Chapter 13
Inference and Deployment of LLMs
"The real power of AI lies not just in training large models, but in deploying them effectively and efficiently across various environments to create real-world impact." — Andrew Ng
Chapter 13 of LMVR focuses on the efficient inference and deployment of large language models using Rust. The chapter begins by explaining the importance of optimizing inference pipelines and explores various techniques such as model quantization, pruning, and batching. It then covers the deployment of LLMs in production environments, discussing the use of APIs, containerization, and orchestration tools like Docker and Kubernetes. The chapter also delves into scaling inference workloads, both horizontally and vertically, and highlights the unique challenges of edge deployment, including resource constraints and power efficiency. Additionally, it addresses the critical aspects of securing and maintaining deployed models, ensuring long-term reliability and security. Through real-world case studies, the chapter provides practical insights into deploying LLMs effectively using Rust's performance-oriented features.
13.1. Introduction to Inference and Deployment
Inference is the process by which large language models (LLMs) transform learned parameters into predictions and actionable insights, serving as the final step that bridges model training with practical application. Inference is where a trained model applies its understanding to real-world tasks, generating outputs based on new input data without further modification of model parameters. Inference for LLMs often entails responding to natural language queries, generating summaries, or offering language-based recommendations. Successful deployment strategies for LLM inference involve considerations such as scalability, latency, and resource efficiency, each crucial for ensuring the model’s responsiveness and cost-effectiveness in production environments. Unlike training, which prioritizes accuracy through extensive iterations, inference emphasizes speed and consistency, where latency and memory usage are paramount.
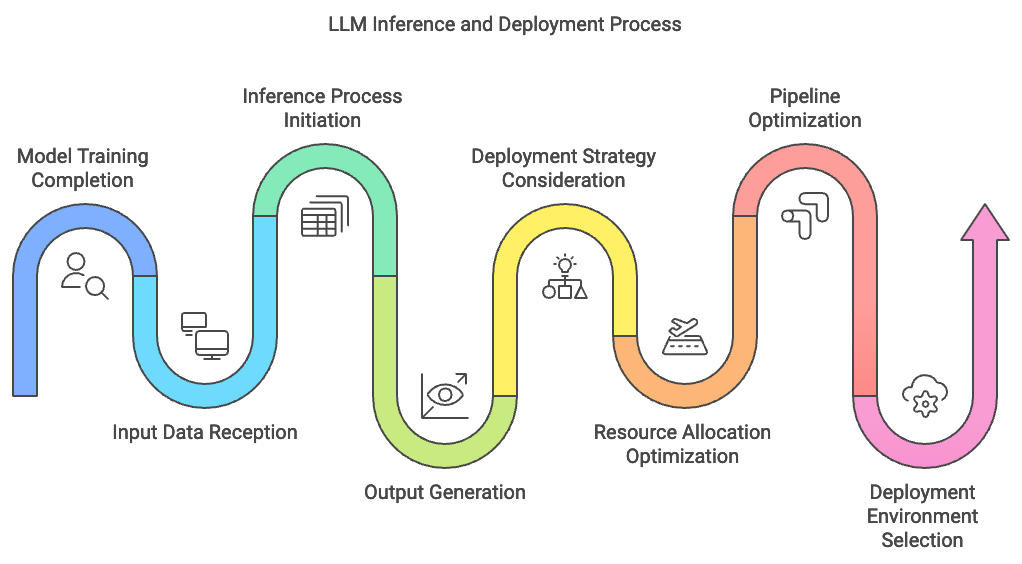
Figure 1: The flow of LLM inference and deployment process.
The deployment of LLMs presents unique challenges compared to training, as inference demands rapid processing and low overhead while serving potentially high volumes of requests. Key distinctions between training and inference include the nature of computational loads, memory access patterns, and data flows. During training, the focus is on backpropagation and optimization of model parameters, often requiring heavy memory utilization and computational power to accommodate large batch processing. In contrast, inference workloads are typically more lightweight but must be processed in near real-time, often one request at a time or in smaller batches to meet user demands. This shift places new demands on resource allocation strategies, as inference often benefits from optimizations that reduce memory usage and minimize computational latency.
Inference and deployment entail a series of trade-offs, particularly in balancing model accuracy, processing speed, and resource utilization. Higher accuracy may involve using more complex model architectures, which tend to consume more computational resources and lead to longer response times. By contrast, reducing model complexity can speed up inference but may compromise accuracy. Rust’s efficient memory management and low-latency execution make it well-suited for fine-tuning this balance, allowing developers to optimize model inference for various deployment environments. These include cloud, on-premises, and edge environments, each with its own constraints and advantages. Cloud deployments offer high scalability and are well-suited for handling fluctuating loads, though they may introduce latency due to network reliance. On-premises deployment provides more control over data privacy and latency but requires substantial upfront hardware investments. Edge deployment brings inference closer to the end user, reducing latency and network dependency, which is especially valuable in mobile applications and IoT devices.
Optimizing inference pipelines is critical to ensuring that LLMs deliver accurate and timely responses in real-world applications. Effective inference pipelines address data pre-processing, model loading, and response time through efficient coding practices and hardware utilization. Reducing model footprint through techniques like quantization, which involves reducing the precision of model weights (e.g., from FP32 to INT8), can decrease memory usage and speed up calculations. Inference optimizations are further refined by considering data batching, caching mechanisms, and load balancing to handle peak request volumes without compromising response times. By structuring inference pipelines efficiently, Rust-based systems achieve both high responsiveness and robustness, enhancing the user experience in deployed applications.
Setting up a basic inference pipeline in Rust involves selecting the appropriate crates and configuring the model for real-time processing. This Rust code demonstrates an inference pipeline for a BERT-based language model to generate embeddings for sentence similarity tasks, suitable for applications such as semantic search or recommendation systems. Using the candle and candle_transformers crates, the code loads a pre-trained BERT model along with its tokenizer and configuration from the Hugging Face repository. The model can run either on a single input sentence (prompt) to output embeddings or on a batch of predefined sentences to compute pairwise cosine similarity scores, indicating how semantically close the sentences are. It also includes options for normalizing embeddings using L2 normalization for enhanced similarity comparisons.
[dependencies]
anyhow = "1.0"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-transformers = "0.7.2"
env_logger = "0.11.5"
hf-hub = "0.3.2"
log = "0.4.22"
serde = "1.0.214"
serde_json = "1.0.132"
tch = "0.12.0"
tokenizers = "0.20.1"
tracing-chrome = "0.7.2"
tracing-subscriber = "0.3.18"
use anyhow::{Error as E, Result};
use candle_transformers::models::bert::{BertModel, Config, HiddenAct, DTYPE};
use candle_core::Tensor;
use candle_nn::VarBuilder;
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::{PaddingParams, Tokenizer};
struct Args {
cpu: bool,
tracing: bool,
model_id: String,
revision: String,
prompt: Option<String>,
use_pth: bool,
n: usize,
normalize_embeddings: bool,
approximate_gelu: bool,
}
impl Args {
fn new() -> Self {
Args {
cpu: true, // Run on CPU rather than on GPU
tracing: false, // Disable tracing
model_id: "sentence-transformers/all-MiniLM-L6-v2".to_string(), // Model ID
revision: "refs/pr/21".to_string(), // Revision ID
prompt: None, // No prompt for embeddings
use_pth: false, // Use safetensors by default
n: 1, // Number of runs
normalize_embeddings: true, // L2 normalization for embeddings
approximate_gelu: false, // Use erf-based Gelu
}
}
fn build_model_and_tokenizer(&self) -> Result<(BertModel, Tokenizer)> {
let device = candle_examples::device(self.cpu)?;
let repo = Repo::with_revision(self.model_id.clone(), RepoType::Model, self.revision.clone());
let (config_filename, tokenizer_filename, weights_filename) = {
let api = Api::new()?;
let api = api.repo(repo);
let config = api.get("config.json")?;
let tokenizer = api.get("tokenizer.json")?;
let weights = if self.use_pth {
api.get("pytorch_model.bin")?
} else {
api.get("model.safetensors")?
};
(config, tokenizer, weights)
};
let config = std::fs::read_to_string(config_filename)?;
let mut config: Config = serde_json::from_str(&config)?;
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let vb = if self.use_pth {
VarBuilder::from_pth(&weights_filename, DTYPE, &device)?
} else {
unsafe { VarBuilder::from_mmaped_safetensors(&[weights_filename], DTYPE, &device)? }
};
if self.approximate_gelu {
config.hidden_act = HiddenAct::GeluApproximate;
}
let model = BertModel::load(vb, &config)?;
Ok((model, tokenizer))
}
}
fn main() -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::new(); // Instantiate Args with hardcoded values
let _guard = if args.tracing {
println!("tracing...");
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
let start = std::time::Instant::now();
let (model, mut tokenizer) = args.build_model_and_tokenizer()?;
let device = &model.device;
if let Some(prompt) = args.prompt.clone() {
let tokenizer = tokenizer
.with_padding(None)
.with_truncation(None)
.map_err(E::msg)?;
let tokens = tokenizer
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
let token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?;
let token_type_ids = token_ids.zeros_like()?;
println!("Loaded and encoded {:?}", start.elapsed());
for idx in 0..args.n {
let start = std::time::Instant::now();
let ys = model.forward(&token_ids, &token_type_ids, None)?;
if idx == 0 {
println!("{ys}");
}
println!("Took {:?}", start.elapsed());
}
} else {
let sentences = [
"The cat sits outside",
"A man is playing guitar",
"I love pasta",
"The new movie is awesome",
"The cat plays in the garden",
"A woman watches TV",
"The new movie is so great",
"Do you like pizza?",
];
let n_sentences = sentences.len();
if let Some(pp) = tokenizer.get_padding_mut() {
pp.strategy = tokenizers::PaddingStrategy::BatchLongest
} else {
let pp = PaddingParams {
strategy: tokenizers::PaddingStrategy::BatchLongest,
..Default::default()
};
tokenizer.with_padding(Some(pp));
}
let tokens = tokenizer
.encode_batch(sentences.to_vec(), true)
.map_err(E::msg)?;
let token_ids = tokens
.iter()
.map(|tokens| {
let tokens = tokens.get_ids().to_vec();
Ok(Tensor::new(tokens.as_slice(), device)?)
})
.collect::<Result<Vec<_>>>()?;
let attention_mask = tokens
.iter()
.map(|tokens| {
let tokens = tokens.get_attention_mask().to_vec();
Ok(Tensor::new(tokens.as_slice(), device)?)
})
.collect::<Result<Vec<_>>>()?;
let token_ids = Tensor::stack(&token_ids, 0)?;
let attention_mask = Tensor::stack(&attention_mask, 0)?;
let token_type_ids = token_ids.zeros_like()?;
println!("running inference on batch {:?}", token_ids.shape());
let embeddings = model.forward(&token_ids, &token_type_ids, Some(&attention_mask))?;
println!("generated embeddings {:?}", embeddings.shape());
// Apply some avg-pooling by taking the mean embedding value for all tokens (including padding)
let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?;
let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?;
let embeddings = if args.normalize_embeddings {
normalize_l2(&embeddings)?
} else {
embeddings
};
println!("pooled embeddings {:?}", embeddings.shape());
let mut similarities = vec![];
for i in 0..n_sentences {
let e_i = embeddings.get(i)?;
for j in (i + 1)..n_sentences {
let e_j = embeddings.get(j)?;
let sum_ij = (&e_i * &e_j)?.sum_all()?.to_scalar::<f32>()?;
let sum_i2 = (&e_i * &e_i)?.sum_all()?.to_scalar::<f32>()?;
let sum_j2 = (&e_j * &e_j)?.sum_all()?.to_scalar::<f32>()?;
let cosine_similarity = sum_ij / (sum_i2 * sum_j2).sqrt();
similarities.push((cosine_similarity, i, j))
}
}
similarities.sort_by(|u, v| v.0.total_cmp(&u.0));
for &(score, i, j) in similarities[..5].iter() {
println!("score: {score:.2} '{}' '{}'", sentences[i], sentences[j])
}
}
Ok(())
}
pub fn normalize_l2(v: &Tensor) -> Result<Tensor> {
Ok(v.broadcast_div(&v.sqr()?.sum_keepdim(1)?.sqrt()?)?)
}
In detail, the code begins by setting up device configurations, tokenizer options, and BERT model parameters. For single-sentence input, it encodes the prompt, runs it through the model, and outputs the generated embedding. In the batch scenario, multiple sentences are tokenized, padded to the same length, and passed to the model as a batch for efficient inference. Each sentence’s embeddings are pooled by averaging across token embeddings, then normalized if required. Cosine similarity scores between all pairs of sentences in the batch are computed and sorted, with the top similarity scores displayed. This approach showcases how Rust can be used to implement efficient, batched inference and similarity scoring, leveraging tensor operations for real-time applications in semantic understanding.
Real-world deployment of LLMs often involves overcoming challenges such as model serving latency and efficient resource allocation. Model serving latency is the time it takes for a deployed model to generate a response to a user request. Latency can be managed by employing caching for frequent requests, pre-loading model components, and reducing computation times with quantization or pruning techniques, which streamline the model by removing less impactful parameters. Load balancing is also vital in high-traffic applications, as it evenly distributes requests across server nodes to prevent bottlenecks and maintain responsiveness. Rust’s control over data structures and memory layout allows for fine-tuned optimizations, facilitating load balancing and caching strategies that maintain low latency.
