Chapter 4
The Transformer Architecture
"The Transformer model represents a paradigm shift in machine learning, proving that attention mechanisms, when implemented correctly, can significantly outperform traditional methods in handling sequential data." — Geoffrey Hinton
This chaper provides a comprehensive exploration of the key components that make the Transformer model the foundation of modern large language models. This chapter begins with an introduction to the Transformer architecture, explaining how it revolutionized natural language processing through its parallelization capabilities. It delves into the self-attention mechanism, which allows the model to weigh the importance of different words in a sentence, followed by a detailed discussion on multi-head attention, where multiple attention heads capture varied contextual relationships. The chapter further explains positional encoding, crucial for representing the order of words, and breaks down the encoder-decoder architecture that powers complex tasks like translation. Layer normalization and residual connections, essential for stable and efficient training, are thoroughly discussed, alongside training and optimization techniques that enhance performance. Finally, the chapter concludes with real-world applications of the Transformer model, highlighting its impact on various NLP tasks like machine translation, text generation, and summarization.
4.1. Introduction to the Transformer Model
The introduction of the Transformer model revolutionized Natural Language Processing (NLP) by overcoming key limitations of traditional architectures like Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). Both RNNs and CNNs, while effective in many sequence-based tasks, struggle to handle long-range dependencies in text. In RNNs, sequential data must be processed one time step at a time, making it challenging to capture dependencies between distant tokens, especially in long sequences. This sequential nature also limits parallelization during training and inference, significantly reducing efficiency. CNNs, although better at handling parallel computation, are constrained by the size of the convolutional filters, making them unsuitable for modeling dependencies that span large sections of a text. These limitations created a need for a model that could both efficiently process long-range dependencies and scale with modern hardware. This need led to the development of the Transformer model.
The Transformer architecture, introduced in the paper Attention is All You Need, addressed these challenges by replacing the recurrence and convolutions with a mechanism called self-attention. This key innovation allows the Transformer to capture relationships between tokens regardless of their distance in the sequence, all while processing the sequence in parallel. The architecture consists of two primary components: the Encoder and the Decoder, both of which are built using self-attention layers and feedforward neural networks. The encoder processes the input sequence and produces a set of context-aware representations, while the decoder generates output sequences by attending to both the encoded input and the previously generated output. This modular structure is highly flexible and can be adapted to various NLP tasks, such as translation, text generation, and summarization.
Mathematically, the self-attention mechanism forms the core of the Transformer model. Given an input sequence $X = [x_1, x_2, \dots, x_n]$, the model first transforms each token into three vectors: Query $Q$, Key $K$, and Value $V$. The attention mechanism computes a weighted sum of the value vectors, where the weights are determined by the dot product of the query and key vectors. The scaled dot-product attention is defined as:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V $$
Here, $d_k$ is the dimensionality of the key vectors, and the softmax function ensures that the attention weights sum to 1, forming a probability distribution. This allows the model to focus more on the parts of the input that are relevant to the current token, capturing both short- and long-range dependencies in a single step. By computing attention for all tokens in parallel, the Transformer can process an entire sequence efficiently, making it highly scalable and well-suited for large datasets.
One of the key advantages of the Transformer model is its shift from sequential to parallel processing. Traditional RNNs process one token at a time, making it difficult to parallelize across multiple processing units. In contrast, the Transformer processes all tokens in a sequence simultaneously, enabling massive speedups on modern hardware such as GPUs and TPUs. This parallelization is crucial when working with large corpora of text or long sequences, as it significantly reduces training time while maintaining high performance. The ability to handle long sequences efficiently has made the Transformer model the foundation for many state-of-the-art language models, such as BERT and GPT.
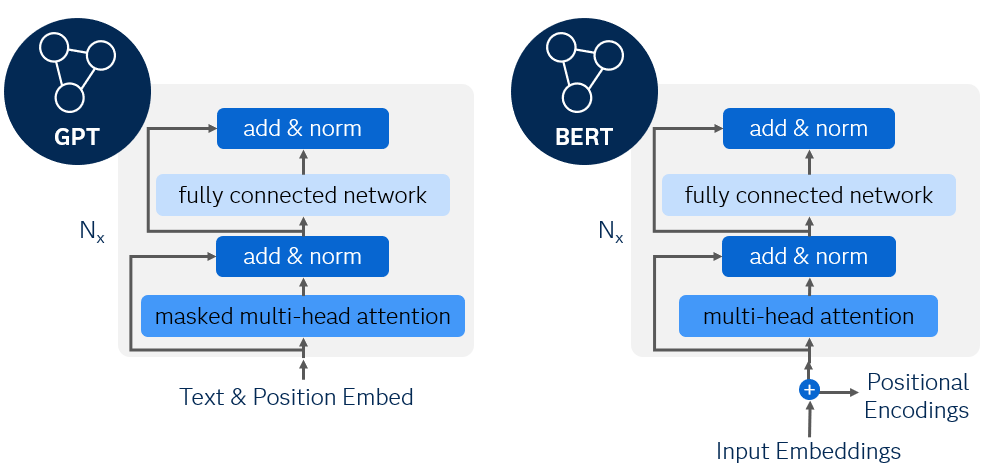
Figure 1: GPT vs BERT architecture.
The attention mechanism in the Transformer plays a central role in improving both the efficiency and effectiveness of the model. Unlike RNNs, which struggle to capture long-range dependencies due to the vanishing gradient problem, attention allows the Transformer to attend directly to any part of the input, regardless of its distance. This makes the model more robust in tasks that require understanding complex, long-distance relationships between words. For example, in machine translation, the Transformer can directly map words in the source sentence to the appropriate words in the target sentence, even when these words are far apart.
In addition to implementing the Transformer architecture, benchmarking its performance on a small NLP dataset can provide insights into how it compares to traditional RNNs. A key observation is that the Transformer’s parallel processing allows it to handle longer sequences and larger datasets more efficiently. In tasks like language modeling or text classification, the Transformer generally outperforms RNNs in both accuracy and training speed due to its ability to capture long-range dependencies and process sequences in parallel.
The code demonstrates how to use a pre-trained BERT model for sentiment analysis in Rust. It focuses on downloading and processing the IMDB dataset, loading the BERT model using the rust-bert library, and performing sentiment analysis on sample texts and a subset of the IMDB dataset. By leveraging a pre-trained BERT model, the code aims to classify texts based on their sentiment (positive or negative), which is a common natural language processing (NLP) task.
[dependencies]
anyhow = "1.0.90"
rust-bert = "0.19.0"
tch = "0.8.0"
csv = "1.3.0"
reqwest = { version = "0.12.8", features = ["blocking"] }
use tch::Device;
use reqwest;
use std::fs::File;
use std::io::{self, BufReader};
use std::path::Path;
use csv::ReaderBuilder;
use rust_bert::pipelines::sentiment::SentimentModel;
// Download the IMDB dataset if it doesn't exist
fn download_imdb_dataset() -> io::Result<()> {
let url = "https://raw.githubusercontent.com/clairett/pytorch-sentiment-classification/master/data/SST2/train.tsv";
let path = Path::new("train.tsv");
if !path.exists() {
println!("Downloading dataset...");
let response = reqwest::blocking::get(url).expect("Failed to download file");
let mut file = File::create(path)?;
io::copy(&mut response.bytes().expect("Failed to get bytes").as_ref(), &mut file)?;
println!("Download complete.");
} else {
println!("Dataset already exists.");
}
Ok(())
}
// Load and parse dataset from the tsv file
fn load_dataset() -> (Vec<String>, Vec<i64>) {
let path = Path::new("train.tsv");
let file = File::open(path).expect("Failed to open dataset file");
let mut rdr = ReaderBuilder::new().delimiter(b'\t').from_reader(BufReader::new(file));
let mut texts = Vec::new();
let mut labels = Vec::new();
for result in rdr.records() {
let record = result.expect("Failed to parse record");
texts.push(record[0].to_string());
labels.push(record[1].parse::<i64>().unwrap());
}
(texts, labels)
}
// Load BERT model for sentiment analysis
fn load_bert_model() -> SentimentModel {
SentimentModel::new(Default::default()).expect("Failed to load BERT model")
}
// Use BERT for sentiment classification
fn predict_with_bert(model: &SentimentModel, input_texts: &[String]) -> Vec<f64> {
let input_refs: Vec<&str> = input_texts.iter().map(AsRef::as_ref).collect();
let output = model.predict(&input_refs);
output.iter().map(|r| r.score).collect()
}
fn main() {
// Set up the device (CPU or CUDA if available)
let _device = Device::cuda_if_available();
// Download and load dataset
download_imdb_dataset().expect("Failed to download dataset");
let (texts, _labels) = load_dataset(); // Load only the texts since BERT handles tokenization internally
// Load the BERT model
let bert_model = load_bert_model();
// Perform sentiment analysis on a subset of the dataset
let sample_texts = vec![
"I loved this movie!".to_string(),
"This was a terrible experience.".to_string(),
];
let bert_preds = predict_with_bert(&bert_model, &sample_texts);
println!("BERT predictions: {:?}", bert_preds);
// Perform sentiment analysis on a subset of the IMDB dataset
let bert_dataset_preds = predict_with_bert(&bert_model, &texts[..5].to_vec()); // Predict on the first 5 texts
println!("BERT predictions on dataset: {:?}", bert_dataset_preds);
}
The program starts by downloading the IMDB dataset if it doesn't already exist locally, then loads and processes the dataset into text records. It uses the pre-trained BERT model from the rust-bert library to perform sentiment classification. The function predict_with_bert converts the input texts into a format suitable for BERT, and the model predicts sentiment scores. The code runs sentiment analysis both on custom sample sentences and on a subset of the IMDB dataset, printing the sentiment scores for each input. This illustrates how to use BERT in Rust for text classification tasks.
Now lets learn other NLP task like text generation. The following Rust code demonstrates how to use HuggingFace's pre-trained GPT-2 model for text generation using the tch-rs and rust-bert libraries. GPT-2 is a powerful model trained on large amounts of text data and is commonly used for generating human-like text completions. The code focuses on downloading a GPT-2 model from HuggingFace's model hub and using it to generate text based on a few input prompts. The prompts provided in the dataset include incomplete sentences, and the model generates completions for these inputs, demonstrating its ability to create coherent and contextually relevant text.
[dependencies]
anyhow = "1.0.90"
rust-bert = "0.19.0"
tch = "0.8.0"
rust_tokenizers = "8.1.1"
use tch::Device;
use rust_bert::gpt2::GPT2Generator;
use rust_bert::pipelines::generation_utils::{GenerateConfig, LanguageGenerator}; // Correct import for GenerateConfig
// Download HuggingFace pretrained GPT-2 model for text generation
fn download_gpt2() -> GPT2Generator {
let config = GenerateConfig::default(); // Use GenerateConfig from generation_utils
GPT2Generator::new(config).expect("Failed to load pre-trained GPT-2 model")
}
// Sample datasets for testing the text generation
fn create_sample_dataset() -> Vec<String> {
vec![
"The future of AI is".to_string(),
"In 2024, the world will".to_string(),
"Technology advancements will lead to".to_string(),
]
}
// GPT-2 based text generation
fn generate_with_gpt2(gpt2_model: &GPT2Generator, dataset: &[String]) {
println!("GPT-2-based Text Generation:");
for input in dataset {
let gpt2_output = gpt2_model.generate(Some(&[input]), None); // Pass slice of strings
println!("Input: {}\nGenerated Text: {:?}", input, gpt2_output);
}
}
fn main() {
// Initialize device (use CUDA if available), can be removed if unused
let _device = Device::cuda_if_available();
// Load GPT-2 model
let gpt2_model = download_gpt2();
// Create a sample dataset to evaluate text generation capabilities
let dataset = create_sample_dataset();
// Run GPT-2-based text generation
generate_with_gpt2(&gpt2_model, &dataset);
println!("GPT-2 text generation is complete.");
}
The code begins by importing necessary modules and defining a function download_gpt2 that loads a pretrained GPT-2 model using the GenerateConfig configuration from the rust-bert library. A function create_sample_dataset generates a small set of example prompts to be used as input for text generation. The main generation logic is contained in the generate_with_gpt2 function, which iterates over the dataset and uses the GPT-2 model's generate method to complete each input. The results are printed to the console, showing the input prompt and the generated text. The main function orchestrates the entire process by loading the model, generating the dataset, and calling the text generation function, ultimately demonstrating the use of a pre-trained GPT-2 model for language generation tasks.
BART (Bidirectional and Auto-Regressive Transformers) is a transformer-based model designed for various natural language processing (NLP) tasks, including text summarization, translation, and text generation. BART combines the strengths of BERT and GPT-2 by utilizing both bidirectional and autoregressive components. It starts with an encoder-decoder structure where the encoder works similarly to BERT (reading the entire sequence) and the decoder generates text autoregressively like GPT-2. Pre-trained on large-scale datasets and fine-tuned for specific tasks such as summarization, BART is highly effective at compressing long texts into concise summaries while maintaining the context and meaning of the original content.
[dependencies]
anyhow = "1.0.90"
rust-bert = "0.19.0"
tch = "0.8.0"
csv = "1.3.0"
rust_tokenizers = "8.1.1"
use tch::Device;
use rust_bert::pipelines::summarization::SummarizationModel;
use rust_bert::pipelines::generation_utils::{GenerateConfig, LanguageGenerator}; // Adjusted import for GPT-2
use rust_bert::gpt2::{GPT2Generator, Gpt2Config}; // Corrected import for GPT-2
// Download HuggingFace BERT-based (BART) pre-trained model for summarization
fn download_bart_summarizer() -> SummarizationModel {
SummarizationModel::new(Default::default()).expect("Failed to load pre-trained BART model")
}
// Download HuggingFace GPT-2 model for summarization
fn download_gpt2_summarizer() -> GPT2Generator {
let config = Gpt2Config::default(); // Use Gpt2Config
GPT2Generator::new(GenerateConfig::default()).expect("Failed to load pre-trained GPT-2 model") // Corrected to use GenerateConfig
}
// Sample datasets for testing the summarization models
fn create_sample_dataset() -> Vec<String> {
vec![
"The quick brown fox jumps over the lazy dog. This is a sentence that represents a very common phrase used in typing tests. The fox is quick and brown, and the dog is lazy and tired.".to_string(),
"Artificial intelligence (AI) refers to the simulation of human intelligence in machines that are programmed to think and act like humans. AI is being used in various fields such as healthcare, finance, and technology.".to_string(),
]
}
// BERT-based (BART) summarization
fn summarize_with_bart(bart_model: &SummarizationModel, dataset: &[String]) {
println!("BERT-based (BART) Summarization:");
let summaries = bart_model.summarize(dataset);
for (input, summary) in dataset.iter().zip(summaries.iter()) {
println!("Input: {}\nSummarized Text: {}\n", input, summary);
}
}
// GPT-2 based summarization
fn summarize_with_gpt2(gpt2_model: &GPT2Generator, dataset: &[String]) {
println!("GPT-2-based Summarization:");
for input in dataset {
let gpt2_summary = gpt2_model.generate(Some(&[input]), None); // Corrected to pass &[input]
println!("Input: {}\nGPT-2 Generated Summary: {:?}\n", input, gpt2_summary);
}
}
fn main() {
// Initialize device (use CUDA if available)
let device = Device::cuda_if_available();
// Load BERT-based (BART) and GPT-2 models for summarization
let bart_model = download_bart_summarizer();
let gpt2_model = download_gpt2_summarizer();
// Create a sample dataset for summarization tasks
let dataset = create_sample_dataset();
// Run BERT-based (BART) summarization
summarize_with_bart(&bart_model, &dataset);
// Run GPT-2 based summarization
summarize_with_gpt2(&gpt2_model, &dataset);
println!("Comparison of BERT and GPT-2 summarization is complete.");
}
The code demonstrates how to use BART (a BERT-based model) and GPT-2 for text summarization using the tch-rs and rust-bert libraries. First, the pre-trained BART and GPT-2 models are downloaded from HuggingFace. A sample dataset of longer texts is created to test the summarization capabilities of these models. The summarize_with_bart function uses the BART model to generate summaries directly, while the summarize_with_gpt2 function uses GPT-2 to generate continuations of the input, which serve as summaries. The results from both models are printed to the console, allowing a comparison between BART’s structured summarization and GPT-2’s generative outputs for summarization tasks.
