Chapter 1
Introduction to Large Language Models
"The intersection of advanced language models and a systems programming language like Rust opens new frontiers in creating efficient, safe, and scalable AI systems." — Yoshua Bengio
Chapter 1 offers a comprehensive introduction to Large Language Models (LLMs) and their implementation using Rust. It begins with a deep dive into the fundamentals of LLMs, tracing their evolution and exploring their key components and applications. The chapter then introduces Rust's powerful language features, particularly those that enhance the efficiency and safety of LLM implementation. It provides a detailed guide on building LLM architectures in Rust, complete with practical examples and case studies. Finally, the chapter addresses the challenges and ethical considerations inherent in deploying LLMs, highlighting Rust's role in overcoming these issues and paving the way for future developments in this field.
1.1. Fundamentals of Large Language Models
A Large Language Model (LLM) is like a magical robot that has read millions of books and learned all sorts of things about how we talk, write, and tell stories. It understands words, sentences, and even the meaning behind them. So, when you ask it a question, it can use everything it has learned to give you an answer, or if you’re telling a story and get stuck, it can help you come up with the next part! It’s like a super helpful friend who knows a lot of words and can always come up with something to say, whether you’re asking it to explain something, tell a joke, or even help with homework. The LLM doesn’t think like we do, but it’s very good at pretending to because it knows so much about language!

Figure 1: Analogy of LLM generated by DALL-E.
Actually, a language model's basic capability lies in its ability to understand and generate human language by learning from vast amounts of text data. At its core, a language model predicts the next word in a sequence based on the previous words, which allows it to generate coherent sentences, respond to queries, and perform tasks such as text completion, translation, or summarization. By learning the patterns and structures of language during training, a model can recognize context, syntax, and semantic relationships. This enables the model to engage in natural language tasks such as answering questions or writing paragraphs that reflect a deep understanding of the input data. As language models evolve, they continue to handle increasingly complex tasks in natural language processing (NLP).
In recent years, LLMs have become a cornerstone of modern artificial intelligence, revolutionizing how machines understand and generate human language. These models represent a significant leap from traditional Natural Language Processing (NLP) techniques, allowing machines to not only process text but also generate coherent and contextually rich language. At their core, LLMs are designed to handle and model language sequences at an unprecedented scale, learning patterns, semantics, and even reasoning from vast amounts of data.
The development of LLMs is deeply rooted in the historical evolution of NLP. Earlier models like rule-based systems and $n$-gram models had limited capabilities in understanding long-range dependencies within language. The introduction of machine learning-based models like word embeddings (e.g., Word2Vec) marked the beginning of data-driven NLP. However, the true transformation came with the development of Transformer-based architectures, as introduced by Vaswani et al. in the seminal paper Attention is All You Need (2017). These architectures laid the foundation for advanced models such as GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and other large-scale models that excel in various NLP tasks, from text generation to machine translation. We will discuss more about this architecture in following chapters.

Figure 2: Transformer architecture (Credit d2l.ai)
Mathematically, LLMs rely on several core components that differentiate them from traditional NLP models. One of the fundamental aspects of these models is tokenization, where text is broken down into smaller units, often subwords or characters, known as tokens. Each token is then represented as a vector in a continuous vector space using embeddings. The embedding vector of a token is learned during the training process and captures semantic and syntactic information about the word.
The attention mechanism is another critical innovation that powers LLMs. Formally, given a sequence of input tokens $\mathbf{x} = [x_1, x_2, \dots, x_n]$, the attention mechanism calculates a weighted sum of the token representations based on their relevance to a particular token. This relevance is quantified using query ($Q$), key ($K$), and value ($V$) matrices, where the attention scores are computed as:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
Here, $d_k$ is the dimension of the key vectors, and the softmax function ensures that the attention scores are normalized across all tokens. This mechanism enables the model to focus on relevant parts of the input sequence when making predictions, allowing it to handle long-range dependencies effectively, which was a significant limitation in earlier models like RNNs and LSTMs.
Sequence length is another factor that sets LLMs apart. Traditional models struggle to capture the context beyond a certain token window. However, Transformer-based architectures, through the self-attention mechanism, enable LLMs to process sequences of considerable length without suffering from the vanishing gradient problem or losing context. This ability allows models like GPT-3 or GPT-4 to generate long coherent pieces of text or accurately summarize large documents.
The pre-training and fine-tuning paradigm is essential for developing effective LLMs. Pre-training is typically done on massive unlabeled datasets where the model learns general language patterns, semantics, and grammar. Formally, this is often accomplished using objectives like masked language modeling (as in BERT) or causal language modeling (as in GPT). During pre-training, the model minimizes a loss function such as the negative log-likelihood:
$$ L = - \sum_{i=1}^{n} \log P(x_i | x_{1}, x_{2}, \dots, x_{i-1}; \theta), $$
where $P(x_i | x_{1}, x_{2}, \dots, x_{i-1}; \theta)$ represents the probability of predicting token $x_i$ given the preceding tokens and model parameters $\theta$. Once pre-training is complete, the model undergoes fine-tuning on domain-specific tasks using labeled datasets, which adapts the general language model to specific applications such as text classification, named entity recognition, or question answering.
The applications of LLMs span across multiple domains and industries. In text generation, models like GPT-4 can create human-like text, which has applications in content creation, dialogue systems, and creative writing. Machine translation has also benefited significantly from LLMs, with systems such as Google Translate using transformer-based models to provide more accurate translations that better capture the nuances of different languages. Another critical application is text summarization, where LLMs condense large volumes of text into shorter, meaningful summaries, which is highly useful in areas like legal document analysis, academic research, and news reporting.
In industry, LLMs are driving innovations in fields like healthcare, where models are being fine-tuned to assist in clinical documentation, patient interaction, and drug discovery. Financial services have leveraged LLMs to analyze market sentiment, automate reporting, and detect fraudulent activities. Moreover, in customer service, LLMs power sophisticated chatbots and virtual assistants capable of providing personalized and context-aware interactions at scale.
