Chapter 11
Retrieval-Augmented Generation (RAG)
"The future of AI lies in combining retrieval and generation to create systems that are both knowledgeable and context-aware, enhancing their ability to generate accurate, relevant information in real-time." — Fei-Fei Li
Chapter 11 of LMVR provides a detailed exploration of Retrieval-Augmented Generation (RAG) and its implementation using Rust. It begins by introducing RAG, explaining how it combines retrieval-based and generative models to enhance the relevance and accuracy of generated text. The chapter covers setting up a Rust environment for RAG, implementing both the retriever and generator components, and integrating them into a cohesive system. It also delves into fine-tuning and optimizing RAG models for specific tasks, deploying them in various environments, and addressing challenges such as scalability and retrieval latency. Finally, the chapter explores the future directions of RAG, including emerging trends and ethical considerations, offering a comprehensive framework for building robust RAG systems using Rust.
11.1. Introduction to Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an advanced NLP technique that strengthens the factual accuracy, contextual relevance, and adaptability of generated text by integrating retrieval-based and generative approaches. This methodology diverges from traditional generative models, which rely solely on pre-trained parameters, by incorporating a retrieval mechanism that accesses external, non-parametric knowledge sources. In RAG, the model dynamically retrieves pertinent information from a large-scale corpus, database, or knowledge base and uses this context to guide and refine the generative process. Formally, RAG leverages two primary components: a retriever $R(q, D)$ and a generator $G(y | x, c)$. The retriever scores documents $d \in D$ based on their relevance to an input query $q$, selecting a set of top-$k$ documents $c$ that maximize $P(d | q)$. These documents are concatenated with the input $x$ to form a context $c = \{d_1, d_2, \dots, d_k\}$ which is passed to the generator $G(y | x, c)$ to produce the final output $y$. This framework provides RAG models with dynamic access to external information, bridging gaps in the model’s parametric memory and enhancing its ability to generate responses informed by up-to-date and specialized content.
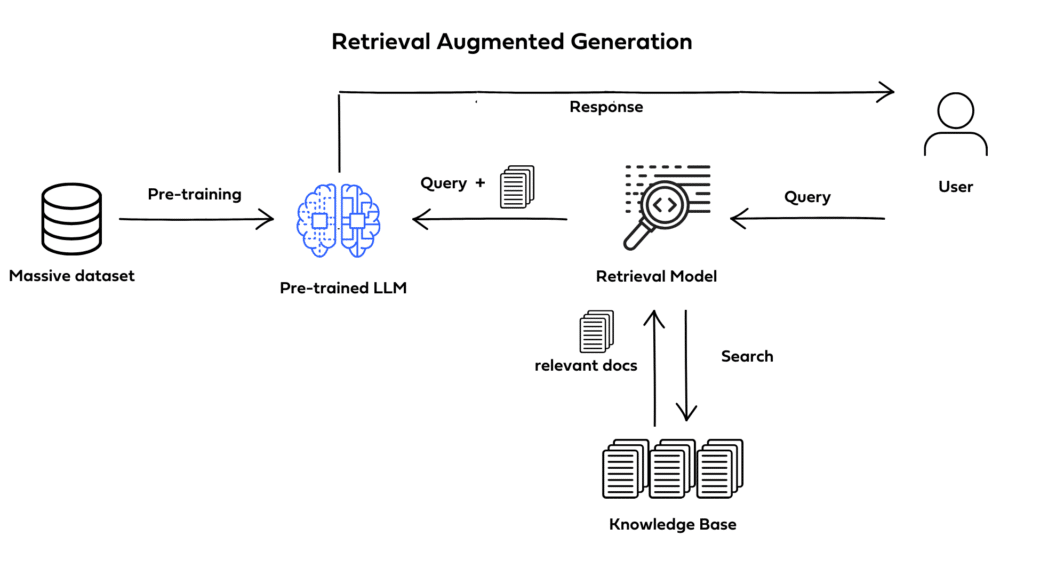
Figure 1: Key concepts in RAG method.
RAG excels in applications where information accuracy, recency, and specificity are essential, making it ideal for fields like open-domain question answering, knowledge-grounded dialogue, fact verification, and technical summarization. In open-domain question answering, RAG outperforms traditional models by efficiently narrowing down a vast corpus to identify documents most relevant to the query. The generator then leverages this targeted context to craft responses that are both specific and accurate. This combination helps to mitigate hallucination—where generative models produce incorrect yet plausible information—by grounding responses in factual data. In fact verification and technical fields such as biomedical or legal domains, RAG enables models to reference verified sources, ensuring that generated responses are reliable and contextually informed by the latest findings or regulations. For instance, in healthcare applications, a RAG system can retrieve recent medical publications or guidelines and synthesize responses aligned with current best practices, offering accurate and relevant information even as knowledge evolves.
In knowledge-grounded dialogue, RAG enhances conversational consistency and coherence by retrieving contextually relevant past dialogue exchanges or related knowledge bases, enabling the generator to respond with a deeper understanding of the conversational context. This feature is particularly valuable in customer service or assistant applications, where maintaining a cohesive flow of dialogue and accurately addressing user queries is crucial. To balance response latency with retrieval accuracy, RAG models can use an efficient retriever, often based on dense vector representations or neural retrieval models, to rapidly identify relevant documents from extensive corpora. However, effective integration between retriever and generator is essential, as irrelevant or poorly contextualized retrievals can detract from the fluency and cohesion of the response. Fine-tuning and rigorous testing are often required to align retrieved information seamlessly with the generated text.
A recent enhancement in RAG approaches involves its combination with large language models (LLMs), such as ChatGPT or LLaMA, where RAG augments these models’ generative capabilities by supplying relevant, up-to-date context retrieved from external databases. This hybrid approach capitalizes on RAG’s retrieval-grounded accuracy and the natural language fluency of LLMs, producing responses that are both articulate and factually reliable. Additionally, RAG systems are adaptable to environments where information is subject to change; they can continuously access external sources without retraining, enabling dynamic responses that reflect the latest available knowledge. As a result, RAG represents a powerful and flexible paradigm in NLP, enabling a broad range of applications that demand factual reliability, adaptive knowledge retrieval, and nuanced natural language generation.
This Rust code demonstrates a simplified Retrieval-Augmented Generation (RAG) pipeline, combining a basic retriever and a language model to generate contextually enhanced responses. Using the langchain_rust crate, it initializes an OpenAI language model and defines a SimpleRetriever struct that mimics a retrieval system by searching a small knowledge base for documents related to a query. Once relevant documents are retrieved, they are formatted as context for the prompt, which is then used to generate an answer from the language model. The code also shows how to handle historical context by incorporating prior interactions in a secondary example.
[dependencies]
langchain-rust = "4.6.0"
serde_json = "1.0.132"
tokio = "1.41.0"
use langchain_rust::{
chain::{Chain, LLMChainBuilder},
fmt_message, fmt_placeholder, fmt_template,
llm::openai::OpenAI,
message_formatter,
prompt::HumanMessagePromptTemplate,
prompt_args,
schemas::messages::Message,
template_fstring,
};
// Define a basic retriever that simulates fetching relevant documents from a database.
struct SimpleRetriever;
impl SimpleRetriever {
fn retrieve(&self, query: &str) -> Vec<String> {
// Simulate retrieving documents by keyword matching (placeholder for a real retrieval system).
let knowledge_base = vec![
"Rust is a systems programming language focused on safety and concurrency.".to_string(),
"The writer of '20,000 Leagues Under the Sea' is Jules Verne.".to_string(),
"Langchain provides tools to build applications using large language models.".to_string(),
];
knowledge_base
.into_iter()
.filter(|doc| doc.to_lowercase().contains(query.to_lowercase().as_str()))
.collect()
}
}
#[tokio::main]
async fn main() {
// Initialize the language model.
let open_ai = OpenAI::default();
// Initialize the retriever.
let retriever = SimpleRetriever;
// Retrieve documents related to the query.
let query = "writer of 20,000 Leagues Under the Sea";
let retrieved_docs = retriever.retrieve(query);
// Format the retrieved documents as context for the generator.
let context = retrieved_docs.join(" ");
// Create a prompt template that includes both the query and retrieved context.
let prompt = message_formatter![
fmt_message!(Message::new_system_message(
"You are a highly knowledgeable assistant who uses external information to answer questions accurately."
)),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"Context: {context}\nQuestion: {input}", "context", "input"
)))
];
// Set up the LLM chain with the context-augmented prompt.
let chain = LLMChainBuilder::new()
.prompt(prompt)
.llm(open_ai.clone())
.build()
.unwrap();
// Run the chain with the input question.
match chain
.invoke(prompt_args! {
"input" => "Who is the writer of 20,000 Leagues Under the Sea?",
"context" => context,
})
.await
{
Ok(result) => {
println!("Result: {:?}", result);
}
Err(e) => panic!("Error invoking LLMChain: {:?}", e),
}
// Example with a historical conversation context.
let prompt_with_history = message_formatter![
fmt_message!(Message::new_system_message(
"You are a knowledgeable assistant that recalls prior conversations and references external information."
)),
fmt_placeholder!("history"),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"Context: {context}\nQuestion: {input}", "context", "input"
))),
];
let chain_with_history = LLMChainBuilder::new()
.prompt(prompt_with_history)
.llm(open_ai)
.build()
.unwrap();
match chain_with_history
.invoke(prompt_args! {
"input" => "Who is the writer of 20,000 Leagues Under the Sea, and what is my name?",
"history" => vec![
Message::new_human_message("My name is: Luis"),
Message::new_ai_message("Hello, Luis."),
],
"context" => context,
})
.await
{
Ok(result) => {
println!("Result with history: {:?}", result);
}
Err(e) => panic!("Error invoking LLMChain with history: {:?}", e),
}
}
The code begins by defining SimpleRetriever with a retrieve method that performs a simple keyword match to return relevant documents from a simulated knowledge base. In the main function, the OpenAI model and the retriever are initialized, and the retrieved documents are combined into a single context string. This context is embedded within a prompt template designed to enhance the LLM’s response accuracy. An LLMChain is set up with this context-augmented prompt, allowing the language model to answer questions with increased relevance to the initial query. Additionally, the code demonstrates maintaining historical context by creating a separate prompt format that includes prior interactions, allowing the model to integrate past conversational history into its response generation. This layered approach provides a foundational RAG setup, where retrieval and generation work together to produce accurate, contextually relevant answers.
Experimenting with different retrieval strategies reveals the advantages and limitations of various methods within a RAG framework. Simple keyword-based retrieval methods are efficient for domains with straightforward terminology but may struggle to capture deeper semantic meaning. Dense retrieval approaches, such as those using embeddings from transformer models, can capture more complex semantic relationships, enhancing retrieval accuracy in scenarios where language is nuanced or less formalized. Integrating dense retrieval into RAG can significantly improve the relevance of retrieved content, especially in applications like customer service or legal research, where understanding intent and context is crucial. Assessing each retrieval method's impact on the quality of generated text provides insight into choosing the best strategy for specific use cases.
In real-world applications, RAG proves highly effective for creating contextually aware responses in dialogue systems. For example, in customer service chatbots, RAG can retrieve relevant support articles or past interactions to address customer queries more comprehensively. Similarly, in healthcare, RAG-powered systems can pull information from medical literature, supporting healthcare professionals with evidence-based responses. Hybrid retrieval-generative models are becoming increasingly popular, bridging the gap between extensive knowledge coverage and fluent language generation.
As RAG technology advances, its applications are likely to expand to more complex, multimodal tasks and real-time interactions. For instance, future RAG models might retrieve and incorporate not just text-based content but also visual or auditory data, making them suitable for applications like virtual assistants that can answer questions about images or audio recordings. Rust’s performance and concurrency advantages make it particularly well-suited for optimizing RAG workflows, efficiently handling retrieval and generation tasks and enabling RAG systems to scale for high-demand applications.
Retrieval-Augmented Generation represents an innovative merging of information retrieval and natural language generation. By combining these elements, RAG enhances generative models with factual grounding and contextual relevance, two essential qualities for applications requiring robust and reliable NLP solutions. Rust-based development in this field could lead to even greater efficiency, responsiveness, and utility in RAG systems, opening new possibilities for knowledge-grounded AI across diverse industries.
11.2. Setting Up the Rust Environment for RAG
Implementing a Retrieval-Augmented Generation (RAG) system in Rust involves a series of advanced steps to fully leverage Rust’s strengths in performance, concurrency, and memory safety. Setting up the RAG environment starts with creating a new Rust project and managing dependencies in Cargo.toml. This includes adding essential crates: langchain-rust for managing RAG workflows, tantivy for retrieval, candle for model inference, tokenizers for text processing, and tokio for asynchronous operations. These libraries collectively allow developers to build a high-performance RAG pipeline where retrieval and generation can operate concurrently and efficiently.
11.2.1. Tokenizers Crate
The first component of a RAG system is text preprocessing. Using the tokenizers crate, we configure a tokenizer to standardize input text for both retrieval and generation, which is a crucial preprocessing step in any RAG pipeline. The tokenizers crate in Rust is a high-performance, versatile library developed primarily to handle tokenization tasks efficiently. It forms the backbone of tokenization pipelines in NLP tasks, particularly in retrieval-augmented generation (RAG) systems where fast and reliable text processing is essential. The library offers implementations for many widely used tokenizers, including Byte-Pair Encoding (BPE) and WordPiece, commonly used in large language models. By leveraging Rust’s capabilities, tokenizers provides a significant performance boost and ensures efficient memory management, which is crucial when working with large datasets in real-time systems.
The tokenization process in tokenizers is structured as a pipeline, allowing text to go through various stages that transform raw input into a format that language models can interpret. This pipeline consists of four main components:
Normalizer: The normalizer prepares the raw text by standardizing it according to specific rules. For instance, common normalization methods include Unicode normalization standards like NFD (Normalization Form D) or NFKC (Normalization Form KC), which standardize characters in terms of composition and compatibility. Using a normalizer ensures consistent input, reducing the chances of errors during tokenization.
PreTokenizer: The pre-tokenizer splits the normalized text into initial tokens, often by whitespace. This step is essential in breaking down text into manageable units before the actual tokenization model processes it. For instance, it might split the sentence “Rust for NLP” into \["Rust", "for", "NLP"\].
Model: The model is the core of tokenization, performing the actual tokenization by mapping tokens into subword units or vocabulary indices. Examples of models include Byte-Pair Encoding (BPE) and WordPiece, each of which has distinct tokenization techniques. These models generate a unique encoding for the input text, making it compatible with the downstream language models.
