Chapter 6
‘Generative Models: GPT and Beyond’
"Generative models like GPT represent a leap forward in our ability to synthesize human-like text, reflecting the profound potential of AI to understand and generate complex language." — Yann LeCun
Chapter 6 of LMVR provides an in-depth exploration of generative models, with a particular focus on GPT and its variants. The chapter begins by introducing the basics of generative models, distinguishing them from discriminative models, and discussing their applications in natural language processing (NLP). It then delves into the GPT architecture, explaining its autoregressive nature, training process, and the benefits of leveraging Transformer models. The chapter also covers advancements in GPT variants, including GPT-2 and GPT-3, examining the impact of scaling on performance and the ethical considerations of deploying large models. Practical sections include implementing basic generative models in Rust, training GPT models, and comparing different GPT variants to understand their strengths and limitations.
6.1. Introduction to Generative Models
Generative models play a crucial role in machine learning by modeling the underlying distribution of data, allowing them to generate new instances that resemble the data they have been trained on. This contrasts with discriminative models, which focus on distinguishing between different classes of data. Generative models aim to understand and reproduce the data distribution itself, which makes them particularly useful in tasks like text generation, summarization, and translation in the domain of natural language processing (NLP). While discriminative models like classification networks are designed to assign labels or categories to inputs, generative models capture the structure and patterns within the data to create new, plausible outputs.
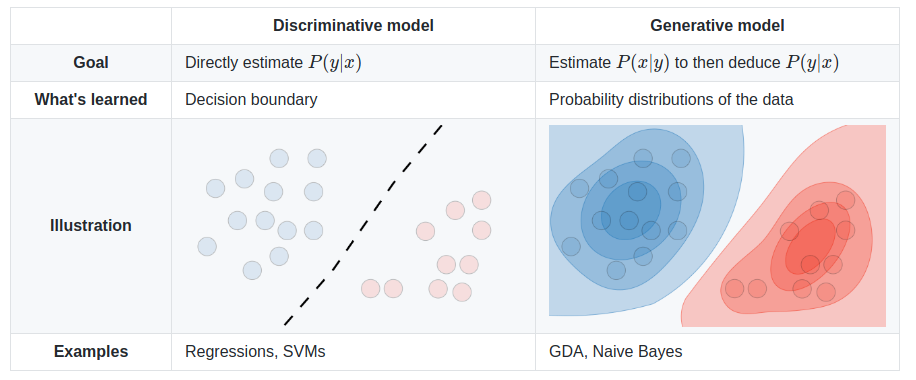
Figure 1: Discriminative vs Generative Models.
In the context of NLP, generative models have become fundamental in producing high-quality, human-like text. Their applications span from generating coherent sentences to summarizing vast amounts of information into concise, meaningful text, and even translating languages with remarkable accuracy. Models like GPT (Generative Pretrained Transformer) exemplify the capability of generative models to create fluid and contextually appropriate text based on a given input or prompt. These models do not merely generate random sequences; instead, they model language patterns, grammar, and semantics, producing text that often mirrors human expression.
At the core of generative models lies their ability to learn the distribution of data. This involves capturing the probability distribution $P(X)$, where $X$ represents the data, such as sentences in a corpus. For autoregressive models, the key idea is to factor the joint probability distribution of a sequence of words into a product of conditional probabilities. For example, in the case of text generation, the probability of the entire sequence is modeled as:
$$P(X) = P(x_1)P(x_2 | x_1)P(x_3 | x_1, x_2) \dots P(x_n | x_1, x_2, \dots, x_{n-1}),$$
where $x_i$ represents each word in the sequence. By learning these conditional probabilities, the model can generate new text one word at a time, based on the previously generated words.
Generative models like GPT utilize autoregressive methods, where the output at each step is conditioned on the previous tokens in the sequence. The Transformer architecture behind GPT has revolutionized generative modeling due to its efficient handling of long-range dependencies through self-attention mechanisms. In this self-attention mechanism, each token in the input sequence attends to all other tokens, enabling the model to capture both local and global patterns within the data. This allows models like GPT to generate coherent and contextually rich text by paying attention to all words in a sentence rather than just neighboring ones, as was the case with earlier models like recurrent neural networks (RNNs) and long short-term memory networks (LSTMs).
Another important concept powering modern generative models is self-supervised learning. In self-supervised learning, the model is trained on tasks where parts of the input data are masked or corrupted, and the model is asked to predict the missing parts. This type of training enables models to learn from vast amounts of unlabeled data, which is critical for large-scale generative models like GPT. By predicting missing words or phrases in a sentence, the model learns the relationships between words and the underlying structure of language. This technique forms the foundation of many state-of-the-art models in NLP today.
The practical implementation of generative models has traditionally been facilitated by frameworks like PyTorch and TensorFlow, but Rust is now gaining traction in the deep learning community due to its performance, low-level control, and memory safety benefits. In Rust, implementing a generative model for tasks like text generation can be achieved using libraries such as tch-rs, rust-bert, and candle. The tch-rs crate provides Rust bindings to PyTorch’s C++ backend, enabling seamless access to pre-trained models and custom training in Rust. Similarly, rust-bert leverages tch-rs to offer pre-trained transformer models, such as GPT-2, for text generation and other NLP tasks. The candle crate, on the other hand, is a native Rust deep learning framework that focuses on providing efficient model implementations and is increasingly being used for experimental and production applications in Rust.
To implement a generative model in Rust, one could use an autoregressive model like GPT-2, which predicts the next word in a sequence based on preceding words. The typical loss function for training such a model is cross-entropy loss, which measures the discrepancy between the predicted probability distribution over vocabulary and the true distribution (often represented by the actual next word). In an autoregressive setup, the model is trained to maximize the probability of each subsequent word in the sequence given the words that came before it. Rust’s performance and control over memory make it an ideal language for fine-tuning these models, enabling developers to implement memory-efficient generative models suitable for real-time or embedded applications.
One of the early challenges faced by generative models was the difficulty in generating coherent long-term sequences. RNNs and LSTMs struggled with maintaining consistency over long text due to their inherent limitations in modeling long-range dependencies. However, with the introduction of Transformer architectures and self-attention mechanisms, these challenges have been significantly mitigated. The Transformer’s ability to process the entire sequence at once, rather than sequentially, allows it to maintain coherence over much longer sequences.
Benchmarking a generative model against a simple baseline is essential for evaluating performance. In the case of text generation, one can compare the quality of the generated text using metrics such as perplexity, which measures how well the model predicts the next word in a sequence. A lower perplexity indicates better performance. Additionally, qualitative evaluations such as human judgment are often used to assess the fluency and coherence of the generated text.
Since 2018, OpenAI's GPT models have seen a rapid increase in the number of parameters, reflecting advancements in model complexity, capacity, and performance. The original GPT, introduced in 2018, had around 117 million parameters and showcased the potential of transformer architectures in language tasks. A year later, GPT-2 scaled up significantly to 1.5 billion parameters, enhancing its ability to generate coherent and contextually aware text. In 2020, OpenAI released GPT-3, which further expanded to 175 billion parameters, allowing the model to handle even more nuanced language understanding and generation tasks across a broader range of topics. This growth in parameters is driven by the need for models to capture increasingly complex language patterns and world knowledge, which requires greater capacity and depth in neural networks. By scaling up parameters, OpenAI aims to improve the model's ability to generalize across diverse tasks with minimal fine-tuning, leveraging the sheer scale to encapsulate more linguistic and factual patterns directly within the model's architecture.
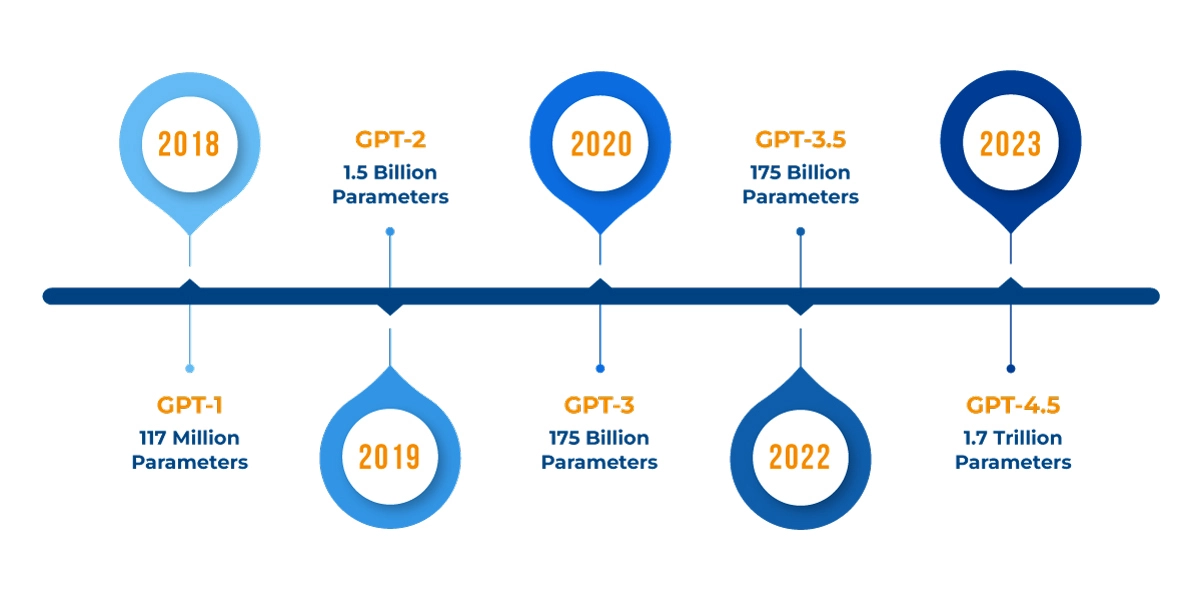
Figure 2: Numbers of parameters of GPT models.
Generative models have evolved rapidly in recent years, propelled by innovations like GPT and its successors. The latest developments focus on creating even larger models, such as GPT-4, which have billions of parameters and can generate text that often mirrors human writing. Additionally, there is growing interest in fine-tuning these models for specialized domains, such as legal or medical text generation, where domain-specific expertise is crucial. Future advancements are expected to extend beyond natural language processing (NLP) to include multimodal models capable of generating text, images, music, and video, broadening the applications and impact of these technologies.
This Rust program showcases the use of prompt engineering techniques with the langchain-rust library to optimize responses from OpenAI’s language models. Prompt engineering involves carefully designing input prompts to steer the model’s response style, tone, and structure. The program demonstrates various techniques, such as defining clear roles, controlling response length, incorporating conversation history, and applying few-shot learning examples. These methods enhance the model’s output by making it more accurate, contextually relevant, and aligned with specific user requirements, demonstrating the effectiveness of prompt engineering in fine-tuning generative model interactions.
[dependencies]
langchain-rust = "4.6.0"
serde_json = "1.0.132"
tokio = "1.41.0"
use langchain_rust::{
chain::{Chain, LLMChainBuilder},
fmt_message, fmt_placeholder, fmt_template,
language_models::llm::LLM,
llm::openai::{OpenAI, OpenAIModel},
message_formatter,
prompt::HumanMessagePromptTemplate,
prompt_args,
schemas::messages::Message,
template_fstring,
};
#[tokio::main]
async fn main() {
// Initialize the OpenAI model:
let open_ai = OpenAI::default().with_model(OpenAIModel::Gpt4oMini.to_string());
// Basic Prompt - Asking a simple question
let basic_response = open_ai.invoke("What is rust").await.unwrap();
println!("Basic Response: {}", basic_response);
// **1. Role Specification** - Specifying a Role with System Message
let role_prompt = message_formatter![
fmt_message!(Message::new_system_message(
"You are a world-class technical documentation writer with a deep knowledge of Rust programming."
)),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"{input}", "input"
)))
];
let role_chain = LLMChainBuilder::new()
.prompt(role_prompt)
.llm(open_ai.clone())
.build()
.unwrap();
match role_chain
.invoke(prompt_args! {
"input" => "Explain Rust in simple terms.",
})
.await
{
Ok(result) => {
println!("Role-Specified Response: {:?}", result);
}
Err(e) => panic!("Error invoking role_chain: {:?}", e),
}
// **2. Response Formatting and Contextual Guidance**
let format_prompt = message_formatter![
fmt_message!(Message::new_system_message(
"You are a concise, professional technical writer. Answer in three bullet points."
)),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"{input}", "input"
)))
];
let format_chain = LLMChainBuilder::new()
.prompt(format_prompt)
.llm(open_ai.clone())
.build()
.unwrap();
match format_chain
.invoke(prompt_args! {
"input" => "What are the key benefits of Rust?",
})
.await
{
Ok(result) => {
println!("Formatted Response: {:?}", result);
}
Err(e) => panic!("Error invoking format_chain: {:?}", e),
}
// **3. Few-Shot Learning Examples** - Providing Examples to Guide the Response
let few_shot_prompt = message_formatter![
fmt_message!(Message::new_system_message(
"You are an expert programmer. Answer in a friendly, concise tone."
)),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"{input}", "input"
))),
fmt_message!(Message::new_human_message("Explain the difference between Rust and C++.")),
fmt_message!(Message::new_ai_message("Rust focuses on memory safety without a garbage collector, whereas C++ provides more control but with greater risk of memory errors.")),
];
let few_shot_chain = LLMChainBuilder::new()
.prompt(few_shot_prompt)
.llm(open_ai.clone())
.build()
.unwrap();
match few_shot_chain
.invoke(prompt_args! {
"input" => "What makes Rust different from Python?",
})
.await
{
Ok(result) => {
println!("Few-Shot Response: {:?}", result);
}
Err(e) => panic!("Error invoking few_shot_chain: {:?}", e),
}
// **4. Historical Context** - Adding Conversation History
let history_prompt = message_formatter![
fmt_message!(Message::new_system_message(
"You are a helpful assistant that remembers context."
)),
fmt_placeholder!("history"),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"{input}", "input"
))),
];
let history_chain = LLMChainBuilder::new()
.prompt(history_prompt)
.llm(open_ai.clone())
.build()
.unwrap();
match history_chain
.invoke(prompt_args! {
"input" => "Who is the writer of 20,000 Leagues Under the Sea?",
"history" => vec![
Message::new_human_message("My name is Luis."),
Message::new_ai_message("Hi Luis, nice to meet you!"),
Message::new_human_message("Can you also tell me who wrote 'Around the World in 80 Days'?"),
Message::new_ai_message("That would be Jules Verne, the famous French author."),
],
})
.await
{
Ok(result) => {
println!("History-Based Response: {:?}", result);
}
Err(e) => panic!("Error invoking history_chain: {:?}", e),
}
// **5. Instructional Prompt for Output Length** - Limiting Response Length
let length_prompt = message_formatter![
fmt_message!(Message::new_system_message(
"You are a Rust expert. Provide a response that is no more than three sentences."
)),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"{input}", "input"
)))
];
let length_chain = LLMChainBuilder::new()
.prompt(length_prompt)
.llm(open_ai.clone())
.build()
.unwrap();
match length_chain
.invoke(prompt_args! {
"input" => "What is Rust and why is it popular?",
})
.await
{
Ok(result) => {
println!("Length-Limited Response: {:?}", result);
}
Err(e) => panic!("Error invoking length_chain: {:?}", e),
}
// **6. Contextual Prompts with Additional Hints** - Providing Specific Hints
let contextual_prompt = message_formatter![
fmt_message!(Message::new_system_message(
"You are a knowledgeable assistant. Answer the following question with a focus on security and performance."
)),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"{input}", "input"
)))
];
let contextual_chain = LLMChainBuilder::new()
.prompt(contextual_prompt)
.llm(open_ai)
.build()
.unwrap();
match contextual_chain
.invoke(prompt_args! {
"input" => "Why do developers choose Rust over other languages?",
})
.await
{
Ok(result) => {
println!("Contextual Response: {:?}", result);
}
Err(e) => panic!("Error invoking contextual_chain: {:?}", e),
}
}
The code begins by initializing an instance of OpenAI’s language model and then defines multiple prompt templates, each incorporating a different prompt engineering technique. Each template is structured with specific instructions for the model, such as assigning a technical writer’s role, formatting responses as concise bullet points, and using prior conversation history to provide context for more personalized interactions. These templates are then combined into LLMChains, which allow the model to be invoked with a prompt tailored to each technique. For example, the history_chain includes conversation history in the prompt to create contextually aware responses, while the few_shot_chain includes sample questions and answers to encourage consistency in style and relevance. By systematically applying these techniques, the code demonstrates how to steer the model’s behavior to produce responses that better match specific goals and communication needs.
6.2. The GPT Architecture
The GPT (Generative Pre-trained Transformer) architecture has revolutionized the landscape of natural language processing by enabling powerful generative capabilities, particularly in text generation. At its core, GPT is built upon the Transformer architecture, which was originally introduced in the seminal paper Attention is All You Need. GPT models leverage this architecture, focusing on autoregressive text generation, where each subsequent word in a sequence is predicted based on all the preceding words. This approach allows GPT models to generate coherent, contextually relevant text in a sequential manner.
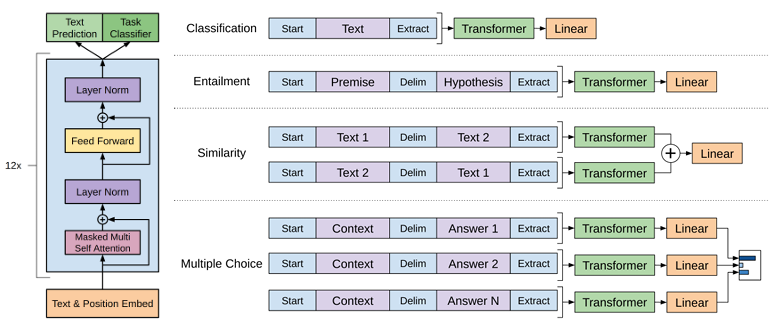
Figure 3: Illustration of GPT-2 architecture.
Autoregression is a fundamental concept in GPT. The model generates text one token at a time, using the probability distribution of the next token conditioned on the previous tokens. Mathematically, this process can be described by the following formula for generating a sequence $x_1, x_2, \dots, x_n$:
$$P(x_1, x_2, \dots, x_n) = \prod_{i=1}^{n} P(x_i | x_1, x_2, \dots, x_{i-1}),$$
where each token $x_i$ is generated based on the tokens that precede it. GPT's autoregressive mechanism ensures that the model captures the dependencies and relationships between words, enabling it to produce fluent and coherent sentences. This is achieved by encoding the entire context of the preceding tokens using a self-attention mechanism, which enables the model to learn both short-range and long-range dependencies within a text sequence.
The training process of GPT involves two primary stages: pre-training and fine-tuning. During the pre-training phase, the model is trained on a large corpus of text using unsupervised learning. The objective is to predict the next token in a sequence given the previous tokens, commonly referred to as a language modeling task. The loss function used in this stage is the negative log-likelihood of the predicted token probabilities:
$$\mathcal{L} = - \sum_{i=1}^{n} \log P(x_i | x_1, x_2, \dots, x_{i-1}),$$
where the model is optimized to minimize this loss over the training data. Tokenization, the process of converting text into smaller components (tokens), is a crucial aspect of GPT's training process. GPT typically uses subword tokenization methods like Byte Pair Encoding (BPE), which strike a balance between character-level and word-level tokenization, enabling the model to handle out-of-vocabulary words and efficiently process large vocabularies.
The Transformer architecture, which powers GPT, relies heavily on self-attention mechanisms to encode the relationships between tokens in a sequence. In the case of GPT, the architecture consists of multiple layers of self-attention blocks followed by feedforward networks. The self-attention mechanism computes a set of attention scores for each token, determining how much focus the model should place on other tokens when generating the next one. The self-attention function for a single token is computed as:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V,$$
where $Q$ (query), $K$ (key), and $V$ (value) are matrices derived from the input tokens, and $d_k$ is the dimensionality of the query and key vectors. This mechanism allows GPT to consider all tokens in the sequence when generating the next token, rather than relying solely on local context. This capacity to capture long-range dependencies is a key reason for the model's ability to generate coherent and contextually rich text.
Large-scale pre-training is a crucial factor in the success of GPT models. By training on vast amounts of diverse data, GPT develops a broad understanding of language that it can apply to a wide range of downstream tasks. After pre-training, the model can be fine-tuned on specific tasks, such as text completion, summarization, or dialogue generation, using a relatively small amount of task-specific labeled data. Fine-tuning adjusts the model weights to optimize performance for the given task while retaining the knowledge acquired during the pre-training phase. This transfer learning approach enables GPT to achieve state-of-the-art performance across many NLP benchmarks.
However, while the GPT architecture excels in generating fluent text, it has some notable limitations. One major challenge is that GPT models are prone to generating plausible but incorrect or nonsensical information, a phenomenon known as hallucination. This occurs because GPT is trained to predict the next word based on probabilities derived from the training data, rather than verifying the factual correctness of the content. Additionally, GPT models have difficulty handling tasks that require complex reasoning or deep understanding of context over extended passages, and they may struggle with tasks that involve maintaining consistency over very long sequences, such as multi-turn conversations.
This Rust program is an implementation of a GPT-like text generation model using the tch-rs crate, which provides Rust bindings to PyTorch. The model, similar to Andrej Karpathy’s minGPT, is trained on the tinyshakespeare dataset. This dataset, available as a simple text file, allows the model to learn how to predict the next character based on previous characters, ultimately enabling it to generate coherent text sequences. The code includes both training and inference (prediction) functionalities, making it a complete example of an autoregressive language model in Rust.
[dependencies]
anyhow = "1.0.90"
tch = "0.12.0"
/* This example uses the tinyshakespeare dataset which can be downloaded at:
https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt
This is mostly a rust port of https://github.com/karpathy/minGPT
*/
use anyhow::{bail, Result};
use tch::data::TextData;
use tch::nn::{ModuleT, OptimizerConfig};
use tch::{nn, Device, IndexOp, Kind, Tensor};
const LEARNING_RATE: f64 = 0.0003;
const BLOCK_SIZE: i64 = 128;
const BATCH_SIZE: i64 = 64;
const EPOCHS: i64 = 100;
const SAMPLING_LEN: i64 = 4096;
#[derive(Debug, Copy, Clone)]
struct Config {
vocab_size: i64,
n_embd: i64,
n_head: i64,
n_layer: i64,
block_size: i64,
attn_pdrop: f64,
resid_pdrop: f64,
embd_pdrop: f64,
}
// Weight decay only applies to the weight matrixes in the linear layers
const NO_WEIGHT_DECAY_GROUP: usize = 0;
const WEIGHT_DECAY_GROUP: usize = 1;
// Custom linear layer so that different groups can be used for weight
// and biases.
#[derive(Debug)]
struct Linear {
pub ws: Tensor,
pub bs: Tensor,
}
impl nn::Module for Linear {
fn forward(&self, xs: &Tensor) -> Tensor {
xs.matmul(&self.ws.tr()) + &self.bs
}
}
fn linear(vs: nn::Path, in_dim: i64, out_dim: i64) -> Linear {
let wd = vs.set_group(WEIGHT_DECAY_GROUP);
let no_wd = vs.set_group(NO_WEIGHT_DECAY_GROUP);
Linear {
ws: wd.randn("weight", &[out_dim, in_dim], 0.0, 0.02),
bs: no_wd.zeros("bias", &[out_dim]),
}
}
fn linear_no_bias(vs: nn::Path, in_dim: i64, out_dim: i64) -> Linear {
let wd = vs.set_group(WEIGHT_DECAY_GROUP);
let no_wd = vs.set_group(NO_WEIGHT_DECAY_GROUP);
Linear {
ws: wd.randn("weight", &[out_dim, in_dim], 0.0, 0.02),
bs: no_wd.zeros_no_train("bias", &[out_dim]),
}
}
fn causal_self_attention(p: &nn::Path, cfg: Config) -> impl ModuleT {
let key = linear(p / "key", cfg.n_embd, cfg.n_embd);
let query = linear(p / "query", cfg.n_embd, cfg.n_embd);
let value = linear(p / "value", cfg.n_embd, cfg.n_embd);
let proj = linear(p / "proj", cfg.n_embd, cfg.n_embd);
let mask_init =
Tensor::ones([cfg.block_size, cfg.block_size], (Kind::Float, p.device())).tril(0);
let mask_init = mask_init.view([1, 1, cfg.block_size, cfg.block_size]);
// let mask = p.var_copy("mask", &mask_init);
let mask = mask_init;
nn::func_t(move |xs, train| {
let (sz_b, sz_t, sz_c) = xs.size3().unwrap();
let sizes = [sz_b, sz_t, cfg.n_head, sz_c / cfg.n_head];
let k = xs.apply(&key).view(sizes).transpose(1, 2);
let q = xs.apply(&query).view(sizes).transpose(1, 2);
let v = xs.apply(&value).view(sizes).transpose(1, 2);
let att = q.matmul(&k.transpose(-2, -1)) * (1.0 / f64::sqrt(sizes[3] as f64));
let att = att.masked_fill(&mask.i((.., .., ..sz_t, ..sz_t)).eq(0.), f64::NEG_INFINITY);
let att = att.softmax(-1, Kind::Float).dropout(cfg.attn_pdrop, train);
let ys = att.matmul(&v).transpose(1, 2).contiguous().view([sz_b, sz_t, sz_c]);
ys.apply(&proj).dropout(cfg.resid_pdrop, train)
})
}
fn block(p: &nn::Path, cfg: Config) -> impl ModuleT {
let ln1 = nn::layer_norm(p / "ln1", vec![cfg.n_embd], Default::default());
let ln2 = nn::layer_norm(p / "ln2", vec![cfg.n_embd], Default::default());
let attn = causal_self_attention(p, cfg);
let lin1 = linear(p / "lin1", cfg.n_embd, 4 * cfg.n_embd);
let lin2 = linear(p / "lin2", 4 * cfg.n_embd, cfg.n_embd);
nn::func_t(move |xs, train| {
let xs = xs + xs.apply(&ln1).apply_t(&attn, train);
let ys =
xs.apply(&ln2).apply(&lin1).gelu("none").apply(&lin2).dropout(cfg.resid_pdrop, train);
xs + ys
})
}
fn gpt(p: nn::Path, cfg: Config) -> impl ModuleT {
let p = &p.set_group(NO_WEIGHT_DECAY_GROUP);
let tok_emb = nn::embedding(p / "tok_emb", cfg.vocab_size, cfg.n_embd, Default::default());
let pos_emb = p.zeros("pos_emb", &[1, cfg.block_size, cfg.n_embd]);
let ln_f = nn::layer_norm(p / "ln_f", vec![cfg.n_embd], Default::default());
let head = linear_no_bias(p / "head", cfg.n_embd, cfg.vocab_size);
let mut blocks = nn::seq_t();
for block_idx in 0..cfg.n_layer {
blocks = blocks.add(block(&(p / block_idx), cfg));
}
nn::func_t(move |xs, train| {
let (_sz_b, sz_t) = xs.size2().unwrap();
let tok_emb = xs.apply(&tok_emb);
let pos_emb = pos_emb.i((.., ..sz_t, ..));
(tok_emb + pos_emb)
.dropout(cfg.embd_pdrop, train)
.apply_t(&blocks, train)
.apply(&ln_f)
.apply(&head)
})
}
/// Generates some sample string using the GPT model.
fn sample(data: &TextData, gpt: &impl ModuleT, input: Tensor) -> String {
let mut input = input;
let mut result = String::new();
for _index in 0..SAMPLING_LEN {
let logits = input.apply_t(gpt, false).i((0, -1, ..));
let sampled_y = logits.softmax(-1, Kind::Float).multinomial(1, true);
let last_label = i64::try_from(&sampled_y).unwrap();
result.push(data.label_to_char(last_label));
input = Tensor::cat(&[input, sampled_y.view([1, 1])], 1).narrow(1, 1, BLOCK_SIZE);
}
result
}
pub fn main() -> Result<()> {
let device = Device::cuda_if_available();
let mut vs = nn::VarStore::new(device);
let data = TextData::new("data/input.txt")?;
let labels = data.labels();
println!("Dataset loaded, {labels} labels.");
let cfg = Config {
vocab_size: labels,
n_embd: 512,
n_head: 8,
n_layer: 8,
block_size: BLOCK_SIZE,
attn_pdrop: 0.1,
resid_pdrop: 0.1,
embd_pdrop: 0.1,
};
let gpt = gpt(vs.root() / "gpt", cfg);
let args: Vec<_> = std::env::args().collect();
if args.len() < 2 {
bail!("usage: main (train|predict weights.ot seqstart)")
}
match args[1].as_str() {
"train" => {
let mut opt = nn::AdamW::default().build(&vs, LEARNING_RATE)?;
opt.set_weight_decay_group(NO_WEIGHT_DECAY_GROUP, 0.0);
opt.set_weight_decay_group(WEIGHT_DECAY_GROUP, 0.1);
let mut idx = 0;
for epoch in 1..(1 + EPOCHS) {
let mut sum_loss = 0.;
let mut cnt_loss = 0.;
for batch in data.iter_shuffle(BLOCK_SIZE + 1, BATCH_SIZE) {
let xs = batch.narrow(1, 0, BLOCK_SIZE).to_kind(Kind::Int64).to_device(device);
let ys = batch.narrow(1, 1, BLOCK_SIZE).to_kind(Kind::Int64).to_device(device);
let logits = xs.apply_t(&gpt, true);
let loss = logits
.view([BATCH_SIZE * BLOCK_SIZE, labels])
.cross_entropy_for_logits(&ys.view([BATCH_SIZE * BLOCK_SIZE]));
opt.backward_step_clip(&loss, 0.5);
sum_loss += f64::try_from(loss)?;
cnt_loss += 1.0;
idx += 1;
if idx % 10000 == 0 {
println!("Epoch: {} loss: {:5.3}", epoch, sum_loss / cnt_loss);
let input = Tensor::zeros([1, BLOCK_SIZE], (Kind::Int64, device));
println!("Sample: {}", sample(&data, &gpt, input));
if let Err(err) = vs.save(format!("gpt{idx}.ot")) {
println!("error while saving {err}");
}
sum_loss = 0.;
cnt_loss = 0.;
}
}
}
}
"predict" => {
vs.load(args[2].as_str())?;
let seqstart = args[3].as_str();
let input = Tensor::zeros([1, BLOCK_SIZE], (Kind::Int64, device));
for (idx, c) in seqstart.chars().rev().enumerate() {
let idx = idx as i64;
if idx >= BLOCK_SIZE {
break;
}
let _filled =
input.i((0, BLOCK_SIZE - 1 - idx)).fill_(data.char_to_label(c)? as i64);
}
println!("Sample: {}", sample(&data, &gpt, input));
}
_ => bail!("usage: main (train|predict weights.ot seqstart)"),
};
Ok(())
}
The code defines a generative model architecture with configurable hyperparameters such as vocabulary size, embedding size, and number of attention heads. It builds a GPT-like model with multiple attention layers that learn to attend to specific positions in the input sequence. The main training loop updates the model using the AdamW optimizer, calculating the loss using cross-entropy based on the model's predicted next character versus the actual character in the sequence. The sample function generates text by sampling from the output probabilities, using a causal mask to ensure that each position only attends to previous positions in the sequence. This mask is crucial for generating text in an autoregressive manner. The predict functionality loads a pre-trained model and takes an input sequence to generate new text, demonstrating the model's learned ability to continue a text sequence in a coherent manner.