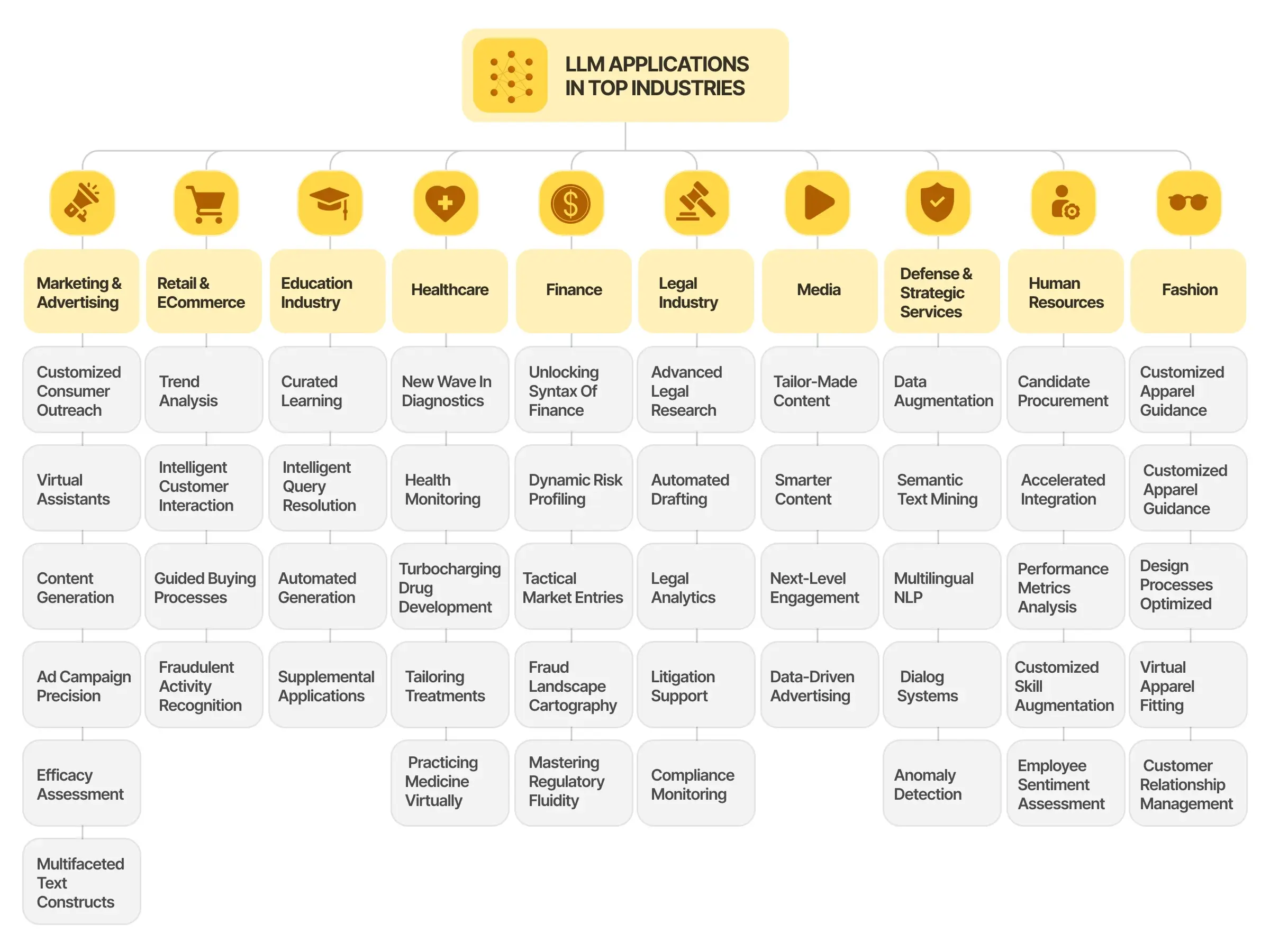
Figure 3: Various applications of LLMs in many industries.
In terms of trends, the scale of LLMs continues to grow, with multilingual models and domain-specific LLMs emerging as key areas of interest. Models like GPT-4 have demonstrated strong capabilities across a variety of languages, driving research into cross-lingual transfer learning and expanding the reach of LLM applications. Additionally, domain-specific LLMs, such as those focused on biomedical text (e.g., PubMedBERT), are being trained to deliver superior performance in specialized fields.
To fully understand the concepts in Large Language Model via Rust (LMVR), readers are advised to first explore Deep Learning via Rust (DLVR) book, as large language models (LLMs) are built on core deep learning principles. DLVR covers foundational topics such as neural networks, backpropagation, and optimization techniques, which are crucial for grasping the workings of LLMs. Additionally, advanced topics like transformer architectures and attention mechanisms, central to LLMs, are discussed in depth in DLVR. By studying both books, readers will gain a comprehensive understanding of deep learning and be better equipped to implement and optimize LLMs using Rust.
[HuggingFace ](https://huggingface.co/)is a leading platform in the AI community that provides access to a vast collection of pre-trained models, datasets, and tools for natural language processing (NLP) tasks. It offers a user-friendly interface and an extensive library, including models such as GPT, BERT, and T5, which are key in understanding and working with Large Language Models (LLMs). For AI engineers, Hugging Face makes it easier to experiment with state-of-the-art models by providing easy integration through their transformers library, allowing them to perform tasks like text generation, sentiment analysis, and translation without needing to build models from scratch. By leveraging Hugging Face, engineers can accelerate their learning, experiment with cutting-edge technologies, and deepen their understanding of LLM architectures and applications across various domains.
Figure 4: HuggingFace AI community for pretrained LLM models.
Hugging Face's Open LLM Leaderboard ranks large language models based on their performance across various NLP tasks. It evaluates models on several benchmarks, such as text generation, question answering, summarization, and other tasks commonly used in AI research and development. The leaderboard provides transparency by showcasing the strengths and weaknesses of each model, offering insights into their capabilities in areas like accuracy, speed, and efficiency. This open and collaborative platform helps AI engineers and researchers compare models, select the best-performing ones for their use cases, and stay updated on the latest advancements in LLM development, fostering a competitive and innovative environment for model improvement.
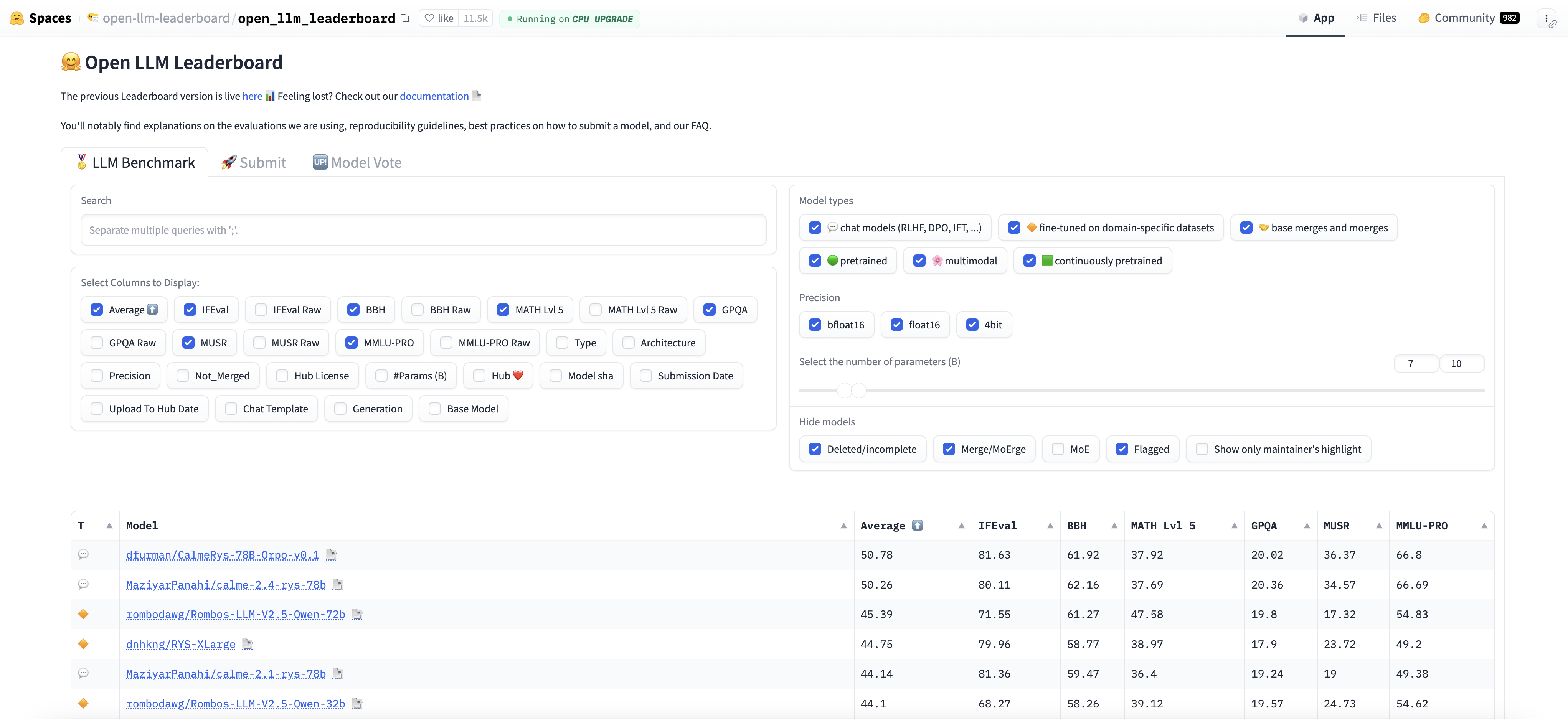
Figure 5: HuggingFace Open LLM Leaderboard.