PostProcessor: After tokenization, the post-processor refines the encoded output by adding special tokens required by language models, such as
[CLS](classification) or[SEP](separator) tokens. This final adjustment ensures the encoded output aligns with the format expected by models for tasks like classification or question answering.
The tokenizers makes it easy to load pretrained tokenizers directly from the Hugging Face Hub, enabling access to a vast array of ready-to-use models. This can streamline setting up a RAG system by providing immediate access to models without additional training:
[dependencies]
tokenizers = "0.20.1"
tokio = "1.41.0"
reqwest = { version = "0.12", features = ["blocking"] }
use reqwest::blocking::get;
use std::fs::File;
use std::io::Write;
use tokenizers::tokenizer::{Result, Tokenizer};
fn main() -> Result<()> {
// URL to download the tokenizer.json for "bert-base-cased" model from Hugging Face
let url = "https://huggingface.co/bert-base-cased/resolve/main/tokenizer.json";
let file_path = "bert-base-cased-tokenizer.json";
// Download the tokenizer file if it doesn't already exist
if !std::path::Path::new(file_path).exists() {
println!("Downloading tokenizer from Hugging Face...");
let response = get(url)?;
let mut file = File::create(file_path)?;
file.write_all(&response.bytes()?)?;
println!("Downloaded and saved tokenizer to {}", file_path);
}
// Load the tokenizer from the downloaded file
let tokenizer = Tokenizer::from_file(file_path)?;
// Encode a sample text
let encoding = tokenizer.encode("Hey there!", false)?;
println!("Tokens: {:?}", encoding.get_tokens());
Ok(())
}
In this example, a pretrained BERT tokenizer (bert-base-cased) is loaded, and the input text "Hey there!" is tokenized. The result is a sequence of tokens that can be fed into a model directly. Loading a pretrained tokenizer is beneficial for tasks where a standard model configuration (such as BERT or GPT) is required.
Creating a custom tokenizer allows greater control over the vocabulary and tokenization rules, particularly in specialized RAG applications. In this example, we create a Byte-Pair Encoding (BPE) tokenizer by deserializing from vocabulary files:
use reqwest::blocking::get;
use std::fs::File;
use std::io::Write;
use std::path::Path;
use tokenizers::tokenizer::{Result as TokenizerResult, Tokenizer}; // Alias to avoid conflict
use tokenizers::models::bpe::BPE;
// Modify the function to return std::result::Result to handle different error types
fn download_file(url: &str, file_path: &str) -> std::result::Result<(), Box<dyn std::error::Error>> {
if !Path::new(file_path).exists() {
println!("Downloading {}...", file_path);
let response = get(url)?; // No conversion needed with Box<dyn std::error::Error>
let mut file = File::create(file_path)?;
file.write_all(&response.bytes()?)?;
println!("Downloaded and saved to {}", file_path);
}
Ok(())
}
fn main() -> TokenizerResult<()> {
// URLs for the vocab and merges files for the "bert-base-cased" tokenizer from Hugging Face
let vocab_url = "https://huggingface.co/bert-base-cased/resolve/main/vocab.json";
let merges_url = "https://huggingface.co/bert-base-cased/resolve/main/merges.txt";
let vocab_path = "vocab.json";
let merges_path = "merges.txt";
// Download the files if they don't already exist
download_file(vocab_url, vocab_path).expect("Failed to download vocab.json");
download_file(merges_url, merges_path).expect("Failed to download merges.txt");
// Create a BPE tokenizer from the downloaded vocabulary and merge files
let bpe_builder = BPE::from_file(vocab_path, merges_path);
let bpe = bpe_builder
.dropout(0.1) // Adds some randomness for robustness
.unk_token("[UNK]".into()) // Sets the unknown token
.build()?;
let tokenizer = Tokenizer::new(bpe); // Remove mut since it's not modified
// Encode a sample input
let encoding = tokenizer.encode("Hey there!", false)?;
println!("Tokens: {:?}", encoding.get_tokens());
Ok(())
}
This code checks for the presence of two required files, vocab.json and merges.txt, which are essential for creating a Byte-Pair Encoding (BPE) tokenizer. If these files are not found locally, it downloads them from Hugging Face using the specified URLs. The download_file function handles this by checking each file’s existence, downloading it if needed, and saving it to the specified path. Once both files are available, the code initializes a BPE tokenizer with them, setting a dropout rate for robustness and specifying an unknown token to handle out-of-vocabulary cases. Finally, the tokenizer encodes a sample text ("Hey there!") and prints the resulting tokens, showcasing the tokenizer’s ability to process text into tokenized units.
For specialized tasks where domain-specific vocabularies are necessary, training a custom tokenizer from scratch can be advantageous. The following example demonstrates training a BPE tokenizer on a custom dataset and saving the resulting configuration:
use tokenizers::models::bpe::{BpeTrainerBuilder, BPE};
use tokenizers::decoders::byte_level::ByteLevel;
use tokenizers::normalizers::{strip::Strip, unicode::NFC, utils::Sequence};
use tokenizers::pre_tokenizers::byte_level::ByteLevel as ByteLevelPreTokenizer;
use tokenizers::{AddedToken, TokenizerBuilder, Result};
fn main() -> Result<()> {
// Set vocabulary size and special tokens for the tokenizer
let vocab_size = 100;
let mut trainer = BpeTrainerBuilder::new()
.vocab_size(vocab_size)
.min_frequency(0)
.special_tokens(vec![
AddedToken::from("<s>", true),
AddedToken::from("<pad>", true),
AddedToken::from("</s>", true),
AddedToken::from("<unk>", true),
AddedToken::from("<mask>", true),
])
.build();
// Build and configure the tokenizer
let mut tokenizer = TokenizerBuilder::new()
.with_model(BPE::default())
.with_normalizer(Some(Sequence::new(vec![
Strip::new(true, true).into(),
NFC.into(),
])))
.with_pre_tokenizer(Some(ByteLevelPreTokenizer::default()))
.with_post_processor(Some(ByteLevel::default()))
.with_decoder(Some(ByteLevel::default()))
.build()?;
// Train the tokenizer on a dataset
tokenizer
.train_from_files(&mut trainer, vec!["vocab.txt".to_string()])? // Ensure vocab.txt is in the correct path
.save("tokenizer.json", false)?;
println!("Tokenizer training completed and saved as tokenizer.json");
Ok(())
}
This code sets up, trains, and saves a Byte-Pair Encoding (BPE) tokenizer in Rust using the tokenizers library. It begins by defining a vocabulary size and special tokens (like TokenizerBuilder configures the tokenizer with a BPE model, a normalizer (to strip unwanted characters and normalize text with NFC), a byte-level pre-tokenizer, post-processor, and decoder to ensure consistent tokenization and decoding. The tokenizer is then trained on a dataset specified in vocab.txt, which should contain sample text data and be located in the same directory as the code or referenced with the correct path. Once trained, the tokenizer is saved as tokenizer.json, which can be loaded later for text processing tasks. This process allows for custom tokenization tailored to specific data, useful for NLP applications requiring specialized vocabularies.
The tokenizers crate leverages CPU parallelism for faster processing, an advantage in large-scale systems like RAG pipelines. By default, tokenizers utilizes all available CPU cores, but this behavior can be adjusted using the RAYON_RS_NUM_THREADS environment variable. For instance, setting RAYON_RS_NUM_THREADS=4 will limit the processing to four threads. This flexibility is crucial in scenarios where resources are shared across multiple applications, as it allows fine-tuning of CPU usage to balance performance and resource availability.
export RAYON_RS_NUM_THREADS=4
Setting this environment variable is beneficial when running tokenizers in multi-threaded environments or in systems with constrained resources, like production servers, to optimize resource usage.
In summary, the tokenizers crate in Rust is a powerful tool for NLP pipelines, especially in retrieval-augmented generation (RAG) setups. It offers flexibility through customizable tokenizers, pretrained models, and CPU parallelism. From loading pretrained models to training custom tokenizers, tokenizers covers a broad range of needs in modern NLP, making it indispensable for high-performance applications that demand real-time processing and scalable text tokenization.
11.2.2. Tantivy Crate
Tantivy is a high-performance, full-text search engine library written in Rust, designed to provide a flexible, Rust-native alternative to traditional search solutions like Apache Lucene. Unlike off-the-shelf servers such as Elasticsearch or Solr, Tantivy is a crate that developers can embed within their applications to create customized search engines. Its Lucene-inspired architecture makes it suitable for complex and large-scale search needs, and it is the foundation of Quickwit, a distributed search engine also written in Rust. Tantivy offers a broad feature set, including full-text search, customizable tokenizers with multi-language support, BM25 scoring, phrase and natural language query handling, faceted search, and range queries. With multithreaded and incremental indexing, SIMD-optimized integer compression, and a minimal startup time, Tantivy is particularly useful for command-line tools and embedded applications.
Architecturally, Tantivy organizes data in an index, which is a collection of segments serving as the smallest unit for indexing and searching. An index is defined by a schema that specifies fields, data types, and properties, ensuring structured data handling. The indexing process is managed by an IndexWriter, which tokenizes fields, creates indices, and stores segments in a directory for persistence. Documents are kept in memory until they reach a specified threshold or commit, at which point they are saved, making them available for search. To optimize performance, segments are merged in the background, reducing disk usage and improving search speed. Queries are handled by a Searcher, which accesses segments based on given parameters and merges results to deliver unified search outcomes. Tantivy supports various storage backends via a directory abstraction, allowing flexibility across different environments. With support for multiple platforms and a thriving open-source community, Tantivy is an excellent choice for developers seeking a powerful, adaptable search engine for high-demand applications.
Below is an example of initializing an index with fields for document title and body, adding a document to the index, and preparing for asynchronous retrieval:
[dependencies]
tantivy = "0.22.0"
use tantivy::schema::{Schema, TEXT, Field};
use tantivy::{Index, doc};
fn create_index() -> (Index, Field, Field) {
let mut schema_builder = Schema::builder();
let title = schema_builder.add_text_field("title", TEXT);
let body = schema_builder.add_text_field("body", TEXT);
let index = Index::create_in_ram(schema_builder.build());
(index, title, body)
}
fn add_document(index: &Index, title: &str, body: &str) {
let mut index_writer = index.writer(50_000_000).unwrap();
// Handle the Result from add_document by unwrapping it
index_writer.add_document(doc!(
index.schema().get_field("title").unwrap() => title,
index.schema().get_field("body").unwrap() => body
)).unwrap();
index_writer.commit().unwrap();
}
fn main() {
let (index, _title, _body) = create_index();
add_document(&index, "Rust RAG Tutorial", "Implementing RAG with Rust crates");
println!("Document added to the index.");
}
The above code creates an in-memory index with tantivy, which is ideal for development and testing. The add_document function adds documents to the index, committing each addition to ensure the index is ready for search operations. Now that documents are stored in the index, we can retrieve them based on queries using tantivy and tokio for asynchronous operations. This allows multiple retrievals to be processed concurrently, essential for real-time systems.
[dependencies]
tantivy = "0.22.0"
tokio = { version = "1.41.0", features = ["full"] }
use tantivy::schema::{Schema, TEXT, Field};
use tantivy::{Index, doc, TantivyDocument};
use tantivy::query::QueryParser;
use tantivy::collector::TopDocs;
use tokio::runtime::Runtime;
use std::sync::Arc;
// Function to create an in-memory index with title and body fields
fn create_index() -> (Index, Field, Field) {
let mut schema_builder = Schema::builder();
let title = schema_builder.add_text_field("title", TEXT);
let body = schema_builder.add_text_field("body", TEXT);
let index = Index::create_in_ram(schema_builder.build());
(index, title, body)
}
// Function to add a document to the index
fn add_document(index: &Index, title: &str, body: &str) {
let mut index_writer = index.writer(50_000_000).unwrap();
index_writer.add_document(doc!(index.schema().get_field("title").unwrap() => title,
index.schema().get_field("body").unwrap() => body)).unwrap();
index_writer.commit().unwrap();
}
// Asynchronous function to retrieve documents based on a query
async fn retrieve_documents(query_str: &str, index: Arc<Index>, title: Field) -> tantivy::Result<()> {
let reader = index.reader()?;
let searcher = reader.searcher();
let query_parser = QueryParser::for_index(&index, vec![title]);
let query = query_parser.parse_query(query_str)?;
let top_docs = searcher.search(&query, &TopDocs::with_limit(10))?;
for (score, doc_address) in top_docs {
// Specify that doc() should return a TantivyDocument
let retrieved_doc: TantivyDocument = searcher.doc(doc_address)?;
println!("Score: {}, Document: {:?}", score, retrieved_doc);
}
Ok(())
}
fn main() {
// Initialize Tokio runtime
let rt = Runtime::new().unwrap();
// Create an in-memory index and add a document
let (index, title, _body) = create_index();
add_document(&index, "Rust RAG Tutorial", "Implementing RAG with Rust crates");
// Use an Arc to share the index reference across threads
let index_arc = Arc::new(index);
rt.block_on(retrieve_documents("Rust", index_arc, title)).unwrap();
println!("Document retrieval completed.");
}
This code demonstrates creating, indexing, and retrieving documents using Tantivy, a full-text search engine library in Rust. It starts by defining an in-memory index with two fields, title and body, through the create_index function. Documents are added to this index in add_document, which takes a title and body, tokenizes them according to the schema, and commits the changes to make the document searchable. The retrieve_documents function performs an asynchronous search on the index, taking a query string and retrieving the top 10 matching documents based on their scores. In main, a Tokio runtime is initialized to manage the asynchronous search process, an index is created and populated with a sample document, and the retrieve_documents function is invoked to search for documents containing the term "Rust." The code outputs the document scores and content for matches, showcasing how Tantivy can be used to manage and query textual data efficiently in Rust.
11.2.3. Hugging Face Candle Crate
Candle is a minimalist machine learning (ML) framework written in Rust, designed for high performance and ease of use, with support for GPU acceleration. The framework offers a straightforward, PyTorch-like syntax, making it accessible for Rust developers who are familiar with other ML frameworks. Users can perform operations like matrix multiplications, define custom kernels, and manage devices (CPU or GPU) efficiently, with GPU support enabled through CUDA. Candle provides an optimized CPU backend with optional MKL support for x86 architectures and Accelerate for macOS, along with support for CUDA backends, allowing users to run models on multiple GPUs. Additionally, Candle supports WASM, enabling models to run directly in browsers, expanding its versatility across different deployment environments.