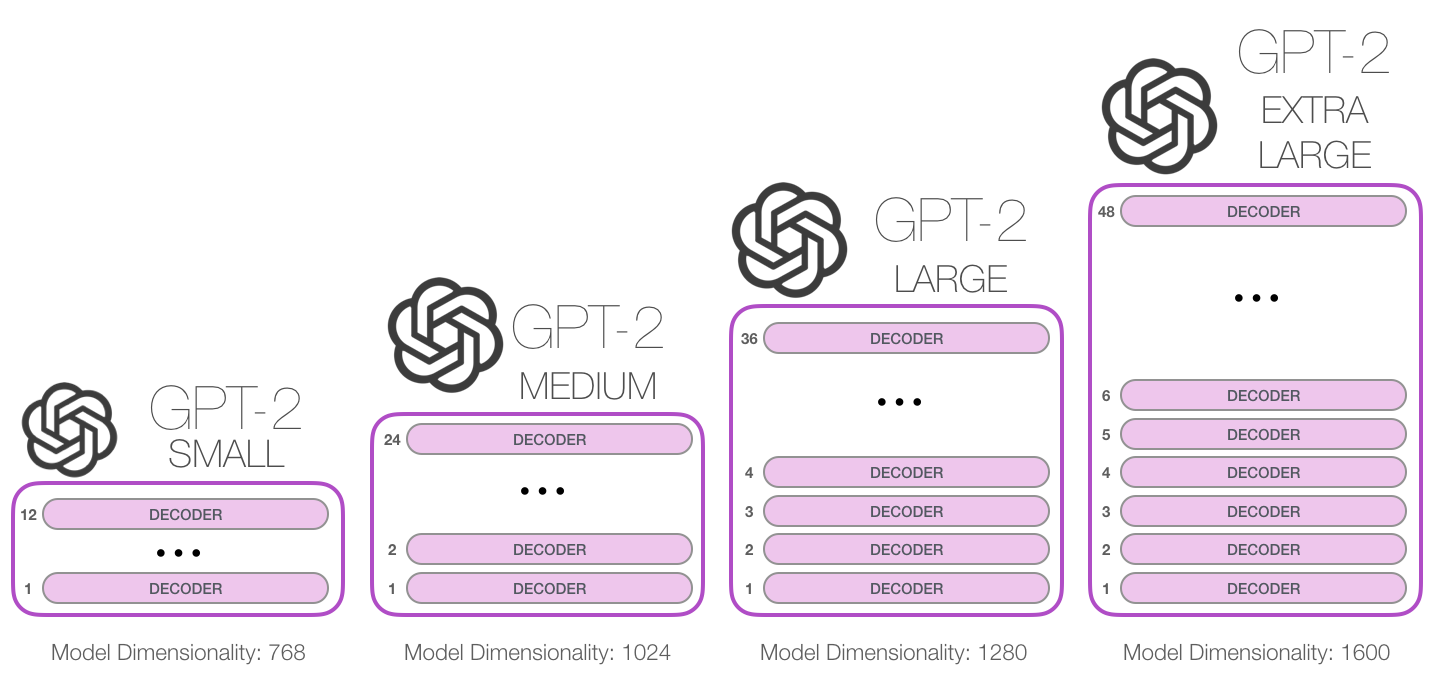
Figure 4: Growth of transformer blocks in various GPT-2 models.
In recent years, industry applications of GPT models have proliferated, especially in areas like customer service, where GPT-powered chatbots can provide automated, contextually relevant responses to user queries. Companies are also using GPT for creative applications, such as content generation and copywriting, where the model can assist in drafting articles, advertisements, or product descriptions. In research, GPT models have been employed to aid in summarizing scientific literature or generating code snippets, demonstrating their versatility across different domains.
As of the latest trends, the development of GPT-4 and similar models with even larger parameter counts has pushed the boundaries of what is possible with generative models. These models can generate highly coherent and contextually nuanced text across a wide range of domains. However, with their growing size, concerns about the computational cost, environmental impact, and ethical considerations, such as biases in generated content, have also become more pronounced. The future of generative models like GPT will likely focus on improving efficiency, interpretability, and control, while exploring new applications that push the limits of machine-generated text.
6.3. GPT Variants and Extensions
As we explore the landscape of generative models, particularly focusing on GPT variants like GPT-2, GPT-3, and their successors, it becomes evident that scaling model architecture and training data has been a central factor in their success. Each GPT variant builds on the foundational Transformer architecture but differs significantly in terms of model size, computational complexity, and the amount of training data involved. GPT-2, for instance, marked a significant jump from GPT, increasing the number of parameters to 1.5 billion from the original GPT’s 110 million. This architectural expansion allowed the model to capture more intricate patterns in the data, enabling it to generate longer and more contextually accurate text. GPT-3, with 175 billion parameters, represents another leap forward, allowing it to engage in few-shot learning and demonstrating remarkable performance across a range of tasks with minimal task-specific data.
This scaling of model parameters aligns with the exponential "More's Law" observed in natural language processing (NLP), where every major iteration in model development introduces an exponential increase in parameters and capabilities. The term, loosely inspired by Moore’s Law in computing, captures the trend in NLP where the number of parameters in generative models doubles (or more) with each generation. This exponential growth has enabled models to handle increasingly complex tasks, from nuanced text generation to advanced problem-solving across diverse domains. Larger models like GPT-4 continue this trajectory, with scaling not only expanding a model's linguistic capabilities but also enhancing its ability to generalize with fewer examples. This rapid increase in model complexity, coupled with advances in computational power and optimized training techniques, has fueled the continuous advancement of generative AI, shaping the future of human-AI interactions across industries.
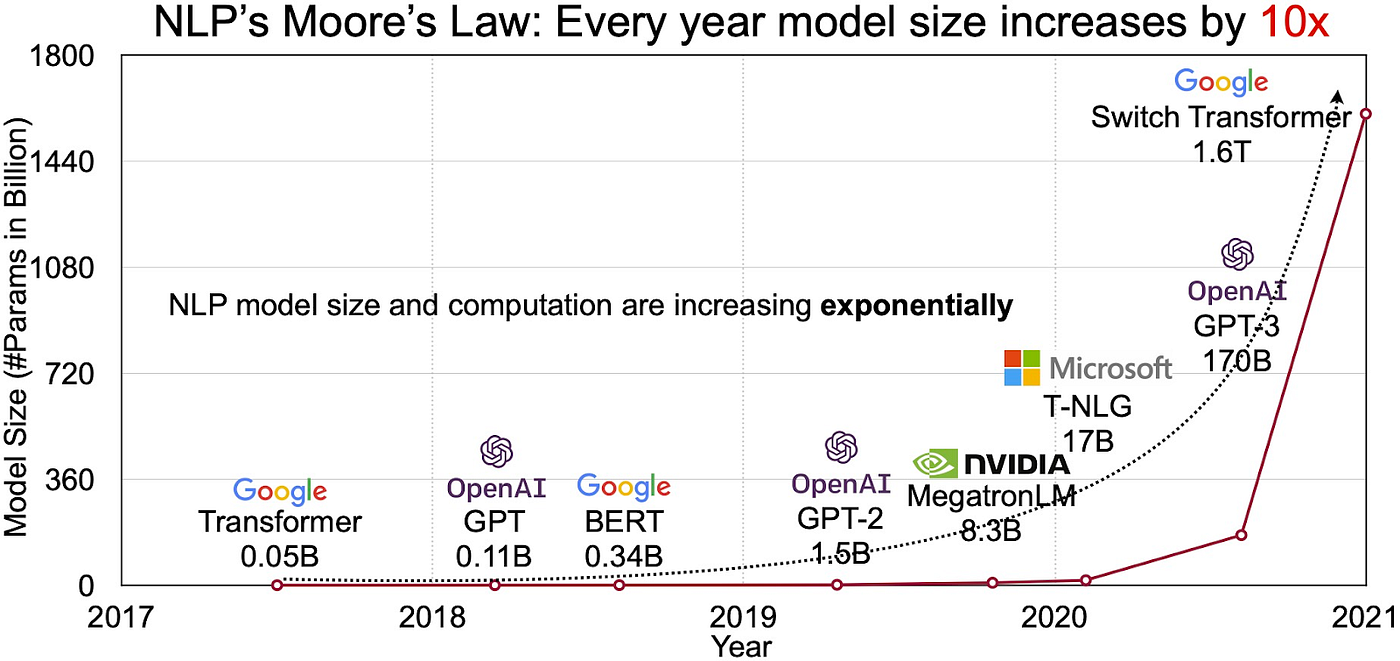
Figure 5: The NLP’s Moore’s law.
The differences in architecture across these GPT variants lie primarily in the number of layers, attention heads, and model dimensions. GPT-2 and GPT-3 both maintain the autoregressive architecture, where the model predicts the next token in a sequence based on the previously generated tokens. However, the scale of GPT-3’s architecture allows it to better capture the context and dependencies between words, leading to more coherent and diverse text generation. Additionally, the training data size for these models has grown proportionally with the architecture. GPT-2 was trained on 40 GB of text data, whereas GPT-3 was trained on 570 GB of text, further enhancing its ability to generalize across domains.
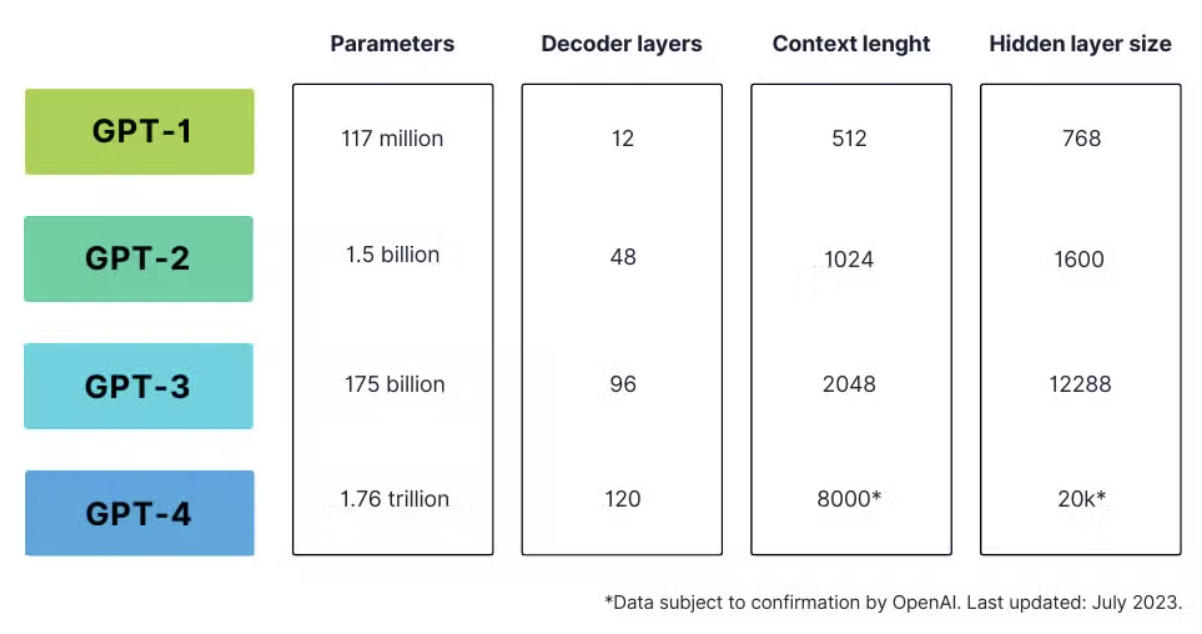
Figure 6: Model size comparison of GPT variants.
The concept of scaling laws plays a crucial role in understanding why larger models like GPT-3 perform significantly better than their smaller counterparts. Scaling laws describe how performance improves as model size, dataset size, and computational power increase. Formally, scaling laws can be expressed as:
$$L(N, D, C) = aN^{-\alpha} + bD^{-\beta} + cC^{-\gamma},$$
where $L$ is the loss function, $N$ represents the number of parameters, $D$ is the dataset size, $C$ is the computation (such as training steps), and $a, b, c$, and the exponents $\alpha, \beta, \gamma$ are empirically determined constants. These scaling laws imply that increasing the model size $N$, training data $D$, and computation $C$ leads to predictable reductions in model loss. For models like GPT-3, this means that expanding the number of parameters significantly improves performance across various tasks. However, this improvement comes at an exponentially increasing computational cost.
With this scaling comes practical trade-offs. As models grow, so do their demands on computational resources. Training a model like GPT-3 requires access to high-performance GPUs or TPUs and substantial memory bandwidth. While the larger models yield better performance, they require distributed computing environments to handle their size and complexity, leading to a significant rise in training costs and energy consumption. From an industry perspective, the deployment of such large models, even for inference tasks, can be prohibitively expensive, particularly when scaled across millions of users. Therefore, there is an active trade-off between model size, computational cost, and performance, with researchers constantly seeking ways to optimize this balance.
The ethical considerations surrounding large-scale generative models like GPT-3 also warrant serious discussion. One of the primary concerns is the propagation of biases present in the training data. Since GPT models are trained on large datasets sourced from the internet, they inevitably absorb and replicate biases found in that data. These biases can manifest in harmful ways, such as reinforcing stereotypes, generating offensive content, or perpetuating misinformation. Additionally, the ability of models like GPT-3 to generate highly plausible but factually incorrect content poses risks in terms of disinformation, particularly in areas like automated content generation, where the output may not be easily verifiable by users.
Another concern is the environmental impact of training and deploying such large models. GPT-3’s training process is estimated to have required millions of dollars' worth of computational resources, contributing significantly to energy consumption and carbon emissions. This has led to increasing interest in developing more energy-efficient architectures and training techniques that reduce the environmental footprint of large language models.
Implementing advanced GPT model features, such as those found in GPT-2 and GPT-3, in Rust is an intriguing challenge that leverages the language’s strengths in performance and memory safety. Rust, with its low-level control and concurrency model, is well-suited to handle the demands of large-scale models. Through the tch-rs crate, which interfaces with PyTorch, developers can recreate Transformer-based architectures and apply optimizations tailored for scaling up. These enhancements include expanding attention heads, increasing feed-forward layer sizes, and employing layer normalization to maintain training stability. Rust’s support for parallel processing is also essential for distributing model computations across multiple GPUs or CPUs, making it a strong candidate for deep learning applications.
This Rust code demonstrates how to set up and use OpenAI’s GPT-2 model for text generation using the rust-bert library, a versatile interface for NLP models. By accessing pretrained resources hosted on Hugging Face, the code initializes and configures the GPT-2 model, enabling users to generate coherent text based on input prompts. This example highlights Rust’s growing role in deep learning, showcasing its potential for text generation applications with advantages in speed and memory efficiency, making it a practical choice for handling complex models.
[dependencies]
anyhow = "1.0.90"
rust-bert = "0.19.0"
use rust_bert::pipelines::text_generation::{TextGenerationConfig, TextGenerationModel};
use rust_bert::resources::RemoteResource;
use std::error::Error;
fn main() -> Result<(), Box<dyn Error>> {
// Set up the model resources with correct URLs
let config_resource = RemoteResource::from_pretrained((
"config",
"https://huggingface.co/gpt2/resolve/main/config.json",
));
let vocab_resource = RemoteResource::from_pretrained((
"vocab",
"https://huggingface.co/gpt2/resolve/main/vocab.json",
));
let merges_resource = RemoteResource::from_pretrained((
"merges",
"https://huggingface.co/gpt2/resolve/main/merges.txt",
));
let model_resource = RemoteResource::from_pretrained((
"model",
"https://huggingface.co/gpt2/resolve/main/rust_model.ot",
));
// Configure the text generation model
let generate_config = TextGenerationConfig {
model_resource: Box::new(model_resource),
config_resource: Box::new(config_resource),
vocab_resource: Box::new(vocab_resource),
merges_resource: Box::new(merges_resource),
max_length: 30, // Set the maximum length of generated text
do_sample: true,
temperature: 1.1,
..Default::default()
};
// Load the GPT-2 model
let model = TextGenerationModel::new(generate_config)?;
// Input prompt
let prompt = "Once upon a time";
// Generate text
let output = model.generate(&[prompt], None);
for sentence in output {
println!("{}", sentence);
}
Ok(())
}
The code begins by specifying four resources (model configuration, vocabulary, merge rules, and model weights) for GPT-2, each loaded from a remote Hugging Face repository using RemoteResource. These resources are wrapped in Box::new to meet the type requirements of TextGenerationConfig, which is configured with specific generation parameters, including maximum output length, sampling behavior, and temperature. Once the model is initialized, a prompt is provided, and the generate method is invoked to create a continuation of the input text. The generated text is then printed, with the model outputting a response based on the input prompt. This setup allows for efficient loading and inference of the GPT-2 model within a Rust environment.
One practical approach is to compare the performance of GPT, GPT-2, and GPT-3 on the same NLP task in Rust. This can be done by implementing a simplified version of these models, training them on a common dataset, and benchmarking their performance using metrics such as perplexity, fluency, and response coherence. The differences in model size and architecture will become evident through these comparisons, as larger models like GPT-3 will likely outperform smaller ones, especially in terms of handling long-range dependencies and generating more coherent text.
This Rust code demonstrates how to load and compare the performance of two different language generation models—GPT-2 and a GPT-3-like model (GPT-Neo)—across various NLP tasks. Utilizing the rust-bert library, the code initializes pretrained language models by accessing model configurations, vocabulary, merge rules, and weight files hosted on Hugging Face. It measures and outputs the time each model takes to generate text, enabling a straightforward comparison of performance between smaller and larger language models in Rust.
[dependencies]
anyhow = "1.0.90"
rust-bert = "0.19.0"
use rust_bert::pipelines::text_generation::{TextGenerationConfig, TextGenerationModel};
use rust_bert::resources::RemoteResource;
use std::error::Error;
use std::time::Instant;
fn main() -> Result<(), Box<dyn Error>> {
// URLs for GPT-2 model resources
let gpt2_resources = (
"https://huggingface.co/gpt2/resolve/main/config.json",
"https://huggingface.co/gpt2/resolve/main/vocab.json",
"https://huggingface.co/gpt2/resolve/main/merges.txt",
"https://huggingface.co/gpt2/resolve/main/rust_model.ot",
);
// URLs for GPT-3-like model resources (e.g., GPT-neo or GPT-J)
let gpt3_resources = (
"https://huggingface.co/EleutherAI/gpt-neo-2.7B/resolve/main/config.json",
"https://huggingface.co/EleutherAI/gpt-neo-2.7B/resolve/main/vocab.json",
"https://huggingface.co/EleutherAI/gpt-neo-2.7B/resolve/main/merges.txt",
"https://huggingface.co/EleutherAI/gpt-neo-2.7B/resolve/main/rust_model.ot",
);
// Load both models
let gpt2_model = load_model(gpt2_resources, "GPT-2")?;
let gpt3_model = load_model(gpt3_resources, "GPT-3")?;
// Test prompts for each NLP task
let prompts = vec![
("text generation", "Once upon a time"),
("question answering", "What is the capital of France?"),
("summarization", "Rust is a systems programming language focused on safety, speed, and concurrency."),
];
// Run models on each task and measure performance
for (task, prompt) in prompts {
println!("\nTask: {}", task);
let gpt2_output = run_model(&gpt2_model, prompt, "GPT-2")?;
let gpt3_output = run_model(&gpt3_model, prompt, "GPT-3")?;
println!("GPT-2 output: {}", gpt2_output);
println!("GPT-3 output: {}", gpt3_output);
}
Ok(())
}
// Function to load a model based on provided URLs and model name
fn load_model(resources: (&str, &str, &str, &str), model_name: &str) -> Result<TextGenerationModel, Box<dyn Error>> {
let (config_url, vocab_url, merges_url, model_url) = resources;
let config_resource = RemoteResource::from_pretrained(("config", config_url));
let vocab_resource = RemoteResource::from_pretrained(("vocab", vocab_url));
let merges_resource = RemoteResource::from_pretrained(("merges", merges_url));
let model_resource = RemoteResource::from_pretrained(("model", model_url));
// Configure the model
let generate_config = TextGenerationConfig {
model_resource: Box::new(model_resource),
config_resource: Box::new(config_resource),
vocab_resource: Box::new(vocab_resource),
merges_resource: Box::new(merges_resource),
max_length: 50,
do_sample: true,
temperature: 1.1,
..Default::default()
};
println!("Loading {} model...", model_name);
let model = TextGenerationModel::new(generate_config)?;
Ok(model)
}
// Function to run a specific model and measure performance
fn run_model(model: &TextGenerationModel, prompt: &str, model_name: &str) -> Result<String, Box<dyn Error>> {
println!("\nRunning {} on prompt: {}", model_name, prompt);
let start_time = Instant::now();
let output = model.generate(&[prompt], None);
let duration = start_time.elapsed();
let generated_text = output.get(0).cloned().unwrap_or_default();
println!("{} took: {:?}", model_name, duration);
Ok(generated_text)
}
The code begins by specifying resource URLs for GPT-2 and GPT-Neo, which act as stand-ins for GPT-2 and GPT-3. These resources, such as configuration files and model weights, are downloaded using RemoteResource::from_pretrained. Two functions, load_model and run_model, handle the loading and execution of each model. load_model creates a TextGenerationModel instance with a specified configuration for each model, while run_model measures the time taken to generate text from each model given a prompt. Finally, for three NLP tasks (text generation, question answering, and summarization), each model generates output for the provided prompt, and the results—including generation times and outputs—are printed for comparison. This setup highlights Rust’s capability in handling deep learning tasks with efficiency.
Managing the computational demands of large GPT models is another significant consideration, especially when implementing them in Rust. Model parallelism is one technique to address this issue. In model parallelism, the parameters of a large model are split across multiple devices, allowing the model to scale beyond the memory limits of a single GPU or CPU. Rust’s memory safety guarantees ensure that these large models can be distributed across devices without risking memory leaks or unsafe memory access, a common concern when working with large-scale computations. Additionally, Rust’s efficient memory management and zero-cost abstractions enable developers to implement optimizations such as mixed precision training, where the model uses lower precision floating-point numbers to reduce memory usage and improve computational efficiency without sacrificing performance.
In industry, advanced GPT variants have been deployed in various applications, from automated customer service chatbots to content generation tools and coding assistants like GitHub Copilot. These models are also being used to automate and streamline workflows in industries such as healthcare, finance, and legal services, where the ability to generate, summarize, and process large volumes of text is highly valuable. GPT-3, in particular, has found widespread use in applications that require natural-sounding, contextually appropriate responses, enabling more sophisticated human-machine interactions.
Looking forward, the latest trends in the development of GPT variants are focused on improving efficiency, reducing the environmental impact, and enhancing the controllability of these models. Researchers are exploring techniques like model distillation, where a smaller model is trained to mimic the behavior of a larger model, effectively compressing the large model’s knowledge into a more manageable size without significant loss in performance. Additionally, hybrid models that combine GPT’s generative capabilities with reinforcement learning techniques are being developed to better align generated content with human values and reduce harmful outputs. These trends indicate a growing recognition of the need to balance the power of large language models with ethical considerations and sustainability.
6.4. Training, Fine-Tuning and Task Adaptation of GPT Model
In this section we discuss the detailed methods OpenAI employs for training, fine-tuning, and adapting their GPT models are thoroughly explored, focusing on a structured Reinforcement Learning with Human Feedback (RLHF) approach. This process involves three critical stages: Supervised Fine-Tuning (SFT) with demonstration data, Reward Model training using comparative data, and policy optimization against this reward model using Proximal Policy Optimization (PPO). These stages ensure that the GPT model can produce responses aligned with human preferences while maintaining adaptability across a range of NLP tasks.
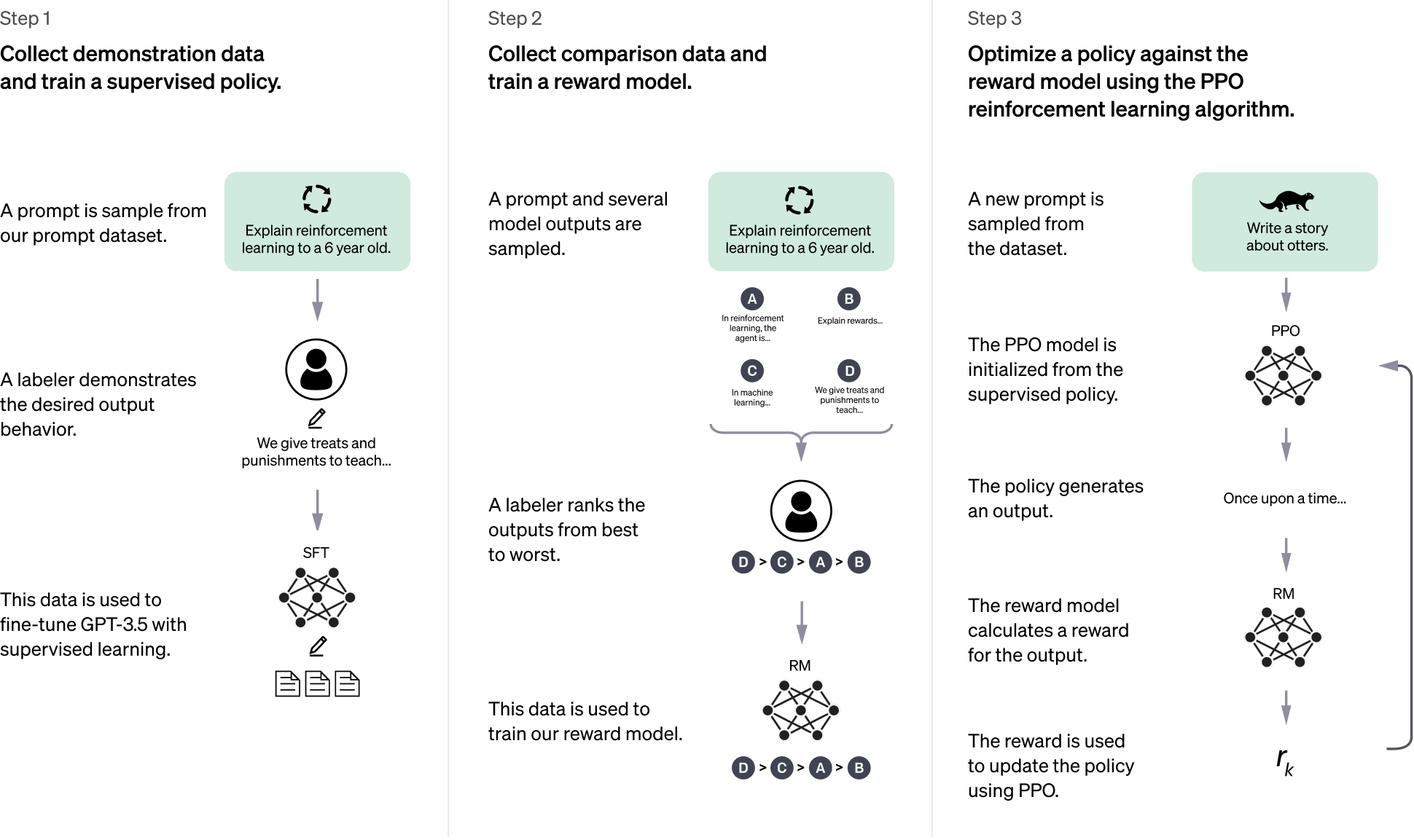
Figure 7: How OpenAI train GPT 3.5 model.