For practical example, we will demonstrate how to perform multiple downstream NLP tasks using publicly available LLM from [HuggingFace](https://huggingface.co/). We'll utilize the rust-bert crate to perform machine translation. These tasks highlight the power and versatility of LLMs in handling various natural language processing needs.
[dependencies]
anyhow = "1.0.90"
rust-bert = "0.19.0"
tch = "0.8.0"
use rust_bert::pipelines::translation::{Language, TranslationModelBuilder};
fn main() -> anyhow::Result<()> {
let model = TranslationModelBuilder::new()
.with_source_languages(vec![Language::English])
.with_target_languages(vec![Language::Spanish, Language::French, Language::Italian])
.create_model()?;
let input_text = "This is a sentence to be translated";
let output = model.translate(&[input_text], None, Language::Spanish)?;
for sentence in output {
println!("{}", sentence);
}
Ok(())
}
This Rust code uses the rust_bert crate to create a machine translation model that can translate text from English to multiple target languages, including Spanish, French, and Italian. The TranslationModelBuilder is initialized with English as the source language and a list of target languages. The model is then used to translate the provided input sentence ("This is a sentence to be translated") into Spanish. The translation is performed by calling the translate method, and the resulting translated sentences are printed to the console. The anyhow::Result return type ensures proper error handling throughout the process.
As closing of this section, lets see how Rust demonstrates the implementation of a simple GPT-like (Generative Pre-trained Transformer) model for character-level language modeling using the tch crate, which provides bindings for PyTorch in Rust. The provided code implements a simplified version of a GPT-like architecture using the Rust library tch, which provides bindings to PyTorch. The model includes key components such as token embeddings, self-attention mechanisms, feed-forward layers, and residual connections, but it omits positional encoding for simplicity. The model is designed to generate predictions in a character-level language modeling task, where it processes sequences of characters from a vocabulary and learns to predict the next character in a sequence. The training loop optimizes the model using the Adam optimizer, and the performance is evaluated based on accuracy. The training process includes logging the loss for each epoch and visualizing the loss progression using the plotters crate, which generates a line chart of the training loss over 500 epochs.
[dependencies]
rand = "0.8.5"
tch = "0.8.0"
plotters = "0.3.7"
use tch::{nn, nn::Module, nn::OptimizerConfig, Tensor, Device, Kind};
use rand::seq::SliceRandom;
use rand::thread_rng;
use plotters::prelude::*;
/// Function to generate synthetic training data for a character-level language model.
fn generate_synthetic_data(vocab: &[char], seq_len: usize, num_samples: usize) -> (Vec<Tensor>, Vec<Tensor>) {
let mut rng = thread_rng();
let mut inputs = Vec::new();
let mut targets = Vec::new();
for _ in 0..num_samples {
let seq: Vec<i64> = vocab
.choose_multiple(&mut rng, seq_len)
.map(|&c| vocab.iter().position(|&v| v == c).unwrap() as i64)
.collect();
inputs.push(Tensor::of_slice(&seq[..seq_len-1]).to_kind(Kind::Int64));
targets.push(Tensor::of_slice(&seq[1..]).to_kind(Kind::Int64));
}
(inputs, targets)
}
/// Advanced GPT-like architecture using self-attention, feed-forward layers, and residual connections.
#[derive(Debug)]
struct AdvancedGPT {
token_embedding: nn::Embedding,
linear_q: nn::Linear,
linear_k: nn::Linear,
linear_v: nn::Linear,
linear_out: nn::Linear,
feed_forward: nn::Sequential,
layer_norm_1: nn::LayerNorm,
layer_norm_2: nn::LayerNorm,
output_linear: nn::Linear,
}
impl AdvancedGPT {
fn new(vs: &nn::Path, vocab_size: i64, hidden_dim: i64) -> Self {
let token_embedding = nn::embedding(vs / "token_embedding", vocab_size, hidden_dim, Default::default());
let linear_q = nn::linear(vs / "linear_q", hidden_dim, hidden_dim, Default::default());
let linear_k = nn::linear(vs / "linear_k", hidden_dim, hidden_dim, Default::default());
let linear_v = nn::linear(vs / "linear_v", hidden_dim, hidden_dim, Default::default());
let linear_out = nn::linear(vs / "linear_out", hidden_dim, hidden_dim, Default::default());
let feed_forward = nn::seq()
.add(nn::linear(vs / "ffn1", hidden_dim, hidden_dim * 4, Default::default()))
.add_fn(|x| x.gelu("none"))
.add(nn::linear(vs / "ffn2", hidden_dim * 4, hidden_dim, Default::default()));
let layer_norm_1 = nn::layer_norm(vs / "layer_norm_1", vec![hidden_dim], Default::default());
let layer_norm_2 = nn::layer_norm(vs / "layer_norm_2", vec![hidden_dim], Default::default());
let output_linear = nn::linear(vs / "output_linear", hidden_dim, vocab_size, Default::default());
Self {
token_embedding, linear_q, linear_k, linear_v, linear_out,
feed_forward, layer_norm_1, layer_norm_2, output_linear
}
}
fn forward(&self, x: &Tensor) -> Tensor {
let embeddings = self.token_embedding.forward(x);
let q = self.linear_q.forward(&embeddings);
let k = self.linear_k.forward(&embeddings);
let v = self.linear_v.forward(&embeddings);
let attention_output = q.matmul(&k.transpose(-2, -1)).softmax(-1, Kind::Float).matmul(&v);
let attention_output = self.linear_out.forward(&attention_output);
let normed_attention = self.layer_norm_1.forward(&(embeddings + attention_output));
let ff_output = self.feed_forward.forward(&normed_attention);
let normed_output = self.layer_norm_2.forward(&(normed_attention + ff_output));
self.output_linear.forward(&normed_output)
}
}
/// Function to evaluate the model's accuracy by comparing the predicted tokens
/// with the target tokens and computing the percentage of correct predictions.
fn evaluate(model: &AdvancedGPT, inputs: &[Tensor], targets: &[Tensor]) -> f64 {
let mut correct_predictions = 0;
let mut total_predictions = 0;
for (input, target) in inputs.iter().zip(targets.iter()) {
let logits = model.forward(input);
let predicted_indices = logits.argmax(-1, false); // Get predicted token indices.
let correct = predicted_indices.eq_tensor(target).to_kind(Kind::Int64).sum(Kind::Int64);
correct_predictions += i64::from(correct);
total_predictions += target.size()[0];
}
correct_predictions as f64 / total_predictions as f64 // Return the accuracy.