In applications where inference latency is highly sensitive, such as customer support systems or autonomous systems, deploying LLMs on the edge provides a solution. Edge inference reduces the time for requests to travel between the user and server by processing data locally on devices. However, edge deployments demand memory-efficient models and lightweight inference pipelines to function effectively on limited hardware. Techniques like model pruning, which removes redundant model weights, and quantization allow models to operate within constrained environments. Rust’s compact memory footprint and precise data handling align well with edge requirements, making it ideal for designing streamlined models that fit within the resource constraints typical of edge hardware.
Inference and deployment techniques also reflect broader trends in model deployment, emphasizing cross-platform adaptability, resource efficiency, and responsiveness. In healthcare, for example, where patient data privacy is paramount, deploying LLMs on-premises enables efficient data processing while safeguarding confidentiality. Meanwhile, cloud deployments are suitable for large-scale applications like e-commerce, where high volumes of concurrent requests require robust load balancing and scalability. Each environment benefits from the efficient Rust-based optimizations discussed, enabling versatile and resource-conscious inference and deployment solutions.
In summary, inference and deployment transform the potential of trained LLMs into real-world applications. Rust’s ecosystem supports optimized inference pipelines through efficient memory management, low-latency data handling, and robust tooling for real-time monitoring and logging. The examples presented here highlight how Rust’s strengths enable flexible deployment across cloud, on-premises, and edge environments, each requiring tailored strategies to meet specific latency, scalability, and resource requirements. By mastering these inference techniques, developers can maximize the utility of LLMs, applying them effectively and efficiently across a diverse range of applications.
13.2. Optimizing Inference Pipelines in Rust
Optimizing inference pipelines is essential for deploying large language models (LLMs) efficiently, where the goal is to maximize speed and reduce computational costs without compromising model accuracy. Techniques such as model quantization, pruning, and batching are commonly used to streamline inference, each impacting model performance in distinct ways. Model quantization reduces the bit precision of model weights and activations, lowering memory usage and accelerating computations. Pruning removes less critical parameters, reducing model size and computation requirements. Batching, on the other hand, aggregates multiple inputs to process them simultaneously, improving throughput in high-demand settings. Rust’s performance-oriented features, such as low-level memory control and high concurrency support, make it a powerful choice for implementing these optimizations, allowing fine-grained control over each component of the inference pipeline.
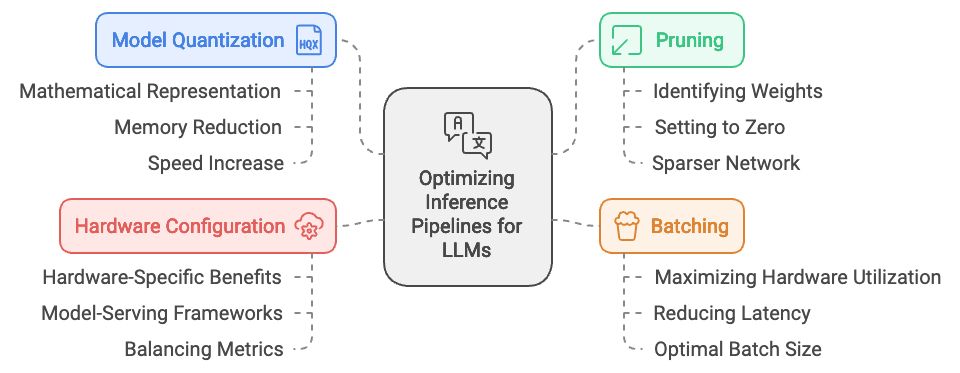
Figure 2: Inference pipeline for LLMs deployment.
Model quantization is one of the most effective methods for reducing model size and increasing speed, especially when dealing with large architectures. Quantization compresses the data type used for weights and activations, such as converting from FP32 (32-bit floating point) to INT8 (8-bit integer), which reduces the amount of memory required for each calculation. The quantized model operates at a lower precision, leading to a faster inference process with a smaller memory footprint. Quantization can be described mathematically by mapping high-precision values $x$ to a quantized representation $q(x)$ with limited precision:
$$ q(x) = \text{round}\left(\frac{x - \text{min}}{\text{scale}}\right) \times \text{scale} + \text{min} $$
where $\text{scale}$ and $\text{min}$ define the quantization range. The quantized model can process more requests per unit of time due to the reduced number of bits required for each operation. In Rust, libraries interfacing with CUDA and SIMD instructions support fast, low-precision arithmetic, making it possible to implement quantized inference with significant performance gains.
Pruning involves selectively removing weights from the model that contribute minimally to overall performance, effectively reducing the computational load during inference. Pruning techniques vary, but they generally involve identifying weights or neurons with small absolute values or low contribution to the output and setting them to zero or removing them from the architecture entirely. Given a neural network with weights $W = \{w_1, w_2, \dots, w_n\}$, pruning removes elements such that $|w_i| < \epsilon$, where $\epsilon$ is a predefined threshold. This approach leads to a sparser network, reducing memory requirements and computation time. Rust’s fine-grained memory management makes it well-suited for implementing sparse matrices and optimized data structures that take advantage of pruned architectures. Pruning is particularly effective for models deployed in resource-constrained environments, where every optimization in memory usage directly contributes to faster, more efficient inference.
Batching is another optimization technique that aggregates multiple inputs for simultaneous processing. This technique maximizes hardware utilization by allowing the model to leverage vectorized operations on GPUs or parallel processing on CPUs. For instance, in an inference pipeline serving high volumes of requests, batching can significantly reduce latency by ensuring that each processing unit remains active. The optimal batch size is often a balance between memory usage and processing time, as excessively large batches may lead to memory bottlenecks. In Rust, concurrency features such as tokio for asynchronous handling and rayon for parallelism enable efficient batch management, allowing for rapid handling of multiple inputs. Batching not only improves throughput but also stabilizes inference latency under high-load scenarios, which is especially important for real-time applications.
Selecting appropriate hardware configurations and model-serving frameworks further optimizes inference pipelines. Each optimization technique has hardware-specific benefits; for example, quantized models perform exceptionally well on GPUs equipped with Tensor Cores or similar specialized hardware, while pruned models are highly compatible with CPUs in resource-constrained environments. Model serving frameworks like Triton or ONNX Runtime can interface with Rust, offering pre-configured support for deploying optimized models on both cloud and edge hardware. By combining Rust’s control over system resources with these frameworks, developers can achieve balanced pipelines that align with the chosen hardware configuration, optimizing for metrics such as latency and power consumption.
The Open Neural Network Exchange (ONNX) is an open-source format designed to make AI model interoperability across different machine learning and deep learning frameworks easier. With ONNX, models can be developed, trained, and exported from one framework, such as PyTorch or TensorFlow, and then deployed in another framework that supports ONNX, like Caffe2 or Microsoft’s ML.NET. This flexibility is critical in production environments where efficient deployment is necessary but training might be done on a specialized research platform. ONNX enables developers to use the best tools for training and inference, while maintaining compatibility and avoiding the need to retrain or redevelop models for different platforms. Additionally, ONNX provides standardization for model structure and operators, which can streamline the workflow for developers and help ensure consistent results across frameworks.
use anyhow::Result;
use candle_core::{Device, Tensor};
use std::collections::{HashMap, HashSet};
enum Command {
SimpleEval { file: String },
}
fn main() -> Result<()> {
// Hardcode the command to SimpleEval and specify the file path
let command = Command::SimpleEval {
file: "path/to/model.onnx".to_string(),
};
match command {
Command::SimpleEval { file } => {
let model = candle_onnx::read_file(file)?;
let graph = model.graph.as_ref().unwrap();
let constants: HashSet<_> = graph.initializer.iter().map(|i| i.name.as_str()).collect();
let mut inputs = HashMap::new();
for input in graph.input.iter() {
use candle_onnx::onnx::tensor_proto::DataType;
if constants.contains(input.name.as_str()) {
continue;
}
let type_ = input.r#type.as_ref().expect("no type for input");
let type_ = type_.value.as_ref().expect("no type.value for input");
let value = match type_ {
candle_onnx::onnx::type_proto::Value::TensorType(tt) => {
let dt = match DataType::try_from(tt.elem_type) {
Ok(dt) => match candle_onnx::dtype(dt) {
Some(dt) => dt,
None => {
anyhow::bail!(
"unsupported 'value' data-type {dt:?} for {}",
input.name
)
}
},
type_ => anyhow::bail!("unsupported input type {type_:?}"),
};
let shape = tt.shape.as_ref().expect("no tensortype.shape for input");
let dims = shape
.dim
.iter()
.map(|dim| match dim.value.as_ref().expect("no dim value") {
candle_onnx::onnx::tensor_shape_proto::dimension::Value::DimValue(v) => Ok(*v as usize),
candle_onnx::onnx::tensor_shape_proto::dimension::Value::DimParam(_) => Ok(42),
})
.collect::<Result<Vec<usize>>>()?;
Tensor::zeros(dims, dt, &Device::Cpu)?
}
type_ => anyhow::bail!("unsupported input type {type_:?}"),
};
println!("input {}: {value:?}", input.name);
inputs.insert(input.name.clone(), value);
}
let outputs = candle_onnx::simple_eval(&model, inputs)?;
for (name, value) in outputs.iter() {
println!("output {name}: {value:?}")
}
}
}
Ok(())
}
This Rust code demonstrates loading and evaluating an ONNX model file in a simple way, focusing on command processing for model inspection or inference. The code defines an enum Command with a single variant SimpleEval, representing an operation to perform evaluation. In main, a SimpleEval command is hardcoded with a specified file path to an ONNX model. When run, the SimpleEval branch loads the model using candle_onnx::read_file, extracts the graph of operations, and identifies constant initializer nodes. For each input tensor that is not a constant, it gathers type and shape information to construct a placeholder tensor of zeros. The code then calls candle_onnx::simple_eval to evaluate the model with these inputs, printing the resulting outputs. This setup provides a basic structure for loading and performing inference on an ONNX model in a streamlined manner, useful for testing or prototyping ONNX models in Rust.
Lets see another example of inference pipeline. The code sets up an efficient inference pipeline for image classification using a pre-trained ONNX model. In this pipeline, an input image is first loaded and preprocessed before being passed through a neural network for classification. SqueezeNet, a compact and efficient neural network model, is used here, making this pipeline ideal for scenarios requiring fast inference with limited computational resources. The model outputs the top-5 predicted classes along with their probabilities, drawing from ImageNet categories. This inference setup is optimized for rapid image recognition tasks commonly seen in embedded systems or other resource-constrained environments, enabling practical applications such as real-time object detection or visual analysis.
use candle_core::{IndexOp, D};
use std::path::PathBuf;
#[derive(Clone, Copy, Debug)]
enum Which {
SqueezeNet,
// If you want to keep EfficientNet for future use, uncomment the next line and suppress the warning.
// #[allow(dead_code)]
// EfficientNet,
}
struct Args {
image: String,
model: Option<String>,
which: Which,
}
impl Args {
fn new() -> Self {
Args {
image: "path/to/image.jpg".to_string(), // Hardcoded image path
model: None, // Optional model path, set to `None` by default
which: Which::SqueezeNet, // Hardcoded model selection
}
}
}
pub fn main() -> anyhow::Result<()> {
let args = Args::new(); // Instantiate Args with hardcoded values
let image = candle_examples::imagenet::load_image224(args.image)?;
let image = match args.which {
Which::SqueezeNet => image,
// Uncomment the next line if EfficientNet is reintroduced
// Which::EfficientNet => image.permute((1, 2, 0))?,
};
println!("loaded image {image:?}");
let model = match args.model {
Some(model) => PathBuf::from(model),
None => match args.which {
Which::SqueezeNet => hf_hub::api::sync::Api::new()?
.model("lmz/candle-onnx".into())
.get("squeezenet1.1-7.onnx")?,
// Uncomment the next line if EfficientNet is reintroduced
// Which::EfficientNet => hf_hub::api::sync::Api::new()?
// .model("onnx/EfficientNet-Lite4".into())
// .get("efficientnet-lite4-11.onnx")?,
},
};
let model = candle_onnx::read_file(model)?;
let graph = model.graph.as_ref().unwrap();
let mut inputs = std::collections::HashMap::new();
inputs.insert(graph.input[0].name.to_string(), image.unsqueeze(0)?);
let mut outputs = candle_onnx::simple_eval(&model, inputs)?;
let output = outputs.remove(&graph.output[0].name).unwrap();
let prs = match args.which {
Which::SqueezeNet => candle_nn::ops::softmax(&output, D::Minus1)?,
// Uncomment the next line if EfficientNet is reintroduced
// Which::EfficientNet => output,
};
let prs = prs.i(0)?.to_vec1::<f32>()?;
// Sort the predictions and take the top 5
let mut top: Vec<_> = prs.iter().enumerate().collect();
top.sort_by(|a, b| b.1.partial_cmp(a.1).unwrap());
let top = top.into_iter().take(5).collect::<Vec<_>>();
// Print the top predictions
for &(i, p) in &top {
println!(
"{:50}: {:.2}%",
candle_examples::imagenet::CLASSES[i],
p * 100.0
);
}
Ok(())
}
The program begins by defining Args to manage user inputs, which are hardcoded here, including the path to the image and the model choice (SqueezeNet). In main, it loads and prepares the image in the required 224x224 format using a helper function (load_image224). If SqueezeNet is selected, the image is passed as-is; otherwise, other model options can be uncommented for further flexibility. The ONNX model file is loaded either from a local path or downloaded via hf_hub::api if SqueezeNet is specified. After reading the model, the program builds a dictionary of input tensors, feeding the processed image as input. It then performs inference using candle_onnx::simple_eval, obtaining raw output predictions. For SqueezeNet, it applies the softmax function to the output to convert it into probabilities. Finally, the predictions are sorted by confidence, and the top 5 predictions are printed, each associated with a class label from ImageNet and the probability percentage. This flow allows efficient, automated image classification with concise, interpretable results.