The first stage, Supervised Fine-Tuning (SFT), establishes a baseline model by training it on high-quality, human-curated data. Each sample contains an input $X$ and an expected output $Y$, allowing the model to learn through labeled examples. This stage optimizes the model's parameters $\theta$ by minimizing the negative log-likelihood loss function, as shown below:
$$ \mathcal{L}_{\text{SFT}}(\theta) = - \sum_{(X, Y) \in \text{Dataset}} \log P_\theta(Y | X) $$
This objective maximizes the likelihood of generating the correct output $Y$ given input $X$, reinforcing the foundational language patterns in the model's responses. In Rust, using the tch-rs crate, this supervised fine-tuning step implementation can be illustrated as follows:
use tch::{nn, Tensor, Device, Kind};
use tch::nn::{Module, OptimizerConfig};
fn supervised_fine_tuning(vs: &nn::Path, input_tensor: Tensor, target_tensor: Tensor) -> Tensor {
let model = nn::seq()
.add(nn::linear(vs / "layer1", 512, 1024, Default::default()))
.add(nn::relu())
.add(nn::linear(vs / "output_layer", 1024, 512, Default::default()));
let optimizer = nn::Adam::default().build(vs, 1e-4).unwrap();
let logits = model.forward(&input_tensor);
let loss = logits.cross_entropy_for_logits(&target_tensor);
optimizer.backward_step(&loss);
loss
}
The second stage, Reward Model Training, refines the model’s understanding of quality by introducing a reward model $R_\phi$, where $\phi$ are the parameters. In this stage, human annotators provide comparative feedback by ranking outputs from the model, which the reward model then uses to learn a scalar reward for each output based on its quality. The reward model's objective function is:
$$\mathcal{L}_{\text{Reward}}(\phi) = \mathbb{E}_{(Y_1, Y_2) \sim D} \left[ \log \sigma\left(R_\phi(Y_1) - R_\phi(Y_2)\right) \right]$$
where $\sigma$ is the sigmoid function, which smooths the difference between scores assigned to preferred and non-preferred outputs. This training ensures that higher rewards are associated with more desirable outputs. A simple Rust implementation of this stage could be as follows:
fn reward_model_training(vs: &nn::Path, y1: Tensor, y2: Tensor) -> Tensor {
let reward_model = nn::seq().add(nn::linear(vs / "reward_layer", 512, 1, Default::default()));
let r_y1 = reward_model.forward(&y1).mean(Kind::Float);
let r_y2 = reward_model.forward(&y2).mean(Kind::Float);
let reward_loss = -(r_y1 - r_y2).sigmoid().log();
reward_loss.backward();
reward_loss
}
The third stage, Policy Optimization using Proximal Policy Optimization (PPO), adapts the model’s policy using reinforcement learning against the reward model. PPO is particularly effective for stabilizing the learning process by clipping the probability ratios between the new and old policies, preventing abrupt changes. The PPO objective function is:
$$ \mathcal{L}_{\text{PPO}}(\theta) = \mathbb{E}_{(X, Y) \sim D} \left[ \min \left( r_t(\theta) \hat{A}, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A} \right) + \beta \, \text{Entropy}(\pi_\theta(Y | X)) \right] $$
where $r_t(\theta) = \frac{\pi_\theta(Y | X)}{\pi_{\theta_{\text{old}}}(Y | X)}$ is the probability ratio, $\epsilon$ is a clipping parameter, and $\beta$ is a coefficient that weights the entropy term to encourage exploration. The PPO algorithm maximizes the reward model's output while maintaining stable learning. An example Rust code for PPO updates can be structured as follows:
fn ppo_update(vs: &nn::Path, input_tensor: Tensor, action_tensor: Tensor, old_log_probs: Tensor, advantage: Tensor) -> Tensor {
let policy_model = nn::seq().add(nn::linear(vs / "policy_layer", 512, 1024, Default::default()));
let optimizer = nn::Adam::default().build(vs, 1e-4).unwrap();
let logits = policy_model.forward(&input_tensor);
let new_log_probs = logits.log_softmax(-1, Kind::Float).gather(1, &action_tensor, false);
let ratio = (new_log_probs - old_log_probs).exp();
let clip_range = 0.2;
let clipped_ratio = ratio.clamp(1.0 - clip_range, 1.0 + clip_range);
let ppo_loss = -Tensor::minimum(ratio * &advantage, clipped_ratio * &advantage).mean(Kind::Float);
optimizer.backward_step(&ppo_loss);
ppo_loss
}
Together, these three stages—Supervised Fine-Tuning (SFT), Reward Model training, and Proximal Policy Optimization (PPO)—form a comprehensive pipeline designed to fine-tune language models like GPT for producing contextually relevant, high-quality outputs that align with human values and expectations. This approach, known as Reinforcement Learning with Human Feedback (RLHF), is crucial for training models to generate responses that not only make logical sense but are also nuanced and user-friendly. By incorporating human feedback into the training loop, RLHF enables models like OpenAI’s GPT-3.5 to adapt dynamically across a diverse array of tasks, such as text generation, summarization, and question-answering, producing outputs that are not only accurate but also aligned with user preferences. This iterative training pipeline allows the model to improve its performance progressively, balancing consistency with flexibility, thereby making it suitable for a broad range of real-world applications.
This code illustrates a simplified training setup for neural networks using the tch crate, a Rust interface for PyTorch. The code includes the foundational stages of a training pipeline: SFT, reward model training, and PPO, each represented as a Rust function that uses basic dummy inputs and a minimal configuration. Supervised fine-tuning serves as the initial training step, where the model learns to make predictions based on labeled data. The reward model training component then teaches the model to evaluate its outputs against a reward signal, guiding it to make choices that yield higher rewards. Finally, the PPO function implements a reinforcement learning approach to optimize the model’s policy, adjusting it toward actions that maximize cumulative rewards. Together, the constants LEARNING_RATE, BLOCK_SIZE, BATCH_SIZE, and EPOCHS determine the model’s training pace and structure, defining parameters like batch size and epochs for each training loop. Although simplified, this code mirrors the architecture of larger-scale RLHF tasks, providing an experimental foundation for training models that learn to prioritize actions aligned with intended outcomes.
[dependencies]
anyhow = "1.0.90"
tch = "0.12.0"
use anyhow::Result;
use tch::data::TextData;
use tch::nn::{ModuleT, OptimizerConfig};
use tch::{nn, Device, Kind, Tensor};
use tch::nn::Optimizer;
const LEARNING_RATE: f64 = 0.0003;
const BLOCK_SIZE: i64 = 128;
const BATCH_SIZE: i64 = 64;
const EPOCHS: i64 = 3;
#[derive(Debug, Copy, Clone)]
struct Config {
vocab_size: i64,
n_embd: i64,
}
// Define gpt function (example)
fn gpt<'a>(path: nn::Path<'a>, config: Config) -> impl ModuleT + 'a {
nn::seq().add(nn::linear(&path / "layer1", config.n_embd, config.vocab_size, Default::default()))
}
// Supervised Fine-Tuning (SFT)
fn supervised_fine_tuning(_vs: &nn::Path, data: &TextData, model: &impl ModuleT, opt: &mut Optimizer) -> Result<()> {
for epoch in 1..=EPOCHS {
let mut total_loss = 0.;
for batch in data.iter_shuffle(BLOCK_SIZE + 1, BATCH_SIZE) {
let xs = batch.narrow(1, 0, BLOCK_SIZE)
.to_kind(Kind::Float) // Consistent dtype
.to_device(Device::cuda_if_available());
let ys = batch.narrow(1, 1, BLOCK_SIZE)
.to_kind(Kind::Float) // Consistent dtype
.to_device(Device::cuda_if_available());
let logits = xs.apply_t(model, true);
let loss = logits.view([BATCH_SIZE * BLOCK_SIZE, data.labels() as i64])
.cross_entropy_for_logits(&ys.view([BATCH_SIZE * BLOCK_SIZE]));
opt.backward_step(&loss);
total_loss += f64::try_from(loss)?;
}
println!("SFT Epoch {epoch} - Loss: {}", total_loss);
}
Ok(())
}
// Reward Model Training
fn train_reward_model(vs: &nn::Path, y1: Tensor, y2: Tensor) -> Tensor {
let reward_model = nn::seq().add(nn::linear(vs / "reward_layer", 512, 1, Default::default()));
let r_y1 = reward_model.forward_t(&y1, true).mean(Kind::Float);
let r_y2 = reward_model.forward_t(&y2, true).mean(Kind::Float);
let reward_loss = -(r_y1 - r_y2).sigmoid().log();
reward_loss.backward();
reward_loss
}
// PPO Policy Optimization
fn ppo_update(vs: &nn::VarStore, input: Tensor, action: Tensor, old_log_probs: Tensor, advantage: Tensor) -> Tensor {
let policy_model = nn::seq().add(nn::linear(vs.root() / "policy_layer", 512, 1024, Default::default()));
let mut opt = nn::Adam::default().build(vs, LEARNING_RATE).unwrap();
let logits = policy_model.forward_t(&input, true);
let new_log_probs = logits.log_softmax(-1, Kind::Float).gather(1, &action, false);
let ratio = (new_log_probs - old_log_probs).exp();
let clip_range = 0.2;
let clipped_ratio = ratio.clamp(1.0 - clip_range, 1.0 + clip_range);
let ppo_loss = -Tensor::minimum(&(ratio * &advantage), &(clipped_ratio * &advantage)).mean(Kind::Float);
opt.backward_step(&ppo_loss);
ppo_loss
}
fn main() -> Result<()> {
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
let data = TextData::new("data/input.txt")?;
let cfg = Config {
vocab_size: data.labels() as i64,
n_embd: 512,
};
let model = gpt(vs.root() / "gpt", cfg);
let mut opt = nn::Adam::default().build(&vs, LEARNING_RATE)?;
// Supervised Fine-Tuning
supervised_fine_tuning(&vs.root(), &data, &model, &mut opt)?;
// Dummy input for demonstration
let y1 = Tensor::randn(&[BATCH_SIZE, 512], (Kind::Float, device));
let y2 = Tensor::randn(&[BATCH_SIZE, 512], (Kind::Float, device));
// Reward Model Training
let reward_loss = train_reward_model(&vs.root(), y1, y2);
println!("Reward Model Loss: {:?}", reward_loss);
// PPO Update (dummy values)
let input = Tensor::randn(&[BATCH_SIZE, BLOCK_SIZE, 512], (Kind::Float, device));
let action = Tensor::randint(0, 512, (Kind::Int64, device)); // Adjusted dtype for actions
let old_log_probs = Tensor::randn(&[BATCH_SIZE, 1], (Kind::Float, device));
let advantage = Tensor::randn(&[BATCH_SIZE, 1], (Kind::Float, device));
let ppo_loss = ppo_update(&vs, input, action, old_log_probs, advantage);
println!("PPO Loss: {:?}", ppo_loss);
Ok(())
}
The code initializes a model (gpt) using a basic linear layer as a placeholder for an actual neural network, setting up a training pipeline that includes supervised fine-tuning, reward-based training, and Proximal Policy Optimization (PPO). In the supervised_fine_tuning function, the model undergoes supervised learning, where it is trained to predict labels based on input data. The train_reward_model function then calculates rewards by evaluating the model's predictions, guiding it to prioritize actions that yield higher rewards. Finally, ppo_update implements the PPO algorithm, adjusting model weights through a policy gradient approach that balances exploration and exploitation—key for reinforcement learning tasks. Each function is optimized using tch's GPU capabilities, highlighting Rust's ability to handle complex machine learning workflows with efficiency and safety.
In Rust, adapting and customizing large language models like GPT-3.5 does not require training from scratch. Instead, we can download or purchase pretrained models and then perform fine-tuning to suit specific needs. This process, similar to techniques used by OpenAI, follows a structured workflow: first, obtaining a pretrained model and fine-tuning it on labeled data to adapt its outputs to the target task. This initial fine-tuning can then be enhanced through reinforcement learning techniques such as Proximal Policy Optimization (PPO), which refines the model’s policy to produce high-quality, contextually relevant outputs aligned with specific goals. Libraries like rust-bert and tch-rs support this deep learning adaptation in Rust, combining high performance and memory safety to extend the capabilities of large language models across specialized tasks and domains.
The first step is downloading and loading the model into Rust. Although GPT-3.5 is not directly available through the Hugging Face API, we can work with pretrained models like GPT-2 as placeholders to set up a similar pipeline. The model’s configuration, vocabulary, merges, and weights are loaded as resources, and a configuration for generation is set. The model’s configuration object includes parameters like max_length, temperature, and do_sample, allowing the model to generate coherent and contextually relevant outputs based on input prompts.
use rust_bert::gpt2::{GPT2Generator};
use rust_bert::pipelines::generation_utils::{GenerateConfig, LanguageGenerator};
use rust_bert::resources::RemoteResource;
use std::error::Error;
fn download_gpt3_5() -> Result<GPT2Generator, Box<dyn Error>> {
let config = RemoteResource::from_pretrained((
"config",
"https://huggingface.co/gpt2/resolve/main/config.json",
));
let vocab = RemoteResource::from_pretrained((
"vocab",
"https://huggingface.co/gpt2/resolve/main/vocab.json",
));
let merges = RemoteResource::from_pretrained((
"merges",
"https://huggingface.co/gpt2/resolve/main/merges.txt",
));
let weights = RemoteResource::from_pretrained((
"weights",
"https://huggingface.co/gpt2/resolve/main/pytorch_model.bin",
));
let generate_config = GenerateConfig {
model_resource: Box::new(weights),
config_resource: Box::new(config),
vocab_resource: Box::new(vocab),
merges_resource: Box::new(merges),
max_length: 1024,
do_sample: true,
temperature: 1.0,
..Default::default()
};
let generator = GPT2Generator::new(generate_config)?;
Ok(generator)
}
fn main() -> Result<(), Box<dyn Error>> {
let generator = download_gpt3_5()?;
let prompt = "Rust is an amazing programming language because";
let output = generator.generate(Some(&[prompt]), None);
println!("{:?}", output);
Ok(())
}
The code begins by defining a function, download_gpt3_5, which sets up resources required for GPT-2, including model weights, configuration, vocabulary, and merges, all hosted on Hugging Face's model repository. Using RemoteResource, the code downloads these assets and then applies them in GenerateConfig, a structure that defines how the model will generate outputs (e.g., maximum token length, sampling behavior). The model is initialized as a GPT2Generator with this configuration. In main, a sample prompt is passed to the generator, which outputs a continuation based on the prompt by using the generate function. This setup highlights the utility of pretrained models in Rust, allowing developers to generate contextually appropriate language outputs by combining pretrained weights with fine-tuning configurations.
After successfully downloading the model, the next step involves fine-tuning. Fine-tuning adjusts the model’s parameters to adapt it to a specific task, where we minimize the supervised loss $L(\theta) = -\sum_{(X, Y) \in D} \log P_\theta(Y \mid X)$, with $\theta$ representing model parameters, $X$ as the input text, and $Y$ as the desired output. This adjustment process requires high-quality labeled data pairs and a structured objective function that aligns the model’s outputs with desired responses, setting the stage for further optimization.
use tch::{nn, Device, Kind, Tensor};
use tch::nn::{Module, OptimizerConfig};
use rust_bert::pipelines::generation::{GPT2Generator};
fn fine_tune_gpt3_5(generator: &GPT2Generator, data: &[(String, String)]) -> Result<(), Box<dyn Error>> {
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
let config = generator.get_config();
let linear_layer = nn::linear(vs.root(), config.n_embd, config.vocab_size, Default::default());
let optimizer = nn::Adam::default().build(&vs, 1e-4)?;
for (input_text, target_text) in data.iter() {
let input_tensor = generator.encode(input_text.clone())?;
let target_tensor = generator.encode(target_text.clone())?;
let logits = linear_layer.forward(&input_tensor);
let loss = logits.cross_entropy_for_logits(&target_tensor);
optimizer.backward_step(&loss);
println!("Fine-tuning loss: {}", f64::try_from(loss)?);
}
Ok(())
}
Finally, we perform task adaptation through reinforcement learning by using Proximal Policy Optimization (PPO). PPO is designed to stabilize the fine-tuned model by adjusting its policy with respect to a reward model, which evaluates how closely the model aligns with human-preferred outputs. The objective function for PPO can be represented as $L_{PPO}(\theta)$, that optimizes the model’s responses while ensuring stability by constraining updates to a safe range.
fn ppo_update(
policy_model: &impl Module,
input_tensor: Tensor,
action_tensor: Tensor,
old_log_probs: Tensor,
advantage: Tensor,
epsilon: f64,
vs: &nn::Path,
) -> Tensor {
let optimizer = nn::Adam::default().build(vs, 1e-4).unwrap();
let logits = policy_model.forward(&input_tensor);
let new_log_probs = logits.log_softmax(-1, Kind::Float).gather(1, &action_tensor, false);
let ratio = (new_log_probs - old_log_probs).exp();
let clipped_ratio = ratio.clamp(1.0 - epsilon, 1.0 + epsilon);
let ppo_loss = -Tensor::minimum(ratio * &advantage, clipped_ratio * &advantage).mean(Kind::Float);
let entropy_bonus = logits.log_softmax(-1, Kind::Float).exp().entropy();
let total_loss = ppo_loss + 0.01 * entropy_bonus;
optimizer.backward_step(&total_loss);
total_loss
}
By combining these techniques—downloading and loading a pretrained model, fine-tuning with labeled data, and refining with PPO—this pipeline adapts GPT-3.5 for specific tasks, improving the model's relevance and quality. The final outcome is a large language model customized to produce high-quality, contextually appropriate responses aligned with user preferences, all while leveraging Rust's powerful performance and safety features.
6.5. Advanced Generative Techniques Beyond GPT
In recent years, the field of generative modeling has expanded beyond autoregressive models like GPT, introducing a range of advanced techniques such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Diffusion Models. These models represent different approaches to generative tasks, and each brings its unique strengths and limitations, especially when applied to domains like image generation, style transfer, and anomaly detection. While GPT models excel in natural language processing through their autoregressive mechanisms, models like VAEs, GANs, and Diffusion Models have proven to be highly effective in other domains, particularly where generating high-resolution and complex data is essential.
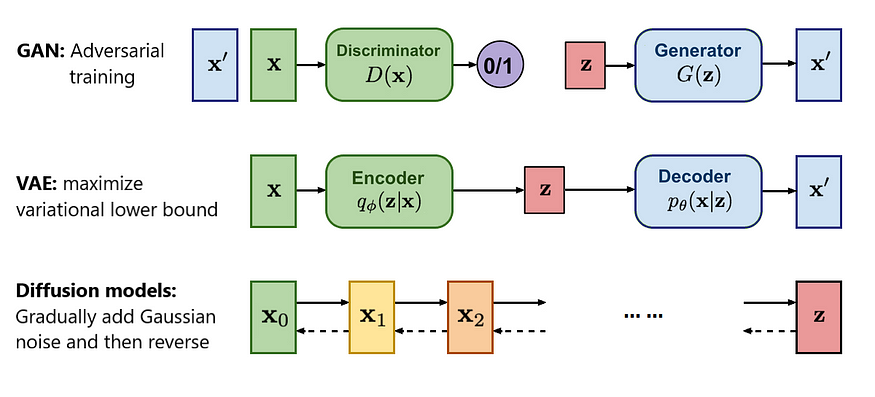
Figure 8: Comparison between GAN, VAE and Diffusion models.
Variational Autoencoders (VAEs) are a class of generative models that aim to learn the underlying distribution of data by encoding it into a latent space and then decoding it back into the original form. VAEs introduce a probabilistic framework where the encoder maps the input data into a distribution over latent variables, typically modeled as a Gaussian distribution. The decoder then reconstructs the data from samples drawn from this latent distribution. Mathematically, the VAE optimizes the evidence lower bound (ELBO) as its loss function:
$$\mathcal{L}_{\text{VAE}} = \mathbb{E}_{q(z|x)} \left[ \log p(x|z) \right] - \text{KL}(q(z|x) || p(z)),$$
where $x$ is the input data, $z$ is the latent variable, $p(x|z)$ is the likelihood of reconstructing $x$ given $z$, and the second term is the Kullback-Leibler (KL) divergence between the approximate posterior $q(z|x)$ and the prior $p(z)$, which ensures that the learned latent space adheres to a Gaussian distribution. VAEs enable smooth interpolation between data points, which makes them useful for tasks like data compression, anomaly detection, and generating variations of input data. The key advantage of VAEs is their ability to model complex latent spaces, allowing for the generation of new, plausible samples even if the model is trained on relatively small datasets.
Generative Adversarial Networks (GANs) are another powerful class of generative models that employ adversarial training between two neural networks: the generator and the discriminator. The generator's task is to produce synthetic data that resembles the training data, while the discriminator's role is to distinguish between real data and generated (fake) data. The two networks are trained simultaneously, with the generator trying to fool the discriminator and the discriminator attempting to become better at detecting fake data. The objective function of a GAN can be formulated as a minimax game:
$$\min_G \max_D \mathbb{E}_{x \sim p_{\text{data}}(x)} \left[ \log D(x) \right] + \mathbb{E}_{z \sim p_z(z)} \left[ \log (1 - D(G(z))) \right],$$
where $G(z)$ represents the generator's output, which is derived from random noise $z$, and $D(x)$ is the discriminator's probability estimate that input $x$ is real. The adversarial nature of GANs often leads to highly realistic outputs, especially in image generation tasks. GANs are widely used for tasks like high-resolution image synthesis, style transfer, and even generating synthetic medical data for research. However, training GANs can be notoriously difficult due to issues like mode collapse, where the generator learns to produce a limited variety of outputs, and instability in the adversarial training process.
Diffusion Models are a more recent development in generative modeling and have gained attention for their ability to generate high-quality, high-resolution data across various modalities, including images, audio, and even 3D shapes. Diffusion models work by iteratively corrupting the data (such as adding noise) and then learning a reverse process that can recover the original data. Mathematically, diffusion models are trained to minimize the difference between the data distribution and the distribution obtained by gradually adding Gaussian noise. The reverse process, modeled as a Markov chain, is used to sample from the noisy distribution back to the original data distribution. The loss function typically involves the reconstruction of data from noisy samples at various levels of degradation:
$$\mathcal{L}_{\text{diffusion}} = \mathbb{E}_{q} \left[ \| x_t - x \|^2 \right],$$
where $x_t$ is the noisy sample at time step $t$, and the model learns to reconstruct the original data $x$ from these noisy versions. Diffusion models have shown impressive results in generating highly detailed images and other forms of data, often outperforming GANs in terms of diversity and fidelity. This is largely due to their more stable training process, which avoids some of the issues found in GANs, such as mode collapse and convergence difficulties.
In practice, implementing a VAE or GAN in Rust involves building the encoder-decoder architecture for VAEs or the generator-discriminator pair for GANs. Using the tch-rs crate, developers can easily implement these models in Rust, leveraging the performance advantages of the language while maintaining compatibility with PyTorch. For a VAE, the encoder network maps the input data to a mean and variance vector, from which latent variables are sampled, while the decoder reconstructs the data from these latent variables. For a GAN, the generator network takes random noise as input and attempts to produce data samples indistinguishable from the real data, while the discriminator tries to classify samples as real or fake.
The Relativistic GAN (RGAN) model extends traditional Generative Adversarial Networks (GANs) by adjusting the discriminator to predict not just whether an image is real or fake but also its realism relative to other generated images. This approach allows the model to capture more nuanced characteristics of real images, improving the quality of generated images. The code here implements a Relativistic Deep Convolutional GAN (DCGAN) using the tch library in Rust, aiming to generate realistic images from latent noise input. This implementation sets up a training loop where a generator learns to create increasingly realistic images, while a discriminator learns to differentiate these from real images. Together, these components create a feedback loop where each model improves based on the other’s outputs.
[dependencies]
anyhow = "1.0.90"
tch = "0.12.0"
// Realtivistic DCGAN.
// https://github.com/AlexiaJM/RelativisticGAN
//
// TODO: override the initializations if this does not converge well.
use anyhow::{bail, Result};
use tch::{kind, nn, nn::OptimizerConfig, Device, Kind, Tensor};
const IMG_SIZE: i64 = 64;
const LATENT_DIM: i64 = 128;
const BATCH_SIZE: i64 = 32;
const LEARNING_RATE: f64 = 1e-4;
const BATCHES: i64 = 100000000;
fn tr2d(p: nn::Path, c_in: i64, c_out: i64, padding: i64, stride: i64) -> nn::ConvTranspose2D {
let cfg = nn::ConvTransposeConfig { stride, padding, bias: false, ..Default::default() };
nn::conv_transpose2d(p, c_in, c_out, 4, cfg)
}
fn conv2d(p: nn::Path, c_in: i64, c_out: i64, padding: i64, stride: i64) -> nn::Conv2D {
let cfg = nn::ConvConfig { stride, padding, bias: false, ..Default::default() };
nn::conv2d(p, c_in, c_out, 4, cfg)
}
fn generator(p: nn::Path) -> impl nn::ModuleT {
nn::seq_t()
.add(tr2d(&p / "tr1", LATENT_DIM, 1024, 0, 1))
.add(nn::batch_norm2d(&p / "bn1", 1024, Default::default()))
.add_fn(|xs| xs.relu())
.add(tr2d(&p / "tr2", 1024, 512, 1, 2))
.add(nn::batch_norm2d(&p / "bn2", 512, Default::default()))
.add_fn(|xs| xs.relu())
.add(tr2d(&p / "tr3", 512, 256, 1, 2))
.add(nn::batch_norm2d(&p / "bn3", 256, Default::default()))
.add_fn(|xs| xs.relu())
.add(tr2d(&p / "tr4", 256, 128, 1, 2))
.add(nn::batch_norm2d(&p / "bn4", 128, Default::default()))
.add_fn(|xs| xs.relu())
.add(tr2d(&p / "tr5", 128, 3, 1, 2))
.add_fn(|xs| xs.tanh())
}
fn leaky_relu(xs: &Tensor) -> Tensor {
xs.maximum(&(xs * 0.2))
}
fn discriminator(p: nn::Path) -> impl nn::ModuleT {
nn::seq_t()
.add(conv2d(&p / "conv1", 3, 128, 1, 2))
.add_fn(leaky_relu)
.add(conv2d(&p / "conv2", 128, 256, 1, 2))
.add(nn::batch_norm2d(&p / "bn2", 256, Default::default()))
.add_fn(leaky_relu)
.add(conv2d(&p / "conv3", 256, 512, 1, 2))
.add(nn::batch_norm2d(&p / "bn3", 512, Default::default()))
.add_fn(leaky_relu)
.add(conv2d(&p / "conv4", 512, 1024, 1, 2))
.add(nn::batch_norm2d(&p / "bn4", 1024, Default::default()))
.add_fn(leaky_relu)
.add(conv2d(&p / "conv5", 1024, 1, 0, 1))
}
fn mse_loss(x: &Tensor, y: &Tensor) -> Tensor {
let diff = x - y;
(&diff * &diff).mean(Kind::Float)
}
// Generate a 2D matrix of images from a tensor with multiple images.
fn image_matrix(imgs: &Tensor, sz: i64) -> Result<Tensor> {
let imgs = ((imgs + 1.) * 127.5).clamp(0., 255.).to_kind(Kind::Uint8);
let mut ys: Vec<Tensor> = vec![];
for i in 0..sz {
ys.push(Tensor::cat(&(0..sz).map(|j| imgs.narrow(0, 4 * i + j, 1)).collect::<Vec<_>>(), 2))
}
Ok(Tensor::cat(&ys, 3).squeeze_dim(0))
}
pub fn main() -> Result<()> {
let device = Device::cuda_if_available();
let args: Vec<_> = std::env::args().collect();
let image_dir = match args.as_slice() {
[_, d] => d.to_owned(),
_ => bail!("usage: main image-dataset-dir"),
};
let images = tch::vision::image::load_dir(image_dir, IMG_SIZE, IMG_SIZE)?;
println!("loaded dataset: {images:?}");
let train_size = images.size()[0];
let random_batch_images = || {
let index = Tensor::randint(train_size, [BATCH_SIZE], kind::INT64_CPU);
images.index_select(0, &index).to_device(device).to_kind(Kind::Float) / 127.5 - 1.
};
let rand_latent = || {
(Tensor::rand([BATCH_SIZE, LATENT_DIM, 1, 1], kind::FLOAT_CPU) * 2.0 - 1.0)
.to_device(device)
};
let mut generator_vs = nn::VarStore::new(device);
let generator = generator(generator_vs.root());
let mut opt_g = nn::adam(0.5, 0.999, 0.).build(&generator_vs, LEARNING_RATE)?;
let mut discriminator_vs = nn::VarStore::new(device);
let discriminator = discriminator(discriminator_vs.root());
let mut opt_d = nn::adam(0.5, 0.999, 0.).build(&discriminator_vs, LEARNING_RATE)?;
let fixed_noise = rand_latent();
for index in 0..BATCHES {
discriminator_vs.unfreeze();
generator_vs.freeze();
let discriminator_loss = {
let batch_images = random_batch_images();
let y_pred = batch_images.apply_t(&discriminator, true);
let y_pred_fake = rand_latent()
.apply_t(&generator, true)
.copy()
.detach()
.apply_t(&discriminator, true);
mse_loss(&y_pred, &(y_pred_fake.mean(Kind::Float) + 1))
+ mse_loss(&y_pred_fake, &(y_pred.mean(Kind::Float) - 1))
};
opt_d.backward_step(&discriminator_loss);
discriminator_vs.freeze();
generator_vs.unfreeze();
let generator_loss = {
let batch_images = random_batch_images();
let y_pred = batch_images.apply_t(&discriminator, true);
let y_pred_fake = rand_latent().apply_t(&generator, true).apply_t(&discriminator, true);
mse_loss(&y_pred, &(y_pred_fake.mean(Kind::Float) - 1))
+ mse_loss(&y_pred_fake, &(y_pred.mean(Kind::Float) + 1))
};
opt_g.backward_step(&generator_loss);
if index % 1000 == 0 {
let imgs = fixed_noise
.apply_t(&generator, true)
.view([-1, 3, IMG_SIZE, IMG_SIZE])
.to_device(Device::Cpu);
tch::vision::image::save(&image_matrix(&imgs, 4)?, format!("relout{index}.png"))?