Candle features a wide array of pre-built models, covering various domains. In natural language processing (NLP), it supports models like LLaMA, Falcon, and StarCoder for tasks such as text generation, code completion, and multilingual chat. For computer vision, Candle includes models like YOLO for object detection, Stable Diffusion for text-to-image generation, and Segment Anything for image segmentation. It also offers models for audio processing, such as Whisper for speech recognition and MetaVoice for text-to-speech. Candle supports various file formats like safetensors, NPZ, GGML, and PyTorch, making it compatible with a broad range of model storage types.
For advanced users, Candle provides tools for model quantization, serverless deployment, and integration with custom samplers or optimizers. It also supports quantized versions of popular models like LLaMA, enabling efficient inference on resource-constrained devices. Additionally, Candle’s modular design includes components like candle-core for core operations, candle-nn for neural network utilities, and candle-datasets for data loading, making it suitable for building custom ML workflows. With its lightweight design and flexibility, Candle aims to streamline deployment and inference in production environments, eliminating Python dependencies and optimizing for Rust's performance advantages.
For the generation step, we use candle to load and infer on machine learning models. This crate enables Rust to handle complex machine learning models, including large transformers. Here’s a setup for loading a model and running inference, creating a generator component that can be integrated into the RAG system:
[dependencies]
anyhow = "1.0.92"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-onnx = "0.7.2"
candle-transformers = "0.7.2"
hf-hub = "0.3.2"
use candle_core::{IndexOp, D};
enum Which {
SqueezeNet,
}
pub fn main() -> anyhow::Result<()> {
// Hard-coded values for image path and model type
let image_path = "path/to/your/image.jpg";
let model_type = Which::SqueezeNet;
// Load the image
let image = candle_examples::imagenet::load_image224(image_path)?;
println!("Loaded image {image:?}");
// Set the model based on the hard-coded model type
let model_path = match model_type {
Which::SqueezeNet => hf_hub::api::sync::Api::new()?
.model("lmz/candle-onnx".into())
.get("squeezenet1.1-7.onnx")?,
};
// Load the model and prepare the input
let model = candle_onnx::read_file(model_path)?;
let graph = model.graph.as_ref().unwrap();
let mut inputs = std::collections::HashMap::new();
inputs.insert(graph.input[0].name.to_string(), image.unsqueeze(0)?);
let mut outputs = candle_onnx::simple_eval(&model, inputs)?;
let output = outputs.remove(&graph.output[0].name).unwrap();
// Process the output based on the model type
let prs = candle_nn::ops::softmax(&output, D::Minus1)?;
let prs = prs.i(0)?.to_vec1::<f32>()?;
// Sort the predictions and take the top 5
let mut top: Vec<_> = prs.iter().enumerate().collect();
top.sort_by(|a, b| b.1.partial_cmp(a.1).unwrap());
let top = top.into_iter().take(5).collect::<Vec<_>>();
// Print the top predictions
for &(i, p) in &top {
println!(
"{:50}: {:.2}%",
candle_examples::imagenet::CLASSES[i],
p * 100.0
);
}
Ok(())
}
This Rust code demonstrates a simple machine learning inference pipeline using the Candle library to load, process, and classify an image with the SqueezeNet model. It starts by hardcoding the path to an input image file and loading it with predefined dimensions, specifically for the SqueezeNet model. Using the Hugging Face Hub API, it then retrieves the ONNX model file for SqueezeNet, loads it into memory, and prepares the input by reshaping the image tensor as needed for model inference. The model's output is processed with a softmax function to generate probability scores for each class, and the top 5 predicted classes with the highest probabilities are selected and displayed. The code prints each class’s name and probability, enabling users to view the model’s predictions for the given image. This example shows how to set up a basic image classification task with hardcoded parameters in Rust using Candle’s functionalities.
11.2.4. Langchain Crate
Finally, LangChain-rust allows us to integrate the retrieval and generation components into a cohesive RAG system. It is a Rust-based implementation of LangChain, designed to facilitate building applications that use large language models (LLMs) with an emphasis on composability. By supporting a range of LLMs, embeddings, vector stores, chains, agents, and tools, LangChain Rust empowers developers to construct complex and adaptable language model-driven applications. For instance, users can integrate LLMs such as OpenAI, Azure OpenAI, or Claude from Anthropic and use embeddings from local and cloud-based sources. This enables various functionalities like conversational chains, SQL chains, and question-answering chains, which can be tailored for specific use cases.
LangChain Rust supports multiple vector stores, such as OpenSearch, Postgres, and Qdrant, making it versatile for document storage and retrieval. With agents and tools like SerpAPI for Google searches, Wolfram for math operations, and even command-line tools, developers can create sophisticated LLM-driven workflows. Additionally, document loaders enable easy handling of files like PDFs, HTML, CSVs, and even source code, making LangChain Rust adaptable to varied data sources. This flexibility allows for advanced applications, such as conversational retrievers that pull from both vector stores and standard databases or chains that interact dynamically with the LLM.
The library is easy to set up, requiring dependencies such as serde_json and langchain-rust, and offers optional features for specialized setups like SQLite or Qdrant. A quick-start example using LangChain Rust shows how to set up an LLM chain with OpenAI, allowing for customized prompts and interaction styles. By using prompt templates, developers can craft specific inputs to the LLM for various types of responses, such as technical documentation or conversational exchanges. LangChain Rust also supports sophisticated prompt handling with macros, which lets users shape the flow of messages in conversational chains.
The provided code demonstrates a simplified example of a vector store retrieval system in Rust using asynchronous traits enabled by the async-trait crate. It showcases how to define a dummy vector store, DummyVectorStore, which implements two key operations: add_documents and similarity_search. These operations allow for document storage and retrieval, respectively, simulating the core functionality of a vector-based information retrieval system. The code further demonstrates setting up a Retriever structure to perform queries against the vector store and retrieve documents based on a search query.
[dependencies]
async-trait = "0.1.83"
futures = "0.3.31"
langchain-rust = "4.6.0"
serde_json = "1.0.132"
tokio = "1.41.0"
use async_trait::async_trait;
use std::error::Error;
use std::sync::Arc;
#[derive(Debug)]
struct Document {
id: String,
_content: String, // Prefixed with underscore to silence unused warning
}
impl Document {
pub fn new(id: &str, content: &str) -> Self {
Document {
id: id.to_string(),
_content: content.to_string(),
}
}
}
#[derive(Debug)]
struct VecStoreOptions;
#[async_trait]
trait VectorStore {
async fn add_documents(
&self,
documents: &[Document],
options: &VecStoreOptions,
) -> Result<Vec<String>, Box<dyn Error + Send + Sync>>;
async fn similarity_search(
&self,
query: &str,
num_results: usize,
options: &VecStoreOptions,
) -> Result<Vec<Document>, Box<dyn Error + Send + Sync>>;
}
struct DummyVectorStore;
#[async_trait]
impl VectorStore for DummyVectorStore {
async fn add_documents(
&self,
documents: &[Document],
_options: &VecStoreOptions,
) -> Result<Vec<String>, Box<dyn Error + Send + Sync>> {
println!("Adding documents: {:?}", documents);
Ok(documents.iter().map(|doc| doc.id.clone()).collect())
}
async fn similarity_search(
&self,
query: &str,
num_results: usize,
_options: &VecStoreOptions,
) -> Result<Vec<Document>, Box<dyn Error + Send + Sync>> {
println!("Performing similarity search for query: '{}', top {} results", query, num_results);
// Dummy implementation: returning empty results
Ok(vec![])
}
}
struct Retriever {
vector_store: Arc<dyn VectorStore + Send + Sync>,
}
impl Retriever {
pub fn new(vector_store: Arc<dyn VectorStore + Send + Sync>) -> Self {
Retriever { vector_store }
}
async fn retrieve(&self, query: &str) -> Result<Vec<Document>, Box<dyn Error + Send + Sync>> {
let options = VecStoreOptions;
self.vector_store.similarity_search(query, 5, &options).await
}
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error + Send + Sync>> {
let vector_store = Arc::new(DummyVectorStore);
let retriever = Retriever::new(vector_store);
// Adding documents
let documents = vec![
Document::new("doc1", "Example content for doc1"),
Document::new("doc2", "Example content for doc2"),
];
retriever.vector_store.add_documents(&documents, &VecStoreOptions).await?;
// Performing a search
let query = "Example query";
match retriever.retrieve(query).await {
Ok(results) => {
for doc in results {
println!("Retrieved document: {:?}", doc);
}
}
Err(e) => eprintln!("Error retrieving documents: {}", e),
}
Ok(())
}
The code defines a Document struct to represent documents with an ID and content, where the content field is unused to avoid warnings. Using the async-trait crate, a VectorStore trait is implemented for DummyVectorStore, which provides asynchronous methods add_documents and similarity_search. The add_documents method simulates adding documents to the store, while similarity_search simulates performing a search operation and returning empty results. A Retriever struct wraps around the vector store to perform document retrieval based on a query, using the vector store's similarity_search method. In the main function, the code creates instances of DummyVectorStore and Retriever, adds documents, and performs a query, outputting the results to the console. This setup emulates a simple search system where documents can be added and queried.
11.2.4. Summary of Rust RAG Toolset
Implementing a Retrieval-Augmented Generation (RAG) system in Rust using a combination of crates like tokenizers, tantivy, candle, and langchain-rust allows for the creation of efficient, contextually aware language model (LLM) applications. RAG systems integrate retrieval and generation capabilities, making them especially effective for applications that require accurate, context-driven responses based on a knowledge base. In this setup, each crate serves a specific role, collectively enabling the construction of a high-performance RAG system.
The process begins with document tokenization using the tokenizers crate, which efficiently segments the text data into tokens suitable for both indexing and embedding generation. Tokenization, a foundational step, ensures that text is processed uniformly, enabling reliable search and retrieval. With support for techniques like Byte-Pair Encoding (BPE) and WordPiece, tokenizers helps generate representations that prepare data for the next stages of retrieval and generative response.
Following tokenization, the tantivy crate is used to build a full-text search index. Acting as a high-performance search engine, tantivy indexes the preprocessed documents to facilitate quick retrieval based on user queries. Its lightweight, scalable architecture allows for efficient keyword-based search, retrieving documents that best match the search terms provided by users. In a RAG setup, tantivy provides the core search mechanism, enabling fast, context-relevant document lookup.
For a more nuanced, semantic retrieval process, langchain-rust complements tantivy by handling embeddings and vector-based similarity searches. Embeddings capture semantic meaning, allowing the system to retrieve documents based on similarity rather than just keyword matching. Using langchain-rust, you can store these embeddings in a vector store, creating a semantic search layer that augments the lexical capabilities of tantivy. This hybrid approach—combining both keyword-based retrieval with tantivy and similarity-based retrieval with embeddings—maximizes relevance and accuracy in retrieved documents.
The generative aspect of the RAG system is driven by candle, which serves as the LLM model backend responsible for generating responses. candle provides flexible, high-performance support for models that can be deployed on both GPU and optimized CPU setups, allowing the generative model to produce responses conditioned on the retrieved documents. With candle, it’s possible to load or fine-tune models on specific domains, enabling more relevant and coherent responses that reflect the retrieved context.
Finally, langchain-rust provides a compositional framework for chaining these retrieval and generation components into a cohesive workflow. By using conversational retriever chains, you can integrate the retrieval stages—handled by tantivy and vector-based embeddings—with candle for the final generation step. This chain can include additional tools or APIs as needed, making the RAG system versatile and interactive. For example, in response to user queries, the retrieval stage fetches contextually relevant documents, while the generation stage in candle produces a response based on this context, resulting in a coherent and informative answer.
In summary, by leveraging tokenizers for text preprocessing, tantivy for efficient document indexing, langchain-rust for vector-based similarity searches and orchestration, and candle for generative responses, developers can build powerful RAG systems. This setup enables high-speed retrieval and response generation, allowing for responsive, contextually aware LLM applications that deliver accurate and context-driven answers to user queries.
11.3. Implementing the Retriever Component in Rust
The retriever component in a Retrieval-Augmented Generation (RAG) system plays a critical role by selecting relevant information from a knowledge base to provide context for the generative model. This retrieval process is fundamental to RAG because it allows the system to access external information dynamically, thus grounding generated responses in real-world data and enhancing factual accuracy. Several retrieval methods exist, ranging from traditional approaches like TF-IDF and BM25 to modern dense retrieval techniques using neural embeddings. Each method offers distinct advantages in terms of speed, scalability, and retrieval accuracy, with traditional methods relying on keyword matching and dense methods leveraging semantic similarity. Implementing an effective retriever requires understanding these retrieval approaches, indexing techniques, and the trade-offs involved in each.
Traditional retrieval methods, such as BM25, are based on sparse representations where text is represented as a set of weighted terms. BM25, a variant of TF-IDF, is often used for information retrieval because it applies term frequency (TF) and inverse document frequency (IDF) to rank documents by relevance. Given a query and a document, BM25 calculates a relevance score using the formula:
$$ \text{BM25}(q, d) = \sum_{t \in q} \frac{\text{IDF}(t) \cdot f(t, d) \cdot (k_1 + 1)}{f(t, d) + k_1 \cdot (1 - b + b \cdot \frac{|d|}{\text{avgdl}})} $$
where $f(t, d)$ represents the frequency of term $t$ in document $d$, $k_1$ and $b$ are hyperparameters controlling term saturation and document length normalization, respectively, and $\text{avgdl}$ is the average document length in the corpus. BM25’s scoring mechanism allows it to effectively capture the relevance of a document based on keyword presence and frequency, making it suitable for smaller, well-defined knowledge bases.
Modern retrieval methods have shifted towards dense representations, where neural embeddings represent documents and queries as vectors in a high-dimensional space. Dense retrieval allows the retriever to capture semantic meaning beyond exact keyword matches, making it effective for open-domain or complex tasks. Dense retrievers use models like BERT to embed both documents and queries, mapping them into a shared embedding space where similar vectors are close to each other. A dense retriever performs approximate nearest neighbor (ANN) search on these embeddings to find documents most relevant to the query. Dense retrieval is computationally more intensive but often achieves higher accuracy, especially for ambiguous or context-sensitive queries.
In building a retriever in Rust, developers have various options for indexing techniques to improve retrieval efficiency. Inverted indices are commonly used with sparse retrieval methods; they allow for fast lookup of documents containing specific terms by mapping each term to a list of document identifiers. For dense retrieval, ANN search methods such as HNSW (Hierarchical Navigable Small World) graph-based search allow efficient similarity searches in high-dimensional spaces, significantly reducing the search time compared to brute-force methods.