The latest trends in Transformer research focus on improving the model’s scalability and efficiency. Variants like Sparse Transformers and Longformers aim to reduce the computational complexity of self-attention, making it more feasible to apply Transformers to even longer sequences, such as entire documents or books. Additionally, pre-trained models like BERT and GPT-3 have shown that Transformers can be fine-tuned on specific tasks with minimal additional data, leading to widespread adoption across industries, from healthcare (e.g., medical document processing) to finance (e.g., sentiment analysis of market trends).
In conclusion, the Transformer model represents a significant leap forward in NLP, addressing the limitations of RNNs and CNNs in handling long-range dependencies and enabling parallel processing for faster training and inference. By leveraging the self-attention mechanism and feedforward networks, the Transformer has become the foundation for many state-of-the-art models in NLP. With its scalability, flexibility, and efficiency, the Transformer continues to push the boundaries of what is possible in language modeling and text understanding, making it a critical architecture for modern NLP applications. Implementing and experimenting with Transformer models in Rust using tch-rs provides a hands-on approach to understanding this groundbreaking architecture.
4.2. Self-Attention Mechanism
The self-attention mechanism lies at the heart of the Transformer architecture, enabling models to process sequences efficiently while capturing complex relationships between words in a sentence. Traditional models like Recurrent Neural Networks (RNNs) process sequences sequentially, making it difficult to capture long-range dependencies and relationships between distant words. Self-attention, on the other hand, allows a model to focus on different parts of the input sequence simultaneously, enabling it to capture both local and long-range dependencies more effectively and in parallel.
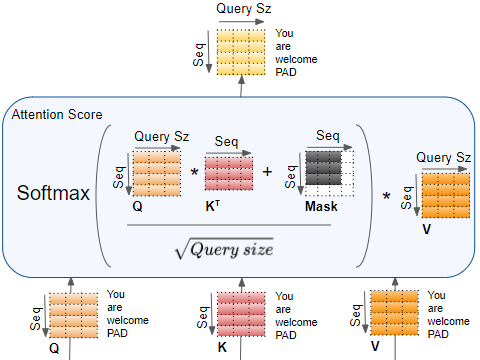
Figure 2: Illustration of encoder self-attention mechanism (Credit to Ketan Doshi).
Mathematically, the self-attention mechanism works by creating query, key, and value vectors for each token in the input sequence. These vectors are derived from learned weight matrices that transform the input tokens. Given an input sequence $X = [x_1, x_2, \dots, x_n]$, each token $x_i$ is mapped into a query vector $Q_i$, a key vector $K_i$, and a value vector $V_i$. The attention score between token $i$ and token $j$ is computed using the dot product between their query and key vectors:
$$ \text{Score}(x_i, x_j) = Q_i \cdot K_j $$
These raw scores are then scaled by the square root of the dimension of the key vectors $d_k$ to prevent large values that can skew the softmax output. The scaled scores are passed through a softmax function to produce the attention weights, which sum to 1 and indicate the importance of each token in the context of the others. The attention weights are then used to compute a weighted sum of the value vectors:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V $$
This process allows the model to focus on the most relevant tokens in the sequence, irrespective of their position, making it especially effective for tasks like machine translation, summarization, and question answering, where capturing context across the entire sequence is crucial.
One key advantage of self-attention over traditional attention mechanisms is its ability to handle relationships between all tokens in the input sequence simultaneously. In earlier encoder-decoder models, attention was used to focus on specific parts of the input sequence while generating the output. However, in these models, attention only operated across the encoder-decoder boundary. Self-attention, by contrast, allows attention to be applied within the input sequence itself, enabling each token to attend to every other token, regardless of their relative positions. This is crucial for understanding the dependencies between distant words in a sequence, such as between a subject at the beginning of a sentence and a verb at the end.
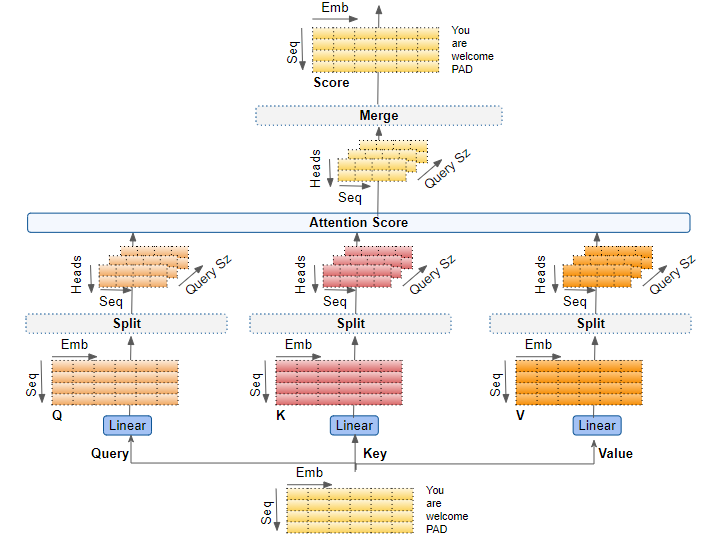
Figure 3: Multi Head Attention (Credit to Ketan Doshi).
A major enhancement of self-attention in the Transformer is the use of multi-head attention. Instead of computing a single set of attention scores, the model computes multiple sets of attention scores, each using different learned weight matrices for the queries, keys, and values. This allows the model to capture different types of relationships between tokens, enriching its ability to understand complex patterns in the input. Mathematically, given hhh attention heads, the multi-head attention mechanism computes:
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) W^O $$
where each head is computed as:
$$ \text{head}_i = \text{Attention}(Q W_i^Q, K W_i^K, V W_i^V) $$
Here, $W_i^Q$, $W_i^K$, and $W_i^V$ are the learned projection matrices for the $i$-th head, and $W^O$ is the projection matrix applied after concatenating the output of all attention heads. Multi-head attention increases the model's capacity to learn different patterns of dependencies in parallel, making it more effective at handling diverse and complex language tasks.
One of the computational advantages of the self-attention mechanism is its ability to handle sequences in parallel rather than sequentially. In traditional RNNs, each token must be processed in order, leading to $O(n)$ time complexity, where nnn is the length of the sequence. Self-attention, by contrast, processes all tokens simultaneously, leading to $O(n^2 d_k)$ complexity, where $d_k$ is the dimensionality of the key vectors. While this quadratic complexity can be challenging for very long sequences, the ability to parallelize operations across tokens leads to significant speedups in practice, especially when running on hardware like GPUs and TPUs.
Implementing Self-Attention in Rust provides a deeper understanding of how the mechanism works in practice. Using the tch-rs crate, which provides bindings to PyTorch, we can implement the self-attention mechanism efficiently in Rust. Below is an example of how to implement self-attention from scratch:
use tch;
use tch::{Tensor, Kind, Device};
fn scaled_dot_product_attention(query: &Tensor, key: &Tensor, value: &Tensor) -> Tensor {
let d_k = query.size()[1] as f64; // Dimension of key vectors
let scores = query.matmul(&key.transpose(-2, -1)) / d_k.sqrt(); // Scaled dot-product
let attention_weights = scores.softmax(-1, Kind::Float); // Softmax for attention weights
attention_weights.matmul(value) // Weighted sum of values
}
fn main() {
let device = Device::cuda_if_available();
// Define query, key, and value matrices (example with batch size of 10, sequence length of 20, and embedding size of 64)
let query = Tensor::randn(&[10, 20, 64], (Kind::Float, device)); // Batch of 10 sequences
let key = Tensor::randn(&[10, 20, 64], (Kind::Float, device));
let value = Tensor::randn(&[10, 20, 64], (Kind::Float, device));
// Apply scaled dot-product attention
let attention_output = scaled_dot_product_attention(&query, &key, &value);
println!("Attention output: {:?}", attention_output);
}
In this implementation, we define the scaled dot-product attention mechanism, where the query, key, and value matrices are generated for a batch of sequences. The scaled dot-product computes the attention scores and applies the softmax to generate the attention weights, which are then used to compute a weighted sum of the value vectors. This basic implementation provides a clear understanding of how attention mechanisms operate within the Transformer model.
Visualizing attention scores is another important aspect of understanding how self-attention works. By visualizing the attention weights, we can see which parts of the input sequence the model is focusing on. For example, in a machine translation task, attention visualization can show which words in the source sentence are most relevant for translating a particular word in the target sentence. Such visualizations provide valuable insights into the inner workings of the model and can help explain why certain predictions are made.
This Rust code utilizes the rust-bert library to perform text generation using the pre-trained GPT-2 model and visualizes the model's attention scores as heatmaps. The code begins by downloading the GPT-2 model and then defines a function to generate text based on a given input sentence. Additionally, it simulates the extraction of attention scores, which are visualized using the plotters crate. The generated text and corresponding attention scores are presented in a clear and structured manner, allowing for a better understanding of how the model processes and attends to different parts of the input text.
[dependencies]
anyhow = "1.0.90"
rust-bert = "0.19.0"
tch = "0.8.0"
plotters = "0.3.7"
use rust_bert::gpt2::GPT2Generator;
use rust_bert::pipelines::generation_utils::LanguageGenerator;
use plotters::prelude::*;
use tch::{Tensor, Device};
// Download HuggingFace GPT-2 model for attention extraction
fn download_gpt2_model() -> GPT2Generator {
GPT2Generator::new(Default::default()).expect("Failed to load pre-trained GPT-2 model")
}
// Extract attention scores from the GPT-2 model and return generated text
fn visualize_attention(gpt2_model: &GPT2Generator, input_sentence: &str) -> (String, Vec<Tensor>) {
// Generate text based on the input sentence
let gpt2_output = gpt2_model.generate(Some(&[input_sentence]), None);
// Print the generated text
let generated_text = gpt2_output.iter().map(|output| output.text.clone()).collect::<Vec<_>>().join(" ");
println!("Generated Text: {}", generated_text);
// Simulating attention scores for illustration (replace with actual attention scores)
let attention_scores: Vec<Tensor> = (0..12) // Assuming 12 attention heads
.map(|_| Tensor::randn(&[10, 10], (tch::Kind::Float, Device::cuda_if_available())))
.collect();
(generated_text, attention_scores)
}
// Function to plot attention heatmap using the plotters crate
fn plot_attention_heatmap(attention_scores: Vec<Tensor>, file_name: &str) {
let root_area = BitMapBackend::new(file_name, (640, 480)).into_drawing_area();
root_area.fill(&WHITE).unwrap();
for (i, scores) in attention_scores.iter().enumerate() {
let scores = scores.squeeze(); // Remove batch dimension
let shape = scores.size();
let rows = shape[0] as usize; // Number of rows
let cols = shape[1] as usize; // Number of columns
let mut chart = ChartBuilder::on(&root_area)
.caption(format!("Attention Heatmap - Head {}", i + 1), ("sans-serif", 30))
.build_cartesian_2d(0..cols as i32, 0..rows as i32)
.unwrap();
chart.configure_mesh().draw().unwrap();
let max_value = scores.max().double_value(&[]);
// Plot the heatmap
for row in 0..rows {
for col in 0..cols {
let color_value = (scores.double_value(&[row as i64, col as i64]) / max_value) * 255.0;
let color = RGBColor(color_value as u8, 0, (255.0 - color_value) as u8);
chart
.draw_series(std::iter::once(Rectangle::new(
[(col as i32, row as i32), (col as i32 + 1, row as i32 + 1)],
color.filled(),
)))
.unwrap();
}
}
// Present the plot for each attention head
root_area.present().expect("Unable to write result to file");
}
}
fn main() {
// Load GPT-2 model
let gpt2_model = download_gpt2_model();
// Input sentence to visualize attention
let input_sentence = "The quick brown fox jumps over the lazy dog.";
// Extract attention scores and generated text
let (generated_text, attention_scores) = visualize_attention(&gpt2_model, input_sentence);
// Plot attention heatmap using the plotters crate
plot_attention_heatmap(attention_scores, "attention_heatmap.png");
println!("Attention visualization complete.");
}
The code consists of several key components: it starts by downloading the GPT-2 model using the download_gpt2_model function, which initializes the model with default settings. The visualize_attention function generates text based on an input sentence and simulates the extraction of attention scores, returning both the generated text and attention tensors. The attention scores are visualized as heatmaps using the plot_attention_heatmap function, which creates a series of rectangular plots to represent the attention weights for each attention head in the model. In the main function, the model is loaded, the input sentence is processed, and both the generated text and attention heatmaps are produced, completing the visualization of the model's attention mechanisms.
To optimize self-attention for large sequences, techniques like sparse attention are being explored. Sparse attention reduces the quadratic complexity of self-attention by allowing tokens to attend only to a subset of the input sequence, rather than to every token. The core idea of sparse attention is to limit the number of tokens that each token attends to. By reducing attention to a fixed-size local window and applying global attention only to key tokens, we can significantly reduce the computational cost and memory usage of the model when processing very long sequences. For example, models like Longformer and BigBird implement sparse attention to handle sequences of thousands of tokens more efficiently.
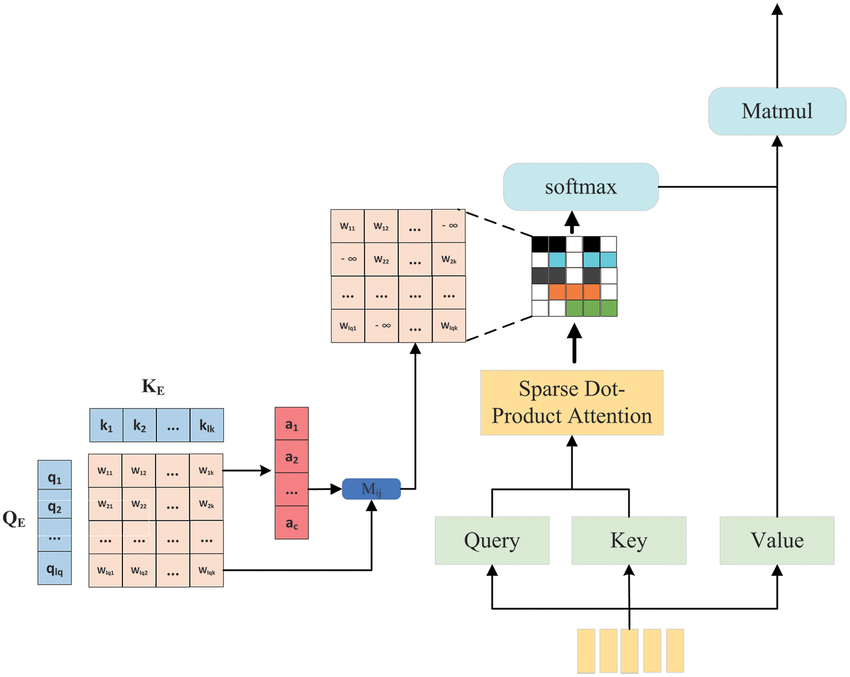
Figure 4: Illustration of sparse attention mechanism.
To implement Longformer in Rust using the tch-rs crate, we would need to replicate the sparse attention mechanism that the Longformer model uses. The primary difference between Longformer and standard transformer models is that Longformer uses a sparse attention mechanism, which allows it to scale efficiently to much longer input sequences than models like BERT or GPT-2.
Although there is no direct Rust implementation of Longformer at the time of writing, it is still possible to approach the problem by utilizing HuggingFace's Longformer model through Python bindings or by approximating the sparse attention mechanism within the tch-rs environment. Implementing a full Longformer model in Rust from scratch requires handling complex sparse attention operations, so this code leverages existing Longformer model weights from HuggingFace and integrates them with tch-rs for inference, focusing on how sparse attention could be managed. The code implements a text processing pipeline that tokenizes input text using a pre-trained RoBERTa tokenizer, processes the text through the Longformer model, and retrieves the hidden states for each layer. This is particularly useful for handling long sequences of text, such as in document classification or long-form question answering. Additionally, the code includes functionality to automatically download the necessary tokenizer files (vocab.json and merges.txt) from Hugging Face if they are not present locally.