}
if index % 100 == 0 {
println!("{index}")
};
}
Ok(())
}
The code defines a DCGAN model where generator builds an image generator from a latent vector, and discriminator classifies images as real or relatively realistic. The training process alternates between updating the discriminator and generator. During each batch, real images are selected from a dataset, and fake images are generated by feeding random noise into the generator. The discriminator loss is calculated by comparing real and fake images with Mean Squared Error (MSE) loss. The generator loss similarly tries to fool the discriminator by making fake images appear more realistic. Optimizers opt_d and opt_g update model weights to minimize these losses. Periodically, sample generated images are saved, allowing us to visually assess training progress. The image_matrix function arranges generated samples into a grid for easier viewing. The model can be trained on either CPU or GPU, and the whole process is repeated for a large number of batches to ensure convergence.
Now lets review sample implementation of VAE that consists of two main parts: an encoder that compresses data into a latent space representation, and a decoder that reconstructs the data from this representation. This code implements a VAE on the MNIST dataset of handwritten digits, with the objective of generating new digit images by learning and sampling from the latent space. Using tch, this implementation leverages efficient GPU-accelerated training to create a generative model that can produce images similar to the training set.
/* Variational Auto-Encoder on MNIST.
The implementation is based on:
https://github.com/pytorch/examples/blob/master/vae/main.py
The 4 following dataset files can be downloaded from http://yann.lecun.com/exdb/mnist/
These files should be extracted in the 'data' directory.
train-images-idx3-ubyte.gz
train-labels-idx1-ubyte.gz
t10k-images-idx3-ubyte.gz
t10k-labels-idx1-ubyte.gz
*/
use anyhow::Result;
use tch::{nn, nn::Module, nn::OptimizerConfig, Kind, Reduction, Tensor};
struct Vae {
fc1: nn::Linear,
fc21: nn::Linear,
fc22: nn::Linear,
fc3: nn::Linear,
fc4: nn::Linear,
}
impl Vae {
fn new(vs: &nn::Path) -> Self {
Vae {
fc1: nn::linear(vs / "fc1", 784, 400, Default::default()),
fc21: nn::linear(vs / "fc21", 400, 20, Default::default()),
fc22: nn::linear(vs / "fc22", 400, 20, Default::default()),
fc3: nn::linear(vs / "fc3", 20, 400, Default::default()),
fc4: nn::linear(vs / "fc4", 400, 784, Default::default()),
}
}
fn encode(&self, xs: &Tensor) -> (Tensor, Tensor) {
let h1 = xs.apply(&self.fc1).relu();
(self.fc21.forward(&h1), self.fc22.forward(&h1))
}
fn decode(&self, zs: &Tensor) -> Tensor {
zs.apply(&self.fc3).relu().apply(&self.fc4).sigmoid()
}
fn forward(&self, xs: &Tensor) -> (Tensor, Tensor, Tensor) {
let (mu, logvar) = self.encode(&xs.view([-1, 784]));
let std = (&logvar * 0.5).exp();
let eps = std.randn_like();
(self.decode(&(&mu + eps * std)), mu, logvar)
}
}
// Reconstruction + KL divergence losses summed over all elements and batch dimension.
fn loss(recon_x: &Tensor, x: &Tensor, mu: &Tensor, logvar: &Tensor) -> Tensor {
let bce = recon_x.binary_cross_entropy::<Tensor>(&x.view([-1, 784]), None, Reduction::Sum);
// See Appendix B from VAE paper:
// Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014
// https://arxiv.org/abs/1312.6114
// 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
let kld = -0.5 * (1i64 + logvar - mu.pow_tensor_scalar(2) - logvar.exp()).sum(Kind::Float);
bce + kld
}
// Generate a 2D matrix of images from a tensor with multiple images.
fn image_matrix(imgs: &Tensor, sz: i64) -> Result<Tensor> {
let imgs = (imgs * 256.).clamp(0., 255.).to_kind(Kind::Uint8);
let mut ys: Vec<Tensor> = vec![];
for i in 0..sz {
ys.push(Tensor::cat(&(0..sz).map(|j| imgs.narrow(0, 4 * i + j, 1)).collect::<Vec<_>>(), 2))
}
Ok(Tensor::cat(&ys, 3).squeeze_dim(0))
}
pub fn main() -> Result<()> {
let device = tch::Device::cuda_if_available();
let m = tch::vision::mnist::load_dir("data")?;
let vs = nn::VarStore::new(device);
let vae = Vae::new(&vs.root());
let mut opt = nn::Adam::default().build(&vs, 1e-3)?;
for epoch in 1..21 {
let mut train_loss = 0f64;
let mut samples = 0f64;
for (bimages, _) in m.train_iter(128).shuffle().to_device(vs.device()) {
let (recon_batch, mu, logvar) = vae.forward(&bimages);
let loss = loss(&recon_batch, &bimages, &mu, &logvar);
opt.backward_step(&loss);
train_loss += f64::try_from(&loss)?;
samples += bimages.size()[0] as f64;
}
println!("Epoch: {}, loss: {}", epoch, train_loss / samples);
let s = Tensor::randn([64, 20], tch::kind::FLOAT_CPU).to(device);
let s = vae.decode(&s).to(tch::Device::Cpu).view([64, 1, 28, 28]);
tch::vision::image::save(&image_matrix(&s, 8)?, format!("s_{epoch}.png"))?
}
Ok(())
}
The Vae struct in this code represents the VAE model, containing fully connected layers for the encoder (fc1, fc21, and fc22) and decoder (fc3 and fc4). The encoder compresses input images to a latent representation, producing two outputs: the mean (mu) and log-variance (logvar) for each input, which parameterize a normal distribution. In the forward method, a random sample (eps) is drawn and scaled by the standard deviation (std), which is derived from logvar, to introduce randomness to the latent encoding. The decoder then reconstructs the image from this sampled latent representation. The loss function combines binary cross-entropy, measuring reconstruction accuracy, with a KL divergence term that regularizes the latent space by penalizing deviation from a normal distribution. In main, the model is trained over 20 epochs, with sample images generated and saved after each epoch, demonstrating the model’s ability to learn and generate new handwritten digits.
Diffusion models, although relatively newer, can also be implemented in Rust using libraries that support advanced machine learning techniques. The iterative nature of diffusion processes makes them computationally intensive, but Rust's concurrency features and memory management can help optimize their performance. Implementing a diffusion model in Rust would involve defining the forward (noise-adding) process and training the reverse (denoising) process, which reconstructs the original data from noisy samples.
The following code represents an implementation of Stable Diffusion, a model for generating images from text prompts. It integrates key components from Huggingface's Diffusers library and the CLIP model for encoding text prompts. The code follows the process of setting up essential model components, including a tokenizer to handle text input, a VAE for latent encoding and decoding, and a UNet for denoising. A scheduler is also included to handle the iterative denoising process used in generating images. Additionally, pre-trained weights for the CLIP, VAE, and UNet models are converted and loaded, readying the models for inference on GPU if available.
[dependencies]
anyhow = "1.0.90"
regex = "1.11.1"
tch = "0.12.0"
// Stable Diffusion implementation inspired:
// - Huggingface's amazing diffuser Python api: https://huggingface.co/blog/annotated-diffusion
// - Huggingface's (also amazing) blog post: https://huggingface.co/blog/annotated-diffusion
// - The "Grokking Stable Diffusion" notebook by Jonathan Whitaker.
// https://colab.research.google.com/drive/1dlgggNa5Mz8sEAGU0wFCHhGLFooW_pf1?usp=sharing
//
// In order to run this, first download the following and extract the file in data/
//
// mkdir -p data && cd data
// wget https://github.com/openai/CLIP/raw/main/clip/bpe_simple_vocab_16e6.txt.gz
// gunzip bpe_simple_vocab_16e6.txt.gz
//
// Download and convert the weights:
//
// 1. Clip Encoding Weights
// wget https://huggingface.co/openai/clip-vit-large-patch14/resolve/main/pytorch_model.bin
// From python, extract the weights and save them as a .npz file.
// import numpy as np
// import torch
// model = torch.load("./pytorch_model.bin")
// np.savez("./pytorch_model.npz", **{k: v.numpy() for k, v in model.items() if "text_model" in k})
//
// Then use tensor_tools to convert this to a .ot file that tch can use.
// cargo run --release --example tensor-tools cp ./data/pytorch_model.npz ./data/pytorch_model.ot
//
// 2. VAE and Unet Weights
// https://huggingface.co/CompVis/stable-diffusion-v1-4/blob/main/vae/diffusion_pytorch_model.bin
// https://huggingface.co/CompVis/stable-diffusion-v1-4/blob/main/unet/diffusion_pytorch_model.bin
//
// import numpy as np
// import torch
// model = torch.load("./vae.bin")
// np.savez("./vae.npz", **{k: v.numpy() for k, v in model.items()})
// model = torch.load("./unet.bin")
// np.savez("./unet.npz", **{k: v.numpy() for k, v in model.items()})
//
// cargo run --release --example tensor-tools cp ./data/vae.npz ./data/vae.ot
// cargo run --release --example tensor-tools cp ./data/unet.npz ./data/unet.ot
// TODO: fix tensor_tools so that it works properly there.
// TODO: Split this file, probably in a way similar to huggingface/diffusers.
use std::collections::{HashMap, HashSet};
use std::io::BufRead;
use tch::{kind, nn, nn::Module, Device, Kind, Tensor};
// The config details can be found in the "text_config" section of this json file:
// https://huggingface.co/openai/clip-vit-large-patch14/blob/main/config.json
// "hidden_act": "quick_gelu"
const VOCAB_SIZE: i64 = 49408;
const EMBED_DIM: i64 = 768; // a.k.a. config.hidden_size
const INTERMEDIATE_SIZE: i64 = 3072;
const MAX_POSITION_EMBEDDINGS: usize = 77;
const NUM_HIDDEN_LAYERS: i64 = 12;
const NUM_ATTENTION_HEADS: i64 = 12;
const HEIGHT: i64 = 512;
const WIDTH: i64 = 512;
const GUIDANCE_SCALE: f64 = 7.5;
const BYTES_TO_UNICODE: [(u8, char); 256] = [
(33, '!'),
(34, '"'),
(35, '#'),
(36, '$'),
(37, '%'),
(38, '&'),
(39, '\''),
(40, '('),
(41, ')'),
(42, '*'),
(43, '+'),
(44, ','),
(45, '-'),
(46, '.'),
(47, '/'),
(48, '0'),
(49, '1'),
(50, '2'),
(51, '3'),
(52, '4'),
(53, '5'),
(54, '6'),
(55, '7'),
(56, '8'),
(57, '9'),
(58, ':'),
(59, ';'),
(60, '<'),
(61, '='),
(62, '>'),
(63, '?'),
(64, '@'),
(65, 'A'),
(66, 'B'),
(67, 'C'),
(68, 'D'),
(69, 'E'),
(70, 'F'),
(71, 'G'),
(72, 'H'),
(73, 'I'),
(74, 'J'),
(75, 'K'),
(76, 'L'),
(77, 'M'),
(78, 'N'),
(79, 'O'),
(80, 'P'),
(81, 'Q'),
(82, 'R'),
(83, 'S'),
(84, 'T'),
(85, 'U'),
(86, 'V'),
(87, 'W'),
(88, 'X'),
(89, 'Y'),
(90, 'Z'),
(91, '['),
(92, '\\'),
(93, ']'),
(94, '^'),
(95, '_'),
(96, '`'),
(97, 'a'),
(98, 'b'),
(99, 'c'),
(100, 'd'),
(101, 'e'),
(102, 'f'),
(103, 'g'),
(104, 'h'),
(105, 'i'),
(106, 'j'),
(107, 'k'),
(108, 'l'),
(109, 'm'),
(110, 'n'),
(111, 'o'),
(112, 'p'),
(113, 'q'),
(114, 'r'),
(115, 's'),
(116, 't'),
(117, 'u'),
(118, 'v'),
(119, 'w'),
(120, 'x'),
(121, 'y'),
(122, 'z'),
(123, '{'),
(124, '|'),
(125, '}'),
(126, '~'),
(161, '¡'),
(162, '¢'),
(163, '£'),
(164, '¤'),
(165, '¥'),
(166, '¦'),
(167, '§'),
(168, '¨'),
(169, '©'),
(170, 'ª'),
(171, '«'),
(172, '¬'),
(174, '®'),
(175, '¯'),
(176, '°'),
(177, '±'),
(178, '²'),
(179, '³'),
(180, '´'),
(181, 'µ'),
(182, '¶'),
(183, '·'),
(184, '¸'),
(185, '¹'),
(186, 'º'),
(187, '»'),
(188, '¼'),
(189, '½'),
(190, '¾'),
(191, '¿'),
(192, 'À'),
(193, 'Á'),
(194, 'Â'),
(195, 'Ã'),
(196, 'Ä'),
(197, 'Å'),
(198, 'Æ'),
(199, 'Ç'),
(200, 'È'),
(201, 'É'),
(202, 'Ê'),
(203, 'Ë'),
(204, 'Ì'),
(205, 'Í'),
(206, 'Î'),
(207, 'Ï'),
(208, 'Ð'),
(209, 'Ñ'),
(210, 'Ò'),
(211, 'Ó'),
(212, 'Ô'),
(213, 'Õ'),
(214, 'Ö'),
(215, '×'),
(216, 'Ø'),
(217, 'Ù'),
(218, 'Ú'),
(219, 'Û'),
(220, 'Ü'),
(221, 'Ý'),
(222, 'Þ'),
(223, 'ß'),
(224, 'à'),
(225, 'á'),
(226, 'â'),
(227, 'ã'),
(228, 'ä'),
(229, 'å'),
(230, 'æ'),
(231, 'ç'),
(232, 'è'),
(233, 'é'),
(234, 'ê'),
(235, 'ë'),
(236, 'ì'),
(237, 'í'),
(238, 'î'),
(239, 'ï'),
(240, 'ð'),
(241, 'ñ'),
(242, 'ò'),
(243, 'ó'),
(244, 'ô'),
(245, 'õ'),
(246, 'ö'),
(247, '÷'),
(248, 'ø'),
(249, 'ù'),
(250, 'ú'),
(251, 'û'),
(252, 'ü'),
(253, 'ý'),
(254, 'þ'),
(255, 'ÿ'),
(0, 'Ā'),
(1, 'ā'),
(2, 'Ă'),
(3, 'ă'),
(4, 'Ą'),
(5, 'ą'),
(6, 'Ć'),
(7, 'ć'),
(8, 'Ĉ'),
(9, 'ĉ'),
(10, 'Ċ'),
(11, 'ċ'),
(12, 'Č'),
(13, 'č'),
(14, 'Ď'),
(15, 'ď'),
(16, 'Đ'),
(17, 'đ'),
(18, 'Ē'),
(19, 'ē'),
(20, 'Ĕ'),
(21, 'ĕ'),
(22, 'Ė'),
(23, 'ė'),
(24, 'Ę'),
(25, 'ę'),
(26, 'Ě'),
(27, 'ě'),
(28, 'Ĝ'),
(29, 'ĝ'),
(30, 'Ğ'),
(31, 'ğ'),
(32, 'Ġ'),
(127, 'ġ'),
(128, 'Ģ'),
(129, 'ģ'),
(130, 'Ĥ'),
(131, 'ĥ'),
(132, 'Ħ'),
(133, 'ħ'),
(134, 'Ĩ'),
(135, 'ĩ'),
(136, 'Ī'),
(137, 'ī'),
(138, 'Ĭ'),
(139, 'ĭ'),
(140, 'Į'),
(141, 'į'),
(142, 'İ'),
(143, 'ı'),
(144, 'IJ'),
(145, 'ij'),
(146, 'Ĵ'),
(147, 'ĵ'),
(148, 'Ķ'),
(149, 'ķ'),
(150, 'ĸ'),
(151, 'Ĺ'),
(152, 'ĺ'),
(153, 'Ļ'),
(154, 'ļ'),
(155, 'Ľ'),
(156, 'ľ'),
(157, 'Ŀ'),
(158, 'ŀ'),
(159, 'Ł'),
(160, 'ł'),
(173, 'Ń'),
];
const PAT: &str =
r"<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+";
// This is mostly a Rust rewrite of the original Python CLIP code.
// https://github.com/openai/CLIP/blob/main/clip/simple_tokenizer.py
struct Tokenizer {
re: regex::Regex,
encoder: HashMap<String, usize>,
decoder: HashMap<usize, String>,
bpe_ranks: HashMap<(String, String), usize>,
start_of_text_token: usize,
end_of_text_token: usize,
}
impl Tokenizer {
fn create<T: AsRef<std::path::Path>>(bpe_path: T) -> anyhow::Result<Tokenizer> {
let bpe_file = std::fs::File::open(bpe_path)?;
let bpe_lines: Result<Vec<String>, _> = std::io::BufReader::new(bpe_file).lines().collect();
let bpe_lines = bpe_lines?;
let bpe_lines: Result<Vec<_>, _> = bpe_lines[1..49152 - 256 - 2 + 1]
.iter()
.map(|line| {
let vs: Vec<_> = line.split_whitespace().collect();
if vs.len() != 2 {
anyhow::bail!("expected two items got {} '{}'", vs.len(), line)
}
Ok((vs[0].to_string(), vs[1].to_string()))
})
.collect();
let bpe_lines = bpe_lines?;
let mut vocab: Vec<String> = Vec::new();
for (_index, elem) in BYTES_TO_UNICODE {
vocab.push(elem.into())
}
for (_index, elem) in BYTES_TO_UNICODE {
vocab.push(format!("{elem}</w>"));
}
for elem in bpe_lines.iter() {
vocab.push(format!("{}{}", elem.0, elem.1))
}
let start_of_text_token = vocab.len();
vocab.push("<|startoftext|>".to_string());
let end_of_text_token = vocab.len();
vocab.push("<|endoftext|>".to_string());
let encoder: HashMap<_, _> = vocab.into_iter().enumerate().map(|(i, v)| (v, i)).collect();
let decoder: HashMap<_, _> = encoder.iter().map(|(k, v)| (*v, k.clone())).collect();
let bpe_ranks: HashMap<_, _> =
bpe_lines.into_iter().enumerate().map(|(i, v)| (v, i)).collect();
let re = regex::Regex::new(PAT)?;
let tokenizer =
Tokenizer { encoder, re, bpe_ranks, decoder, start_of_text_token, end_of_text_token };
Ok(tokenizer)
}
fn get_pairs(word: &[String]) -> HashSet<(String, String)> {
let mut pairs = HashSet::new();
for (i, v) in word.iter().enumerate() {
if i > 0 {
pairs.insert((word[i - 1].clone(), v.clone()));
}
}
pairs
}
fn bpe(&self, token: &str) -> Vec<usize> {
let mut word: Vec<String> = token.chars().map(|x| x.to_string()).collect();
if word.is_empty() {
return Vec::new();
}
let last_index = word.len() - 1;
word[last_index] = format!("{}</w>", word[last_index]);
while word.len() > 1 {
let mut current_min = None;
let pairs = Self::get_pairs(&word);
for p in pairs.iter() {
match self.bpe_ranks.get(p) {
None => {}
Some(v) => {
let should_replace = match current_min {
None => true,
Some((current_min, _)) => v < current_min,
};
if should_replace {
current_min = Some((v, p))
}
}
}
}
let (first, second) = match current_min {
None => break,
Some((_v, (first, second))) => (first, second),
};
let mut new_word = vec![];
let mut index = 0;
while index < word.len() {
let w = &word[index];
if index + 1 < word.len() && w == first && &word[index + 1] == second {
new_word.push(format!("{first}{second}"));
index += 2
} else {
new_word.push(w.clone());
index += 1
}
}
word = new_word
}
word.iter().map(|x| *self.encoder.get(x).unwrap()).collect()
}
fn encode(&self, s: &str, pad_size_to: Option<usize>) -> anyhow::Result<Vec<usize>> {
let s = s.to_lowercase();
let mut bpe_tokens: Vec<usize> = vec![self.start_of_text_token];
for token in self.re.captures_iter(&s) {
let token = token.get(0).unwrap().as_str();
bpe_tokens.extend(self.bpe(token))
}
match pad_size_to {
None => bpe_tokens.push(self.end_of_text_token),
Some(pad_size_to) => {
bpe_tokens.resize_with(
std::cmp::min(bpe_tokens.len(), pad_size_to - 1),
Default::default,
);
while bpe_tokens.len() < pad_size_to {
bpe_tokens.push(self.end_of_text_token)
}
}
}
Ok(bpe_tokens)
}
fn decode(&self, tokens: &[usize]) -> String {
let s: String = tokens.iter().map(|token| self.decoder[token].as_str()).collect();
s.replace("</w>", " ")
}
}
// CLIP Text Model
// https://github.com/huggingface/transformers/blob/674f750a57431222fa2832503a108df3badf1564/src/transformers/models/clip/modeling_clip.py
#[derive(Debug)]
struct ClipTextEmbeddings {
token_embedding: nn::Embedding,
position_embedding: nn::Embedding,
position_ids: Tensor,
}
impl ClipTextEmbeddings {
fn new(vs: nn::Path) -> Self {
let token_embedding =
nn::embedding(&vs / "token_embedding", VOCAB_SIZE, EMBED_DIM, Default::default());
let position_embedding = nn::embedding(
&vs / "position_embedding",
MAX_POSITION_EMBEDDINGS as i64,
EMBED_DIM,
Default::default(),
);
let position_ids =
Tensor::arange(MAX_POSITION_EMBEDDINGS as i64, (Kind::Int64, vs.device()))
.expand([1, -1], false);
ClipTextEmbeddings { token_embedding, position_embedding, position_ids }
}
}
impl Module for ClipTextEmbeddings {
fn forward(&self, xs: &Tensor) -> Tensor {
let token_embedding = self.token_embedding.forward(xs);
let position_embedding = self.position_embedding.forward(&self.position_ids);
token_embedding + position_embedding
}
}
fn quick_gelu(xs: &Tensor) -> Tensor {
xs * (xs * 1.702).sigmoid()
}
#[derive(Debug)]
struct ClipAttention {
k_proj: nn::Linear,
v_proj: nn::Linear,
q_proj: nn::Linear,
out_proj: nn::Linear,
head_dim: i64,
scale: f64,
}
impl ClipAttention {
fn new(vs: nn::Path) -> Self {
let k_proj = nn::linear(&vs / "k_proj", EMBED_DIM, EMBED_DIM, Default::default());
let v_proj = nn::linear(&vs / "v_proj", EMBED_DIM, EMBED_DIM, Default::default());
let q_proj = nn::linear(&vs / "q_proj", EMBED_DIM, EMBED_DIM, Default::default());
let out_proj = nn::linear(&vs / "out_proj", EMBED_DIM, EMBED_DIM, Default::default());
let head_dim = EMBED_DIM / NUM_ATTENTION_HEADS;
let scale = (head_dim as f64).powf(-0.5);
ClipAttention { k_proj, v_proj, q_proj, out_proj, head_dim, scale }
}
fn shape(&self, xs: &Tensor, seq_len: i64, bsz: i64) -> Tensor {
xs.view((bsz, seq_len, NUM_ATTENTION_HEADS, self.head_dim)).transpose(1, 2).contiguous()
}
fn forward(&self, xs: &Tensor, causal_attention_mask: &Tensor) -> Tensor {
let (bsz, tgt_len, embed_dim) = xs.size3().unwrap();
let query_states = xs.apply(&self.q_proj) * self.scale;
let proj_shape = (bsz * NUM_ATTENTION_HEADS, -1, self.head_dim);
let query_states = self.shape(&query_states, tgt_len, bsz).view(proj_shape);
let key_states = self.shape(&xs.apply(&self.k_proj), -1, bsz).view(proj_shape);
let value_states = self.shape(&xs.apply(&self.v_proj), -1, bsz).view(proj_shape);
let attn_weights = query_states.bmm(&key_states.transpose(1, 2));
let src_len = key_states.size()[1];
let attn_weights =
attn_weights.view((bsz, NUM_ATTENTION_HEADS, tgt_len, src_len)) + causal_attention_mask;
let attn_weights = attn_weights.view((bsz * NUM_ATTENTION_HEADS, tgt_len, src_len));
let attn_weights = attn_weights.softmax(-1, Kind::Float);
let attn_output = attn_weights.bmm(&value_states);
attn_output
.view((bsz, NUM_ATTENTION_HEADS, tgt_len, self.head_dim))
.transpose(1, 2)
.reshape([bsz, tgt_len, embed_dim])
.apply(&self.out_proj)
}
}
#[derive(Debug)]
struct ClipMlp {
fc1: nn::Linear,
fc2: nn::Linear,
}
impl ClipMlp {
fn new(vs: nn::Path) -> Self {
let fc1 = nn::linear(&vs / "fc1", EMBED_DIM, INTERMEDIATE_SIZE, Default::default());
let fc2 = nn::linear(&vs / "fc2", INTERMEDIATE_SIZE, EMBED_DIM, Default::default());
ClipMlp { fc1, fc2 }
}
}
impl Module for ClipMlp {
fn forward(&self, xs: &Tensor) -> Tensor {
let xs = xs.apply(&self.fc1);
quick_gelu(&xs).apply(&self.fc2)
}
}
#[derive(Debug)]
struct ClipEncoderLayer {
self_attn: ClipAttention,
layer_norm1: nn::LayerNorm,
mlp: ClipMlp,
layer_norm2: nn::LayerNorm,
}
impl ClipEncoderLayer {
fn new(vs: nn::Path) -> Self {
let self_attn = ClipAttention::new(&vs / "self_attn");
let layer_norm1 = nn::layer_norm(&vs / "layer_norm1", vec![EMBED_DIM], Default::default());
let mlp = ClipMlp::new(&vs / "mlp");
let layer_norm2 = nn::layer_norm(&vs / "layer_norm2", vec![EMBED_DIM], Default::default());
ClipEncoderLayer { self_attn, layer_norm1, mlp, layer_norm2 }
}
fn forward(&self, xs: &Tensor, causal_attention_mask: &Tensor) -> Tensor {
let residual = xs;
let xs = self.layer_norm1.forward(xs);
let xs = self.self_attn.forward(&xs, causal_attention_mask);
let xs = xs + residual;
let residual = &xs;
let xs = self.layer_norm2.forward(&xs);
let xs = self.mlp.forward(&xs);
xs + residual
}
}
#[derive(Debug)]
struct ClipEncoder {
layers: Vec<ClipEncoderLayer>,
}
impl ClipEncoder {
fn new(vs: nn::Path) -> Self {
let vs = &vs / "layers";
let mut layers: Vec<ClipEncoderLayer> = Vec::new();
for index in 0..NUM_HIDDEN_LAYERS {
let layer = ClipEncoderLayer::new(&vs / index);
layers.push(layer)
}
ClipEncoder { layers }
}
fn forward(&self, xs: &Tensor, causal_attention_mask: &Tensor) -> Tensor {
let mut xs = xs.shallow_clone();
for layer in self.layers.iter() {
xs = layer.forward(&xs, causal_attention_mask)
}
xs
}
}
#[derive(Debug)]
struct ClipTextTransformer {
embeddings: ClipTextEmbeddings,
encoder: ClipEncoder,
final_layer_norm: nn::LayerNorm,
}
impl ClipTextTransformer {
fn new(vs: nn::Path) -> Self {
let vs = &vs / "text_model";
let embeddings = ClipTextEmbeddings::new(&vs / "embeddings");
let encoder = ClipEncoder::new(&vs / "encoder");
let final_layer_norm =
nn::layer_norm(&vs / "final_layer_norm", vec![EMBED_DIM], Default::default());
ClipTextTransformer { embeddings, encoder, final_layer_norm }
}
// https://github.com/huggingface/transformers/blob/674f750a57431222fa2832503a108df3badf1564/src/transformers/models/clip/modeling_clip.py#L678
fn build_causal_attention_mask(bsz: i64, seq_len: i64, device: Device) -> Tensor {
let mut mask = Tensor::ones([bsz, seq_len, seq_len], (Kind::Float, device));
mask.fill_(f32::MIN as f64).triu_(1).unsqueeze(1)
}
}
impl Module for ClipTextTransformer {
fn forward(&self, xs: &Tensor) -> Tensor {
let (bsz, seq_len) = xs.size2().unwrap();
let xs = self.embeddings.forward(xs);
let causal_attention_mask = Self::build_causal_attention_mask(bsz, seq_len, xs.device());
let xs = self.encoder.forward(&xs, &causal_attention_mask);
xs.apply(&self.final_layer_norm)
}
}
#[derive(Debug)]
struct GeGlu {
proj: nn::Linear,
}
impl GeGlu {
fn new(vs: nn::Path, dim_in: i64, dim_out: i64) -> Self {
let proj = nn::linear(&vs / "proj", dim_in, dim_out * 2, Default::default());
Self { proj }
}
}
impl Module for GeGlu {
fn forward(&self, xs: &Tensor) -> Tensor {
let hidden_states_and_gate = xs.apply(&self.proj).chunk(2, -1);
&hidden_states_and_gate[0] * hidden_states_and_gate[1].gelu("none")
}
}
#[derive(Debug)]
struct FeedForward {
project_in: GeGlu,
linear: nn::Linear,
}
impl FeedForward {
// The glu parameter in the python code is unused?