To illustrate a retriever implementation in Rust, we start with a BM25-based sparse retrieval model using the tantivy library, which provides efficient indexing and querying capabilities. The following code demonstrates the setup of a BM25 retriever that indexes a set of documents and retrieves the top-ranked results for a given query. The code demonstrates a basic search application, a full-text search engine inspired by Apache Lucene. It defines a schema for indexing documents with fields for "title" and "body," adds documents to an in-memory index, and performs a search on this index. The example uses BM25 scoring to rank documents based on a query string, "Rust programming safety," and then retrieves and displays the top results.
use tantivy::{schema::*, Index, doc, TantivyDocument};
use tantivy::collector::TopDocs;
use tantivy::query::QueryParser;
use std::error::Error;
fn main() -> Result<(), Box<dyn Error>> {
// Define the schema for the document index
let mut schema_builder = Schema::builder();
let title = schema_builder.add_text_field("title", TEXT | STORED);
let body = schema_builder.add_text_field("body", TEXT | STORED);
let schema = schema_builder.build();
// Create an in-memory index
let index = Index::create_in_ram(schema.clone());
let mut index_writer = index.writer(50_000_000)?;
// Add documents to the index
index_writer.add_document(doc!(title => "Rust for System Programming", body => "Rust offers safety and concurrency."))?;
index_writer.add_document(doc!(title => "Advantages of Rust", body => "Rust is known for its memory safety and efficiency."))?;
index_writer.commit()?;
// Define a query and search using BM25
let query = "Rust programming safety";
let query_parser = QueryParser::for_index(&index, vec![title, body]);
let query = query_parser.parse_query(query)?;
let searcher = index.reader()?.searcher();
let top_docs = searcher.search(&query, &TopDocs::with_limit(5))?;
// Display retrieved documents
for (_score, doc_address) in top_docs {
// Explicitly specify TantivyDocument to deserialize the document
let retrieved_doc: TantivyDocument = searcher.doc(doc_address)?;
println!("{:?}", retrieved_doc);
}
Ok(())
}
In this code, we first set up the schema for our documents, specifying that both the title and body fields are text fields that should be stored in the index. After creating an in-memory index, two sample documents are added with information about Rust's advantages in system programming and memory safety. We use a query parser to convert a query string into a format that Tantivy's searcher can process. The searcher then retrieves the top-ranked documents based on the BM25 relevance score, and we explicitly cast the retrieved documents to TantivyDocument to display their content. This setup provides a simple yet powerful search mechanism for document retrieval.
Expanding the retriever to support dense retrieval enables more nuanced information retrieval based on semantic similarity rather than keyword matching. Dense retrieval involves encoding both documents and queries into embeddings and performing an approximate nearest neighbor (ANN) search to identify relevant documents. Integrating dense retrieval in Rust requires an embedding model, often imported from libraries like candle or rust-bert, and an ANN search method like HNSW. The combination of dense retrieval and ANN search is particularly effective in large, open-domain contexts where keyword-based retrieval may fail to capture complex relationships.
Integrating the retriever with a knowledge base requires an interface for both document storage and retrieval. When implementing RAG in production environments, retrieval quality directly impacts overall system performance. For instance, in a customer service context, accurately retrieved information ensures that the system provides relevant, precise answers, significantly enhancing user satisfaction. Hybrid retrieval methods that combine BM25 and dense retrieval further improve performance by offering both term-matching accuracy and semantic relevance.
Industry use cases for RAG systems with advanced retrievers range from legal research, where dense retrieval helps navigate extensive case law databases, to e-commerce applications, where hybrid retrieval provides precise product recommendations. Emerging trends in retrieval focus on query expansion, where additional terms are added to enhance retrieval relevance, and relevance feedback, where user interactions are incorporated to improve subsequent retrieval quality. In legal and healthcare industries, such techniques are crucial as they ensure that retrieval accuracy aligns with complex, domain-specific queries.
Rust’s performance and low-level control make it highly suitable for building efficient retrieval systems. As retrieval continues to advance with hybrid models and ANN search improvements, Rust’s capabilities in concurrency and memory management provide a foundation for deploying scalable, high-performance RAG systems. By implementing retrieval strategies in Rust, developers can enhance both the speed and relevance of RAG outputs, contributing to a more robust and versatile NLP solution. As RAG’s applications grow, the Rust ecosystem will play a key role in developing retrieval systems that meet the needs of diverse, data-intensive industries.
11.4. Implementing the Generator Component in Rust
In a Retrieval-Augmented Generation (RAG) system, the generator component is responsible for producing coherent and contextually relevant text based on retrieved information. The generator synthesizes this information, creating a response that maintains fluency while incorporating precise knowledge from the retriever. This component is essential for tasks such as question answering, summarization, and dialogue generation, where the generated content must be accurate and grounded in external information. Several generative models are well-suited for RAG, including GPT, BART, and T5, each with distinct architectures that influence how they handle context and incorporate external knowledge. By conditioning these models on retrieved content, developers can ensure that outputs are both relevant and informative, an essential factor for high-quality RAG applications.
One of the main challenges in integrating retrieval results into generation lies in maintaining fluency and coherence, especially as retrieved information may not align perfectly with the generator’s language structure. Conditioning the generator on retrieved information requires thoughtful design, as effective integration ensures that the model remains responsive to the context without introducing redundant or irrelevant information. Techniques like attention mechanisms are commonly employed to enhance this conditioning by focusing on relevant sections of the retrieved content, while memory networks enable the model to retain and retrieve pertinent details dynamically. Conditioning can be represented as a transformation $G(c, r)$, where $G$ is the generator, $c$ the original context or query, and $r$ the retrieved information, creating an output that combines the coherence of $G$ with the factual basis of $r$.
Choosing the appropriate generator architecture is crucial, as each model type offers unique benefits for RAG. For example, GPT-based models, which are autoregressive, are highly effective at generating coherent sequences due to their training on vast language corpora. BART and T5, which incorporate encoder-decoder structures, excel in tasks that require sequence-to-sequence transformations, making them suitable for summarization and complex conditional generation. The pre-training of these models also impacts performance, as models trained on large, diverse datasets can generalize better and handle nuanced language variations, essential in tasks requiring both precision and creativity.
To demonstrate a basic generator implementation in Rust, the following example uses a pre-trained transformer model to generate text conditioned on external input. This code demonstrates a basic setup for using a language model (specifically the RWKV model) to generate text in response to a query in Rust. The model and tokenizer are loaded from specified file paths, and a user query is combined with additional retrieved context information. This combined text is tokenized, passed through the model, and then decoded to produce a generated response. The code is structured to use the candle_transformers library, although parts of the implementation are placeholders simulating model loading and text generation for demonstration.
[dependencies]
anyhow = "1.0.92"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-onnx = "0.7.2"
candle-transformers = "0.7.2"
hf-hub = "0.3.2"
use candle_transformers::models::rwkv_v6::Tokenizer;
use candle_core::Device;
use std::error::Error;
// Placeholder model structure for demonstration; replace with the actual supported model if available.
struct RWKVModel {
// Simulated structure; use actual methods or constructor if provided by `candle_transformers`
}
impl RWKVModel {
// Placeholder for loading and initializing a model
fn new(model_path: &str, _device: &Device) -> Result<Self, Box<dyn Error>> {
// Simulated load; replace with actual model loading if supported
println!("Model loaded from {}", model_path);
Ok(Self {})
}
fn forward(&self, input_tokens: &[u32]) -> Result<Vec<u32>, Box<dyn Error>> {
// Simulated forward pass; replace with actual model inference
Ok(input_tokens.to_vec())
}
}
fn main() -> Result<(), Box<dyn Error>> {
// Define paths for the model and tokenizer files
let model_path = "path/to/rwkv-model"; // Update with actual path
let tokenizer_path = "path/to/rwkv-tokenizer.json"; // Update with actual path
// Load the tokenizer
let tokenizer = Tokenizer::new(tokenizer_path)?;
// Initialize the RWKV model on CPU
let device = Device::Cpu;
let model = RWKVModel::new(model_path, &device)?;
// Define the user query and retrieved context
let query = "Explain the significance of Rust in system programming.";
let retrieved_info = "Rust is designed for memory safety and concurrency, making it highly suitable for systems programming.";
// Combine retrieved information with the query as input for the generator
let input_text = format!("Context: {} Query: {}", retrieved_info, query);
let input_tokens = tokenizer.encode(&input_text)?;
// Generate text based on the combined input
let response_tokens = model.forward(&input_tokens)?;
let response_text = tokenizer.decode(&response_tokens)?;
println!("Generated Response: {}", response_text);
Ok(())
}
The code first initializes paths for the model and tokenizer files and loads the tokenizer. The RWKV model is then loaded on the CPU device, though the device parameter is unused in this implementation, which is marked by prefixing it with an underscore. The user query and retrieved information are combined to create an input text, which is tokenized before being passed through the model’s forward method. This forward method simulates model inference by simply echoing the input tokens as output tokens. Finally, the response tokens are decoded back into text, and the generated response is printed. This structure is a foundation for building language model applications that combine retrieval-augmented generation (RAG) techniques by using a retrieved context alongside the query to improve response relevance.
Integrating retrieved information effectively often involves exploring different conditioning techniques. Concatenating retrieved information is a simple yet effective approach; however, for applications requiring deeper integration, embedding or attention-based methods can offer significant improvements. Embedding-based conditioning, for example, transforms both the query and the retrieved information into shared vector representations, allowing the generator to interpret semantic relationships between them. Attention mechanisms, by contrast, focus selectively on portions of the retrieved information during generation, reducing the likelihood of incorporating irrelevant details. These techniques optimize the generator’s response quality, ensuring it emphasizes relevant information while maintaining natural language flow.
Evaluating the generator’s performance in RAG systems involves assessing whether the generated text accurately reflects the retrieved information. For example, an evaluation metric for RAG responses could involve measuring coherence and factual alignment, where coherence assesses the fluency and logical structure of the generated text, and factual alignment measures the extent to which the generated content accurately incorporates retrieved data. Fine-tuning the generator on domain-specific datasets can further improve performance, as it enables the model to adapt to the linguistic style and terminology of the target domain, enhancing its ability to generate context-aware responses. Fine-tuning is particularly valuable in specialized fields like healthcare, where accurate terminology is crucial, or finance, where the generator must adapt to sector-specific language.
RAG systems with advanced generators are transforming multiple industries by enabling knowledge-grounded applications. For instance, in education, RAG-based tutoring systems provide personalized explanations by retrieving course-specific information and generating responses tailored to each student’s questions. Similarly, in customer service, RAG enables chatbots to deliver accurate and contextually relevant responses by retrieving support articles and integrating them into conversational replies. Recent advancements in RAG generators focus on improving conditioning methods, such as hybrid attention models that combine content attention with retrieval-based attention, allowing models to distinguish between general context and specific retrieved facts.
Rust’s performance and memory management make it ideal for deploying RAG generators, as efficient handling of model inference speeds up response times and reduces memory overhead. With its powerful concurrency support, Rust enables developers to run retrieval and generation in parallel, optimizing for applications where low latency is essential. Rust’s capabilities, combined with advanced conditioning techniques, provide a robust environment for deploying real-time, scalable RAG solutions.
Implementing a generator in Rust with the flexibility to integrate retrieved information effectively enhances the quality and applicability of RAG systems across domains. By experimenting with various conditioning techniques and adjusting model architectures, developers can optimize the generator’s accuracy, coherence, and relevance, providing a foundation for sophisticated, knowledge-grounded language models in diverse real-world applications. Through continued exploration of advanced generation techniques and conditioning strategies, Rust will play an instrumental role in evolving RAG capabilities, bringing context-aware, reliable text generation to the forefront of NLP innovation.
11.5. Integrating the Retriever and Generator Components
In a Retrieval-Augmented Generation (RAG) system, the interaction between the retriever and generator components is essential to produce high-quality, contextually relevant outputs. The retriever identifies relevant information from a knowledge base, which is then used by the generator to craft coherent and context-aware responses. This information flow begins with query processing, where user input is transformed into a query for the retriever. The retriever then selects pertinent information, and the generator incorporates this retrieved content into its output. Effective integration between the retriever and generator ensures that the RAG system provides users with accurate, reliable, and contextually enriched responses.
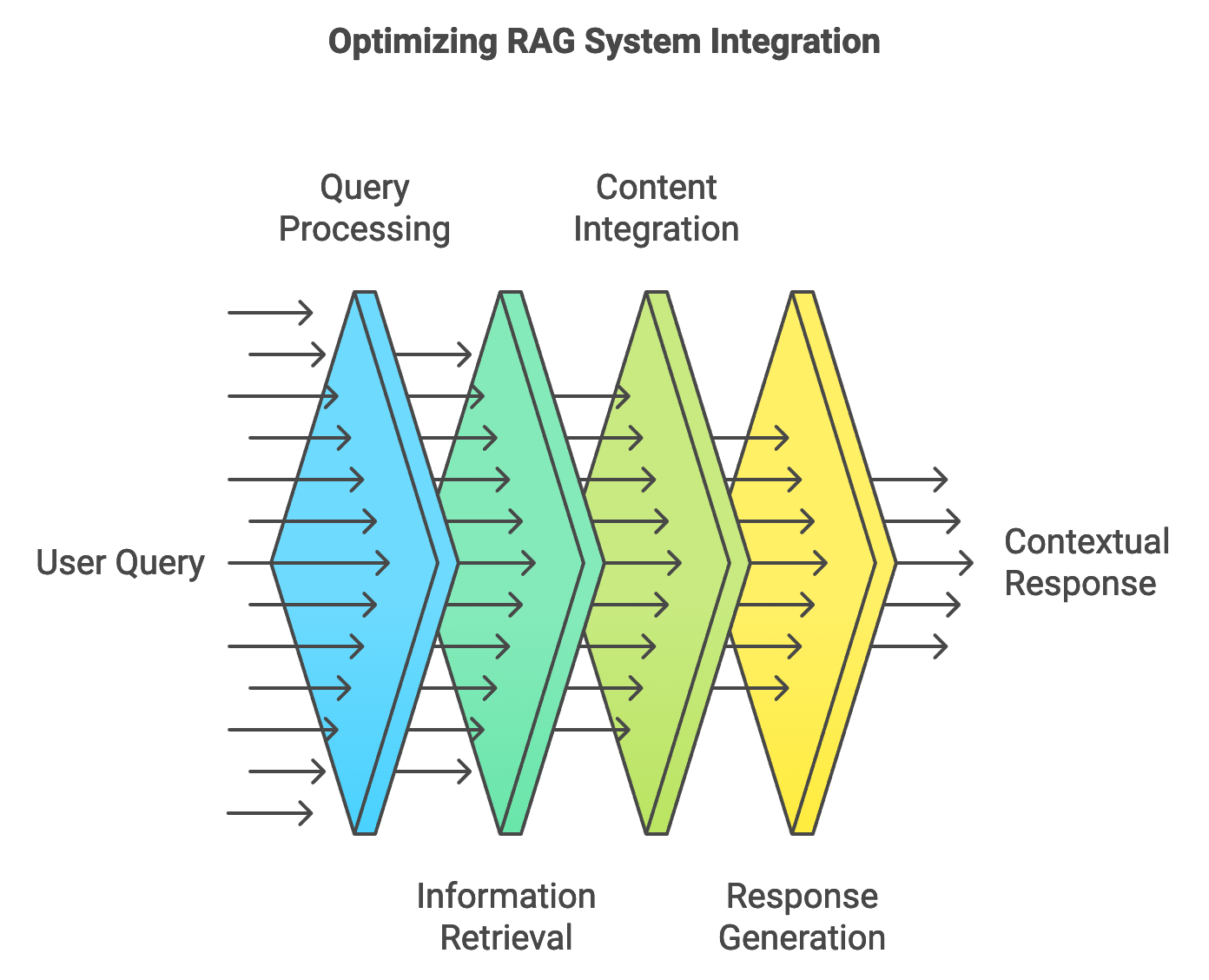
Figure 2: From user query to contextual response.