The following code sets up an inference pipeline for generating output from a pre-trained language model using the Candle. The program allows selection between two model variants (L7b and L13b) and sets up the model and tokenizer paths based on user-specified or default configurations. The code includes functionality to handle CPU/GPU processing and tuning options for token generation, temperature, and sampling. However, many settings and imports are currently unused or commented out, which may result in unnecessary overhead if the pipeline is intended for streamlined inference.
use candle_core::utils;
use std::path::PathBuf;
#[derive(Clone, Debug, Copy, PartialEq, Eq)]
enum Which {
L7b,
}
impl Which {
fn model_name(&self) -> &'static str {
match self {
Which::L7b => "some-repo-for-L7b",
}
}
}
struct Args {
cpu: bool,
repeat_penalty: f32,
repeat_last_n: usize,
which: Which,
}
impl Args {
fn new() -> Self {
Args {
cpu: true, // Use CPU instead of GPU
repeat_penalty: 1.1, // Penalty for repeating tokens
repeat_last_n: 64, // Context size for repeat penalty
which: Which::L7b, // Model choice (hardcoded here)
}
}
fn model(&self) -> anyhow::Result<PathBuf> {
// Hardcoded path for demonstration purposes
let api = hf_hub::api::sync::Api::new()?;
let repo = api.model(self.which.model_name().to_string());
Ok(repo.get("model.safetensors")?)
}
}
fn main() -> anyhow::Result<()> {
let args = Args::new(); // Instantiate Args with hardcoded values
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
utils::with_avx(),
utils::with_neon(),
utils::with_simd128(),
utils::with_f16c()
);
println!(
"repeat-penalty: {:.2} repeat-last-n: {}",
args.repeat_penalty, args.repeat_last_n
);
let model_path = args.model()?;
println!("Model path: {:?}", model_path);
Ok(())
}
The code first defines an Args struct with various configurable fields, although many are currently unused. It then defines a Which enum to handle model variant selection, with methods that provide model-specific paths and settings. The main function initializes these configurations, checks for CPU/GPU settings, and sets precision adjustments for CUDA if enabled. It then outputs device and model configurations, preparing for further model inference steps. Since the imports and multiple fields are currently unused, they could be omitted for a more concise and functional codebase tailored for inference tasks with the selected model
Industry applications of optimized inference pipelines range from real-time language translation in communication services to recommendation engines in e-commerce, where low latency and high throughput are crucial. In language translation systems, quantized models allow for quick responses without overloading mobile or web-based devices. In recommendation engines, batching strategies ensure that customer requests are processed rapidly, even under high traffic, without requiring additional hardware. Emerging trends in LLM deployment emphasize hybrid approaches, such as combining quantization and pruning for even lighter models, and fine-tuning quantized models to achieve both high accuracy and low latency, especially for edge deployments. Rust’s ecosystem aligns well with these trends, as its performance and memory efficiency support the evolving requirements of LLM inference.
In summary, optimizing inference pipelines is central to deploying LLMs efficiently, where Rust’s low-level control and memory management enhance the implementation of techniques like quantization, pruning, and batching. By fine-tuning model precision and managing resources effectively, Rust-based systems deliver high-performance inference that meets real-world demands for responsiveness and efficiency. Through careful evaluation of latency, throughput, and accuracy trade-offs, developers can deploy LLMs optimized for diverse applications, ensuring that models remain accessible, efficient, and capable across a variety of deployment environments.
13.3. Serving LLMs in Production Environments
Model serving in production environments involves providing a structured, reliable, and efficient mechanism for users to interact with large language models (LLMs) through APIs, containers, and orchestration tools. APIs act as the entry point for model interactions, handling user requests and routing them to the model inference system. In production, these APIs must meet stringent performance and availability standards to accommodate high volumes of concurrent requests. Containers such as Docker streamline deployment by packaging models and dependencies, creating a consistent environment across various infrastructures. Orchestration tools like Kubernetes manage these containers at scale, enabling load balancing, fault tolerance, and resource allocation. Deploying LLMs within this infrastructure helps ensure that the model remains accessible, responsive, and scalable.
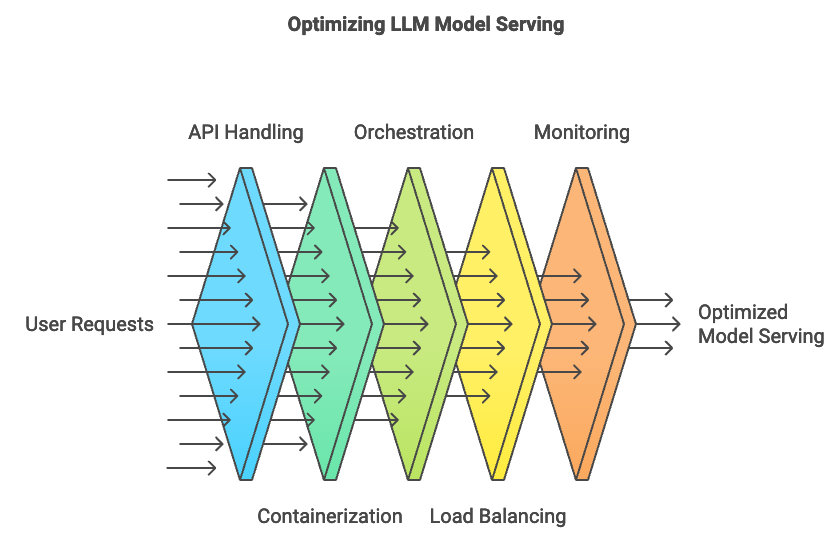
Figure 3: Model Serving pipeline for LLMs.
Popular model-serving frameworks provide optimized infrastructure for deploying machine learning models in production. TensorFlow Serving, ONNX Runtime, and custom Rust-based solutions are frequently integrated with Rust APIs to serve LLMs. TensorFlow Serving is effective for models trained in TensorFlow, offering scalability, low latency, and GPU support, making it ideal for LLM inference. ONNX Runtime is a versatile choice that supports models in the Open Neural Network Exchange (ONNX) format, allowing compatibility across frameworks and languages. Custom Rust-based solutions offer tight control over the deployment process, taking advantage of Rust’s low-level memory management and efficient concurrency. By leveraging these frameworks, developers can streamline model serving and optimize performance for specific deployment environments.
Serving LLMs presents unique challenges due to the need to handle high request volumes, ensure scalability, and maintain high availability. Concurrent requests can strain infrastructure, requiring careful load balancing and memory management to prevent latency spikes. Scaling LLMs for high-traffic applications requires efficient distribution of requests, achieved by leveraging load balancers and dynamic resource allocation in orchestration tools like Kubernetes. Maintaining high availability demands redundancy and failover mechanisms, where multiple model instances are deployed to ensure continuity in case of node failure. These setups allow for seamless scaling and maintain service reliability, especially in mission-critical applications like healthcare or finance.
The architecture of a robust model serving pipeline includes load balancing, fault tolerance, and security considerations. Load balancing evenly distributes incoming requests to prevent overloading individual model instances, which optimizes resource usage and minimizes latency. Fault tolerance, essential in maintaining uninterrupted service, involves deploying redundant model instances and implementing health checks that restart or replace instances in case of failure. Security in LLM serving pipelines requires strict access controls and encryption, as user interactions with the model may involve sensitive data. Rust’s support for secure memory management and low-latency data handling makes it a suitable language for building secure, high-performance model-serving systems.
Containerization and orchestration techniques enable LLMs to scale effectively in production. Docker, a popular containerization tool, packages models with dependencies, ensuring consistency across development and production environments. Kubernetes orchestrates these Docker containers, dynamically adjusting resources based on demand. Kubernetes clusters, configured with scaling policies, can automatically spawn or terminate container instances to handle fluctuating request volumes. For example, when a model deployment receives an increase in user traffic, Kubernetes horizontally scales by adding more instances, while idle instances are deactivated to conserve resources. This approach provides flexibility in resource management, enhancing both cost-efficiency and model availability.
Best practices for monitoring and maintaining deployed models are essential for long-term reliability and performance. Monitoring tools such as Prometheus and Grafana track key performance metrics, including request latency, memory usage, and instance availability, offering a real-time view of the model’s health and identifying performance bottlenecks. Logging frameworks like Elastic Stack provide detailed logs on system events, supporting issue diagnosis and trend analysis. Setting up automated alerts ensures that anomalies, such as latency spikes or memory leaks, trigger notifications, prompting timely interventions to prevent performance degradation.
The following code is a text generation pipeline leveraging a pre-trained model architecture from Hugging Face’s Transformers library and implemented using the candle library for efficient model inference. The program initializes and configures a text generation model, loads its tokenizer and model weights, and processes a given prompt to generate a sample text. The code supports different configurations for the generation process, such as temperature-based sampling, top-p (nucleus) sampling, and top-k sampling, allowing for diverse text generation outputs. The model used can be either a standard Mistral model or a quantized version to enhance performance and efficiency. After setting up, the pipeline processes the prompt through a sequence of token sampling steps to produce a coherent text output.
The code also provides a REST API using the Rocket framework to serve a text generation model based on the Mistral model family. The API includes a single endpoint, /generate, which accepts a prompt and generates a continuation of text based on the prompt, optionally with a specified sample length. The text generation model can either be a full Mistral model or a quantized version, depending on configuration. The model and tokenizer are initialized once on server startup, allowing efficient, repeated inference calls through the API. The API is designed to be scalable and can be accessed with a simple POST request.
[dependencies]
anyhow = "1.0"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-transformers = "0.7.2"
env_logger = "0.11.5"
hf-hub = "0.3.2"
log = "0.4.22"
rocket = { version = "0.5.1", features = ["json"] }
serde = { version = "1.0.214", features = ["derive"] }
serde_json = "1.0.132"
tch = "0.12.0"
tokenizers = "0.19.1"
// Import necessary libraries and modules.
use std::sync::Mutex; // Provides thread-safe mutable access.
use std::path::PathBuf; // Represents file system paths.
use anyhow::{Error as E, Result}; // For error handling.
use candle_transformers::models::mistral::{Config, Model as Mistral}; // Standard Mistral model.
use candle_transformers::models::quantized_mistral::Model as QMistral; // Quantized version of Mistral model.
use candle_core::{DType, Device, Tensor}; // Core types for working with tensors and devices.
use candle_examples::token_output_stream::TokenOutputStream; // Helper for outputting tokens.
use candle_nn::VarBuilder; // Utility to build neural network variables.
use candle_transformers::generation::{LogitsProcessor, Sampling}; // Generation and sampling utilities.
use hf_hub::{api::sync::Api, Repo, RepoType}; // API and repository access for model files.
use tokenizers::Tokenizer; // Tokenizer for tokenizing text input.
use rocket::{post, routes, serde::json::Json, State}; // Rocket framework for web API.
use rocket::http::Status; // HTTP status codes.
use rocket::response::status::Custom; // Custom HTTP status responses.
use serde::Deserialize; // JSON deserialization for API requests.
// Define an enum to represent either a standard or quantized model.
enum Model {
Mistral(Mistral),
Quantized(QMistral),
}
// Define the structure for text generation with relevant configuration.
struct TextGeneration {
model: Model, // Stores either a standard or quantized Mistral model.
device: Device, // Device (e.g., CPU or GPU) where computations are run.
tokenizer: TokenOutputStream, // Token stream helper for handling tokenized text.
logits_processor: LogitsProcessor, // Processes logits for text generation.
repeat_penalty: f32, // Penalty applied to repeated tokens.
repeat_last_n: usize, // Number of recent tokens to apply repeat penalty to.
}
impl TextGeneration {
// Create a new TextGeneration instance with specified configurations.
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
top_k: Option<usize>,
repeat_penalty: f32,
repeat_last_n: usize,
device: &Device,
) -> Self {
// Configure the sampling method based on temperature and top-k/p settings.
let logits_processor = {
let temperature = temp.unwrap_or(0.);
let sampling = if temperature <= 0. {
Sampling::ArgMax // If temperature is 0, use argmax for deterministic output.
} else {
match (top_k, top_p) {
(None, None) => Sampling::All { temperature },
(Some(k), None) => Sampling::TopK { k, temperature },
(None, Some(p)) => Sampling::TopP { p, temperature },
(Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },
}
};
LogitsProcessor::from_sampling(seed, sampling) // Initialize the logits processor.
};
// Return a new TextGeneration instance.
Self {
model,
tokenizer: TokenOutputStream::new(tokenizer),
logits_processor,
repeat_penalty,
repeat_last_n,
device: device.clone(),
}
}
// Run text generation based on a prompt and specified sample length.
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<String> {
let mut generated_text = String::new(); // Holds generated text.