// https://github.com/huggingface/diffusers/blob/d3d22ce5a894becb951eec03e663951b28d45135/src/diffusers/models/attention.py#L347
fn new(vs: nn::Path, dim: i64, dim_out: Option<i64>, mult: i64) -> Self {
let inner_dim = dim * mult;
let dim_out = dim_out.unwrap_or(dim);
let vs = &vs / "net";
let project_in = GeGlu::new(&vs / 0, dim, inner_dim);
let linear = nn::linear(&vs / 2, inner_dim, dim_out, Default::default());
Self { project_in, linear }
}
}
impl Module for FeedForward {
fn forward(&self, xs: &Tensor) -> Tensor {
xs.apply(&self.project_in).apply(&self.linear)
}
}
#[derive(Debug)]
struct CrossAttention {
to_q: nn::Linear,
to_k: nn::Linear,
to_v: nn::Linear,
to_out: nn::Linear,
heads: i64,
scale: f64,
}
impl CrossAttention {
// Defaults should be heads = 8, dim_head = 64, context_dim = None
fn new(
vs: nn::Path,
query_dim: i64,
context_dim: Option<i64>,
heads: i64,
dim_head: i64,
) -> Self {
let no_bias = nn::LinearConfig { bias: false, ..Default::default() };
let inner_dim = dim_head * heads;
let context_dim = context_dim.unwrap_or(query_dim);
let scale = 1.0 / f64::sqrt(dim_head as f64);
let to_q = nn::linear(&vs / "to_q", query_dim, inner_dim, no_bias);
let to_k = nn::linear(&vs / "to_k", context_dim, inner_dim, no_bias);
let to_v = nn::linear(&vs / "to_v", context_dim, inner_dim, no_bias);
let to_out = nn::linear(&vs / "to_out" / 0, inner_dim, query_dim, Default::default());
Self { to_q, to_k, to_v, to_out, heads, scale }
}
fn reshape_heads_to_batch_dim(&self, xs: &Tensor) -> Tensor {
let (batch_size, seq_len, dim) = xs.size3().unwrap();
xs.reshape([batch_size, seq_len, self.heads, dim / self.heads])
.permute([0, 2, 1, 3])
.reshape([batch_size * self.heads, seq_len, dim / self.heads])
}
fn reshape_batch_dim_to_heads(&self, xs: &Tensor) -> Tensor {
let (batch_size, seq_len, dim) = xs.size3().unwrap();
xs.reshape([batch_size / self.heads, self.heads, seq_len, dim])
.permute([0, 2, 1, 3])
.reshape([batch_size / self.heads, seq_len, dim * self.heads])
}
fn attention(&self, query: &Tensor, key: &Tensor, value: &Tensor) -> Tensor {
let xs = query
.matmul(&(key.transpose(-1, -2) * self.scale))
.softmax(-1, Kind::Float)
.matmul(value);
self.reshape_batch_dim_to_heads(&xs)
}
fn forward(&self, xs: &Tensor, context: Option<&Tensor>) -> Tensor {
let query = xs.apply(&self.to_q);
let context = context.unwrap_or(xs);
let key = context.apply(&self.to_k);
let value = context.apply(&self.to_v);
let query = self.reshape_heads_to_batch_dim(&query);
let key = self.reshape_heads_to_batch_dim(&key);
let value = self.reshape_heads_to_batch_dim(&value);
self.attention(&query, &key, &value).apply(&self.to_out)
}
}
#[derive(Debug)]
struct BasicTransformerBlock {
attn1: CrossAttention,
ff: FeedForward,
attn2: CrossAttention,
norm1: nn::LayerNorm,
norm2: nn::LayerNorm,
norm3: nn::LayerNorm,
}
impl BasicTransformerBlock {
fn new(vs: nn::Path, dim: i64, n_heads: i64, d_head: i64, context_dim: Option<i64>) -> Self {
let attn1 = CrossAttention::new(&vs / "attn1", dim, None, n_heads, d_head);
let ff = FeedForward::new(&vs / "ff", dim, None, 4);
let attn2 = CrossAttention::new(&vs / "attn2", dim, context_dim, n_heads, d_head);
let norm1 = nn::layer_norm(&vs / "norm1", vec![dim], Default::default());
let norm2 = nn::layer_norm(&vs / "norm2", vec![dim], Default::default());
let norm3 = nn::layer_norm(&vs / "norm3", vec![dim], Default::default());
Self { attn1, ff, attn2, norm1, norm2, norm3 }
}
fn forward(&self, xs: &Tensor, context: Option<&Tensor>) -> Tensor {
let xs = self.attn1.forward(&xs.apply(&self.norm1), None) + xs;
let xs = self.attn2.forward(&xs.apply(&self.norm2), context) + xs;
xs.apply(&self.norm3).apply(&self.ff) + xs
}
}
#[derive(Debug, Clone, Copy)]
struct SpatialTransformerConfig {
depth: i64,
num_groups: i64,
context_dim: Option<i64>,
}
impl Default for SpatialTransformerConfig {
fn default() -> Self {
Self { depth: 1, num_groups: 32, context_dim: None }
}
}
#[derive(Debug)]
struct SpatialTransformer {
norm: nn::GroupNorm,
proj_in: nn::Conv2D,
transformer_blocks: Vec<BasicTransformerBlock>,
proj_out: nn::Conv2D,
#[allow(dead_code)]
config: SpatialTransformerConfig,
}
impl SpatialTransformer {
fn new(
vs: nn::Path,
in_channels: i64,
n_heads: i64,
d_head: i64,
config: SpatialTransformerConfig,
) -> Self {
let inner_dim = n_heads * d_head;
let group_cfg = nn::GroupNormConfig { eps: 1e-6, affine: true, ..Default::default() };
let norm = nn::group_norm(&vs / "norm", config.num_groups, in_channels, group_cfg);
let conv_cfg = nn::ConvConfig { stride: 1, padding: 0, ..Default::default() };
let proj_in = nn::conv2d(&vs / "proj_in", in_channels, inner_dim, 1, conv_cfg);
let mut transformer_blocks = vec![];
let vs_tb = &vs / "transformer_blocks";
for index in 0..config.depth {
let tb = BasicTransformerBlock::new(
&vs_tb / index,
inner_dim,
n_heads,
d_head,
config.context_dim,
);
transformer_blocks.push(tb)
}
let proj_out = nn::conv2d(&vs / "proj_out", inner_dim, in_channels, 1, conv_cfg);
Self { norm, proj_in, transformer_blocks, proj_out, config }
}
fn forward(&self, xs: &Tensor, context: Option<&Tensor>) -> Tensor {
let (batch, _channel, height, weight) = xs.size4().unwrap();
let residual = xs;
let xs = xs.apply(&self.norm).apply(&self.proj_in);
let inner_dim = xs.size()[1];
let mut xs = xs.permute([0, 2, 3, 1]).view((batch, height * weight, inner_dim));
for block in self.transformer_blocks.iter() {
xs = block.forward(&xs, context)
}
let xs =
xs.view((batch, height, weight, inner_dim)).permute([0, 3, 1, 2]).apply(&self.proj_out);
xs + residual
}
}
#[derive(Debug, Clone, Copy)]
struct AttentionBlockConfig {
num_head_channels: Option<i64>,
num_groups: i64,
rescale_output_factor: f64,
eps: f64,
}
impl Default for AttentionBlockConfig {
fn default() -> Self {
Self { num_head_channels: None, num_groups: 32, rescale_output_factor: 1., eps: 1e-5 }
}
}
#[derive(Debug)]
struct AttentionBlock {
group_norm: nn::GroupNorm,
query: nn::Linear,
key: nn::Linear,
value: nn::Linear,
proj_attn: nn::Linear,
channels: i64,
num_heads: i64,
config: AttentionBlockConfig,
}
impl AttentionBlock {
fn new(vs: nn::Path, channels: i64, config: AttentionBlockConfig) -> Self {
let num_head_channels = config.num_head_channels.unwrap_or(channels);
let num_heads = channels / num_head_channels;
let group_cfg = nn::GroupNormConfig { eps: config.eps, affine: true, ..Default::default() };
let group_norm = nn::group_norm(&vs / "group_norm", config.num_groups, channels, group_cfg);
let query = nn::linear(&vs / "query", channels, channels, Default::default());
let key = nn::linear(&vs / "key", channels, channels, Default::default());
let value = nn::linear(&vs / "value", channels, channels, Default::default());
let proj_attn = nn::linear(&vs / "proj_attn", channels, channels, Default::default());
Self { group_norm, query, key, value, proj_attn, channels, num_heads, config }
}
fn transpose_for_scores(&self, xs: Tensor) -> Tensor {
let (batch, t, _h_times_d) = xs.size3().unwrap();
xs.view((batch, t, self.num_heads, -1)).permute([0, 2, 1, 3])
}
}
impl Module for AttentionBlock {
fn forward(&self, xs: &Tensor) -> Tensor {
let residual = xs;
let (batch, channel, height, width) = xs.size4().unwrap();
let xs = xs.apply(&self.group_norm).view((batch, channel, height * width)).transpose(1, 2);
let query_proj = xs.apply(&self.query);
let key_proj = xs.apply(&self.key);
let value_proj = xs.apply(&self.value);
let query_states = self.transpose_for_scores(query_proj);
let key_states = self.transpose_for_scores(key_proj);
let value_states = self.transpose_for_scores(value_proj);
let scale = f64::powf((self.channels as f64) / (self.num_heads as f64), -0.25);
let attention_scores =
(query_states * scale).matmul(&(key_states.transpose(-1, -2) * scale));
let attention_probs = attention_scores.softmax(-1, Kind::Float);
let xs = attention_probs.matmul(&value_states);
let xs = xs.permute([0, 2, 1, 3]).contiguous();
let mut new_xs_shape = xs.size();
new_xs_shape.pop();
new_xs_shape.pop();
new_xs_shape.push(self.channels);
let xs = xs
.view(new_xs_shape.as_slice())
.apply(&self.proj_attn)
.transpose(-1, -2)
.view((batch, channel, height, width));
(xs + residual) / self.config.rescale_output_factor
}
}
#[derive(Debug)]
struct Downsample2D {
conv: Option<nn::Conv2D>,
padding: i64,
}
impl Downsample2D {
fn new(
vs: nn::Path,
in_channels: i64,
use_conv: bool,
out_channels: i64,
padding: i64,
) -> Self {
let conv = if use_conv {
let config = nn::ConvConfig { stride: 2, padding, ..Default::default() };
let conv = nn::conv2d(&vs / "conv", in_channels, out_channels, 3, config);
Some(conv)
} else {
None
};
Downsample2D { conv, padding }
}
}
impl Module for Downsample2D {
fn forward(&self, xs: &Tensor) -> Tensor {
match &self.conv {
None => xs.avg_pool2d([2, 2], [2, 2], [0, 0], false, true, None),
Some(conv) => {
if self.padding == 0 {
xs.pad([0, 1, 0, 1], "constant", Some(0.)).apply(conv)
} else {
xs.apply(conv)
}
}
}
}
}
// This does not support the conv-transpose mode.
#[derive(Debug)]
struct Upsample2D {
conv: nn::Conv2D,
}
impl Upsample2D {
fn new(vs: nn::Path, in_channels: i64, out_channels: i64) -> Self {
let config = nn::ConvConfig { padding: 1, ..Default::default() };
let conv = nn::conv2d(&vs / "conv", in_channels, out_channels, 3, config);
Self { conv }
}
}
impl Upsample2D {
fn forward(&self, xs: &Tensor, size: Option<(i64, i64)>) -> Tensor {
let xs = match size {
None => {
// The following does not work and it's tricky to pass no fixed
// dimensions so hack our way around this.
// xs.upsample_nearest2d(&[], Some(2.), Some(2.)
let (_bsize, _channels, h, w) = xs.size4().unwrap();
xs.upsample_nearest2d([2 * h, 2 * w], Some(2.), Some(2.))
}
Some((h, w)) => xs.upsample_nearest2d([h, w], None, None),
};
xs.apply(&self.conv)
}
}
#[derive(Debug, Clone, Copy)]
struct ResnetBlock2DConfig {
out_channels: Option<i64>,
temb_channels: Option<i64>,
groups: i64,
groups_out: Option<i64>,
eps: f64,
use_in_shortcut: Option<bool>,
// non_linearity: silu
output_scale_factor: f64,
}
impl Default for ResnetBlock2DConfig {
fn default() -> Self {
Self {
out_channels: None,
temb_channels: Some(512),
groups: 32,
groups_out: None,
eps: 1e-6,
use_in_shortcut: None,
output_scale_factor: 1.,
}
}
}
#[derive(Debug)]
struct ResnetBlock2D {
norm1: nn::GroupNorm,
conv1: nn::Conv2D,
norm2: nn::GroupNorm,
conv2: nn::Conv2D,
time_emb_proj: Option<nn::Linear>,
conv_shortcut: Option<nn::Conv2D>,
config: ResnetBlock2DConfig,
}
impl ResnetBlock2D {
fn new(vs: nn::Path, in_channels: i64, config: ResnetBlock2DConfig) -> Self {
let out_channels = config.out_channels.unwrap_or(in_channels);
let conv_cfg = nn::ConvConfig { stride: 1, padding: 1, ..Default::default() };
let group_cfg = nn::GroupNormConfig { eps: config.eps, affine: true, ..Default::default() };
let norm1 = nn::group_norm(&vs / "norm1", config.groups, in_channels, group_cfg);
let conv1 = nn::conv2d(&vs / "conv1", in_channels, out_channels, 3, conv_cfg);
let groups_out = config.groups_out.unwrap_or(config.groups);
let norm2 = nn::group_norm(&vs / "norm2", groups_out, out_channels, group_cfg);
let conv2 = nn::conv2d(&vs / "conv2", out_channels, out_channels, 3, conv_cfg);
let use_in_shortcut = config.use_in_shortcut.unwrap_or(in_channels != out_channels);
let conv_shortcut = if use_in_shortcut {
let conv_cfg = nn::ConvConfig { stride: 1, padding: 0, ..Default::default() };
Some(nn::conv2d(&vs / "conv_shortcut", in_channels, out_channels, 1, conv_cfg))
} else {
None
};
let time_emb_proj = config.temb_channels.map(|temb_channels| {
nn::linear(&vs / "time_emb_proj", temb_channels, out_channels, Default::default())
});
Self { norm1, conv1, norm2, conv2, time_emb_proj, config, conv_shortcut }
}
fn forward(&self, xs: &Tensor, temb: Option<&Tensor>) -> Tensor {
let shortcut_xs = match &self.conv_shortcut {
Some(conv_shortcut) => xs.apply(conv_shortcut),
None => xs.shallow_clone(),
};
let xs = xs.apply(&self.norm1).silu().apply(&self.conv1);
let xs = match (temb, &self.time_emb_proj) {
(Some(temb), Some(time_emb_proj)) => {
temb.silu().apply(time_emb_proj).unsqueeze(-1).unsqueeze(-1) + xs
}
_ => xs,
};
let xs = xs.apply(&self.norm2).silu().apply(&self.conv2);
(shortcut_xs + xs) / self.config.output_scale_factor
}
}
#[derive(Debug, Clone, Copy)]
struct DownEncoderBlock2DConfig {
num_layers: i64,
resnet_eps: f64,
resnet_groups: i64,
output_scale_factor: f64,
add_downsample: bool,
downsample_padding: i64,
}
impl Default for DownEncoderBlock2DConfig {
fn default() -> Self {
Self {
num_layers: 1,
resnet_eps: 1e-6,
resnet_groups: 32,
output_scale_factor: 1.,
add_downsample: true,
downsample_padding: 1,
}
}
}
#[derive(Debug)]
struct DownEncoderBlock2D {
resnets: Vec<ResnetBlock2D>,
downsampler: Option<Downsample2D>,
#[allow(dead_code)]
config: DownEncoderBlock2DConfig,
}
impl DownEncoderBlock2D {
fn new(
vs: nn::Path,
in_channels: i64,
out_channels: i64,
config: DownEncoderBlock2DConfig,
) -> Self {
let resnets: Vec<_> = {
let vs = &vs / "resnets";
let conv_cfg = ResnetBlock2DConfig {
eps: config.resnet_eps,
out_channels: Some(out_channels),
groups: config.resnet_groups,
output_scale_factor: config.output_scale_factor,
temb_channels: None,
..Default::default()
};
(0..(config.num_layers))
.map(|i| {
let in_channels = if i == 0 { in_channels } else { out_channels };
ResnetBlock2D::new(&vs / i, in_channels, conv_cfg)
})
.collect()
};
let downsampler = if config.add_downsample {
let downsample = Downsample2D::new(
&(&vs / "downsamplers") / 0,
out_channels,
true,
out_channels,
config.downsample_padding,
);
Some(downsample)
} else {
None
};
Self { resnets, downsampler, config }
}
}
impl Module for DownEncoderBlock2D {
fn forward(&self, xs: &Tensor) -> Tensor {
let mut xs = xs.shallow_clone();
for resnet in self.resnets.iter() {
xs = resnet.forward(&xs, None)
}
match &self.downsampler {
Some(downsampler) => xs.apply(downsampler),
None => xs,
}
}
}
#[derive(Debug, Clone, Copy)]
struct UpDecoderBlock2DConfig {
num_layers: i64,
resnet_eps: f64,
resnet_groups: i64,
output_scale_factor: f64,
add_upsample: bool,
}
impl Default for UpDecoderBlock2DConfig {
fn default() -> Self {
Self {
num_layers: 1,
resnet_eps: 1e-6,
resnet_groups: 32,
output_scale_factor: 1.,
add_upsample: true,
}
}
}
#[derive(Debug)]
struct UpDecoderBlock2D {
resnets: Vec<ResnetBlock2D>,
upsampler: Option<Upsample2D>,
#[allow(dead_code)]
config: UpDecoderBlock2DConfig,
}
impl UpDecoderBlock2D {
fn new(
vs: nn::Path,
in_channels: i64,
out_channels: i64,
config: UpDecoderBlock2DConfig,
) -> Self {
let resnets: Vec<_> = {
let vs = &vs / "resnets";
let conv_cfg = ResnetBlock2DConfig {
out_channels: Some(out_channels),
eps: config.resnet_eps,
groups: config.resnet_groups,
output_scale_factor: config.output_scale_factor,
temb_channels: None,
..Default::default()
};
(0..(config.num_layers))
.map(|i| {
let in_channels = if i == 0 { in_channels } else { out_channels };
ResnetBlock2D::new(&vs / i, in_channels, conv_cfg)
})
.collect()
};
let upsampler = if config.add_upsample {
let upsample = Upsample2D::new(&vs / "upsamplers" / 0, out_channels, out_channels);
Some(upsample)
} else {
None
};
Self { resnets, upsampler, config }
}
}
impl Module for UpDecoderBlock2D {
fn forward(&self, xs: &Tensor) -> Tensor {
let mut xs = xs.shallow_clone();
for resnet in self.resnets.iter() {
xs = resnet.forward(&xs, None)
}
match &self.upsampler {
Some(upsampler) => upsampler.forward(&xs, None),
None => xs,
}
}
}
#[derive(Debug, Clone, Copy)]
struct UNetMidBlock2DConfig {
num_layers: i64,
resnet_eps: f64,
resnet_groups: Option<i64>,
attn_num_head_channels: Option<i64>,
// attention_type "default"
output_scale_factor: f64,
}
impl Default for UNetMidBlock2DConfig {
fn default() -> Self {
Self {
num_layers: 1,
resnet_eps: 1e-6,
resnet_groups: Some(32),
attn_num_head_channels: Some(1),
output_scale_factor: 1.,
}
}
}
#[derive(Debug)]
struct UNetMidBlock2D {
resnet: ResnetBlock2D,
attn_resnets: Vec<(AttentionBlock, ResnetBlock2D)>,
#[allow(dead_code)]
config: UNetMidBlock2DConfig,
}
impl UNetMidBlock2D {
fn new(
vs: nn::Path,
in_channels: i64,
temb_channels: Option<i64>,
config: UNetMidBlock2DConfig,
) -> Self {
let vs_resnets = &vs / "resnets";
let vs_attns = &vs / "attentions";
let resnet_groups = config.resnet_groups.unwrap_or_else(|| i64::min(in_channels / 4, 32));
let resnet_cfg = ResnetBlock2DConfig {
eps: config.resnet_eps,
groups: resnet_groups,
output_scale_factor: config.output_scale_factor,
temb_channels,
..Default::default()
};
let resnet = ResnetBlock2D::new(&vs_resnets / "0", in_channels, resnet_cfg);
let attn_cfg = AttentionBlockConfig {
num_head_channels: config.attn_num_head_channels,
num_groups: resnet_groups,
rescale_output_factor: config.output_scale_factor,
eps: config.resnet_eps,
};
let mut attn_resnets = vec![];
for index in 0..config.num_layers {
let attn = AttentionBlock::new(&vs_attns / index, in_channels, attn_cfg);
let resnet = ResnetBlock2D::new(&vs_resnets / (index + 1), in_channels, resnet_cfg);
attn_resnets.push((attn, resnet))
}
Self { resnet, attn_resnets, config }
}
fn forward(&self, xs: &Tensor, temb: Option<&Tensor>) -> Tensor {
let mut xs = self.resnet.forward(xs, temb);
for (attn, resnet) in self.attn_resnets.iter() {
xs = resnet.forward(&xs.apply(attn), temb)
}
xs
}
}
#[derive(Debug, Clone, Copy)]
struct UNetMidBlock2DCrossAttnConfig {
num_layers: i64,
resnet_eps: f64,
resnet_groups: Option<i64>,
attn_num_head_channels: i64,
// attention_type "default"
output_scale_factor: f64,
cross_attn_dim: i64,
}
impl Default for UNetMidBlock2DCrossAttnConfig {
fn default() -> Self {
Self {
num_layers: 1,
resnet_eps: 1e-6,
resnet_groups: Some(32),
attn_num_head_channels: 1,
output_scale_factor: 1.,
cross_attn_dim: 1280,
}
}
}
#[derive(Debug)]
struct UNetMidBlock2DCrossAttn {
resnet: ResnetBlock2D,
attn_resnets: Vec<(SpatialTransformer, ResnetBlock2D)>,
#[allow(dead_code)]
config: UNetMidBlock2DCrossAttnConfig,
}
impl UNetMidBlock2DCrossAttn {
fn new(
vs: nn::Path,
in_channels: i64,
temb_channels: Option<i64>,
config: UNetMidBlock2DCrossAttnConfig,
) -> Self {
let vs_resnets = &vs / "resnets";
let vs_attns = &vs / "attentions";
let resnet_groups = config.resnet_groups.unwrap_or_else(|| i64::min(in_channels / 4, 32));
let resnet_cfg = ResnetBlock2DConfig {
eps: config.resnet_eps,
groups: resnet_groups,
output_scale_factor: config.output_scale_factor,
temb_channels,
..Default::default()
};
let resnet = ResnetBlock2D::new(&vs_resnets / "0", in_channels, resnet_cfg);
let n_heads = config.attn_num_head_channels;
let attn_cfg = SpatialTransformerConfig {
depth: 1,
num_groups: resnet_groups,
context_dim: Some(config.cross_attn_dim),
};
let mut attn_resnets = vec![];
for index in 0..config.num_layers {
let attn = SpatialTransformer::new(
&vs_attns / index,
in_channels,
n_heads,
in_channels / n_heads,
attn_cfg,
);
let resnet = ResnetBlock2D::new(&vs_resnets / (index + 1), in_channels, resnet_cfg);
attn_resnets.push((attn, resnet))
}
Self { resnet, attn_resnets, config }
}
fn forward(
&self,
xs: &Tensor,
temb: Option<&Tensor>,
encoder_hidden_states: Option<&Tensor>,
) -> Tensor {
let mut xs = self.resnet.forward(xs, temb);
for (attn, resnet) in self.attn_resnets.iter() {
xs = resnet.forward(&attn.forward(&xs, encoder_hidden_states), temb)
}
xs
}
}
#[derive(Debug, Clone)]
struct EncoderConfig {
// down_block_types: DownEncoderBlock2D
block_out_channels: Vec<i64>,
layers_per_block: i64,
norm_num_groups: i64,
double_z: bool,
}
impl Default for EncoderConfig {
fn default() -> Self {
Self {
block_out_channels: vec![64],
layers_per_block: 2,
norm_num_groups: 32,
double_z: true,
}
}
}
#[derive(Debug)]
struct Encoder {
conv_in: nn::Conv2D,
down_blocks: Vec<DownEncoderBlock2D>,
mid_block: UNetMidBlock2D,
conv_norm_out: nn::GroupNorm,
conv_out: nn::Conv2D,
#[allow(dead_code)]
config: EncoderConfig,
}
impl Encoder {
fn new(vs: nn::Path, in_channels: i64, out_channels: i64, config: EncoderConfig) -> Self {
let conv_cfg = nn::ConvConfig { stride: 1, padding: 1, ..Default::default() };
let conv_in =
nn::conv2d(&vs / "conv_in", in_channels, config.block_out_channels[0], 3, conv_cfg);
let mut down_blocks = vec![];
let vs_down_blocks = &vs / "down_blocks";
for index in 0..config.block_out_channels.len() {
let out_channels = config.block_out_channels[index];
let in_channels = if index > 0 {
config.block_out_channels[index - 1]
} else {
config.block_out_channels[0]
};
let is_final = index + 1 == config.block_out_channels.len();
let cfg = DownEncoderBlock2DConfig {
num_layers: config.layers_per_block,
resnet_eps: 1e-6,
resnet_groups: config.norm_num_groups,
add_downsample: !is_final,
downsample_padding: 0,
..Default::default()
};
let down_block =
DownEncoderBlock2D::new(&vs_down_blocks / index, in_channels, out_channels, cfg);
down_blocks.push(down_block)
}
let last_block_out_channels = *config.block_out_channels.last().unwrap();
let mid_cfg = UNetMidBlock2DConfig {
resnet_eps: 1e-6,
output_scale_factor: 1.,
attn_num_head_channels: None,
resnet_groups: Some(config.norm_num_groups),
..Default::default()
};
let mid_block =
UNetMidBlock2D::new(&vs / "mid_block", last_block_out_channels, None, mid_cfg);
let group_cfg = nn::GroupNormConfig { eps: 1e-6, ..Default::default() };
let conv_norm_out = nn::group_norm(
&vs / "conv_norm_out",
config.norm_num_groups,
last_block_out_channels,
group_cfg,
);
let conv_out_channels = if config.double_z { 2 * out_channels } else { out_channels };
let conv_cfg = nn::ConvConfig { padding: 1, ..Default::default() };
let conv_out =
nn::conv2d(&vs / "conv_out", last_block_out_channels, conv_out_channels, 3, conv_cfg);
Self { conv_in, down_blocks, mid_block, conv_norm_out, conv_out, config }
}
}
impl Module for Encoder {
fn forward(&self, xs: &Tensor) -> Tensor {
let mut xs = xs.apply(&self.conv_in);
for down_block in self.down_blocks.iter() {
xs = xs.apply(down_block)
}
self.mid_block.forward(&xs, None).apply(&self.conv_norm_out).silu().apply(&self.conv_out)
}
}
#[derive(Debug, Clone)]
struct DecoderConfig {
// up_block_types: UpDecoderBlock2D
block_out_channels: Vec<i64>,
layers_per_block: i64,
norm_num_groups: i64,
}
impl Default for DecoderConfig {
fn default() -> Self {
Self { block_out_channels: vec![64], layers_per_block: 2, norm_num_groups: 32 }
}
}
#[derive(Debug)]
struct Decoder {
conv_in: nn::Conv2D,
up_blocks: Vec<UpDecoderBlock2D>,
mid_block: UNetMidBlock2D,
conv_norm_out: nn::GroupNorm,
conv_out: nn::Conv2D,
#[allow(dead_code)]
config: DecoderConfig,
}
impl Decoder {
fn new(vs: nn::Path, in_channels: i64, out_channels: i64, config: DecoderConfig) -> Self {
let n_block_out_channels = config.block_out_channels.len();
let last_block_out_channels = *config.block_out_channels.last().unwrap();
let conv_cfg = nn::ConvConfig { stride: 1, padding: 1, ..Default::default() };
let conv_in =
nn::conv2d(&vs / "conv_in", in_channels, last_block_out_channels, 3, conv_cfg);
let mid_cfg = UNetMidBlock2DConfig {
resnet_eps: 1e-6,
output_scale_factor: 1.,
attn_num_head_channels: None,
resnet_groups: Some(config.norm_num_groups),
..Default::default()
};
let mid_block =
UNetMidBlock2D::new(&vs / "mid_block", last_block_out_channels, None, mid_cfg);
let mut up_blocks = vec![];
let vs_up_blocks = &vs / "up_blocks";
let reversed_block_out_channels: Vec<_> =
config.block_out_channels.iter().copied().rev().collect();
for index in 0..n_block_out_channels {
let out_channels = reversed_block_out_channels[index];
let in_channels = if index > 0 {
reversed_block_out_channels[index - 1]
} else {
reversed_block_out_channels[0]
};
let is_final = index + 1 == n_block_out_channels;
let cfg = UpDecoderBlock2DConfig {
num_layers: config.layers_per_block + 1,
resnet_eps: 1e-6,
resnet_groups: config.norm_num_groups,
add_upsample: !is_final,
..Default::default()
};
let up_block =
UpDecoderBlock2D::new(&vs_up_blocks / index, in_channels, out_channels, cfg);
up_blocks.push(up_block)
}
let group_cfg = nn::GroupNormConfig { eps: 1e-6, ..Default::default() };
let conv_norm_out = nn::group_norm(
&vs / "conv_norm_out",
config.norm_num_groups,
config.block_out_channels[0],
group_cfg,
);
let conv_cfg = nn::ConvConfig { padding: 1, ..Default::default() };
let conv_out =
nn::conv2d(&vs / "conv_out", config.block_out_channels[0], out_channels, 3, conv_cfg);
Self { conv_in, up_blocks, mid_block, conv_norm_out, conv_out, config }
}
}
impl Module for Decoder {
fn forward(&self, xs: &Tensor) -> Tensor {
let mut xs = self.mid_block.forward(&xs.apply(&self.conv_in), None);
for up_block in self.up_blocks.iter() {
xs = xs.apply(up_block)
}
xs.apply(&self.conv_norm_out).silu().apply(&self.conv_out)
}
}
#[derive(Debug, Clone)]
struct AutoEncoderKLConfig {
block_out_channels: Vec<i64>,
layers_per_block: i64,
latent_channels: i64,
norm_num_groups: i64,
}
impl Default for AutoEncoderKLConfig {
fn default() -> Self {
Self {
block_out_channels: vec![64],
layers_per_block: 1,
latent_channels: 4,
norm_num_groups: 32,
}
}
}
// https://github.com/huggingface/diffusers/blob/970e30606c2944e3286f56e8eb6d3dc6d1eb85f7/src/diffusers/models/vae.py#L485
// This implementation is specific to the config used in stable-diffusion-v1-4
// https://huggingface.co/CompVis/stable-diffusion-v1-4/blob/main/vae/config.json
#[derive(Debug)]
struct AutoEncoderKL {
encoder: Encoder,
decoder: Decoder,
quant_conv: nn::Conv2D,
post_quant_conv: nn::Conv2D,
#[allow(dead_code)]
config: AutoEncoderKLConfig,
}
impl AutoEncoderKL {
fn new(vs: nn::Path, in_channels: i64, out_channels: i64, config: AutoEncoderKLConfig) -> Self {
let latent_channels = config.latent_channels;
let encoder_cfg = EncoderConfig {
block_out_channels: config.block_out_channels.clone(),
layers_per_block: config.layers_per_block,
norm_num_groups: config.norm_num_groups,
double_z: true,
};
let encoder = Encoder::new(&vs / "encoder", in_channels, latent_channels, encoder_cfg);
let decoder_cfg = DecoderConfig {
block_out_channels: config.block_out_channels.clone(),
layers_per_block: config.layers_per_block,
norm_num_groups: config.norm_num_groups,
};
let decoder = Decoder::new(&vs / "decoder", latent_channels, out_channels, decoder_cfg);
let conv_cfg = Default::default();
let quant_conv =
nn::conv2d(&vs / "quant_conv", 2 * latent_channels, 2 * latent_channels, 1, conv_cfg);
let post_quant_conv =
nn::conv2d(&vs / "post_quant_conv", latent_channels, latent_channels, 1, conv_cfg);
Self { encoder, decoder, quant_conv, post_quant_conv, config }
}
// Returns the parameters of the latent distribution.
