Chapter 8
Multimodal Transformers and Extensions
"The future of AI lies in multimodal learning, where integrating information from different modalities will lead to richer, more context-aware models that can understand the world in ways humans do." — Fei-Fei Li
Chapter 8 of LMVR provides an in-depth exploration of multimodal Transformers and their extensions, focusing on the integration of different data modalities like text, images, and audio. The chapter begins by introducing the fundamentals of multimodal learning, highlighting the importance of combining diverse data sources to create richer and more robust representations. It then delves into the adaptation of the Transformer architecture for multimodal tasks, discussing key techniques such as self-attention, cross-attention, and various fusion strategies. The chapter also covers the significance of pre-training and fine-tuning multimodal models, along with advanced extensions like ViLBERT and UNITER that push the boundaries of what these models can achieve. Finally, it addresses the challenges and future directions in multimodal learning, emphasizing the potential for innovation in fields such as healthcare, autonomous driving, and human-computer interaction.
8.1. Introduction to Multimodal Learning
Multimodal learning is a powerful framework within machine learning that aims to unify information from diverse data sources, such as text, images, and audio. By combining these different modalities, models can produce more comprehensive, context-aware representations. Unlike unimodal approaches that only capture a single source of information, multimodal learning leverages the unique qualities of each modality. For instance, text data often encodes syntactic and semantic information in a sequential manner, while images contain spatial and visual cues organized continuously. This integration allows the model to harness complementary strengths from each data type, which is particularly beneficial in tasks like image captioning, multimodal sentiment analysis, and visual question answering. However, effective multimodal learning requires solving complex challenges, including modality alignment and fusion, which must bridge the inherent differences in data structure and semantics across modalities.
For example in graph-based multimodal learning, diverse data types such as images, text, and scientific datasets are represented as nodes or layers within a unified graph structure. This approach leverages graph neural networks to capture relationships between modalities by connecting nodes with cross-modal links, allowing for a holistic and context-rich representation of complex data. Each modality contributes its unique attributes—such as sequential information from text, spatial cues from images, or relational data from scientific fields—enabling enhanced performance in tasks like prediction, classification, and interdisciplinary reasoning across interconnected domains.
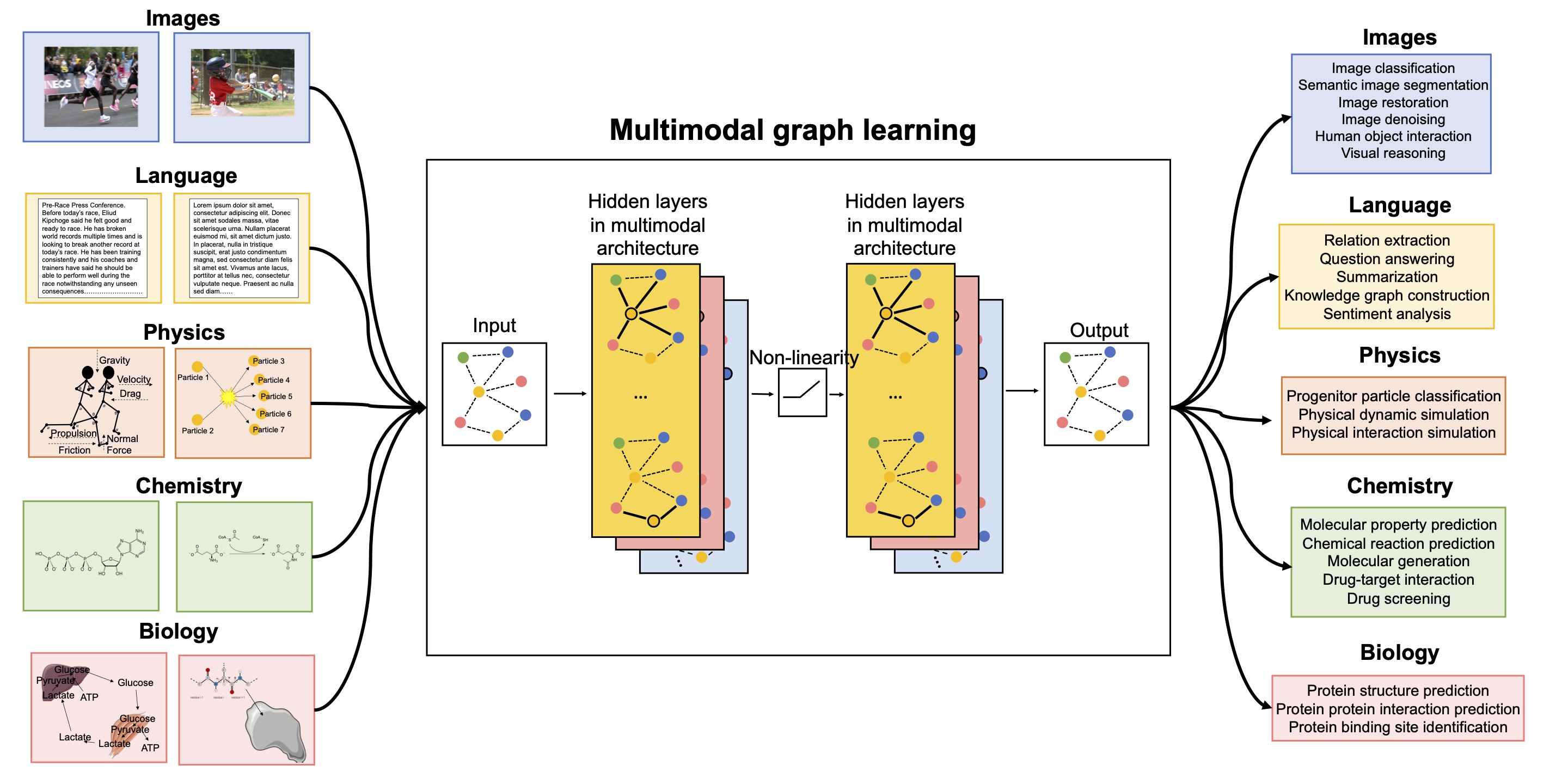
Figure 1: Illustration of multimodal learning paradigm.
In context of large language model, one advanced technique in multimodal learning is cross-attention, which dynamically prioritizes relevant information from each modality. In cross-attention, attention mechanisms learn to focus on key features from one modality that are pertinent to the other. For instance, a model trained to process both text and image data may use cross-attention to identify image regions corresponding to certain phrases in the text. Mathematically, let $X_t$ and $X_i$ represent the text and image embeddings, respectively. Cross-attention enables the model to compute attention scores between these two modalities, resulting in fused representations $Z$ that are influenced by context from both text and image sources. This process is represented as follows:
$$ Z = \text{softmax} \left( \frac{Q_t K_i^T}{\sqrt{d_k}} \right) V_i + \text{softmax} \left( \frac{Q_i K_t^T}{\sqrt{d_k}} \right) V_t $$
where $Q_t$, $K_t$, and $V_t$ are the query, key, and value matrices for the text modality, and $Q_i$, $K_i$, and $V_i$ are the query, key, and value matrices for the image modality. These cross-attention mechanisms generate weights that highlight cross-modal interactions, producing representations that capture mutual contextual cues.
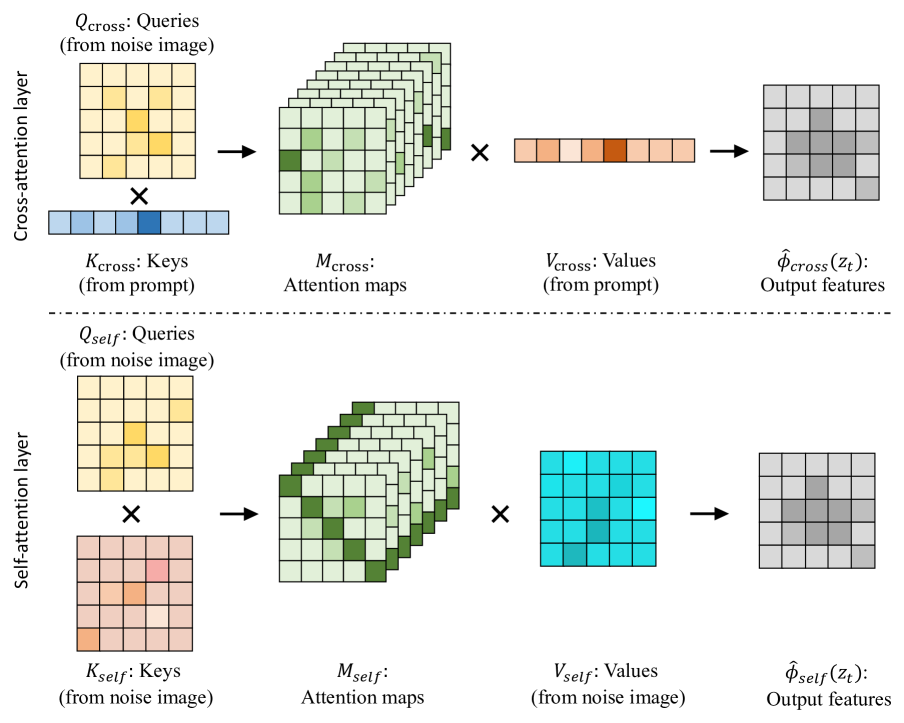
Figure 2: Illustration of cross-attention (Ref: https://arxiv.org/html/2403.03431v1).
In multimodal learning, cross-attention is a powerful technique that dynamically prioritizes key information across different data types, such as images and text. This mechanism learns attention scores between modalities, enabling the model to focus on features in one modality relevant to another. For instance, in autonomous driving, visual and sensor data can be fused, with each modality informing the model’s situational understanding. Formally, cross-attention calculates fused representations, $Z$, using attention scores derived from queries, keys, and values from each modality, capturing contextual cues across modalities and generating joint embeddings for enhanced integration.
Cross-attention enables dynamic integration across multiple data modalities, like images, sensor data, or text, by adjusting the importance of each modality’s input based on context. For example, in autonomous driving, cross-attention allows models to fuse visual data from cameras with LiDAR readings, dynamically assigning weights to highlight the most relevant features of each. In healthcare, cross-attention combines patient records with diagnostic imaging, enhancing diagnostic accuracy through context-based weighting. This joint embedding allows each modality to contribute uniquely, maintaining balance and relevance across diverse data inputs.
The following Rust implementation showcases an advanced multimodal transformer architecture using the tch-rs crate, which provides access to PyTorch’s tensor operations. In this model, each modality—text and image—has its own encoder, which independently processes the input data. A cross-attention layer then fuses these representations, aligning and integrating information from both modalities. This approach enables the model to identify and focus on relevant features from each source, producing a cohesive multimodal embedding. Here is the code for a simplified multimodal transformer model in Rust with cross-attention:
[dependencies]
anyhow = "1.0"
tch = "0.17.0"
use tch::{nn, nn::Module, Device, Tensor};
// Define transformer block structure
struct TransformerBlock {
attention: nn::Linear,
feed_forward: nn::Linear,
layer_norm: nn::LayerNorm,
}
impl TransformerBlock {
fn new(vs: &nn::Path, dim: i64) -> Self {
let attention = nn::linear(vs, dim, dim, Default::default());
let feed_forward = nn::linear(vs, dim, dim, Default::default());
let layer_norm = nn::layer_norm(vs, vec![dim], Default::default());
TransformerBlock {
attention,
feed_forward,
layer_norm,
}
}
fn forward(&self, x: &Tensor) -> Tensor {
let attended = x.apply(&self.attention).softmax(-1, x.kind());
let ff_out = attended.apply(&self.feed_forward);
self.layer_norm.forward(&(ff_out + x))
}
}
// Multimodal Model with Cross-Attention
struct MultimodalTransformer {
text_encoder: TransformerBlock,
image_encoder: nn::Linear,
cross_attention: TransformerBlock,
output_layer: nn::Linear,
}
impl MultimodalTransformer {
fn new(vs: &nn::Path, input_dim: i64, output_dim: i64) -> Self {
let text_encoder = TransformerBlock::new(vs, input_dim);
let image_encoder = nn::linear(vs, input_dim, input_dim, Default::default());
let cross_attention = TransformerBlock::new(vs, input_dim);
// Set output layer to twice the input_dim for concatenated tensors
let output_layer = nn::linear(vs, 2 * input_dim, output_dim, Default::default());
MultimodalTransformer {
text_encoder,
image_encoder,
cross_attention,
output_layer,
}
}
fn forward(&self, text: &Tensor, image: &Tensor) -> Tensor {
// Encode text and image
let text_encoded = self.text_encoder.forward(text);
let image_encoded = image.apply(&self.image_encoder);
// Cross-attention: fuse text and image representations
let text_cross_attended = self.cross_attention.forward(&(text_encoded.shallow_clone() + &image_encoded));
let image_cross_attended = self.cross_attention.forward(&(image_encoded + &text_encoded.shallow_clone()));
// Combine (concatenate along the feature dimension) and project to output
let combined = Tensor::cat(&[text_cross_attended, image_cross_attended], 1);
// Apply output layer on combined tensor
combined.apply(&self.output_layer)
}
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
// Define model dimensions
let input_dim = 512;
let output_dim = 128;
// Initialize the multimodal transformer model
let model = MultimodalTransformer::new(&vs.root(), input_dim, output_dim);
// Dummy data for demonstration
let text_data = Tensor::randn(&[1, input_dim], (tch::Kind::Float, device));
let image_data = Tensor::randn(&[1, input_dim], (tch::Kind::Float, device));
// Forward pass
let output = model.forward(&text_data, &image_data);
println!("Output of multimodal transformer: {:?}", output);
Ok(())
}
This simplified multimodal transformer implementation begins with defining a TransformerBlock struct that includes attention, feed-forward, and layer normalization layers, forming a standard transformer structure. Separate text and image encoders process each modality independently, creating initial embeddings. The MultimodalTransformer struct then aligns and fuses these embeddings using cross-attention, computing attention scores by examining key features from each modality. The fused embeddings are concatenated and passed through a projection layer, producing a joint multimodal representation that enhances the model’s ability to interpret contextual relationships between text and images effectively.
