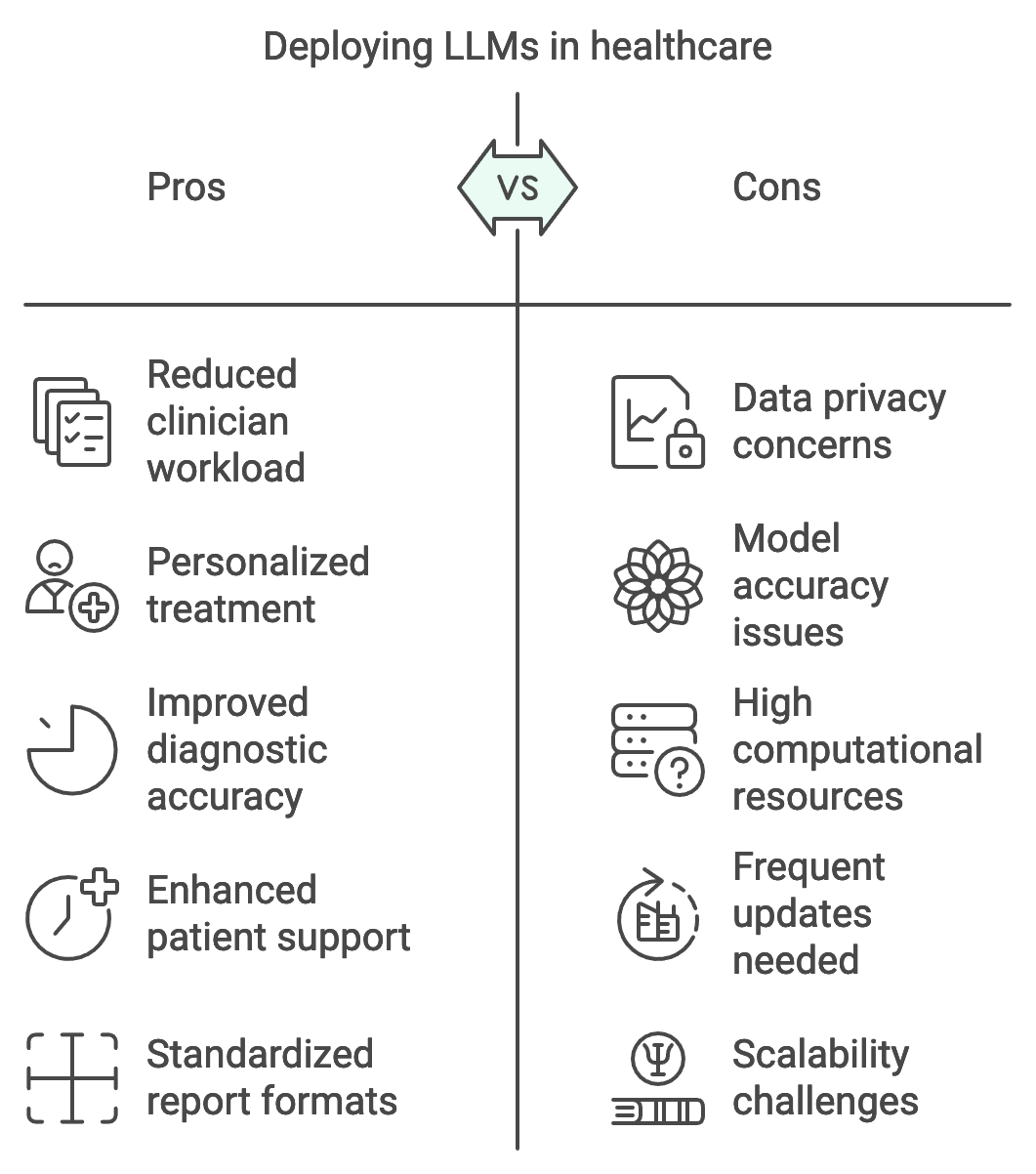
Figure 6: Pros and Cons to LLM apps in Healthcare.