}
/// Function to plot the loss using the plotters crate
fn plot_loss(losses: &Vec<f64>) {
let root = BitMapBackend::new("loss_plot.png", (640, 480)).into_drawing_area();
root.fill(&WHITE).unwrap();
// Compute the y-axis range (min and max loss values)
let min_loss = losses.iter().cloned().fold(f64::INFINITY, f64::min);
let max_loss = losses.iter().cloned().fold(f64::NEG_INFINITY, f64::max);
// Build the chart using correct ranges for x and y
let mut chart = ChartBuilder::on(&root)
.caption("Training Loss per Epoch", ("sans-serif", 50).into_font())
.margin(3)
.x_label_area_size(30)
.y_label_area_size(30)
.build_cartesian_2d(0..losses.len(), min_loss..max_loss)
.unwrap();
chart.configure_mesh().draw().unwrap();
// Plot the loss as a line series
chart.draw_series(LineSeries::new(
(0..).zip(losses.iter().cloned()),
&RED,
)).unwrap();
root.present().unwrap();
}
fn main() {
let device = Device::cuda_if_available();
let vs = nn::VarStore::new(device);
let vocab: Vec<char> = "abcdefghijklmnopqrstuvwxyz ".chars().collect();
let vocab_size = vocab.len() as i64;
let seq_len = 5;
let num_samples = 1000;
let (inputs, targets) = generate_synthetic_data(&vocab, seq_len, num_samples);
let hidden_dim = 128;
let model = AdvancedGPT::new(&vs.root(), vocab_size, hidden_dim);
let mut opt = nn::Adam::default().build(&vs, 1e-3).unwrap();
let mut losses = Vec::new(); // To store the loss for each epoch
for epoch in 1..=500 {
let mut total_loss = 0.0;
for (input, target) in inputs.iter().zip(targets.iter()) {
let logits = model.forward(input);
let loss = logits.cross_entropy_for_logits(target);
opt.backward_step(&loss);
total_loss += f64::from(loss);
}
let average_loss = total_loss / num_samples as f64;
losses.push(average_loss);
println!("Epoch: {}, Loss: {:.4}", epoch, average_loss);
}
// Plot the loss after training
plot_loss(&losses);
// Evaluate the model's accuracy.
let accuracy = evaluate(&model, &inputs, &targets);
println!("Evaluation accuracy: {:.4}", accuracy);
}
The model begins by embedding the input tokens, followed by applying self-attention, which allows it to focus on relevant parts of the input sequence. The self-attention mechanism computes scaled dot-product attention, transforming queries, keys, and values through linear layers to capture contextual relationships within the input. After attention, the embeddings pass through a feed-forward network with residual connections and layer normalization to stabilize training and improve performance. The final output is generated via a linear layer, producing logits that represent the predicted token probabilities. The model is trained over 500 epochs with synthetic data, using cross-entropy loss to guide learning, and its accuracy is evaluated by comparing the predicted token indices with the actual target indices.
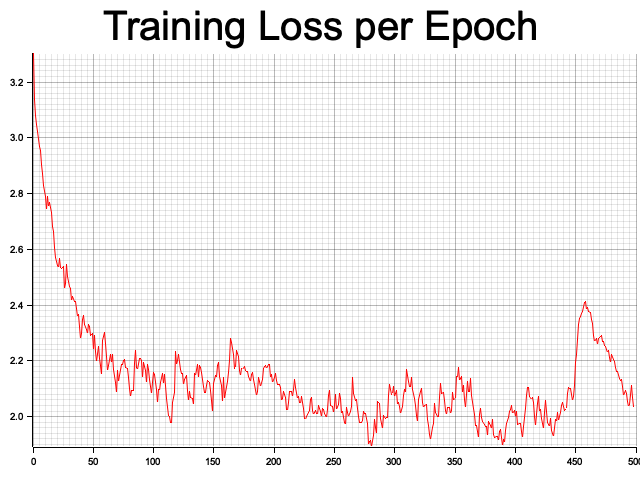
Figure 6: Loss plot of character level language model using GPT-2 like architecture.
Further improvements could include adding a validation dataset to monitor validation loss during training, which would help in detecting overfitting. Additionally, incorporating positional encoding can enhance the model's ability to capture positional information in sequences. Another enhancement could involve experimenting with hyperparameters such as learning rate, hidden dimensions, or adding multiple attention heads to further improve model performance.
In conclusion, Large Language Models have reshaped the landscape of artificial intelligence, allowing machines to perform complex language tasks with remarkable accuracy. From the Transformer architecture and attention mechanisms to pre-training and fine-tuning, the mathematical foundations of LLMs enable their unparalleled performance. With wide-ranging applications across industries and continuous advancements in scale, LLMs are set to remain a dominant force in the AI-driven future.
1.2. Rust Language Features for LLMs
In the development and deployment of Large Language Models (LLMs), efficient memory management, concurrency, and performance optimization are critical factors, especially when dealing with large-scale data and computations. Rust, a systems programming language known for its memory safety and concurrency features, provides unique advantages in the context of LLM implementation. Unlike traditional programming languages like C++ or Python, Rust’s ownership model ensures that data is handled safely without the need for a garbage collector. This is particularly relevant for LLMs, where models are often large and resource-intensive, and managing memory efficiently can have a significant impact on performance.
Figure 7: Rust offers amazing features for LLMs development and serving.
At the core of Rust’s approach to memory management is its ownership and borrowing system, which guarantees that data is either owned by a single variable or borrowed in a way that ensures safe access. This design prevents issues like dangling pointers or memory leaks, common in languages without built-in memory safety mechanisms. For LLM implementations, where large tensors and complex data structures are manipulated, Rust’s strict control over memory can prevent common bugs and improve runtime performance, making it a strong candidate for building high-performance LLM systems.
When building LLMs in Rust, tensor operations and matrix computations are essential, as they form the backbone of model training and inference. Rust provides powerful libraries such as tch-rs and ndarray, which enable high-performance tensor computations. tch-rs is a Rust binding for the popular PyTorch framework, allowing Rust developers to leverage PyTorch’s highly optimized tensor operations and deep learning capabilities while benefiting from Rust's performance advantages. The ndarray crate, on the other hand, offers n-dimensional array support with efficient handling of matrix operations, making it suitable for numerical tasks like tensor manipulation, which are integral to the operation of LLMs. These libraries not only provide the necessary functionality for handling large datasets and complex operations but also integrate seamlessly with Rust’s memory safety guarantees.
Formally, the manipulation of tensors involves operations like matrix multiplication, which is a core part of training LLMs. For example, given two matrices $A$ and $B$, the matrix multiplication is defined as:
$$C_{ij} = \sum_{k} A_{ik} B_{kj}$$
In Rust, using libraries like tch-rs, this can be efficiently computed while leveraging Rust’s low-level control over memory. Additionally, Rust’s support for concurrency through features like threads, async/await, and the Rayon crate for parallelism allows for distributing tensor operations across multiple CPU or GPU cores, making large-scale model training feasible without sacrificing safety or performance. This ability to efficiently handle concurrent computations is crucial when training or fine-tuning LLMs, which often require distributing workloads over multiple processors to achieve faster training times.
Another advantage of Rust for LLMs lies in its memory management techniques, which allow developers to optimize the allocation and deallocation of resources explicitly. This is particularly useful when working with large models that consume significant memory resources. In contrast to languages like Python, where memory management is often handled automatically but can lead to unpredictable garbage collection cycles, Rust allows for deterministic memory handling, which reduces overhead and improves predictability in high-performance applications like LLM training.
Here’s a simple Rust code that implements a basic LLM using the tch-rs crate and a pre-trained BERT architecture. The provided Rust code demonstrates the use of a pre-trained BERT model for masked language modeling. It leverages the tch-rs and rust-bert libraries to load the model, tokenizer, and weights, and runs a forward pass to predict a masked token in a given sentence. Specifically, it tokenizes a sentence with a masked word, runs the masked language modeling task to predict the missing word, and then decodes the output to display the predicted token.