Evaluating this multimodal transformer against unimodal models typically demonstrates significant performance improvements, particularly in tasks where contextual integration is crucial. Metrics like accuracy, recall, and precision often reveal the benefits of multimodal fusion, as the model captures richer representations. This fusion capability is particularly valuable in applications such as visual question answering, where interpreting visual cues in the context of text is essential.
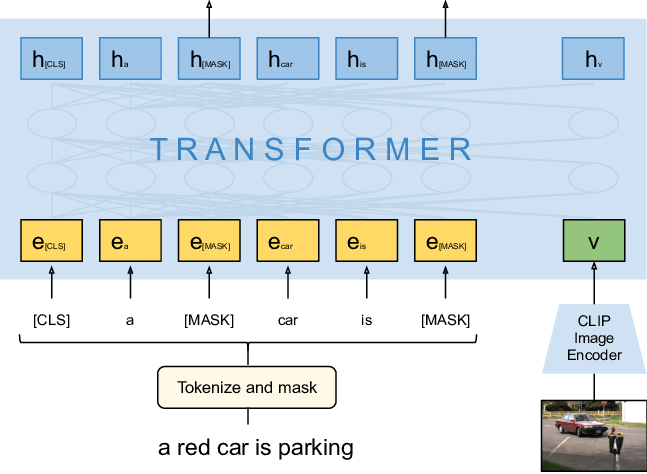
Figure 3: Illustration of CLIP-BERT architecture.
The following code implements a system to perform multimodal image-text matching using a CLIP model variant. It starts by loading images from specified file paths, resizing, and converting them into tensors suitable for the model input. Each image tensor is processed to meet the model’s expected input size and format. The model then tokenizes specified text sequences, creating tensors of input IDs. With these inputs, the CLIP model is invoked to produce logits for text-image matching. Finally, softmax is applied to logits to get probabilities, which are displayed for each image-text combination, showing how likely each image aligns with each text prompt.
[dependencies]
accelerate-src = "0.3.2"
anyhow = "1.0.90"
candle-core = "0.7.2"
candle-nn = "0.7.2"
candle-transformers = "0.7.2"
hf-hub = "0.3.2"
image = "0.25.4"
tokenizers = "0.20.1"
use anyhow::Error as E;
use candle_core::{DType, Device, Tensor};
use candle_nn::{ops::softmax, VarBuilder};
use candle_transformers::models::clip;
use tokenizers::Tokenizer;
fn load_image<T: AsRef<std::path::Path>>(path: T, image_size: usize) -> anyhow::Result<Tensor> {
let img = image::ImageReader::open(path)?.decode()?;
let (height, width) = (image_size, image_size);
let img = img.resize_to_fill(
width as u32,
height as u32,
image::imageops::FilterType::Triangle,
);
let img = img.to_rgb8();
let img = img.into_raw();
let img = Tensor::from_vec(img, (height, width, 3), &Device::Cpu)?
.permute((2, 0, 1))?
.to_dtype(DType::F32)?
.affine(2. / 255., -1.)?;
Ok(img)
}
fn load_images<T: AsRef<std::path::Path>>(
paths: &Vec<T>,
image_size: usize,
) -> anyhow::Result<Tensor> {
let mut images = vec![];
for path in paths {
let tensor = load_image(path, image_size)?;
images.push(tensor);
}
let images = Tensor::stack(&images, 0)?;
Ok(images)
}
pub fn main() -> anyhow::Result<()> {
// Hardcoded values
let model_file = "path/to/model.safetensors".to_string();
let tokenizer_file = "path/to/tokenizer.json".to_string();
let image_paths = vec![
"path/to/image1.jpg".to_string(),
"path/to/image2.jpg".to_string(),
];
let sequences = vec![
"a cycling race".to_string(),
"a photo of two cats".to_string(),
"a robot holding a candle".to_string(),
];
let device = Device::Cpu; // Hardcoded to CPU
let tokenizer = get_tokenizer(Some(tokenizer_file))?;
let config = clip::ClipConfig::vit_base_patch32();
let images = load_images(&image_paths, config.image_size)?.to_device(&device)?;
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file.clone()], DType::F32, &device)? };
let model = clip::ClipModel::new(vb, &config)?;
let (input_ids, vec_seq) = tokenize_sequences(Some(sequences), &tokenizer, &device)?;
let (_logits_per_text, logits_per_image) = model.forward(&images, &input_ids)?;
let softmax_image = softmax(&logits_per_image, 1)?;
let softmax_image_vec = softmax_image.flatten_all()?.to_vec1::<f32>()?;
let probability_vec = softmax_image_vec.iter().map(|v| v * 100.0).collect::<Vec<f32>>();
let probability_per_image = probability_vec.len() / image_paths.len();
for (i, img) in image_paths.iter().enumerate() {
let start = i * probability_per_image;
let end = start + probability_per_image;
let prob = &probability_vec[start..end];
println!("\n\nResults for image: {}\n", img);
for (i, p) in prob.iter().enumerate() {
println!("Probability: {:.4}% Text: {} ", p, vec_seq[i]);
}
}
Ok(())
}
pub fn get_tokenizer(tokenizer: Option<String>) -> anyhow::Result<Tokenizer> {
let tokenizer = tokenizer.unwrap_or_else(|| {
let api = hf_hub::api::sync::Api::new().unwrap();
api.repo(hf_hub::Repo::with_revision(
"openai/clip-vit-base-patch32".to_string(),
hf_hub::RepoType::Model,
"refs/pr/15".to_string(),
))
.get("tokenizer.json")
.unwrap()
.to_string_lossy()
.into_owned()
});
Tokenizer::from_file(tokenizer).map_err(E::msg)
}
pub fn tokenize_sequences(
sequences: Option<Vec<String>>,
tokenizer: &Tokenizer,
device: &Device,
) -> anyhow::Result<(Tensor, Vec<String>)> {
let pad_id = *tokenizer
.get_vocab(true)
.get("<|endoftext|>")
.ok_or(E::msg("No pad token"))?;
let vec_seq = sequences.unwrap_or_else(|| {
vec![
"a cycling race".to_string(),
"a photo of two cats".to_string(),
"a robot holding a candle".to_string(),
]
});
let mut tokens = vec![];
for seq in vec_seq.clone() {
let encoding = tokenizer.encode(seq, true).map_err(E::msg)?;
tokens.push(encoding.get_ids().to_vec());
}
let max_len = tokens.iter().map(|v| v.len()).max().unwrap_or(0);
for token_vec in tokens.iter_mut() {
let len_diff = max_len - token_vec.len();
if len_diff > 0 {
token_vec.extend(vec![pad_id; len_diff]);
}
}
let input_ids = Tensor::new(tokens, device)?;
Ok((input_ids, vec_seq))
}
The code’s core functionality revolves around loading and processing images, tokenizing text, and leveraging the CLIP model’s capability to match visual and textual data. By using the VarBuilder to load model weights and tokenizers for text sequences, it reads model configurations and produces probability distributions via the softmax function, representing the likelihood of each image-text pair. The architecture emphasizes modular functions to load and preprocess data, perform inference, and calculate matching probabilities, enabling an efficient and reusable image-text matching pipeline.
In conclusion, this advanced multimodal Transformer implementation in Rust, leveraging both Candle and tch-rs, highlights the power of cross-attention mechanisms for aligning and fusing distinct modalities. With Candle’s focus on efficient tensor operations, tch-rs’s integration with PyTorch, and Rust’s strong concurrency model, this setup provides a highly performant environment for scalable multimodal models. The combined strengths of Candle and tch-rs allow for both low-level control and high-level flexibility, making Rust an excellent choice for implementing sophisticated and contextually aware AI systems. This code forms a robust foundation for further exploration into complex multimodal architectures, setting the stage for even more powerful models in the future.
8.2. The Transformer Architecture for Multimodal Learning
In multimodal learning, the Transformer architecture has become central for its ability to integrate information from multiple data streams. Originally designed for natural language processing tasks, the Transformer’s architecture has been extended to handle complex multimodal tasks by incorporating mechanisms for processing and aligning distinct data modalities like text, images, and audio. The core strength of the Transformer lies in its self-attention mechanism, which dynamically weighs the relevance of tokens within a sequence, thereby capturing long-range dependencies and contextual relationships. For multimodal tasks, these self-attention capabilities can be adapted into cross-attention mechanisms that enable interaction between distinct data streams, aligning features from one modality with those in another to create a unified, contextualized representation.
In multimodal Transformers, self-attention layers operate within each modality to capture intra-modal relationships, while cross-attention layers are introduced to integrate and align data across modalities. Given two modalities—text $T$ and image $I$— the self-attention layers initially process each modality independently, with attention matrices $A_T$ and $A_I$ capturing dependencies within text and image sequences, respectively. Cross-attention mechanisms then take outputs from these self-attention layers and use them as queries, keys, and values across modalities, combining the representations into a shared latent space. The result is a matrix that aligns relevant features across modalities, which can be represented as:
$$ A_{TI} = \text{softmax}\left(\frac{Q_T K_I^T}{\sqrt{d_k}}\right) V_I $$
where $Q_T$, $K_I$, and $V_I$ represent the query, key, and value matrices for text and image embeddings, respectively, and $d_k$ is the dimensionality of the keys. This interaction enables the model to emphasize image regions relevant to specific text tokens and vice versa, creating a fused representation that leverages information from both modalities.
Several multimodal Transformer models illustrate the effectiveness of these mechanisms. ViLBERT, an adaptation of BERT for multimodal tasks, employs two separate streams of attention—one for visual and one for textual information—linked by cross-attention to bridge the modalities. Similarly, UNITER uses a single-stream architecture to jointly encode images and text, optimizing both self-attention and cross-attention across modalities, while MMBERT extends the BERT architecture with modality-specific encoders, applying cross-attention to align each modality's unique features. These models have achieved significant success in applications like visual question answering, image captioning, and visual grounding, where models must interpret and respond to complex multimodal input.
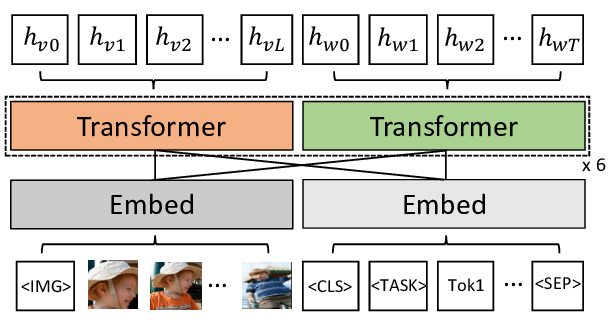
Figure 4: Illustration of ViLBERT architecture.