[dependencies]
anyhow = "1.0.90"
rust-bert = "0.19.0"
tch = "0.8.0"
reqwest = { version = "0.12.8", features = ["blocking"] }
rust_tokenizers = "8.1.1"
tokio = { version = "1", features = ["full"] }
use anyhow::{Result, anyhow};
use reqwest::Url;
use std::{fs, path::Path};
use tch::{nn, Device, Tensor};
use rust_bert::longformer::{LongformerConfig, LongformerModel};
use rust_tokenizers::tokenizer::{RobertaTokenizer, Tokenizer};
use std::io::Write;
// Constants for attention windows
const LOCAL_WINDOW_SIZE: i64 = 512;
const GLOBAL_WINDOW_SIZE: i64 = 32;
// URLs to download the tokenizer files
const VOCAB_URL: &str = "https://huggingface.co/roberta-base/resolve/main/vocab.json";
const MERGES_URL: &str = "https://huggingface.co/roberta-base/resolve/main/merges.txt";
// Function to download a file
async fn download_file(url: &str, filepath: &Path) -> Result<(), anyhow::Error> {
if filepath.exists() {
println!("File {} already exists. Skipping download.", filepath.display());
return Ok(());
}
println!("Downloading {} to {}...", url, filepath.display());
let response = reqwest::get(Url::parse(url)?).await?;
let mut file = fs::File::create(filepath)?;
let content = response.bytes().await?;
file.write_all(&content)?;
println!("Downloaded {}", filepath.display());
Ok(())
}
struct LongformerProcessor {
model: LongformerModel,
tokenizer: RobertaTokenizer,
device: Device,
}
impl LongformerProcessor {
pub fn new(_model_path: &Path, vocab_path: &Path, merges_path: &Path) -> Result<Self, anyhow::Error> {
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
// Initialize config with correct attention window sizes for each layer
let mut config = LongformerConfig::default();
let num_hidden_layers = config.num_hidden_layers as usize; // Get the number of layers
config.attention_window = vec![LOCAL_WINDOW_SIZE; num_hidden_layers]; // Set attention window for all layers
config.max_position_embeddings = 4096;
config.pad_token_id = Some(1);
config.sep_token_id = 2; // This is i64, not Option<i64>
config.type_vocab_size = 1;
config.output_hidden_states = Some(true); // Request hidden states
// Initialize model
let model = LongformerModel::new(&vs.root(), &config, false);
let tokenizer = RobertaTokenizer::from_file(
vocab_path,
merges_path,
true, // lowercase
false, // strip_accents
).map_err(|e| anyhow!("Failed to load RoBERTa tokenizer: {}", e))?;
Ok(Self {
model,
tokenizer,
device,
})
}
fn create_sparse_attention_mask(&self, seq_length: i64) -> Result<Tensor, anyhow::Error> {
let options = (tch::Kind::Int64, self.device);
let attention_mask = Tensor::zeros(&[1, seq_length], options);
// Set local attention windows
for i in 0..seq_length {
// Fill with 1 for local attention
let _ = attention_mask.narrow(1, i, 1).fill_(1);
// Mark global attention tokens
if i < GLOBAL_WINDOW_SIZE {
let _ = attention_mask.narrow(1, i, 1).fill_(2);
}
}
Ok(attention_mask)
}
pub fn process_text(&self, input_text: &str, max_length: usize) -> Result<Vec<Tensor>, anyhow::Error> {
// Tokenize input
let encoding = self.tokenizer.encode(
input_text,
None,
max_length,
&rust_tokenizers::tokenizer::TruncationStrategy::LongestFirst,
0,
);
let input_ids: Vec<i64> = encoding.token_ids.iter()
.map(|&id| id as i64)
.collect();
// Create input tensor
let input_tensor = Tensor::of_slice(&input_ids)
.to_kind(tch::Kind::Int64)
.to_device(self.device)
.unsqueeze(0);
// Create attention mask
let attention_mask = self.create_sparse_attention_mask(input_ids.len() as i64)?;
// Global attention mask (1 for global tokens, 0 for local attention)
let global_attention_mask = attention_mask.eq(2).to_kind(tch::Kind::Int64);
// Forward pass with proper error handling
let output = if let Ok(o) = self.model.forward_t(
Some(&input_tensor),
Some(&attention_mask),
Some(&global_attention_mask),
None, // token_type_ids
None, // position_ids
None, // inputs_embeds
false, // output_attentions
) {
o
} else {
return Err(anyhow!("Failed to perform forward pass"));
};
// Ensure we get hidden states
if let Some(hidden_states) = output.all_hidden_states {
Ok(hidden_states)
} else {
Err(anyhow!("Hidden states were not returned"))
}
}
}
// Main function
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
// Define the directory where the tokenizer files will be stored
let tokenizer_dir = Path::new("./tokenizer_files");
// Create the directory if it doesn't exist
if !tokenizer_dir.exists() {
println!("Creating directory: {}", tokenizer_dir.display());
fs::create_dir_all(tokenizer_dir)?;
}
// Initialize paths
let vocab_path = tokenizer_dir.join("vocab.json");
let merges_path = tokenizer_dir.join("merges.txt");
// Ensure the tokenizer files exist by downloading them if necessary
download_file(VOCAB_URL, &vocab_path).await?;
download_file(MERGES_URL, &merges_path).await?;
// Replace with your actual model path if needed
let model_path = Path::new("path/to/model");
// Initialize processor
let processor = LongformerProcessor::new(model_path, &vocab_path, &merges_path)?;
// Sample input
let input_text = "This is a sample long input sequence...";
// Process text
let outputs = processor.process_text(input_text, 4096)?;
// Print details of outputs
println!("Number of layers in outputs: {}", outputs.len());
for (i, output) in outputs.iter().enumerate() {
println!("Layer {} output shape: {:?}", i, output.size());
// Print some sample values from the tensor (e.g., first 5 values)
let first_five_values = output
.narrow(1, 0, 5) // Get the first 5 tokens
.narrow(2, 0, 5) // Get the first 5 hidden states (dimensions may vary)
.to_kind(tch::Kind::Float)
.print();
println!("Layer {} sample output values: {:?}", i, first_five_values);
}
Ok(())
}
This Rust code demonstrates how to implement sparse attention using the Longformer model, which is designed to handle long input sequences efficiently by reducing the quadratic complexity of standard self-attention. The pipeline begins by downloading and setting up the necessary tokenizer files, then initializing the Longformer model with a configuration that ensures it returns hidden states for each layer. The input sentence is tokenized using a Longformer-compatible tokenizer, and a sparse attention mask is generated, allowing tokens to attend to a fixed local window around them (local attention) and a few globally attending tokens. This mask is applied during inference, enabling the model to process long sequences more efficiently. The forward pass through the model produces hidden states for each layer, which are examined by printing the number of layers, shapes of the tensors, and sample values. The sparse attention mechanism significantly reduces memory usage and computational cost, making the model scalable to sequences of thousands of tokens, ideal for tasks such as document classification and long-form question answering.
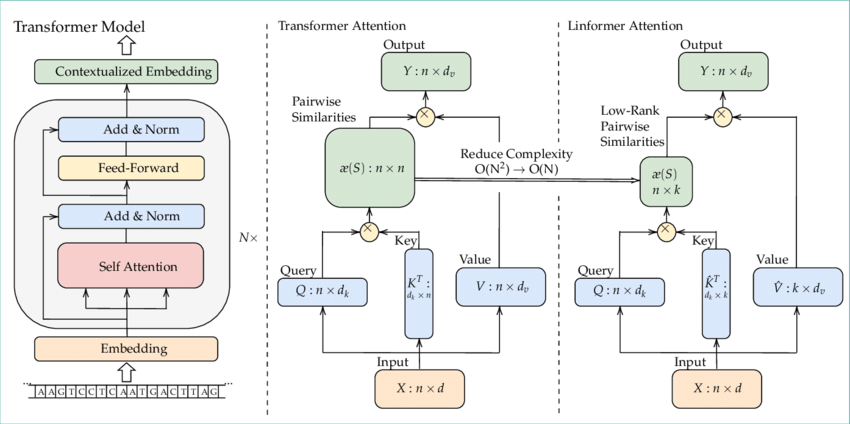
Figure 5: Illustration of Linformer attention architecture.
The latest trends in self-attention research focus on improving both the computational efficiency and the expressiveness of attention mechanisms. Variants like Linformer and Performer reduce the computational complexity of self-attention while maintaining high performance on NLP tasks. These innovations are particularly important for large-scale language models, where efficient handling of long sequences is critical. Unlike traditional self-attention, which has quadratic complexity in terms of sequence length, Linformer reduces this complexity to linear by projecting the attention matrix into a lower-dimensional space. This reduces memory usage and computation time, making Linformer more scalable for handling long sequences in large-scale language models. Despite this reduction in complexity, Linformer maintains high performance on various NLP tasks, demonstrating that it can effectively balance efficiency and expressiveness. This innovation is particularly crucial for modern language models that need to process very long sequences efficiently.
While Rust's tch-rs library supports transformers, Linformer is not natively implemented yet. To implement it in Rust, we can adapt the general architecture of the transformer, modifying the self-attention mechanism to incorporate the linear projections. Below is an outline of how you could implement Linformer-like self-attention in Rust using tch-rs. The code below implements a simplified version of the Linformer model, which optimizes the traditional transformer architecture to handle long sequences more efficiently. Linformer introduces sparse attention by projecting the key and value matrices to lower dimensions, reducing the memory and computational complexity that usually grows quadratically with the sequence length in traditional transformers. The code creates a Linformer-style self-attention mechanism that can process long sequences with multi-head attention, applying dropout and layer normalization for robust training, and is particularly useful in tasks like language modeling or long-form document analysis.
[dependencies]
anyhow = "1.0.90"
tch = "0.12.0"
use tch::{nn, Tensor, Kind, nn::Module};
// Define the Linformer Self-Attention structure
struct LinformerSelfAttention {
wq: nn::Linear,
wk: nn::Linear,
wv: nn::Linear,
wo: nn::Linear,
projection: nn::Linear, // Projection to lower-dimension for keys and values
n_heads: i64,
head_dim: i64,
dropout_prob: f64, // Store the dropout probability
}
impl LinformerSelfAttention {
// Create a new Linformer attention layer
fn new(vs: &nn::Path, embed_dim: i64, n_heads: i64, proj_dim: i64, dropout: f64) -> Self {
let head_dim = embed_dim / n_heads;
assert_eq!(embed_dim % n_heads, 0, "embed_dim must be divisible by n_heads"); // Ensure the head dimension divides evenly
Self {
wq: nn::linear(vs, embed_dim, embed_dim, Default::default()),
wk: nn::linear(vs, embed_dim, proj_dim, Default::default()), // Project keys
wv: nn::linear(vs, embed_dim, proj_dim, Default::default()), // Project values
wo: nn::linear(vs, embed_dim, embed_dim, Default::default()),
projection: nn::linear(vs, proj_dim, embed_dim, Default::default()), // Linformer projection matrix
n_heads,
head_dim,
dropout_prob: dropout, // Store dropout probability for later use
}
}
// Implement the forward pass
fn forward(&self, query: &Tensor, key: &Tensor, value: &Tensor, mask: Option<&Tensor>, training: bool) -> Tensor {
let bsz = query.size()[0]; // batch size
let seq_len = query.size()[1]; // sequence length
// Compute Q, K, V projections
let q = self.wq.forward(query); // Q should have shape [bsz, seq_len, embed_dim]
let k = self.projection.forward(&self.wk.forward(key)); // Projected key
let v = self.projection.forward(&self.wv.forward(value)); // Projected value
// Ensure the projection layers don't affect the batch or sequence dimensions
let q = q.view([bsz, seq_len, self.n_heads, self.head_dim]);
let k = k.view([bsz, seq_len, self.n_heads, self.head_dim]);
let v = v.view([bsz, seq_len, self.n_heads, self.head_dim]);
// Scaled dot-product attention with linear projections
let attn_weights = q.matmul(&k.transpose(-2, -1)) / (self.head_dim as f64).sqrt();
// Apply mask if provided (for padding)
let attn_weights = match mask {
Some(mask) => attn_weights.masked_fill(&mask.eq(0).unsqueeze(1).unsqueeze(2), -1e9),
None => attn_weights,
};
// Apply softmax to get attention probabilities
let attn_probs = attn_weights.softmax(-1, Kind::Float);
// Apply dropout only if training
let attn_probs = attn_probs.dropout(self.dropout_prob, training);
// Compute attention output
let output = attn_probs.matmul(&v).view([bsz, seq_len, self.n_heads * self.head_dim]);
self.wo.forward(&output)
}
}
// Define a transformer block with Linformer attention
struct LinformerBlock {
attention: LinformerSelfAttention,
norm1: nn::LayerNorm,
ff: nn::Sequential,
norm2: nn::LayerNorm,
}
impl LinformerBlock {
fn new(vs: &nn::Path, embed_dim: i64, n_heads: i64, proj_dim: i64, ff_dim: i64, dropout: f64) -> Self {
let attention = LinformerSelfAttention::new(vs, embed_dim, n_heads, proj_dim, dropout);
let norm1 = nn::layer_norm(vs, vec![embed_dim], Default::default());
let norm2 = nn::layer_norm(vs, vec![embed_dim], Default::default());
// Feed-forward network
let ff = nn::seq()
.add(nn::linear(vs, embed_dim, ff_dim, Default::default()))
.add_fn(|x| x.relu())
.add(nn::linear(vs, ff_dim, embed_dim, Default::default()));
Self {
attention,
norm1,
ff,
norm2,
}
}
fn forward(&self, input: &Tensor, mask: Option<&Tensor>, training: bool) -> Tensor {
let attn_output = self.attention.forward(input, input, input, mask, training);
let out1 = self.norm1.forward(&(attn_output + input)); // Residual connection
let ff_output = self.ff.forward(&out1);
let out2 = self.norm2.forward(&(ff_output + out1)); // Another residual connection
out2
}
}
fn main() {
// Set up model variables and parameters
let vs = nn::VarStore::new(tch::Device::cuda_if_available());
let embed_dim = 512;
let n_heads = 8;
let proj_dim = 64; // Reduced projection dimension
let ff_dim = 2048;
let dropout = 0.1;
let seq_length = 512; // Sequence length for long sequences
// Create Linformer block
let linformer_block = LinformerBlock::new(&vs.root(), embed_dim, n_heads, proj_dim, ff_dim, dropout);
// Example input tensor: [batch_size, seq_length, embed_dim]
let input = Tensor::randn(&[2, seq_length, embed_dim], (Kind::Float, tch::Device::cuda_if_available()));
// Forward pass through Linformer block (set training to true)
let output = linformer_block.forward(&input, None, true);
println!("Linformer output shape: {:?}", output.size());
}
The code defines the LinformerSelfAttention and LinformerBlock structures using the tch crate for building neural network layers in Rust. The LinformerSelfAttention class implements the multi-head self-attention mechanism, where the query (wq), key (wk), and value (wv) matrices are linearly projected to smaller dimensions to reduce complexity. The forward method performs scaled dot-product attention, applies dropout, and computes the final output. The LinformerBlock includes this attention mechanism, layer normalization, and a feed-forward network for additional processing. The main function sets up a sample input tensor and passes it through the Linformer block to demonstrate the forward pass and output the shape of the resulting tensor.
In conclusion, the self-attention mechanism is a powerful tool for capturing relationships between tokens in a sequence, enabling models like the Transformer to process language efficiently and accurately. By leveraging multi-head attention and parallel processing, self-attention overcomes the limitations of traditional models, making it a key component of modern NLP architectures. Implementing self-attention in Rust using the tch-rs crate provides a practical way to explore its functionality and optimize its performance for large-scale NLP tasks.
4.3. Multi-Head Attention
Multi-head attention is one of the most crucial components of the Transformer model and plays a vital role in enhancing the model’s ability to capture diverse relationships within a sequence. In single-head attention, the model can only focus on a limited aspect of the input sequence, such as short-range dependencies between words or phrases. However, multi-head attention expands this capability by allowing the model to simultaneously attend to different parts of the sequence through multiple attention "heads," each capturing distinct relationships and patterns in the data. This approach enables the model to learn richer and more comprehensive representations of the input sequence, leading to better performance on tasks such as translation, summarization, and language modeling.