Emerging trends suggest that LLMs in healthcare are moving toward personalized medicine, telehealth, and advanced diagnostics. Personalized medicine is a field where LLMs can be particularly transformative. By leveraging patient-specific data—such as genetic profiles, lifestyle factors, and medical histories—LLMs can offer tailored treatment recommendations, assisting clinicians in developing targeted therapies. Mathematically, this personalized approach can be represented as a function f(p,h,g)→rf(p, h, g) \\rightarrow rf(p,h,g)→r, where ppp represents patient-specific factors, hhh denotes historical medical data, ggg includes genetic information, and rrr is the recommended treatment protocol. Telehealth applications, especially in rural or underserved areas, also benefit from LLMs capable of interpreting patient input, analyzing symptoms, and providing preliminary advice or triage decisions, reducing barriers to accessing timely healthcare. Furthermore, LLMs are being increasingly utilized in diagnostic tools that assist in the interpretation of medical images, pathology reports, and lab results, transforming AI-driven diagnostics into a reality in clinical workflows.
Existing deployments of healthcare LLMs offer valuable lessons, especially regarding scalability and accuracy. In one case, an LLM was integrated into a large healthcare system to assist with the preliminary assessment of radiology reports. This deployment revealed that scaling an LLM across multiple hospitals required adjustments in both hardware resources and data preprocessing pipelines to accommodate diverse data formats. The system achieved considerable success in standardizing report formats and detecting critical findings, such as tumor markers, with high accuracy. However, frequent updates were necessary to maintain performance as new data types and sources were integrated. Scalability in healthcare LLMs is often constrained by the computational resources needed to process large amounts of unstructured data, particularly in hospitals with high patient throughput. To address this, Rust’s performance and memory safety characteristics make it an ideal choice for building efficient healthcare LLMs, allowing developers to optimize resource use without compromising model accuracy.
To implement a small-scale version of one of these case studies, we can consider a Rust-based solution that replicates an LLM for symptom checking. This application processes symptom descriptions from patients and generates preliminary diagnostic suggestions based on predefined medical knowledge encoded in the model. This pseudocode demonstrates a small-scale inference pipeline for a symptom-checking LLM tailored for healthcare. The setup creates a secure API where patients can input symptom descriptions and receive preliminary diagnostic suggestions. Designed to simulate real-world applications, this pipeline tokenizes symptoms, processes them through the LLM, and returns diagnostic predictions in a readable format. This example illustrates a scalable and high-performance solution for clinical support, emphasizing Rust’s strengths in memory management, concurrency, and real-time processing.
# Import necessary modules for API setup, data handling, and model inference
# Define the global application state to hold the healthcare model
CLASS AppState:
FUNCTION __init__(self, model):
# Initialize the model with a secure, thread-safe structure
SET self.model TO a thread-safe reference to the LLM model
# Define the structure to store incoming patient symptom descriptions
CLASS SymptomInput:
ATTRIBUTE symptoms: STRING
# Define the endpoint to handle symptom diagnosis requests
FUNCTION diagnose_endpoint(input: SymptomInput, state: AppState) -> STRING:
# Acquire secure lock on the model to ensure thread-safe access
ACQUIRE lock on state.model OR RETURN "Model lock error"
# Tokenize the patient's symptoms for model processing
SET tokens TO model.tokenizer.encode(input.symptoms)
# Run model inference to generate diagnostic suggestions
SET predictions TO model.forward(tokens) OR RETURN "Inference error"
# Convert predictions to a readable string format
SET result TO convert predictions to string
# Return the diagnostic suggestions in a JSON response
RETURN JSON response containing result
# Main function to initialize model, configure API, and handle requests
FUNCTION main() -> SUCCESS or ERROR:
# Specify the device for running model inference (CPU or GPU)
SET device TO CPU
# Load the healthcare LLM model onto the specified device
SET model TO load Whisper model on device
# Initialize the application state with the loaded model
SET state TO new instance of AppState with model
# Build the API with endpoint:
INITIALIZE API framework
REGISTER endpoint "/diagnose" with diagnose_endpoint
ATTACH application state for secure model access
# Launch the API server to handle incoming requests
START the API server
# Execute the main function to deploy the pipeline
CALL main()
This pseudocode simulates a secure inference pipeline for a healthcare LLM, enabling real-time symptom checking. The AppState class holds the model in a secure, thread-safe structure to support multiple requests. SymptomInput standardizes patient symptoms for input, while the diagnose_endpoint function tokenizes this input, processes it through the model, and converts predictions to a readable format. The main function configures the API server, loading the model on the appropriate hardware (e.g., CPU) and attaching the endpoint for handling real-time requests. This setup showcases a performant, scalable solution for deploying an LLM-based healthcare API, ideal for clinical applications requiring fast and secure symptom analysis.