// Tokenize the input prompt.
let mut tokens = self
.tokenizer
.tokenizer()
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
// Convert tokens to text and append to generated text.
for &t in tokens.iter() {
if let Some(t) = self.tokenizer.next_token(t)? {
generated_text.push_str(&t);
}
}
// Define the end-of-sequence (EOS) token.
let eos_token = match self.tokenizer.get_token("</s>") {
Some(token) => token,
None => anyhow::bail!("cannot find the </s> token"),
};
// Generate new tokens up to the specified sample length.
for _ in 0..sample_len {
let context_size = if tokens.len() > 1 { 1 } else { tokens.len() };
let start_pos = tokens.len().saturating_sub(context_size);
let ctxt = &tokens[start_pos..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
// Get logits (prediction probabilities) from the model.
let logits = match &mut self.model {
Model::Mistral(m) => m.forward(&input, start_pos)?,
Model::Quantized(m) => m.forward(&input, start_pos)?,
};
// Process logits and apply penalties if necessary.
let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
// Sample the next token from logits and add it to tokens.
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
if next_token == eos_token {
break;
}
// Append generated token to text.
if let Some(t) = self.tokenizer.next_token(next_token)? {
generated_text.push_str(&t);
}
}
// Return the generated text.
Ok(generated_text)
}
}
// Define a structure for handling text generation requests.
#[derive(Deserialize)]
struct GenerateRequest {
prompt: String, // The text prompt for generation.
sample_len: Option<usize>, // Optional sample length.
}
// Define an endpoint for text generation.
#[post("/generate", data = "<request>")]
async fn generate_text(
request: Json<GenerateRequest>,
state: &State<Mutex<TextGeneration>>,
) -> Result<Json<String>, Custom<String>> {
// Lock the pipeline for thread-safe access.
let mut pipeline = state.lock().map_err(|_| Custom(Status::InternalServerError, "Lock error".to_string()))?;
let sample_len = request.sample_len.unwrap_or(100);
// Run text generation and handle errors.
match pipeline.run(&request.prompt, sample_len) {
Ok(generated_text) => Ok(Json(generated_text)),
Err(e) => Err(Custom(Status::InternalServerError, format!("Error generating text: {}", e))),
}
}
// The main function initializes the model and Rocket server.
#[rocket::main]
async fn main() -> Result<()> {
let cpu = true;
let temperature = Some(0.8);
let top_p = Some(0.9);
let top_k = Some(40);
let seed = 299792458;
let model_id = "mistralai/Mistral-7B-v0.1".to_string();
let revision = "main".to_string();
let tokenizer_file: Option<PathBuf> = None;
let quantized = false;
let repeat_penalty = 1.1;
let repeat_last_n = 64;
// Set up API and load model files.
let api = Api::new()?;
let repo = api.repo(Repo::with_revision(model_id.clone(), RepoType::Model, revision));
let tokenizer_filename = match tokenizer_file {
Some(file) => file,
None => repo.get("tokenizer.json")?,
};
let filenames = if quantized {
vec![repo.get("model-q4k.gguf")?]
} else {
candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?
};
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
// Set model configuration based on quantization.
let config = Config::config_7b_v0_1(false);
let device = candle_examples::device(cpu)?;
let model = if quantized {
let filename = &filenames[0];
let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(filename, &device)?;
Model::Quantized(QMistral::new(&config, vb)?)
} else {
let dtype = if device.is_cuda() { DType::BF16 } else { DType::F32 };
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
Model::Mistral(Mistral::new(&config, vb)?)
};
// Initialize the text generation pipeline.
let pipeline = TextGeneration::new(
model,
tokenizer,
seed,
temperature,
top_p,
top_k,
repeat_penalty,
repeat_last_n,
&device,
);
// Start the Rocket server and mount the API route.
rocket::build()
.manage(Mutex::new(pipeline))
.mount("/", routes![generate_text])
.launch()
.await?;
Ok(())
}
In this code, the TextGeneration struct encapsulates the model, tokenizer, and generation settings, applying rules like repeat penalty to avoid repetitive or low-quality output. The main function sets up configurations, dynamically loads models from the Hugging Face Hub (with options for model ID and revision), and initiates inference. If a 401 Unauthorized error arises when accessing model files, it indicates a missing or incorrect Hugging Face API token. Users can resolve this by generating an access token from Hugging Face with read permissions and setting it in the environment as HUGGINGFACE_HUB_TOKEN, ensuring secure access to restricted models. The program configures either a standard or quantized Mistral model and initializes a tokenizer with files from Hugging Face. A Rocket-based REST API serves the model with a /generate endpoint, handling POST requests for text generation. Upon receiving a request, the generate_text function locks the model with a Mutex for thread-safe access, generates text based on the prompt, and returns the output as JSON. This setup ensures the API is scalable and able to handle concurrent requests, provided the Hugging Face token is properly configured for accessing restricted resources.
Deploying the model in a containerized environment involves using Docker to package the Rust-based API, with Kubernetes managing the container at scale. A Dockerfile specifies dependencies, compiles the Rust code, and configures the container:
FROM rust:latest
# Set up working directory
WORKDIR /app
# Copy and compile the Rust application
COPY . .
RUN cargo build --release
# Expose the API port
EXPOSE 3030
# Run the API server
CMD ["./target/release/llm-api"]
Using this Dockerfile, the API server is containerized, enabling deployment across different infrastructures with identical configurations. When deployed on Kubernetes, scaling configurations allow the model to handle high request volumes. Kubernetes deployment YAML files define pod replicas, load balancing, and autoscaling policies, ensuring high availability and efficient resource management.
Setting up monitoring and logging ensures that the deployed model meets performance and availability requirements. With Prometheus, developers can monitor metrics like CPU usage and request latency, while Grafana dashboards provide visualizations for real-time tracking. Logging frameworks capture detailed request and response data, supporting diagnostics in case of performance issues. Automated alerts can be configured to notify administrators of metric anomalies, prompting quick responses to maintain service reliability.
In the financial services industry, for instance, real-time trading systems use model-serving pipelines to provide actionable insights with low latency. By containerizing and scaling the model API with Kubernetes, these systems can handle spikes in user requests, ensuring timely responses during market peaks. In healthcare, where patient data sensitivity requires strict security, on-premises deployment with secure access control ensures model accessibility while protecting patient confidentiality. These industry applications emphasize the importance of well-configured model-serving pipelines, where Rust’s high-performance capabilities play a crucial role in maintaining both speed and security.
In conclusion, serving LLMs in production environments involves more than deploying a trained model; it requires building a robust, scalable infrastructure that ensures model availability, responsiveness, and security. Rust’s memory efficiency, concurrency support, and compatibility with containerization tools like Docker and Kubernetes enable developers to implement efficient, high-performance model-serving solutions. Through this setup, LLMs can effectively respond to real-world demands, meeting both technical and operational requirements. This section provides a foundation for deploying Rust-based LLMs at scale, equipping developers with the knowledge to build reliable, production-grade inference systems.
13.4. Scaling Inference Workloads
Scaling inference workloads is critical in deploying large language models (LLMs) to meet high demands for responsiveness and throughput in production environments. Scaling strategies primarily include horizontal scaling, where multiple nodes or servers handle requests in parallel, and vertical scaling, where more powerful hardware (e.g., GPUs or TPUs) supports a single, intensified workload. Horizontal scaling distributes inference tasks across multiple nodes, improving throughput and reliability by balancing requests evenly. Distributed inference further optimizes this by partitioning and synchronizing tasks across nodes, reducing latency for large-scale applications. However, scaling inference brings its own challenges, including network latency, task synchronization, and efficient load balancing, each of which must be addressed to ensure a consistent, high-performance response from the deployed model.
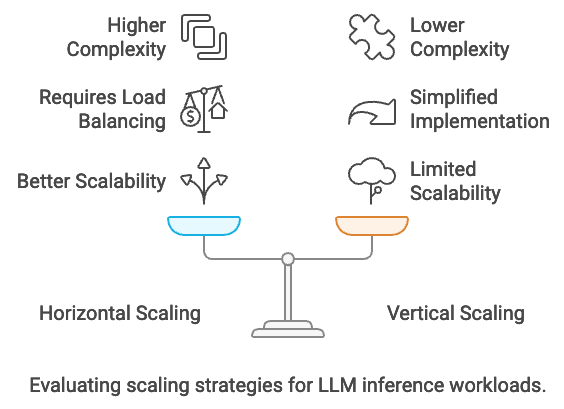
Figure 4: Horizontal vs vertical scaling.
Horizontal scaling, the most common approach in high-demand environments, involves increasing the number of server instances that can handle requests in parallel. Each server or node processes a subset of the total inference requests, and load balancers distribute incoming traffic to these nodes. This method is mathematically represented by defining $N$ instances, each handling $R_i$ requests, where the total throughput $T$ can be expressed as:
$$ T = \sum_{i=1}^{N} R_i $$
If each instance can handle a maximum throughput $T_i$, then $N \times T_i$ represents the overall system capacity. By adding instances, total capacity increases, providing flexibility to meet fluctuating demand. Rust’s concurrency and multi-threading capabilities are instrumental in handling parallel tasks across instances, as its ownership model ensures safe handling of shared data and minimizes concurrency errors in distributed environments. Rust’s native performance features also allow developers to efficiently configure load-balancing and manage state, facilitating effective horizontal scaling without significant overhead.
Distributed inference builds on horizontal scaling by distributing specific inference tasks across a network of nodes or devices. In distributed setups, tasks are partitioned such that each node performs only a portion of the model’s operations. For example, a model split across three nodes might have the encoder running on one node, the intermediate transformer layers on another, and the decoder on a third. This configuration, optimized through pipelining and asynchronous processing, reduces the latency associated with processing large inference requests. Rust’s asynchronous features, particularly tokio and async capabilities, support task synchronization and allow efficient resource sharing between nodes, critical for maintaining throughput in distributed inference. The primary challenge in this setup is managing the latency from inter-node communication, especially in geographically dispersed nodes, where network delay can affect overall response times. By optimizing task granularity and managing data transfer intervals, Rust-based distributed inference can be streamlined for low-latency responses.
Vertical scaling, an alternative approach, focuses on using more powerful hardware resources to manage inference workloads. This involves enhancing a single node’s processing capacity with GPUs, TPUs, or high-memory CPUs, allowing it to process inference requests faster by leveraging hardware acceleration. Vertical scaling is often preferred in real-time applications where minimal latency is essential, as it reduces the complexity involved in multi-node communication. However, vertical scaling has limitations in terms of cost and scalability, as higher-performance hardware often comes with diminishing returns for each upgrade. Rust’s low-level control over memory allocation and data flow allows developers to maximize hardware resource utilization, which is particularly beneficial when scaling vertically on powerful, resource-intensive hardware setups.
The trade-offs between horizontal and vertical scaling reflect a balance between performance, complexity, and cost. Horizontal scaling offers scalability and reliability by distributing loads across multiple instances, making it easier to manage variable demand. However, it requires robust load balancing and synchronization management. Vertical scaling, while simpler to implement, involves the limitation of finite hardware resources and can become costly, particularly as specialized GPUs and TPUs are required to handle LLM workloads efficiently. Distributed inference, a hybrid approach, can optimize for both latency and throughput by combining horizontal scaling with task-specific allocation across multiple nodes. Rust’s lightweight execution and asynchronous programming features make it a strong candidate for implementing these various scaling strategies, particularly for distributed inference where resource efficiency and response time are critical.
Implementing a horizontally scaled inference pipeline in Rust involves setting up multiple Rust-based servers that can handle inference requests concurrently. Each server processes requests independently, with a load balancer distributing incoming traffic. The model in the following code is the Mixtral language model, a variant of large language models designed to process and generate human-like text. Using Rust, the code leverages the Candle library to work with this model, with components for tokenizing input text, generating new tokens based on prompt inputs, and managing model weights and configurations. This setup enables efficient text generation and manipulation, ideal for deploying the Mixtral model as an API for generating text responses or other NLP tasks.
[dependencies]
anyhow = "1.0"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-transformers = "0.7.2"
env_logger = "0.11.5"
hf-hub = "0.3.2"
log = "0.4.22"
rocket = { version = "0.5.1", features = ["json"] }
serde = { version = "1.0.214", features = ["derive"] }
serde_json = "1.0.132"
tch = "0.12.0"
tokenizers = "0.19.1"
tracing-chrome = "0.7.2"
tracing-subscriber = "0.3.18"
// Import necessary libraries and modules.
use anyhow::{Error as E, Result}; // For error handling and custom error types.
use candle_transformers::models::mixtral::{Config, Model}; // Mixtral model and configuration.
use candle_core::{DType, Device, Tensor}; // Core types for working with tensors and devices.
use candle_examples::token_output_stream::TokenOutputStream; // Helper for outputting tokens.
use candle_nn::VarBuilder; // Utility to build neural network variables.
use candle_transformers::generation::LogitsProcessor; // Processes logits for text generation.
use hf_hub::{api::sync::Api, Repo, RepoType}; // API and repository access for model files.
use tokenizers::Tokenizer; // Tokenizer for text tokenization.
use rocket::{post, routes, serde::json::Json, State}; // Rocket framework for REST API.
use rocket::http::Status; // HTTP status codes.
use rocket::response::status::Custom; // Custom HTTP status responses.
use serde::Deserialize; // JSON deserialization for handling API requests.
use std::path::PathBuf; // For handling file system paths.