Different integration strategies, such as pipeline integration and end-to-end training, offer distinct advantages. Pipeline integration processes the retrieval and generation stages sequentially, where the retriever first identifies relevant content, which the generator then incorporates in its response. This approach is modular, allowing easy customization and separate fine-tuning of each component. End-to-end training, by contrast, allows the retriever and generator to be trained jointly, optimizing the overall system for the task at hand. Although end-to-end training can improve coherence and relevance, it often demands significant computational resources and complex training workflows. Choosing the appropriate integration strategy depends on the application’s requirements, as pipeline integration is typically faster to implement and modify, while end-to-end training may provide superior performance at the cost of increased computational complexity.
Balancing retrieval quality and generation fluency is a key challenge in integrating retrievers and generators, particularly in real-time applications where response time is crucial. High-quality retrieval ensures that the generator receives accurate, relevant information, but excessively detailed retrieval results can sometimes overwhelm the generator, reducing fluency and coherence in the output. Conversely, overly generalized retrieval may lead to vague responses that fail to address the user’s query adequately. Various optimization techniques, such as dynamic retrieval and iterative refinement, can help balance these aspects by adjusting the retrieval depth and selectively refining the generator’s conditioning on retrieved information. Dynamic retrieval, for example, allows the retriever to adjust the quantity and specificity of information based on the complexity of the query, ensuring that the generator is neither overloaded nor underinformed.
The RWKV V6 model is a Recurrent World Knowledge Vector Transformer, designed to handle sequential data and large context efficiently, making it suitable for tasks that benefit from long-context attention, such as natural language processing. Unlike traditional transformer models that rely on full self-attention, RWKV V6 uses recurrent neural network-like architectures with token-level recurrence, allowing it to scale effectively for long sequences without sacrificing performance. This structure makes it ideal for applications where a blend of recurrent and attention mechanisms can capture context over extended input sequences, while still leveraging the benefits of transformers. The code scenario presented here integrates RWKV V6 with the Tantivy search engine to build a basic Retrieval-Augmented Generation (RAG) system in Rust. In this setup, a retriever searches for relevant documents from an in-memory index based on a user query, while the RWKV model generates responses by using the retrieved information as context. This RAG configuration is useful for applications where a model needs to answer questions or provide summaries based on a predefined knowledge base.
[dependencies]
anyhow = "1.0.92"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-onnx = "0.7.2"
candle-transformers = "0.7.2"
hf-hub = "0.3.2"
tantivy = "0.22.0"
use candle_transformers::models::rwkv_v6::Tokenizer;
use candle_core::Device;
use tantivy::{schema::{Schema, STORED, TEXT}, doc, Index, IndexWriter};
use tantivy::collector::TopDocs;
use tantivy::query::QueryParser;
use tantivy::TantivyDocument;
use std::sync::{Arc, RwLock};
use std::thread;
use std::time::Duration;
use std::error::Error;
// Placeholder RWKV model structure for demonstration purposes
struct RWKVModel;
impl RWKVModel {
fn new(model_path: &str, _device: &Device) -> Result<Self, Box<dyn Error>> {
println!("Model loaded from {}", model_path);
Ok(Self {})
}
fn forward(&self, input_tokens: &[u32]) -> Result<Vec<u32>, Box<dyn Error>> {
Ok(input_tokens.to_vec())
}
}
// Function to retrieve information from Tantivy index based on a query
fn retrieve_information(index: &Index, query: &str) -> Result<String, Box<dyn Error>> {
let searcher = index.reader()?.searcher();
let query_parser = QueryParser::for_index(index, vec![index.schema().get_field("body").unwrap()]);
let parsed_query = query_parser.parse_query(query)?;
let top_docs = searcher.search(&parsed_query, &TopDocs::with_limit(5))?;
let mut retrieved_content = String::new();
for (_score, doc_address) in top_docs {
let doc: TantivyDocument = searcher.doc(doc_address)?; // Correct type for `doc`
if let Some(field_value) = doc.get_first(index.schema().get_field("body").unwrap()) {
if let tantivy::schema::OwnedValue::Str(text) = field_value {
retrieved_content.push_str(&text);
retrieved_content.push_str(" ");
}
}
}
Ok(retrieved_content.trim().to_string())
}
fn main() -> Result<(), Box<dyn Error>> {
// Initialize schema and create in-memory index
let mut schema_builder = Schema::builder();
let title = schema_builder.add_text_field("title", TEXT | STORED);
let body = schema_builder.add_text_field("body", TEXT | STORED);
let schema = schema_builder.build();
let index = Index::create_in_ram(schema);
let index_writer: Arc<RwLock<IndexWriter>> = Arc::new(RwLock::new(index.writer(50_000_000)?));
// Define paths for the model and tokenizer files
let model_path = "path/to/rwkv-model";
let tokenizer_path = "path/to/rwkv-tokenizer.json"; // Update to the actual path
// Print debug information for tokenizer path
println!("Attempting to load tokenizer from: {}", tokenizer_path);
// Load the tokenizer
let tokenizer = match Tokenizer::new(tokenizer_path) {
Ok(tokenizer) => tokenizer,
Err(e) => {
eprintln!("Failed to load tokenizer: {:?}", e);
return Err(Box::new(e));
}
};
// Initialize the RWKV model on CPU
let device = Device::Cpu;
let model = RWKVModel::new(model_path, &device)?;
// Thread 1: Indexing documents concurrently
let index_writer_clone_1 = index_writer.clone();
thread::spawn(move || {
for i in 0..50 {
let _ = index_writer_clone_1.write().unwrap().add_document(doc!(
title => "Of Mice and Men",
body => "A few miles south of Soledad, the Salinas River drops in close to the hillside bank..."
));
println!("Indexed doc {i} from thread 1");
thread::sleep(Duration::from_millis(20));
}
});
// Thread 2: Another indexing thread
let index_writer_clone_2 = index_writer.clone();
thread::spawn(move || {
for i in 0..50 {
let _ = index_writer_clone_2.write().unwrap().add_document(doc!(
title => "Manufacturing Consent",
body => "Some great book description..."
));
println!("Indexed doc {i} from thread 2");
thread::sleep(Duration::from_millis(20));
}
});
// Main thread: Periodic commit
let index_writer_clone = index_writer.clone();
thread::spawn(move || {
for _ in 0..5 {
let _ = index_writer_clone.write().unwrap().commit();
println!("Committed index changes.");
thread::sleep(Duration::from_secs(1));
}
});
// Simulate RAG-based response generation after indexing
thread::sleep(Duration::from_secs(6)); // Wait for indexing threads to finish
// User query example
let user_query = "Why is Rust popular in systems programming?";
let retrieved_info = retrieve_information(&index, user_query)?;
// Combine the retrieved information with the user query
let input_text = format!("Context: {} Query: {}", retrieved_info, user_query);
let input_tokens = tokenizer.encode(&input_text)?;
// Generate response using the model
let response_tokens = model.forward(&input_tokens)?;
let response_text = tokenizer.decode(&response_tokens)?;
println!("Generated Response: {}", response_text);
Ok(())
}
In the code, we first define a schema and set up a Tantivy in-memory index to store documents. Multiple threads are used to add documents concurrently, with periodic commits to save changes to the index. The retriever function, retrieve_information, searches the index based on a user query, retrieving relevant content from stored documents. A tokenizer is loaded to handle encoding and decoding of input and output text for the RWKV V6 model. After combining the retrieved information with the user query, the encoded input is passed to the RWKV model for generating a response, which is then decoded and printed. This structure illustrates a basic pipeline for using a pre-trained generative model with a retrieval component, simulating an interactive question-answering system.
Experimenting with different integration strategies, such as pipeline versus end-to-end, reveals their impact on system performance. In the pipeline approach, the retriever and generator work independently, allowing each component to be optimized separately. This modular setup facilitates faster inference times, as each component operates with minimal dependency on the other. However, in applications requiring more cohesive responses, end-to-end training may provide advantages by jointly optimizing the retrieval and generation processes. This strategy enables the generator to learn to selectively attend to retrieval results, improving coherence and relevance. Although more complex, end-to-end integration often enhances user satisfaction in applications like dialogue systems, where the interaction between retrieval and generation must be seamless.
Testing the integrated RAG system on real-world tasks, such as open-domain question answering, provides a practical measure of its effectiveness. By simulating queries typical of the application’s target environment, developers can evaluate how accurately and fluently the system addresses user needs. For example, in customer support applications, the system’s ability to retrieve and generate accurate responses to common questions can significantly impact user experience. Evaluation metrics, such as retrieval accuracy, generation fluency, and response relevance, help quantify performance and guide further optimization.
RAG systems have transformative potential across numerous industries. In healthcare, integrating retrievers with medical literature databases allows RAG-based systems to generate informed responses for clinicians, streamlining information retrieval and decision support. Similarly, in legal research, RAG enables comprehensive case analysis by retrieving relevant precedents and synthesizing them into concise, contextually accurate summaries. Industry trends indicate an increasing interest in dynamic retrieval methods that adjust the retrieval strategy based on the user’s query context, as well as hybrid integration approaches that balance modularity with coherence.
Rust’s strengths in concurrency and low-level memory management provide a foundation for scaling RAG systems, ensuring high performance even in demanding applications. By optimizing retriever-generator integration in Rust, developers can implement efficient, responsive RAG systems capable of real-time, large-scale deployments. Rust’s robust environment supports the modularity required for pipeline integrations while enabling high-performance, end-to-end RAG systems. This integration of retrieval and generation, when optimized, results in an agile and capable RAG system, opening new possibilities for contextual, knowledge-augmented NLP applications across diverse fields.
11.6. Fine-Tuning and Optimizing RAG Systems
Fine-tuning Retrieval-Augmented Generation (RAG) systems enables the retriever and generator components to adapt to specific tasks or domains, enhancing both accuracy and relevance. In a RAG system, fine-tuning aligns the retrieval component with the vocabulary and content style of the target domain, ensuring that retrieved information is pertinent. The generator, when fine-tuned, can respond coherently within domain-specific language constraints, improving the quality of generated text. The process involves adjusting both components by training on labeled data, optimizing parameters to match domain-specific requirements without the computational demands of training from scratch. This adaptation allows RAG systems to offer tailored outputs in fields like healthcare, where responses must align with medical terminology, or finance, where accurate and timely information retrieval and generation are critical.
Figure 3: From initialization to optimized RAG outputs.
Optimization techniques further enhance the efficiency and accuracy of RAG systems. Hyperparameter tuning, for instance, adjusts learning rates, batch sizes, and other training parameters to balance retrieval accuracy with generation fluency. Model pruning, which involves removing redundant neurons or connections from the model, reduces memory requirements and inference time without significantly impacting performance. Quantization is another effective technique, converting high-precision model weights into lower precision formats to decrease computational load. This reduction is especially valuable for deploying RAG systems on edge devices or environments with limited processing power. Combined, these optimizations allow RAG systems to operate effectively across various applications, from real-time chatbots to resource-constrained customer service platforms.
Continuous monitoring and updating are essential to maintaining the performance of a RAG system over time. Language models can experience model drift, where performance declines as the target domain or language trends evolve. Regular evaluations help identify when the model needs retraining or updates. An adaptive retrieval approach, for example, dynamically adjusts retrieval thresholds based on query complexity, ensuring that the system continues to retrieve the most relevant information. Real-time fine-tuning, where the model incrementally learns from user interactions or recent data, also supports long-term accuracy and adaptability in dynamic environments.
Choosing between fine-tuning and training a RAG system from scratch depends largely on resource availability and the level of specialization required. Fine-tuning offers a low-cost, high-efficiency solution for most applications, using pre-trained models as a foundation and applying task-specific adjustments. However, training from scratch allows for greater control over the model’s architecture and knowledge base, though it demands significantly more data and computational power. Fine-tuning typically balances flexibility with resource efficiency, especially beneficial in scenarios where large-scale retraining is impractical.
This Rust code demonstrates a basic setup for RAG system, simulating a pipeline where a retriever retrieves relevant documents, and a generator produces responses based on the retrieved context. The retriever is built with the Tantivy search engine using BM25 ranking for effective document retrieval. In this setup, the retriever searches through indexed documents to retrieve context related to a user’s question. A simulated GPT-based model then generates a response tailored to the input query and the retrieved information, making this approach useful for applications like question-answering within a specific domain.riever and GPT-based generator for a specific question-answering task. This implementation first fine-tunes the retriever to optimize information retrieval within the target domain, then fine-tunes the generator to adapt its response style to domain-specific queries.
[dependencies]
anyhow = "1.0.92"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-onnx = "0.7.2"
candle-transformers = "0.7.2"
hf-hub = "0.3.2"
tantivy = "0.22.0"
use tantivy::schema::*;
use tantivy::tokenizer::NgramTokenizer;
use tantivy::collector::TopDocs;
use tantivy::query::QueryParser;
use tantivy::{doc, Index, IndexWriter};
use tantivy::TantivyDocument;
use std::error::Error;
// Placeholder struct to simulate a GPT-based generator model
struct SimulatedGPTModel;
impl SimulatedGPTModel {
fn new() -> Self {
SimulatedGPTModel
}
fn generate_response(&self, context: &str, question: &str) -> Result<String, Box<dyn Error>> {
// Simulating a GPT response by echoing the context and question.