Looking toward the future, LLMs hold immense promise for driving new healthcare innovations. One of the most exciting opportunities is the development of AI-based diagnostic tools capable of processing multimodal data, such as combining patient symptoms, genetic information, and medical images. The mathematical foundation for these systems often relies on cross-modal learning, where data from different sources contribute to a unified diagnostic output. Mathematically, this can be modeled as a function $f(x_s, x_g, x_i) \rightarrow d$, where $x_s$ represents symptom-based data, $x_g$ genetic data, $x_i$ imaging data, and ddd is the diagnostic output. Future healthcare LLMs could leverage such cross-modal architectures to support comprehensive patient assessments, thereby transforming AI-assisted diagnostics.
However, challenges remain, particularly regarding data availability, model interpretability, and compliance with evolving healthcare regulations. Healthcare data is often fragmented and inconsistently formatted, making it difficult to compile datasets that accurately represent the target population. Additionally, to gain clinician trust, LLMs must provide interpretable insights that clinicians can verify. Interpretability remains a complex challenge, as it involves developing techniques to visualize the model’s decision-making processes, potentially with feature attribution methods like SHAP values. Regulatory frameworks are also continuously evolving, especially as AI tools become more embedded in clinical care. Developers must therefore stay informed about new requirements, ensuring LLMs meet both ethical and legal standards throughout their lifecycle.
Finally, let us propose a new healthcare application that leverages LLMs: a patient monitoring system that analyzes real-time data from wearable devices to predict potential health issues. This system could combine LLMs with streaming data from heart rate monitors, blood glucose sensors, and sleep trackers to detect anomalies and notify healthcare providers before symptoms escalate. Rust’s concurrency model is particularly well-suited for handling real-time data ingestion and analysis, allowing the system to monitor multiple data streams simultaneously. To develop this system, steps would include gathering a comprehensive dataset of physiological data, training an LLM on health event prediction, and deploying the model in a secure, compliant environment. Evaluation metrics could include model precision, recall, and latency, ensuring the system’s performance aligns with clinical standards for real-time monitoring.
In conclusion, LLMs present transformative opportunities in healthcare, from enabling AI-driven diagnostics to supporting personalized medicine. Through case studies and proposed applications, it is evident that Rust’s strengths in memory safety, concurrency, and performance make it an ideal language for building secure and efficient healthcare LLM solutions. By addressing key challenges such as data diversity, interpretability, and compliance, future healthcare applications will be able to realize the full potential of LLMs in delivering high-quality patient care and advancing medical research. This section underscores the promising path forward for LLMs in healthcare, emphasizing the need for continued innovation, rigorous testing, and ethical deployment to create a future where AI and healthcare work hand in hand.
14.7. Conclusion
Chapter 14 equips readers with a deep understanding of how to develop and deploy large language models in healthcare using Rust, ensuring that these applications are not only innovative but also ethically sound and compliant with healthcare regulations. By mastering these techniques, readers can contribute to the future of healthcare, where AI plays a pivotal role in enhancing patient care and medical research.
14.7.1. Further Learning with GenAI
Each prompt is carefully crafted to push readers to explore the complexities and nuances of using LLMs in healthcare, ensuring a comprehensive understanding of both the technical and ethical challenges involved.
Explain the key challenges and opportunities of applying large language models (LLMs) in healthcare. How do data privacy, regulatory compliance, and ethical considerations shape the development and deployment of these models?