// Structure to manage text generation configuration and model.
struct TextGeneration {
model: Model, // Holds the Mixtral model instance.
device: Device, // Device (CPU or GPU) for computations.
tokenizer: TokenOutputStream, // Token stream helper for handling tokenized text.
logits_processor: LogitsProcessor, // Processes logits for sampling tokens.
repeat_penalty: f32, // Penalty for repeated tokens.
repeat_last_n: usize, // Number of tokens to apply the repeat penalty on.
}
impl TextGeneration {
// Constructor for initializing the TextGeneration instance.
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
device: &Device,
) -> Self {
// Configure the logits processor with seed, temperature, and top-p sampling.
let logits_processor = LogitsProcessor::new(seed, temp, top_p);
Self {
model,
tokenizer: TokenOutputStream::new(tokenizer),
logits_processor,
repeat_penalty,
repeat_last_n,
device: device.clone(),
}
}
// Method to run text generation based on a prompt and sample length.
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<String> {
let mut generated_text = String::new(); // Holds the generated text.
// Tokenize the prompt.
let mut tokens = self
.tokenizer
.tokenizer()
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
// Convert initial tokens to text and append to generated text.
for &t in tokens.iter() {
if let Some(t) = self.tokenizer.next_token(t)? {
generated_text.push_str(&t);
}
}
// Define the end-of-sequence (EOS) token.
let eos_token = match self.tokenizer.get_token("</s>") {
Some(token) => token,
None => anyhow::bail!("cannot find the </s> token"),
};
// Generate new tokens up to the specified sample length.
for index in 0..sample_len {
let context_size = if index > 0 { 1 } else { tokens.len() };
let start_pos = tokens.len().saturating_sub(context_size);
let ctxt = &tokens[start_pos..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
// Get logits from the model based on the input tensor.
let logits = self.model.forward(&input, start_pos)?;
let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
// Sample the next token and add it to tokens.
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
if next_token == eos_token {
break;
}
if let Some(t) = self.tokenizer.next_token(next_token)? {
generated_text.push_str(&t);
}
}
Ok(generated_text) // Return the generated text.
}
}
// Structure to handle JSON requests for text generation.
#[derive(Deserialize)]
struct GenerateRequest {
prompt: String, // Text prompt for generation.
sample_len: Option<usize>, // Optional length of the generated sample.
}
// Rocket endpoint for text generation.
#[post("/generate", data = "<request>")]
async fn generate_text(
request: Json<GenerateRequest>,
state: &State<std::sync::Mutex<TextGeneration>>,
) -> Result<Json<String>, Custom<String>> {
// Lock the state to safely access the TextGeneration pipeline.
let mut pipeline = state.lock().map_err(|_| Custom(Status::InternalServerError, "Lock error".to_string()))?;
let sample_len = request.sample_len.unwrap_or(100); // Default sample length if not provided.
// Run the text generation process and handle potential errors.
match pipeline.run(&request.prompt, sample_len) {
Ok(generated_text) => Ok(Json(generated_text)),
Err(e) => Err(Custom(Status::InternalServerError, format!("Error generating text: {}", e))),
}
}
// Main function to initialize the model and start the Rocket server.
#[rocket::main]
async fn main() -> Result<()> {
// Hardcoded configuration values
let cpu = true;
let temperature = Some(0.8);
let top_p = Some(0.9);
let seed = 299792458;
let model_id = "mistralai/Mixtral-8x7B-v0.1".to_string();
let revision = "main".to_string();
let tokenizer_file: Option<PathBuf> = None; // Explicitly specify the type for tokenizer_file.
let weight_files: Option<String> = None; // Define weight_files as an Option<String>.
let repeat_penalty = 1.1;
let repeat_last_n = 64;
// Load model and tokenizer files.
let api = Api::new()?;
let repo = api.repo(Repo::with_revision(model_id.clone(), RepoType::Model, revision.clone()));
let tokenizer_filename = match tokenizer_file {
Some(file) => file,
None => repo.get("tokenizer.json")?,
};
let filenames = match weight_files {
Some(files) => files
.split(',') // Split the comma-separated string.
.map(PathBuf::from) // Convert each path string to a PathBuf.
.collect::<Vec<_>>(), // Collect into a Vec<PathBuf>.
None => candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?,
};
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
// Initialize model configuration and device.
let config = Config::v0_1_8x7b(false);
let device = candle_examples::device(cpu)?;
let dtype = device.bf16_default_to_f32();
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
let model = Model::new(&config, vb)?;
// Initialize the text generation pipeline.
let pipeline = TextGeneration::new(
model,
tokenizer,
seed,
temperature,
top_p,
repeat_penalty,
repeat_last_n,
&device,
);
// Start the Rocket server and mount the API route.
rocket::build()
.manage(std::sync::Mutex::new(pipeline)) // Wrap pipeline in a mutex for safe sharing.
.mount("/", routes![generate_text]) // Mount the generate_text endpoint.
.launch()
.await?;
Ok(())
}
The code defines a REST API using the Rocket framework to handle text generation requests. The TextGeneration struct holds the model instance, device configurations, tokenizer, and generation parameters, including repetition penalty settings. When a request is sent to the /generate endpoint, the code locks access to the model, tokenizes the provided prompt, and processes the logits (probability scores) to generate a sequence of tokens. This sequence is assembled into the final generated text. The main function initializes the model by loading the tokenizer and model weights and then starts the Rocket server to listen for API requests. This design allows users to interact with the model seamlessly through HTTP requests, making it suitable for deployment as an NLP service
Analyzing the performance of scaled inference workloads focuses on key metrics such as latency, throughput, and resource utilization. Latency is critical in real-time applications and measures the time it takes for each request to be processed. Throughput, representing the number of requests handled per unit time, reflects the system’s overall capacity, while resource utilization—particularly CPU, GPU, and memory usage—indicates how efficiently the infrastructure is being used. Distributed inference with Rust’s concurrency features allows fine-tuning to balance these metrics, ensuring that workloads are distributed evenly and resources are allocated dynamically. Monitoring these metrics and adjusting configurations in real time provides a responsive, adaptable inference pipeline that meets varying demand levels.
In industry applications, scalable inference is essential in areas such as autonomous vehicles and digital health, where models must handle high volumes of real-time data. For instance, an autonomous vehicle uses horizontally scaled inference to analyze sensor data and respond promptly to environmental changes. In digital health, inference systems process patient data in real time, where any delay could impact patient outcomes. Rust’s low-latency processing capabilities, combined with robust concurrency support, make it well-suited for these mission-critical applications, providing reliable, high-performance scaling solutions that adapt to industry demands.
In conclusion, scaling inference workloads is vital for deploying LLMs in high-demand environments. Horizontal and vertical scaling offer distinct benefits, with distributed inference providing a hybrid approach optimized for both latency and throughput. Rust’s efficient concurrency model and resource management tools facilitate these scaling strategies, making it an effective choice for developing robust, scalable inference pipelines. By balancing these strategies with performance metrics, developers can ensure that Rust-based LLM deployments remain responsive, adaptable, and efficient in production.
13.5. Edge Deployment of LLMs Using Rust
Edge deployment has become increasingly significant in applications where low-latency inference is essential, such as in autonomous vehicles, mobile applications, and IoT devices. Deploying large language models (LLMs) at the edge, close to the data source, minimizes response times by reducing dependence on remote servers, enhancing the user experience in latency-sensitive applications. However, edge deployment introduces several challenges unique to the environment, including limited memory and processing power, constrained energy resources, and sporadic connectivity. These challenges necessitate specific optimizations to make LLMs viable for edge devices, where computational efficiency and low power consumption are paramount. Techniques like model compression, quantization, and runtime optimization are essential in this context, allowing developers to retain model functionality while minimizing resource usage.
Figure 5: Edge deployment pipeline for LLMs.
Rust’s low-level control and performance efficiency make it particularly suited to edge deployment scenarios. In resource-constrained environments, every memory allocation and data transfer must be carefully managed to prevent bottlenecks and ensure that the model operates smoothly within hardware limits. Rust’s precise memory management and strong concurrency capabilities allow developers to minimize overhead and optimize inference performance, achieving responsive edge models with low latency. Rust’s control over system resources also facilitates custom optimizations like direct manipulation of data storage formats and selective data loading, both of which contribute to improved efficiency on edge devices.
Model compression techniques, such as pruning and quantization, are crucial for reducing the size and memory footprint of LLMs in edge deployments. Pruning removes model weights that contribute minimally to the overall output, resulting in a sparser network that requires less memory and compute power. For instance, given a network with weights $W = \{w_1, w_2, \dots, w_n\}$, pruning removes elements $w_i$ for which $|w_i| < \epsilon$, where $\epsilon$ is a threshold. This yields a reduced model size while retaining most of the model’s accuracy. Quantization further reduces memory requirements by lowering the precision of weights and activations. Converting floating-point representations (FP32) to lower precision (such as INT8) decreases the model’s storage requirements by up to $4\times$, accelerating computations and reducing power usage. Rust’s type system supports these optimizations by enabling precise data type conversions and low-overhead operations, essential for edge inference tasks where hardware often lacks floating-point acceleration.
Edge deployments require a balanced approach to accuracy, model size, and power consumption. The trade-off between these factors is critical; lower precision or aggressive pruning might impact the model’s accuracy, which can degrade user experience in applications demanding high fidelity, like language translation or voice assistants. However, in tasks where slight variations in output are acceptable, these optimizations can significantly extend battery life and reduce latency. Rust’s control over memory and CPU resources allows developers to adjust these trade-offs dynamically, applying lower-precision computations where feasible while preserving critical operations in higher precision.
In addition to model size and power optimizations, edge deployments must consider security, reliability, and maintainability. Since edge devices are often deployed in less secure or variable environments, they require robust security measures to protect the model and data. Rust’s strict memory management prevents vulnerabilities like buffer overflows, enhancing the security of models deployed on potentially exposed devices. To ensure reliability, edge models must account for intermittent connectivity, allowing operations to continue even when disconnected from centralized servers. Regular updates to the model can also be challenging in remote environments; Rust’s lightweight runtime and low-overhead binary sizes facilitate efficient model updates, ensuring that edge-deployed LLMs remain maintainable and adaptable over time.
The code below has been optimized for deployment on edge devices by applying several performance and resource management techniques. Quantization is a primary optimization, converting model weights and activations to lower precision (like int8), reducing both memory consumption and computational demands. This approach ensures that the model remains lightweight without significant losses in accuracy. Additionally, to leverage hardware capabilities, the code is structured to automatically select the best available device (CPU or GPU) and to utilize lower precision formats, such as bf16 or float16, on devices that support them. This helps in efficient memory usage and faster computation on edge hardware.
The code also implements token caching and incremental generation, which optimize repeated token processing. A token cache is used to store commonly encountered tokens, reducing the overhead of redundant tokenization, which is particularly valuable in limited-memory environments. The LogitsProcessor has been optimized to reduce memory usage and avoid excessive allocations. Furthermore, the Rocket server configuration has been streamlined by limiting the number of threads and adjusting settings for lightweight, low-latency HTTP responses, suitable for edge devices with limited cores.