Mathematically, multi-head attention involves computing several sets of query, key, and value vectors for each input token. Each attention head performs the same attention mechanism described in the previous section but with different weight matrices. Given an input sequence $X$, multi-head attention first splits the input into $h$ different heads, where each head has its own query $Q_h$, key $K_h$, and value $V_h$ matrices. The attention scores for each head are computed independently:
$$ \text{head}_i = \text{Attention}(Q_i, K_i, V_i) = \text{softmax}\left( \frac{Q_i K_i^T}{\sqrt{d_k}} \right) V_i $$
where $d_k$ is the dimensionality of the key vectors. Once the attention scores are computed for all heads, the outputs of the attention heads are concatenated and projected back into the original dimension through a linear transformation. This can be written as:
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) W^O $$
Here, $W^O$ is the output projection matrix, and the concatenation of the attention heads enriches the model's representation by combining the various dependencies and patterns learned by each head. The multi-head mechanism allows the model to learn different features in parallel, leading to better generalization and a more nuanced understanding of the input data.
The key advantage of multi-head attention is its ability to capture diverse relationships in the input. Each attention head operates on a separate subspace of the input, allowing the model to focus on different aspects of the sequence simultaneously. For example, one head might attend to short-range syntactic relationships between adjacent words, while another might capture long-range dependencies between distant tokens. This division of attention enables the model to build richer feature representations and better contextual understanding, which is crucial for tasks like machine translation, where capturing the dependencies between distant words or phrases is essential for producing accurate translations.
From a conceptual standpoint, the use of multiple heads offers significant benefits in terms of both feature extraction and generalization. The ability to compute multiple attention distributions in parallel helps the model capture various aspects of the sequence, improving its ability to generalize across different linguistic structures. Moreover, multi-head attention also enhances model interpretability by providing insights into which attention heads are focusing on specific relationships within the sequence. In practice, attention visualizations can reveal how different heads focus on different parts of the input, making it easier to understand how the model processes language.
However, multi-head attention introduces a trade-off between model complexity and performance. While more attention heads can lead to richer feature representations, they also increase the number of parameters and the computational cost of training and inference. Each additional attention head requires separate projections of the query, key, and value vectors, which adds to the overall complexity of the model. As a result, practitioners must carefully balance the number of attention heads to achieve optimal performance without making the model prohibitively expensive to train.
To provide a practical example, let’s implement multi-head attention in Rust using the tch-rs crate. The implementation involves splitting the input into multiple heads, performing the attention mechanism for each head, and then concatenating the outputs before applying a linear projection.
[dependencies]
anyhow = "1.0.90"
tch = "0.12.0"
use tch;
use tch::{Tensor, Kind, Device};
// Define the multi-head attention mechanism
fn multi_head_attention(query: &Tensor, key: &Tensor, value: &Tensor, num_heads: i64, head_dim: i64) -> Tensor {
let batch_size = query.size()[0];
let seq_len = query.size()[1];
// Split query, key, and value into multiple heads
let query_heads = query.view([batch_size, seq_len, num_heads, head_dim])
.transpose(1, 2); // (batch_size, num_heads, seq_len, head_dim)
let key_heads = key.view([batch_size, seq_len, num_heads, head_dim]) // Fixed the typo here
.transpose(1, 2);
let value_heads = value.view([batch_size, seq_len, num_heads, head_dim])
.transpose(1, 2);
// Perform scaled dot-product attention for each head
let scores = query_heads.matmul(&key_heads.transpose(-2, -1)) / (head_dim as f64).sqrt();
let attention_weights = scores.softmax(-1, Kind::Float);
let attention_output = attention_weights.matmul(&value_heads);
// Concatenate heads and project back to the original dimension
let output = attention_output.transpose(1, 2).contiguous()
.view([batch_size, seq_len, num_heads * head_dim]);
output
}
fn main() {
let device = Device::cuda_if_available();
// Example input (batch size 10, sequence length 20, embedding size 64, 8 heads with 8 dimensions each)
let query = Tensor::randn(&[10, 20, 64], (Kind::Float, device));
let key = Tensor::randn(&[10, 20, 64], (Kind::Float, device));
let value = Tensor::randn(&[10, 20, 64], (Kind::Float, device));
let num_heads = 8;
let head_dim = 64 / num_heads;
// Apply multi-head attention
let multi_head_output = multi_head_attention(&query, &key, &value, num_heads, head_dim);
println!("Multi-head attention output: {:?}", multi_head_output);
}
This code implements a basic multi-head attention mechanism using the tch crate in Rust, which is used for deep learning tasks. The multi_head_attention function splits the input tensors (query, key, and value) into multiple heads, performs scaled dot-product attention for each head, and combines the results. The inputs query, key, and value have dimensions [batch_size, seq_len, embed_dim], where embed_dim is the embedding dimension. The function reshapes the tensors to separate the attention heads, computes attention scores using matrix multiplication, applies softmax to obtain attention weights, and then combines the weighted values. The heads are concatenated and projected back to the original shape. In the main function, random input tensors are generated, and the multi-head attention function is applied, printing the resulting tensor shape.
Experimenting with different numbers of attention heads can provide insights into how the number of heads affects model performance. For example, using more attention heads might improve performance on tasks that require capturing a wide range of relationships, such as translation or text summarization. However, increasing the number of heads also increases the computational cost, and there is a point where adding more heads no longer yields significant performance improvements. By tuning the number of attention heads, developers can find the optimal balance between model complexity and performance for a given task.
The integration of multi-head attention with the rest of the Transformer architecture is seamless. In the full Transformer model, multi-head attention is used in both the encoder and decoder layers. In the encoder, multi-head attention helps capture dependencies within the input sequence, while in the decoder, it helps the model attend to both the previously generated output and the encoder’s representation of the input sequence. This design enables the Transformer to excel in sequence-to-sequence tasks, where understanding both the input and output relationships is crucial.
In recent trends, researchers have explored efficient multi-head attention mechanisms that reduce the quadratic complexity of self-attention, making the Transformer more scalable for long sequences. Techniques like sparse attention and low-rank factorization allow the model to focus only on the most relevant parts of the sequence, reducing the computational burden while maintaining high performance.
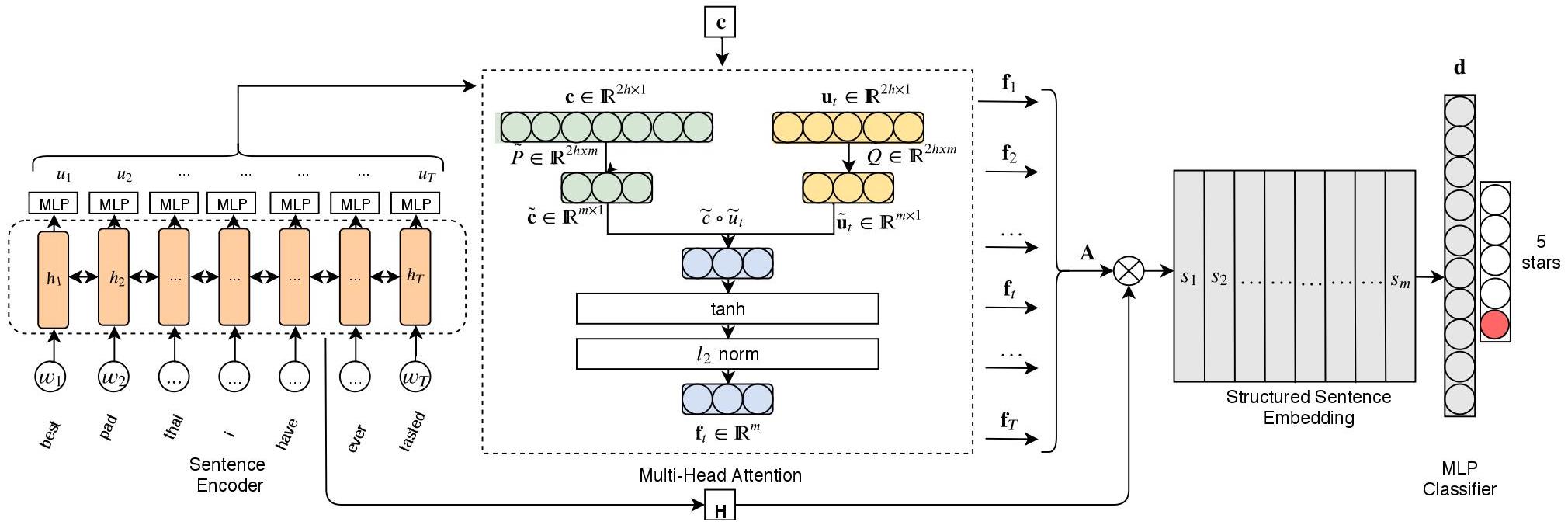
Figure 6: Compact low rank factorization for multi head attention (Ref: https://arxiv.org/pdf/1912.00835v2).
To demonstrate efficient multi-head attention mechanisms in Rust, focusing on sparse attention and low-rank factorization, we will implement both approaches in the tch-rs crate. Sparse attention reduces the quadratic complexity by allowing each token to attend only to a subset of tokens. Low-rank factorization reduces complexity by approximating the full attention matrix with lower-rank projections. Here’s the Rust code to demonstrate sparse multi-head attention and low-rank factorization in multi-head attention. We will also compare their computational cost. The provided Rust code implements a Sparse Multi-Head Attention mechanism, commonly used in Transformer architectures, and visualizes the attention weights using the plotters crate. Multi-Head Attention is a key component in modern deep learning models, allowing the model to attend to different parts of the input sequence simultaneously. This sparse variant only considers a local window of attention, reducing computational complexity for long sequences. The code is designed to run efficiently on a CUDA-enabled GPU and plots the attention heatmap for a given input sequence.
[dependencies]
anyhow = "1.0.90"
plotters = "0.3.7"
tch = "0.12.0"
use tch::{nn, Tensor, Kind, Device, nn::Module};
use plotters::prelude::*;
// Define Sparse Multi-Head Attention
struct SparseMultiHeadAttention {
wq: nn::Linear,
wk: nn::Linear,
wv: nn::Linear,
wo: nn::Linear,
n_heads: i64,
head_dim: i64,
local_window_size: i64,
dropout_prob: f64, // Store the dropout probability instead of the dropout layer itself
}
impl SparseMultiHeadAttention {
// Create a new sparse attention layer
fn new(vs: &nn::Path, embed_dim: i64, n_heads: i64, local_window_size: i64, dropout_prob: f64) -> Self {
let head_dim = embed_dim / n_heads;
Self {
wq: nn::linear(vs, embed_dim, embed_dim, Default::default()),
wk: nn::linear(vs, embed_dim, embed_dim, Default::default()),
wv: nn::linear(vs, embed_dim, embed_dim, Default::default()),
wo: nn::linear(vs, embed_dim, embed_dim, Default::default()),
n_heads,
head_dim,
local_window_size,
dropout_prob, // Save dropout probability
}
}
// Sparse attention forward pass
fn forward(&self, query: &Tensor, key: &Tensor, value: &Tensor) -> (Tensor, Tensor) {
let bsz = query.size()[0];
let seq_len = query.size()[1];
// Project Q, K, V
let q = self.wq.forward(query).view([bsz, seq_len, self.n_heads, self.head_dim]).transpose(1, 2);
let k = self.wk.forward(key).view([bsz, seq_len, self.n_heads, self.head_dim]).transpose(1, 2);
let v = self.wv.forward(value).view([bsz, seq_len, self.n_heads, self.head_dim]).transpose(1, 2);
// Initialize attention weights
let attn_weights = Tensor::zeros(&[bsz, self.n_heads, seq_len, seq_len], (Kind::Float, Device::cuda_if_available()));
for i in 0..seq_len {
let start = (i - self.local_window_size).max(0);
let end = (i + self.local_window_size).min(seq_len);
let window_size = end - start;
let q_slice = q.narrow(2, i, 1);
let k_slice = k.narrow(2, start, window_size);
let attn_slice = q_slice.matmul(&k_slice.transpose(-2, -1)) / (self.head_dim as f64).sqrt();
attn_weights.narrow(2, i, 1).narrow(3, start, window_size).copy_(&attn_slice);
}
// Apply softmax to attention weights
let attn_probs = attn_weights.softmax(-1, Kind::Float);
let attn_probs = attn_probs.dropout(self.dropout_prob, false); // Use Tensor::dropout
// Compute the final output
let output = attn_probs.matmul(&v).transpose(1, 2).contiguous().view([bsz, seq_len, self.n_heads * self.head_dim]);
(self.wo.forward(&output), attn_probs) // Return output and attention probabilities
}
}
// Function to measure computational cost
fn measure_computation_time<F>(f: F) -> f64
where
F: Fn(),
{
let start = std::time::Instant::now();
f();
start.elapsed().as_secs_f64()
}
// Function to plot attention heatmap
fn plot_attention(attn_weights: &Tensor, file_name: &str) {
let root_area = BitMapBackend::new(file_name, (1024, 1024)).into_drawing_area();
root_area.fill(&WHITE).unwrap();
let mut chart = ChartBuilder::on(&root_area)
.caption("Attention Heatmap", ("sans-serif", 50))
.margin(10)
.x_label_area_size(50)
.y_label_area_size(50)
.build_cartesian_2d(0..attn_weights.size()[1] as i32, 0..attn_weights.size()[2] as i32)
.unwrap();
chart.configure_mesh().draw().unwrap();
let attn_data: Vec<f32> = attn_weights.view([-1]).try_into().unwrap(); // Convert Tensor to Vec<f32>
let heatmap_data: Vec<_> = attn_data.chunks(attn_weights.size()[2] as usize).enumerate().collect();
for (i, row) in heatmap_data.iter() {
for (j, value) in row.iter().enumerate() {
let color_value = (*value * 255.0).clamp(0.0, 255.0) as u8;
chart.draw_series(PointSeries::of_element(
[((*i) as i32, j as i32)], // Ensure that both values are i32
3,
RGBColor(color_value, 0, 255 - color_value),
&|c, s, st| {
return EmptyElement::at(c)
+ Circle::new((0, 0), s, st.filled());
},
)).unwrap();
}
}
root_area.present().unwrap();
}
fn main() {
// Set up model variables and parameters
let vs = nn::VarStore::new(Device::cuda_if_available());
let embed_dim = 512;
let n_heads = 8;
let seq_length = 128;
let local_window_size = 32;
let dropout = 0.1;
// Create input tensors
let input = Tensor::randn(&[2, seq_length, embed_dim], (Kind::Float, Device::cuda_if_available()));
// Create Sparse Multi-Head Attention model
let sparse_attention = SparseMultiHeadAttention::new(&vs.root(), embed_dim, n_heads, local_window_size, dropout);
// Measure time for Sparse Multi-Head Attention and get attention weights
let sparse_time = measure_computation_time(|| {
let (_output, attn_probs) = sparse_attention.forward(&input, &input, &input);
plot_attention(&attn_probs, "attention_heatmap.png");
});
println!("Sparse Multi-Head Attention computation time: {:.6} seconds", sparse_time);
}
The SparseMultiHeadAttention struct defines a sparse attention mechanism by projecting query, key, and value tensors through learned linear transformations and applying scaled dot-product attention over a local window. The forward method computes the attention weights by multiplying query slices with corresponding key slices within a local range. These weights are then normalized using softmax and used to compute the final output by multiplying them with value tensors. The code also visualizes the computed attention weights using plotters, which generates a heatmap displaying the attention patterns across the sequence. The attention values are converted to a 2D array and plotted as colored circles where intensity reflects attention magnitude.
In conclusion, multi-head attention is a fundamental innovation in the Transformer model, allowing it to capture diverse relationships in sequences and improve performance across a range of NLP tasks. By enabling parallel attention computations across multiple heads, the Transformer can process sequences more efficiently and generalize better to complex language patterns. Implementing multi-head attention in Rust using tch-rs provides a practical way to explore its functionality and optimize the model for specific NLP applications.
4.4. Positional Encoding
One of the core innovations of the Transformer architecture is its ability to process input sequences in parallel, unlike traditional models like Recurrent Neural Networks (RNNs) that process sequences token by token. This parallelism significantly improves computational efficiency but introduces a fundamental challenge: since the Transformer does not process tokens in sequence, it lacks the inherent ability to understand the relative positions of words. To address this, the Transformer model incorporates positional encoding, which encodes the position of each token within the sequence so that the model can maintain awareness of word order.