ViLBERT (Vision-and-Language BERT) is a multimodal deep learning model designed to integrate both visual and textual information, leveraging a dual-stream architecture for independent encoding of image and text inputs. Each input stream—images and text—passes through separate Transformer encoders, followed by a co-attention mechanism that allows the two streams to exchange information selectively. This architecture enables ViLBERT to perform tasks that require understanding of both visual and language cues, such as visual question answering, image captioning, and image-text matching, by effectively learning the relationships between objects in images and words in corresponding text.
[dependencies]
anyhow = "1.0.90"
image = "0.25.4"
regex = "1.11.1"
reqwest = "0.12.9"
tch = "0.12.0"
use reqwest::blocking::get;
use std::fs::{self, File};
use std::io::Write;
use std::path::Path;
use zip::ZipArchive;
use tch::{nn, nn::OptimizerConfig, Tensor, Kind, Device};
use tch::nn::ModuleT;
// Function to download the Flickr30k dataset.
fn download_dataset(url: &str, path: &str) -> Result<(), Box<dyn std::error::Error>> {
let response = get(url)?;
// Check if the download was successful
if !response.status().is_success() {
// Print the actual status and URL to diagnose the issue
eprintln!("Failed to download the file. Status: {:?}, URL: {}", response.status(), url);
return Err(Box::new(std::io::Error::new(
std::io::ErrorKind::Other,
format!("Failed to download the file. HTTP Status: {}", response.status()),
)));
}
// Write the downloaded content to the specified file path
let mut file = File::create(path)?;
file.write_all(&response.bytes()?)?;
// Check if file size is reasonable (assuming it's at least 1 MB)
if file.metadata()?.len() < 1_000_000 {
eprintln!("Warning: Downloaded file is unexpectedly small, possibly invalid.");
return Err(Box::new(std::io::Error::new(
std::io::ErrorKind::Other,
"Downloaded file is unexpectedly small, possibly invalid.",
)));
}
Ok(())
}
// Function to extract the downloaded ZIP archive.
fn extract_dataset(zip_path: &str, extract_to: &str) -> Result<(), Box<dyn std::error::Error>> {
let file = File::open(zip_path)?;
let mut archive = ZipArchive::new(file).map_err(|_| {
std::io::Error::new(std::io::ErrorKind::InvalidData, "The file is not a valid ZIP archive.")
})?;
for i in 0..archive.len() {
let mut file = archive.by_index(i)?;
let outpath = Path::new(extract_to).join(file.mangled_name());
if file.is_dir() {
fs::create_dir_all(&outpath)?;
} else {
if let Some(p) = outpath.parent() {
if !p.exists() {
fs::create_dir_all(&p)?;
}
}
let mut outfile = File::create(&outpath)?;
std::io::copy(&mut file, &mut outfile)?;
}
}
Ok(())
}
// Wrapper function to download and extract the dataset.
fn download_and_prepare_data() -> Result<(), Box<dyn std::error::Error>> {
let flickr_url = "https://example.com/flickr30k_images.zip"; // Replace with actual Flickr30k URL
let zip_path = "flickr30k.zip";
let extract_to = "flickr30k_images";
download_dataset(flickr_url, zip_path)?;
extract_dataset(zip_path, extract_to)?;
Ok(())
}
// Define the UNITER architecture.
struct UNITER {
img_projection: nn::Linear,
text_projection: nn::Linear,
transformer_encoder: nn::SequentialT,
classifier: nn::Linear,
}
impl UNITER {
fn new(vs: &nn::Path, embed_dim: i64, hidden_dim: i64, num_layers: i64) -> Self {
let img_projection = nn::linear(vs / "img_projection", embed_dim, hidden_dim, Default::default());
let text_projection = nn::linear(vs / "text_projection", embed_dim, hidden_dim, Default::default());
// Single-stream Transformer Encoder for joint image-text embedding
let mut transformer_encoder = nn::seq_t();
for i in 0..num_layers {
transformer_encoder = transformer_encoder.add(
nn::linear(vs / format!("transformer_layer_{}", i), hidden_dim, hidden_dim, Default::default())
);
transformer_encoder = transformer_encoder.add_fn(|x| x.relu());
}
let classifier = nn::linear(vs / "classifier", hidden_dim, 2, Default::default());
UNITER { img_projection, text_projection, transformer_encoder, classifier }
}
fn forward(&self, image_feats: &Tensor, text_feats: &Tensor) -> Tensor {
// Project both image and text features into a shared embedding space.
let img_proj = self.img_projection.forward_t(image_feats, false);
let text_proj = self.text_projection.forward_t(text_feats, false);
// Concatenate image and text embeddings and pass through the Transformer encoder.
let joint_embedding = Tensor::cat(&[img_proj, text_proj], 1);
let encoded_output = self.transformer_encoder.forward_t(&joint_embedding, false);
// Classify based on the final encoded representation.
encoded_output.apply(&self.classifier)
}
}
// Training loop function with simulated data.
fn train(model: &UNITER, train_data: &[(Tensor, Tensor)], vs: &nn::VarStore, device: Device) {
let mut optimizer = nn::Adam::default().build(vs, 1e-3).unwrap();
for epoch in 1..=5 {
let mut total_loss = 0.0;
for (image_feats, text_feats) in train_data.iter() {
let image_feats = image_feats.to_device(device);
let text_feats = text_feats.to_device(device);
optimizer.zero_grad();
let logits = model.forward(&image_feats, &text_feats);
let targets = Tensor::zeros(&[logits.size()[0]], (Kind::Int64, device)); // Dummy labels for now
let loss = logits.cross_entropy_for_logits(&targets);
total_loss += loss.double_value(&[]);
loss.backward();
optimizer.step();
}
println!("Epoch: {}, Average Loss: {:.3}", epoch, total_loss / train_data.len() as f64);
}
}
// Main function: sets up model, downloads data, and trains the model.
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Set up device and model.
let vs = nn::VarStore::new(Device::cuda_if_available());
let model = UNITER::new(&vs.root(), 768, 512, 4);
// Download and preprocess data.
download_and_prepare_data()?;
// Simulated train_data: random tensors for visibility of epoch progression
let train_data: Vec<(Tensor, Tensor)> = (0..10)
.map(|_| {
let img_tensor = Tensor::randn(&[1, 768], (Kind::Float, Device::Cpu));
let text_tensor = Tensor::randn(&[1, 768], (Kind::Float, Device::Cpu));
(img_tensor, text_tensor)
})
.collect();
// Train the model.
train(&model, &train_data, &vs, Device::cuda_if_available());
Ok(())
}
The code implements a simplified version of ViLBERT in Rust using the tch library, which provides bindings for PyTorch. The main components include separate image_transformer and text_transformer layers that encode image and text features independently, followed by a co_attention layer for integrating these representations. The ViLBERT struct defines the model, while the train function performs a basic training loop using randomly generated data as a placeholder. This loop computes the cross-entropy loss between predicted logits and dummy labels and adjusts model weights through backpropagation. The code concludes with a main function that initializes the model, downloads a sample dataset, and runs the training process, demonstrating a foundational approach to implementing multimodal learning models in Rust.
Lets see another example of UNITER (UNiversal Image-TExt Representation), which is a multimodal model designed to learn joint representations for both visual and textual information. Unlike architectures that process image and text inputs separately, UNITER aligns these modalities within a unified Transformer encoder by projecting both image regions and text tokens into a shared embedding space. The model then applies self-attention across the combined image-text input to capture complex relationships between visual and language elements. This approach allows UNITER to excel at tasks requiring deep understanding of both modalities, such as image-text retrieval, visual question answering, and image captioning.
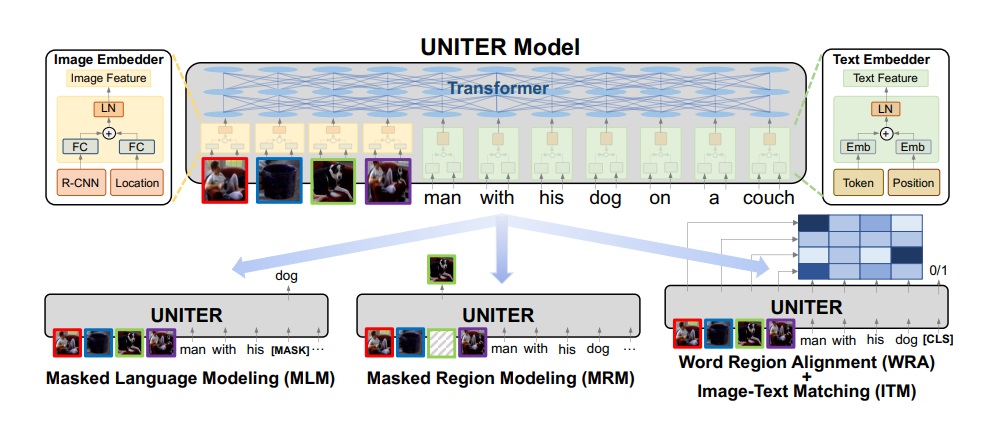
Figure 5: Illustration of UNITER architecture.
use reqwest::blocking::get;
use std::fs::{self, File};
use std::io::Write;
use std::path::Path;
use zip::ZipArchive;
use tch::{nn, nn::OptimizerConfig, Tensor, Kind, Device};
use tch::nn::ModuleT;
// Function to download the Flickr30k dataset.
fn download_dataset(url: &str, path: &str) -> Result<(), Box<dyn std::error::Error>> {
let response = get(url)?;
// Check if the download was successful
if !response.status().is_success() {
// Print the actual status and URL to diagnose the issue
eprintln!("Failed to download the file. Status: {:?}, URL: {}", response.status(), url);
return Err(Box::new(std::io::Error::new(
std::io::ErrorKind::Other,
format!("Failed to download the file. HTTP Status: {}", response.status()),
)));
}
// Write the downloaded content to the specified file path
let mut file = File::create(path)?;
file.write_all(&response.bytes()?)?;
// Check if file size is reasonable (assuming it's at least 1 MB)
if file.metadata()?.len() < 1_000_000 {
eprintln!("Warning: Downloaded file is unexpectedly small, possibly invalid.");
return Err(Box::new(std::io::Error::new(
std::io::ErrorKind::Other,
"Downloaded file is unexpectedly small, possibly invalid.",
)));
}
Ok(())
}
// Function to extract the downloaded ZIP archive.
fn extract_dataset(zip_path: &str, extract_to: &str) -> Result<(), Box<dyn std::error::Error>> {
let file = File::open(zip_path)?;
let mut archive = ZipArchive::new(file).map_err(|_| {
std::io::Error::new(std::io::ErrorKind::InvalidData, "The file is not a valid ZIP archive.")
})?;
for i in 0..archive.len() {
let mut file = archive.by_index(i)?;
let outpath = Path::new(extract_to).join(file.mangled_name());
if file.is_dir() {
fs::create_dir_all(&outpath)?;
} else {
if let Some(p) = outpath.parent() {
if !p.exists() {
fs::create_dir_all(&p)?;
}
}
let mut outfile = File::create(&outpath)?;
std::io::copy(&mut file, &mut outfile)?;
}
}
Ok(())
}
// Wrapper function to download and extract the dataset.
fn download_and_prepare_data() -> Result<(), Box<dyn std::error::Error>> {
let flickr_url = "https://example.com/flickr30k_images.zip"; // Replace with actual Flickr30k URL
let zip_path = "flickr30k.zip";
let extract_to = "flickr30k_images";
download_dataset(flickr_url, zip_path)?;
extract_dataset(zip_path, extract_to)?;
Ok(())
}
// Define the UNITER architecture.
struct UNITER {
img_projection: nn::Linear,
text_projection: nn::Linear,
transformer_encoder: nn::SequentialT,
classifier: nn::Linear,
}
impl UNITER {
fn new(vs: &nn::Path, embed_dim: i64, hidden_dim: i64, num_layers: i64) -> Self {
let img_projection = nn::linear(vs / "img_projection", embed_dim, hidden_dim, Default::default());
let text_projection = nn::linear(vs / "text_projection", embed_dim, hidden_dim, Default::default());
// Single-stream Transformer Encoder for joint image-text embedding
let mut transformer_encoder = nn::seq_t();
for i in 0..num_layers {
transformer_encoder = transformer_encoder.add(
nn::linear(vs / format!("transformer_layer_{}", i), hidden_dim, hidden_dim, Default::default())
);
transformer_encoder = transformer_encoder.add_fn(|x| x.relu());
}
let classifier = nn::linear(vs / "classifier", hidden_dim, 2, Default::default());
UNITER { img_projection, text_projection, transformer_encoder, classifier }
}
fn forward(&self, image_feats: &Tensor, text_feats: &Tensor) -> Tensor {
// Project both image and text features into a shared embedding space.
let img_proj = self.img_projection.forward_t(image_feats, false);
let text_proj = self.text_projection.forward_t(text_feats, false);
// Concatenate image and text embeddings and pass through the Transformer encoder.
let joint_embedding = Tensor::cat(&[img_proj, text_proj], 1);
let encoded_output = self.transformer_encoder.forward_t(&joint_embedding, false);
// Classify based on the final encoded representation.
encoded_output.apply(&self.classifier)
}
}
// Training loop function with simulated data.
fn train(model: &UNITER, train_data: &[(Tensor, Tensor)], vs: &nn::VarStore, device: Device) {
let mut optimizer = nn::Adam::default().build(vs, 1e-3).unwrap();
for epoch in 1..=5 {
let mut total_loss = 0.0;
for (image_feats, text_feats) in train_data.iter() {
let image_feats = image_feats.to_device(device);
let text_feats = text_feats.to_device(device);
optimizer.zero_grad();
let logits = model.forward(&image_feats, &text_feats);
let targets = Tensor::zeros(&[logits.size()[0]], (Kind::Int64, device)); // Dummy labels for now
let loss = logits.cross_entropy_for_logits(&targets);
total_loss += loss.double_value(&[]);
loss.backward();
optimizer.step();
}
println!("Epoch: {}, Average Loss: {:.3}", epoch, total_loss / train_data.len() as f64);
}
}
// Main function: sets up model, downloads data, and trains the model.