[dependencies]
anyhow = "1.0.90"
rust-bert = "0.19.0"
tch = "0.8.0"
rust_tokenizers = "8.1.1"
use rust_bert::bert::{BertConfig, BertForMaskedLM, BertModelResources, BertVocabResources};
use rust_bert::resources::{RemoteResource, ResourceProvider};
use rust_tokenizers::tokenizer::{BertTokenizer, Tokenizer, TruncationStrategy};
use tch::{Device, Tensor};
fn main() -> anyhow::Result<()> {
// Load the pre-trained BERT model resources for masked language modeling
let vocab_resource = RemoteResource::from_pretrained(BertVocabResources::BERT);
let weights_resource = RemoteResource::from_pretrained(BertModelResources::BERT);
// Device configuration
let device = Device::cuda_if_available();
// Load the BERT config using the default configuration
let config = BertConfig::default(); // Use default BERT configuration
// Load the BERT model with configuration and weights
let mut vs = tch::nn::VarStore::new(device); // Declare vs as mutable
let model = BertForMaskedLM::new(&vs.root(), &config); // Initialize the model
vs.load(weights_resource.get_local_path()?)?; // Load weights
// Load the tokenizer
let vocab_path = vocab_resource.get_local_path()?;
let tokenizer = BertTokenizer::from_file(vocab_path.to_str().unwrap(), true, false)?;
// Example input text with a masked token
let input_text = "Rust is a [MASK] programming language.";
// Tokenize the input text
let tokenized_input = tokenizer.encode(input_text, None, 128, &TruncationStrategy::LongestFirst, 0);
let input_tensor = Tensor::of_slice(&tokenized_input.token_ids).to_device(device).unsqueeze(0); // Add batch dimension
// Forward pass through the model (masked language modeling task)
let output = model.forward_t(
Some(&input_tensor),
None,
None,
None,
None,
None, // Option<&Tensor>
None, // Option<&Tensor>
false,
);
// Extract prediction scores from the output structure (instead of logits)
let prediction_scores = output.prediction_scores;
// Get the mask token ID using `convert_tokens_to_ids` method
let mask_token = "[MASK]";
let mask_token_id = tokenizer.convert_tokens_to_ids(&[mask_token])[0]; // Retrieve the mask token ID
// Find the index of the mask token in the input sequence
let mask_index = tokenized_input.token_ids.iter().position(|&id| id == mask_token_id).unwrap();
// Decode the output prediction: extract the predicted token for the mask position
let predicted_token_id = prediction_scores
.get(0)
.get(mask_index.try_into().unwrap()) // Convert usize to i64
.argmax(-1, false)
.int64_value(&[]); // Get predicted token ID
let predicted_token = tokenizer.decode(&[predicted_token_id], true, true); // Decode the token ID to string
println!("Predicted token: {}", predicted_token);
Ok(())
}
The code first sets up the BERT model and tokenizer, loading pre-trained weights and configuration from the Hugging Face repository. The input text, containing a masked token ([MASK]), is tokenized and transformed into a tensor format, which is fed into the BERT model. The model predicts the most likely word for the masked position. After the forward pass, the output consists of prediction scores, and the code retrieves the predicted token ID for the masked word. Finally, it decodes this ID into the corresponding word using the tokenizer and prints the result.
To enhance the code, error handling and flexibility could be improved. For example, rather than panicking on potential errors (such as failed tokenization or tensor operations), it would be beneficial to handle those cases gracefully. Additionally, instead of hardcoding the input text, the code could accept dynamic input from the user or from files, making it more versatile. Another enhancement would be to add functionality to handle sentences with multiple masked tokens, allowing for multi-word prediction.
In terms of high-performance computing (HPC), Rust has been increasingly adopted in industries where performance and safety are critical. For instance, machine learning infrastructure at companies like Amazon Web Services (AWS) has integrated Rust in performance-critical components to achieve low latency and efficient resource management. In the context of LLMs, integrating Rust with HPC frameworks allows for faster model training, better memory utilization, and the ability to handle larger models without hitting performance bottlenecks. By utilizing Rust’s ecosystem, developers can write scalable, high-performance applications that support both CPU and GPU acceleration, crucial for modern LLM applications in industries such as healthcare (e.g., for medical document analysis) and finance (e.g., for fraud detection or market sentiment analysis).
Recent trends show that as LLMs grow in scale—such as GPT-4 and LLaMA—there is a greater need for systems-level optimizations to handle the increasing computational and memory demands. Rust’s emphasis on zero-cost abstractions, combined with its ecosystem of efficient crates, positions it as an attractive choice for building LLM applications that are both scalable and robust. The language’s capability to safely and efficiently handle concurrency, tensor operations, and memory management provides a foundation for implementing high-performance LLMs that can meet the demands of modern AI-driven industries.
In summary, Rust’s unique features—memory safety, ownership model, concurrency support, and its integration with libraries like tch-rs and ndarray—make it an excellent language for implementing LLMs. By using Rust, developers can ensure efficient, safe, and high-performance handling of large datasets and computational tasks, which is essential for the continued advancement of LLM technologies in various domains.
1.3. Implementing LLM Architectures in Rust
Implementing Large Language Model (LLM) architectures in Rust requires a deep understanding of both the underlying machine learning concepts and Rust’s unique system-level features. Building LLMs involves assembling key components, including the tokenizer, embedding layers, and Transformer blocks, which are the foundational elements of these models. Rust, with its powerful memory safety and concurrency capabilities, provides a performant and safe environment to implement these components while taking full advantage of system resources.
At the heart of any LLM is the tokenizer, which breaks down input text into a sequence of tokens. Tokenization is crucial for converting raw text into a form that the model can process. A common tokenization method involves dividing text into subword units, such as in Byte-Pair Encoding (BPE). For instance, given a word like "machine," it can be broken down into smaller units like \["ma", "chine"\]. In Rust, the tokenizer can be implemented using libraries like tokenizers, which provides efficient tokenization processes while ensuring memory safety and concurrency. The tokenized text is then mapped to numerical vectors in the embedding layer, where each token is assigned a high-dimensional representation. Mathematically, given a token ttt, its embedding vector ete_tet is a point in a ddd-dimensional space, where ddd is the dimensionality of the embedding.
Once tokenized input is embedded, it passes through Transformer blocks, the core component of modern LLMs. A Transformer block consists of multiple layers, primarily the multi-head self-attention mechanism and feed-forward neural networks. In the self-attention mechanism, the model attends to different parts of the input sequence by computing attention scores. The tch-rs crate in Rust allows the efficient implementation of this attention mechanism, as it provides bindings to PyTorch’s highly optimized tensor operations, while also supporting multi-threading for faster computations.
Rust’s parallel processing capabilities can be leveraged for both model training and inference, enabling efficient use of hardware resources like CPUs and GPUs. The Rayon crate allows for data parallelism, where batches of data can be processed concurrently, significantly speeding up both the training and inference phases. During training, gradients from multiple data points can be computed in parallel, and Rust’s async/await functionality can be utilized for efficient asynchronous computation, which is especially useful in large-scale LLMs. This not only improves throughput but also ensures that the model scales efficiently with available hardware.
To build and deploy a basic LLM in Rust, one must start by structuring the codebase around the major components—tokenization, embedding, Transformer blocks, and model inference. Rust’s strict type system ensures that errors are caught early in development, making the implementation more robust. Once the model architecture is in place, it can be trained on a dataset using a combination of libraries like ndarray for numerical computations and tch-rs for deep learning operations. After training, the model can be deployed as a service using frameworks like Actix-web or Rocket, which allow for building high-performance web applications in Rust. These frameworks enable the deployment of the LLM as a REST API, where the model can process text input and generate output in real-time.
A useful case study in this context is the development of a simple language model or chatbot in Rust. The chatbot can be built using a pre-trained LLM model, fine-tuned for conversational tasks. For example, using a GPT-like architecture, a chatbot can generate human-like responses to user input by leveraging Rust’s speed and efficiency in processing conversational data. With Rust’s low-level control over memory and its performance guarantees, the chatbot can be optimized to handle a large number of simultaneous user requests, making it scalable for production-level deployment.