Ok(format!("Generated response based on context: '{}', question: '{}'", context, question))
}
}
// Function to retrieve information using BM25-based retriever
fn retrieve_information(index: &Index, query_str: &str, schema: &Schema) -> Result<String, Box<dyn Error>> {
let reader = index.reader()?;
let searcher = reader.searcher();
// Using the QueryParser to parse the input query
let title_field = schema.get_field("title").unwrap();
let body_field = schema.get_field("body").unwrap();
let query_parser = QueryParser::for_index(index, vec![title_field, body_field]);
let query = query_parser.parse_query(query_str)?;
// Perform the search with BM25 ranking
let top_docs = searcher.search(&query, &TopDocs::with_limit(5))?;
let mut context = String::new();
for (_, doc_address) in top_docs {
let retrieved_doc: TantivyDocument = searcher.doc(doc_address)?; // Explicit type for `retrieved_doc`
if let Some(field) = retrieved_doc.get_first(body_field) {
if let tantivy::schema::OwnedValue::Str(text) = field {
context.push_str(&text);
context.push_str(" ");
}
}
}
Ok(context.trim().to_string())
}
fn main() -> Result<(), Box<dyn Error>> {
// Set up schema for Tantivy
let mut schema_builder = Schema::builder();
let text_field_indexing = TextFieldIndexing::default()
.set_tokenizer("ngram3")
.set_index_option(IndexRecordOption::WithFreqsAndPositions);
let text_options = TextOptions::default()
.set_indexing_options(text_field_indexing)
.set_stored();
let title = schema_builder.add_text_field("title", text_options);
let body = schema_builder.add_text_field("body", TEXT);
let schema = schema_builder.build();
// Create index in RAM and register custom tokenizer
let index = Index::create_in_ram(schema.clone());
index
.tokenizers()
.register("ngram3", NgramTokenizer::new(3, 3, false).unwrap());
// Insert documents to the index
let mut index_writer: IndexWriter = index.writer(50_000_000)?;
index_writer.add_document(doc!(
title => "The Old Man and the Sea",
body => "An old man fishes alone in a skiff in the Gulf Stream, hoping for a big catch."
))?;
index_writer.add_document(doc!(
title => "Of Mice and Men",
body => "A river and mountains provide the backdrop for a tale of friendship and hardship."
))?;
index_writer.add_document(doc!(
title => "Frankenstein",
body => "A scientific endeavor takes a dark turn, with unforeseen consequences for its creator."
))?;
index_writer.commit()?;
// Initialize the simulated GPT-based generator model
let generator = SimulatedGPTModel::new();
// Sample question for RAG-based QA
let question = "What is the story of Frankenstein about?";
// Retrieve context from the index using BM25
let context = retrieve_information(&index, &question, &schema)?;
// Generate response using the simulated GPT model
let response = generator.generate_response(&context, &question)?;
println!("Generated Response: {}", response);
Ok(())
}
The code begins by defining a schema for document indexing, specifying a title field with a custom 3-gram tokenizer and a body field for full-text search. Documents are then indexed into a Tantivy in-memory index. The retrieve_information function performs a BM25 search on this index, using the input question to find top-matching documents and concatenate relevant text from their body fields. A simulated GPT model, represented by the SimulatedGPTModel struct, formats a response by combining the retrieved context with the question. The main function demonstrates the full flow, creating a sample question, retrieving context, and generating a simulated response. This structure provides a foundational RAG system that can be expanded with an actual GPT model for generation.
Experimenting with various optimization techniques, such as hyperparameter tuning and model pruning, further enhances system performance. Hyperparameter tuning in Rust, for example, involves systematically adjusting parameters like batch size and learning rate to maximize both accuracy and inference speed. Model pruning and quantization, meanwhile, streamline the RAG system’s memory and processing requirements, particularly valuable in environments where resources are limited. The combination of these techniques ensures that RAG systems remain efficient and responsive, meeting the requirements of latency-sensitive applications like interactive chatbots and on-device processing.
Setting up a monitoring framework in Rust allows for continuous performance tracking, ensuring that the RAG system remains effective over time. By implementing performance metrics like response latency, retrieval accuracy, and generation quality, developers can monitor model drift and other degradation indicators. Rust’s concurrency support allows this monitoring framework to operate alongside RAG processes without impacting performance, providing real-time insights that inform system updates. For instance, if the retrieval quality declines, the system could dynamically adjust the retrieval threshold or initiate a fine-tuning cycle to refresh the retriever’s knowledge base.
In real-world applications, fine-tuning and optimizing RAG systems deliver substantial benefits. In finance, for instance, real-time question-answering systems rely on RAG to retrieve up-to-date market data and generate insights tailored to analyst queries. In healthcare, fine-tuning RAG systems on medical literature enables clinical support tools to deliver precise, context-sensitive responses. Industry trends in RAG optimization highlight techniques like adaptive retrieval and real-time fine-tuning, which continuously adjust model behavior based on incoming data, keeping RAG systems relevant and efficient in dynamic environments.
Rust’s high-performance capabilities and memory safety make it an ideal choice for optimizing RAG systems. By fine-tuning retriever and generator components, implementing hyperparameter optimization, and setting up monitoring, Rust provides a comprehensive framework for developing robust, adaptable RAG applications. The result is a high-performance RAG system capable of maintaining accuracy, speed, and relevance across various domains and deployment scenarios, setting a new standard for efficient, knowledge-grounded NLP solutions.
11.7. Deploying RAG Systems Using Rust
Deploying Retrieval-Augmented Generation (RAG) systems introduces unique challenges and considerations due to the complex interaction between retrieval and generation components. The deployment process must address scalability, latency, and resource management to ensure that RAG systems deliver accurate and timely responses. Since these systems often operate in high-demand environments, efficient resource utilization and responsive scaling are critical for maintaining performance under varying workloads. Deployment environments for RAG systems range from cloud-based platforms to on-premises and edge deployments, each offering specific advantages. Cloud platforms allow rapid scalability and offer managed services, making them ideal for large-scale applications with fluctuating demand. On-premises deployments, while limited in scalability, provide greater data control and security, suitable for sectors like healthcare and finance. Edge deployments, meanwhile, deliver low-latency processing by bringing computation closer to the end user, enhancing responsiveness in real-time applications.
Figure 4: Flow of RAG deployment.
Monitoring and maintaining deployed RAG systems are essential for handling data drift and model updates. As user interactions evolve, RAG systems must adapt to reflect changes in domain-specific terminology, query patterns, and knowledge sources. Continuous monitoring of system metrics, such as retrieval latency, generation accuracy, and response times, helps detect early signs of model drift, guiding timely retraining or updates. Real-time performance monitoring also supports the detection of bottlenecks, especially in applications with latency-sensitive requirements, enabling developers to optimize retrieval processes, adjust caching mechanisms, or scale the system dynamically to maintain performance.
Choosing the appropriate deployment environment requires an understanding of the trade-offs between cost, performance, and scalability. Cloud-based RAG deployments benefit from flexible scaling and managed infrastructure, making them suitable for applications with unpredictable or high demand. However, these solutions incur operational costs tied to resource usage, which can be significant for continuous, real-time applications. In contrast, edge deployments reduce network latency by processing queries locally, which is advantageous for applications like smart assistants or autonomous systems where immediate response is critical. The trade-off here is limited computational resources, necessitating efficient retrieval and generation optimizations, such as model quantization and reduced parameter models, to achieve desired performance without exceeding device capacity.
The deployment of RAG systems in real-time applications introduces additional complexities related to retrieval and generation latency. Since these systems rely on retrieving and synthesizing information, any delay in retrieval can cascade, impacting the overall response time. Techniques such as asynchronous retrieval and parallel processing help manage these latencies by enabling the retriever to handle multiple queries concurrently. Rust’s concurrency features, including asynchronous programming and multi-threading, play a vital role here, allowing RAG systems to optimize retrieval and generation workflows for minimal latency. In applications like customer support, where delays in query processing can affect user experience, these optimizations are crucial for maintaining seamless interaction.
Ensuring the robustness and reliability of deployed RAG systems requires strategies such as redundancy, load balancing, and failover mechanisms. Redundancy, where multiple retrievers or generators are deployed simultaneously, ensures that the system remains operational even if a component fails. Load balancing distributes incoming queries evenly across retrievers and generators, preventing any single instance from becoming a bottleneck, which is especially relevant in cloud-based and high-demand environments. Failover mechanisms automatically redirect requests to backup instances if a primary retriever or generator encounters issues, enhancing reliability. Implementing these strategies helps maintain performance consistency, ensuring that RAG systems are dependable in production, even under heavy loads.
This Rust code demonstrates a basic setup for a RAG system, implemented with Tantivy and Rocket. RAG systems are widely used for question-answering and interactive applications where relevant information retrieval is combined with a generative response. This code showcases how to use a BM25-based retrieval model with Tantivy, a fast, full-text search engine library, and simulate a generative model using Rocket as the HTTP server framework. Such a system allows users to query text data, retrieves related information, and generates a response based on both the retrieved context and the user’s input.
The RAG pipeline in this code starts by indexing documents in Tantivy, including titles and bodies of text. The system then uses the retrieval component to fetch relevant documents based on a user query, simulating the way RAG systems first gather context before generating a final response. In this case, the generative component is simulated using a basic Rust struct that formats the response by combining the context and user query. By building this RAG service as an HTTP API, users can interact with the system by sending POST requests to a specific endpoint with a query and receiving generated responses in JSON format.
[dependencies]
anyhow = "1.0.92"
hf-hub = "0.3.2"
simple_logger = "5.0.0"
tantivy = "0.22.0"
tch = "0.12.0"
rocket = { version = "0.5.1", features = ["json"] }
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
tokio = { version = "1.41.0", features = ["full"] }
log = "0.4.22"
use rocket::serde::{json::Json, Deserialize, Serialize};
use rocket::{post, routes};
use tantivy::schema::*;
use tantivy::tokenizer::NgramTokenizer;
use tantivy::collector::TopDocs;
use tantivy::query::QueryParser;
use tantivy::{doc, Index, IndexWriter};
use tantivy::TantivyDocument;
use std::error::Error;
use std::sync::Arc;
use tokio::sync::RwLock;
use log::info;
use simple_logger;
// Simulated GPT-based generator model
#[derive(Clone)]
struct SimulatedGPTModel;
impl SimulatedGPTModel {
fn new() -> Self {
SimulatedGPTModel
}
fn generate_response(&self, context: &str, question: &str) -> String {
format!("Generated response based on context: '{}', question: '{}'", context, question)
}
}
// RAGService struct to handle retrieval and generation requests
#[derive(Clone)]
struct RAGService {
index: Arc<Index>,
schema: Schema,
generator: SimulatedGPTModel,
}
impl RAGService {
fn new(index: Index, schema: Schema) -> Self {
let generator = SimulatedGPTModel::new();
Self {
index: Arc::new(index),
schema,
generator,
}
}
async fn retrieve(&self, query_str: &str) -> Result<String, Box<dyn Error>> {
let reader = self.index.reader()?;
let searcher = reader.searcher();
let title_field = self.schema.get_field("title").unwrap();
let body_field = self.schema.get_field("body").unwrap();
let query_parser = QueryParser::for_index(&self.index, vec![title_field, body_field]);
let query = query_parser.parse_query(query_str)?;
let top_docs = searcher.search(&query, &TopDocs::with_limit(5))?;
let mut context = String::new();
for (_, doc_address) in top_docs {
let retrieved_doc: TantivyDocument = searcher.doc(doc_address)?;
if let Some(field) = retrieved_doc.get_first(body_field) {
if let tantivy::schema::OwnedValue::Str(text) = field {
context.push_str(&text);
context.push_str(" ");
}
}
}
Ok(context.trim().to_string())
}
fn generate(&self, context: &str, question: &str) -> String {
self.generator.generate_response(context, question)
}
}
#[derive(Deserialize)]
struct QueryParams {
question: String,
}
#[derive(Serialize)]
struct Response {
response: String,
}
#[post("/rag", data = "<params>")]
async fn rag_endpoint(
params: Json<QueryParams>,
service: &rocket::State<Arc<RwLock<RAGService>>>,
) -> Result<Json<Response>, String> {
let start = std::time::Instant::now();
let service = service.read().await;
// Retrieval
let context = match service.retrieve(¶ms.question).await {
Ok(context) => context,
Err(e) => {
log::error!("Error during retrieval: {:?}", e);
return Err("Retrieval error".to_string());
}
};
// Generation
let response_text = service.generate(&context, ¶ms.question);
let duration = start.elapsed();
info!("Processed request in {:?}", duration);
Ok(Json(Response { response: response_text }))
}
#[rocket::main]
async fn main() -> Result<(), Box<dyn Error>> {
simple_logger::init().unwrap();
// Define Tantivy schema and setup index
let mut schema_builder = Schema::builder();
let text_field_indexing = TextFieldIndexing::default()
.set_tokenizer("ngram3")
.set_index_option(IndexRecordOption::WithFreqsAndPositions);
let text_options = TextOptions::default()
.set_indexing_options(text_field_indexing)
.set_stored();
let title = schema_builder.add_text_field("title", text_options);
let body = schema_builder.add_text_field("body", TEXT);
let schema = schema_builder.build();
let index = Index::create_in_ram(schema.clone());
index
.tokenizers()
.register("ngram3", NgramTokenizer::new(3, 3, false).unwrap());
// Insert documents into Tantivy index
let mut index_writer: IndexWriter = index.writer(50_000_000)?;
index_writer.add_document(doc!(
title => "The Old Man and the Sea",
body => "An old man fishes alone in a skiff in the Gulf Stream, hoping for a big catch."
))?;
index_writer.add_document(doc!(
title => "Of Mice and Men",
body => "A river and mountains provide the backdrop for a tale of friendship and hardship."
))?;
index_writer.add_document(doc!(
title => "Frankenstein",
body => "A scientific endeavor takes a dark turn, with unforeseen consequences for its creator."
))?;
index_writer.commit()?;
// Initialize the RAG service with the index and generator
let rag_service = Arc::new(RwLock::new(RAGService::new(index, schema)));
// Start the Rocket server
info!("Starting RAG server on port 8000");
rocket::build()
.manage(rag_service)
.mount("/", routes![rag_endpoint])
.launch()
.await?;
Ok(())
}
The code initializes a Tantivy index and defines a schema for documents with fields like title and body. An RAGService struct encapsulates both the retrieval and generation functionalities. The Rocket server exposes an endpoint at /rag where users can send queries. The retrieval process fetches context based on the query, and the SimulatedGPTModel struct formats a response. This implementation provides a foundational RAG setup in Rust, allowing for further expansion with actual generative models or integration with more advanced retrieval and scoring techniques.