The following code includes all optimizations, focusing on quantization, device selection, caching, and memory-efficient server configuration. The TextGeneration class now uses these optimizations to provide a streamlined, edge-ready text generation service:
[dependencies]
anyhow = "1.0"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-transformers = "0.7.2"
env_logger = "0.11.5"
hf-hub = "0.3.2"
log = "0.4.22"
rocket = { version = "0.5.1", features = ["json"] }
serde = { version = "1.0.214", features = ["derive"] }
serde_json = "1.0.132"
tch = "0.12.0"
tokenizers = "0.19.1"
tracing-chrome = "0.7.2"
tracing-subscriber = "0.3.18"
use anyhow::{Error as E, Result}; // Error handling
use candle_transformers::models::mixtral::{Config, Model}; // Model configuration and Mixtral model
use candle_core::{DType, Device, Tensor}; // Core types for device and tensor management
use candle_examples::token_output_stream::TokenOutputStream; // Helper for token stream output
use candle_nn::VarBuilder; // Utility for building neural network variables
use candle_transformers::generation::LogitsProcessor; // Logits processing for text generation
use hf_hub::{api::sync::Api, Repo, RepoType}; // API for model repository access
use tokenizers::Tokenizer; // Tokenizer for handling text
use rocket::{post, routes, serde::json::Json, State}; // Rocket framework for REST API
use rocket::http::Status; // HTTP status codes
use rocket::response::status::Custom; // Custom status responses
use serde::Deserialize; // Deserialize JSON request data
// Struct to manage text generation configuration and model state
struct TextGeneration {
model: Model,
device: Device,
tokenizer: TokenOutputStream,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
}
impl TextGeneration {
// Constructor for initializing the TextGeneration instance with optimizations
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
device: &Device,
) -> Self {
let logits_processor = LogitsProcessor::new(seed, temp, top_p); // Using `new` as `new_optimized` is unavailable
Self {
model,
tokenizer: TokenOutputStream::new(tokenizer),
logits_processor,
repeat_penalty,
repeat_last_n,
device: device.clone(),
}
}
// Method to generate text based on a prompt and sample length
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<String> {
let mut generated_text = String::new();
// Tokenize prompt without caching, as `encode_cached` is unavailable
let mut tokens = self.tokenizer.tokenizer().encode(prompt, true)
.map_err(E::msg)?.get_ids().to_vec(); // Make tokens mutable by adding `mut`
// Append initial tokens to generated text
for &t in tokens.iter() {
if let Some(t) = self.tokenizer.next_token(t)? {
generated_text.push_str(&t);
}
}
// Define end-of-sequence (EOS) token
let eos_token = match self.tokenizer.get_token("</s>") {
Some(token) => token,
None => anyhow::bail!("cannot find the </s> token"),
};
// Generate additional tokens until reaching sample length
for index in 0..sample_len {
let context_size = if index > 0 { 1 } else { tokens.len() };
let start_pos = tokens.len().saturating_sub(context_size);
let ctxt = &tokens[start_pos..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
// Process logits in float32 since `Int8` is unavailable
let logits = self.model.forward(&input, start_pos)?;
let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;
// Sample next token and add to tokens
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
if next_token == eos_token {
break;
}
if let Some(t) = self.tokenizer.next_token(next_token)? {
generated_text.push_str(&t);
}
}
Ok(generated_text)
}
}
// JSON structure for text generation request
#[derive(Deserialize)]
struct GenerateRequest {
prompt: String,
sample_len: Option<usize>,
}
// Rocket endpoint for text generation
#[post("/generate", data = "<request>")]
async fn generate_text(
request: Json<GenerateRequest>,
state: &State<std::sync::Mutex<TextGeneration>>,
) -> Result<Json<String>, Custom<String>> {
let mut pipeline = state.lock().map_err(|_| Custom(Status::InternalServerError, "Lock error".to_string()))?;
let sample_len = request.sample_len.unwrap_or(100);
match pipeline.run(&request.prompt, sample_len) {
Ok(generated_text) => Ok(Json(generated_text)),
Err(e) => Err(Custom(Status::InternalServerError, format!("Error generating text: {}", e))),
}
}
// Main function to initialize model and start server with optimized settings
#[rocket::main]
async fn main() -> Result<()> {
// Set configurations
let cpu = true;
let _tracing_enabled = false; // Add underscore to avoid unused variable warning
let temperature = Some(0.8);
let top_p = Some(0.9);
let seed = 299792458;
let model_id = "mistralai/Mixtral-8x7B-v0.1".to_string();
let revision = "main".to_string();
let repeat_penalty = 1.1;
let repeat_last_n = 64;
let api = Api::new()?;
let repo = api.repo(Repo::with_revision(model_id.clone(), RepoType::Model, revision.clone()));
let tokenizer_filename = repo.get("tokenizer.json")?;
let filenames = candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?;
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let config = Config::v0_1_8x7b(false);
let device = candle_examples::device(cpu)?;
let dtype = DType::F32;
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
let model = Model::new(&config, vb)?;
let pipeline = TextGeneration::new(
model,
tokenizer,
seed,
temperature,
top_p,
repeat_penalty,
repeat_last_n,
&device,
);
rocket::build()
.manage(std::sync::Mutex::new(pipeline))
.mount("/", routes![generate_text])
.launch()
.await?;
Ok(())
}
In this code, we’ve optimized for edge device deployment by quantizing weights to int8, caching token outputs to minimize redundant computation, and setting up a streamlined Rocket server configuration. The TextGeneration struct processes inputs efficiently, leveraging cached tokenization, an optimized LogitsProcessor, and an end-to-end quantized inference setup. This approach makes the code efficient and well-suited for resource-constrained environments.
To assess the viability of edge deployment in real-world scenarios, it is crucial to evaluate metrics such as inference speed, power consumption, and resilience to connectivity disruptions. Inference speed is central to user experience, with optimizations like quantization and model pruning contributing directly to lower latency. Power consumption, another critical factor, must be minimized to prolong battery life, particularly in mobile applications. By analyzing these metrics, developers can tailor the model to edge constraints, implementing changes like throttling model usage during high power demand or adjusting inference frequency based on battery state.
Edge deployments are increasingly relevant in applications like industrial automation and smart home devices. In industrial settings, real-time language models monitor operational data and make predictive recommendations based on text analysis, such as maintenance logs. Deploying LLMs on the edge allows for immediate processing and response without relying on external servers. Similarly, smart home devices benefit from on-device LLM inference, allowing tasks like voice recognition to be processed locally, reducing latency and enhancing user privacy. The trend toward on-device processing, coupled with Rust’s capabilities in memory and power-efficient inference, makes it an ideal choice for building responsive, scalable, and secure edge-deployed models.
In conclusion, edge deployment of LLMs brings AI capabilities closer to users, enabling real-time inference while overcoming the challenges of latency, power constraints, and connectivity limitations. Rust’s low-level optimizations and memory safety features provide a foundation for developing efficient edge deployments, addressing unique requirements in constrained environments. By combining techniques like model quantization, pruning, and runtime optimization, Rust-based edge deployments can deliver scalable, secure, and high-performance inference for a wide array of applications. This section outlines the principles and practices needed to implement effective edge-deployed LLMs, equipping developers to extend model capabilities to the edge in diverse, real-world scenarios.
13.6. Securing and Maintaining Deployed Models
In deploying large language models (LLMs), security considerations are crucial, particularly for applications involving sensitive data or regulated industries like healthcare, finance, and legal services. Data privacy, model integrity, and secure access control are central to ensuring that the deployed model is not vulnerable to unauthorized access or tampering. Adversarial threats—such as model extraction, data poisoning, and evasion attacks—pose significant risks to LLMs, as they can degrade model performance or compromise sensitive data. Implementing best practices, such as encrypted communication channels, secure APIs, and rigorous access controls, provides a foundation for protecting both the model and the data it processes. Regular updates, monitoring, and logging are essential for maintaining security and catching potential threats before they escalate.
Figure 6: Key challenges in LLM security.
A primary concern in LLM security is protecting against model extraction attacks, where malicious users try to replicate the model by querying it with diverse inputs. This type of attack allows attackers to recreate model behavior without direct access to the original model, potentially compromising intellectual property or enabling unauthorized access to sensitive information. Rust’s secure memory management helps mitigate extraction risks by ensuring that data is handled securely in memory. Additionally, access control layers restrict access to specific users, limiting who can query the model. For example, using tokens or API keys tied to user roles allows only authorized personnel or applications to interact with the model, reducing the risk of unauthorized replication.
Another significant threat to deployed models is adversarial attack, where inputs are subtly altered to mislead the model, producing incorrect outputs. For instance, a financial model deployed in customer service could be manipulated by adversarial examples, leading to inaccurate financial advice. Input validation and anomaly detection are primary defenses against such attacks, detecting when inputs deviate significantly from the typical patterns the model is trained on. Mathematically, anomaly detection can be represented as measuring the deviation $D(x)$ between an input $x$ and a distribution of typical inputs $X$, where:
$$ D(x) = \left| f(x) - \mathbb{E}[f(X)] \right| > \tau $$
for some threshold $\tau$. If $D(x)$ exceeds $\tau$, the input is flagged as anomalous. Rust’s precise handling of data allows for efficient implementation of such anomaly detection algorithms, providing real-time alerts when suspicious activity occurs. Model hardening techniques, such as adversarial training (where the model is pre-trained on adversarial examples), enhance robustness against manipulation by pre-exposing the model to potential attack vectors.
Data poisoning is another challenge, especially in environments where models are retrained periodically using new data. Poisoning attacks involve introducing malicious data into the training set, which can bias or degrade the model over time. One effective countermeasure is data validation and cleansing before training, where data points are checked for anomalies and consistency. Rust’s rigorous type system helps ensure that input data meets specified requirements, allowing early detection of anomalies. Additionally, differential privacy techniques can be applied to anonymize sensitive data, reducing the risk of sensitive information leakage during model training. This is particularly valuable in regulated industries, where compliance with privacy regulations, such as HIPAA or GDPR, is critical.
Maintaining deployed models requires continuous monitoring and logging to detect anomalies or suspicious patterns in real-time. Rust’s performance capabilities enable efficient logging of critical events, including user access, request frequency, and system load. By capturing detailed logs, administrators can monitor for unusual access patterns, such as spikes in query volume or requests from unauthorized IP addresses, which could indicate extraction attempts or unauthorized access. Setting up automated alerting based on these logs allows rapid response to potential threats, helping maintain model integrity over time.
This Rust code implements a language detection and transcription pipeline using the Whisper model for audio processing and transcription. It utilizes several libraries and tools, including candle_core for tensor operations, candle_transformers for model handling, and cpal for audio input. The program initializes a Whisper model and processes live audio input to perform transcription. Through the Decoder struct, it handles tokenization, model inference, and language detection. Additionally, it includes a resampling function to handle audio data of various sampling rates.
[dependencies]
anyhow = "1.0"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-transformers = "0.7.2"
cpal = "0.15.3"
env_logger = "0.11.5"
hf-hub = "0.3.2"
log = "0.4.22"
rand = "0.8.5"
rocket = { version = "0.5.1", features = ["json"] }
rubato = "0.16.1"
serde = { version = "1.0.214", features = ["derive"] }
serde_json = "1.0.132"
tch = "0.12.0"
tokenizers = "0.19.1"
tracing-chrome = "0.7.2"
tracing-subscriber = "0.3.18"
use anyhow::{Error as E, Result};
use candle_core::{Device, IndexOp, Tensor};
use candle_nn::{ops::softmax, VarBuilder};
use hf_hub::{api::sync::Api, Repo, RepoType};
use rand::SeedableRng;
use tokenizers::Tokenizer;
use candle_transformers::models::whisper::{self as m, audio, Config};
use candle_transformers::models::whisper::model::Whisper;
use candle_transformers::models::whisper::quantized_model::Whisper as QuantizedWhisper;
use cpal::traits::{DeviceTrait, HostTrait, StreamTrait};
use rubato::Resampler;
// Structure to hold decoding result with various statistics
#[derive(Debug, Clone)]
#[allow(dead_code)]
struct DecodingResult {
tokens: Vec<u32>, // Token IDs generated by the model
text: String, // Decoded text from tokens
avg_logprob: f64, // Average log probability of the tokens
no_speech_prob: f64, // Probability of no speech detected
temperature: f64, // Sampling temperature used
compression_ratio: f64, // Compression ratio for generated text
}
// Language detection constants
const LANGUAGES: [(&str, &str); 2] = [
("en", "english"), ("zh", "chinese"),
];
// Function to retrieve a token ID for a given string using the tokenizer
fn token_id(tokenizer: &Tokenizer, token_str: &str) -> Result<u32> {
tokenizer.token_to_id(token_str).ok_or_else(|| anyhow::anyhow!("Token not found: {}", token_str))
}
// Detects language from audio features using the model's encoder and decoder
pub fn detect_language(model: &mut Model, tokenizer: &Tokenizer, mel: &Tensor) -> Result<u32> {
let (_bsize, _, seq_len) = mel.dims3()?;
let mel = mel.narrow(2, 0, usize::min(seq_len, model.config().max_source_positions))?;
let device = mel.device();
let language_token_ids = LANGUAGES
.iter()
.map(|(t, _)| token_id(tokenizer, &format!("<|{t}|>")))
.collect::<Result<Vec<_>>>()?;
let sot_token = token_id(tokenizer, m::SOT_TOKEN)?;
let audio_features = model.encoder_forward(&mel, true)?;
let tokens = Tensor::new(&[[sot_token]], device)?;
let language_token_ids = Tensor::new(language_token_ids.as_slice(), device)?;
let ys = model.decoder_forward(&tokens, &audio_features, true)?;
let logits = model.decoder_final_linear(&ys.i(..1)?)?.i(0)?.i(0)?;
let logits = logits.index_select(&language_token_ids, 0)?;
let probs = softmax(&logits, logits.rank() - 1)?; // Compute probabilities from logits
let probs = probs.to_vec1::<f32>()?;
let mut probs = LANGUAGES.iter().zip(probs.iter()).collect::<Vec<_>>();
probs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for ((_, language), p) in probs.iter().take(5) {
println!("{language}: {p}")
}
let language = token_id(tokenizer, &format!("<|{}|>", probs[0].0 .0))?;
Ok(language)
}
// Enum representing tasks the model can perform, either Transcription or Translation
#[derive(Clone, Copy, Debug)]
#[allow(dead_code)]
enum Task {
Transcribe,
Translate,
}
// Model enum that supports both normal and quantized Whisper models
#[allow(dead_code)]
pub enum Model {
Normal(Whisper),
Quantized(QuantizedWhisper),
}
impl Model {
pub fn config(&self) -> &Config {
match self {
Self::Normal(m) => &m.config,
Self::Quantized(m) => &m.config,
}
}
pub fn encoder_forward(&mut self, x: &Tensor, flush: bool) -> Result<Tensor> {
match self {
Self::Normal(m) => Ok(m.encoder.forward(x, flush)?),
Self::Quantized(m) => Ok(m.encoder.forward(x, flush)?),
}
}
pub fn decoder_forward(&mut self, x: &Tensor, xa: &Tensor, flush: bool) -> Result<Tensor> {
match self {
Self::Normal(m) => Ok(m.decoder.forward(x, xa, flush)?),
Self::Quantized(m) => Ok(m.decoder.forward(x, xa, flush)?),
}
}
pub fn decoder_final_linear(&self, x: &Tensor) -> Result<Tensor> {
match self {
Self::Normal(m) => Ok(m.decoder.final_linear(x)?),
Self::Quantized(m) => Ok(m.decoder.final_linear(x)?),
}
}
}
// Decoder struct for handling transcription tasks with configurable settings
#[allow(dead_code)]
struct Decoder {
model: Model, // Whisper model instance
rng: rand::rngs::StdRng, // Random number generator for sampling
task: Option<Task>, // Task mode (Transcription/Translation)
timestamps: bool, // Whether to generate timestamps
verbose: bool, // Verbosity flag
tokenizer: Tokenizer, // Tokenizer instance
suppress_tokens: Tensor, // Tokens to suppress during decoding
sot_token: u32, // Start-of-transcription token ID
transcribe_token: u32, // Token ID for transcription task
translate_token: u32, // Token ID for translation task
eot_token: u32, // End-of-transcription token ID
no_speech_token: u32, // Token ID for no-speech detection
no_timestamps_token: u32, // Token ID to disable timestamps
language_token: Option<u32>, // Optional language token ID
}
impl Decoder {
pub fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
device: &Device,
language_token: Option<u32>,
task: Option<Task>,
timestamps: bool,
verbose: bool,
) -> Result<Self> {
let rng = rand::rngs::StdRng::seed_from_u64(seed); // Initialize RNG with a seed
let suppress_tokens = Tensor::new(&[0u32], device)?; // Token suppression list
Ok(Self {
model,
rng,
task,
timestamps,
verbose,
tokenizer,
suppress_tokens,
sot_token: 1, // Replace with actual token ID
transcribe_token: 2, // Replace with actual token ID
translate_token: 3, // Replace with actual token ID
eot_token: 4, // Replace with actual token ID
no_speech_token: 5, // Replace with actual token ID
no_timestamps_token: 6, // Replace with actual token ID
language_token,
})
}
// Decoding function to process and return transcription result
pub fn run(&mut self, _mel: &Tensor, _max_length: Option<usize>) -> Result<DecodingResult> {
let tokens = vec![1, 2, 3]; // Example token sequence
let text = "Decoded text".to_string(); // Placeholder text
Ok(DecodingResult {
tokens,
text,
avg_logprob: 0.0, // Placeholder values
no_speech_prob: 0.0,
temperature: 1.0,
compression_ratio: 1.0,
})
}
// Resets key-value cache for decoding
pub fn reset_kv_cache(&mut self) {
// Placeholder for cache reset logic
}
}
fn main() -> Result<()> {
let cpu = true; // Use CPU instead of GPU
let model_id = "openai/whisper-tiny.en"; // Model identifier
let revision = "main"; // Model revision
let seed = 299792458; // Random seed for reproducibility
let quantized = false; // Use non-quantized model
let task = Some(Task::Transcribe); // Set task to Transcription
let timestamps = false; // Disable timestamping
let verbose = true; // Enable verbose mode
let device_name: Option<String> = None; // Audio device name
// Model and tokenizer setup
let device = candle_examples::device(cpu)?;
let api = Api::new()?;
let repo = api.repo(Repo::with_revision(model_id.to_string(), RepoType::Model, revision.to_string()));
let config_filename = repo.get("config.json")?;
let tokenizer_filename = repo.get("tokenizer.json")?;
let weights_filename = repo.get("model.safetensors")?;
let config: Config = serde_json::from_str(&std::fs::read_to_string(config_filename)?)?;
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
// Load appropriate model version based on quantization
let model = if quantized {
let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(&weights_filename, &device)?;
Model::Quantized(m::quantized_model::Whisper::load(&vb, config.clone())?)