When implementing LLMs in Rust, debugging and testing become essential parts of the development process. Rust’s strong emphasis on compile-time error checking reduces the likelihood of runtime errors, making debugging more efficient. Additionally, unit testing can be performed using Rust’s built-in test framework, ensuring that individual components like tokenization, embedding, and attention mechanisms work as expected. Once the model is deployed, continuous monitoring and optimization are necessary to ensure that it performs well under real-world conditions. Rust’s integration with profiling tools and support for low-level optimizations makes it easier to fine-tune both memory usage and processing speed.
The following code demonstrates the use of Rust, the Huggingface candle crate, and pre-trained models to build a natural language processing (NLP) pipeline for sentence embeddings and similarity calculations. The script loads a pre-trained BERT-based model from Huggingface's model hub, processes a set of input sentences, and uses BERT to generate embeddings. These embeddings are then averaged and compared using cosine similarity to determine how similar the sentences are to one another. The code makes efficient use of Rust's strong performance capabilities and memory safety features to handle NLP tasks that are typically computationally intensive.
[dependencies]
accelerate-src = "0.3.2"
anyhow = "1.0.90"
candle-core = "0.7.2"
candle-nn = "0.7.2"
candle-transformers = "0.7.2"
clap = "4.5.20"
hf-hub = "0.3.2"
serde = "1.0.210"
serde_json = "1.0.132"
tokenizers = "0.20.1"
use candle_transformers::models::bert::{BertModel, Config, HiddenAct, DTYPE};
use anyhow::{Error as E, Result};
use candle_core::{Device, Tensor};
use candle_nn::VarBuilder;
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::{PaddingParams, Tokenizer};
use std::fs;
fn build_model_and_tokenizer() -> Result<(BertModel, Tokenizer)> {
let device = Device::cuda_if_available(0)?; // Automatically use GPU 0 if available
let model_id = "sentence-transformers/all-MiniLM-L6-v2".to_string();
let revision = "main".to_string();
let repo = Repo::with_revision(model_id, RepoType::Model, revision);
let (config_filename, tokenizer_filename, weights_filename) = {
let api = Api::new()?;
let api = api.repo(repo);
let config = api.get("config.json")?;
let tokenizer = api.get("tokenizer.json")?;
let weights = api.get("model.safetensors")?;
(config, tokenizer, weights)
};
let config = fs::read_to_string(config_filename)?;
let mut config: Config = serde_json::from_str(&config)?;
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[weights_filename], DTYPE, &device)? };
config.hidden_act = HiddenAct::GeluApproximate;
let model = BertModel::load(vb, &config)?;
Ok((model, tokenizer))
}
fn main() -> Result<()> {
let (model, mut tokenizer) = build_model_and_tokenizer()?;
let device = &model.device;
let sentences = [
"The cat sits outside",
"A man is playing guitar",
"I love pasta",
"The new movie is awesome",
"The cat plays in the garden",
"A woman watches TV",
"The new movie is so great",
"Do you like pizza?",
];
let n_sentences = sentences.len();
// Set padding for the batch
let pp = PaddingParams {
strategy: tokenizers::PaddingStrategy::BatchLongest,
..Default::default()
};
tokenizer.with_padding(Some(pp));
let tokens = tokenizer
.encode_batch(sentences.to_vec(), true)
.map_err(E::msg)?;
let token_ids = tokens
.iter()
.map(|tokens| {
let tokens = tokens.get_ids().to_vec();
Ok(Tensor::new(tokens.as_slice(), device)?)
})
.collect::<Result<Vec<_>>>()?;
let attention_mask = tokens
.iter()
.map(|tokens| {
let tokens = tokens.get_attention_mask().to_vec();
Ok(Tensor::new(tokens.as_slice(), device)?)
})
.collect::<Result<Vec<_>>>()?;
let token_ids = Tensor::stack(&token_ids, 0)?;
let attention_mask = Tensor::stack(&attention_mask, 0)?;
let token_type_ids = token_ids.zeros_like()?;
println!("Running inference on batch {:?}", token_ids.shape());
let embeddings = model.forward(&token_ids, &token_type_ids, Some(&attention_mask))?;
println!("Generated embeddings {:?}", embeddings.shape());
// Apply some avg-pooling by taking the mean embedding value for all tokens (including padding)
let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?;
let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?;
let embeddings = normalize_l2(&embeddings)?;
println!("Pooled embeddings {:?}", embeddings.shape());
// Calculate cosine similarities between sentences
let mut similarities = vec![];
for i in 0..n_sentences {
let e_i = embeddings.get(i)?;
for j in (i + 1)..n_sentences {
let e_j = embeddings.get(j)?;
let sum_ij = (&e_i * &e_j)?.sum_all()?.to_scalar::<f32>()?;
let sum_i2 = (&e_i * &e_i)?.sum_all()?.to_scalar::<f32>()?;
let sum_j2 = (&e_j * &e_j)?.sum_all()?.to_scalar::<f32>()?;
let cosine_similarity = sum_ij / (sum_i2 * sum_j2).sqrt();
similarities.push((cosine_similarity, i, j))
}
}
// Print top 5 sentence pairs with the highest similarity
similarities.sort_by(|u, v| v.0.total_cmp(&u.0));
for &(score, i, j) in similarities[..5].iter() {
println!("Score: {score:.2} '{}' '{}'", sentences[i], sentences[j]);
}
Ok(())
}
pub fn normalize_l2(v: &Tensor) -> Result<Tensor> {
Ok(v.broadcast_div(&v.sqr()?.sum_keepdim(1)?.sqrt()?)?)
}
The code starts by defining a function, build_model_and_tokenizer(), which loads a pre-trained BERT model from Huggingface's sentence-transformers/all-MiniLM-L6-v2 repository, along with its tokenizer and model weights. The model and tokenizer are instantiated using the candle crate's tensor operations and are then used to encode a batch of input sentences. After tokenization, the model performs a forward pass to generate embeddings for each sentence. These embeddings are pooled by averaging the values of each token, resulting in a single vector per sentence. Finally, the script computes cosine similarities between the sentence embeddings to determine which pairs of sentences are most alike, printing the top 5 most similar sentence pairs.
The Huggingface candle crate is a Rust-based framework designed for training and deploying transformer models with optimized performance and memory handling. It allows users to leverage the efficiency of Rust while working with complex deep learning models, such as BERT, without needing to rely on bindings to Python-based frameworks like PyTorch. Candle provides a native Rust interface for tensor operations, model building, and training, all while maintaining compatibility with Huggingface's extensive ecosystem of pre-trained models. This makes it an excellent choice for developers looking to build scalable, high-performance machine learning applications in Rust, particularly in resource-constrained environments.
The latest trends in LLM deployment also emphasize the importance of efficient inference in production environments. As LLMs become larger, the need for optimized inference pipelines becomes critical. Rust’s performance, combined with tools like ONNX (Open Neural Network Exchange) and TorchScript, allows models to be exported and optimized for inference without sacrificing the memory safety guarantees that Rust provides. This makes Rust a compelling choice for building large-scale, production-ready LLM systems that are both performant and secure.
In conclusion, implementing LLM architectures in Rust combines the language’s strengths—memory safety, parallel processing, and high performance—with the capabilities of modern deep learning libraries. By utilizing Rust’s features for efficient memory management and leveraging its ecosystem for tensor operations and concurrency, developers can build robust, scalable LLMs suitable for a wide range of applications, from chatbots to real-time text generation systems. The result is a high-performance, production-ready deployment of LLMs that can meet the growing demands of AI-driven industries.