Experimenting with deployment strategies, such as deploying RAG systems on cloud platforms versus edge devices, helps evaluate performance trade-offs. In cloud deployments, where resources are scalable, the system can handle high query volumes, making it suitable for large organizations. Edge deployments, by contrast, prioritize local processing to reduce latency, making them ideal for applications requiring rapid, on-device responses, such as personal assistants or mobile apps. Monitoring the impact of these deployments on latency, accuracy, and resource usage provides valuable data to inform deployment decisions.
In a production environment, ongoing monitoring is crucial to ensure that the RAG system remains performant and relevant. Tracking metrics like retrieval latency, model accuracy, and resource utilization helps developers detect potential bottlenecks or performance degradation early. For instance, an increase in retrieval latency may indicate an overload in query processing, prompting adjustments in resource allocation or optimization of retrieval algorithms. Rust’s efficient concurrency handling and memory safety allow this monitoring framework to operate in tandem with the RAG system without impacting performance, supporting the system’s long-term robustness.
Deploying RAG systems has transformative potential across industries. In financial services, RAG systems can support analysts by retrieving and generating timely insights on market data and trends. In healthcare, edge-deployed RAG systems offer immediate, knowledge-grounded responses to clinicians, providing decision support in real-time. Trends in RAG deployment emphasize distributed architecture and hybrid cloud-edge models, which combine the scalability of cloud resources with the responsiveness of edge processing.
Rust’s efficiency and memory control offer an optimal foundation for deploying scalable RAG systems across various deployment environments. By implementing robust deployment pipelines, real-time monitoring, and adaptive performance adjustments, Rust allows developers to build resilient, high-performance RAG applications. This combination of scalability, responsiveness, and observability positions Rust-based RAG systems as a powerful solution for real-world, knowledge-driven applications, pushing the boundaries of NLP innovation.
11.8. Challenges and Future Directions in RAG
Developing and deploying Retrieval-Augmented Generation (RAG) systems presents several challenges that continue to shape the trajectory of RAG technology. Scalability, for instance, remains a pressing concern as RAG systems must handle substantial data volumes, requiring efficient resource management and distributed processing. Retrieval accuracy is another critical area, as the quality of retrieved information directly impacts the coherence and relevance of generated outputs. Low retrieval precision can lead to irrelevant or incomplete information being passed to the generator, diminishing response quality. Furthermore, integrating retrieval and generation components into a cohesive pipeline often involves complex coordination, especially in real-time systems where latency can become a bottleneck. Achieving seamless integration is essential for applications that demand fast, accurate responses, requiring optimization strategies and advanced concurrency control.
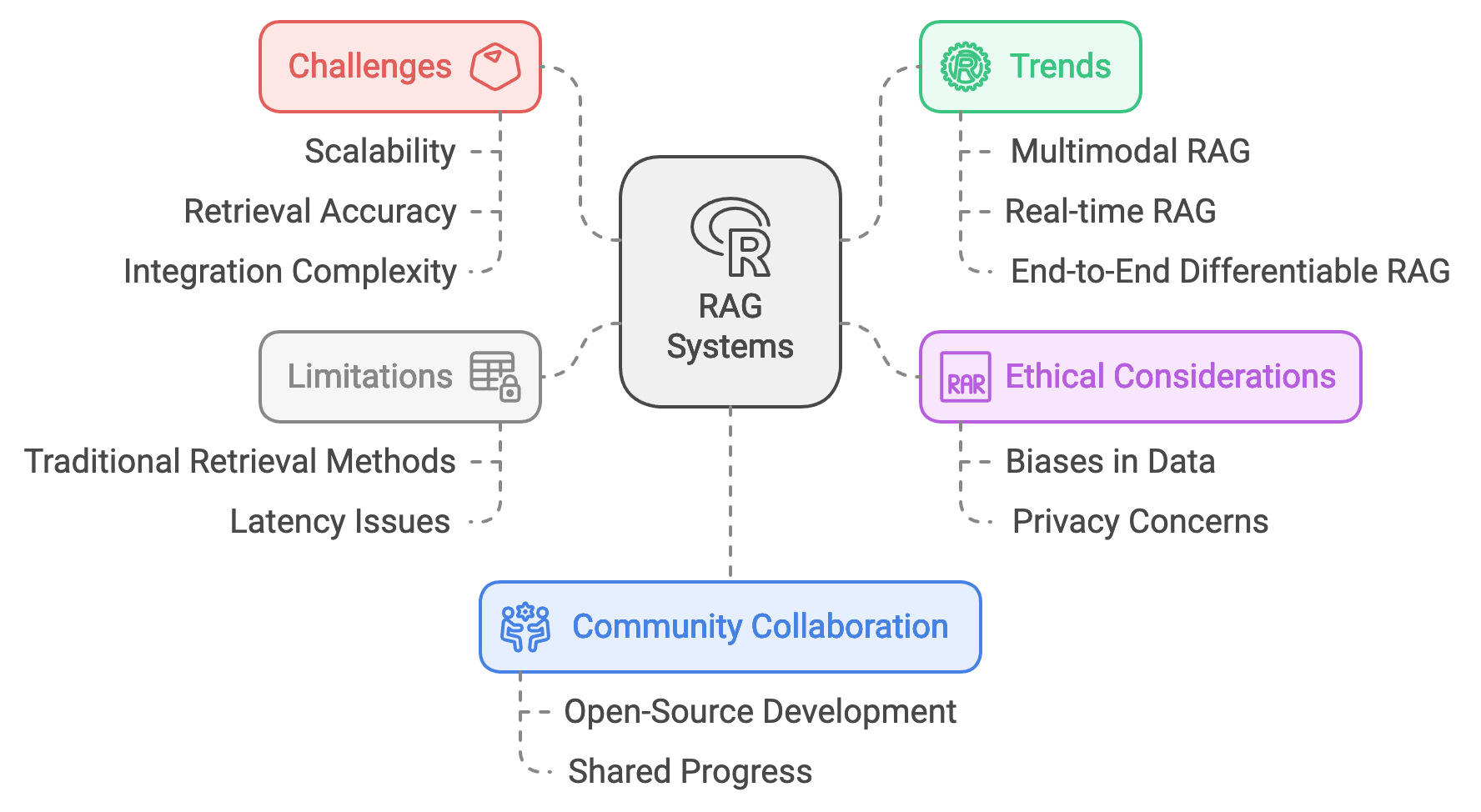
Figure 5: Challenges and future directions of RAG.
Emerging trends in RAG suggest exciting developments on the horizon. Multimodal RAG, which combines textual input with other data types like images or audio, is gaining traction as a way to enrich the contextual relevance of responses, particularly in domains like autonomous systems or interactive media. Real-time RAG represents another frontier, where rapid response times are paramount for applications like virtual assistants and customer support chatbots. Additionally, end-to-end differentiable RAG systems, which allow for joint optimization of retrieval and generation through backpropagation, hold promise for enhancing model coherence and retrieval quality in a unified training loop. This approach enables models to learn which retrieval strategies best support the generation process, creating a feedback loop that refines both components in tandem.
Ethical considerations are also central to the evolution of RAG technology, especially given the potential for biases in retrieved data to influence generated responses. RAG systems are susceptible to propagating misinformation when the underlying retrieval data contains inaccuracies or biases, amplifying the risk of harmful outputs. Privacy concerns are equally significant, as RAG systems often interact with sensitive or proprietary data, necessitating strict adherence to privacy-preserving techniques. Encryption, data minimization, and secure access controls are essential to ensuring that RAG systems respect user privacy, particularly in sectors like healthcare and finance where confidentiality is paramount.
The limitations of current RAG approaches highlight areas ripe for innovation. Traditional retrieval methods, while effective, often struggle with nuance and context, making it difficult to retrieve information that is both relevant and precise in complex scenarios. Innovations such as context-aware retrieval algorithms and hybrid sparse-dense retrieval models can improve accuracy by capturing the intricate relationships between query terms and document content. Similarly, latency remains a persistent issue in large-scale RAG systems, where high query volumes can lead to processing delays. Rust’s concurrency capabilities offer a promising solution, as efficient parallelization and asynchronous retrieval processes can reduce latency, improving response times in real-time applications.
Community collaboration and open-source development play crucial roles in advancing RAG technology. The open-source model facilitates shared progress and transparency, as developers contribute improvements and address common challenges collectively. By pooling resources and expertise, the community can accelerate the adoption of innovative retrieval algorithms, streamline deployment pipelines, and develop best practices for RAG optimization. Open-source initiatives also help mitigate ethical concerns by fostering transparency, as contributors can audit code for potential biases and suggest improvements, creating a more equitable and trustworthy technology foundation.
RAG systems hold long-term implications for society, particularly regarding information accessibility and the potential for misuse. As RAG systems become more sophisticated, they can democratize access to knowledge, providing tailored responses that help users navigate vast information landscapes efficiently. However, the technology’s capability for rapid, personalized content generation also raises concerns about misuse. There is potential for RAG systems to be co-opted for generating persuasive misinformation or privacy-invasive applications, underscoring the need for ethical guidelines and accountability measures. Responsible development and deployment practices, bolstered by ethical considerations and transparency, will be essential to ensuring RAG systems benefit society at large.
Experimenting with advanced features of Rust and RAG opens opportunities to push the boundaries of RAG capabilities. Integrating multimodal inputs, for instance, requires handling different data formats within the same retrieval and generation pipeline. This Rust code demonstrates a multimodal RAG system that uses Tantivy for retrieval and simulates a generative model. It combines textual and image features to enhance the context for information retrieval and generation. The code builds an in-memory index with sample products, each containing a product ID, descriptive text, and an associated image ID. Using Tantivy's indexing and query capabilities, the code retrieves relevant documents based on a query and ranks them by price, while also providing image-related information in the retrieval process.
use std::cmp::Reverse;
use std::collections::{HashMap, HashSet};
use std::sync::{Arc, RwLock, Weak};
use tantivy::collector::TopDocs;
use tantivy::index::SegmentId;
use tantivy::query::QueryParser;
use tantivy::schema::{Schema, FAST, TEXT, STRING};
use tantivy::{
doc, DocId, Index, IndexWriter, Opstamp, Searcher, SearcherGeneration, SegmentReader, Warmer,
TantivyDocument,
};
type ProductId = u64;
type Price = u32;
// Simulate a multimodal feature fetcher for price and image data.
pub trait MultimodalFeatureFetcher: Send + Sync + 'static {
fn fetch_prices(&self, product_ids: &[ProductId]) -> Vec<Price>;
fn fetch_image_features(&self, product_ids: &[ProductId]) -> Vec<String>; // Image IDs as strings
}
type SegmentKey = (SegmentId, Option<Opstamp>);
struct DynamicMultimodalColumn {
field: String,
price_cache: RwLock<HashMap<SegmentKey, Arc<Vec<Price>>>>,
image_cache: RwLock<HashMap<SegmentKey, Arc<Vec<String>>>>, // Cache for image data
feature_fetcher: Box<dyn MultimodalFeatureFetcher>,
}
impl DynamicMultimodalColumn {
pub fn with_product_id_field<T: MultimodalFeatureFetcher>(field: String, feature_fetcher: T) -> Self {
DynamicMultimodalColumn {
field,
price_cache: Default::default(),
image_cache: Default::default(),
feature_fetcher: Box::new(feature_fetcher),
}
}
pub fn multimodal_data_for_segment(&self, segment_reader: &SegmentReader) -> (Option<Arc<Vec<Price>>>, Option<Arc<Vec<String>>>) {
let segment_key = (segment_reader.segment_id(), segment_reader.delete_opstamp());
let prices = self.price_cache.read().unwrap().get(&segment_key).cloned();
let images = self.image_cache.read().unwrap().get(&segment_key).cloned();
(prices, images)
}
}
impl Warmer for DynamicMultimodalColumn {
fn warm(&self, searcher: &Searcher) -> tantivy::Result<()> {
for segment in searcher.segment_readers() {
let product_id_reader = segment
.fast_fields()
.u64(&self.field)?