#[allow(dead_code)]
fn encode(&self, xs: &Tensor) -> Tensor {
xs.apply(&self.encoder).apply(&self.quant_conv)
}
/// Takes as input some sampled values.
fn decode(&self, xs: &Tensor) -> Tensor {
xs.apply(&self.post_quant_conv).apply(&self.decoder)
}
}
#[derive(Debug, Clone, Copy)]
struct DownBlock2DConfig {
num_layers: i64,
resnet_eps: f64,
// resnet_time_scale_shift: "default"
// resnet_act_fn: "swish"
resnet_groups: i64,
output_scale_factor: f64,
add_downsample: bool,
downsample_padding: i64,
}
impl Default for DownBlock2DConfig {
fn default() -> Self {
Self {
num_layers: 1,
resnet_eps: 1e-6,
resnet_groups: 32,
output_scale_factor: 1.,
add_downsample: true,
downsample_padding: 1,
}
}
}
#[derive(Debug)]
struct DownBlock2D {
resnets: Vec<ResnetBlock2D>,
downsampler: Option<Downsample2D>,
#[allow(dead_code)]
config: DownBlock2DConfig,
}
impl DownBlock2D {
fn new(
vs: nn::Path,
in_channels: i64,
out_channels: i64,
temb_channels: Option<i64>,
config: DownBlock2DConfig,
) -> Self {
let vs_resnets = &vs / "resnets";
let resnet_cfg = ResnetBlock2DConfig {
out_channels: Some(out_channels),
eps: config.resnet_eps,
output_scale_factor: config.output_scale_factor,
temb_channels,
..Default::default()
};
let resnets = (0..config.num_layers)
.map(|i| {
let in_channels = if i == 0 { in_channels } else { out_channels };
ResnetBlock2D::new(&vs_resnets / i, in_channels, resnet_cfg)
})
.collect();
let downsampler = if config.add_downsample {
let downsampler = Downsample2D::new(
&vs / "downsamplers" / 0,
out_channels,
true,
out_channels,
config.downsample_padding,
);
Some(downsampler)
} else {
None
};
Self { resnets, downsampler, config }
}
fn forward(&self, xs: &Tensor, temb: Option<&Tensor>) -> (Tensor, Vec<Tensor>) {
let mut xs = xs.shallow_clone();
let mut output_states = vec![];
for resnet in self.resnets.iter() {
xs = resnet.forward(&xs, temb);
output_states.push(xs.shallow_clone());
}
let xs = match &self.downsampler {
Some(downsampler) => {
let xs = xs.apply(downsampler);
output_states.push(xs.shallow_clone());
xs
}
None => xs,
};
(xs, output_states)
}
}
#[derive(Debug, Clone, Copy)]
struct CrossAttnDownBlock2DConfig {
downblock: DownBlock2DConfig,
attn_num_head_channels: i64,
cross_attention_dim: i64,
// attention_type: "default"
}
impl Default for CrossAttnDownBlock2DConfig {
fn default() -> Self {
Self { downblock: Default::default(), attn_num_head_channels: 1, cross_attention_dim: 1280 }
}
}
#[derive(Debug)]
struct CrossAttnDownBlock2D {
downblock: DownBlock2D,
attentions: Vec<SpatialTransformer>,
#[allow(dead_code)]
config: CrossAttnDownBlock2DConfig,
}
impl CrossAttnDownBlock2D {
fn new(
vs: nn::Path,
in_channels: i64,
out_channels: i64,
temb_channels: Option<i64>,
config: CrossAttnDownBlock2DConfig,
) -> Self {
let downblock = DownBlock2D::new(
vs.clone(),
in_channels,
out_channels,
temb_channels,
config.downblock,
);
let n_heads = config.attn_num_head_channels;
let cfg = SpatialTransformerConfig {
depth: 1,
context_dim: Some(config.cross_attention_dim),
num_groups: config.downblock.resnet_groups,
};
let vs_attn = &vs / "attentions";
let attentions = (0..config.downblock.num_layers)
.map(|i| {
SpatialTransformer::new(
&vs_attn / i,
out_channels,
n_heads,
out_channels / n_heads,
cfg,
)
})
.collect();
Self { downblock, attentions, config }
}
fn forward(
&self,
xs: &Tensor,
temb: Option<&Tensor>,
encoder_hidden_states: Option<&Tensor>,
) -> (Tensor, Vec<Tensor>) {
let mut output_states = vec![];
let mut xs = xs.shallow_clone();
for (resnet, attn) in self.downblock.resnets.iter().zip(self.attentions.iter()) {
xs = resnet.forward(&xs, temb);
xs = attn.forward(&xs, encoder_hidden_states);
output_states.push(xs.shallow_clone());
}
let xs = match &self.downblock.downsampler {
Some(downsampler) => {
let xs = xs.apply(downsampler);
output_states.push(xs.shallow_clone());
xs
}
None => xs,
};
(xs, output_states)
}
}
#[derive(Debug, Clone, Copy)]
struct UpBlock2DConfig {
num_layers: i64,
resnet_eps: f64,
// resnet_time_scale_shift: "default"
// resnet_act_fn: "swish"
resnet_groups: i64,
output_scale_factor: f64,
add_upsample: bool,
}
impl Default for UpBlock2DConfig {
fn default() -> Self {
Self {
num_layers: 1,
resnet_eps: 1e-6,
resnet_groups: 32,
output_scale_factor: 1.,
add_upsample: true,
}
}
}
#[derive(Debug)]
struct UpBlock2D {
resnets: Vec<ResnetBlock2D>,
upsampler: Option<Upsample2D>,
#[allow(dead_code)]
config: UpBlock2DConfig,
}
impl UpBlock2D {
fn new(
vs: nn::Path,
in_channels: i64,
prev_output_channels: i64,
out_channels: i64,
temb_channels: Option<i64>,
config: UpBlock2DConfig,
) -> Self {
let vs_resnets = &vs / "resnets";
let resnet_cfg = ResnetBlock2DConfig {
out_channels: Some(out_channels),
temb_channels,
eps: config.resnet_eps,
output_scale_factor: config.output_scale_factor,
..Default::default()
};
let resnets = (0..config.num_layers)
.map(|i| {
let res_skip_channels =
if i == config.num_layers - 1 { in_channels } else { out_channels };
let resnet_in_channels = if i == 0 { prev_output_channels } else { out_channels };
let in_channels = resnet_in_channels + res_skip_channels;
ResnetBlock2D::new(&vs_resnets / i, in_channels, resnet_cfg)
})
.collect();
let upsampler = if config.add_upsample {
let upsampler = Upsample2D::new(&vs / "upsamplers" / 0, out_channels, out_channels);
Some(upsampler)
} else {
None
};
Self { resnets, upsampler, config }
}
fn forward(
&self,
xs: &Tensor,
res_xs: &[Tensor],
temb: Option<&Tensor>,
upsample_size: Option<(i64, i64)>,
) -> Tensor {
let mut xs = xs.shallow_clone();
for (index, resnet) in self.resnets.iter().enumerate() {
xs = Tensor::cat(&[&xs, &res_xs[res_xs.len() - index - 1]], 1);
xs = resnet.forward(&xs, temb);
}
match &self.upsampler {
Some(upsampler) => upsampler.forward(&xs, upsample_size),
None => xs,
}
}
}
#[derive(Debug, Clone, Copy)]
struct CrossAttnUpBlock2DConfig {
upblock: UpBlock2DConfig,
attn_num_head_channels: i64,
cross_attention_dim: i64,
// attention_type: "default"
}
impl Default for CrossAttnUpBlock2DConfig {
fn default() -> Self {
Self { upblock: Default::default(), attn_num_head_channels: 1, cross_attention_dim: 1280 }
}
}
#[derive(Debug)]
struct CrossAttnUpBlock2D {
upblock: UpBlock2D,
attentions: Vec<SpatialTransformer>,
#[allow(dead_code)]
config: CrossAttnUpBlock2DConfig,
}
impl CrossAttnUpBlock2D {
fn new(
vs: nn::Path,
in_channels: i64,
prev_output_channels: i64,
out_channels: i64,
temb_channels: Option<i64>,
config: CrossAttnUpBlock2DConfig,
) -> Self {
let upblock = UpBlock2D::new(
vs.clone(),
in_channels,
prev_output_channels,
out_channels,
temb_channels,
config.upblock,
);
let n_heads = config.attn_num_head_channels;
let cfg = SpatialTransformerConfig {
depth: 1,
context_dim: Some(config.cross_attention_dim),
num_groups: config.upblock.resnet_groups,
};
let vs_attn = &vs / "attentions";
let attentions = (0..config.upblock.num_layers)
.map(|i| {
SpatialTransformer::new(
&vs_attn / i,
out_channels,
n_heads,
out_channels / n_heads,
cfg,
)
})
.collect();
Self { upblock, attentions, config }
}
fn forward(
&self,
xs: &Tensor,
res_xs: &[Tensor],
temb: Option<&Tensor>,
upsample_size: Option<(i64, i64)>,
encoder_hidden_states: Option<&Tensor>,
) -> Tensor {
let mut xs = xs.shallow_clone();
for (index, resnet) in self.upblock.resnets.iter().enumerate() {
xs = Tensor::cat(&[&xs, &res_xs[res_xs.len() - index - 1]], 1);
xs = resnet.forward(&xs, temb);
xs = self.attentions[index].forward(&xs, encoder_hidden_states);
}
match &self.upblock.upsampler {
Some(upsampler) => upsampler.forward(&xs, upsample_size),
None => xs,
}
}
}
#[derive(Debug)]
struct Timesteps {
num_channels: i64,
flip_sin_to_cos: bool,
downscale_freq_shift: f64,
device: Device,
}
impl Timesteps {
fn new(
num_channels: i64,
flip_sin_to_cos: bool,
downscale_freq_shift: f64,
device: Device,
) -> Self {
Self { num_channels, flip_sin_to_cos, downscale_freq_shift, device }
}
}
impl Module for Timesteps {
fn forward(&self, xs: &Tensor) -> Tensor {
let half_dim = self.num_channels / 2;
let exponent = Tensor::arange(half_dim, (Kind::Float, self.device)) * -f64::ln(10000.);
let exponent = exponent / (half_dim as f64 - self.downscale_freq_shift);
let emb = exponent.exp();
// emb = timesteps[:, None].float() * emb[None, :]
let emb = xs.unsqueeze(-1) * emb.unsqueeze(0);
let emb = if self.flip_sin_to_cos {
Tensor::cat(&[emb.cos(), emb.sin()], -1)
} else {
Tensor::cat(&[emb.sin(), emb.cos()], -1)
};
if self.num_channels % 2 == 1 {
emb.pad([0, 1, 0, 0], "constant", None)
} else {
emb
}
}
}
#[derive(Debug)]
struct TimestepEmbedding {
linear_1: nn::Linear,
linear_2: nn::Linear,
}
impl TimestepEmbedding {
// act_fn: "silu"
fn new(vs: nn::Path, channel: i64, time_embed_dim: i64) -> Self {
let linear_cfg = Default::default();
let linear_1 = nn::linear(&vs / "linear_1", channel, time_embed_dim, linear_cfg);
let linear_2 = nn::linear(&vs / "linear_2", time_embed_dim, time_embed_dim, linear_cfg);
Self { linear_1, linear_2 }
}
}
impl Module for TimestepEmbedding {
fn forward(&self, xs: &Tensor) -> Tensor {
xs.apply(&self.linear_1).silu().apply(&self.linear_2)
}
}
#[derive(Debug, Clone, Copy)]
struct BlockConfig {
out_channels: i64,
use_cross_attn: bool,
}
#[derive(Debug, Clone)]
struct UNet2DConditionModelConfig {
center_input_sample: bool,
flip_sin_to_cos: bool,
freq_shift: f64,
blocks: Vec<BlockConfig>,
layers_per_block: i64,
downsample_padding: i64,
mid_block_scale_factor: f64,
norm_num_groups: i64,
norm_eps: f64,
cross_attention_dim: i64,
attention_head_dim: i64,
}
impl Default for UNet2DConditionModelConfig {
fn default() -> Self {
Self {
center_input_sample: false,
flip_sin_to_cos: true,
freq_shift: 0.,
blocks: vec![
BlockConfig { out_channels: 320, use_cross_attn: true },
BlockConfig { out_channels: 640, use_cross_attn: true },
BlockConfig { out_channels: 1280, use_cross_attn: true },
BlockConfig { out_channels: 1280, use_cross_attn: false },
],
layers_per_block: 2,
downsample_padding: 1,
mid_block_scale_factor: 1.,
norm_num_groups: 32,
norm_eps: 1e-5,
cross_attention_dim: 1280,
attention_head_dim: 8,
}
}
}
#[derive(Debug)]
enum UNetDownBlock {
Basic(DownBlock2D),
CrossAttn(CrossAttnDownBlock2D),
}
#[derive(Debug)]
enum UNetUpBlock {
Basic(UpBlock2D),
CrossAttn(CrossAttnUpBlock2D),
}
#[derive(Debug)]
struct UNet2DConditionModel {
conv_in: nn::Conv2D,
time_proj: Timesteps,
time_embedding: TimestepEmbedding,
down_blocks: Vec<UNetDownBlock>,
mid_block: UNetMidBlock2DCrossAttn,
up_blocks: Vec<UNetUpBlock>,
conv_norm_out: nn::GroupNorm,
conv_out: nn::Conv2D,
config: UNet2DConditionModelConfig,
}
impl UNet2DConditionModel {
fn new(
vs: nn::Path,
in_channels: i64,
out_channels: i64,
config: UNet2DConditionModelConfig,
) -> Self {
let n_blocks = config.blocks.len();
let b_channels = config.blocks[0].out_channels;
let bl_channels = config.blocks.last().unwrap().out_channels;
let time_embed_dim = b_channels * 4;
let conv_cfg = nn::ConvConfig { stride: 1, padding: 1, ..Default::default() };
let conv_in = nn::conv2d(&vs / "conv_in", in_channels, b_channels, 3, conv_cfg);
let time_proj =
Timesteps::new(b_channels, config.flip_sin_to_cos, config.freq_shift, vs.device());
let time_embedding =
TimestepEmbedding::new(&vs / "time_embedding", b_channels, time_embed_dim);
let vs_db = &vs / "down_blocks";
let down_blocks = (0..n_blocks)
.map(|i| {
let BlockConfig { out_channels, use_cross_attn } = config.blocks[i];
let in_channels =
if i > 0 { config.blocks[i - 1].out_channels } else { b_channels };
let db_cfg = DownBlock2DConfig {
num_layers: config.layers_per_block,
resnet_eps: config.norm_eps,
resnet_groups: config.norm_num_groups,
add_downsample: i < n_blocks - 1,
downsample_padding: config.downsample_padding,
..Default::default()
};
if use_cross_attn {
let config = CrossAttnDownBlock2DConfig {
downblock: db_cfg,
attn_num_head_channels: config.attention_head_dim,
cross_attention_dim: config.cross_attention_dim,
};
let block = CrossAttnDownBlock2D::new(
&vs_db / i,
in_channels,
out_channels,
Some(time_embed_dim),
config,
);
UNetDownBlock::CrossAttn(block)
} else {
let block = DownBlock2D::new(
&vs_db / i,
in_channels,
out_channels,
Some(time_embed_dim),
db_cfg,
);
UNetDownBlock::Basic(block)
}
})
.collect();
let mid_cfg = UNetMidBlock2DCrossAttnConfig {
resnet_eps: config.norm_eps,
output_scale_factor: config.mid_block_scale_factor,
cross_attn_dim: config.cross_attention_dim,
attn_num_head_channels: config.attention_head_dim,
resnet_groups: Some(config.norm_num_groups),
..Default::default()
};
let mid_block = UNetMidBlock2DCrossAttn::new(
&vs / "mid_block",
bl_channels,
Some(time_embed_dim),
mid_cfg,
);
let vs_ub = &vs / "up_blocks";
let up_blocks = (0..n_blocks)
.map(|i| {
let BlockConfig { out_channels, use_cross_attn } = config.blocks[n_blocks - 1 - i];
let prev_out_channels =
if i > 0 { config.blocks[n_blocks - i].out_channels } else { bl_channels };
let in_channels = {
let index = if i == n_blocks - 1 { 0 } else { n_blocks - i - 2 };
config.blocks[index].out_channels
};
let ub_cfg = UpBlock2DConfig {
num_layers: config.layers_per_block + 1,
resnet_eps: config.norm_eps,
resnet_groups: config.norm_num_groups,
add_upsample: i < n_blocks - 1,
..Default::default()
};
if use_cross_attn {
let config = CrossAttnUpBlock2DConfig {
upblock: ub_cfg,
attn_num_head_channels: config.attention_head_dim,
cross_attention_dim: config.cross_attention_dim,
};
let block = CrossAttnUpBlock2D::new(
&vs_ub / i,
in_channels,
prev_out_channels,
out_channels,
Some(time_embed_dim),
config,
);
UNetUpBlock::CrossAttn(block)
} else {
let block = UpBlock2D::new(
&vs_ub / i,
in_channels,
prev_out_channels,
out_channels,
Some(time_embed_dim),
ub_cfg,
);
UNetUpBlock::Basic(block)
}
})
.collect();
let group_cfg = nn::GroupNormConfig { eps: config.norm_eps, ..Default::default() };
let conv_norm_out =
nn::group_norm(&vs / "conv_norm_out", config.norm_num_groups, b_channels, group_cfg);
let conv_out = nn::conv2d(&vs / "conv_out", b_channels, out_channels, 3, conv_cfg);
Self {
conv_in,
time_proj,
time_embedding,
down_blocks,
mid_block,
up_blocks,
conv_norm_out,
conv_out,
config,
}
}
}
impl UNet2DConditionModel {
fn forward(&self, xs: &Tensor, timestep: f64, encoder_hidden_states: &Tensor) -> Tensor {
let (bsize, _channels, height, width) = xs.size4().unwrap();
let device = xs.device();
let n_blocks = self.config.blocks.len();
let num_upsamplers = n_blocks - 1;
let default_overall_up_factor = 2i64.pow(num_upsamplers as u32);
let forward_upsample_size =
height % default_overall_up_factor != 0 || width % default_overall_up_factor != 0;
// 0. center input if necessary
let xs = if self.config.center_input_sample { xs * 2.0 - 1.0 } else { xs.shallow_clone() };
// 1. time
let emb = (Tensor::ones([bsize], (Kind::Float, device)) * timestep)
.apply(&self.time_proj)
.apply(&self.time_embedding);
// 2. pre-process
let xs = xs.apply(&self.conv_in);
// 3. down
let mut down_block_res_xs = vec![xs.shallow_clone()];
let mut xs = xs;
for down_block in self.down_blocks.iter() {
let (_xs, res_xs) = match down_block {
UNetDownBlock::Basic(b) => b.forward(&xs, Some(&emb)),
UNetDownBlock::CrossAttn(b) => {
b.forward(&xs, Some(&emb), Some(encoder_hidden_states))
}
};
down_block_res_xs.extend(res_xs);
xs = _xs;
}
// 4. mid
let xs = self.mid_block.forward(&xs, Some(&emb), Some(encoder_hidden_states));
// 5. up
let mut xs = xs;
let mut upsample_size = None;
for (i, up_block) in self.up_blocks.iter().enumerate() {
let n_resnets = match up_block {
UNetUpBlock::Basic(b) => b.resnets.len(),
UNetUpBlock::CrossAttn(b) => b.upblock.resnets.len(),
};
let res_xs = down_block_res_xs.split_off(down_block_res_xs.len() - n_resnets);
if i < n_blocks - 1 && forward_upsample_size {
let (_, _, h, w) = down_block_res_xs.last().unwrap().size4().unwrap();
upsample_size = Some((h, w))
}
xs = match up_block {
UNetUpBlock::Basic(b) => b.forward(&xs, &res_xs, Some(&emb), upsample_size),
UNetUpBlock::CrossAttn(b) => {
b.forward(&xs, &res_xs, Some(&emb), upsample_size, Some(encoder_hidden_states))
}
};
}
// 6. post-process
xs.apply(&self.conv_norm_out).silu().apply(&self.conv_out)
}
}
// TODO: LMSDiscreteScheduler
// https://github.com/huggingface/diffusers/blob/32bf4fdc4386809c870528cb261028baae012d27/src/diffusers/schedulers/scheduling_lms_discrete.py#L47
fn build_clip_transformer(device: Device) -> anyhow::Result<ClipTextTransformer> {
let mut vs = nn::VarStore::new(device);
let text_model = ClipTextTransformer::new(vs.root());
vs.load("data/pytorch_model.ot")?;
Ok(text_model)
}
fn build_vae(device: Device) -> anyhow::Result<AutoEncoderKL> {
let mut vs_ae = nn::VarStore::new(device);
// https://huggingface.co/CompVis/stable-diffusion-v1-4/blob/main/vae/config.json
let autoencoder_cfg = AutoEncoderKLConfig {
block_out_channels: vec![128, 256, 512, 512],
layers_per_block: 2,
latent_channels: 4,
norm_num_groups: 32,
};
let autoencoder = AutoEncoderKL::new(vs_ae.root(), 3, 3, autoencoder_cfg);
vs_ae.load("data/vae.ot")?;
Ok(autoencoder)
}
fn build_unet(device: Device) -> anyhow::Result<UNet2DConditionModel> {
let mut vs_unet = nn::VarStore::new(device);
// https://huggingface.co/CompVis/stable-diffusion-v1-4/blob/main/unet/config.json
let unet_cfg = UNet2DConditionModelConfig {
attention_head_dim: 8,
blocks: vec![
BlockConfig { out_channels: 320, use_cross_attn: true },
BlockConfig { out_channels: 640, use_cross_attn: true },
BlockConfig { out_channels: 1280, use_cross_attn: true },
BlockConfig { out_channels: 1280, use_cross_attn: false },
],
center_input_sample: false,
cross_attention_dim: 768,
downsample_padding: 1,
flip_sin_to_cos: true,
freq_shift: 0.,
layers_per_block: 2,
mid_block_scale_factor: 1.,
norm_eps: 1e-5,
norm_num_groups: 32,
};
let unet = UNet2DConditionModel::new(vs_unet.root(), 4, 4, unet_cfg);
vs_unet.load("data/unet.ot")?;
Ok(unet)
}
#[derive(Debug, Clone, Copy)]
enum BetaSchedule {
#[allow(dead_code)]
Linear,
ScaledLinear,
}
#[derive(Debug, Clone, Copy)]
struct DDIMSchedulerConfig {
beta_start: f64,
beta_end: f64,
beta_schedule: BetaSchedule,
eta: f64,
}
impl Default for DDIMSchedulerConfig {
fn default() -> Self {
Self {
beta_start: 0.00085f64,
beta_end: 0.012f64,
beta_schedule: BetaSchedule::ScaledLinear,
eta: 0.,
}
}
}
#[derive(Debug, Clone)]
struct DDIMScheduler {
timesteps: Vec<usize>,
alphas_cumprod: Vec<f64>,
step_ratio: usize,
#[allow(dead_code)]
config: DDIMSchedulerConfig,
}
// clip_sample: False, set_alpha_to_one: False
impl DDIMScheduler {
fn new(inference_steps: usize, train_timesteps: usize, config: DDIMSchedulerConfig) -> Self {
let step_ratio = train_timesteps / inference_steps;
// TODO: Remove this hack which aimed at matching the behavior of diffusers==0.2.4
let timesteps = (0..(inference_steps + 1)).map(|s| s * step_ratio).rev().collect();
let betas = match config.beta_schedule {
BetaSchedule::ScaledLinear => Tensor::linspace(
config.beta_start.sqrt(),
config.beta_end.sqrt(),
train_timesteps as i64,
kind::FLOAT_CPU,
)
.square(),
BetaSchedule::Linear => Tensor::linspace(
config.beta_start,
config.beta_end,
train_timesteps as i64,
kind::FLOAT_CPU,
),
};
let alphas: Tensor = 1.0 - betas;
let alphas_cumprod = Vec::<f64>::try_from(alphas.cumprod(0, Kind::Double)).unwrap();
Self { alphas_cumprod, timesteps, step_ratio, config }
}
// https://github.com/huggingface/diffusers/blob/6e099e2c8ce4c4f5c7318e970a8c093dc5c7046e/src/diffusers/schedulers/scheduling_ddim.py#L195
fn step(&self, model_output: &Tensor, timestep: usize, sample: &Tensor) -> Tensor {
let prev_timestep = if timestep > self.step_ratio { timestep - self.step_ratio } else { 0 };
let alpha_prod_t = self.alphas_cumprod[timestep];
let alpha_prod_t_prev = self.alphas_cumprod[prev_timestep];
let beta_prod_t = 1. - alpha_prod_t;
let beta_prod_t_prev = 1. - alpha_prod_t_prev;
let pred_original_sample =
(sample - beta_prod_t.sqrt() * model_output) / alpha_prod_t.sqrt();
let variance = (beta_prod_t_prev / beta_prod_t) * (1. - alpha_prod_t / alpha_prod_t_prev);
let std_dev_t = self.config.eta * variance.sqrt();
let pred_sample_direction =
(1. - alpha_prod_t_prev - std_dev_t * std_dev_t).sqrt() * model_output;
let prev_sample = alpha_prod_t_prev.sqrt() * pred_original_sample + pred_sample_direction;
if self.config.eta > 0. {
&prev_sample + Tensor::randn_like(&prev_sample) * std_dev_t
} else {
prev_sample
}
}
}
fn main() -> anyhow::Result<()> {
println!("Cuda available: {}", tch::Cuda::is_available());
println!("Cudnn available: {}", tch::Cuda::cudnn_is_available());
// TODO: Switch to using claps to allow more flags?
let mut prompt = "A rusty robot holding a fire torch in its hand".to_string();
let mut device = Device::cuda_if_available();
for arg in std::env::args().skip(1) {
if arg.as_str() == "cpu" {
device = Device::Cpu;
} else {
prompt = arg;
}
}
let n_steps = 30;
let scheduler = DDIMScheduler::new(n_steps, 1000, Default::default());
let tokenizer = Tokenizer::create("data/bpe_simple_vocab_16e6.txt")?;
let tokens = tokenizer.encode(&prompt, Some(MAX_POSITION_EMBEDDINGS))?;
let str = tokenizer.decode(&tokens);
println!("Str: {str}");
let tokens: Vec<i64> = tokens.iter().map(|x| *x as i64).collect();
let tokens = Tensor::f_of_slice(&tokens)?.view((1, -1)).to(device);
let uncond_tokens = tokenizer.encode("", Some(MAX_POSITION_EMBEDDINGS))?;
let uncond_tokens: Vec<i64> = uncond_tokens.iter().map(|x| *x as i64).collect();
let uncond_tokens = Tensor::f_of_slice(&uncond_tokens)?.view((1, -1)).to(device);
println!("Tokens: {tokens:?}");
let no_grad_guard = tch::no_grad_guard();
println!("Building the Clip transformer.");
let text_model = build_clip_transformer(device)?;
let text_embeddings = text_model.forward(&tokens);
let uncond_embeddings = text_model.forward(&uncond_tokens);
let text_embeddings = Tensor::cat(&[uncond_embeddings, text_embeddings], 0);
println!("Text embeddings: {text_embeddings:?}");
println!("Building the autoencoder.");
let vae = build_vae(device)?;
println!("Building the unet.");
let unet = build_unet(device)?;
let bsize = 1;
// DETERMINISTIC SEEDING
tch::manual_seed(32);
let mut latents = Tensor::randn([bsize, 4, HEIGHT / 8, WIDTH / 8], (Kind::Float, device));
for (timestep_index, ×tep) in scheduler.timesteps.iter().enumerate() {
println!("Timestep {timestep_index} {timestep} {latents:?}");
let latent_model_input = Tensor::cat(&[&latents, &latents], 0);
let noise_pred = unet.forward(&latent_model_input, timestep as f64, &text_embeddings);
let noise_pred = noise_pred.chunk(2, 0);
let (noise_pred_uncond, noise_pred_text) = (&noise_pred[0], &noise_pred[1]);
let noise_pred = noise_pred_uncond + (noise_pred_text - noise_pred_uncond) * GUIDANCE_SCALE;
latents = scheduler.step(&noise_pred, timestep, &latents);
let image = vae.decode(&(&latents / 0.18215));
let image = (image / 2 + 0.5).clamp(0., 1.).to_device(Device::Cpu);
let image = (image * 255.).to_kind(Kind::Uint8);
tch::vision::image::save(&image, format!("sd_{timestep_index}.png"))?