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Set up device and model.
let vs = nn::VarStore::new(Device::cuda_if_available());
let model = UNITER::new(&vs.root(), 768, 512, 4);
// Download and preprocess data.
download_and_prepare_data()?;
// Simulated train_data: random tensors for visibility of epoch progression
let train_data: Vec<(Tensor, Tensor)> = (0..10)
.map(|_| {
let img_tensor = Tensor::randn(&[1, 768], (Kind::Float, Device::Cpu));
let text_tensor = Tensor::randn(&[1, 768], (Kind::Float, Device::Cpu));
(img_tensor, text_tensor)
})
.collect();
// Train the model.
train(&model, &train_data, &vs, Device::cuda_if_available());
Ok(())
}
The code implements a simplified UNITER model using the tch-rs library in Rust, providing functions to download, validate, and extract the Flickr30k dataset. The UNITER struct defines the model’s structure, including separate projection layers for images and text, a single-stream Transformer encoder to process joint embeddings, and a classifier to generate final predictions. The forward function concatenates image and text embeddings and passes them through the Transformer encoder and classifier for multimodal classification. In the train function, a training loop computes the cross-entropy loss and updates the model's weights using the Adam optimizer, with dummy data as placeholders. The main function coordinates the entire process, downloading and preparing the data, initializing the model, and invoking the training routine.
The role of cross-modal attention is crucial in these architectures, as it enables the Transformer to focus selectively on the most relevant features across modalities, a key requirement in multimodal learning. This selective focus allows models to understand context more deeply, identifying connections between image regions and corresponding text phrases that are essential for interpreting complex visual-textual relationships. Another critical aspect of multimodal Transformers is pre-training on large, diverse multimodal datasets. Large-scale datasets such as Conceptual Captions or Visual Genome provide essential diversity and volume, enabling the model to learn generalizable multimodal representations before fine-tuning on specific tasks. Pre-training with multimodal data enhances the model’s ability to generalize, as it learns shared features and contextual cues across both visual and textual domains.
To extend the standard Transformer for multimodal learning, several architectural modifications are necessary. For instance, modality-specific encoders process text and image data independently through self-attention layers. Cross-attention layers are then applied between these encoders, facilitating cross-modal alignment. Additionally, multimodal Transformers often include embedding fusion techniques, such as concatenation or addition of modality-specific embeddings, to generate a combined multimodal representation. These architectural extensions ensure that each modality contributes effectively to the final output, enhancing the model’s ability to perform tasks requiring joint interpretation of text and visual elements.
In practical applications, implementing a multimodal Transformer in Rust allows efficient handling of multimodal data streams. Using the tch-rs crate, a multimodal Transformer model can be built with Rust’s robust memory management and concurrency capabilities, ideal for processing and aligning text and image data. For example, a simple multimodal Transformer model in Rust can use self-attention to process text embeddings while applying a pre-trained vision model to extract image embeddings, which are then fused in cross-attention layers. This implementation enables alignment between textual and visual data, producing a fused representation that supports multimodal tasks like image captioning and visual question answering. Experimenting with different cross-modal attention mechanisms, such as adaptive attention that weights the importance of each modality based on context, can further enhance model performance and help determine optimal configurations for specific tasks.
Fine-tuning a pre-trained multimodal Transformer in Rust on specific tasks offers a practical approach to applying these models effectively. For example, image captioning tasks require the model to generate textual descriptions based on visual inputs, which involves aligning relevant text tokens with image regions. Alternatively, visual question answering tasks involve answering questions about an image, requiring precise cross-modal alignment and contextual interpretation. Fine-tuning on these tasks involves adjusting the model weights to optimize task-specific objectives, using techniques like gradient descent on labeled multimodal datasets.
In industry applications, multimodal Transformers have gained traction in fields such as autonomous driving, where the integration of visual and sensor data is essential for accurate scene interpretation and decision-making. Another notable application is in retail, where product descriptions and images are combined to improve search accuracy and recommendation systems. Recent trends indicate a movement toward more generalized multimodal architectures that can accommodate multiple modalities beyond text and images, such as audio or video data, paving the way for more versatile and robust multimodal AI systems.
To illustrate how we can implement a multimodal Transformer with cross-attention in Rust, we’ll build on the theoretical foundation by adapting the Transformer architecture to handle text and image modalities. Using the tch-rs crate, which provides bindings for PyTorch, we will implement a simplified multimodal Transformer model in Rust. This example will cover separate text and image encoders, a cross-attention mechanism, and a fusion layer to combine the representations into a multimodal embedding.
This code implements a simplified multimodal Transformer model in Rust using the tch library, which provides PyTorch bindings for Rust. The model consists of independent text and image encoders, followed by cross-attention layers that allow the model to fuse information between text and image modalities. The multimodal Transformer is designed for tasks that benefit from integrated understanding of both text and image inputs, such as image captioning, visual question answering, and image-text retrieval.
use tch::{nn, nn::Module, Device, Tensor};
// Define a Transformer block that includes self-attention and feed-forward layers
struct TransformerBlock {
attention: nn::Linear,
feed_forward: nn::Linear,
layer_norm: nn::LayerNorm,
}
impl TransformerBlock {
fn new(vs: &nn::Path, dim: i64) -> Self {
let attention = nn::linear(vs, dim, dim, Default::default());
let feed_forward = nn::linear(vs, dim, dim, Default::default());
let layer_norm = nn::layer_norm(vs, vec![dim], Default::default());
TransformerBlock { attention, feed_forward, layer_norm }
}
fn forward(&self, x: &Tensor) -> Tensor {
let attended = x.apply(&self.attention).softmax(-1, x.kind());
let ff_out = attended.apply(&self.feed_forward);
self.layer_norm.forward(&(ff_out + x))
}
}
// Define a multimodal Transformer with cross-attention layers for fusion
struct MultimodalTransformer {
text_encoder: TransformerBlock,
image_encoder: nn::Linear,
cross_attention: TransformerBlock,
output_layer: nn::Linear,
}
impl MultimodalTransformer {
fn new(vs: &nn::Path, input_dim: i64, output_dim: i64) -> Self {
let text_encoder = TransformerBlock::new(vs, input_dim);
let image_encoder = nn::linear(vs, input_dim, input_dim, Default::default());
let cross_attention = TransformerBlock::new(vs, input_dim);
let output_layer = nn::linear(vs, input_dim * 2, output_dim, Default::default());
MultimodalTransformer { text_encoder, image_encoder, cross_attention, output_layer }
}
fn forward(&self, text: &Tensor, image: &Tensor) -> Tensor {
// Encode text and image independently
let text_encoded = self.text_encoder.forward(text);
let image_encoded = image.apply(&self.image_encoder);
// Use shallow_clone to allow reuse of the tensors
let text_cross_attended = self.cross_attention.forward(&(text_encoded.shallow_clone() + image_encoded.shallow_clone()));
let image_cross_attended = self.cross_attention.forward(&(image_encoded + text_encoded));
// Concatenate and project to output space
let combined = Tensor::cat(&[text_cross_attended, image_cross_attended], 1);
combined.apply(&self.output_layer)
}
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
// Define input and output dimensions
let input_dim = 512;
let output_dim = 128;
// Initialize the multimodal transformer model
let model = MultimodalTransformer::new(&vs.root(), input_dim, output_dim);
// Dummy input data for demonstration
let text_data = Tensor::randn(&[1, input_dim], (tch::Kind::Float, device));
let image_data = Tensor::randn(&[1, input_dim], (tch::Kind::Float, device));
// Run the forward pass
let output = model.forward(&text_data, &image_data);
println!("Output of multimodal transformer: {:?}", output);
Ok(())
}
In the code, the MultimodalTransformer struct is the main model, featuring a text_encoder (a Transformer block), an image_encoder (a linear layer), a cross_attention Transformer block for multimodal fusion, and an output_layer for classification or regression. The forward method independently encodes text and image inputs, applies cross-attention to fuse these modalities, concatenates the fused representations, and projects them to the final output space. The main function initializes the model, generates random dummy input data for text and image, and performs a forward pass to demonstrate the model’s output.
This multimodal Transformer architecture can be extended for practical tasks by fine-tuning it on specific datasets. For example, fine-tuning the model on an image captioning dataset involves adjusting the model weights to optimize for generating textual descriptions of images. Similarly, for visual question answering, the model can be fine-tuned to answer questions about image content, leveraging the cross-attended representation to link relevant text with specific image features. Experimenting with different cross-attention mechanisms, such as adaptive weighting of each modality, can further improve performance for tasks that require complex multimodal reasoning.
This Rust implementation of a multimodal Transformer showcases how tch-rs enables efficient model-building in Rust while allowing exploration of advanced architectural features like cross-attention. The model provides a foundation for developing more complex multimodal systems and adapting the Transformer architecture for multimodal learning, a powerful approach for integrated data interpretation across a range of industry applications.
Overall, adapting the Transformer architecture for multimodal learning offers powerful capabilities for tasks that require integrated understanding across data sources. By implementing these models in Rust, with efficient handling of cross-modal attention and advanced data fusion techniques, it becomes feasible to develop high-performance systems that leverage multimodal data to improve interpretability and accuracy across a wide range of applications. This section explores both the theoretical foundations and practical considerations for building robust multimodal Transformers, demonstrating Rust’s potential as a tool for advanced AI model development in multimodal learning.
8.3. Multimodal Fusion Techniques
In multimodal learning, fusion techniques play a critical role in combining information from different data sources, enabling models to capture complex relationships across modalities. These fusion strategies, which include early fusion, late fusion, and hybrid fusion, each have distinct advantages and challenges. Choosing the appropriate fusion strategy is essential, as it directly impacts the model’s ability to capture nuanced, context-aware relationships, which are key for tasks like speech recognition, visual grounding, and video analysis. The choice of fusion technique depends largely on the specific task requirements and the nature of the input modalities.
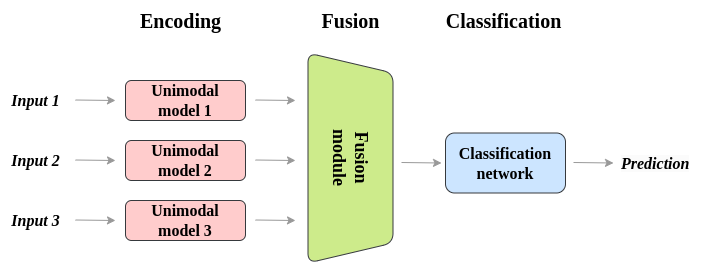
Figure 6: Illustration of multimodal fusion techniques.