1.4. Challenges and Ethical Considerations
As Large Language Models (LLMs) continue to evolve, their development and deployment present both technical challenges and ethical considerations that must be addressed thoughtfully. In the context of Rust, the unique demands of handling large datasets and model sizes pose significant hurdles. LLMs often require enormous amounts of memory and computational resources to train and deploy, which can strain both hardware and software. Rust, with its ownership model and memory safety guarantees, helps manage resources efficiently, but scaling LLMs still requires careful engineering. One of the primary technical challenges is optimizing tensor operations and data processing in memory-constrained environments. For instance, performing matrix multiplications, as seen in Transformer architectures, where the computational complexity scales quadratically with sequence length, demands efficient memory management and parallel computation. Given an input sequence $\mathbf{X}$, computing the attention matrix $\mathbf{A} = \mathbf{X}\mathbf{X}^T$in Rust involves leveraging libraries like tch-rs while ensuring minimal memory overhead through Rust's ownership and borrowing system. Rust's low-level control over memory allows developers to optimize such operations, but handling very large models in memory-intensive environments remains a challenge, often requiring offloading techniques such as model sharding or quantization.
Figure 8: LLM ethical consideration complexity.
In addition to the technical challenges, the ethical implications of LLM deployment have become a critical area of discussion, particularly concerning bias, fairness, and transparency. LLMs, by their very nature, are trained on vast datasets that can contain inherent biases—social, cultural, or linguistic—that may manifest in the model’s outputs. For example, language models may unintentionally generate biased responses based on gender, race, or ethnicity if trained on datasets that reflect these biases. Formal studies in machine learning fairness have highlighted how LLMs can perpetuate and even amplify biases when used in real-world applications like hiring or criminal justice. In Rust-based LLM systems, ensuring transparency involves making models interpretable and accountable. This can be addressed by integrating explainability frameworks that provide insights into how a model arrived at a particular decision or prediction, fostering trust in AI systems. Moreover, Rust's robust ecosystem can be extended to build auditability tools that track and report on model behavior during deployment, ensuring compliance with ethical standards.
A key concern in the deployment of LLMs is ensuring data privacy and security. LLMs often rely on large datasets that may contain sensitive information, especially in fields such as healthcare or finance. To address these concerns, it is crucial to adopt strategies that safeguard data throughout the model's lifecycle. One such strategy is differential privacy, a mathematical framework designed to prevent the model from memorizing or leaking sensitive information from the training data. In formal terms, differential privacy ensures that any query to the model yields similar results regardless of whether a particular individual’s data is included in the dataset, thereby protecting privacy. The challenge in Rust-based systems is implementing privacy-preserving techniques in a manner that aligns with Rust’s strict memory safety guarantees while maintaining performance. Furthermore, secure enclaves and homomorphic encryption are emerging as ways to enable encrypted data processing without exposing raw data, which can be particularly useful when deploying LLMs in sensitive environments. Integrating such techniques with Rust’s high-performance systems can pave the way for more secure AI applications.
Performance optimization remains a crucial consideration in deploying LLMs at scale, particularly when building models in Rust. Techniques such as model pruning, quantization, and low-rank approximation can reduce the size and computational complexity of LLMs without significantly compromising accuracy. Mathematically, pruning involves eliminating less critical parameters from the model’s weight matrix, leading to sparse matrix representations that reduce both memory usage and computation. Given a weight matrix $\mathbf{W} \in \mathbb{R}^{n \times m}$, pruning aims to reduce the number of non-zero elements, transforming it into a sparse matrix. Rust's capabilities for fine-grained memory management make it well-suited for implementing these optimization techniques, as developers can directly manage how the sparse matrices are stored and processed in memory. Additionally, quantization, which involves reducing the precision of the model’s parameters (e.g., from 32-bit to 8-bit), is another widely adopted technique in optimizing LLMs. This technique reduces memory usage and improves inference speed, and Rust’s type system enables precise control over how data is represented, ensuring safety even when manipulating lower-precision data formats.
The future of LLM development is evolving rapidly, and Rust has the potential to play a significant role in addressing emerging challenges. As LLMs grow larger and more complex, the need for high-performance, scalable, and secure systems will become even more critical. Rust’s emphasis on concurrency, combined with its ability to handle system-level optimizations, positions it well for future LLM implementations that require distributed computing and multi-node training. Additionally, with the increasing focus on energy-efficient AI, Rust’s ability to produce highly optimized code with minimal runtime overhead will be essential in developing LLMs that are not only performant but also sustainable. In industries like healthcare and autonomous systems, where AI applications require both precision and reliability, Rust can provide a solid foundation for building LLMs that meet stringent regulatory and safety standards.
In conclusion, while Rust offers several advantages for implementing and deploying LLMs, including memory safety, performance optimization, and robust concurrency support, there are also significant challenges, particularly when dealing with large datasets and ensuring ethical compliance. By leveraging Rust’s unique features and integrating emerging privacy-preserving and fairness-enhancing techniques, developers can address both the technical and ethical challenges posed by modern LLMs. As the field of LLM development continues to advance, Rust's role in building secure, efficient, and ethically sound AI systems will become increasingly prominent.
1.5. Conclusion
Chapter 1 has laid a strong foundation for understanding the intersection of Large Language Models and Rust programming. By integrating theoretical insights with practical implementations, this chapter equips readers with the knowledge and tools needed to build efficient and ethical LLMs using Rust. The journey ahead promises to explore these concepts in greater depth, with Rust serving as a key enabler for innovative and responsible AI development.
1.5.1. Further Learning with GenAI
The path to mastering Large Language Models with Rust is one of intellectual rigor and technical excellence. These comprehensive prompts are crafted to challenge your understanding, push the boundaries of your knowledge, and inspire you to delve deeply into both the theory and practice of cutting-edge AI.
Detail the architectural and theoretical advancements that have transitioned NLP from statistical models to Large Language Models like GPT and BERT. How have these advancements impacted the performance, scalability, and applicability of NLP tasks across different domains? Provide a deep analysis of how these models handle complex language understanding compared to their predecessors.
Analyze the inner workings of the Transformer architecture, focusing on the self-attention mechanism and its role in handling long-range dependencies in text. How does the multi-head attention mechanism improve the model’s ability to process information, and what are the implications for model scalability and parallelism? Explore the mathematical underpinnings of these mechanisms.
Discuss the various tokenization techniques used in LLMs, such as Byte-Pair Encoding (BPE) and WordPiece. How do these techniques influence model training and inference in terms of efficiency, accuracy, and handling of out-of-vocabulary words? Compare and contrast the implementation of these techniques in Rust versus other programming environments.
Explore the process of creating and optimizing embedding layers in LLMs using Rust. How does Rust's memory safety and management capabilities enhance the efficiency of embedding operations? Provide examples of optimizing embeddings in large-scale models, and discuss the trade-offs between memory usage and computational performance.
Explain the pre-training and fine-tuning phases of LLMs in depth. How do different pre-training objectives (e.g., masked language modeling, next sentence prediction) influence the model’s capabilities? Provide a step-by-step guide on implementing these phases in Rust, including handling large datasets, optimizing performance, and fine-tuning for specific downstream tasks.
Delve into the technical challenges of handling large-scale datasets in Rust for training LLMs. What strategies can be employed to manage memory efficiently, reduce I/O bottlenecks, and parallelize data processing? Discuss advanced techniques such as distributed training, data sharding, and lazy loading in the Rust ecosystem.
Analyze how Rust’s concurrency and parallel processing capabilities can be leveraged to accelerate the training of LLMs. What are the best practices for implementing multi-threading, async programming, and parallel execution in Rust to handle the computational demands of LLMs? Provide examples of optimizing training pipelines with Rust’s concurrency features.
Explore the implications of Rust’s ownership and borrowing model on LLM development, particularly in managing large data structures like tensors and model parameters. How does this model contribute to memory safety and prevent common issues such as data races and memory leaks? Compare this approach to memory management in other languages like Python and C++.