}
drop(no_grad_guard);
Ok(())
}
This code implements Stable Diffusion in Rust, using a combination of CLIP for text encoding, a Variational Autoencoder (VAE) for compressing images into a latent space, a UNet model for iterative denoising, and a scheduler to guide each diffusion step. Text is first tokenized by a custom tokenizer and processed into embeddings via CLIP, which provides context to the UNet for image generation. The UNet, structured with downsampling and upsampling blocks and cross-attention layers, takes these embeddings and a noisy latent vector to denoise it progressively, using time embeddings to keep track of diffusion steps. The scheduler, DDIM, iteratively refines this vector towards a noise-free latent representation aligned with the text prompt. Finally, the VAE decoder reconstructs the denoised latent representation into an image, outputting visuals at each timestep to show the image gradually emerging from random noise. This setup allows text prompts to guide image generation in a structured, stepwise diffusion process.
In terms of comparing output quality and diversity between GPT models and other generative techniques like VAEs, GANs, and Diffusion Models, the choice of model depends on the task at hand. GPT models excel in text generation due to their ability to capture long-range dependencies in language through self-attention mechanisms. However, VAEs and GANs are more suited to tasks like image generation and style transfer, where modeling complex distributions and generating high-resolution outputs are critical. Diffusion models, with their stable training process and high-quality output, are becoming increasingly popular in domains that require fine-grained control over the generative process, such as high-resolution image synthesis or multi-modal generation tasks.
In industry, GANs have become particularly useful in areas like game development, fashion design, and virtual content creation, where generating synthetic yet realistic images and animations is crucial. VAEs are often employed in anomaly detection and scientific data modeling, where understanding latent structures in the data is important. Diffusion models, while still emerging, are being explored in fields like art generation, audio synthesis, and even medical imaging, where high-resolution, complex data generation is required.
The latest trends in generative modeling reflect a growing interest in hybrid models that combine the strengths of different techniques. For example, hybrid models that integrate the autoregressive power of GPT with the generative capabilities of VAEs or GANs are being explored to handle multi-modal tasks, where both text and images need to be generated coherently. Similarly, diffusion models are being extended to handle more complex tasks, such as video generation and cross-modal translation, making them a promising area for future research and development.
In conclusion, while GPT models have made significant strides in generative tasks related to language, advanced generative techniques like VAEs, GANs, and Diffusion Models offer powerful alternatives for other domains. These models provide different mechanisms for generating high-quality data, and each excels in specific applications, from image synthesis to anomaly detection. With Rust’s growing ecosystem for machine learning, implementing these advanced models offers an exciting opportunity to explore generative tasks in a high-performance, memory-safe environment.
Section 6.6. GPT vs LLaMA Architectures
The architectures of GPT and LLaMA offer distinct approaches to autoregressive modeling, each shaped by specific design choices that impact scalability, efficiency, and adaptability in generating human-like text. To understand the differences, we need to examine the formal underpinnings of their architecture, token dependencies, attention mechanisms, and parameter allocation strategies, as well as how these models are trained to balance efficiency with expressive capacity.
GPT, the Generative Pre-trained Transformer, is fundamentally built on an autoregressive transformer architecture. This model operates by predicting each subsequent token based on a sequence of previous tokens, with the goal of maximizing the probability of generating coherent text given prior context. Formally, given a sequence $x = \{x_1, x_2, \ldots, x_n\}$, the model optimizes the conditional probability $P(x_i | x_{ $$P(x) = \prod_{i=1}^{n} P(x_i | x_{ GPT implements a decoder-only transformer structure where only causal (unidirectional) attention is used, limiting attention to preceding tokens. This causal masking is enforced to ensure that predictions rely solely on previously observed tokens, maintaining the autoregressive property. Architecturally, each transformer block in GPT includes a masked multi-head self-attention layer and a feed-forward neural network layer, each followed by layer normalization. Notationally, let $H^{(l)}$ denote the hidden state at layer $l$, then the self-attention operation at each layer can be expressed as $$H^{(l+1)} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V,$$ where $Q = H^{(l)}W_Q$, $K = H^{(l)}W_K$, and $V = H^{(l)}W_V$ are the query, key, and value matrices with dimension $d_k$. Each layer’s output is subsequently passed through a feed-forward neural network, given by $$\text{FFN}(H^{(l+1)}) = \text{ReLU}(H^{(l+1)}W_1 + b_1)W_2 + b_2.$$ GPT’s architectural simplicity emphasizes scaling up layers and model size, using large datasets for pretraining and limited architectural adjustments to maintain a high degree of generality. In contrast, LLaMA (Large Language Model Meta AI) introduces several architectural refinements aimed at enhancing parameter efficiency and performance, particularly for training large-scale models with fewer resources. LLaMA shares the autoregressive objective with GPT but optimizes for efficiency through techniques such as rotary positional embeddings (RoPE) and an alternative approach to parameter scaling. Rotary embeddings enable position encodings directly in attention, preserving relative position information without the rigid sinusoidal embeddings in traditional transformers. In mathematical terms, RoPE applies a rotation matrix $R$ to the query and key vectors, allowing the model to capture positional information as part of the dot product computation within the attention mechanism: $$Q' = Q \cdot R, \quad K' = K \cdot R$$ where the rotation matrix $R$ is a function of the relative position in the sequence, effectively encoding token positions through learned rotations rather than static embeddings. Figure 9: Comparison of LLAMA and GPT-3 (decoder-only) Architectures. Additionally, LLaMA emphasizes efficiency by focusing on densely packed parameters and reducing the depth of its feed-forward layers while preserving high hidden dimensions in the attention blocks. Unlike GPT’s emphasis on adding layers to increase capacity, LLaMA's architecture optimizes for broader and shallower layers, facilitating faster training times and making effective use of training data. The model also employs dynamic scaling techniques for layer normalization, balancing gradient flow and stability across layers. This shift in parameter allocation strategy enables LLaMA to achieve comparable or superior performance to GPT at similar parameter counts, particularly in resource-constrained training scenarios. Training objectives and dataset usage further delineate the models. GPT models are typically trained with vast datasets across diverse domains, focusing on generality and domain transferability. LLaMA, however, is optimized for more targeted datasets, prioritizing high-quality, diverse text sources that reduce the need for excessive parameter counts. Both models rely on a cross-entropy loss function to measure prediction accuracy, defined as $$\mathcal{L} = -\sum_{i=1}^{n} \log P(x_i | x_{ with gradient-based optimization to iteratively minimize loss across training sequences. LLaMA’s design choices allow it to achieve efficient scaling laws, where performance improvements per additional parameter are maximized without excessive growth in model size, an aspect that differentiates it markedly from GPT’s scaling approach. In terms of optimizations and regularizations, GPT and LLaMA adopt distinct strategies that reflect their design philosophies and target applications. GPT models, especially in larger variants like GPT-3, focus on scaling through dense parameterization, with optimizations largely aimed at infrastructure-level improvements to support massive model size and data throughput. Regularization techniques such as dropout and layer normalization help prevent overfitting and stabilize training across these deep networks, while model parallelism enables efficient distribution of computations across large hardware clusters. LLaMA, however, leverages optimizations focused on parameter efficiency, such as the use of low-rank adapters and more compact architectures that maintain performance with fewer parameters. Regularization in LLaMA is more adaptive; it includes techniques like rotational embeddings to enhance embedding stability across layers and minimize loss drift, allowing it to achieve competitive performance in a more resource-efficient manner than traditional scaling methods. These optimizations enable LLaMA to operate effectively in environments with limited computational resources, making it more accessible for on-device applications and streamlined for fine-tuning on specialized tasks. This code sets up a scenario in which a language model (similar to LLaMA) is used to generate text based on a predefined prompt. It starts by downloading and loading a tokenizer configuration if it's not already available locally. The code defines a tokenizer to encode and decode text using byte-pair encoding (BPE), allowing it to convert text inputs into token sequences for the model to process. The model configuration specifies essential hyperparameters, including embedding dimensions, the number of transformer layers, and attention heads. The In the main function, after initializing the tokenizer and the LLaMA model configuration, the tokenizer is tested by encoding and decoding a sample sentence. Then, using the initial prompt, the code generates text iteratively by feeding tokens into the model and sampling the next token based on the output logits converted to probabilities through a softmax layer. This iterative process simulates autoregressive text generation, where each token is selected based on its probability. Each sampled token is decoded to produce human-readable text, and the process repeats until the model generates 100 tokens or completes the text generation. GPT and LLaMA models have found substantial traction in industry applications due to their advanced language generation capabilities, high accuracy, and versatility across multiple domains. The industry adoption of GPT began as OpenAI released models like GPT-2 and GPT-3, which demonstrated groundbreaking capabilities in natural language understanding and generation, inspiring a wide range of applications in fields from customer service to creative writing and beyond. More recently, LLaMA (Large Language Model Meta AI), developed by Meta, emerged as an open-source alternative to proprietary GPT models, providing an adaptable and resource-efficient option for companies and research institutions. Both GPT and LLaMA have seen extensive deployment, though they cater to slightly different operational needs and scaling strategies. GPT models, especially GPT-3 and GPT-4, have become a staple in customer support automation, content generation, code synthesis, and conversational AI. Major companies integrate GPT-powered chatbots and virtual assistants to manage customer inquiries, improve response times, and enhance customer experience. Microsoft, a key partner with OpenAI, has embedded GPT-4 into various products, including Microsoft Copilot and Office 365 applications, to assist with tasks like drafting emails, summarizing documents, and generating complex spreadsheets. Additionally, GPT models are used to support developers in tools like GitHub Copilot, which leverages GPT’s ability to generate code snippets, suggest solutions, and accelerate software development workflows. Beyond the office, industries like media and entertainment rely on GPT for creative assistance, using it to brainstorm ideas, draft scripts, and even generate realistic dialogue for virtual characters. LLaMA, with its efficient architecture and open-access approach, has opened new doors for companies looking to implement large language models without proprietary constraints. Designed for parameter efficiency, LLaMA is especially popular among organizations seeking to deploy advanced language models on smaller budgets or with limited computational resources. Since LLaMA’s models are open-source, industries with stringent security requirements or specialized needs have adopted it as a foundation for building custom applications. For instance, in healthcare and finance, LLaMA’s flexibility allows organizations to fine-tune the model on domain-specific data without sharing sensitive information externally. LLaMA has also become a preferred choice for academic institutions and smaller tech companies aiming to leverage language models for research, personalized learning, and domain-specific knowledge extraction. More recently, the development of instruction-tuned variants, such as GPT-4-turbo and LLaMA 2, has further refined the industry’s approach to aligning these models with user intent. GPT-4-turbo, optimized for performance, is widely used in real-time, high-availability environments where quick and accurate responses are critical. LLaMA 2, open-source and instruction-tuned, is tailored for specialized interactions and responsive to custom training, thus making it ideal for industries that need high levels of adaptability, such as healthcare for diagnosing patient symptoms or financial services for personalized recommendations. The industry adoption of both GPT and LLaMA reflects a broader trend in natural language processing toward models that are not only powerful but also adaptable to specific operational constraints and goals. Both models drive innovations in automation, creativity, and interaction, collectively pushing the frontier of what language AI can achieve and enabling organizations to offer richer, more intuitive user experiences across diverse applications. While both GPT and LLaMA adhere to the autoregressive transformer structure, they diverge in architectural strategies: GPT relies on straightforward scaling with deep networks, whereas LLaMA innovates with parameter efficiency, rotational embeddings, and selective dataset optimization. This distinction gives LLaMA a unique advantage in environments with limited computational resources, offering a more efficient alternative to traditional large-scale transformers like GPT while still maintaining robust generative performance. Evaluating generative models, particularly those that produce text, requires a combination of automated metrics and human evaluation to ensure the generated outputs are both quantitatively strong and qualitatively meaningful. The nature of generative models, such as GPT, demands evaluation frameworks that assess the coherence, relevance, and creativity of the generated outputs. However, due to the inherently subjective nature of many generative tasks, automated metrics are often insufficient to fully capture the performance of these models, necessitating human evaluation as a complementary approach. Automated metrics like BLEU (Bilingual Evaluation Understudy), ROUGE (Recall-Oriented Understudy for Gisting Evaluation), and perplexity are widely used to measure the quality of text generated by language models. BLEU, originally developed for machine translation, compares the n-grams in the generated text with those in a reference text to calculate precision, determining how closely the generated text matches the ground truth. The BLEU score is computed as follows: $$\text{BLEU} = \text{BP} \cdot \exp \left( \sum_{n=1}^{N} w_n \log p_n \right),$$ where $p_n$ represents the precision of n-grams, $w_n$ are the weights assigned to each n-gram order, and $\text{BP}$ is a brevity penalty that penalizes short translations. While BLEU is effective at measuring overlap between generated and reference text, it is less sensitive to creativity and fluency, and it often fails to capture the nuances of long-form text generation, where there may be multiple valid ways to express the same idea. ROUGE, particularly ROUGE-L, is another common metric used for text summarization tasks. It calculates the recall of overlapping n-grams, and ROUGE-L focuses on the longest common subsequence between generated and reference text. The recall is computed as: $$\text{ROUGE-L} = \frac{LCS(X, Y)}{|Y|},$$ where $LCS(X, Y)$ is the length of the longest common subsequence between the generated text $X$ and the reference text $Y$, and $|Y|$ is the length of the reference. ROUGE offers a better sense of fluency and structure compared to BLEU, especially in tasks like summarization, but like BLEU, it focuses heavily on surface-level similarity, making it less effective for tasks requiring creative generation or tasks where multiple diverse outputs are acceptable. Perplexity is a more general measure used to evaluate language models, reflecting how well the model predicts the next word in a sequence. Perplexity is defined as the exponential of the negative log-likelihood of the test data: $$\text{Perplexity} = \exp \left( - \frac{1}{N} \sum_{i=1}^{N} \log P(x_i | x_1, \dots, x_{i-1}) \right),$$ where $P(x_i | x_1, \dots, x_{i-1})$ represents the conditional probability of the next word $x_i$ given the previous words. A lower perplexity indicates that the model is more confident in its predictions, leading to better language generation. However, perplexity does not directly correlate with human judgment of text quality, as a model with low perplexity might still produce incoherent or repetitive text if it learns to overfit on high-probability word sequences. Despite the utility of these automated metrics, human evaluation remains a crucial aspect of assessing generative models. Human evaluators can assess qualitative factors such as creativity, relevance, fluency, and coherence—areas where automated metrics often fall short. For instance, a human evaluator can judge whether the generated text is engaging or whether it captures the intended meaning, which cannot always be measured by BLEU or ROUGE. Human evaluation can be conducted through various methods, such as Likert-scale ratings on different aspects of the text (e.g., fluency, creativity) or through pairwise comparisons between different model outputs. However, human evaluation introduces challenges, such as subjectivity, bias, and variability between evaluators. Additionally, human evaluation is time-consuming and resource-intensive, making it impractical for evaluating large-scale models on massive datasets. As a result, a balanced evaluation framework often combines automated metrics with human evaluation, allowing models to be assessed both quantitatively and qualitatively. Designing an effective evaluation framework requires balancing quantitative metrics like BLEU and ROUGE with qualitative assessments like human evaluation. For instance, when evaluating a model trained for text summarization, an evaluator may use ROUGE to measure how well the generated summary captures the key points of the source text while also conducting a human evaluation to assess whether the summary is concise, coherent, and understandable. In Rust, implementing these evaluation frameworks involves creating tools that can compute automated metrics like BLEU, ROUGE, and perplexity, as well as designing interfaces for conducting human evaluations. The robustness of generative models is another crucial aspect of evaluation. Robustness testing involves assessing how well the model performs when presented with adversarial examples or noisy inputs. Adversarial examples, which are intentionally crafted inputs designed to confuse the model, can highlight weaknesses in a generative model's understanding of language or structure. For instance, a GPT model might be tested by altering key words in the input sentence or introducing irrelevant information to see whether the generated output remains coherent and contextually appropriate. This form of evaluation helps to ensure that the model is resilient to unexpected or adversarial inputs, making it more reliable in real-world applications. Adversarial training techniques can also be employed to improve the robustness of generative models. In this context, the model is exposed to adversarial inputs during training, which helps it learn to generate more reliable outputs in the face of noise or misleading information. This form of testing is particularly important for models deployed in sensitive domains, such as healthcare or legal settings, where generating incorrect or misleading text can have serious consequences. In Rust, robustness testing can be implemented by developing mechanisms to introduce controlled noise into the input data and evaluating the model's responses. This might involve adding adversarial tokens to input text or generating alternative forms of input sentences to test how the model adapts. Evaluating the model’s resilience to these adversarial conditions provides insight into how well it will perform in varied and unpredictable real-world settings. To demonstrate Rust’s capabilities in evaluating generative models with a focus on automated metrics like BLEU and ROUGE using the This Rust code demonstrates calculating BLEU and ROUGE-L scores, two common metrics for evaluating text generation quality. The Ethical considerations are central to the evaluation of generative models, particularly when it comes to fairness, bias, and responsible use. Because generative models are trained on vast datasets that often contain biased or harmful content, they may unintentionally propagate these biases in their outputs. For instance, GPT models trained on large internet-based datasets might reflect societal biases related to gender, race, or other sensitive topics. Therefore, part of the evaluation process must include fairness assessments, where the model’s outputs are scrutinized for bias and harmful content. This ethical evaluation can involve analyzing model outputs across different demographic groups to ensure that the model is not disproportionately biased against certain populations. Techniques like counterfactual fairness testing, where hypothetical scenarios are introduced to detect bias, are increasingly used to measure fairness in generative models. These evaluations ensure that the model does not generate outputs that perpetuate stereotypes or reflect unjust biases, especially in domains like automated content generation, hiring, or personalized recommendations. In terms of industry use cases, evaluating generative models plays a critical role in deploying them for real-world applications. For instance, in customer support, the quality and relevance of chatbot responses need to be evaluated rigorously to ensure that users receive accurate and helpful information. In creative fields like content generation and marketing, human evaluation is key to determining whether the generated text aligns with brand messaging and customer engagement strategies. Moreover, in legal and healthcare applications, robustness testing and fairness evaluation are essential to ensure that the models do not produce biased or harmful outputs, which could lead to legal or ethical issues. Recent trends in generative model evaluation include a growing focus on multi-modal evaluation, where generative models that produce text, images, or audio are assessed across different modalities. For instance, models like DALL·E, which generate images from text prompts, require evaluation frameworks that can assess the coherence between the input text and the generated image, blending text-based and image-based evaluation metrics. This shift toward multi-modal generative models will likely lead to the development of new evaluation methodologies that go beyond traditional text metrics and incorporate more comprehensive, multi-dimensional assessments. In conclusion, evaluating generative models involves a delicate balance between automated metrics and human judgment, as both provide complementary insights into the model’s performance. While metrics like BLEU, ROUGE, and perplexity offer a quantitative measure of the model’s accuracy and coherence, human evaluation captures more nuanced aspects like creativity and relevance. Rust’s ecosystem allows for the implementation of these evaluation metrics, enabling developers to assess generative models in a high-performance environment while integrating qualitative evaluations to better understand the capabilities and limitations of these models. Robustness testing and ethical evaluation are also crucial components, ensuring that generative models are reliable, fair, and suitable for real-world applications. Deploying large-scale generative models like GPT in production environments presents a set of unique challenges, particularly when considering the computational complexity and resource demands of these models. Models such as GPT-3, which can have hundreds of billions of parameters, require significant computational resources for both training and inference. When moving these models from research environments into real-time applications, such as chatbots or automated content generation systems, the need for optimization becomes critical. Ensuring scalability, low latency, and efficient resource utilization are key concerns, especially when deploying on platforms that handle high traffic or need to deliver near-instantaneous responses. One of the primary techniques used to optimize generative models for deployment is model quantization. Quantization involves reducing the precision of the model's weights and activations from the typical 32-bit floating point (FP32) format to lower precision formats such as 16-bit (FP16) or even 8-bit integers. The goal of quantization is to reduce the memory footprint and computational demands of the model without significantly impacting its performance. Mathematically, quantization can be understood as mapping high-precision values into a lower precision space: $$\hat{W} = Q(W),$$ where $W$ represents the original model weights, $Q$ is the quantization function, and $\hat{W}$ are the quantized weights. Quantization introduces small errors in the model’s calculations, but for many tasks, especially in natural language processing, these errors have minimal impact on overall model accuracy. The benefits, however, are significant in terms of reduced memory usage and faster inference, which are crucial for real-time applications. Another popular technique for optimizing large models is model distillation. In model distillation, a smaller "student" model is trained to mimic the behavior of a larger "teacher" model. The student model learns by minimizing the difference between its outputs and those of the teacher model, using a soft version of the standard cross-entropy loss: $$\mathcal{L}_{\text{distill}} = (1 - \alpha) \mathcal{L}_{\text{hard}} + \alpha \mathcal{L}_{\text{soft}},$$ where $\mathcal{L}_{\text{hard}}$ is the standard loss on the true labels, $\mathcal{L}_{\text{soft}}$ is the loss on the teacher model's soft predictions, and $\alpha$ controls the balance between the two. The distillation process effectively transfers the knowledge of the larger model into a smaller, more efficient model that retains much of the performance but with significantly reduced computational requirements. This makes distillation particularly useful in environments where inference speed and memory efficiency are critical, such as mobile applications or edge computing devices. In deployment scenarios, the trade-offs between model accuracy, speed, and resource consumption are essential considerations. In real-time applications like interactive chatbots or personalized recommendation systems, latency is a primary concern. Large models can introduce delays in generating responses, which negatively affects user experience. Optimizations such as pruning, where unnecessary neurons or layers are removed from the network, can help speed up inference. Pruning works by identifying weights that contribute little to the final output and setting them to zero, effectively reducing the size and complexity of the model without a significant loss in accuracy: $$\mathcal{W}_{\text{pruned}} = \{ w_i : |w_i| < \epsilon \},$$ where $w_i$ represents the weights in the model, and $\epsilon$ is a threshold below which weights are pruned. By sparsifying the model, the computation required for inference is reduced, resulting in faster response times and lower memory usage. Scalability is another key factor in deploying generative models. When a model is deployed at scale, such as serving thousands or millions of requests per day, it must be able to handle concurrent requests without bottlenecking the system. Distributed computing techniques, such as model parallelism and data parallelism, are often employed to spread the computational workload across multiple GPUs or machines. Model parallelism splits the model’s layers across multiple devices, allowing for large models to be trained or inferred across several machines, while data parallelism distributes the input data across devices, enabling faster processing by running computations in parallel. In Rust, implementing these optimization techniques involves using frameworks like The Rust code below demonstrates the practical application of model optimization techniques like quantization and pruning, essential for deploying large-scale generative models such as GPT in production environments. Using the The code first defines quantization and pruning functions: Hardware acceleration also plays a critical role in optimizing generative model deployments. Utilizing GPUs, TPUs, or even specialized hardware like FPGAs can drastically reduce the time required for inference, making it possible to deploy models in real-time systems. Rust’s performance benefits come into play here, as it allows developers to write low-level, efficient code that can interface directly with these hardware accelerators, ensuring that the models make the best possible use of the available resources. By taking advantage of Rust’s concurrency model, developers can implement systems that handle high-throughput requests efficiently, ensuring that the model scales gracefully in production. A key challenge in deploying generative models is managing the trade-off between accuracy and resource consumption. For example, quantizing a model from FP32 to INT8 may lead to faster inference times but can also result in a slight degradation in model accuracy. The extent to which accuracy is sacrificed depends on the application. In scenarios where small drops in accuracy are acceptable—such as in chatbot applications where naturalness in conversation is more important than perfect precision—quantization is a highly effective