Describe the process of building a robust healthcare data pipeline using Rust. What are the essential steps for ensuring data integrity, privacy, and interoperability when handling large volumes of healthcare data?
Discuss the importance of data preprocessing and anonymization in healthcare LLM applications. How can Rust-based tools be used to implement these processes, and what are the trade-offs between data utility and privacy?
Explore the specific considerations for training LLMs on healthcare data. How do domain-specific knowledge, imbalanced datasets, and the need for high accuracy influence the training process?
Analyze the role of transfer learning in adapting general-purpose LLMs to healthcare-specific tasks. What are the key challenges and benefits of fine-tuning pre-trained models for healthcare applications?
Discuss the importance of explainability and interpretability in healthcare LLMs. How can Rust-based models be designed to ensure that their outputs are understandable and actionable for healthcare professionals?
Explain the challenges of deploying LLMs in healthcare environments, including latency, accuracy, and integration with existing IT systems. How can Rust be used to address these challenges effectively?
Explore the ethical considerations of using LLMs in healthcare, particularly in terms of bias, fairness, and patient consent. How can Rust-based systems be designed to detect and mitigate these ethical issues?
Discuss the regulatory requirements for deploying AI in healthcare, such as HIPAA and GDPR. How can developers ensure that their Rust-based LLM applications comply with these regulations?
Analyze the impact of real-time inference capabilities in healthcare applications. How can Rust be used to optimize inference pipelines for speed and accuracy in time-sensitive medical scenarios?
Explain the process of securing healthcare LLMs against adversarial attacks and data breaches. What techniques can be used in Rust to protect both model integrity and patient data privacy?
Discuss the role of continuous monitoring and maintenance in ensuring the long-term reliability of deployed healthcare LLMs. How can Rust-based systems be set up to track performance and implement updates?
Explore the challenges of integrating LLMs into existing healthcare IT infrastructure. How can Rust-based models be deployed in a way that ensures compatibility and minimal disruption?
Analyze the potential of LLMs to improve patient outcomes and healthcare delivery. What are the most promising applications of LLMs in healthcare, and how can Rust be used to develop these applications?
Explain the trade-offs between model complexity and inference speed in healthcare scenarios. How can Rust-based models be optimized to balance these factors effectively?
Discuss the importance of model validation and testing in healthcare LLM deployments. What are the best practices for ensuring that Rust-based models meet the required accuracy and reliability standards?
Explore the use of synthetic data and data augmentation in training healthcare LLMs. How can Rust be used to generate and utilize synthetic data to improve model robustness and generalization?
Analyze the role of patient consent and data ownership in the development of healthcare LLMs. How can Rust-based systems be designed to respect and enforce these principles?
Discuss the future potential of LLMs in healthcare, including personalized medicine, telehealth, and AI-driven diagnostics. How can Rust be leveraged to innovate in these emerging areas?
Explain the key lessons learned from existing case studies of LLM deployments in healthcare. What best practices can be derived from these experiences, and how can they inform the development of future Rust-based healthcare applications?
Embrace these challenges with curiosity and dedication, knowing that your work has the potential to transform healthcare and improve lives through the responsible use of AI technology.
14.7.2. Hands On Practices
Self-Exercise 14.1: Building and Securing a Healthcare Data Pipeline Using Rust
Objective: To design and implement a secure data pipeline for healthcare applications using Rust, focusing on data preprocessing, anonymization, and compliance with privacy regulations.
Tasks:
Set up a Rust-based data pipeline to ingest, preprocess, and anonymize healthcare data, ensuring compliance with relevant privacy regulations.
Implement data validation and integrity checks to ensure that the processed data is accurate and reliable for use in training large language models.
Integrate data anonymization techniques to protect patient privacy, balancing the trade-offs between data utility and confidentiality.
Test the pipeline with a sample dataset, identifying and addressing any issues related to data handling, security, or privacy.
Deliverables:
A Rust codebase for a healthcare data pipeline that includes preprocessing, validation, and anonymization components.
A detailed report on the implementation process, including the techniques used for data security and privacy, and compliance considerations.
A performance evaluation of the pipeline, focusing on its ability to handle large healthcare datasets securely and efficiently.