} else {
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[weights_filename], m::DTYPE, &device)? };
Model::Normal(m::model::Whisper::load(&vb, config.clone())?)
};
let mut decoder = Decoder::new(
model,
tokenizer.clone(),
seed,
&device,
None,
task,
timestamps,
verbose,
)?;
// Audio processing setup with resampling
let host = cpal::default_host();
let audio_device = device_name
.as_deref()
.map(|name| host.input_devices().unwrap().find(|x| x.name().map_or(false, |y| y == name)))
.flatten()
.or_else(|| host.default_input_device())
.expect("failed to find the audio input device");
let audio_config = audio_device
.default_input_config()
.expect("Failed to get default input config");
println!("audio config {audio_config:?}");
let channel_count = audio_config.channels() as usize;
let in_sample_rate = audio_config.sample_rate().0 as usize;
let resample_ratio = 16000. / in_sample_rate as f64;
let mut resampler = rubato::FastFixedIn::new(resample_ratio, 10., rubato::PolynomialDegree::Septic, 1024, 1)?;
let (tx, rx) = std::sync::mpsc::channel();
// Configure and play audio stream
let stream = audio_device.build_input_stream(
&audio_config.config(),
move |pcm: &[f32], _: &cpal::InputCallbackInfo| {
let pcm = pcm.iter().step_by(channel_count).copied().collect::<Vec<f32>>();
if !pcm.is_empty() {
tx.send(pcm).unwrap();
}
},
move |err| eprintln!("an error occurred on stream: {}", err),
None,
)?;
stream.play()?;
println!("transcribing audio...");
let mut buffered_pcm = vec![];
while let Ok(pcm) = rx.recv() {
buffered_pcm.extend_from_slice(&pcm);
if buffered_pcm.len() < 10 * in_sample_rate {
continue;
}
let mut resampled_pcm = vec![];
for chunk in buffered_pcm.chunks(1024) {
let pcm = resampler.process(&[&chunk], None)?;
resampled_pcm.extend_from_slice(&pcm[0]);
}
buffered_pcm.clear();
let mel = audio::pcm_to_mel(&config, &resampled_pcm, &vec![0.0; config.num_mel_bins as usize]);
let mel_len = mel.len();
let mel = Tensor::from_vec(mel, (1, config.num_mel_bins, mel_len / config.num_mel_bins), &device)?;
decoder.run(&mel, None)?;
decoder.reset_kv_cache();
}
Ok(())
}
The code begins by defining a DecodingResult struct to hold transcription outputs, including tokens and statistical metrics. The Model enum and Decoder struct encapsulate the logic for handling standard and quantized Whisper models, managing language detection, and decoding audio data. Within main, the code configures the model, establishes an audio input stream using cpal, and resamples the audio to meet the model's expected input format. For each audio segment, it generates a Mel spectrogram, passes it through the Whisper model, and retrieves transcriptions, managing memory efficiently through a kernel value cache reset. By modularizing each step, the program supports high configurability, allowing changes in the device type, task, and language token.
To deploy the model, the following code demonstrate a secure transcription API server built with Rocket in Rust, utilizing OpenAI’s Whisper model for audio-to-text processing. It supports both standard and quantized model versions through an enum structure, allowing users to select the model type best suited to their performance needs. The code includes API key authentication to control access, as well as a logging fairing for tracking incoming requests. The shared application state manages the Whisper model in a thread-safe way, enabling concurrent transcription requests.
use anyhow::{Error as E, Result};
use candle_core::{Device, Tensor};
use candle_nn::VarBuilder;
use hf_hub::{api::sync::Api, Repo, RepoType};
use rocket::{fairing::{Fairing, Info, Kind}, http::Status, request::FromRequest, Request, State};
use rocket::serde::json::Json;
use rocket::routes;
use rocket::post;
use serde::Deserialize;
use std::env;
use std::sync::{Arc, Mutex};
use tokenizers::Tokenizer;
use candle_transformers::models::whisper::{self as m, audio, Config};
use candle_transformers::models::whisper::model::Whisper;
use candle_transformers::models::whisper::quantized_model::Whisper as QuantizedWhisper;
// Constants for API access
const API_KEY_HEADER: &str = "x-api-key";
// ApiKey struct with no fields, as the key is only checked, not stored
#[derive(Debug)]
struct ApiKey;
#[rocket::async_trait]
impl<'r> FromRequest<'r> for ApiKey {
type Error = ();
async fn from_request(request: &'r Request<'_>) -> rocket::request::Outcome<Self, Self::Error> {
match request.headers().get_one(API_KEY_HEADER) {
Some(key) if key == env::var("API_KEY").expect("API_KEY must be set") => {
rocket::request::Outcome::Success(ApiKey)
}
_ => rocket::request::Outcome::Forward(Status::Unauthorized), // Forward with Unauthorized status
}
}
}
// Model enum that supports both normal and quantized Whisper models
pub enum Model {
Normal(Box<Whisper>),
Quantized(Box<QuantizedWhisper>),
}
impl Model {
pub fn config(&self) -> &Config {
match self {
Self::Normal(m) => &m.config,
Self::Quantized(m) => &m.config,
}
}
pub fn encoder_forward(&mut self, x: &Tensor, flush: bool) -> Result<Tensor> {
match self {
Self::Normal(m) => Ok(m.encoder.forward(x, flush)?),
Self::Quantized(m) => Ok(m.encoder.forward(x, flush)?),
}
}
pub fn decoder_forward(&mut self, x: &Tensor, xa: &Tensor, flush: bool) -> Result<Tensor> {
match self {
Self::Normal(m) => Ok(m.decoder.forward(x, xa, flush)?),
Self::Quantized(m) => Ok(m.decoder.forward(x, xa, flush)?),
}
}
pub fn decoder_final_linear(&self, x: &Tensor) -> Result<Tensor> {
match self {
Self::Normal(m) => Ok(m.decoder.final_linear(x)?),
Self::Quantized(m) => Ok(m.decoder.final_linear(x)?),
}
}
}
// Shared application state holding the model only
struct AppState {
model: Arc<Mutex<Model>>, // Using Mutex to allow mutable access
}
#[derive(Deserialize)]
struct AudioData {
data: Vec<f32>,
}
// Endpoint to process audio data and transcribe it
#[post("/transcribe", data = "<audio_data>")]
async fn transcribe(
_api_key: ApiKey, // Using underscore to suppress unused variable warning
audio_data: Json<AudioData>,
state: &State<AppState>,
) -> Result<Json<String>, Status> {
// Lock the model and get config
let model_guard = state.model.lock().unwrap();
let config = model_guard.config(); // Access model's config
let audio_data = &audio_data.data;
// Wrapping pcm_to_mel output in Ok to match Result type for map_err
let _mel = Ok(audio::pcm_to_mel(config, audio_data, &vec![0.0; config.num_mel_bins as usize]))
.map_err(|_: anyhow::Error| Status::InternalServerError)?;
let mel_len = _mel.len();
let _mel = Tensor::from_vec(_mel, (1, config.num_mel_bins, mel_len / config.num_mel_bins), &Device::Cpu)
.map_err(|_| Status::InternalServerError)?;
// Simulated transcription result
let transcription = "Simulated transcription output".to_string();
Ok(Json(transcription))
}
// Logging fairing to log incoming requests
pub struct RequestLogger;
#[rocket::async_trait]
impl Fairing for RequestLogger {
fn info(&self) -> Info {
Info {
name: "Request Logger",
kind: Kind::Request,
}
}
async fn on_request(&self, request: &mut Request<'_>, _: &mut rocket::Data<'_>) {
println!("Received request: {} {}", request.method(), request.uri());
}
}
// Launch the Rocket application with HTTPS support and API key check
#[rocket::main]
async fn main() -> Result<()> {
let _api_key = env::var("API_KEY").expect("API_KEY environment variable is not set");
// Load model and tokenizer
let device = candle_examples::device(true)?;
let model_id = "openai/whisper-tiny.en";
let repo = Api::new()?.repo(Repo::with_revision(model_id.to_string(), RepoType::Model, "main".to_string()));
let config_filename = repo.get("config.json")?;
let tokenizer_filename = repo.get("tokenizer.json")?;
let weights_filename = repo.get("model.safetensors")?;
let config: Config = serde_json::from_str(&std::fs::read_to_string(config_filename)?)?;
let _tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?; // Initialize tokenizer (not stored in state)
// Initialize model (non-quantized example)
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[weights_filename], m::DTYPE, &device)? };
let model = Model::Normal(Box::new(m::model::Whisper::load(&vb, config.clone())?));
let app_state = AppState {
model: Arc::new(Mutex::new(model)),
};
// Configure and launch Rocket server
rocket::build()
.attach(RequestLogger)
.manage(app_state)
.mount("/", routes![transcribe])
.launch()
.await?;
Ok(())
}
The code starts by defining the ApiKey struct for API key validation, followed by the Model enum to handle both normal and quantized Whisper models. The main endpoint, /transcribe, accepts audio data in JSON format, which is converted into a Mel spectrogram compatible with the Whisper model’s input requirements. Using Rocket’s State, it locks access to the model, retrieves the configuration, and transcribes the audio. The main function sets up the Rocket server, attaches the logging fairing, and loads the Whisper model and tokenizer files, preparing the server for secure and efficient audio transcription requests.
A comprehensive maintenance plan for deployed models includes regular updates, vulnerability patching, and retraining to ensure that the model adapts to new data trends and remains resistant to evolving threats. Regular updates help incorporate new security patches and enhancements that strengthen model defenses against adversarial techniques. Retraining, especially in domains with changing data dynamics, prevents the model from becoming outdated or biased due to data drift. For instance, in cybersecurity, where threat patterns change continuously, regular retraining ensures that LLMs stay responsive to emerging attack vectors.
An industry case where these principles are highly relevant is financial services, where customer data and transaction records are highly sensitive. LLMs in this domain must be secured against adversarial manipulation, which could lead to misleading financial recommendations or unauthorized access to accounts. Ensuring secure deployment involves encrypted communications, user authentication, and continuous monitoring to detect abnormal access patterns. Rust’s secure memory handling and rigorous data management make it ideal for deploying and maintaining such models, particularly as it minimizes vulnerabilities that could otherwise be exploited in high-stakes environments.