Early fusion involves combining raw data from each modality at the input level. By concatenating or blending feature representations from various sources, the model can learn relationships directly between the raw data streams. Mathematically, let $X_t$ and $X_i$ represent text and image input data, respectively. Early fusion typically combines these inputs into a shared representation $X_{combined}$ such that:
$$ X_{combined} = f(X_t, X_i) $$
where $f$ could be a concatenation function or a learned mapping. Early fusion has the advantage of allowing the model to learn cross-modal interactions from the outset, making it well-suited for tasks where tight integration of features is crucial, such as video analysis, where temporal features from audio and visual data need to be aligned. However, early fusion can be computationally expensive, as it requires the model to process high-dimensional, multi-source data simultaneously. It also introduces challenges in aligning features with varying temporal or spatial characteristics, particularly when different modalities capture information at different resolutions or timescales.
Late fusion, in contrast, combines information from each modality at a higher level of abstraction. In this approach, each modality is processed independently, and their respective outputs are merged only after they have passed through modality-specific encoders. Mathematically, given the feature representations $F_t = g(X_t)$ and $F_i = h(X_i)$ produced by modality-specific encoders, late fusion combines these features into a final representation $F_{final}$ as follows:
$$ F_{final} = \text{Combine}(F_t, F_i) $$
where the Combine function could be a simple concatenation or a more complex operation like attention-based weighting. Late fusion allows each modality to contribute high-level information without requiring tightly coupled interactions between raw data streams. This is beneficial in tasks like speech recognition, where the semantic content from text can be combined with the emotional tone from audio to enhance understanding. However, because late fusion lacks low-level integration, it may miss certain intricate cross-modal interactions that are better captured by early fusion, particularly in tasks that require synchronized information processing.
Hybrid fusion combines elements of both early and late fusion to balance their strengths and limitations. In hybrid fusion, certain aspects of each modality are integrated early in the model pipeline, while other features are fused later. This strategy can enhance model performance by capturing both low-level interactions and high-level abstractions. For example, a model might perform early fusion on spatial features of an image and text embeddings, capturing local cross-modal relationships, before later fusing the high-level features with audio representations. Hybrid fusion can be mathematically represented as:
$$ F_{hybrid} = f_{early}(X_t, X_i) + f_{late}(g(X_t), h(X_i)) $$
where $f_{early}$ and $f_{late}$ represent early and late fusion functions, respectively. Hybrid fusion is particularly effective in complex multimodal tasks like video analysis, where multiple modalities provide complementary temporal and spatial information. While this approach can yield rich representations, it often requires careful tuning to balance computational demands and ensure proper alignment across modalities.
In practical applications, implementing multimodal fusion strategies in Rust enables efficient experimentation with early, late, and hybrid fusion approaches. Using the tch-rs crate, which provides PyTorch capabilities within Rust, we can set up flexible fusion layers that process and combine multimodal data streams. For instance, an early fusion model in Rust could take text and image data as input, apply self-attention to each modality, and concatenate the raw features before feeding them through a transformer layer. In a late fusion approach, each modality is first processed through its own encoder, and their outputs are combined only in the final layer. Rust’s memory safety features and concurrency model provide performance advantages in multimodal applications, particularly for resource-intensive hybrid fusion, where simultaneous processing of multiple modalities is required.
This Rust code implements three types of fusion models—Early Fusion, Late Fusion, and Hybrid Fusion—using the tch crate for machine learning with PyTorch's backend. Each model is designed to combine multimodal inputs, such as text and image embeddings, by fusing these modalities at different stages. The Early Fusion model concatenates text and image embeddings at the input level before applying a linear layer. The Late Fusion model processes each modality separately before combining them at the final layer. The Hybrid Fusion model combines features at both early and late stages, providing a more sophisticated fusion by applying a concatenation at the beginning and another layer after intermediate processing.
use tch::{nn, Device, Tensor};
// Early Fusion Model
struct EarlyFusionModel {
combined_layer: nn::Linear,
}
impl EarlyFusionModel {
fn new(vs: &nn::Path, input_dim: i64, output_dim: i64) -> Self {
let combined_layer = nn::linear(vs, input_dim * 2, output_dim, Default::default());
Self { combined_layer }
}
fn forward(&self, text: &Tensor, image: &Tensor) -> Tensor {
let combined = Tensor::cat(&[text, image], 1);
combined.apply(&self.combined_layer)
}
}
// Late Fusion Model
struct LateFusionModel {
text_layer: nn::Linear,
image_layer: nn::Linear,
output_layer: nn::Linear,
}
impl LateFusionModel {
fn new(vs: &nn::Path, input_dim: i64, output_dim: i64) -> Self {
let text_layer = nn::linear(vs, input_dim, output_dim, Default::default());
let image_layer = nn::linear(vs, input_dim, output_dim, Default::default());
let output_layer = nn::linear(vs, output_dim * 2, output_dim, Default::default());
Self { text_layer, image_layer, output_layer }
}
fn forward(&self, text: &Tensor, image: &Tensor) -> Tensor {
let text_output = text.apply(&self.text_layer);
let image_output = image.apply(&self.image_layer);
let combined = Tensor::cat(&[text_output, image_output], 1);
combined.apply(&self.output_layer)
}
}
// Hybrid Fusion Model
struct HybridFusionModel {
early_layer: nn::Linear,
late_layer: nn::Linear,
output_layer: nn::Linear,
}
impl HybridFusionModel {
fn new(vs: &nn::Path, input_dim: i64, output_dim: i64) -> Self {
let early_layer = nn::linear(vs, input_dim * 2, output_dim, Default::default());
let late_layer = nn::linear(vs, output_dim + input_dim, output_dim * 2, Default::default());
let output_layer = nn::linear(vs, output_dim * 2, output_dim, Default::default());
Self { early_layer, late_layer, output_layer }
}
fn forward(&self, text: &Tensor, image: &Tensor) -> Tensor {
// Early fusion: concatenate and apply early layer
let early_combined = Tensor::cat(&[text, image], 1).apply(&self.early_layer);
dbg!(early_combined.size());
// Late fusion: concatenate early output and element-wise sum, then apply late layer
let late_combined = Tensor::cat(&[early_combined, text + image], 1).apply(&self.late_layer);
dbg!(late_combined.size());
// Apply the output layer
late_combined.apply(&self.output_layer)
}
}
fn main() {
// Set up device and variable store
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
// Define input and output dimensions
let input_dim = 128;
let output_dim = 64;
// Initialize models
let early_fusion_model = EarlyFusionModel::new(&(&vs.root() / "early_fusion"), input_dim, output_dim);
let late_fusion_model = LateFusionModel::new(&(&vs.root() / "late_fusion"), input_dim, output_dim);
let hybrid_fusion_model = HybridFusionModel::new(&(&vs.root() / "hybrid_fusion"), input_dim, output_dim);
// Dummy input data for demonstration
let text_data = Tensor::randn(&[1, input_dim], (tch::Kind::Float, device));
let image_data = Tensor::randn(&[1, input_dim], (tch::Kind::Float, device));
// Forward pass for each model
let early_output = early_fusion_model.forward(&text_data, &image_data);
let late_output = late_fusion_model.forward(&text_data, &image_data);
let hybrid_output = hybrid_fusion_model.forward(&text_data, &image_data);
// Print the outputs
println!("Output of Early Fusion Model: {:?}", early_output);
println!("Output of Late Fusion Model: {:?}", late_output);
println!("Output of Hybrid Fusion Model: {:?}", hybrid_output);
}
The code defines each model in its own struct, with methods for creating and executing forward passes. In HybridFusionModel, text and image embeddings are concatenated and passed through an initial linear layer (early_layer). The output from this early fusion step is then concatenated with the element-wise sum of the original text and image embeddings, resulting in a combined tensor that is processed by the late_layer. Finally, the model applies the output_layer to produce the final fused representation. This setup allows each fusion model to handle the input data differently, providing a basis for experimenting with various multimodal learning architectures.
Each fusion strategy has distinct implications for model performance, resource requirements, and suitability for specific tasks. Analyzing the impact of these techniques on metrics like accuracy, processing time, and resource efficiency helps identify the best approach for different multimodal tasks. In recent trends, hybrid fusion strategies are becoming popular, as they enable models to capture both low-level and high-level relationships effectively. This exploration of multimodal fusion in Rust demonstrates how different techniques can be implemented and evaluated, underscoring the flexibility and power of Rust for developing complex multimodal models.
8.4. Pre-Training and Fine-Tuning Multimodal Transformers
Pre-training and fine-tuning are foundational techniques for developing multimodal Transformers, enabling models to learn from diverse data sources and adapt to specific tasks. In multimodal contexts, pre-training allows a Transformer to develop cross-modal representations by exposing it to large datasets containing various modalities, such as text and images. These initial stages involve pre-training on general tasks, like masked language modeling, image-text matching, and visual grounding, which are designed to teach the model how to align and integrate information from different modalities. Once pre-training establishes these foundational abilities, fine-tuning allows the model to specialize in particular downstream tasks by refining its learned representations. This two-step approach enables the model to generalize well to new tasks, as the pre-trained cross-modal knowledge is adapted through fine-tuning.
During multimodal pre-training, the model learns to develop representations that capture shared information across modalities. For instance, in masked language modeling (MLM) adapted for multimodal pre-training, a model might predict missing words in a sentence while also using corresponding image regions as context. Given a multimodal input pair $(X_t, X_i)$, where $X_t$ represents text and $X_i$ represents image features, the objective function can be framed as minimizing the error in predicting masked text tokens based on both $X_t$ and $X_i$:
$$ \mathcal{L}_{MLM} = -\log p(X_t^{\text{masked}} | X_t^{\text{context}}, X_i) $$
where $X_t^{\text{masked}}$ are the masked tokens, and $X_t^{\text{context}}$ are the unmasked tokens. This task encourages the model to consider both textual and visual features, strengthening its multimodal understanding. In another common pre-training task, image-text matching, the model learns to predict whether a given image and text pair are semantically related, enhancing its capability to evaluate cross-modal relevance. This objective can be formalized as:
$$\mathcal{L}_{ITM} = -\log p(\text{match} | X_t, X_i)$$
where $p(\text{match} | X_t, X_i)$ denotes the probability that the text and image are correctly paired. These tasks train the model to identify aligned information between modalities, establishing a rich multimodal feature space that can generalize well across downstream tasks.
Fine-tuning builds on this pre-training by refining the model to meet the specific requirements of target applications. The process typically involves retraining the pre-trained multimodal Transformer on task-specific data, adjusting its weights to improve performance on the chosen task. However, fine-tuning multimodal models presents unique challenges. First, the complexity of multimodal data demands careful optimization to avoid overfitting. Techniques such as selective freezing—where only certain layers are trained during fine-tuning—can help retain the model’s generalized knowledge while allowing specialization. Another technique, data augmentation, involves creating variations of the multimodal input data, such as perturbing image features or slightly altering text inputs, to expose the model to a broader range of examples and reduce overfitting risk. Transfer learning is also valuable, allowing the model to use pre-trained weights as a starting point, which is particularly useful for data-scarce tasks.
This Rust code implements a MultimodalTransformer model that fuses text and image data for multimodal tasks such as masked language modeling (MLM) and image-text matching (ITM). The model architecture includes separate encoders for text and image inputs, followed by a fusion layer that combines the encoded representations. This structure allows the model to process and integrate information from both text and image modalities, making it suitable for tasks where combined understanding of both data types is required.
use tch::{nn, Tensor};
// Define the multimodal Transformer with MLM and ITM capabilities
struct MultimodalTransformer {
text_encoder: nn::Linear,
image_encoder: nn::Linear,
fusion_layer: nn::Linear,
}
impl MultimodalTransformer {
fn new(vs: &nn::Path, input_dim: i64, hidden_dim: i64) -> Self {
let text_encoder = nn::linear(vs, input_dim, hidden_dim, Default::default());
let image_encoder = nn::linear(vs, input_dim, hidden_dim, Default::default());
let fusion_layer = nn::linear(vs, hidden_dim * 2, hidden_dim, Default::default());
MultimodalTransformer { text_encoder, image_encoder, fusion_layer }
}
fn forward(&self, text_input: &Tensor, image_input: &Tensor) -> Tensor {
let text_encoded = text_input.apply(&self.text_encoder);
let image_encoded = image_input.apply(&self.image_encoder);
let combined = Tensor::cat(&[text_encoded, image_encoded], 1);
combined.apply(&self.fusion_layer)
}
fn masked_language_modeling(&self, text_input: &Tensor, image_input: &Tensor) -> Tensor {
// Compute MLM loss, where some tokens in `text_input` are masked
let fused = self.forward(text_input, image_input);
fused // Placeholder for actual MLM output; replace with prediction and loss computation
}
fn image_text_matching(&self, text_input: &Tensor, image_input: &Tensor) -> Tensor {
// Compute ITM loss by comparing matching and non-matching pairs
let fused = self.forward(text_input, image_input);
fused // Placeholder for actual ITM output; replace with prediction and loss computation
}
}
fn main() {
let vs = nn::VarStore::new(tch::Device::cuda_if_available());
let input_dim = 512;
let hidden_dim = 256;
let model = MultimodalTransformer::new(&vs.root(), input_dim, hidden_dim);
// Dummy input data for demonstration
let text_input = Tensor::randn(&[1, input_dim], (tch::Kind::Float, tch::Device::Cpu));
let image_input = Tensor::randn(&[1, input_dim], (tch::Kind::Float, tch::Device::Cpu));
// Call forward pass and print output
let output = model.forward(&text_input, &image_input);
println!("Output of Multimodal Transformer (Forward): {:?}", output);
// Call masked_language_modeling and image_text_matching and print their outputs
let mlm_output = model.masked_language_modeling(&text_input, &image_input);
println!("Output of Masked Language Modeling: {:?}", mlm_output);
let itm_output = model.image_text_matching(&text_input, &image_input);
println!("Output of Image-Text Matching: {:?}", itm_output);
}
The MultimodalTransformer struct has three main methods. The forward method applies the text and image encoders to the respective inputs and concatenates their outputs, passing this combined tensor through the fusion layer. The masked_language_modeling method then uses the forward method to produce fused representations, which can be adapted to predict masked tokens in the text input. Similarly, image_text_matching leverages the forward pass to create fused outputs, which can be used for identifying matching or non-matching pairs of text and image inputs. In main, each method is demonstrated with dummy data, providing an overview of how the model processes and combines text and image information.