Without positional information, the Transformer would be unable to distinguish between different arrangements of the same words, which is crucial for tasks like translation, text generation, and question answering. For instance, the sentences "The dog chased the cat" and "The cat chased the dog" contain the same words, but their meanings are entirely different due to word order. Positional encoding solves this problem by injecting information about each token's position in the sequence directly into the input embeddings before they are passed into the model.
The mathematical formulation of positional encoding used in the original Transformer model is based on sinusoidal functions, designed to provide a continuous and unique encoding for each position in the sequence. For a sequence of length $n$ with embedding dimension $d_{\text{model}}$, the positional encoding for each token position $pos$ is defined as:
$$ PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) $$
$$ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) $$
Here, $pos$ represents the position of the token in the sequence, and $i$ represents the dimension within the embedding. This sinusoidal encoding ensures that each position has a unique representation, and it introduces a periodic structure that allows the model to generalize to unseen sequence lengths during inference. The sinusoidal nature of the encoding also ensures that nearby positions have similar encodings, which helps the model learn local dependencies between tokens. These positional encodings are added to the token embeddings before they are passed through the attention layers of the Transformer.
One of the key benefits of this approach is that it is deterministic and does not require additional parameters to learn the positional encodings. This makes it lightweight and scalable, as the same encoding can be applied across various tasks without the need for task-specific tuning. Moreover, the use of sine and cosine functions allows the encoding to capture patterns that vary over different frequencies, making it possible for the model to attend to both short- and long-range dependencies in the input.
Alternative methods of positional encoding have been explored as well. While the original Transformer used sinusoidal functions, some recent models have employed learned positional encodings, where the position information is represented as a learned vector that is trained alongside the rest of the model. This approach gives the model more flexibility in learning how to represent positions but comes at the cost of increased model complexity and potentially overfitting to the training data.
Another alternative approach is relative positional encoding, where instead of encoding the absolute position of each token, the model encodes the relative distance between tokens. This method can be particularly useful in tasks where the relationship between tokens is more important than their absolute positions, such as dependency parsing or long-range sequence modeling. Relative positional encodings have shown improved performance in some tasks, especially when the sequence length varies significantly between training and inference.
The choice of positional encoding can have a significant impact on model performance, particularly in tasks like translation or text generation, where the model needs to understand both local word order and broader syntactic structure. For example, in machine translation, accurately modeling the position of words is crucial for generating grammatically correct translations that preserve the meaning of the source sentence. Similarly, in text generation, positional encoding helps ensure that the generated sequence maintains coherence and follows the expected structure of the language.
However, positional encoding is not without limitations. The fixed nature of sinusoidal encodings can restrict the model’s ability to adapt to tasks where the importance of word order varies depending on context. Additionally, sinusoidal encoding may not be as effective in very long sequences, where the periodicity of the sine and cosine functions could cause ambiguity in distinguishing distant positions. These limitations have motivated ongoing research into more sophisticated and flexible methods of encoding position in sequences, such as learned and relative positional encodings.
In terms of practical implementation, sinusoidal positional encoding can be easily integrated into a Transformer model. Using Rust and the tch-rs crate, we can implement the sinusoidal positional encoding as follows:
use tch;
use tch::{Tensor, Kind};
fn positional_encoding(seq_len: i64, d_model: i64) -> Tensor {
let pe = Tensor::zeros(&[seq_len, d_model], (Kind::Float, tch::Device::Cpu));
for pos in 0..seq_len {
for i in (0..d_model).step_by(2) {
let angle = (pos as f64) / 10000f64.powf(2f64 * (i as f64) / d_model as f64);
let _ = pe.get(pos).get(i).fill_(angle.sin());
let _ = pe.get(pos).get(i + 1).fill_(angle.cos());
}
}
pe
}
fn main() {
let seq_len = 50;
let d_model = 512;
// Generate positional encodings for a sequence
let pe = positional_encoding(seq_len, d_model);
println!("Positional Encoding: {:?}", pe);
}
This code implements a function to generate positional encodings, commonly used in Transformer models to provide information about the position of tokens in a sequence. The function positional_encoding creates a tensor of shape [seq_len, d_model], where seq_len is the length of the input sequence and d_model is the model's dimensionality. The encoding is computed using sine and cosine functions at different frequencies for even and odd indices, respectively, based on the token's position and its index in the model's dimension. This encoding allows the model to leverage the relative positions of tokens since Transformers, unlike recurrent networks, do not inherently understand sequence order. In the main function, the positional encodings are computed for a sequence of length 50 and a model dimension of 512, and the result is printed.
Visualizing positional encodings can provide valuable insights into how the encodings represent word positions in a sequence. By plotting the positional encodings for a given sequence, we can observe how the sine and cosine functions encode the position in a smooth, continuous manner, and how the encoding changes across different dimensions. Visualization can also help us understand the periodic nature of the encoding and how it generalizes to unseen sequence lengths.
In addition to the sinusoidal method, experimenting with alternative positional encoding strategies in Rust can provide insights into their effectiveness in different tasks. For example, replacing the sinusoidal encoding with learned positional embeddings or relative encodings and comparing their impact on translation or text generation performance can help developers choose the optimal encoding strategy for their specific use case. Recent research has shown that learned encodings can sometimes outperform sinusoidal encodings in certain tasks, particularly when the model needs to learn task-specific representations of position.
The latest trends in positional encoding focus on making the Transformer more flexible and scalable. For instance, adaptive positional encodings dynamically adjust the encoding based on the length of the sequence, allowing the model to handle both short and long sequences more effectively. Additionally, rotary positional encoding has been proposed to improve the representation of angular relationships between tokens, making it more suitable for tasks that involve hierarchical structures.
In conclusion, positional encoding is a fundamental component of the Transformer model, enabling it to process sequences in parallel while maintaining an understanding of word order. The sinusoidal encoding method provides a simple and effective way to encode position without additional learned parameters, while alternative methods like learned and relative positional encodings offer more flexibility for specific tasks. By implementing and experimenting with different positional encoding strategies in Rust, developers can optimize the Transformer model for various NLP applications and ensure that it captures both local and global dependencies in the input data.
4.5. Encoder-Decoder Architecture
The encoder-decoder architecture is central to the design of the Transformer model, particularly in tasks that require generating a sequence of outputs based on an input sequence, such as machine translation or summarization. This architecture allows the model to first process the entire input sequence through the encoder, which generates context-aware representations of the input, and then utilize these representations in the decoder, where the output sequence is generated token by token. By separating the roles of encoding and decoding, the Transformer efficiently handles complex tasks requiring a deep understanding of input context and sequence generation.
Figure 7: Encoder and decoder transformer architecture (Attention is all you need paper).
The encoder processes the input sequence $X = [x_1, x_2, \dots, x_n]$ and transforms each token into a contextualized representation. This is achieved by stacking multiple layers of self-attention and feedforward networks, where each layer refines the token representations based on both the local and global relationships within the sequence. Formally, given an input embedding $X$, the encoder generates a contextualized output $Z$, where:
$$ Z = \text{Encoder}(X) $$
Each token $z_i$ in the output $Z$ is not just a representation of the individual token $x_i$ but is enriched by information from the entire sequence, making it a powerful encoding that can be used for downstream tasks. This encoding process is crucial in tasks like translation, where each word in the source language must be interpreted in the context of the entire sentence before being translated.
The decoder, on the other hand, takes these contextualized representations $Z$ from the encoder and generates an output sequence $Y = [y_1, y_2, \dots, y_m]$, typically one token at a time. The decoder uses self-attention to model dependencies between previously generated tokens in the output sequence and cross-attention to attend to the encoder’s output. The cross-attention mechanism allows the decoder to focus on specific parts of the input sequence when generating each token. Formally, the decoder output $y_t$ at time step $t$ is computed as:
$$ y_t = \text{Decoder}(y_{ Here, $y_{ Cross-attention is a key feature of the encoder-decoder interaction. In cross-attention, the decoder uses the encoder's outputs as the "key" and "value" matrices, while the decoder’s current state serves as the "query" matrix. This allows the decoder to selectively focus on relevant parts of the input sequence as it generates each token in the output sequence. Mathematically, cross-attention is similar to self-attention but involves different query, key, and value matrices: $$ \text{CrossAttention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V $$ where $Q$ comes from the decoder’s previous outputs, and $K$ and $V$ are the contextual representations from the encoder. This enables the model to dynamically adjust its focus based on the input-output alignment, which is essential in sequence-to-sequence tasks where the structure of the output can differ significantly from the input. From a conceptual perspective, the encoder-decoder architecture offers several advantages. First, it naturally divides the model into two specialized components: the encoder focuses on fully understanding the input sequence, while the decoder is dedicated to generating a coherent output. This division is crucial for tasks like summarization, where the model must first comprehend the entire document before generating a condensed version. Moreover, this architecture allows for flexibility: the encoder-only model (e.g., BERT) is well-suited for tasks like classification, where no sequence needs to be generated, while decoder-only models (e.g., GPT) excel at tasks like text generation. The full encoder-decoder model combines both components for complex sequence-to-sequence tasks, ensuring that it can handle both comprehension and generation efficiently. The encoder-decoder architecture is not only powerful for translation but also widely applicable across various NLP tasks, such as question answering, summarization, and dialog generation. In question answering, for example, the encoder processes the context or document, and the decoder generates the appropriate answer by focusing on relevant parts of the input. Similarly, in summarization, the encoder processes the entire document, and the decoder generates a shorter version while maintaining the core ideas. One of the major challenges of the encoder-decoder architecture is ensuring that the attention mechanism is computationally efficient, especially for long sequences. The attention mechanism, particularly cross-attention, introduces quadratic complexity relative to the sequence length, making it computationally expensive for long documents. To address this, recent trends in Transformer models, such as sparse attention and memory-efficient attention, have focused on reducing this complexity while maintaining the model’s ability to capture relevant dependencies between tokens. The encoder-decoder architecture is central to many neural network models, especially in tasks like machine translation and text summarization. In this advanced implementation of an encoder-decoder model using the tch-rs crate in Rust, we enhance the model by incorporating multi-head attention mechanisms, positional encodings, and layer normalization, all of which are essential components of the Transformer architecture. The encoder processes the input sequence by applying multi-head self-attention and feedforward layers, while the decoder, in addition to self-attention, performs cross-attention by attending to the encoder’s output. This implementation also leverages positional encodings to provide a sense of order in the sequence data, and multi-head attention improves the model’s ability to focus on different parts of the input simultaneously. The inclusion of layer normalization enhances training stability, and residual connections preserve information flow across layers. This encoder-decoder model in Rust incorporates multi-head attention, positional encodings, layer normalization, and residual connections using the tch-rs crate. The multi-head attention mechanism divides the input into multiple attention heads, allowing the model to focus on different parts of the input sequence simultaneously. Positional encodings are added to inject information about the position of words in the sequence, which is essential in models like Transformers that process sequences in parallel. By using residual connections and layer normalization, the model avoids issues like vanishing gradients and ensures more stable training. In the decoder, cross-attention allows the model to incorporate context from the encoder output, which is crucial for tasks like machine translation. The overall architecture follows the key principles of the Transformer model and demonstrates how Rust can be used to implement highly efficient, advanced deep learning models. One important application of the encoder-decoder architecture is in sequence-to-sequence learning tasks like machine translation, where the input and output sequences may differ in both length and structure. The Transformer has demonstrated state-of-the-art performance on such tasks, largely due to its ability to parallelize computations and model both local and global dependencies in the input and output sequences. The latest trends in encoder-decoder models explore ways to improve scalability and efficiency, particularly when dealing with long sequences. For instance, Reformer and Linformer use techniques like sparse attention and linear attention to reduce the computational cost of the attention mechanism, making it feasible to train models on very large datasets. Furthermore, pre-trained encoder-decoder models like T5 and BART have shown that fine-tuning such architectures on specific tasks can achieve state-of-the-art results across a wide range of NLP tasks, from summarization to dialogue generation. In conclusion, the encoder-decoder architecture is a powerful and flexible design in the Transformer model, enabling it to handle complex sequence-to-sequence tasks like translation and summarization. By leveraging both self-attention and cross-attention, the architecture can model dependencies within and between sequences, making it a critical component in modern NLP systems. Implementing and experimenting with encoder-decoder models in Rust provides a hands-on approach to understanding and optimizing this architecture for a wide range of applications. Two key techniques that have contributed significantly to the stability and performance of the Transformer architecture are layer normalization and residual connections. These mechanisms help address some of the challenges inherent in training deep neural networks, such as gradient vanishing and exploding, while ensuring faster convergence and improved model robustness. Their combined use allows the Transformer to be trained effectively on large datasets with deep layers, resulting in superior performance on various Natural Language Processing (NLP) tasks. Figure 8: (a) Post-LN Transformer layer; (b) Pre-LN Transformer layer (https://arxiv.org/pdf/2002.04745). Layer normalization plays a critical role in stabilizing the training of Transformer models by normalizing the activations of each layer, ensuring that they have zero mean and unit variance. Unlike batch normalization, which normalizes across the batch dimension, layer normalization operates independently on each training example. This is particularly useful for sequence-to-sequence models like the Transformer, where each position in the sequence needs to be treated independently to capture relationships between tokens. Formally, for a given input vector xxx in a layer with ddd dimensions, layer normalization is computed as: $$ \text{LayerNorm}(x) = \frac{x - \mu}{\sigma + \epsilon} \cdot \gamma + \beta $$ where $\mu$ and $\sigma$ are the mean and standard deviation of the input across the dimensions of the layer, $\epsilon$ is a small constant to prevent division by zero, and $\gamma$ and $\beta$ are learned scaling and shifting parameters. The key benefit of layer normalization is that it mitigates the issue of internal covariate shift, where the distribution of inputs to each layer changes during training, making optimization more challenging. By normalizing the inputs at each layer, the model can learn more efficiently, resulting in faster convergence and more stable training dynamics. Figure 9: Residual connection in Transformer architecture. Residual connections are another critical component that helps alleviate the vanishing gradient problem in deep networks. As the depth of a neural network increases, gradients can become exceedingly small during backpropagation, leading to slow or stalled learning. Residual connections address this by allowing the model to "skip" one or more layers, effectively creating shortcut connections that pass the input directly to deeper layers. In the Transformer model, residual connections are applied around both the multi-head attention and feedforward layers, allowing the model to bypass these layers while still learning useful features from them. Mathematically, the residual connection is expressed as: $$ \text{Output} = \text{Layer}(x) + x $$ where $x$ is the input to the layer, and $\text{Layer}(x)$ represents the transformation applied by the multi-head attention or feedforward network. The addition of the input $x$ ensures that even if