strategy. However, in tasks like medical diagnosis or legal document generation, where accuracy is paramount, more careful balancing of these trade-offs is required. Evaluating the performance of these optimized models in production-like environments requires rigorous testing to ensure that the model meets the necessary performance criteria, such as response time, throughput, and scalability. In Rust, developers can simulate production environments by deploying models on cloud infrastructure or on local clusters and monitoring key performance indicators (KPIs) such as latency, memory usage, and CPU/GPU utilization. Tools such as Prometheus and Grafana can be integrated with Rust-based systems to visualize these metrics in real-time, allowing developers to fine-tune the deployment for optimal performance. In industry, optimizing and deploying generative models at scale has become a focal point, particularly in applications that require both high accuracy and low latency. For example, companies deploying automated customer service agents powered by GPT models must ensure that the system can handle thousands of concurrent conversations with minimal delay. Similarly, in recommendation engines or personalized content generation, the system must be able to process user inputs and generate responses in near real-time, all while running on infrastructure that may be resource-constrained. The latest trends in deploying generative models include the increasing use of serverless architectures and edge computing. Serverless architectures allow models to be deployed without worrying about the underlying infrastructure, with cloud providers dynamically allocating resources based on demand. This is particularly useful for handling variable workloads where the demand for model inference can spike unexpectedly. Edge computing, on the other hand, involves deploying models closer to the end-user, such as on mobile devices or local servers, to reduce latency and bandwidth costs. Both approaches emphasize the need for lightweight, efficient models that can run in resource-constrained environments without compromising performance. In summary, the deployment and optimization of generative models like GPT involve navigating a range of challenges, from reducing model size and computational demands to ensuring that models can scale efficiently in production environments. Techniques like quantization, pruning, and model distillation play crucial roles in optimizing these models for real-time applications, and hardware acceleration and distributed computing further enhance performance. Rust provides a powerful platform for implementing these optimizations, offering both performance and concurrency advantages, which are essential for large-scale deployments. As the demand for generative models in production continues to grow, the ability to balance model performance with resource efficiency will be key to their success. In conclusion, Chapter 6 highlights the significant advancements in generative models, particularly through GPT and its variants. By understanding the architecture, training processes, and practical implementations, readers gain insights into how these models generate coherent and contextually relevant text. This chapter underscores the transformative impact of generative models in NLP and sets the stage for exploring further advancements and applications in the field. Each prompt is crafted to encourage a comprehensive understanding and hands-on experience with the nuances of generative models in the context of natural language processing and beyond. Explain the fundamental differences between generative and discriminative models. How do generative models like GPT differ in their approach to learning and generating data, and what are the implications for tasks such as text generation and summarization? Describe the architecture of the GPT model, focusing on its autoregressive nature. How does the autoregressive approach enable GPT to generate coherent sequences of text? Implement a basic GPT model in Rust and analyze how the model predicts the next word in a sequence. Discuss the importance of large-scale pre-training in the GPT architecture. How does pre-training on vast datasets enable GPT to perform well on various downstream tasks with minimal fine-tuning? Implement a small-scale pre-training process in Rust and evaluate its impact on the model's text generation capabilities. Compare the training objectives of GPT with those of other generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs). How do these objectives influence the model's ability to generate diverse and high-quality text? What are the key architectural differences between GPT, GPT-2, and GPT-3? Discuss how scaling the model size and training data impacts the capabilities and limitations of these models. Implement key architectural changes from GPT-2 or GPT-3 in Rust and evaluate their effects on a text generation task. Explore the concept of self-supervised learning in the context of GPT models. How does self-supervision enable GPT to learn rich language representations without explicit labels? Implement a self-supervised learning framework in Rust and demonstrate its application in training a GPT model. Discuss the role of tokenization in GPT models. How does the choice of tokenizer (e.g., Byte-Pair Encoding, WordPiece) affect the model's ability to handle different languages and dialects? Implement a custom tokenizer in Rust and evaluate its performance in a GPT model. Explain the concept of model fine-tuning in the context of GPT. How can pre-trained GPT models be fine-tuned for specific NLP tasks like sentiment analysis or dialogue generation? Implement a fine-tuning pipeline in Rust and compare the performance of a fine-tuned GPT model with a baseline model. What are the challenges of fine-tuning large-scale GPT models on domain-specific data? Discuss strategies for handling overfitting, data scarcity, and transfer learning in fine-tuning. Implement these strategies in Rust and analyze their impact on model performance. Explore the concept of zero-shot and few-shot learning in GPT models. How does GPT-3 achieve impressive performance on new tasks with minimal or no task-specific data? Implement a few-shot learning scenario in Rust and evaluate the model's ability to generalize to new tasks. Discuss the ethical implications of deploying large generative models like GPT-3. What are the risks associated with biased or harmful text generation, and how can these be mitigated in practice? Implement a bias detection and mitigation framework in Rust for evaluating generated text. Compare the output quality of GPT models with other generative techniques, such as VAEs and GANs. How do these models differ in terms of creativity, coherence, and diversity of generated content? Implement a simple VAE or GAN in Rust and compare its outputs with those of a GPT model. What are the key evaluation metrics for assessing the quality of text generated by GPT models? Discuss the trade-offs between automated metrics (e.g., BLEU, ROUGE) and human evaluation. Implement these evaluation metrics in Rust and use them to assess the performance of a GPT model. Explore advanced generative techniques beyond GPT, such as Diffusion Models. How do these models differ in their approach to generating data, and what are their strengths in comparison to autoregressive models? Implement a simple diffusion model in Rust and compare its outputs with GPT-generated text. Discuss the scalability challenges of deploying large-scale GPT models in production environments. How can techniques like model quantization, pruning, and distributed computing help manage these challenges? Implement these optimization techniques in Rust and evaluate their impact on model performance and resource usage. Explain the process of model distillation and its application in creating smaller, more efficient versions of GPT models. How does distillation preserve the performance of the original model while reducing computational requirements? Implement model distillation in Rust and compare the performance of the distilled model with the original GPT. What are the key considerations for deploying GPT models in real-time applications? Discuss the trade-offs between model accuracy, latency, and resource consumption. Implement a deployment pipeline in Rust for serving a GPT model in a real-time application and analyze its performance. Explore the concept of controlled text generation in GPT models. How can techniques like conditional sampling or attribute control be used to guide the model's output towards desired characteristics? Implement controlled text generation in Rust and evaluate its effectiveness in producing targeted content. Discuss the potential of transfer learning in extending the capabilities of GPT models to other domains, such as code generation or multimodal tasks. How can pre-trained language models be adapted to handle these new tasks? Implement a transfer learning scenario in Rust where GPT is fine-tuned for code generation or a multimodal task. Analyze the impact of scaling laws on the performance of GPT models. How do model size, dataset size, and computational resources interact to influence the effectiveness of generative models? Implement experiments in Rust to explore these scaling laws and derive insights for optimizing model performance. As you work through these exercises, you'll not only build a solid understanding of the theoretical principles but also gain hands-on experience in implementing, fine-tuning, and optimizing these powerful models for various applications. Objective: To understand the autoregressive nature of GPT models by implementing a basic version in Rust, generating coherent text sequences, and analyzing the predictions. Tasks: Implement a basic GPT model in Rust that leverages an autoregressive approach for text generation, focusing on how the model predicts the next word in a sequence. Train the model on a small text corpus, ensuring that it learns to generate coherent sentences by predicting subsequent tokens. Analyze the model’s performance by comparing its predictions with the ground truth and observing how well it captures language patterns. Experiment with different context window sizes and evaluate how the length of the input affects the coherence of the generated output. Deliverables: A Rust codebase that implements an autoregressive GPT model for text generation. A training report that includes insights into how the model’s predictions evolve over time and how context window size influences performance. Examples of generated text sequences, with analysis on how well the model captures syntactic and semantic coherence. Objective: To practice fine-tuning a pre-trained GPT model on a domain-specific dataset, improving its ability to generate context-relevant text for a specific task. Tasks: Load a pre-trained GPT model and fine-tune it on a domain-specific dataset (e.g., legal, medical, or technical documents). Implement the fine-tuning process in Rust, focusing on adapting the model’s parameters to the new dataset while avoiding overfitting. Evaluate the model’s performance by generating domain-specific text and comparing it with the original pre-trained model’s output. Experiment with various fine-tuning strategies, such as adjusting learning rates or freezing parts of the model, to optimize the fine-tuning process. Deliverables: A Rust codebase that fine-tunes a pre-trained GPT model on a domain-specific dataset. A performance report comparing the outputs of the fine-tuned model with the original model, highlighting improvements in text relevance and coherence. An analysis of the fine-tuning strategies implemented, with a discussion on the trade-offs between model adaptation and overfitting. Objective: To understand the impact of tokenization on GPT models by implementing a custom tokenizer and evaluating how it affects text generation and model performance. Tasks: Implement a custom tokenizer in Rust, using methods such as Byte-Pair Encoding (BPE) or WordPiece, to preprocess text for a GPT model. Integrate the tokenizer into a GPT model pipeline and evaluate how the choice of tokenization method affects the model’s ability to generate coherent text. Experiment with different tokenization strategies, such as varying the token vocabulary size, and analyze how tokenization impacts training time, memory usage, and model output quality. Compare the performance of your custom tokenizer with standard tokenizers to identify strengths and weaknesses. Deliverables: A Rust implementation of a custom tokenizer for GPT models. A detailed analysis of how different tokenization strategies impact model performance, including training time, memory consumption, and text generation quality. A comparison report showing the trade-offs between custom and standard tokenizers for various text generation tasks. Objective: To understand the process of model distillation by creating a smaller, more efficient version of a GPT model while preserving its performance. Tasks: Implement model distillation in Rust by training a smaller GPT model (the student model) to mimic the behavior of a larger pre-trained GPT model (the teacher model). Train the student model on the same dataset, using the teacher model’s outputs as soft targets to guide the learning process. Compare the performance of the distilled GPT model with the original larger model in terms of text generation quality and computational efficiency. Experiment with different model sizes for the student model and analyze how the size reduction affects performance and resource usage. Deliverables: A Rust implementation of the model distillation process for GPT models. A comparative analysis of the distilled model’s performance and resource efficiency versus the original model, including metrics like accuracy, speed, and memory consumption. A report discussing the trade-offs between model size and performance, with recommendations for optimal model distillation strategies. Objective: To explore techniques for guiding GPT models towards generating specific types of content, using controlled text generation approaches. Tasks: Implement controlled text generation in Rust by modifying a GPT model to condition its output based on specific attributes (e.g., sentiment, style, or topic). Experiment with conditional sampling techniques or attribute control mechanisms to steer the model’s generated text towards desired characteristics. Evaluate the effectiveness of these control techniques by generating text under different conditions and comparing it with unconstrained GPT outputs. Analyze the trade-offs between flexibility and control in the text generation process, and identify scenarios where controlled generation is most useful. Deliverables: A Rust codebase implementing controlled text generation in a GPT model, with support for attribute-based conditioning. A report evaluating the quality of the controlled text generation outputs, with examples demonstrating the effects of different attributes on generated text. An analysis discussing the benefits and challenges of controlled text generation, particularly in balancing creativity with precision in language generation tasks.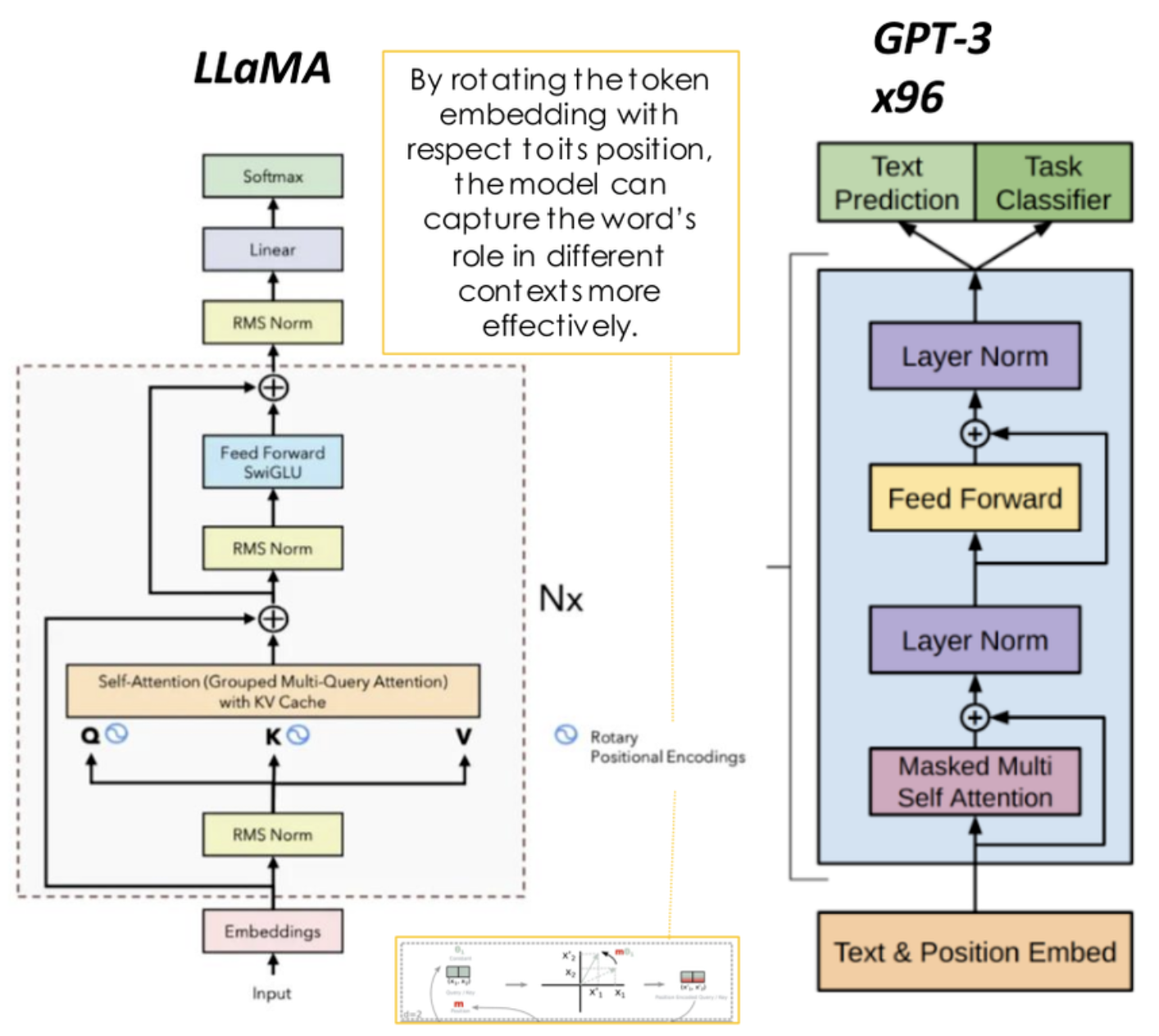
Llama model architecture is then defined, featuring an embedding layer, multiple RMS normalization blocks, and a linear layer to produce the final output logits.[dependencies]
anyhow = "1.0"
serde_json = "1.0.132"
tch = "0.12.0"
reqwest = { version = "0.12.8", features = ["blocking"] }
use anyhow::{bail, Context, Result};
use std::collections::{HashMap, HashSet};
use std::fs;
use std::io::Write;
use std::path::Path;
use reqwest::blocking::get;
use tch::nn::{self, Module};
use tch::{Device, Kind, Tensor};
// URL and path for the tokenizer file
const TOKENIZER_URL: &str = "https://huggingface.co/hf-internal-testing/llama-tokenizer/raw/main/tokenizer.json";
const TOKENIZER_PATH: &str = "llama-tokenizer.json";
pub struct Tokenizer {
encoder: HashMap<Vec<u8>, usize>,
decoder: HashMap<usize, String>,
bpe_ranks: HashMap<(Vec<u8>, Vec<u8>), usize>,
}
const DELIM: char = '▁';
const CONTEXT_SIZE: usize = 512;
const START_PROMPT: &str = r"
EDWARD:
I wonder how our princely father 'scaped,
Or whether he be 'scaped away or no...
";
impl Tokenizer {
pub fn from_file<P: AsRef<std::path::Path>>(path: P) -> Result<Self> {
let reader = std::io::BufReader::new(std::fs::File::open(path)?);
let config: serde_json::Value = serde_json::from_reader(reader)?;
let model = config.get("model").context("no model key")?;
let type_ = model.get("type").context("no model.type key")?.as_str().context("not a string")?;
if type_ != "BPE" {
bail!(format!("model type is not BPE: {type_}"))
}
let vocab = model.get("vocab").context("no model.vocab key")?.as_object().context("model.vocab not an object")?;
let single_chars: HashSet<u8> = vocab.iter().filter_map(|(key, _)| {
let b = key.as_bytes();
if b.len() == 1 { Some(b[0]) } else { None }
}).collect();
let encoder = vocab.iter().rev().map(|(key, value)| {
let key = key.strip_prefix("<0x").and_then(|s| s.strip_suffix('>'))
.and_then(|s| u8::from_str_radix(s, 16).ok())
.and_then(|s| if single_chars.contains(&s) { None } else { Some(s) })
.map_or_else(|| key.as_bytes().to_vec(), |s| vec![s]);
value.as_i64().context("not an int").map(|v| (key, v as usize))
}).collect::<Result<HashMap<_, _>>>()?;
let bpe_ranks = model.get("merges").context("no model.merges key")?
.as_array().context("model.merges not an array")?
.iter().enumerate().map(|(i, value)| {
let value = value.as_str().context("not a string")?;
match value.split_once(' ') {
Some((v1, v2)) => Ok(((v1.as_bytes().to_vec(), v2.as_bytes().to_vec()), i)),
None => bail!(format!("no space in merge '{value}'")),
}
}).collect::<Result<HashMap<_, _>>>()?;
let decoder = encoder.iter().map(|(k, v)| (*v, String::from_utf8_lossy(k).replace(DELIM, " "))).collect();
Ok(Self { encoder, decoder, bpe_ranks })
}
pub fn encode(&self, s: &str) -> Result<Vec<usize>> {
let mut buffer = [0u8; 4];
let s = format!("{DELIM}{}", s.replace(' ', DELIM.encode_utf8(&mut buffer)));
Ok(self.bpe(&s))
}
fn bpe(&self, s: &str) -> Vec<usize> {
let mut buffer = [0u8; 4];
let mut word: Vec<Vec<u8>> = vec![];
for c in s.chars() {
let buffer = c.encode_utf8(&mut buffer);
word.push(buffer.as_bytes().to_vec());
}
while word.len() > 1 {
let mut current_min = None;
let pairs = Self::get_pairs(&word);
for p in pairs.iter() {
if let Some(v) = self.bpe_ranks.get(p) {
let should_replace = match current_min {
None => true,
Some((current_min, _)) => v < current_min,
};
if should_replace { current_min = Some((v, p)) }
}
}
let (first, second) = match current_min { None => break, Some((_v, (first, second))) => (first, second) };
let mut new_word = vec![];
let mut index = 0;
while index < word.len() {
if index + 1 < word.len() && &word[index] == first && &word[index + 1] == second {
let mut merged = first.clone();
merged.extend_from_slice(second);
new_word.push(merged);
index += 2;
} else {
new_word.push(word[index].clone());
index += 1;
}
}
word = new_word;
}
word.iter().filter_map(|x| self.encoder.get(x)).copied().collect()
}
fn get_pairs(word: &[Vec<u8>]) -> HashSet<(Vec<u8>, Vec<u8>)> {
let mut pairs = HashSet::new();
for (i, v) in word.iter().enumerate() {
if i > 0 { pairs.insert((word[i - 1].clone(), v.clone())); }
}
pairs
}
pub fn decode(&self, tokens: &[usize]) -> String {
tokens
.iter()
.map(|&token| {
// Use the token if it exists in the decoder; otherwise, use a placeholder
self.decoder.get(&token).map_or("[UNKNOWN]", |s| s.as_str())
})
.collect::<Vec<&str>>()
.join(" ")
}
}
// Download function
fn download_tokenizer() -> Result<()> {
if !Path::new(TOKENIZER_PATH).exists() {
println!("Tokenizer file not found, downloading from Hugging Face...");
let response = get(TOKENIZER_URL).context("Failed to download tokenizer file")?;
if !response.status().is_success() {
bail!("Failed to download file: HTTP {}", response.status());
}
let mut file = fs::File::create(TOKENIZER_PATH).context("Failed to create tokenizer file")?;
file.write_all(&response.bytes().context("Failed to read response bytes")?)
.context("Failed to write tokenizer file")?;
println!("Tokenizer downloaded and saved to {}", TOKENIZER_PATH);
} else {
println!("Tokenizer file already exists, skipping download.");
}
Ok(())
}
// Model configuration and implementation
struct Config {
_block_size: usize,
vocab_size: usize,
n_layer: usize,
n_head: usize,
n_embd: usize,
}
impl Config {
fn config_7b() -> Self {
Self { _block_size: 4096, vocab_size: 32000, n_layer: 32, n_head: 32, n_embd: 4096 }
}
}
#[derive(Debug)]
struct RmsNorm {
scale: Tensor,
size: i64,
}
impl RmsNorm {
fn new(vs: &nn::Path, size: i64) -> Self {
let scale = vs.zeros("scale", &[size]);
Self { scale, size }
}
}
impl Module for RmsNorm {
fn forward(&self, xs: &Tensor) -> Tensor {
let norm_xs = (xs * xs).mean_dim(-1, true, Kind::Float);
let xs_normed = xs * (norm_xs + 1e-5).rsqrt();
let scale = self.scale.reshape([1, 1, self.size]);
scale * xs_normed
}
}
#[derive(Debug)]
struct Llama {
wte: nn::Embedding,
blocks: Vec<RmsNorm>,
lm_head: nn::Linear,
}
impl Llama {
fn new(vs: nn::Path, config: &Config) -> Self {
let c = nn::LinearConfig { bias: false, ..Default::default() };
let lm_head = nn::linear(&vs / "lm_head", config.n_embd as i64, config.vocab_size as i64, c);
let wte = nn::embedding(&vs / "transformer" / "wte", config.vocab_size as i64, config.n_embd as i64, Default::default());
let blocks = (0..config.n_layer).map(|i| RmsNorm::new(&(&vs / "transformer" / "h" / i), config.n_embd as i64)).collect();
Self { wte, blocks, lm_head }
}
fn forward(&self, x: &Tensor, _freqs_cis: &Tensor) -> Tensor {
let (_, t) = x.size2().unwrap();
let mut x = self.wte.forward(x);
for block in &self.blocks {
x = block.forward(&x);
}
self.lm_head.forward(&x.slice(1, t - 1, t, 1))
}
}
fn precompute_freqs_cis(config: &Config) -> Tensor {
let seq_len = CONTEXT_SIZE;
let n_elem = config.n_embd / config.n_head;
let theta: Vec<_> = (0..n_elem).step_by(2).map(|i| 1f32 / 10000f32.powf(i as f32 / n_elem as f32)).collect();
let arange: Vec<_> = (0..seq_len).map(|c| c as f32).collect();
let idx_theta = Tensor::of_slice(&arange).outer(&Tensor::of_slice(&theta));
let shape = [1, 1, seq_len as i64, n_elem as i64 / 2, 1];
let idx_theta_cos = idx_theta.cos().reshape(shape);
let idx_theta_sin = idx_theta.sin().reshape(shape);
Tensor::cat(&[&idx_theta_cos, &idx_theta_sin], -1)
}
fn main() -> Result<()> {
// Ensure the tokenizer file is downloaded
download_tokenizer()?;
// Load the tokenizer
let tokenizer = Tokenizer::from_file(TOKENIZER_PATH)?;
let mut tokens = tokenizer.encode(START_PROMPT)?;
let mut new_tokens = vec![];
let device = Device::Cpu; // Force to run on CPU
let vs = nn::VarStore::new(device);
let config = Config::config_7b();
let freqs_cis = precompute_freqs_cis(&config).to_device(device);
let llama = Llama::new(vs.root(), &config);
// Test the tokenizer
let sample_text = "Hello, how are you?";
let encoded = tokenizer.encode(sample_text)?;
let decoded = tokenizer.decode(&encoded);
println!("Encoded: {:?}\nDecoded: {}", encoded, decoded);
for index in 0..100 {
let ctxt: Vec<_> = tokens[tokens.len().saturating_sub(CONTEXT_SIZE)..]
.iter()
.map(|c| *c as i64)
.collect();
let ctxt = Tensor::of_slice(&ctxt).reshape([1, -1]);
let logits = llama.forward(&ctxt, &freqs_cis);
// Apply softmax to convert logits to probabilities
let probabilities = logits.softmax(-1, Kind::Float);
// Check probabilities sum
println!("Sum of probabilities: {:?}", probabilities.sum(Kind::Float));
let sampled_y = probabilities.get(0).get(0).multinomial(1, true);
let next_token = i64::try_from(&sampled_y)? as usize;
tokens.push(next_token);
new_tokens.push(next_token);
println!("{} token: {} '{}'", index + 1, next_token, tokenizer.decode(&[next_token]));
}
println!("End of generation!");
println!("----\n{}\n----", tokenizer.decode(&new_tokens));
Ok(())
}
6.7. Evaluating Generative Models
tch-rs crate, let's create a simple program that evaluates a generated text sequence using BLEU and ROUGE. We will compute these scores for model-generated text against reference text. Here’s a sample code demonstrating this in Rust:use std::collections::HashMap;
// BLEU metric calculation
fn calculate_bleu(reference: &str, generated: &str, n: usize) -> f64 {
let reference_ngrams = get_ngrams(reference, n);
let generated_ngrams = get_ngrams(generated, n);
let mut match_count = 0;
for (ngram, count) in generated_ngrams {
if let Some(ref_count) = reference_ngrams.get(&ngram) {
match_count += count.min(*ref_count);
}
}
let total_ngrams = generated.split_whitespace().count().saturating_sub(n - 1);
let precision = match_count as f64 / total_ngrams as f64;
let brevity_penalty = if generated.len() < reference.len() {
(generated.len() as f64 / reference.len() as f64).exp()
} else {
1.0
};
brevity_penalty * precision
}
// ROUGE-L metric calculation
fn calculate_rouge_l(reference: &str, generated: &str) -> f64 {
let ref_words: Vec<_> = reference.split_whitespace().collect();
let gen_words: Vec<_> = generated.split_whitespace().collect();
let lcs_length = longest_common_subsequence(&ref_words, &gen_words);
lcs_length as f64 / ref_words.len() as f64
}
// Helper functions
fn get_ngrams(text: &str, n: usize) -> HashMap<String, usize> {
let words: Vec<&str> = text.split_whitespace().collect();
let mut ngrams = HashMap::new();
for i in 0..=(words.len().saturating_sub(n)) {
let ngram = words[i..i + n].join(" ");
*ngrams.entry(ngram).or_insert(0) += 1;
}
ngrams
}
fn longest_common_subsequence(reference: &[&str], generated: &[&str]) -> usize {
let mut dp = vec![vec![0; generated.len() + 1]; reference.len() + 1];
for (i, &r) in reference.iter().enumerate() {
for (j, &g) in generated.iter().enumerate() {
if r == g {
dp[i + 1][j + 1] = dp[i][j] + 1;
} else {
dp[i + 1][j + 1] = dp[i + 1][j].max(dp[i][j + 1]);
}
}
}
dp[reference.len()][generated.len()]
}
// Sample main function to test BLEU and ROUGE calculations
fn main() {
let reference_text = "the cat sat on the mat";
let generated_text = "the cat is on the mat";
let bleu_score = calculate_bleu(reference_text, generated_text, 4);
println!("BLEU Score: {:.3}", bleu_score);
let rouge_l_score = calculate_rouge_l(reference_text, generated_text);
println!("ROUGE-L Score: {:.3}", rouge_l_score);
// In a real application, use tch to load and run your model and generate text
}
calculate_bleu function computes the BLEU score by comparing n-grams (subsequences of n words) from a generated text and a reference text to measure precision, adjusting with a brevity penalty to prevent favoring shorter generated texts. The calculate_rouge_l function calculates the ROUGE-L score by determining the longest common subsequence (LCS) between the generated and reference text, measuring the recall of overlapping structures. Supporting functions, get_ngrams and longest_common_subsequence, help generate n-grams and calculate the LCS, respectively. In main, sample texts are used to showcase these metric calculations, with scores displayed to quantify how well the generated text matches the reference. This setup could be expanded to evaluate generative models’ outputs, providing insights into their accuracy and coherence relative to human-written references.6.8. Deployment and Optimization of Generative Models
tch-rs, which provide Rust bindings for PyTorch, or utilizing specialized hardware acceleration libraries that interface with Rust. For example, model quantization can be implemented in Rust by converting the model's weights and activations to lower-precision formats during both training and inference. Similarly, pruning can be applied by analyzing the importance of weights and eliminating those that have minimal contribution to the model's predictions.tch-rs crate, it showcases how to reduce computational demands and improve inference speed by transforming a model's weights to more efficient formats. The example is designed to reflect the kind of optimizations required when scaling models for real-time applications, where resources and latency are critical.use tch::{nn, Device, Kind, Tensor};
/// Function to quantize a tensor by converting weights to 8-bit integers.
fn quantize_tensor(tensor: &Tensor) -> Tensor {
let scale = 127.0 / tensor.abs().max().double_value(&[]);
(tensor * scale).clamp(-127.0, 127.0).to_kind(Kind::Int8)
}
/// Function to prune tensor weights below a specified threshold.
fn prune_tensor(tensor: &Tensor, threshold: f64) -> Tensor {
tensor * tensor.gt(threshold).to_kind(tensor.kind())
}
struct LinearLayer {
ws: Tensor,
bs: Option<Tensor>, // Optional bias
quantized: bool,
pruned: bool,
}
impl LinearLayer {
fn new(vs: &nn::Path, in_features: i64, out_features: i64, quantized: bool, pruned: bool) -> Self {
// Initialize weights with mean 0.0 and standard deviation 1.0
let ws = vs.randn("ws", &[in_features, out_features], 0.0, 1.0);
let bs = Some(vs.zeros("bs", &[out_features]));
Self { ws, bs, quantized, pruned }
}
fn forward(&self, input: &Tensor) -> Tensor {
let mut weights = self.ws.shallow_clone();
// Apply quantization if enabled
if self.quantized {
weights = quantize_tensor(&weights).to_kind(Kind::Float);
}
// Apply pruning if enabled
if self.pruned {
weights = prune_tensor(&weights, 0.1); // Prune values below 0.1
}
// Perform the forward pass with optional bias
let output = input.matmul(&weights);
match &self.bs {
Some(bias) => output + bias,
None => output,
}
}
}
struct Model {
linear: LinearLayer,
}
impl Model {
fn new(vs: &nn::Path, in_features: i64, out_features: i64, quantized: bool, pruned: bool) -> Self {
let linear = LinearLayer::new(vs, in_features, out_features, quantized, pruned);
Self { linear }
}
fn forward(&self, input: &Tensor) -> Tensor {
self.linear.forward(input)
}
}
fn main() {
let device = Device::Cpu;
let vs = nn::VarStore::new(device);
let in_features = 4;
let out_features = 3;
// Initialize model with quantization and pruning enabled
let model = Model::new(&vs.root(), in_features, out_features, true, true);
// Random input tensor for testing
let input = Tensor::randn(&[1, in_features], (Kind::Float, device));
let output = model.forward(&input);
println!("Input Tensor: {:?}", input);
println!("Output Tensor: {:?}", output);
}
quantize_tensor scales weights to 8-bit integers, reducing memory requirements, while prune_tensor sets weights below a specified threshold to zero, minimizing unnecessary computations. A simple model with a linear layer is then instantiated, where the forward pass applies these optimizations based on provided flags. The forward function adjusts the layer’s weights with quantization and pruning before using them in matrix multiplication for the output. This approach ensures that only the necessary, high-value weights are retained, significantly reducing the model’s size and processing load, making it more suitable for deployment in resource-constrained or high-traffic environments.6.9. Conclusion
6.9.1. Further Learning with GenAI
6.9.2. Hands On Practices
Self-Exercise 6.1: Implementing Autoregressive Text Generation with GPT
Self-Exercise 6.2: Fine-Tuning GPT for Domain-Specific Text Generation
Self-Exercise 6.3: Implementing and Optimizing Tokenization for GPT Models
Self-Exercise 6.4: Implementing Model Distillation for GPT
Self-Exercise 6.5: Controlled Text Generation with GPT
Comments