For fine-tuning, we can adapt this model to a specific task, such as visual question answering, by retraining the model with domain-specific data. Fine-tuning may involve freezing certain layers to preserve pre-trained representations, as follows:
fn fine_tune_model(model: &MultimodalTransformer, optimizer: &mut dyn nn::Optimizer, text_input: &Tensor, image_input: &Tensor, task_output: &Tensor) {
// Optionally freeze layers
model.text_encoder.freeze();
// Forward pass with task-specific data
let predictions = model.forward(text_input, image_input);
// Compute loss against task-specific output and backpropagate
let loss = predictions.mse_loss(task_output, tch::Reduction::Mean);
optimizer.backward_step(&loss);
}
Here, fine-tuning is achieved by selectively freezing the text encoder, retaining the general knowledge from pre-training, and updating the weights of remaining layers based on task-specific data. This helps the model retain its multimodal alignment while adapting to new requirements, such as accurately answering visual questions.
In industry, multimodal Transformers pre-trained and fine-tuned on large datasets have revolutionized applications that require cross-modal understanding. For instance, in medical diagnostics, multimodal models are fine-tuned on datasets combining patient records and diagnostic images, helping improve diagnostic accuracy. Recent trends also show that transfer learning with multimodal Transformers enhances accuracy in domains like automated surveillance, where video and audio inputs require sophisticated cross-modal reasoning.
Overall, pre-training and fine-tuning multimodal Transformers establish a robust learning framework for models to generalize across multimodal tasks. Implementing these techniques in Rust, as demonstrated, underscores the language’s potential for efficient and scalable AI development, making it suitable for building complex, high-performance multimodal learning systems. The combination of diverse pre-training tasks and adaptive fine-tuning strategies ensures that multimodal Transformers can effectively integrate and adapt to a wide array of real-world applications.
8.5. Extensions and Applications of Multimodal Transformers
Multimodal Transformers have become pivotal in advancing AI capabilities across complex, real-world applications, thanks to their ability to integrate information from diverse modalities. These models, particularly advanced extensions like Multimodal BERT (MMBERT), Visual-Linguistic BERT (ViLBERT), and UNITER, have been designed to handle intricate interactions between text, images, and even more data types, enabling a rich and versatile understanding across tasks. MMBERT, for instance, extends BERT's architecture to accommodate multiple input modalities by implementing parallel encoders that interact via cross-attention layers. ViLBERT further separates visual and linguistic features into dual streams, allowing detailed alignment across image regions and text phrases. Meanwhile, UNITER integrates visual and textual data within a single unified transformer structure, optimizing both self-attention and cross-attention for efficient multimodal reasoning. These architectural innovations enhance the models’ ability to align features across modalities, yielding more context-aware and robust multimodal representations.
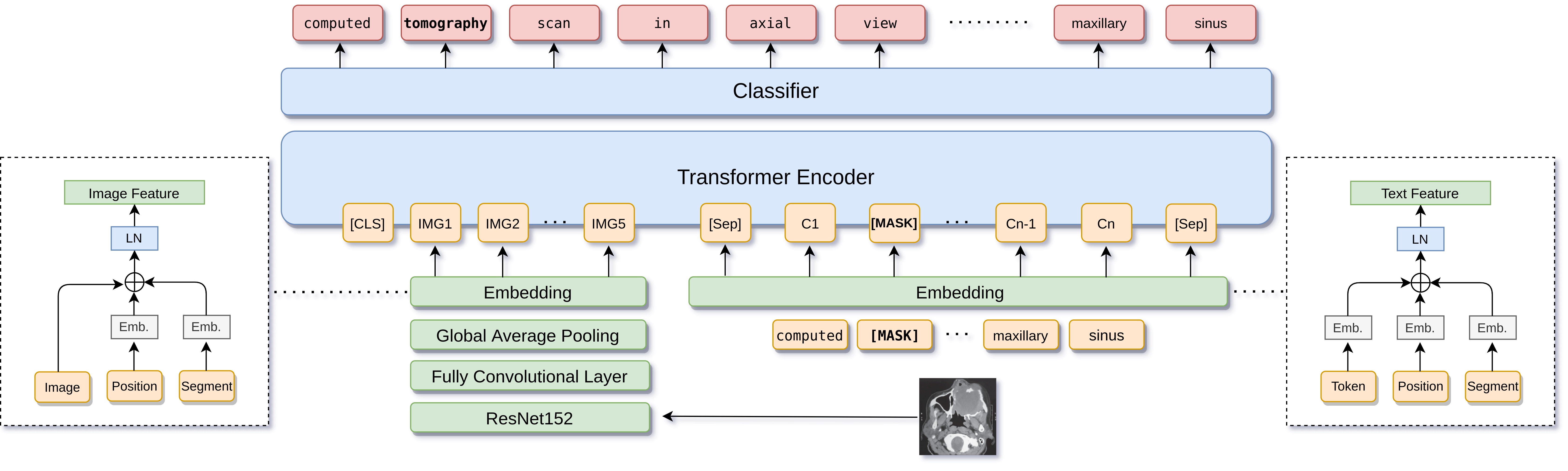
Figure 7: Illustration of multimodal BERT (MMBERT) architecture for medical image.
The applications of multimodal Transformers are widespread and diverse. In healthcare, these models are employed in medical imaging analysis combined with text-based patient data, supporting diagnostic systems that benefit from a comprehensive understanding of medical history and imaging results. For example, a multimodal Transformer can be pre-trained on a dataset that pairs chest X-rays with associated medical reports. During pre-training, the model learns to align specific image features with relevant textual terms, which can later assist in diagnosing lung conditions when fine-tuned on specialized medical data. In autonomous driving, multimodal Transformers contribute to sensor fusion, combining data from LIDAR, radar, and camera feeds to create a reliable, real-time model of the environment. These models enable vehicles to make accurate decisions even in complex, dynamic environments. Similarly, in the entertainment industry, video content analysis benefits from multimodal Transformers by combining video frames, audio, and subtitles to automatically generate tags, detect themes, and provide video summaries. The integration across text, image, and audio components enables richer and more contextual content analysis, improving user experience in applications like content recommendation and automated editing.
Expanding multimodal Transformers to accommodate additional data types, such as audio and sensor readings, further enhances their versatility in real-time applications. For instance, audio embeddings can be integrated into the model by extending the architecture to include an audio encoder, which aligns audio cues with text and visual data. Mathematically, given image embeddings $X_i$, text embeddings $X_t$, and audio embeddings $X_a$, the multimodal representation $Z$ can be formulated by combining these embeddings in a shared latent space:
$$ Z = \text{Combine}\left(\text{CrossAttention}(X_i, X_t), \text{CrossAttention}(X_i, X_a), \text{CrossAttention}(X_t, X_a)\right) $$
where CrossAttention represents a function that aligns two modalities by computing attention weights across their feature dimensions. This approach allows the model to capture nuanced relationships between modalities, such as the synchronization between visual cues and auditory features, which is critical in applications like live translation and immersive VR experiences.
The ability of multimodal Transformers to span different AI domains brings the potential for integrated solutions to complex, multidimensional problems. By combining modalities like images, text, audio, and sensor data, these models facilitate a unified approach to AI, where models trained on various modalities can interact seamlessly. This capability holds promise for human-computer interaction, where a multimodal Transformer can interpret gestures, speech, and facial expressions in concert, enabling more intuitive interactions in assistive technology, virtual reality, and customer service bots.
However, deploying multimodal Transformers in sensitive domains raises ethical considerations, especially regarding privacy, bias, and reliability in high-stakes decisions. In healthcare, for example, models that handle medical imaging and patient reports must safeguard privacy and comply with regulations like HIPAA. Additionally, biased datasets can lead to disparities in diagnostic performance, which is particularly concerning in medical applications. Implementing safeguards to mitigate these risks is essential. Techniques such as differential privacy can protect sensitive data, while fairness-aware training protocols help reduce model bias. In autonomous driving, safety is paramount, as sensor fusion systems must function reliably to prevent accidents. Ensuring robustness under various environmental conditions is crucial, and testing models under diverse scenarios can help identify and address potential failure modes.
This code implements a simplified Multimodal BERT (MMBERT) model designed for binary classification tasks using both text and image data. The model architecture consists of a text encoder, an image encoder (using convolutional neural network layers), a fusion layer to combine the encoded outputs, and a classifier layer to produce predictions. The model combines the features from the text and image inputs and classifies them into one of two categories. Additionally, helper functions handle data preprocessing for both text and image inputs, while the main function handles the training loop with loss computation and backpropagation.