.first_or_default_col(0);
let product_ids: Vec<ProductId> = segment
.doc_ids_alive()
.map(|doc| product_id_reader.get_val(doc))
.collect();
// Fetch prices and image features
let prices = self.feature_fetcher.fetch_prices(&product_ids);
let images = self.feature_fetcher.fetch_image_features(&product_ids);
let prices: Vec<Price> = prices.into_iter().collect();
let images: Vec<String> = images.into_iter().collect();
let key = (segment.segment_id(), segment.delete_opstamp());
self.price_cache.write().unwrap().insert(key.clone(), Arc::new(prices));
self.image_cache.write().unwrap().insert(key, Arc::new(images));
}
Ok(())
}
fn garbage_collect(&self, live_generations: &[&SearcherGeneration]) {
let live_keys: HashSet<SegmentKey> = live_generations
.iter()
.flat_map(|gen| gen.segments())
.map(|(&segment_id, &opstamp)| (segment_id, opstamp))
.collect();
self.price_cache.write().unwrap().retain(|key, _| live_keys.contains(key));
self.image_cache.write().unwrap().retain(|key, _| live_keys.contains(key));
}
}
// External source for multimodal data (text and image features)
#[derive(Default, Clone)]
pub struct ExternalFeatureTable {
prices: Arc<RwLock<HashMap<ProductId, Price>>>,
image_features: Arc<RwLock<HashMap<ProductId, String>>>,
}
impl ExternalFeatureTable {
pub fn update_price(&self, product_id: ProductId, price: Price) {
self.prices.write().unwrap().insert(product_id, price);
}
pub fn update_image_feature(&self, product_id: ProductId, image_id: String) {
self.image_features.write().unwrap().insert(product_id, image_id);
}
}
impl MultimodalFeatureFetcher for ExternalFeatureTable {
fn fetch_prices(&self, product_ids: &[ProductId]) -> Vec<Price> {
let prices = self.prices.read().unwrap();
product_ids.iter().map(|id| *prices.get(id).unwrap_or(&0)).collect()
}
fn fetch_image_features(&self, product_ids: &[ProductId]) -> Vec<String> {
let image_features = self.image_features.read().unwrap();
product_ids.iter().map(|id| image_features.get(id).cloned().unwrap_or_default()).collect()
}
}
// Simulated multimodal response generator
struct SimulatedMultimodalGenerator;
impl SimulatedMultimodalGenerator {
fn generate_response(&self, text_context: &str, image_context: &str) -> String {
format!(
"Generated response with text context: '{}', image context: '{}'",
text_context, image_context
)
}
}
fn main() -> tantivy::Result<()> {
// Define schema
let mut schema_builder = Schema::builder();
let product_id = schema_builder.add_u64_field("product_id", FAST);
let text = schema_builder.add_text_field("text", TEXT);
let image_id = schema_builder.add_text_field("image_id", STRING | FAST); // Image ID as string
let schema = schema_builder.build();
let feature_table = ExternalFeatureTable::default();
let dynamic_column = Arc::new(DynamicMultimodalColumn::with_product_id_field(
"product_id".to_string(),
feature_table.clone(),
));
// Set initial prices and image features
const OLIVE_OIL: ProductId = 323423;
const GLOVES: ProductId = 3966623;
const SNEAKERS: ProductId = 23222;
feature_table.update_price(OLIVE_OIL, 12);
feature_table.update_price(GLOVES, 13);
feature_table.update_price(SNEAKERS, 80);
feature_table.update_image_feature(OLIVE_OIL, "image_olive_oil.jpg".to_string());
feature_table.update_image_feature(GLOVES, "image_gloves.jpg".to_string());
feature_table.update_image_feature(SNEAKERS, "image_sneakers.jpg".to_string());
let index = Index::create_in_ram(schema.clone());
let mut writer: IndexWriter = index.writer_with_num_threads(1, 15_000_000)?;
writer.add_document(doc!(product_id=>OLIVE_OIL, text=>"cooking olive oil from greece", image_id=>"image_olive_oil.jpg"))?;
writer.add_document(doc!(product_id=>GLOVES, text=>"kitchen gloves, perfect for cooking", image_id=>"image_gloves.jpg"))?;
writer.add_document(doc!(product_id=>SNEAKERS, text=>"uber sweet sneakers", image_id=>"image_sneakers.jpg"))?;
writer.commit()?;
let warmers = vec![Arc::downgrade(&dynamic_column) as Weak<dyn Warmer>];
let reader = index.reader_builder().warmers(warmers).try_into()?;
let query_parser = QueryParser::for_index(&index, vec![text]);
let query = query_parser.parse_query("cooking")?;
let searcher = reader.searcher();
let score_by_price = move |segment_reader: &SegmentReader| {
let (prices, images) = dynamic_column.multimodal_data_for_segment(segment_reader);
let prices = prices.unwrap();
let images = images.unwrap();
move |doc_id: DocId| {
println!("Image context for doc {}: {}", doc_id, images[doc_id as usize]);
Reverse(prices[doc_id as usize])
}
};
let most_expensive_first = TopDocs::with_limit(10).custom_score(score_by_price);
let hits = searcher.search(&query, &most_expensive_first)?;
let generator = SimulatedMultimodalGenerator;
for (Reverse(_price), doc_address) in hits { // Prefix price with _ to suppress unused warning
let doc: TantivyDocument = searcher.doc(doc_address)?; // Explicitly set type here
// Extract text context using pattern matching on OwnedValue
let text_context = match doc.get_first(text) {
Some(tantivy::schema::OwnedValue::Str(text)) => text,
_ => "",
};
// Extract image context using pattern matching on OwnedValue
let image_context = match doc.get_first(image_id) {
Some(tantivy::schema::OwnedValue::Str(image)) => image,
_ => "",
};
let response = generator.generate_response(text_context, image_context);
println!("Generated response for doc {}: {}", doc_address.doc_id, response);
}
Ok(())
}
In the implementation, the DynamicMultimodalColumn struct manages multimodal data caches, including both prices and image IDs for each document segment, and an external feature table simulates fetching these features from an external source. The RAG system is built as a query-driven retrieval process, where a query finds relevant product descriptions, and prices rank the search results in descending order. Finally, a simulated generator model creates responses by combining the retrieved text and image features, demonstrating how multimodal data can be integrated to enhance the quality and relevance of generated answers.
Addressing challenges in RAG, such as retrieval accuracy and latency, involves implementing optimization techniques. One approach is to dynamically adjust retrieval thresholds based on query complexity, ensuring that simpler queries receive faster responses without sacrificing quality. Real-time RAG can also benefit from Rust’s asynchronous capabilities, which manage parallel query processing, enabling the retriever and generator to operate in a coordinated, low-latency manner. For applications requiring high retrieval accuracy, hybrid sparse-dense retrieval methods can be explored, combining keyword-based retrieval with embedding-based dense retrieval for nuanced, contextually relevant outputs.
RAG’s future applications are extensive, from personalized information retrieval to AI-assisted decision-making. Personalized retrieval leverages user preferences and historical data to tailor outputs, enhancing relevance in domains like e-commerce and content recommendation. Rust’s performance-oriented features make it an ideal framework for developing these responsive, personalized RAG systems. AI-assisted decision-making, particularly in fields like finance or law, can harness RAG to retrieve relevant case studies or market trends, delivering insights that support informed decisions. However, these advancements must be evaluated for feasibility and ethical impact, ensuring that they serve users responsibly and ethically.
The Rust ecosystem is poised to play a central role in the evolution of RAG, enabling efficient, scalable solutions capable of handling the technology’s most pressing challenges. By exploring multimodal integration, real-time processing, and continuous monitoring, Rust offers a robust foundation for deploying advanced, ethical, and high-performance RAG systems across diverse industries. As RAG technology advances, its potential to transform access to knowledge and decision-making processes underscores the importance of responsible development practices and collaborative innovation, securing a promising future for RAG-driven solutions.
11.9. Conclusion
Chapter 11 equips readers with the knowledge and tools needed to effectively build and deploy Retrieval-Augmented Generation systems using Rust. By mastering the concepts and techniques outlined, readers will be able to create advanced AI systems that leverage the strengths of both retrieval and generation, ensuring that the outputs are both accurate and contextually relevant, paving the way for innovative applications in various domains.
11.9.1. Further Learning with GenAI
Each prompt is crafted to encourage deep engagement with the material, challenging readers to think critically and explore the nuances of RAG within the context of Rust’s unique features and capabilities.
Explain the core principles of Retrieval-Augmented Generation (RAG). How does RAG differ from traditional generative models, and what advantages does it offer in terms of accuracy and contextual relevance?
Describe the process of setting up a Rust development environment for implementing RAG systems. What are the key libraries and tools needed, and how do they facilitate the integration of retrieval and generation components?
Discuss the role of the retriever component in a RAG system. How do different retrieval methods, such as BM25 and dense retrieval using neural embeddings, impact the quality and speed of information retrieval? Implement and compare these methods in Rust.
Explore the challenges of integrating retrieval results with a generative model in a RAG system. What strategies can be used to ensure that the generated text is both coherent and contextually accurate? Implement a basic integration in Rust.
Analyze the trade-offs between sparse and dense retrieval methods in RAG. What are the advantages and limitations of each approach, particularly in terms of scalability and relevance? Implement both methods in Rust and evaluate their performance on a common dataset.
Discuss the importance of indexing techniques in optimizing the retriever component of a RAG system. How do inverted indices and approximate nearest neighbor (ANN) search improve retrieval efficiency? Implement these techniques in Rust and compare their effectiveness.
Explain the conditioning of a generative model on retrieved information in a RAG system. How does this conditioning influence the generation process, and what techniques can be used to improve it? Implement a conditioning mechanism in Rust and analyze its impact.
Explore the concept of pipeline integration versus end-to-end training in RAG systems. What are the benefits and challenges of each approach, particularly in terms of model performance and complexity? Implement both strategies in Rust and compare their outcomes.
Discuss the role of attention mechanisms in enhancing the interaction between retrieval and generation in RAG systems. How do these mechanisms improve the coherence and accuracy of generated text? Implement an attention-based RAG model in Rust.
Analyze the impact of retrieval latency on the overall performance of a RAG system. What techniques can be used to minimize latency without compromising retrieval quality? Implement and test these techniques in Rust.
Explore the process of fine-tuning a RAG system for a specific task or domain. What are the key considerations in adapting both the retriever and generator components, and how does fine-tuning improve system performance? Implement a fine-tuning process in Rust.
Discuss the challenges of deploying RAG systems in real-time applications. What strategies can be employed to optimize scalability, latency, and resource management in such deployments? Implement a deployment pipeline in Rust and evaluate its performance.
Explain the concept of model pruning and quantization in the context of RAG systems. How do these techniques help optimize model size and inference speed, particularly in resource-constrained environments? Implement these optimizations in Rust.
Analyze the trade-offs between deploying RAG systems on cloud platforms versus edge devices. What are the key considerations for each environment, particularly in terms of performance, cost, and scalability? Implement deployment strategies for both environments in Rust.
Explore the ethical considerations of using RAG systems, particularly in terms of bias, misinformation, and privacy. How can these issues be mitigated during the development and deployment phases? Implement bias detection and mitigation strategies in Rust.
Discuss the future directions of RAG technology, such as multimodal RAG and real-time RAG. How can Rust’s features be leveraged to explore these emerging trends and push the boundaries of what RAG systems can achieve? Implement a prototype of a multimodal RAG system in Rust.
Explain the importance of continuous monitoring and updating of deployed RAG systems. How can Rust be used to implement a robust monitoring framework that tracks system performance and adapts to changing conditions?
Explore the challenges of handling out-of-distribution (OOD) data in RAG systems. What strategies can be used to detect and manage OOD inputs, ensuring that the system remains robust in real-world applications? Implement OOD detection techniques in Rust.
Discuss the role of hybrid retrieval approaches in improving the performance of RAG systems. How can combining sparse and dense retrieval methods enhance retrieval accuracy and relevance? Implement a hybrid retrieval strategy in Rust and evaluate its effectiveness.
Analyze the potential of real-time RAG systems in applications such as personalized information retrieval or AI-assisted decision-making. What are the technical challenges involved, and how can Rust be used to address them? Implement a real-time RAG system in Rust and test its performance.
Embrace these challenges with curiosity and determination, knowing that your efforts will not only enhance your technical skills but also empower you to contribute to the cutting-edge development of RAG systems in the field of AI.
11.9.2. Hands On Practices
Self-Exercise 11.1: Implementing and Evaluating Sparse vs. Dense Retrieval in RAG
Objective: To understand the differences between sparse and dense retrieval methods in a RAG system by implementing and evaluating both approaches in Rust.
Tasks:
Implement a sparse retrieval method (e.g., BM25) in Rust and apply it to a sample text corpus for retrieval tasks.
Implement a dense retrieval method using neural embeddings and apply it to the same corpus.
Compare the performance of both retrieval methods in terms of accuracy, retrieval speed, and relevance of the retrieved information.
Analyze the trade-offs between sparse and dense retrieval, focusing on their effectiveness in different scenarios.
Deliverables:
A Rust codebase implementing both sparse (BM25) and dense retrieval methods.
A detailed report comparing the performance of the two retrieval methods, including metrics such as retrieval speed, accuracy, and relevance.
A summary of the trade-offs between sparse and dense retrieval, with recommendations for when to use each approach.
Self-Exercise 11.2: Fine-Tuning a RAG System for Domain-Specific Applications
Objective: To adapt a RAG system to a specific domain by fine-tuning both the retriever and generator components in Rust.
Tasks:
Select a domain-specific dataset relevant to a particular application (e.g., legal documents, medical records).
Fine-tune the retriever component on the domain-specific dataset to improve the relevance of retrieved information.
Fine-tune the generator component to ensure that generated text is coherent and contextually appropriate for the selected domain.
Evaluate the performance of the fine-tuned RAG system, focusing on metrics such as accuracy, fluency, and domain relevance.
Deliverables:
A Rust codebase with fine-tuned retriever and generator components tailored to the selected domain.
A performance evaluation report that includes metrics on the accuracy, fluency, and relevance of the fine-tuned RAG system.
A discussion of the challenges encountered during the fine-tuning process and the strategies used to overcome them.
Self-Exercise 11.3: Implementing and Testing Real-Time RAG System Deployment
Objective: To deploy a real-time RAG system in a production environment using Rust, focusing on optimizing for low latency and high scalability.
Tasks:
Develop a REST API in Rust that serves a RAG system for real-time inference, handling both retrieval and generation tasks.
Implement optimizations to reduce inference latency, such as caching frequently retrieved results and optimizing model execution.
Deploy the RAG system on a cloud platform or edge device, ensuring that the deployment is scalable and robust.
Test the deployed system under different load conditions, analyzing its performance in terms of response time, scalability, and resource usage.
Deliverables:
A Rust codebase with a deployed REST API for real-time RAG system inference.
A performance report detailing the latency, scalability, and resource usage of the deployed RAG system under various conditions.
Recommendations for further optimizing the real-time RAG system deployment based on the test results.
Self-Exercise 11.4: Addressing Out-of-Distribution Data in RAG Systems
Objective: To enhance the robustness of a RAG system by implementing techniques to detect and manage out-of-distribution (OOD) data using Rust.
Tasks:
Implement a mechanism in Rust to detect OOD inputs during the retrieval phase of a RAG system, using techniques such as confidence scoring or anomaly detection.
Develop a strategy to handle detected OOD inputs, such as fallback retrieval methods or flagging for further review.
Integrate the OOD detection and handling mechanism into an existing RAG system.
Test the system with a dataset containing both in-distribution and OOD samples, evaluating the effectiveness of the OOD management strategies.
Deliverables:
A Rust codebase with OOD detection and management integrated into a RAG system.
A testing report that includes metrics on the accuracy and robustness of the RAG system when handling OOD data.
An analysis of the effectiveness of the OOD management strategies, with recommendations for improving the system’s robustness.
Self-Exercise 11.5: Implementing Hybrid Retrieval Approaches in RAG
Objective: To explore the benefits of combining sparse and dense retrieval methods in a hybrid approach within a RAG system using Rust.
Tasks:
Implement a hybrid retrieval approach that combines sparse (e.g., BM25) and dense retrieval methods in Rust.
Design a strategy for integrating the results of both retrieval methods to optimize relevance and accuracy.
Apply the hybrid retrieval approach to a RAG system and evaluate its performance on a diverse dataset.
Analyze the results, focusing on the improvements in retrieval accuracy and relevance compared to using either method alone.
Deliverables:
A Rust codebase implementing a hybrid retrieval approach within a RAG system.
A performance evaluation report comparing the hybrid retrieval approach with standalone sparse and dense methods, including metrics on accuracy and relevance.
A discussion of the advantages and challenges of implementing hybrid retrieval, with suggestions for further refinement.
Comments