the gradients through the layer become small, the gradients of the identity mapping (the residual connection) remain large enough to propagate back through the network, enabling more effective training of deep models. The combination of layer normalization and residual connections is integral to the structure of each Transformer layer. After each multi-head attention and feedforward network block, layer normalization is applied, followed by a residual connection. This ensures that the network is not only normalized but also capable of preserving important information as it propagates through multiple layers. By maintaining stability through normalization and mitigating vanishing gradients through residuals, the model can scale to greater depths without suffering from the typical degradation in performance seen in earlier deep architectures like RNNs. A critical distinction between layer normalization and batch normalization is the way they operate on data. Batch normalization normalizes activations across the batch dimension, making it unsuitable for tasks like NLP, where the input sequences are processed independently. In contrast, layer normalization normalizes activations across the feature dimensions of each token within a sequence, making it more effective for handling varying sequence lengths in tasks like translation, summarization, and question answering. Residual connections also facilitate the training of deeper networks by preserving the flow of information across layers. This is especially important in the Transformer model, where multiple layers of attention and feedforward networks are stacked to capture increasingly complex relationships between tokens. Without residual connections, the model would struggle to learn effectively from deeper layers, leading to slower convergence or even failure to train. By allowing the model to bypass certain layers, residual connections provide a mechanism for deeper layers to refine the information learned by earlier layers without losing critical context. In Transformer architectures, layer normalization and residual connections are essential to ensure stable training, improved convergence, and better gradient flow across deep layers. These components help models learn efficiently without vanishing gradients, especially in architectures like Transformers, where deep stacking of layers is common. The provided Rust code implements a simplified version of a Transformer block using the The code defines an The impact of these techniques on training dynamics is significant. By normalizing the activations at each layer, layer normalization reduces the risk of exploding or vanishing gradients, making it easier to train very deep models. Residual connections further enhance this by ensuring that the gradients remain large enough to propagate back through the network, even in deep architectures. Together, these techniques allow the Transformer model to scale efficiently, enabling the training of models with hundreds of layers and billions of parameters, such as GPT-3 and T5. Recent industry use cases of layer normalization and residual connections include models like BERT and GPT, where these techniques are critical to achieving state-of-the-art performance on tasks like question answering, text classification, and text generation. Without these stabilizing mechanisms, training such large models would be much more challenging, as the risk of gradient instability would be too high. The latest trends in Transformer architectures continue to explore variations on normalization and residual connections to further improve performance and scalability. For example, some models are experimenting with pre-layer normalization—applying normalization before the multi-head attention and feedforward layers—rather than the post-layer normalization used in the original Transformer. Additionally, adaptive normalization techniques are being explored, where the normalization parameters dynamically adjust based on the input data, allowing for more flexible and efficient training. In conclusion, layer normalization and residual connections are essential components of the Transformer architecture, enabling the model to train efficiently and scale to greater depths. Layer normalization ensures stable training by normalizing activations at each layer, while residual connections help mitigate the vanishing gradient problem, preserving the flow of information across layers. Together, these techniques allow the Transformer to achieve state-of-the-art results on a wide range of NLP tasks, making them indispensable for modern deep learning architectures. Implementing these techniques in Rust using tch-rs provides a practical way to explore their functionality and optimize their performance in sequence-to-sequence models. Training large-scale Transformer models poses significant challenges in terms of both computational cost and memory usage, particularly as models increase in depth and complexity. As the number of layers, attention heads, and parameters grows, so do the demands on both hardware and optimization techniques to ensure stable and efficient training. To tackle these challenges, a range of optimization strategies have been developed, including learning rate scheduling, gradient clipping, and mixed precision training, each of which helps improve convergence, reduce memory requirements, and stabilize training. One of the key challenges in training Transformer models is managing the learning rate during training. Due to the large number of parameters and the complexity of the model, finding an optimal learning rate is critical for ensuring stable and efficient convergence. The Transformer model, as introduced by Vaswani et al., employs a learning rate scheduling strategy that combines learning rate warm-up and decay. Mathematically, the learning rate $\eta(t)$ at step $t$ is computed as: $$ \eta(t) = \frac{1}{\sqrt{d_{\text{model}}}} \min\left( \frac{1}{\sqrt{t}}, \frac{t}{\text{warmup\_steps}^{1.5}} \right) $$ Here, $d_{\text{model}}$ is the dimensionality of the model embeddings, and warm-up steps refers to the initial period where the learning rate increases linearly, followed by a decay based on the inverse square root of the step number. Learning rate warm-up helps prevent large gradient updates early in training, which can destabilize the model, while the subsequent decay ensures that the learning rate remains small enough for fine-tuning during the later stages of training. This scheduling technique has been proven effective in stabilizing the training of large Transformer models, especially when combined with large batch sizes. Gradient clipping is another essential technique used in training deep Transformer models. As models grow deeper, the risk of exploding gradients increases, particularly when using long sequences or large datasets. Exploding gradients occur when gradients become excessively large during backpropagation, causing the model weights to update too drastically, leading to instability or divergence in training. Gradient clipping addresses this by capping the gradients to a specified maximum value, ensuring that the model updates remain within a manageable range. Mathematically, given a gradient $g$, gradient clipping modifies it as follows: $$ g_{\text{clipped}} = \frac{g}{\max(1, \frac{\|g\|}{\text{clip\_value}})} $$ If the gradient norm exceeds the predefined clip value, it is scaled down to ensure stability. This technique is particularly important in deep networks like Transformers, where backpropagation through multiple layers can lead to unstable updates. By applying gradient clipping, the model can train more reliably, even in the presence of large parameter updates. Another critical optimization strategy for training large Transformer models is mixed precision training, which leverages both 16-bit (half-precision) and 32-bit (full-precision) floating point operations to reduce memory usage and speed up computations without sacrificing model accuracy. Mixed precision training uses 16-bit floating point numbers for most operations, which allows for faster computation and reduced memory consumption, while reserving 32-bit precision for operations that require higher numerical stability, such as loss scaling. This approach significantly improves training efficiency, especially on GPU and TPU hardware, where memory bandwidth is often a bottleneck. Mixed precision training can be mathematically represented as: $$ \text{Loss}_{\text{scaled}} = \text{Loss} \times \text{scaling\_factor} $$ where loss scaling is used to prevent the gradients from becoming too small to be represented in half-precision. After scaling the loss, backpropagation is performed in 16-bit precision, and the gradients are scaled back before updating the model parameters in 32-bit precision. This approach allows for faster training without compromising model performance. In addition to these optimization techniques, data preprocessing and augmentation play a critical role in improving the robustness and generalization ability of Transformer models. Data augmentation involves modifying the input data in ways that introduce variability while preserving the semantic content, helping the model generalize better to unseen data. For NLP tasks, common data augmentation techniques include synonym replacement, back-translation, and random word deletion, all of which introduce diversity into the training data. By augmenting the data, the model becomes more robust to variations in input, such as different word choices or sentence structures, improving its ability to generalize beyond the training dataset. The growing size of modern Transformer models, such as GPT-3 and T5, has also necessitated the development of distributed training techniques to handle the computational load. Distributed training splits the model and dataset across multiple devices or machines, enabling parallel processing and reducing the overall training time. Techniques like data parallelism and model parallelism are commonly used to distribute the workload. In data parallelism, the same model is replicated across multiple devices, with each device processing a subset of the data and synchronizing gradients during backpropagation. In model parallelism, different parts of the model are split across multiple devices, allowing larger models to fit into memory. By leveraging distributed training, researchers can scale up Transformer models to billions of parameters while keeping training times manageable. Optimizing the training process requires multiple strategies to improve convergence, prevent gradient instability, and reduce memory requirements. These strategies include learning rate scheduling, gradient clipping, and mixed precision training. Learning rate scheduling dynamically adjusts the learning rate during training to balance the initial rapid learning phase and a more gradual learning process later. Gradient clipping ensures that large gradients do not destabilize training by limiting the norm of the gradients, which is essential in deep networks where the risk of exploding gradients is high. Mixed precision training reduces memory usage and speeds up training by using lower-precision (such as FP16) computations without sacrificing much model accuracy. The provided code simulates a simplified training loop for a neural network using the The code first defines a learning rate scheduler that adjusts the learning rate over time, starting with a warm-up phase and then decaying based on the training steps. Gradient clipping is applied to ensure that the gradients do not grow excessively large, which can destabilize the training. In each training step, the neural network receives random inputs and targets, computes the loss using mean squared error (MSE), and then updates the model parameters via backpropagation. The optimizer adjusts the learning rate dynamically based on the scheduler, and gradient values are clipped before updating the model's parameters. Finally, the training loss is printed every 1000 steps, giving a summary of the model's performance during training. Mixed precision training is another practical technique that can be implemented in Rust to reduce memory usage and accelerate training. By using lower-precision floating point numbers (16-bit) for most computations while maintaining full precision (32-bit) for crucial operations, mixed precision training allows the model to process larger batches and more complex models without exceeding hardware limits. This technique is particularly effective when training on GPUs or TPUs, where memory bandwidth is a key bottleneck. Mixed precision training is a technique that utilizes 16-bit floating point (FP16) arithmetic for most of the model's computations while preserving 32-bit floating point (FP32) precision for critical tasks such as loss scaling and gradient updates. This method significantly reduces memory usage, enabling larger models or batch sizes to fit into GPU memory, while accelerating training by taking advantage of hardware-optimized low-precision operations. Modern GPUs, particularly those equipped with Tensor Cores (e.g., NVIDIA's V100, A100), excel at handling FP16 computations, processing them faster and more efficiently than full-precision alternatives. Mixed precision training is essential for scaling large language models (LLMs), as it optimizes memory utilization and computational speed without sacrificing accuracy or stability. In Rust, the The code first defines a simple neural network using two linear layers and ReLU activation, built with In terms of industry applications, these optimization techniques have been widely adopted in large-scale models like BERT, GPT-3, and T5. Learning rate scheduling and gradient clipping are standard practices for stabilizing training, while mixed precision training has become essential for training extremely large models on modern hardware. Additionally, distributed training techniques have allowed companies like OpenAI and Google to scale Transformer models to billions of parameters, enabling breakthroughs in NLP tasks such as text generation, translation, and summarization. In conclusion, optimizing the training of large Transformer models requires a combination of advanced techniques, including learning rate scheduling, gradient clipping, mixed precision training, and data augmentation. By implementing these strategies in Rust using tch-rs, developers can train deep Transformer models more efficiently, reducing computational costs and improving model stability. As models continue to grow in size and complexity, these techniques will become increasingly important for maintaining scalability and performance in modern NLP applications. The Transformer model has revolutionized Natural Language Processing (NLP) by excelling in a wide range of tasks, from machine translation to text summarization, question answering, and more. The key to the Transformer’s success lies in its ability to process sequences in parallel through its self-attention mechanism, which allows it to capture both local and global dependencies within text. This flexibility enables the Transformer to handle diverse tasks with minimal changes to its architecture, making it the foundation for many state-of-the-art models, such as BERT and GPT-3. For tasks like machine translation, the encoder-decoder architecture of the Transformer is particularly well-suited. The encoder processes the input sentence in one language and generates a context-rich representation of the entire sequence. The decoder then uses this representation to generate a sentence in the target language. Mathematically, the sequence-to-sequence translation process can be viewed as a mapping from a source sequence $X$ to a target sequence $Y$, where the Transformer maximizes the probability $P(Y|X)$ by modeling both the input-output dependencies and the relationships between tokens within each sequence. The attention mechanism enables the decoder to attend to specific parts of the input sequence when generating each word in the translation, ensuring accurate word alignment and contextual consistency. In text summarization, the Transformer is used to condense long documents into shorter, meaningful summaries. Unlike traditional models that may struggle to handle long dependencies in the text, the Transformer can efficiently capture relationships between distant parts of a document. By learning to attend to the most relevant portions of the input, the model generates coherent summaries that preserve the essential meaning. The Transformer is often trained on large corpora to perform this task by optimizing a loss function that minimizes the difference between the generated summary and the reference summary, typically using cross-entropy loss: $$ L_{\text{summarization}} = - \sum_{i=1}^{N} y_i \log(\hat{y}_i) $$ where $y_i$ is the reference summary token, and $\hat{y}_i$ is the predicted token from the Transformer model. For question answering, pre-trained Transformer models such as BERT have shown remarkable success. In this task, the model takes a question and a context passage as input and predicts the span of text within the passage that contains the answer. BERT’s encoder-only architecture is ideal for this task, as it allows the model to build a contextualized representation of both the question and the passage, and then perform a softmax over the possible answer spans. Formally, the model predicts two probabilities: $P_{\text{start}}(i)$ and $P_{\text{end}}(i)$, which represent the likelihood that the $i$-th token in the passage is the start or end of the answer span, respectively. The model maximizes the sum of these probabilities over the possible spans: $$ \hat{y} = \arg\max_{i,j} P_{\text{start}}(i) P_{\text{end}}(j) $$ This approach has been particularly successful in datasets like SQuAD (Stanford Question Answering Dataset), where pre-trained Transformer models outperform traditional approaches by a significant margin. The versatility of the Transformer model comes from its ability to be fine-tuned on different tasks with minimal architectural changes. Pre-trained models, such as BERT, GPT, and T5, are often first trained on large unlabeled corpora using unsupervised objectives like masked language modeling or causal language modeling. After pre-training, these models are fine-tuned on specific tasks with relatively small labeled datasets. The fine-tuning process involves modifying the final layers of the Transformer to fit the task-specific objective, such as classification or sequence generation. Fine-tuning is mathematically similar to standard supervised learning, where the model minimizes a task-specific loss function $L_{\text{task}}$ on a labeled dataset: $$ \theta^* = \arg\min_{\theta} L_{\text{task}}(\theta) $$ Here, $\theta$ represents the model parameters, which are updated through backpropagation to minimize the loss. The advantage of fine-tuning is that the pre-trained model has already learned general language representations, and only minimal task-specific training is needed to achieve high performance. In practice, hyperparameter tuning plays a significant role in maximizing the performance of the Transformer model on different tasks. Key hyperparameters, such as the learning rate, batch size, number of attention heads, and depth of the model, must be carefully selected to ensure optimal training. For instance, increasing the number of attention heads can improve the model’s ability to capture diverse relationships in the input, but it also increases computational cost. Similarly, deeper models may capture more complex patterns but require more careful optimization to prevent overfitting. The large-scale pre-training of Transformer models has profoundly reshaped NLP by enabling models like GPT-3, with hundreds of billions of parameters, to understand and generate text across diverse tasks. Trained on massive amounts of data from various domains, these models excel at tasks such as text completion, summarization, and translation with little to no task-specific training. This is made possible through transfer learning, where knowledge acquired during extensive pre-training is adapted to downstream tasks via minimal fine-tuning. This approach has shifted NLP toward a paradigm where pre-trained models lay the foundation for nearly all state-of-the-art systems, minimizing the need for exhaustive task-specific datasets. In real-world applications, Transformer models are deployed across industries to handle diverse tasks including language translation (Google Translate), news summarization, question answering (search engines and virtual assistants), and sentiment analysis for social media monitoring. This flexibility is due to the self-attention mechanism, which enables the model to capture complex dependencies in sequential data, making Transformers adaptable beyond NLP to areas like image processing and speech recognition. These adaptations showcase the Transformer’s capacity to manage complex data relationships, driving innovation across various fields. To fully leverage Transformer-based Large Language Models (LLMs) like GPT-3, developers are focusing on creating specialized LLM applications that utilize prompt engineering, retrieval-augmented generation (RAG), and AI agents. These techniques enhance the model’s accuracy, contextual relevance, and ability to handle real-time data, unlocking new capabilities in applications such as automated customer support, content creation, and information retrieval. Prompt engineering allows for precise input design to guide model responses, while RAG integrates LLMs with real-time data retrieval for grounded, contextually rich outputs. AI agents expand this framework by enabling autonomous systems that use LLMs to execute complex workflows and integrate seamlessly with other APIs or tools. Rust crates like The The use tch;