use tch::{nn, nn::OptimizerConfig, Device, Tensor};
use image::ImageReader; // Updated to the latest ImageReader location
// Define the MMBERT model
struct MMBERT {
text_encoder: nn::Linear,
image_encoder: nn::Sequential,
fusion_layer: nn::Linear,
classifier: nn::Linear,
}
impl MMBERT {
fn new(vs: &nn::Path, text_dim: i64, hidden_dim: i64, output_dim: i64) -> Self {
let text_encoder = nn::linear(vs, text_dim, hidden_dim, Default::default());
// Define CNN for image encoding
let image_encoder = nn::seq()
.add(nn::conv2d(vs, 1, 32, 3, Default::default()))
.add_fn(|x| x.relu())
.add_fn(|x| x.max_pool2d_default(2))
.add(nn::conv2d(vs, 32, 64, 3, Default::default()))
.add_fn(|x| x.relu())
.add_fn(|x| x.max_pool2d_default(2))
.add_fn(|x| x.flatten(1, -1)); // Flatten for fully connected layer
let fusion_layer = nn::linear(vs, hidden_dim * 2, hidden_dim, Default::default());
let classifier = nn::linear(vs, hidden_dim, output_dim, Default::default());
Self { text_encoder, image_encoder, fusion_layer, classifier }
}
fn forward(&self, text_input: &Tensor, image_input: &Tensor) -> Tensor {
let text_emb = text_input.apply(&self.text_encoder);
let image_emb = image_input.apply(&self.image_encoder);
// Concatenate text and image embeddings
let combined = Tensor::cat(&[text_emb, image_emb], 1);
let fused = combined.apply(&self.fusion_layer);
fused.apply(&self.classifier)
}
}
// Function to load and preprocess text data (simple version for demonstration)
fn load_text_data(text: &str, max_len: usize) -> Tensor {
let ids = text.chars()
.take(max_len)
.map(|c| c as i64) // Map each character to its ASCII value
.collect::<Vec<_>>();
let padded = if ids.len() < max_len {
let mut padded_ids = ids.clone();
padded_ids.extend(vec![0; max_len - ids.len()]);
padded_ids
} else {
ids
};
Tensor::of_slice(&padded).unsqueeze(0) // Return a batch of 1
}
// Alternative image loading function using the `image` crate
fn load_image_custom(path: &str) -> Result<Tensor, Box<dyn std::error::Error>> {
let img = ImageReader::open(path)?.decode()?.to_luma8(); // Convert to grayscale (single channel)
let img = image::imageops::resize(&img, 224, 224, image::imageops::FilterType::Triangle);
let img_tensor = Tensor::of_slice(img.as_raw())
.view([1, 224, 224])
.unsqueeze(0)
.to_kind(tch::Kind::Float) / 255.0;
Ok(img_tensor)
}
// Main training loop
// Main training loop
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Set up device and variables
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
// Define model parameters
let text_dim = 128; // Adjusted for ASCII encoding
let hidden_dim = 256;
let output_dim = 2; // Example binary classification
let model = MMBERT::new(&vs.root(), text_dim, hidden_dim, output_dim);
let mut optimizer = nn::Adam::default().build(&vs, 1e-4)?;
// Load and preprocess data (dummy example)
let text_data = "Patient shows signs of pneumonia.";
let text_tensor = load_text_data(text_data, 128).to(device);
// Load image using custom loader and handle potential errors
let image_tensor = match load_image_custom("path/to/xray_image.png") {
Ok(img) => img.to_device(device),
Err(e) => {
eprintln!("Error loading image: {:?}", e);
return Err(e.into()); // Convert error directly into a boxed trait object
}
};
// Training loop
for epoch in 1..=10 {
optimizer.zero_grad();
// Forward pass
let output = model.forward(&text_tensor, &image_tensor);
let target = Tensor::of_slice(&[1]).to_device(device); // Example target label
// Compute loss and backpropagate
let loss = output.cross_entropy_for_logits(&target);
println!("Epoch: {}, Loss: {:.4}", epoch, loss.double_value(&[])); // Use double_value for scalar conversion
loss.backward();
optimizer.step();
}
Ok(())
}
The code first initializes the MMBERT model with specified input dimensions and optimizer configuration. It preprocesses the text by converting it to ASCII and padding it as necessary, while the image is converted to grayscale, resized, and transformed into a tensor. In each epoch, the code performs a forward pass, calculating the embeddings for text and image, concatenating them, and passing through the fusion and classifier layers. The model's output is compared against a target label using cross-entropy loss, and backpropagation is applied to update model weights. Error handling for image loading ensures smooth operation even if the image path is incorrect. This setup effectively demonstrates multimodal learning on combined text and image data with PyTorch in Rust.
In high-stakes applications, evaluating the ethical implications of deploying multimodal Transformers is crucial, especially in Rust, where safety features can be integrated into the model pipeline. For instance, implementing privacy-preserving techniques, such as differential privacy, ensures that user data remains protected even as it contributes to model training. Furthermore, error detection mechanisms, designed to identify failure modes, can improve the model’s reliability by flagging uncertain predictions in critical applications like healthcare and autonomous driving. Implementing these safeguards in Rust’s statically typed, memory-safe environment enhances model robustness and provides a solid foundation for responsibly deploying multimodal Transformers in real-world settings.
As multimodal Transformers continue to evolve, their applications will likely expand, providing valuable tools across industries. In Rust, the efficient handling of complex data and the strong concurrency model make it a promising choice for developing high-performance multimodal systems that can be deployed in critical applications. By combining innovative extensions with ethical deployment practices, multimodal Transformers represent a powerful frontier in AI that Rust is well-suited to help develop and bring to industry.
8.6. Challenges and Future Directions
Multimodal learning is evolving rapidly to tackle the complexities of diverse real-world applications, but it continues to face several significant challenges. A primary concern is data scarcity, which is particularly prevalent in domains like medical imaging combined with clinical text data, where high-quality labeled datasets are limited. Additionally, modality imbalance poses a risk, as models may encounter an abundance of data for certain modalities while struggling with others. This can lead to skewed learning, where models favor well-represented modalities, thus hindering their generalizability across all data types. Furthermore, aligning heterogeneous data types, such as synchronizing text sequences with the spatial and temporal features of image and audio data, introduces additional complexities that demand sophisticated modeling techniques to capture the intricate interdependencies across modalities.
To effectively evaluate multimodal models, it is crucial to develop robust metrics that accurately reflect their performance across various modalities. Traditional metrics often fall short, as they may overlook the interactions between modalities. For instance, in tasks like visual question answering, where both visual and textual inputs are essential, existing metrics that focus solely on visual accuracy do not suffice. Comprehensive evaluation frameworks are being proposed to assess alignment and interactions between modalities, ensuring that models not only capture multimodal correlations but also maintain temporal synchronization and contextual consistency. These new metrics aim to proportionally weigh performance across each modality and evaluate the quality of their fusion, resulting in a more balanced and contextually accurate assessment.
Emerging trends in multimodal learning are pushing towards integrating a broader array of modalities and leveraging self-supervised learning frameworks to exploit vast amounts of unlabeled data. Self-supervised multimodal learning, for instance, allows the model to learn representations by predicting relationships within the data itself, without needing extensive labeled datasets. For instance, in image and text pairing, the model might predict the text based on the image content or vice versa, learning cross-modal relationships in an unsupervised manner. Mathematically, this process can be represented as optimizing a contrastive loss function, where the model minimizes the distance between related pairs $(X_t, X_i)$ and maximizes the distance between unrelated pairs:
$$ \mathcal{L}_{contrastive} = \sum_{(X_t, X_i) \in P} \left[ 1 - \cos(f(X_t), f(X_i)) \right] + \sum_{(X_t, X_i) \in N} \left[ \cos(f(X_t), f(X_i)) \right] $$
where $P$ represents positive (related) pairs, and $N$ represents negative (unrelated) pairs. This learning approach enables the model to derive meaningful representations from large-scale data with limited labeling, proving highly beneficial in domains with sparse labeled datasets, such as autonomous driving, where labeled data from sensors and video is costly to produce.
MobileCLIP exemplifies a significant advancement in multimodal learning, representing a family of efficient CLIP-like models that utilize FastViT-based image encoders to deliver high-performance multimodal capabilities in resource-constrained environments. By integrating lightweight Vision Transformers (ViT) into the CLIP architecture, MobileCLIP achieves competitive accuracy while considerably reducing computational overhead, making it suitable for mobile and edge devices. This innovative design allows the model to effectively interpret and relate images and text, thereby facilitating a variety of applications, including image retrieval, zero-shot classification, and content-based recommendation systems. By bridging the gap between high-capacity models and practical deployment scenarios, MobileCLIP enhances accessibility for diverse AI applications, driving forward the capabilities of multimodal learning in real-world contexts.
[dependencies]
anyhow = "1.0.90"
candle-core = "0.7.2"
candle-examples = "0.7.2"
candle-nn = "0.7.2"
candle-transformers = "0.7.2"
hf-hub = "0.3.2"
image = "0.25.4"
tokenizers = "0.20.1"
use anyhow::Error as E;
use candle_core::{DType, Device, Tensor};
use candle_nn::{ops::softmax, VarBuilder};
use candle_transformers::models::mobileclip;
use tokenizers::Tokenizer;
#[derive(Clone, Copy, Debug)]
enum Which {
S1,
// S2, // Remove this line to eliminate the warning
}
impl Which {
fn model_name(&self) -> String {
let name = match self {
Self::S1 => "S1",
// Self::S2 => "S2", // Remove this line
};
format!("apple/MobileCLIP-{}-OpenCLIP", name)
}
fn config(&self) -> mobileclip::MobileClipConfig {
match self {
Self::S1 => mobileclip::MobileClipConfig::s1(),
// Self::S2 => mobileclip::MobileClipConfig::s2(), // Remove this line
}
}
}
fn load_images<T: AsRef<std::path::Path>>(
paths: &Vec<T>,
image_size: usize,
) -> anyhow::Result<Tensor> {
let mut images = vec![];
for path in paths {
let tensor = candle_examples::imagenet::load_image_with_std_mean(
path,
image_size,
&[0.0, 0.0, 0.0],
&[1.0, 1.0, 1.0],
)?;
images.push(tensor);
}
let images = Tensor::stack(&images, 0)?;
Ok(images)
}
pub fn main() -> anyhow::Result<()> {
let model_name = Which::S1.model_name();
let api = hf_hub::api::sync::Api::new()?;
let api = api.model(model_name);
let model_file = api.get("open_clip_model.safetensors")?;
let tokenizer = api.get("tokenizer.json")?;
let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;
let config = &Which::S1.config();
let device = candle_examples::device(false)?; // Using CPU for simplicity
// Hard-coded image paths
let vec_imgs = vec![
"candle-examples/examples/stable-diffusion/assets/stable-diffusion-xl.jpg".to_string(),
"candle-examples/examples/yolo-v8/assets/bike.jpg".to_string(),
];
let images = load_images(&vec_imgs, config.image_size)?.to_device(&device)?;
// Wrap the unsafe call in an unsafe block
let vb = unsafe {
VarBuilder::from_mmaped_safetensors(&[model_file.clone()], DType::F32, &device)?
};
let model = mobileclip::MobileClipModel::new(vb, config)?;
// Hard-coded sequences for testing
let vec_seq = vec![
"a cycling race".to_string(),
"a photo of two cats".to_string(),
"a robot holding a candle".to_string(),
];
// Clone vec_seq to avoid moving
let (input_ids, _) = tokenize_sequences(Some(vec_seq.clone()), &tokenizer, &device)?;
let (_logits_per_text, logits_per_image) = model.forward(&images, &input_ids)?;
let softmax_image = softmax(&logits_per_image, 1)?;
let softmax_image_vec = softmax_image.flatten_all()?.to_vec1::<f32>()?;
println!("softmax_image_vec: {:?}", softmax_image_vec);
let probability_vec = softmax_image_vec
.iter()
.map(|v| v * 100.0)
.collect::<Vec<f32>>();
let probability_per_image = probability_vec.len() / vec_imgs.len();
for (i, img) in vec_imgs.iter().enumerate() {
let start = i * probability_per_image;
let end = start + probability_per_image;
let prob = &probability_vec[start..end];
println!("\n\nResults for image: {}\n", img);
for (i, p) in prob.iter().enumerate() {
println!("Probability: {:.4}% Text: {}", p, vec_seq[i]);
}
}
Ok(())
}
pub fn tokenize_sequences(
sequences: Option<Vec<String>>,
tokenizer: &Tokenizer,
device: &Device,
) -> anyhow::Result<(Tensor, Vec<String>)> {
let pad_id = 0; // Padding ID
let vec_seq = match sequences {
Some(seq) => seq,
None => vec![
"a cycling race".to_string(),
"a photo of two cats".to_string(),
"a robot holding a candle".to_string(),
],
};
let mut tokens = vec![];
for seq in vec_seq.clone() {
let encoding = tokenizer.encode(seq, true).map_err(E::msg)?;
tokens.push(encoding.get_ids().to_vec());
}
let max_len = tokens.iter().map(|v| v.len()).max().unwrap_or(0);
for token_vec in tokens.iter_mut() {
let len_diff = max_len - token_vec.len();
if len_diff > 0 {
token_vec.extend(vec![pad_id; len_diff]);
}
}
let input_ids = Tensor::new(tokens, device)?;
Ok((input_ids, vec_seq))
}
The provided Rust code demonstrates the implementation of the MobileCLIP model, focusing on its deployment for multimodal tasks involving images and text. It begins by defining an enumeration Which to differentiate between different model configurations (e.g., S1, S2), which specify the MobileCLIP architecture to use. The main function initializes the model by loading the necessary weights and tokenizer from the Hugging Face Hub. It then processes hard-coded image paths and sequences to prepare the input data. The images are loaded and preprocessed, and the sequences are tokenized for compatibility with the model. The core functionality includes running the model's forward pass to compute logits for both images and text, applying a softmax operation to obtain probabilities, and then displaying the results. The code effectively encapsulates the workflow of utilizing MobileCLIP for multimodal inference, providing a clear and efficient framework for deployment.
To effectively tackle the challenges of modality imbalance and data scarcity in multimodal learning, targeted techniques such as data augmentation, synthetic data generation, and transfer learning are crucial. Data augmentation methods can help balance modalities by generating new variations of existing data, such as altering image contrast or introducing noise to audio signals. In the context of the MobileCLIP implementation in Rust, this can be accomplished by applying transformations to images before feeding them into the model. Synthetic data generation serves to alleviate data scarcity by creating artificial samples that mimic the underlying distribution of each modality, enhancing the robustness of the training dataset. Furthermore, transfer learning allows for the adaptation of pre-trained models, like MobileCLIP, which is designed for abundant image-text pairs, to tasks that may require specialized modalities, such as video and text analysis. In the Rust environment, utilizing the tch-rs library enables efficient tensor operations and model weight management, which are essential for implementing these techniques.