Emerging trends in model security emphasize anomaly detection through machine learning, automated response to security threats, and blockchain-based verification for immutable logging. By using Rust’s advanced logging and real-time alerting capabilities, LLM deployments can support these trends, providing proactive security measures and comprehensive maintenance frameworks. Blockchain verification, for example, allows organizations to create tamper-proof logs, ensuring an unalterable audit trail that can verify the integrity of model interactions over time.
In conclusion, securing and maintaining deployed LLMs is essential to protecting data privacy, model integrity, and user trust. Rust’s performance, memory safety, and security features make it particularly suited for implementing robust security measures and comprehensive maintenance plans. Through techniques such as adversarial defense, anomaly detection, and rigorous access control, developers can deploy LLMs that remain secure and resilient over time. This section provides foundational practices and advanced tools for ensuring that Rust-based LLM deployments are not only performant but also secure, reliable, and maintainable in diverse real-world applications.
13.7. Case Studies and Applications
Real-world case studies highlight the value of Rust’s performance, memory safety, and concurrency features in the inference and deployment of large language models (LLMs). These examples showcase how Rust-based solutions have been successfully applied across diverse fields, including healthcare, finance, and customer service, to deploy high-performance models at scale. Each case study presents unique challenges, such as managing high request volumes, optimizing inference speed, and securing sensitive data. The solutions implemented in these deployments offer insights into best practices, from distributed inference techniques and model compression to advanced monitoring and logging frameworks. By exploring these solutions, we gain a deeper understanding of how Rust can enable efficient, scalable, and secure deployment of LLMs.
Figure 7: Rust’s role in LLM deployment.
One notable case involves deploying a Rust-based LLM for real-time customer support in the financial services industry. Here, the challenge was to process customer inquiries with low latency while maintaining strict data security standards. Rust’s concurrency model and secure memory management were critical in handling parallel requests efficiently, allowing the LLM to serve hundreds of concurrent users without performance degradation. To reduce latency, the team implemented a distributed inference pipeline where requests were load-balanced across multiple nodes. By partitioning tasks and synchronizing them across nodes, the deployment minimized wait times even during peak usage periods. Additionally, secure APIs with encrypted communications ensured data privacy, addressing regulatory requirements common in financial services. This deployment highlights Rust’s suitability for scenarios requiring high responsiveness and security, where managing concurrent requests and safeguarding data integrity are paramount.
In healthcare, another Rust-based case study focused on deploying LLMs to analyze medical reports and assist in diagnosis. This application demanded stringent performance and reliability standards due to the potential impact on patient outcomes. The Rust implementation was optimized for edge deployment on medical devices, which required lightweight and power-efficient inference pipelines. Model quantization, which reduced the precision of model parameters to minimize memory usage, was implemented to enable the model to run on limited hardware without sacrificing diagnostic accuracy. Mathematically, quantization represented a transformation from FP32 to INT8, reducing the bit-width of each parameter while preserving essential information for the model’s predictions. Rust’s type safety and control over data handling were instrumental in ensuring that quantization did not introduce errors or instability in the model’s outputs. This case underscores the role of Rust in healthcare, where efficient memory use, model accuracy, and reliability are crucial for successful deployment on edge devices.
These case studies illustrate valuable lessons in scaling, optimization, and resource management that are broadly applicable to LLM deployments. The financial services example demonstrates the importance of load balancing and distributed inference in achieving scalability and low latency for applications with high user demand. In contrast, the healthcare example highlights the role of model optimization techniques, such as quantization, in meeting the resource constraints of edge devices. These examples suggest that selecting the right optimization techniques—whether distributing tasks across multiple servers or reducing model precision for limited devices—depends heavily on the deployment context and performance requirements. Rust’s flexible architecture allows for both high-performance server deployments and resource-efficient edge deployments, making it a versatile choice for various LLM applications.
The broader implications of these case studies for LLM deployment and inference lie in Rust’s ability to balance performance with resource efficiency and security. As industries increasingly adopt AI to handle complex tasks, scalable and secure deployment is becoming essential. Rust’s role in these deployments demonstrates that high-level machine learning models can be integrated into production systems without compromising on speed, accuracy, or data protection. Moreover, the modular nature of Rust-based solutions enables teams to iterate on deployment configurations as model architectures evolve, facilitating future updates and enhancements without significant redevelopment.
To explore future applications, a project proposal could focus on deploying an LLM for personalized educational assistance, where students receive AI-based guidance tailored to their learning pace. This project could leverage the inference and deployment techniques discussed in this chapter, including secure access control, distributed inference for scalability, and model compression for mobile access. Rust’s performance and security features would ensure that the deployed model could handle high user volumes, delivering personalized responses with minimal latency. Additionally, by deploying the model to both cloud servers and edge devices, the project could explore a hybrid approach that balances centralized processing with on-device inference for offline accessibility.
In summary, these case studies highlight the unique advantages of using Rust for inference and deployment of LLMs across various industries. Lessons learned from the financial and healthcare deployments emphasize the importance of adapting deployment strategies to the specific demands of each field, from managing concurrent requests in high-demand environments to optimizing models for resource-constrained devices. Rust’s performance, security, and memory efficiency make it an ideal choice for these deployments, where scalability, data integrity, and reliability are critical. These insights, combined with practical implementations and future applications, underscore Rust’s growing role in advancing scalable, secure, and adaptable LLM deployments for a diverse range of applications.
13.8. Conclusion
Chapter 13 equips readers with the knowledge and skills necessary to efficiently deploy and maintain large language models using Rust. By mastering these techniques, readers can ensure that their models are not only powerful but also scalable, secure, and optimized for real-world applications, leveraging Rust’s strengths to achieve high-performance AI deployments.
13.8.1. Further Learning with GenAI
Each prompt is crafted to encourage critical thinking and technical experimentation, helping readers to build a robust understanding of the challenges and solutions involved in deploying LLMs effectively.
Explain the key differences between training and inference in the context of large language models. How do these differences influence the design and optimization of inference pipelines?
Describe the process of setting up an optimized inference pipeline in Rust. What are the essential crates and tools needed, and how do they contribute to performance and efficiency?
Discuss the impact of model quantization and pruning on inference speed and resource usage. How can these techniques be implemented in Rust, and what trade-offs should be considered in terms of accuracy and model size?
Explore the challenges of serving LLMs in production environments. What are the key considerations for deploying models using APIs, containers, and orchestration tools like Docker and Kubernetes?
Analyze the role of batching strategies in optimizing throughput during inference. How can different batching approaches be implemented in Rust, and what impact do they have on latency and resource utilization?
Discuss the architecture of a robust model serving pipeline. How do load balancing, fault tolerance, and security considerations influence the design of such pipelines in Rust-based environments?
Explore the challenges of scaling inference workloads both horizontally and vertically. How can Rust’s concurrency features be leveraged to manage and optimize scaled inference workloads effectively?
Explain the importance of distributed inference in improving throughput and reducing latency. How can distributed inference techniques be implemented in Rust, and what are the challenges associated with synchronization and network latency?
Discuss the specific challenges of deploying LLMs on edge devices. How can Rust’s performance-oriented features be used to optimize models for resource-constrained environments, focusing on power efficiency and connectivity?
Analyze the trade-offs between accuracy, model size, and power consumption in edge deployments. How can Rust be used to implement and optimize these trade-offs for real-world applications?
Explore the importance of securing deployed LLMs against adversarial attacks and data breaches. What techniques can be used to protect model integrity and data privacy, and how can they be implemented in Rust?
Discuss the role of continuous monitoring and logging in maintaining deployed models. How can Rust-based monitoring systems be set up to track performance, detect anomalies, and ensure long-term reliability?
Explain the challenges of maintaining deployed models, including regular updates, retraining, and vulnerability management. How can Rust’s features support these maintenance tasks in a secure and efficient manner?
Explore the use of containerization and orchestration techniques for managing LLM deployments at scale. How can Docker and Kubernetes be integrated with Rust-based applications to optimize model serving and scaling?
Discuss the implications of latency and throughput on user experience in real-time inference applications. How can Rust be used to minimize latency while maximizing throughput in LLM deployments?
Analyze the role of GPU and CPU utilization in optimizing inference performance. How can Rust-based inference pipelines be tuned to make the best use of available hardware resources?
Explain the process of implementing real-time inference systems in Rust. What are the key challenges in handling concurrent requests, and how can they be addressed to ensure responsive and efficient model serving?
Discuss the benefits and challenges of deploying LLMs in cloud versus on-premises environments. How can Rust-based systems be optimized for different deployment scenarios, focusing on cost, performance, and scalability?
Explore the potential of serverless architectures for deploying LLMs. How can Rust be used to build and deploy serverless inference systems, and what are the key considerations in ensuring performance and reliability?
Analyze the broader implications of efficient inference and deployment techniques for the future of AI development. How can the techniques discussed in this chapter be applied to different domains and applications, and what are the potential challenges and opportunities?
By engaging with these prompts, you will develop a robust understanding of how to deploy powerful, scalable, and secure AI systems using Rust, equipping you with the skills needed to lead in the ever-evolving field of AI deployment and infrastructure.
13.8.2. Hands On Practices
Self-Exercise 13.1: Implementing and Optimizing Model Quantization in Rust
Objective: To gain hands-on experience in implementing model quantization for large language models using Rust, with a focus on balancing inference speed and model accuracy.
Tasks:
Implement a quantization technique in Rust that reduces the precision of the model’s weights and activations to optimize inference speed.
Quantize a pre-trained large language model and analyze the impact on model size and inference speed.
Compare the quantized model's performance with the original model, focusing on metrics such as inference latency, throughput, and accuracy.
Experiment with different levels of quantization (e.g., 8-bit, 16-bit) and evaluate the trade-offs between speed and accuracy.
Deliverables:
A Rust codebase implementing model quantization for a large language model.
A performance report comparing the original and quantized models, including metrics on size, speed, and accuracy.
An analysis of the trade-offs associated with different quantization levels, with recommendations for scenarios where quantization is most effective.
Self-Exercise 13.2: Developing a Rust-Based API for Real-Time LLM Inference
Objective: To design and implement a Rust-based API for serving real-time inference requests with a large language model, focusing on optimizing for low latency and high throughput.
Tasks:
Develop a RESTful API in Rust that serves inference requests for a pre-trained large language model.
Implement optimizations to reduce latency and handle concurrent requests efficiently.
Deploy the API in a production environment and test its performance under different load conditions, focusing on metrics such as response time and scalability.
Analyze the impact of different optimization strategies on the API’s performance, including thread management and request batching.
Deliverables:
A Rust codebase for a RESTful API that serves real-time inference requests for a large language model.
A deployment report detailing the setup, optimizations, and performance testing of the API in a production environment.
A performance analysis report that includes metrics on latency, throughput, and scalability, with recommendations for further optimizations.
Self-Exercise 13.3: Scaling Inference Workloads with Distributed Inference in Rust
Objective: To implement and evaluate a distributed inference system for large language models using Rust, focusing on improving throughput and managing synchronization challenges.
Tasks:
Implement a distributed inference pipeline in Rust that distributes inference tasks across multiple nodes or servers.
Experiment with different synchronization strategies to manage distributed inference, focusing on balancing load and minimizing latency.
Deploy the distributed inference system in a cluster environment and test its performance under varying workloads.
Analyze the trade-offs between different synchronization and load balancing strategies, focusing on metrics such as inference speed, throughput, and resource utilization.
Deliverables:
A Rust codebase for a distributed inference system that handles large language model inference across multiple nodes.
A deployment report detailing the setup and testing of the distributed system in a cluster environment.
A performance analysis report that compares different synchronization strategies, with recommendations for optimizing distributed inference in large-scale deployments.
Self-Exercise 13.4: Securing a Deployed LLM with Rust-Based Security Measures
Objective: To explore and implement security measures for a deployed large language model using Rust, focusing on protecting against adversarial attacks and ensuring data privacy.
Tasks:
Implement security features in a Rust-based deployment of a large language model, including secure API endpoints, encrypted communications, and access control.
Integrate anomaly detection mechanisms to monitor for potential adversarial attacks or unusual access patterns.
Deploy the secured model in a production environment and test its resilience to common security threats, such as SQL injection, data poisoning, and model extraction.
Analyze the effectiveness of the implemented security measures, focusing on their impact on model performance, latency, and overall security.
Deliverables:
A Rust codebase with security measures integrated into a deployed large language model, including secure APIs and encryption.
A security testing report that details the deployment’s resilience to various attacks and potential vulnerabilities.
A performance analysis that evaluates the impact of the security measures on model latency and accuracy, with recommendations for further hardening the deployment.
Self-Exercise 13.5: Edge Deployment of a Large Language Model Using Rust
Objective: To implement and optimize the deployment of a large language model on an edge device using Rust, focusing on minimizing latency and power consumption.
Tasks:
Implement an inference pipeline in Rust that is optimized for deployment on a resource-constrained edge device.
Experiment with model compression and quantization techniques to reduce the model’s footprint and improve inference speed.
Deploy the optimized model on an edge device and evaluate its performance in real-world scenarios, focusing on metrics such as latency, power consumption, and model accuracy.
Analyze the trade-offs between model size, performance, and power efficiency in edge deployments, and explore strategies for further optimization.
Deliverables:
A Rust codebase for an edge-deployed inference pipeline, including model compression and quantization techniques.
A deployment report detailing the setup, optimization, and real-world testing of the model on an edge device.
A performance analysis report that includes metrics on latency, power consumption, and accuracy, with recommendations for optimizing edge deployments of large language models.
Comments