Self-Exercise 14.2: Training a Healthcare-Specific LLM with Rust
Objective: To train a large language model on healthcare-specific data using Rust, with a focus on domain adaptation, bias mitigation, and model explainability.
Tasks:
Prepare a healthcare-specific dataset, ensuring it is properly preprocessed and annotated for training a large language model.
Implement a Rust-based training pipeline, incorporating transfer learning techniques to adapt a general-purpose model to healthcare-specific tasks.
Experiment with different methods to mitigate bias in the model, ensuring fairness across different patient demographics.
Develop strategies to enhance the explainability of the model’s predictions, making it easier for healthcare professionals to interpret and trust the results.
Deliverables:
A Rust codebase for training a healthcare-specific large language model, including data preprocessing and bias mitigation techniques.
A training report detailing the performance of the model on healthcare tasks, with a focus on accuracy, fairness, and explainability.
A set of recommendations for further improving the model’s performance and interpretability in healthcare applications.
Self-Exercise 14.3: Deploying and Monitoring a Healthcare LLM for Real-Time Inference
Objective: To deploy a large language model for real-time inference in a healthcare environment, focusing on optimizing latency, accuracy, and compliance with healthcare regulations.
Tasks:
Implement an inference pipeline in Rust that serves a healthcare-specific large language model, optimizing for low latency and high accuracy.
Deploy the model in a secure environment, ensuring that the deployment complies with healthcare regulations such as HIPAA.
Set up a real-time monitoring system to track the performance of the deployed model, focusing on key metrics such as latency, accuracy, and throughput.
Analyze the monitoring data to identify potential issues with the model’s performance, and implement updates or adjustments as needed.
Deliverables:
A Rust codebase for deploying and serving a healthcare large language model, including real-time inference capabilities.
A deployment report detailing the steps taken to ensure compliance with healthcare regulations and optimize inference performance.
A monitoring report that includes performance metrics and an analysis of the deployed model’s real-time behavior, with recommendations for ongoing maintenance and updates.
Self-Exercise 14.4: Ensuring Ethical Compliance in Healthcare LLM Deployment
Objective: To design and implement strategies for ensuring ethical compliance in the deployment of large language models in healthcare, focusing on bias detection, patient consent, and regulatory adherence.
Tasks:
Implement bias detection techniques in a deployed healthcare LLM, ensuring that the model’s predictions are fair and equitable across different patient demographics.
Develop a system for managing patient consent, ensuring that data used for training and inference complies with legal and ethical standards.
Integrate continuous monitoring for ethical compliance, including mechanisms to detect and respond to potential ethical violations or model drift.
Conduct a thorough evaluation of the deployed model’s ethical performance, focusing on bias, fairness, and adherence to patient consent regulations.
Deliverables:
A Rust codebase with integrated bias detection and patient consent management features for a deployed healthcare LLM.
A compliance report detailing the ethical considerations addressed during deployment, including bias detection results and consent management processes.
An evaluation report on the model’s ethical performance, with recommendations for improving ethical compliance in future deployments.
Self-Exercise 14.5: Innovating Healthcare with LLMs: Case Study Implementation
Objective: To analyze a real-world case study of large language model deployment in healthcare and implement a small-scale version using Rust, focusing on replicating the critical aspects of the deployment.
Tasks:
Select a case study of a successful LLM deployment in healthcare, analyzing the key challenges, solutions, and outcomes.
Implement a small-scale version of the case study using Rust, focusing on the most critical components such as data handling, model training, and deployment.
Experiment with the implementation to explore potential improvements or adaptations, considering factors such as model performance, scalability, and compliance.
Evaluate the implemented model against the original case study, identifying key takeaways and lessons learned for future healthcare LLM projects.
Deliverables:
A Rust codebase that replicates a small-scale version of the selected healthcare LLM case study, including key deployment components.
A case study analysis report that details the original deployment’s challenges, solutions, and outcomes, along with insights gained from the implementation.
A performance evaluation of the implemented model, with a comparison to the original case study and recommendations for future innovations in healthcare LLM deployments.
Comments