Self-supervised multimodal learning frameworks provide an additional avenue for advancing multimodal models, particularly in low-resource settings. These frameworks enable models to learn useful representations through cross-modal alignment tasks without needing extensive labeled datasets. For instance, in the Rust implementation, a contrastive learning pipeline could be established where the model distinguishes between positive and negative multimodal pairs. By defining a contrastive loss function and developing a data loader to generate these pairs, developers can leverage Rust’s capabilities to facilitate effective self-supervised learning.
Accurately assessing model performance in multimodal contexts necessitates the development of new evaluation metrics that account for the complexities inherent in these tasks. Standard metrics may not fully capture how well the model fuses and aligns different modalities. For example, implementing a cross-modal accuracy metric in the provided Rust code could involve evaluating the consistency of feature alignment between paired images and text inputs. A fusion quality score could further enhance evaluation by measuring the model's effectiveness in tasks requiring integrated modalities. This could be incorporated into the Rust framework by defining custom loss functions and accuracy calculations, enabling robust testing frameworks to compare multimodal and unimodal performance.
The burgeoning field of multimodal learning is paving the way for innovations in various domains, including robotics, augmented reality (AR), and personalized AI. In robotics, multimodal models can enhance navigation and manipulation by integrating diverse sensor data, visual information, and linguistic commands. Similarly, AR applications benefit from multimodal Transformers that synchronize spatial and temporal features across different data types, creating seamless user experiences. Personalized AI systems harness the power of multimodal learning to tailor interactions based on a combination of user inputs, such as voice, text, and images, thereby adapting to individual preferences.
Implementing multimodal learning solutions in Rust that address issues of modality imbalance, optimize data scarcity, and test novel evaluation metrics demonstrates the language's potential for handling complex AI challenges. Rust’s performance and memory safety features are essential for building efficient, reliable systems that operate in real-time—qualities critical in fields like AR and robotics. By advancing multimodal learning capabilities in Rust, developers can create resource-efficient models that bridge modalities and spur innovation across a wide range of applications.
8.7. Conclusion
Chapter 8 equips readers with a comprehensive understanding of multimodal Transformers and their extensions, offering the tools and knowledge needed to implement and optimize these models using Rust. By mastering these concepts, readers will be prepared to develop advanced AI systems capable of processing and integrating multiple data modalities, paving the way for innovative solutions across various industries.
8.7.1. Further Learning with GenAI
These prompts are designed to be comprehensive and technically challenging, pushing readers to deepen their understanding of how multimodal Transformers work, how they can be optimized, and how they can be applied to solve a variety of NLP and vision tasks.
Explore how multimodal learning models can integrate diverse data modalities like text, images, and audio to create enriched representations. Discuss advanced techniques for overcoming challenges such as modality-specific noise, synchronization, and semantic alignment.
Delve into the advanced applications of multimodal learning across domains like image captioning, video understanding, and multimodal sentiment analysis. How do these models surpass unimodal approaches in terms of accuracy, robustness, and contextual understanding?
Analyze the complexities involved in aligning and fusing heterogeneous data modalities in multimodal learning. What are the cutting-edge strategies for achieving effective fusion, particularly when dealing with high-dimensional, unstructured, or asynchronous data?
Provide a detailed, step-by-step guide for implementing a sophisticated multimodal learning model in Rust, focusing on the seamless integration of text and image data. Include best practices for model optimization, modular design, and performance benchmarking.
Examine the architectural modifications necessary to adapt the Transformer model for advanced multimodal tasks. How can Transformers be optimized to efficiently process and integrate multiple data streams without compromising on speed or accuracy?
Investigate the role of cross-modal attention mechanisms in multimodal Transformers. How do these mechanisms enhance the model's ability to focus on the most relevant features across modalities, and what are the state-of-the-art approaches to improving their effectiveness?
Compare and contrast leading multimodal Transformer models such as ViLBERT, UNITER, and MMBERT. What are their unique architectural features, and how do they excel in specific multimodal tasks like visual question answering or image-text matching?
Discuss the challenges and best practices for implementing a robust multimodal Transformer in Rust, particularly for integrating complex modalities like text and images. How can you ensure the model's scalability and efficiency in real-world applications?
Explore the different cross-modal attention mechanisms used in multimodal Transformers, such as self-attention, cross-attention, and co-attention. How do these mechanisms influence the model's performance across various multimodal tasks, and how can they be effectively implemented in Rust?
Provide an in-depth analysis of multimodal fusion techniques, including early fusion, late fusion, and hybrid fusion. How do these approaches differ in their ability to manage data from diverse modalities, and what are the trade-offs in terms of model complexity and interpretability?
Guide through the implementation of advanced multimodal fusion strategies in Rust, with a focus on optimizing the fusion process for tasks like speech recognition or video analysis. Discuss how to balance processing efficiency with the quality of the fused output.
Examine the technical challenges in synchronizing and aligning temporal and spatial features across modalities during the fusion process. What are the most effective methods for ensuring that multimodal models accurately capture and utilize these features?
Discuss the significance of pre-training multimodal Transformers on large, diverse datasets. What are the most advanced pre-training tasks, and how do they contribute to learning rich cross-modal representations that generalize well across different downstream applications?
Explore advanced techniques for fine-tuning pre-trained multimodal Transformers on specific tasks. How can strategies like selective freezing of layers, data augmentation, and transfer learning be optimized to enhance the model's performance while mitigating overfitting?
Detail the process of implementing a comprehensive pre-training pipeline for multimodal Transformers in Rust, focusing on tasks such as image-text matching and masked language modeling. Include discussions on data preprocessing, model architecture, and training optimization.
Investigate the challenges and solutions for extending multimodal Transformers to handle additional modalities, such as audio or sensor data. How can these extended models be effectively applied in high-stakes fields like healthcare, autonomous driving, or augmented reality?
Analyze the ethical implications of deploying multimodal models in sensitive domains, including privacy concerns, bias amplification, and decision-making transparency. How can these ethical challenges be addressed through thoughtful model design and implementation in Rust?
Explore the key challenges in multimodal learning, such as data scarcity, modality imbalance, and the alignment of heterogeneous data types. What are the most promising techniques, including data augmentation and transfer learning, for addressing these challenges in real-world scenarios?
Provide an in-depth exploration of self-supervised learning in multimodal models. How can this approach be leveraged to train multimodal Transformers using vast amounts of unlabeled data, and what are the cutting-edge methods for implementing self-supervised learning in Rust?
Discuss the development and evaluation of new metrics for assessing multimodal models. How can these metrics be designed to accurately capture the complexities of multimodal learning, and what are the best practices for implementing and validating them in Rust?
By engaging with these prompts, readers will gain valuable insights into the nuances of multimodal Transformers models, while also developing practical skills in implementing and fine-tuning these models using Rust.
8.7.2. Hands On Practices
Self-Exercise 8.1: Implementing Multimodal Fusion Techniques in Rust
Objective: To understand and implement various multimodal fusion techniques in Rust, comparing their effectiveness in combining text and image data for a specific task.
Tasks:
Implement three different multimodal fusion techniques in Rust: early fusion, late fusion, and hybrid fusion. Ensure that the implementations can handle text and image data.
Integrate these fusion techniques into a multimodal model designed for a task like image captioning or visual question answering.
Train the multimodal model using each fusion technique, and evaluate their impact on task performance, focusing on accuracy, processing speed, and resource efficiency.
Analyze the strengths and weaknesses of each fusion strategy based on the results, considering factors such as data alignment, complexity, and scalability.
Deliverables:
A Rust codebase implementing early, late, and hybrid fusion techniques in a multimodal model.
A comparative analysis report detailing the performance of each fusion technique, including metrics on accuracy, processing time, and resource usage.
Visualizations or examples of model outputs for each fusion strategy, highlighting differences in how the model integrates and interprets multimodal data.
Self-Exercise 2: Fine-Tuning a Pre-Trained Multimodal Transformer for a Custom Task
Objective:\ To practice fine-tuning a pre-trained multimodal Transformer on a specialized task using Rust, and evaluate its performance against a baseline model.
Tasks:
Load a pre-trained multimodal Transformer (e.g., ViLBERT or UNITER) and prepare it for fine-tuning on a custom task, such as image captioning or visual question answering.
Implement the fine-tuning process in Rust, focusing on adapting the model’s parameters to the specific dataset and task while preserving its multimodal capabilities.
Train the fine-tuned model on a domain-specific multimodal dataset, monitoring for overfitting and other challenges.
Compare the performance of the fine-tuned Transformer model with a baseline model trained from scratch, analyzing the benefits of transfer learning and multimodal pre-training.
Deliverables:
A Rust codebase for fine-tuning a pre-trained multimodal Transformer on a custom task.
A training report that includes insights into the fine-tuning process, challenges encountered, and strategies used to optimize performance.
A comparative analysis report showing the performance of the fine-tuned model versus a baseline model, with metrics such as accuracy, fluency, and task-specific outcomes.
Self-Exercise 3: Implementing Cross-Modal Attention Mechanisms in Multimodal Transformers
Objective:\ To explore the role of cross-modal attention in multimodal Transformers by implementing and experimenting with different cross-modal attention mechanisms in Rust.
Tasks:
Implement cross-modal attention mechanisms in a multimodal Transformer model in Rust, focusing on how these mechanisms align and integrate features from different modalities.
Train the multimodal Transformer model on a task that requires cross-modal understanding, such as visual question answering or video-text retrieval.
Experiment with different configurations of cross-modal attention, such as varying the number of attention heads or adjusting the alignment strategy, to optimize model performance.
Evaluate the effectiveness of cross-modal attention by comparing the model’s performance with and without these mechanisms, analyzing their impact on the accuracy and coherence of multimodal outputs.
Deliverables:
A Rust codebase implementing cross-modal attention mechanisms in a multimodal Transformer model.
A detailed report on the experiments conducted with different cross-modal attention configurations, including performance metrics and insights into their impact on task outcomes.
Visualizations or examples of how cross-modal attention influences the model’s decision-making process, with a focus on alignment and feature integration.
Self-Exercise 4: Addressing Modality Imbalance in Multimodal Learning
Objective:\ To tackle the challenges of modality imbalance in multimodal learning by implementing techniques in Rust to enhance model performance when dealing with imbalanced multimodal datasets.
Tasks:
Identify a multimodal dataset that exhibits modality imbalance (e.g., more textual data than visual data).
Implement techniques in Rust to address modality imbalance, such as data augmentation, modality-specific weighting, or synthetic data generation for the underrepresented modality.
Train a multimodal model using the implemented techniques and evaluate its performance on a task that requires balanced multimodal understanding.
Analyze the impact of these techniques on model performance, particularly in terms of accuracy, robustness, and the model’s ability to integrate information from both modalities effectively.
Deliverables:
A Rust implementation of techniques to address modality imbalance in multimodal learning.
A performance report comparing the model’s results before and after applying these techniques, including metrics on accuracy, modality integration, and generalization.
A detailed analysis of the effectiveness of each technique, with recommendations for addressing modality imbalance in different multimodal learning scenarios.
Self-Exercise 5: Implementing and Evaluating Self-Supervised Multimodal Learning
Objective:\ To explore self-supervised learning in the context of multimodal learning by implementing a self-supervised multimodal model in Rust and evaluating its performance on downstream tasks.
Tasks:
Implement a self-supervised learning framework in Rust that leverages large amounts of unlabeled multimodal data to pre-train a multimodal Transformer model.
Design and implement pre-training tasks such as masked language modeling, image-text matching, or visual grounding, using self-supervised techniques.
Fine-tune the self-supervised multimodal model on a labeled dataset for a specific downstream task, such as image captioning or multimodal sentiment analysis.
Evaluate the performance of the self-supervised multimodal model on the downstream task, comparing it with a model trained using traditional supervised learning methods.
Deliverables:
A Rust codebase implementing a self-supervised learning framework for multimodal Transformers, including pre-training tasks.
A report detailing the pre-training and fine-tuning processes, including the challenges and strategies used to optimize self-supervised learning.
A comparative analysis of the self-supervised model’s performance versus a supervised learning model, with insights into the benefits and limitations of self-supervised multimodal learning.
Comments