use tch::{Tensor, Kind, Device};
// Function for positional encoding to incorporate sequence order information
fn positional_encoding(seq_len: i64, embed_size: i64) -> Tensor {
let mut pos_enc = Tensor::zeros(&[seq_len, embed_size], (Kind::Float, Device::Cpu));
for pos in 0..seq_len {
for i in (0..embed_size).step_by(2) {
let angle = pos as f64 / (10000_f64).powf(i as f64 / embed_size as f64);
// Debug: Print position and index values
println!("pos: {}, i: {}, embed_size: {}", pos, i, embed_size);
// Check if i is within bounds before accessing
if i < embed_size {
pos_enc = pos_enc.index_put_(
&[Some(Tensor::of_slice(&[pos])), Some(Tensor::of_slice(&[i]))],
&Tensor::of_slice(&[angle.cos() as f32]),
false
);
}
// Check if i + 1 is within bounds before accessing
if i + 1 < embed_size {
pos_enc = pos_enc.index_put_(
&[Some(Tensor::of_slice(&[pos])), Some(Tensor::of_slice(&[i + 1]))],
&Tensor::of_slice(&[angle.sin() as f32]),
false
);
}
}
}
pos_enc
}
// Multi-head attention function
fn multi_head_attention(query: &Tensor, key: &Tensor, value: &Tensor, num_heads: i64) -> Tensor {
let _head_dim = query.size()[1] / num_heads; // Changed to _head_dim to avoid warning
let query_split = query.chunk(num_heads, 0);
let key_split = key.chunk(num_heads, 0);
let value_split = value.chunk(num_heads, 0);
let mut output_heads = vec![];
for h in 0..num_heads {
let h_usize = h as usize;
let attention_weights = query_split[h_usize].matmul(&key_split[h_usize].transpose(-2, -1));
let attention_weights = attention_weights.softmax(-1, Kind::Float);
let attended_values = attention_weights.matmul(&value_split[h_usize]);
output_heads.push(attended_values);
}
Tensor::cat(&output_heads, 0)
}
// Define the encoder with multi-head attention and layer normalization
fn encoder(query: &Tensor, num_layers: i64, num_heads: i64, embed_size: i64) -> Tensor {
let pos_enc = positional_encoding(query.size()[1], embed_size);
let mut output = query + pos_enc; // Add positional encoding
for _ in 0..num_layers {
// Multi-head self-attention followed by layer normalization and feedforward
let attention_output = multi_head_attention(&output, &output, &output, num_heads);
output = (attention_output + output).layer_norm(&[embed_size], None::<Tensor>, None::<Tensor>, 1e-5, true); // Specified None::<Tensor>
let feedforward = output.matmul(&output.transpose(-2, -1)).relu();
output = (feedforward + output).layer_norm(&[embed_size], None::<Tensor>, None::<Tensor>, 1e-5, true); // Specified None::<Tensor>
}
output
}
// Define the decoder with multi-head attention and cross-attention
fn decoder(encoder_output: &Tensor, target: &Tensor, num_layers: i64, num_heads: i64, embed_size: i64) -> Tensor {
let pos_enc = positional_encoding(target.size()[1], embed_size);
let mut output = target + pos_enc; // Add positional encoding
for _ in 0..num_layers {
// Multi-head self-attention in the decoder
let self_attention_output = multi_head_attention(&output, &output, &output, num_heads);
output = (self_attention_output + output).layer_norm(&[embed_size], None::<Tensor>, None::<Tensor>, 1e-5, true); // Specified None::<Tensor>
// Cross-attention with encoder output
let cross_attention_output = multi_head_attention(&output, &encoder_output, &encoder_output, num_heads);
output = (cross_attention_output + output).layer_norm(&[embed_size], None::<Tensor>, None::<Tensor>, 1e-5, true); // Specified None::<Tensor>
// Feedforward and layer normalization
let feedforward = output.matmul(&output.transpose(-2, -1)).relu();
output = (feedforward + output).layer_norm(&[embed_size], None::<Tensor>, None::<Tensor>, 1e-5, true); // Specified None::<Tensor>
}
output
}
fn main() {
let device = Device::cuda_if_available();
let seq_len = 20;
let embed_size = 64;
let num_heads = 8;
let num_layers = 6;
// Example input and target sequences (batch size 10, sequence length 20, embedding size 64)
let input = Tensor::randn(&[10, seq_len, embed_size], (Kind::Float, device));
let target = Tensor::randn(&[10, seq_len, embed_size], (Kind::Float, device));
// Forward pass through encoder and decoder
let encoder_output = encoder(&input, num_layers, num_heads, embed_size);
let decoder_output = decoder(&encoder_output, &target, num_layers, num_heads, embed_size);
println!("Decoder output: {:?}", decoder_output);
}
4.6. Layer Normalization and Residual Connections
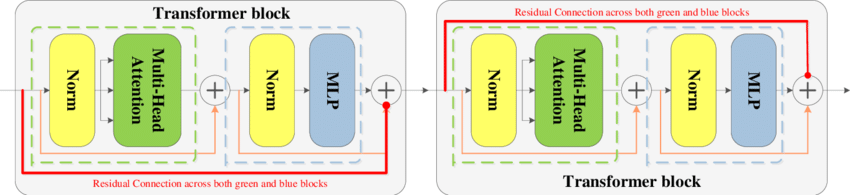
tch library for tensor operations. This code simulates key components of a Transformer block, including layer normalization, dropout for regularization, and residual connections, which are fundamental to modern deep learning architectures.use tch;
use tch::{Tensor, Kind, Device};
// Enhanced layer normalization with learnable parameters (scale and shift)
fn layer_norm(input: &Tensor, scale: &Tensor, shift: &Tensor) -> Tensor {
let mean = input.mean_dim(-1, true, Kind::Float);
let std = input.std_dim(-1, true, true); // Removed the extra argument
(input - &mean) / (std + 1e-5) * scale + shift // Normalization with learned parameters
}
// Dropout function for regularization
fn dropout(input: &Tensor, p: f64) -> Tensor {
input.dropout(p, true)
}
// Transformer block with residual connections, layer normalization, and dropout
fn advanced_transformer_block(input: &Tensor, weight: &Tensor, bias: &Tensor, scale: &Tensor, shift: &Tensor, p_dropout: f64) -> Tensor {
// Simulate multi-head attention
let attn_output = input.matmul(weight) + bias;
let attn_output_norm = layer_norm(&attn_output, scale, shift); // Layer normalization with learnable parameters
// Residual connection with dropout
let residual_output = input + dropout(&attn_output_norm, p_dropout);
// Simulate feedforward network
let ff_output = residual_output.relu().matmul(weight) + bias;
let ff_output_norm = layer_norm(&ff_output, scale, shift); // Apply layer normalization again
// Final residual connection and dropout
residual_output + dropout(&ff_output_norm, p_dropout)
}
fn main() {
let device = Device::cuda_if_available();
// Example input tensor (batch size 10, sequence length 20, embedding size 64)
let input = Tensor::randn(&[10, 20, 64], (Kind::Float, device));
// Example weight, bias, scale, and shift tensors
let weight = Tensor::randn(&[64, 64], (Kind::Float, device));
let bias = Tensor::randn(&[64], (Kind::Float, device));
let scale = Tensor::ones(&[64], (Kind::Float, device)); // Learnable scale parameter for layer norm
let shift = Tensor::zeros(&[64], (Kind::Float, device)); // Learnable shift parameter for layer norm
// Set dropout probability
let p_dropout = 0.1;
// Apply the advanced transformer block
let output = advanced_transformer_block(&input, &weight, &bias, &scale, &shift, p_dropout);
println!("Advanced Transformer block output: {:?}", output);
}
advanced_transformer_block function that performs operations on input data using learnable weights, biases, and normalization parameters (scale and shift). It first applies a simulated multi-head attention mechanism using matrix multiplication (matmul), followed by layer normalization to stabilize training. Dropout is used for regularization, and a residual connection is added to preserve the original input. The feedforward network is then applied to the residual output, followed by another normalization and dropout step. This structure mirrors the architecture of transformer blocks, which allow for deep, stable, and regularized learning. The code is designed to be run on either CPU or GPU (CUDA) for optimized performance.4.7. Training and Optimization Techniques
tch library, which is Rust's binding to PyTorch. The code defines a small feedforward neural network with two linear layers and uses Adam as the optimizer. The training process includes several important features such as learning rate scheduling with warm-up and decay, gradient clipping to prevent exploding gradients, and periodic loss reporting. The neural network is trained on randomly generated data, and the goal is to demonstrate how to implement a complete training loop with key techniques for stabilizing the training process in a Rust-based deep learning framework.use tch;
use tch::{nn, nn::OptimizerConfig, Device, Kind, Tensor, nn::ModuleT};
// Learning rate scheduler function with warm-up and decay
fn learning_rate_scheduler(step: i64, warmup_steps: i64, d_model: f64) -> f64 {
let step = step as f64;
let warmup_steps = warmup_steps as f64;
(1.0 / (d_model.sqrt())) * (step.min(warmup_steps).recip()) * (step.powf(0.5))
}
// Gradient clipping function to prevent exploding gradients
fn clip_gradients(gradients: &mut Tensor, max_norm: f64) {
let total_norm = gradients.norm().double_value(&[]);
if total_norm > max_norm {
let scale_factor = max_norm / total_norm;
*gradients = &*gradients * scale_factor; // Reborrow the mutable reference
}
}
fn main() {
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
let mut opt = nn::Adam::default().build(&vs, 1e-3).unwrap();
// Example model with random weights and biases
let model = nn::seq()
.add(nn::linear(vs.root() / "layer1", 64, 128, Default::default()))
.add_fn(|xs| xs.relu())
.add(nn::linear(vs.root() / "layer2", 128, 64, Default::default()));
let warmup_steps = 4000;
let d_model = 512.0;
// Training loop with gradient clipping and learning rate scheduling
for step in 1..10000 {
let input = Tensor::randn(&[32, 64], (Kind::Float, device)); // Example batch input
let target = Tensor::randn(&[32, 64], (Kind::Float, device)); // Example batch target
// Forward pass
let output = model.forward_t(&input, true); // Use forward_t for training mode
let loss = output.mse_loss(&target, tch::Reduction::Mean);
opt.zero_grad();
loss.backward();
// Apply gradient clipping
for (_name, param) in vs.variables() {
let mut grad = param.grad();
clip_gradients(&mut grad, 0.5);
}
// Update the learning rate using the scheduler
let lr = learning_rate_scheduler(step, warmup_steps, d_model);
opt.set_lr(lr);
// Optimizer step
opt.step();
if step % 1000 == 0 {
println!("Step: {}, Loss: {:?}", step, loss.double_value(&[]));
}
}
}
tch-rs crate facilitates efficient mixed precision training by managing tensor precision and executing FP16 operations on GPUs, making it an excellent choice for memory-intensive and performance-critical applications. The provided code demonstrates the complete training process with random input and target tensors, performing forward passes, loss calculation, backpropagation, and optimizer updates, although it uses float32 precision for all computations in this case.use tch;
use tch::{nn, nn::OptimizerConfig, Device, Kind, Tensor, nn::ModuleT};
// Define a simple model for training
fn build_model(vs: &nn::Path) -> impl nn::ModuleT {
nn::seq()
.add(nn::linear(vs / "layer1", 128, 256, Default::default()))
.add_fn(|xs| xs.relu())
.add(nn::linear(vs / "layer2", 256, 128, Default::default()))
}
// Function for training with gradient descent
fn mixed_precision_training() {
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
let model = build_model(&vs.root());
// Optimizer (Adam) and learning rate
let mut opt = nn::Adam::default().build(&vs, 1e-3).unwrap();
for epoch in 1..=100 {
let input = Tensor::randn(&[32, 128], (Kind::Float, device));
let target = Tensor::randn(&[32, 128], (Kind::Float, device));
// Perform forward pass
let output = model.forward_t(&input, true);
let loss = output.mse_loss(&target, tch::Reduction::Mean);
// Backward pass with gradient descent
opt.zero_grad();
loss.backward();
opt.step();
// Print loss every 10 epochs
if epoch % 10 == 0 {
println!("Epoch: {}, Loss: {:?}", epoch, loss.double_value(&[]));
}
}
}
fn main() {
mixed_precision_training();
}
tch's nn::seq method. The mixed_precision_training function handles the training loop, where input and target tensors are randomly generated for each epoch. The forward pass through the model computes predictions, and the mean squared error (MSE) loss is calculated against the target. The optimizer, Adam, performs gradient descent after the loss is backpropagated. Although the original goal was to implement mixed precision training, this version does not use it due to the lack of an autocast feature in tch. Instead, the training runs in full precision, printing the loss every 10 epochs to monitor progress.4.8. Applications of the Transformer Model
anchor-chain, llm-chain, and langchain-rust support this ecosystem, each offering unique features and modularity that empower developers to build adaptable, high-performance LLM-powered applications across various domains.anchor-chain crate is a Rust library designed to facilitate structured prompting through flexible chains of prompts. It allows for the modular construction of complex prompt chains, where each prompt’s output serves as input to the next, enabling more controlled and nuanced interactions with LLMs. For instance, in applications requiring sequential processing of information, such as summarization followed by classification, anchor-chain provides robust support for prompt chaining. Sample usage with anchor-chain involves defining prompt steps in advance and linking them as functions, which is efficient for workflows that rely on a defined sequence of prompts:[dependencies]
anchor-chain = "0.4.2"
tokio = "1.41.0"
use std::collections::HashMap;
#[tokio::main]
async fn main() {
use anchor_chain::{
chain::ChainBuilder,
models::openai::OpenAIModel,
nodes::prompt::Prompt,
};
let chain = ChainBuilder::new()
.link(Prompt::new("{{ input }}"))
.link(OpenAIModel::new_gpt3_5_turbo("You are a helpful assistant".to_string()).await)
.build();
let result = chain
.process(HashMap::from([("input".to_string(), "Write a hello world program in Rust".to_string())]))
.await
.expect("Error processing chain");
println!("Result: {}", result);
}
llm-chain crate builds upon the concept of prompt engineering and chaining but introduces flexibility by integrating with different backends like OpenAI and Hugging Face. It emphasizes retrieval-augmented generation, allowing developers to implement RAG by integrating external databases or knowledge bases for real-time, contextually enriched responses. This approach is particularly useful for applications where the model needs to access external information, such as generating answers based on up-to-date knowledge or user-specific data. llm-chain supports modular workflows, and its design promotes interoperability between various data sources, making it ideal for dynamic applications like chatbots:[dependencies]
llm-chain-openai = "0.13.0"
tokio = { version = "1", features = ["full", "rt-multi-thread"] }
llm-chain = "0.13.0"
use std::error::Error;
use llm_chain::{executor, parameters, prompt};
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// Attempt to initialize a generic executor if OpenAI-specific executor isn’t available
let exec = executor!()?;
let res = prompt!(
"You are a robot assistant for making personalized greetings",
"Make a personalized greeting for Joe"
)
.run(¶meters!(), &exec)
.await?;
println!("{}", res);
Ok(())
}
For more extensive capabilities, including the orchestration of AI agents, langchain-rust provides a highly flexible framework with advanced features for managing complex agent behaviors. Inspired by Python's LangChain, langchain-rust allows developers to create multi-step agents that use conditional logic and can interact with various data sources, APIs, or other agents. This makes it suitable for applications requiring autonomous task completion, such as automated research assistants or multi-stage data processing pipelines. With langchain-rust, developers can build agents that assess user inputs, retrieve relevant information, and generate detailed responses through intelligent decision-making pathways:
[dependencies]
langchain-rust = "4.6.0"
serde_json = "1.0.132"
tokio = "1.41.0"
use langchain_rust::{
chain::{Chain, LLMChainBuilder},
fmt_message, fmt_placeholder, fmt_template,
language_models::llm::LLM,
llm::openai::{OpenAI, OpenAIModel},
message_formatter,
prompt::HumanMessagePromptTemplate,
prompt_args,
schemas::messages::Message,
template_fstring,
};
#[tokio::main]
async fn main() {
//We can then initialize the model:
// If you'd prefer not to set an environment variable you can pass the key in directly via the `openai_api_key` named parameter when initiating the OpenAI LLM class:
// let open_ai = OpenAI::default()
// .with_config(
// OpenAIConfig::default()
// .with_api_key("<your_key>"),
// ).with_model(OpenAIModel::Gpt4oMini.to_string());
let open_ai = OpenAI::default().with_model(OpenAIModel::Gpt4oMini.to_string());
//Once you've installed and initialized the LLM of your choice, we can try using it! Let's ask it what LangSmith is - this is something that wasn't present in the training data so it shouldn't have a very good response.
let resp = open_ai.invoke("What is rust").await.unwrap();
println!("{}", resp);
// We can also guide it's response with a prompt template. Prompt templates are used to convert raw user input to a better input to the LLM.
let prompt = message_formatter![
fmt_message!(Message::new_system_message(
"You are world class technical documentation writer."
)),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"{input}", "input"
)))
];
//We can now combine these into a simple LLM chain:
let chain = LLMChainBuilder::new()
.prompt(prompt)
.llm(open_ai.clone())
.build()
.unwrap();
//We can now invoke it and ask the same question. It still won't know the answer, but it should respond in a more proper tone for a technical writer!
match chain
.invoke(prompt_args! {
"input" => "Quien es el escritor de 20000 millas de viaje submarino",
})
.await
{
Ok(result) => {
println!("Result: {:?}", result);
}
Err(e) => panic!("Error invoking LLMChain: {:?}", e),
}
//If you want to prompt to have a list of messages you could use the `fmt_placeholder` macro
let prompt = message_formatter![
fmt_message!(Message::new_system_message(
"You are world class technical documentation writer."