Provide an in-depth analysis of how Rust crates like
tch-rsandndarraycan be used for efficient tensor operations in LLMs. What are the key features and optimizations provided by these crates, and how do they compare to popular libraries in other languages, such as TensorFlow or PyTorch? Demonstrate the implementation of complex tensor manipulations and their applications in LLMs.Discuss advanced techniques for optimizing the performance of LLMs implemented in Rust. This includes model pruning, quantization, and mixed-precision training. How can these techniques be integrated into a Rust-based training pipeline to enhance model efficiency without sacrificing accuracy? Provide detailed examples and benchmarks.
Guide the development of a simple yet comprehensive LLM-based application, such as a chatbot, using Rust. Discuss the architectural decisions, code structure, and optimization strategies that ensure the application is both performant and scalable. How can Rust’s features be fully utilized to handle real-time processing and large-scale deployment?
Explore the ethical implications of deploying LLMs in real-world applications, particularly focusing on issues of bias, fairness, and transparency. How can Rust be used to build more ethical AI systems, and what role does the language’s safety and performance features play in ensuring responsible AI development? Provide examples of mitigating bias during training and deployment.
Provide an in-depth analysis of the sources of bias in LLMs and their impact on various applications. How can Rust-based implementations address these biases through data augmentation, adversarial training, or algorithmic fairness techniques? Discuss the effectiveness of these approaches and how they can be integrated into the model development lifecycle.
Discuss the importance of model interpretability and explainability in LLMs. How can Rust be used to implement interpretable models or add explainability layers to existing models? Explore techniques like attention visualization, model introspection, and rule-based explanations within the context of Rust-based LLMs.
Compare the process of implementing LLMs in Rust with other programming languages like Python, Java, and C++. What are the unique challenges and benefits of using Rust for this purpose? Discuss the trade-offs in terms of performance, ease of development, and integration with existing AI frameworks.
Provide a comprehensive guide to deploying Rust-based LLMs in production environments. What are the critical factors to consider, such as scalability, security, and monitoring? How can Rust’s features be leveraged to ensure robust and reliable deployment pipelines? Include a discussion of cloud-native deployment options and containerization.
Explore how Rust’s concurrency model can be utilized to achieve efficient and scalable real-time inference with LLMs. What are the best practices for managing concurrent requests, optimizing latency, and ensuring consistent performance in high-demand applications? Provide practical examples and performance benchmarks.
Discuss the potential for integrating Rust with languages like Python or frameworks like TensorFlow for LLM development. What are the benefits of such integration, particularly in leveraging the strengths of both ecosystems? Provide a detailed guide to setting up and managing a hybrid Rust-based LLM development environment.
Analyze the future trends in Large Language Models, such as multimodal models, zero-shot learning, and continual learning. How is Rust positioned to support these advancements, particularly in terms of performance, safety, and scalability? Discuss the potential developments in Rust’s ecosystem that could further enhance its applicability to cutting-edge AI research.
Conduct a deep analysis of a real-world case study involving the deployment of LLMs in an industry like healthcare, finance, or technology. What challenges were faced during implementation, and how could Rust have been used to address these challenges more effectively? Discuss the lessons learned and how they can be applied to future LLM projects in Rust.
As you explore these prompts, remember that each one is an opportunity to innovate, build, and refine your skills, contributing to the exciting frontier of AI development with Rust. Embrace the challenge, and let your passion for learning guide you to new heights of expertise.
1.5.2. Hands On Practices
Self-Exercise 1.1: Advanced Tokenization and Embedding Optimization
Objective: To design and implement a custom tokenization and embedding pipeline that can efficiently process complex multilingual text data.
Tasks:
Research and design a custom tokenizer that can handle multilingual text, focusing on languages with non-Latin scripts and agglutinative languages.
Implement the tokenizer in Rust, incorporating both Byte-Pair Encoding (BPE) and character-level tokenization techniques.
Develop a custom embedding layer in Rust that can efficiently handle the outputs of your tokenizer.
Optimize the memory usage and computational efficiency of the embedding layer for large-scale text processing.
Evaluate the performance of your custom tokenizer and embedding layer on a multilingual dataset, comparing it with standard pre-trained embeddings.
Deliverables:
A Rust implementation of the custom tokenizer and embedding layer.
A detailed report comparing the performance, efficiency, and memory usage of your custom solution with pre-trained embeddings.
A comprehensive analysis of the trade-offs between different tokenization and embedding approaches for multilingual text data.
Self-Exercise 1.2: Custom Transformer Implementation
Objective: To design and train a miniature Transformer model from scratch using Rust, without relying on high-level deep learning libraries.
Tasks:
Study the Transformer architecture, focusing on attention mechanisms, layer normalization, and positional encoding.
Implement the Transformer model in Rust, utilizing basic tensor operations provided by crates like
ndarrayortch-rs.Train the model on a small dataset for a specific NLP task, such as machine translation or text summarization.
Optimize the training process by experimenting with different hyperparameters and optimization techniques.
Compare the performance of your custom Transformer with a baseline model implemented using a popular deep learning framework.
Deliverables:
A complete Rust implementation of the miniature Transformer model.
Training logs and performance metrics, including loss curves and accuracy scores.
A comparative analysis of the strengths and limitations of the Rust-based Transformer versus the baseline model.
Self-Exercise 1.3: Distributed Training Pipeline Development
Objective: To build a distributed training pipeline for Large Language Models using Rust, focusing on parallelization and scalability.
Tasks:
Design a distributed training architecture that leverages multiple GPUs or nodes in a cluster.
Implement gradient accumulation, synchronized parameter updates, and efficient data loading mechanisms in Rust.
Train a medium-sized language model on a large text corpus using the distributed pipeline.
Analyze the scalability and resource utilization of your pipeline compared to a non-distributed setup.
Experiment with different communication strategies (e.g., ring all-reduce, parameter server) to optimize training efficiency.
Deliverables:
A working distributed training pipeline implemented in Rust.
Performance benchmarks comparing distributed and non-distributed training setups.
A report detailing the scalability, efficiency, and challenges encountered during the implementation and training process.
Self-Exercise 1.4: Bias Mitigation and Fairness Auditing
Objective: To implement and evaluate advanced techniques for bias mitigation in Large Language Models, with a focus on fairness.
Tasks:
Identify sources of bias in a pre-trained LLM and quantify their impact on model performance across different demographic groups.
Implement bias mitigation techniques such as adversarial debiasing, bias regularization, and post-hoc adjustments in Rust.
Evaluate the effectiveness of these techniques on a sensitive task, using real-world data (e.g., job candidate evaluation, credit scoring).
Develop a fairness auditing tool in Rust that can automatically assess and report potential biases in LLMs.
Integrate the fairness auditing tool into your model development pipeline and test it on various datasets.
Deliverables:
A Rust implementation of the bias mitigation techniques.
An evaluation report on the effectiveness of these techniques in improving fairness.
A fully functional fairness auditing tool, along with documentation and examples of its use.
Self-Exercise 1.5: Secure Model Deployment
Objective: To design and implement a secure deployment strategy for a Rust-based Large Language Model, focusing on protection against adversarial attacks and data privacy.
Tasks:
Research and implement techniques such as differential privacy, secure multi-party computation, and encrypted model inference in Rust.
Simulate various attack scenarios (e.g., model inversion, membership inference, adversarial examples) and test the security of your deployed model.
Analyze the trade-offs between security measures and model performance, identifying areas for optimization.
Develop a secure deployment pipeline that integrates these security measures, ensuring minimal impact on performance.
Document the deployment process, including guidelines for maintaining security and privacy in production environments.
Deliverables:
A Rust-based implementation of security measures for LLM deployment.
A report on the effectiveness of the security techniques, including performance trade-offs and attack mitigation results.
A fully documented secure deployment pipeline, ready for production use, along with detailed guidelines for future deployments.
Comments