)),
fmt_placeholder!("history"),
fmt_template!(HumanMessagePromptTemplate::new(template_fstring!(
"{input}", "input"
))),
];
let chain = LLMChainBuilder::new()
.prompt(prompt)
.llm(open_ai)
.build()
.unwrap();
match chain
.invoke(prompt_args! {
"input" => "Who is the writer of 20,000 Leagues Under the Sea, and what is my name?",
"history" => vec![
Message::new_human_message("My name is: luis"),
Message::new_ai_message("Hi luis"),
],
})
.await
{
Ok(result) => {
println!("Result: {:?}", result);
}
Err(e) => panic!("Error invoking LLMChain: {:?}", e),
}
}
Each of these crates brings unique advantages. anchor-chain is best suited for structured, sequential prompts; it excels in applications with predefined workflows. llm-chain offers a more dynamic approach, perfect for RAG-based applications that require real-time data retrieval, making it a good choice for applications in knowledge management or customer support. langchain-rust, meanwhile, provides the most flexibility and is ideal for building fully autonomous AI agents capable of handling complex tasks and interactions.
Prompt engineering is the process of crafting inputs to guide a large language model (LLM) toward generating responses that meet specific goals. Since LLMs like GPT-3 or GPT-4 generate text based on the input they receive, a well-designed prompt can significantly influence the quality, relevance, and accuracy of the output. Prompt engineering is crucial in applications ranging from simple information retrieval to complex task automation, especially when no task-specific model fine-tuning is involved. There are several techniques within prompt engineering for example:
Zero-shot Learning: Zero-shot prompts are used without examples or specific instructions on how the model should respond. Instead, they rely on the model's pre-trained knowledge to generate the correct response. For instance, asking, “What is the capital of France?” relies on the model's inherent knowledge base to provide the answer without contextual training.
Instruction-based Prompts: Here, the prompt directly instructs the model on what action to perform. For example, a prompt such as, “Summarize the following article…” explicitly directs the LLM to summarize a given input. These prompts are clear and straightforward, suitable for cases where the task and desired output format are unambiguous.
Few-shot Learning: In few-shot prompting, the prompt includes several examples demonstrating how the model should respond. For instance, to perform text classification, the prompt may contain labeled examples (“Positive: This product is great!” and “Negative: I don’t like this product”) before providing a new input. This technique is valuable for improving the model's accuracy on new tasks without additional training, as it leverages examples to ‘guide’ the model’s responses.
Chain-of-Thought Prompts: Chain-of-thought prompting is a method where the prompt encourages the model to reason through multiple steps to reach a conclusion. This approach is beneficial in tasks that require logical progression, such as mathematical problem-solving or multi-step reasoning, by encouraging the model to “think aloud” in its response.
Retrieval-Augmented Generation (RAG) is a framework that combines LLMs with information retrieval systems to provide more accurate, contextually relevant responses. RAG mitigates one of the main limitations of LLMs: their static nature, which means they cannot access real-time information beyond their training data. By incorporating external retrieval, RAG enhances an LLM's ability to generate responses grounded in current or domain-specific information. The core methods in RAG include:
Document Retrieval: The RAG pipeline typically begins with a retrieval step, where a query (often the user’s question) is used to retrieve relevant documents from an external knowledge base or database. Common retrieval techniques involve dense vector search using embeddings or keyword-based search with inverted indices. Dense vector search utilizes neural network embeddings, which can capture semantic similarities, making it suitable for more nuanced information retrieval.
Fusion of Retrieved Information and Generation: After retrieving the relevant documents, the next step is to integrate this information into the prompt for the LLM. One approach, known as fusion-in-decoder, appends the retrieved documents to the initial query and passes them through the LLM to generate a response. This method ensures that the model's output is directly informed by the retrieved information, enhancing accuracy and contextual grounding.
Fine-tuning for RAG Tasks: In advanced setups, models can be fine-tuned to weigh retrieved documents effectively, improving the relevance and coherence of responses. This fine-tuning process can involve training on large, domain-specific datasets where retrieved information is consistently merged with model output, ensuring the LLM learns to prioritize retrieved data in response generation.
Prompt Chaining in RAG: In complex queries requiring multiple steps, RAG can employ a chain of prompts where initial queries are used to retrieve information, followed by refined prompts to generate responses based on the retrieved content. For instance, a question might first prompt a retrieval step for background context, followed by a summarization or answer generation step.
AI agents represent a class of applications where LLMs perform complex workflows autonomously, often by interacting with external APIs, databases, or other AI systems. AI agents go beyond simple question-answering tasks, taking on roles as interactive assistants capable of executing multi-step processes, conducting real-time analysis, or even operating independently to meet specific objectives. AI agents are particularly suited for dynamic environments, such as automated customer support, research assistance, and autonomous task completion. Key techniques for developing AI agents include:
Autonomous Decision-Making: At the core of an AI agent’s functionality is the ability to make decisions based on input and contextual information. This can involve conditional logic, where the agent’s actions depend on specific triggers or conditions. For example, an agent assisting with customer support might check for the user’s account status before performing account-specific operations. This decision-making layer is often implemented with conditional statements or policy-based actions programmed to respond to different types of input.
Memory and Context Management: Effective AI agents require memory to retain information across interactions. Memory enables the agent to hold onto context from prior exchanges, essential for applications where continuity is required, such as in personal assistant roles or long-term support scenarios. Context can be maintained by storing key information across interactions or by integrating a memory system that retrieves prior responses. Techniques such as episodic memory (where interactions are stored as separate episodes) or semantic memory (where long-term knowledge is stored in structured formats) are often used to manage this information.
Integration with External APIs and Tools: Advanced AI agents often need to interact with external APIs or tools to gather information, perform actions, or retrieve real-time data. For example, a travel assistant might integrate with airline and hotel booking APIs to offer comprehensive travel suggestions. This integration typically requires a middleware layer that facilitates secure API requests, data formatting, and error handling to ensure the AI agent’s seamless operation within broader workflows.
Multi-Agent Collaboration and Task Decomposition: In some complex systems, multiple AI agents are employed, each specializing in a particular task or sub-process. This is known as multi-agent collaboration, where each agent completes its assigned task and communicates results with other agents. For instance, one agent might retrieve data, while another analyzes it, and a third agent generates a report. Task decomposition is a strategy used here, where a large, complex task is broken down into smaller, manageable tasks, each handled by a specialized agent. This modular approach improves efficiency and allows for parallel processing.
Workflow Management and Orchestration: For agents executing multi-step tasks, workflow management is crucial to control the flow and sequence of operations. Techniques like finite state machines (FSM) or behavior trees are employed to manage state transitions, ensuring that agents operate within a defined process structure. Workflow orchestration tools may also be used to manage dependencies between tasks, handle retries, and log process outcomes, all of which are essential for maintaining robust and reliable agent functionality.
Together, prompt engineering, retrieval-augmented generation, and AI agent development comprise a robust framework for building versatile, high-performing applications with LLMs. By mastering these techniques, developers can harness the full potential of LLMs to create applications that are highly responsive, contextually accurate, and capable of handling complex, dynamic workflows autonomously.
Overall, the choice between these crates depends on the application's requirements: whether it needs structured prompt chaining, real-time information retrieval, or autonomous agent behaviors. By utilizing these Rust-based tools, developers can fully harness the capabilities of LLMs, achieving high levels of contextual accuracy and adaptability in a variety of applications.
4.9. Conclusion
Chapter 4 provides a comprehensive understanding of the Transformer architecture, emphasizing its innovative approach to processing sequential data and its practical implementation using Rust. By mastering the concepts and techniques discussed, readers will be equipped to build and optimize powerful NLP models that leverage the full potential of Transformers.
4.9.1. Further Learning with GenAI
Each prompt is crafted to encourage a comprehensive understanding and hands-on experience, guiding readers to explore the intricate details of Transformer models and their application in various natural language processing scenarios.
Explain the key limitations of traditional RNNs and CNNs that led to the development of the Transformer architecture. How do Transformers address these limitations, particularly in handling long-range dependencies and parallel processing? Discuss the implications for NLP tasks like translation and summarization.
Describe the self-attention mechanism in detail, including the role of query, key, and value vectors. How does self-attention enable the model to focus on different parts of the input sequence? Provide a step-by-step implementation of self-attention in Rust and analyze its computational complexity.
Compare the concept of self-attention with traditional attention mechanisms. How does self-attention improve over these methods in terms of scalability and parallelization? Implement both mechanisms in Rust and evaluate their performance on an NLP task.
Discuss the purpose of multi-head attention in the Transformer architecture. How does using multiple attention heads enhance the model's ability to capture diverse patterns in the data? Implement multi-head attention in Rust, experimenting with different numbers of heads, and analyze the results.
Explain the significance of positional encoding in the Transformer model. How does it compensate for the lack of inherent sequence order in self-attention mechanisms? Implement sinusoidal positional encoding in Rust and explore alternative encoding methods, comparing their effectiveness.
Describe the architecture of the encoder and decoder in the Transformer model. How do these components interact through cross-attention? Implement a full encoder-decoder model in Rust, focusing on the integration of cross-attention, and evaluate its performance on a sequence-to-sequence task.
Analyze the role of layer normalization and residual connections in the Transformer model. How do these techniques contribute to training stability and convergence in deep networks? Implement layer normalization and residual connections in Rust, and experiment with their impact on model performance.
Discuss the challenges of training large Transformer models, including computational costs and memory usage. How can optimization techniques like learning rate scheduling, gradient clipping, and mixed precision training help address these challenges? Implement these techniques in Rust and evaluate their effectiveness.
Explain the concept of learning rate warm-up in the context of Transformer training. Why is it important, and how does it contribute to training stability? Implement learning rate warm-up in Rust and analyze its impact on model convergence.
Discuss the trade-offs between using encoder-only, decoder-only, and full encoder-decoder Transformer models for different NLP tasks. Provide examples of tasks where each architecture excels, and implement them in Rust to compare their performance.
Explore the scalability advantages of the Transformer architecture compared to RNNs, particularly in handling large datasets. How do the parallelization capabilities of Transformers affect training and inference speed? Implement a Transformer model in Rust, optimizing it for large-scale NLP tasks.
Describe the impact of model architecture on the interpretability of Transformer models. How do attention mechanisms and multi-head attention contribute to model transparency? Implement tools in Rust to visualize and interpret attention weights in a Transformer model.
Discuss the practical challenges of implementing and optimizing Transformer models in Rust for real-world applications. How can techniques like distributed training and memory optimization improve model scalability and performance? Explore these techniques in a Rust implementation.
Explain the concept of cross-attention in the encoder-decoder Transformer architecture. How does cross-attention facilitate the generation of output sequences? Implement cross-attention in Rust and analyze its role in tasks like machine translation.
Discuss the use of pre-trained Transformer models in transfer learning. How can fine-tuning be applied to adapt these models to specific NLP tasks? Implement fine-tuning for a pre-trained Transformer model in Rust and evaluate its performance on a custom task.
Analyze the computational complexity of the self-attention mechanism in the Transformer model. How does this complexity scale with input sequence length, and what are the implications for large-scale NLP tasks? Implement and optimize self-attention in Rust to handle long sequences efficiently.
Explore the role of data augmentation and preprocessing in improving the robustness of Transformer models. How can these techniques enhance model generalization? Implement data augmentation strategies in Rust and evaluate their impact on Transformer training.
Discuss the importance of hyperparameter tuning in optimizing Transformer models. What are the key hyperparameters that affect model performance, and how can they be tuned effectively? Implement a hyperparameter tuning strategy in Rust and analyze its effect on a Transformer model's performance.
Explain the concept of mixed precision training and its benefits in reducing memory usage and speeding up Transformer training. How can this technique be implemented in Rust, and what are the trade-offs involved? Experiment with mixed precision training on a Transformer model in Rust.
Describe the process of integrating Transformer models into a production environment. What are the key considerations for deployment, including model serving, scalability, and inference speed? Implement a deployment pipeline for a Transformer model in Rust, focusing on optimization for real-time inference.
Embrace these challenges with curiosity and determination, knowing that your efforts will equip you with the expertise to build powerful, state-of-the-art language models that can transform the future of technology.
4.9.2. Hands On Practices
Self-Exercise 4.1: Implementing and Analyzing Self-Attention Mechanism
Objective: To gain a deep understanding of the self-attention mechanism by implementing it from scratch and analyzing its performance in NLP tasks.
Tasks:
Implement the self-attention mechanism in Rust, focusing on the mathematical operations involved, including the calculation of query, key, and value vectors.
Integrate your self-attention implementation into a simple Transformer model designed for a text classification task.
Analyze the computational complexity of your self-attention implementation, especially how it scales with increasing sequence length.
Experiment with different input sequence lengths and observe the impact on performance and attention distribution.
Deliverables:
A Rust codebase containing the self-attention mechanism and its integration into a Transformer model.
A detailed report on the computational complexity of self-attention, including analysis of performance across different sequence lengths.
Visualizations that show how attention is distributed across the input sequence for various examples.
Self-Exercise 4.2: Implementing Multi-Head Attention and Exploring Its Benefits
Objective: To understand the purpose and benefits of multi-head attention in Transformers by implementing and experimenting with it in Rust.
Tasks:
Implement multi-head attention in Rust, ensuring you correctly split the input vectors, apply self-attention to each head, and concatenate the results.
Integrate multi-head attention into a Transformer model and train it on a text generation task.
Experiment with different numbers of attention heads, analyzing how the model's performance and ability to capture diverse patterns change.
Compare the results of your multi-head attention implementation with a single-head attention mechanism to evaluate the benefits of using multiple heads.
Deliverables:
A Rust implementation of multi-head attention, including integration into a Transformer model.
A report comparing the performance of different numbers of attention heads, including metrics such as accuracy and training time.
Insights and visualizations showing how multi-head attention captures different aspects of the input data.
Self-Exercise 4.3: Fine-Tuning a Transformer Model for a Custom NLP Task
Objective: To practice fine-tuning a pre-trained Transformer model for a specific NLP task and evaluate its performance against a baseline model.
Tasks:
Load a pre-trained Transformer model and prepare it for fine-tuning on a specific NLP task, such as sentiment analysis or named entity recognition.
Implement the fine-tuning process in Rust, adapting the Transformer architecture as necessary for the target task.
Train the fine-tuned model on a labeled dataset, ensuring to monitor for issues like overfitting or data imbalance.
Compare the performance of the fine-tuned Transformer with a baseline model, analyzing metrics such as accuracy, precision, recall, and F1-score.
Deliverables:
A Rust codebase for fine-tuning a pre-trained Transformer model on a custom NLP task.
A training report that includes the steps taken to fine-tune the model, modifications made to the architecture, and any challenges encountered.
A comparative analysis report showing the performance of the fine-tuned Transformer versus a baseline model, with detailed metric evaluations.
Self-Exercise 4.4: Implementing and Visualizing Positional Encoding in Transformers
Objective: To understand and implement positional encoding in the Transformer architecture, exploring how it enables the model to capture sequence information.
Tasks:
Implement sinusoidal positional encoding in Rust, ensuring you understand the mathematical rationale behind the encoding strategy.
Integrate positional encoding into a Transformer model designed for a machine translation task.
Visualize the positional encodings applied to different sequence lengths and analyze how they help the Transformer model understand word order.
Experiment with alternative positional encoding methods and compare their effectiveness with the sinusoidal approach.
Deliverables:
A Rust implementation of sinusoidal positional encoding and its integration into a Transformer model.
Visualizations of positional encodings for different sequence lengths, with explanations of how they influence model performance.
A comparative report analyzing the effectiveness of sinusoidal versus alternative positional encodings in a machine translation task.
Self-Exercise 4.5: Optimizing Transformer Training with Mixed Precision and Learning Rate Scheduling
Objective:\ To optimize the training of Transformer models by implementing mixed precision training and learning rate scheduling, analyzing their impact on performance and efficiency.
Tasks:
Implement mixed precision training in Rust for a Transformer model, focusing on reducing memory usage and speeding up the training process.
Integrate learning rate scheduling into your training pipeline, experimenting with different scheduling strategies, such as warm-up and decay.
Train the Transformer model on a large-scale NLP task, comparing the results of mixed precision training and learning rate scheduling with a standard training setup.
Analyze the trade-offs between training efficiency, model accuracy, and resource utilization.
Deliverables:
A Rust codebase that implements mixed precision training and learning rate scheduling for Transformer models.
A detailed training report that compares the efficiency and effectiveness of mixed precision training and learning rate scheduling against standard training methods.
A performance analysis report that includes metrics on training time, memory usage, and model accuracy, along with insights into the trade-offs involved.
Comments